作者:海博 理想汽车高级大数据工程师、贾天福 理想汽车高级大数据工程师
引言:智能汽车时代的数据挑战
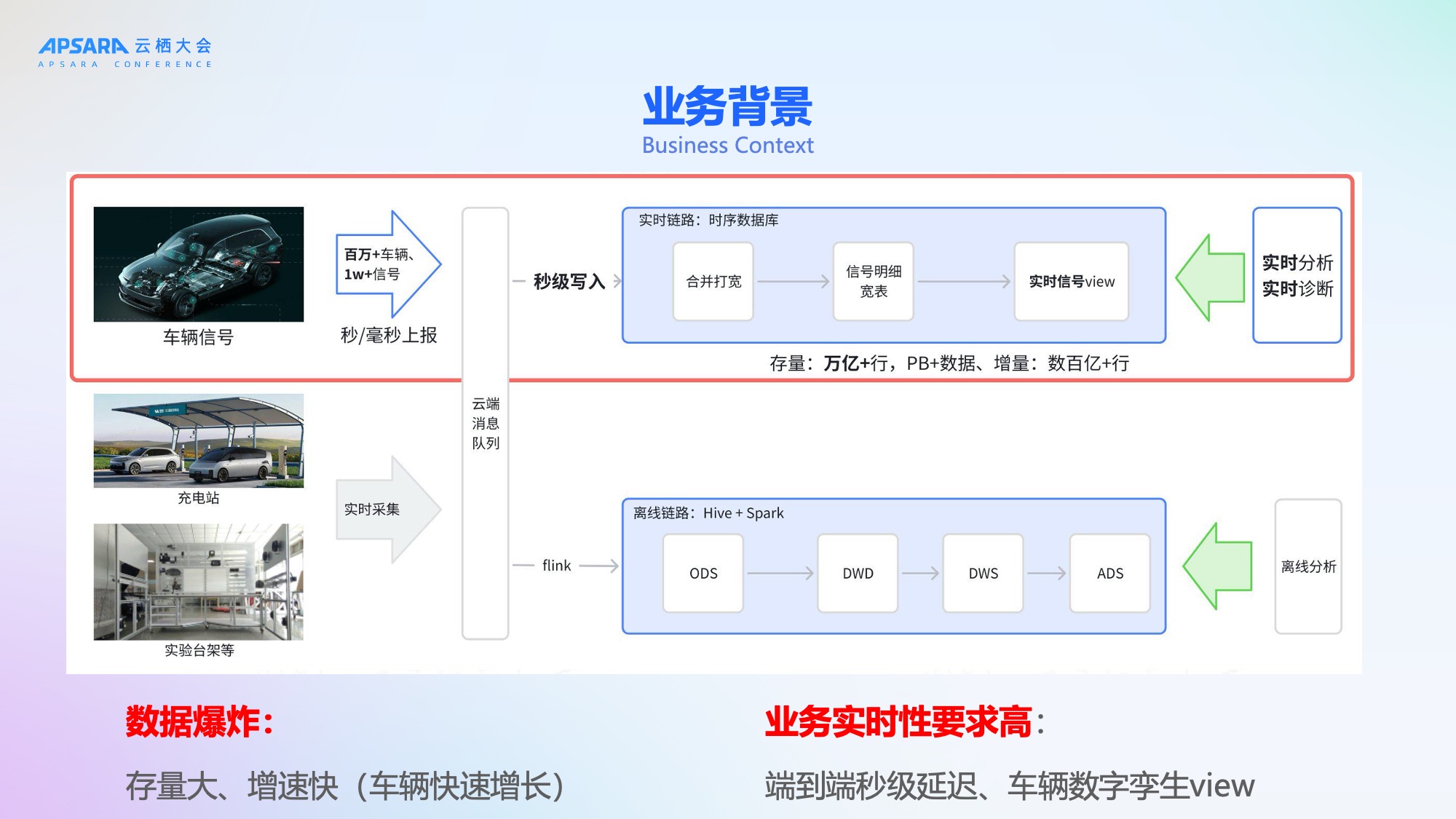
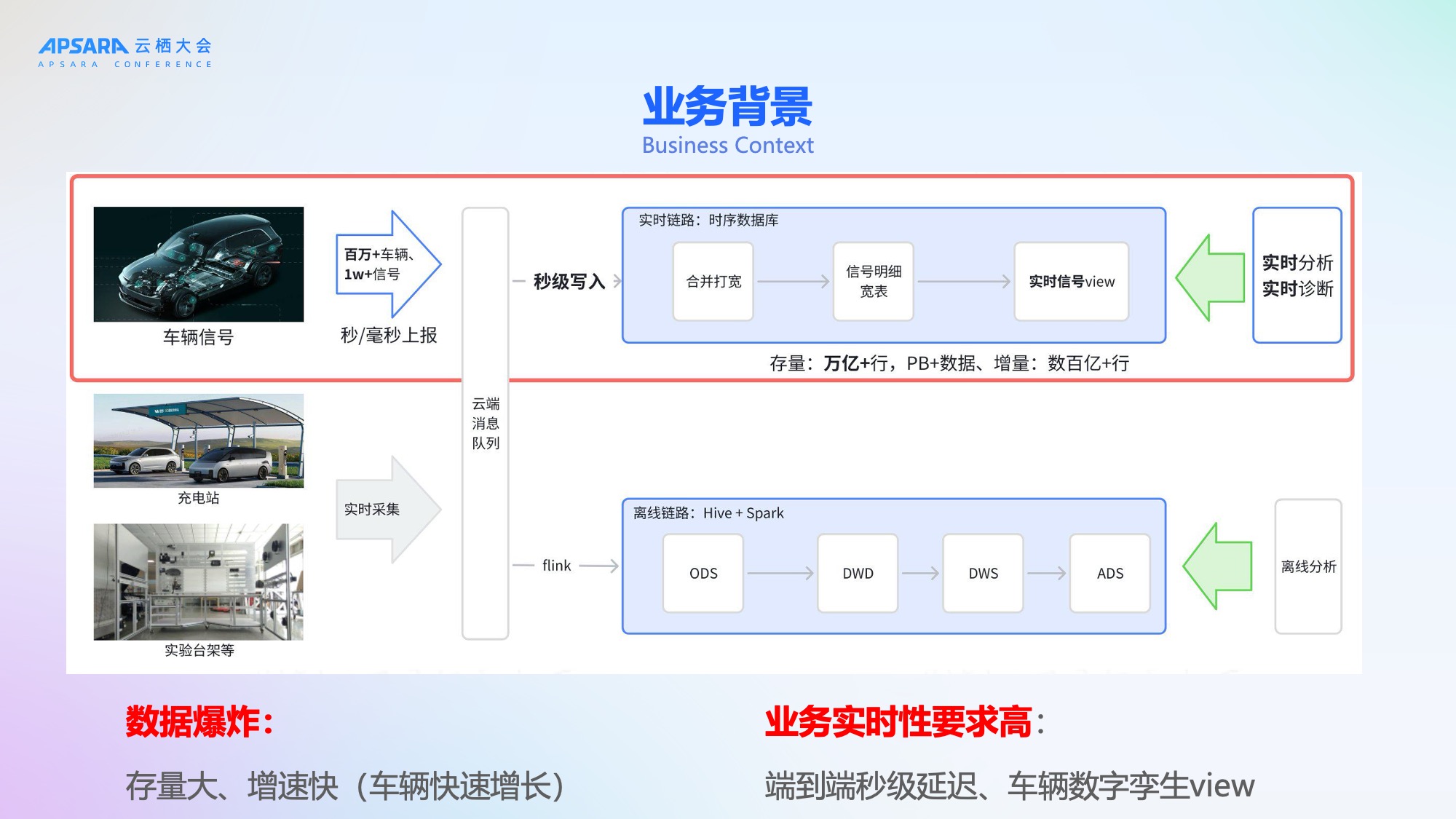
随着电动车和智能汽车的快速普及,车联网信号数据呈现爆发式增长。理想汽车作为国内领先的智能电动汽车企业,已拥有超过100万辆在网车辆,每辆车每秒上报多达上万个信号(如车速、胎压、温度、电池状态等),整体数据规模达到万亿级别。这些数据不仅体量巨大,而且对实时性要求极高------端到端延迟需控制在2秒以内,至少不超过5秒,以支撑数字孪生、智能诊断、车辆预警等关键业务场景。
理想汽车大数据团队面临的核心挑战是如何在保障高实时性的同时,实现系统的高稳定性、高弹性与低成本。为此,团队决定重构数据底座,引入阿里云 Hologres + Flink 技术栈,打造新一代车联网实时分析平台。本文将系统介绍这一实践过程。

一、海量车联网信号的挑战
理想汽车当前拥有100万辆以上存量汽车,每辆车约有1万个信号进行实时的秒级甚至毫秒级上报。这些信号涵盖制动系统、自动驾驶系统、动力系统、车身系统、座椅系统等多个维度,数据灌入实时数据库后,存量数据达万亿行、PB级别,日增数据达数百亿行。
业务对数据链路的实时性要求极高,端到端延迟需控制在2秒以内,至少不超过5秒。为满足这一需求,理想汽车曾构建了一套离线与实时双链路的整体保障方案。然而,随着数据爆炸式增长,进入2025年后,旧有技术栈问题频发,暴露出两大核心挑战:稳定性不足、弹性能力弱/成本高。
挑战一:稳定性不足
数据的持续增长不断触发系统瓶颈,导致故障频发。具体表现为:
- 写入延迟:节假日等流量高峰期间,写入RPS超过150万,系统出现明显延迟,无法满足业务时效性要求;
- 冷查询打满资源:大量30天以上的冷数据查询QPS峰值超1万,占用大量计算资源,影响热数据服务;
- 容错能力弱:系统故障时高度依赖人工处理,恢复效率低,最慢需12小时才能完全恢复;
- 流程不完善:业务接入缺乏准入评估,上线前测试不充分,导致资源错配与线上Bug频出;
- 缺乏兜底机制:升级需停服、难回滚,故障时无法快速止损。
这些问题叠加,使得系统SLA难以保障,严重影响用户体验与业务发展。

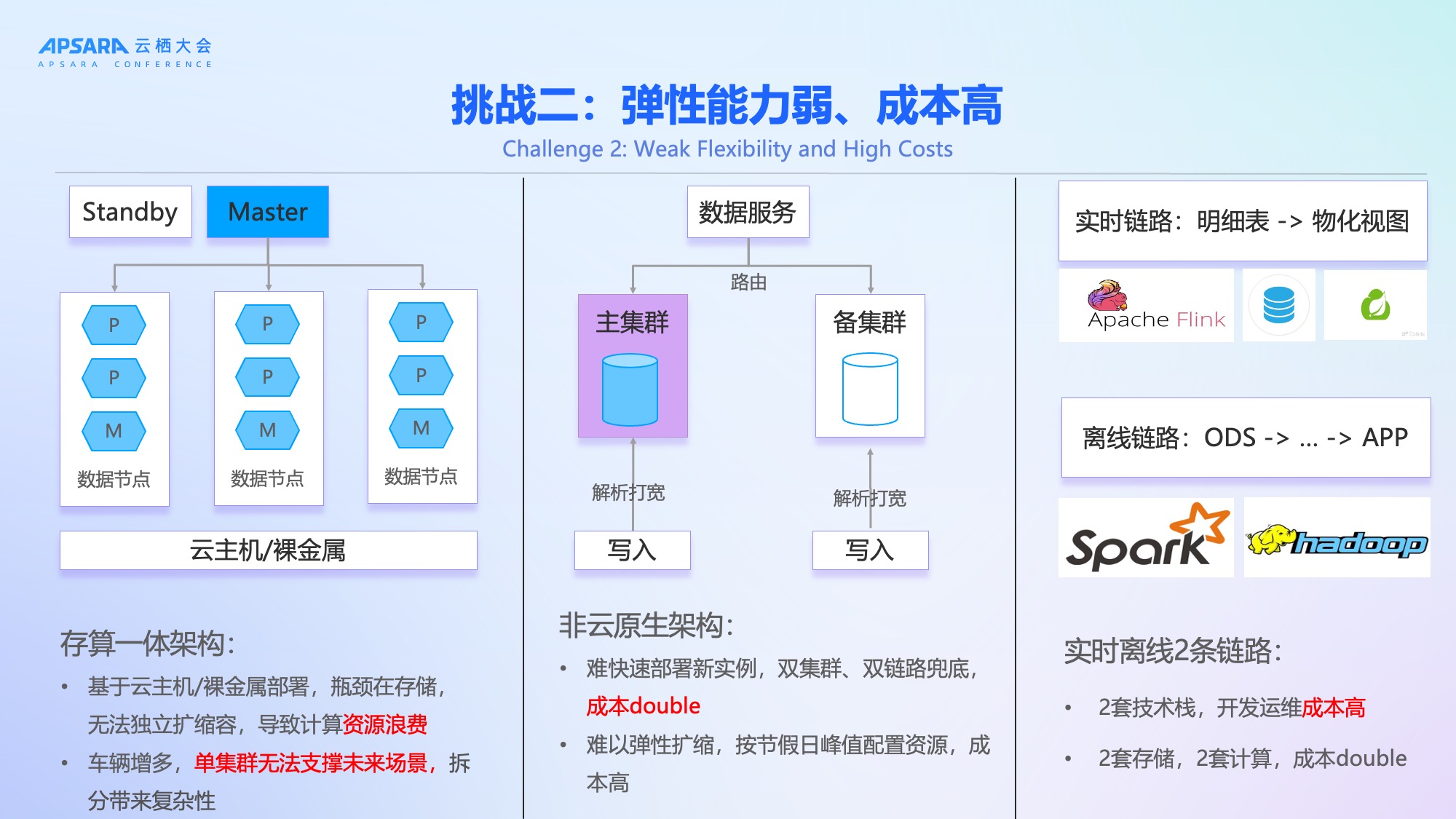
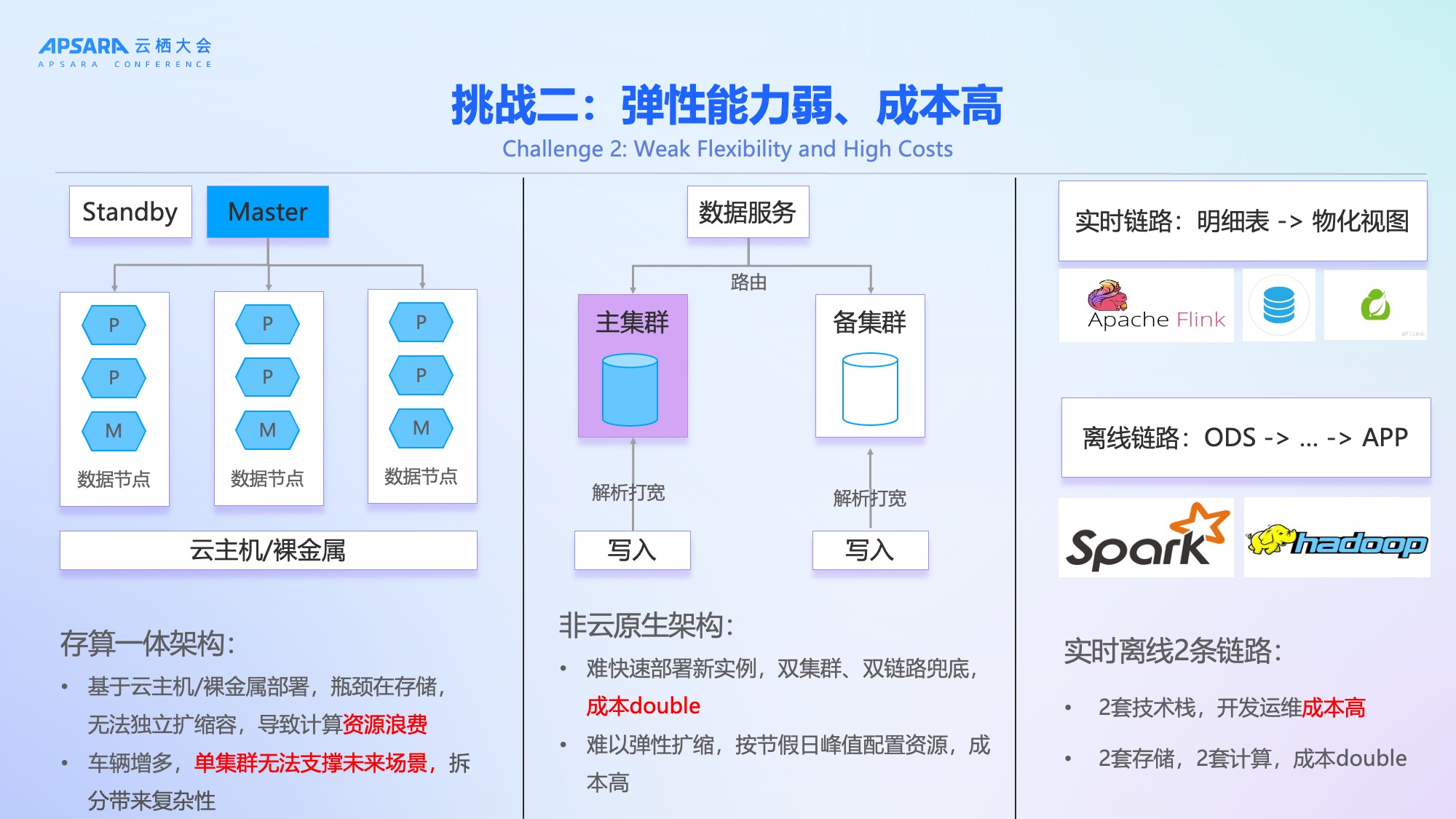
挑战二:弹性能力弱、成本高
理想汽车原有架构采用存算一体的非云原生设计,部署在云主机或裸金属服务器上,存在显著缺陷:
- 资源无法弹性扩缩:为应对节假日峰值,需长期按最高负载配置资源,造成大量闲置浪费;
- 存算耦合:存储与计算绑定,无法独立扩展,计算资源利用率低;
- 双集群双链路冗余:为保障稳定性,采用主备双集群 + 实时/离线双链路方案,导致资源成本翻倍;
- 技术栈割裂:实时链路(明细表→物化视图)与离线链路(ODS→DWD→DWS→APP)使用两套技术栈、两套存储,开发运维成本高;
- 集群拆分复杂:单集群无法支撑未来200万辆车规模,拆分带来数据路由、一致性等新问题。
该架构不仅成本高昂,且难以适应立项汽车未来几百万车辆业务的高速增长。
二、基于阿里云Hologres+Flink架构方案
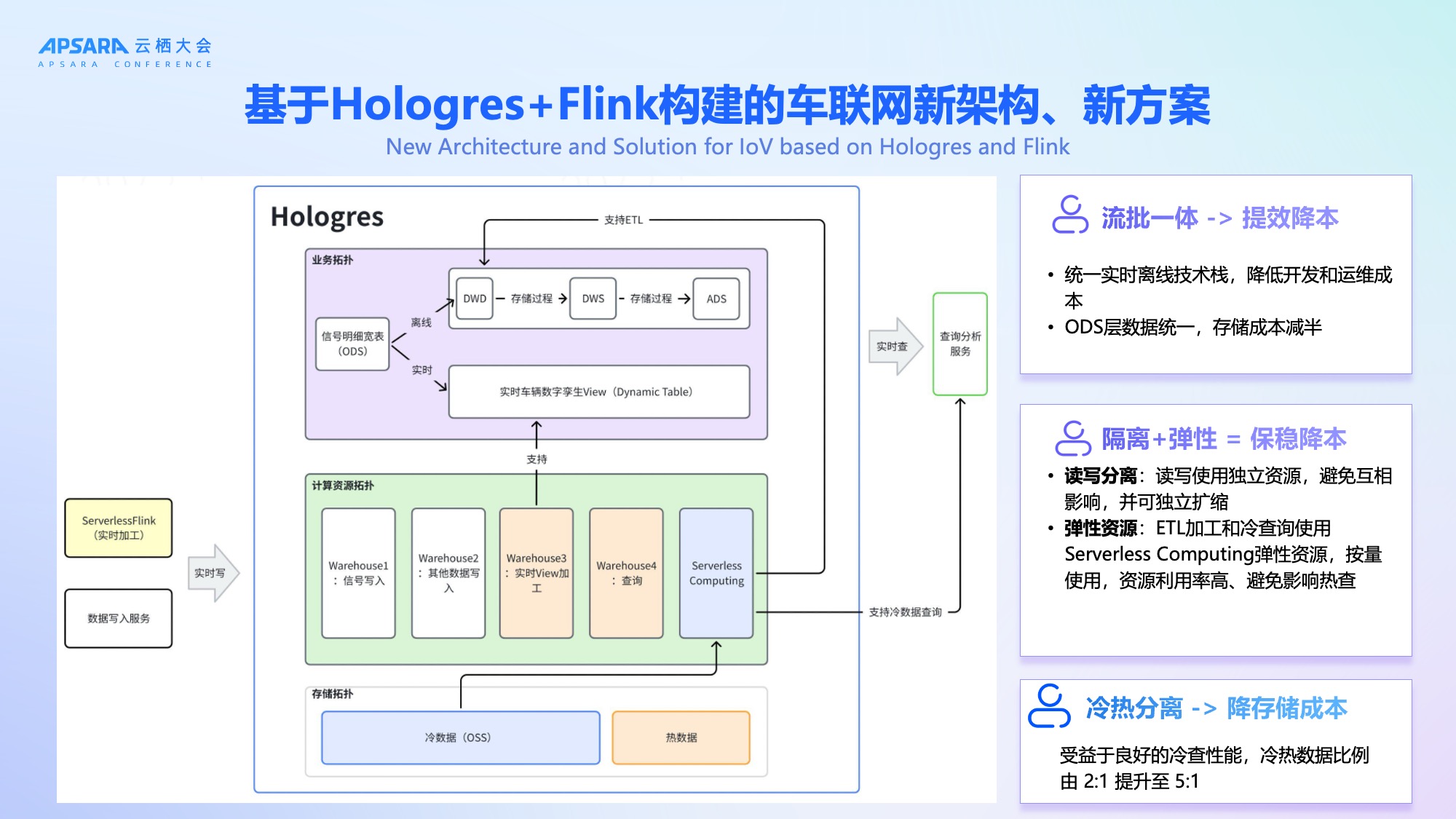
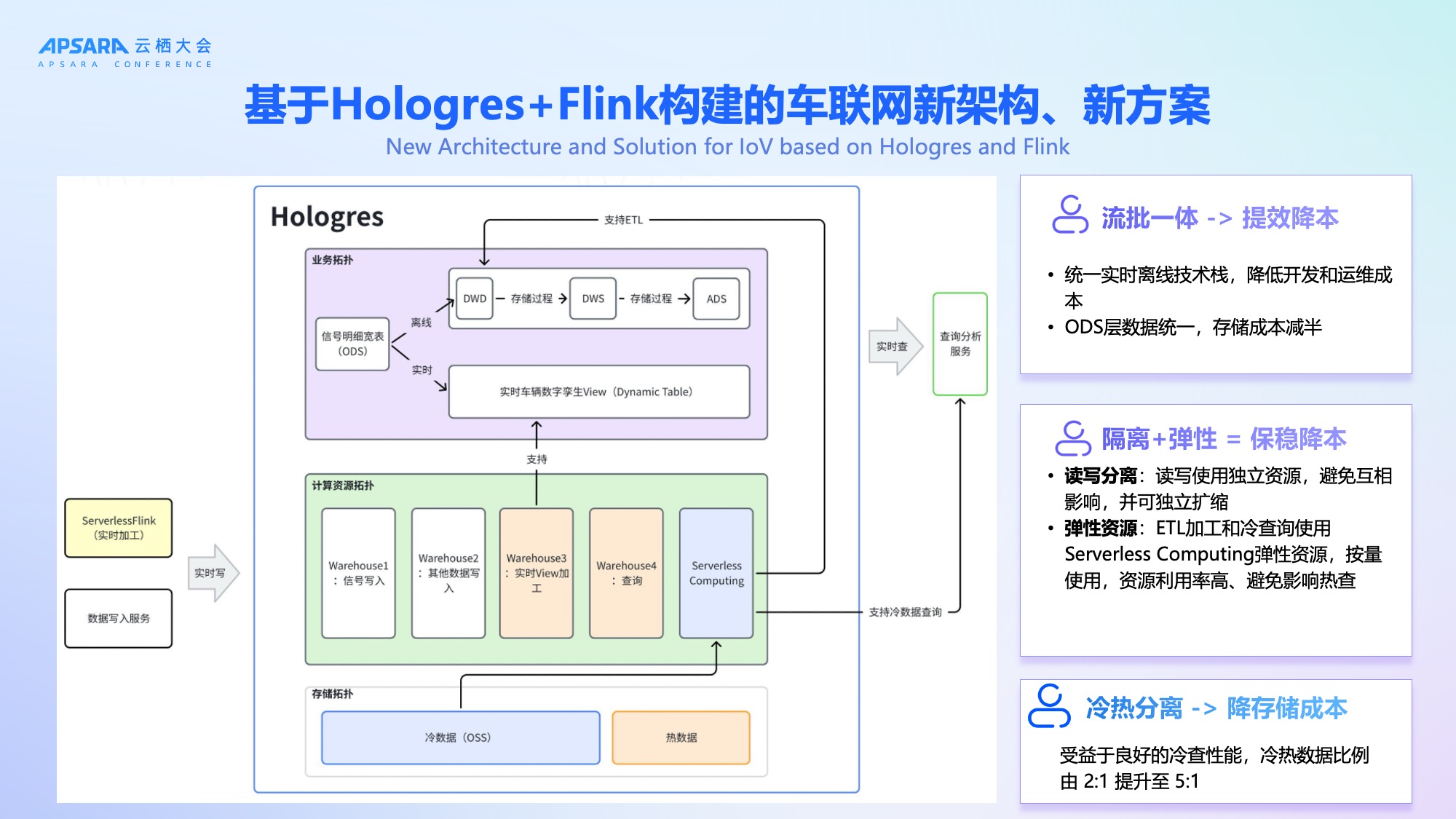
为应对上述挑战,理想汽车于2024年底启动技术架构升级,全面引入阿里云Hologres+ Flink,构建"弹性、高可用、低成本"的新一代车联网数据平台。
新架构自下而上分为四层:
- **写入层:**通过阿里云实时计算Flink版的Serverless实现高性能数据写入,Hologres具备极强的写入能力,写入即可查。
- 存储层:利用 Hologres的冷热分层能力,部分数据放在OSS,将冷热数据比例从2:1提升至5:1,显著降低存储成本;
- 计算层:通过 Hologres计算组实现读写分离 + 负载隔离,写入、加工、查询等分别属于不同计算组,互相不受影像。存在OSS的历史数据,对性能不敏感,搭配Hologres Serverless Computing 弹性资源可以直接进行冷查询或者ETL加工大宽表,成本低,又不会影响其他计算组的稳定性。整体架构可以保障高优业务(如热查询、实时预警)的稳定性;
- 业务层:统一实时与离线链路,实现流批一体,ODS层数据统一存储,存储成本减半。
关键创新在于:不再需要双集群、双链路兜底,Hologres 自身的高可用与弹性能力即可保障SLA。
性能压测验证
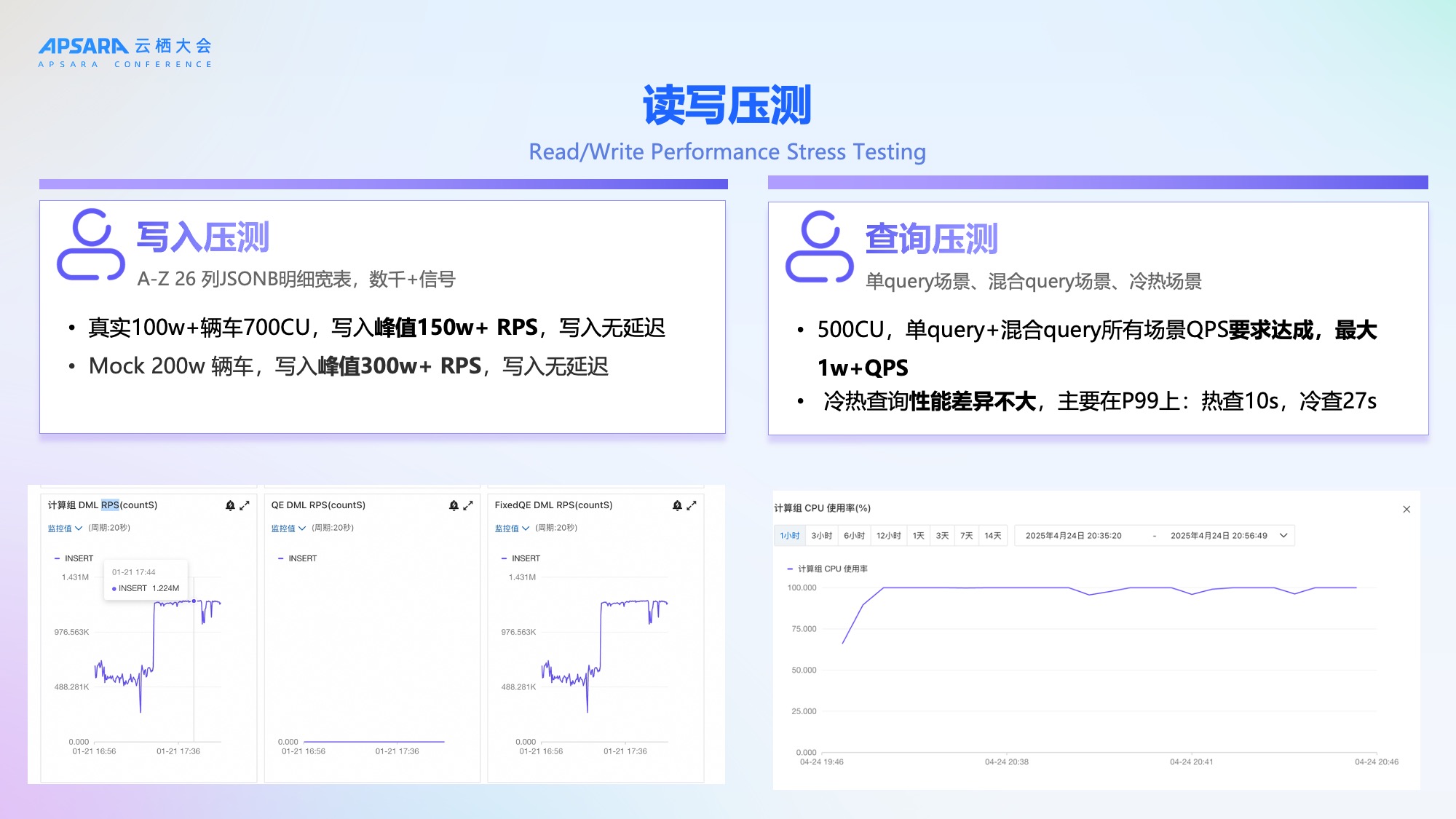
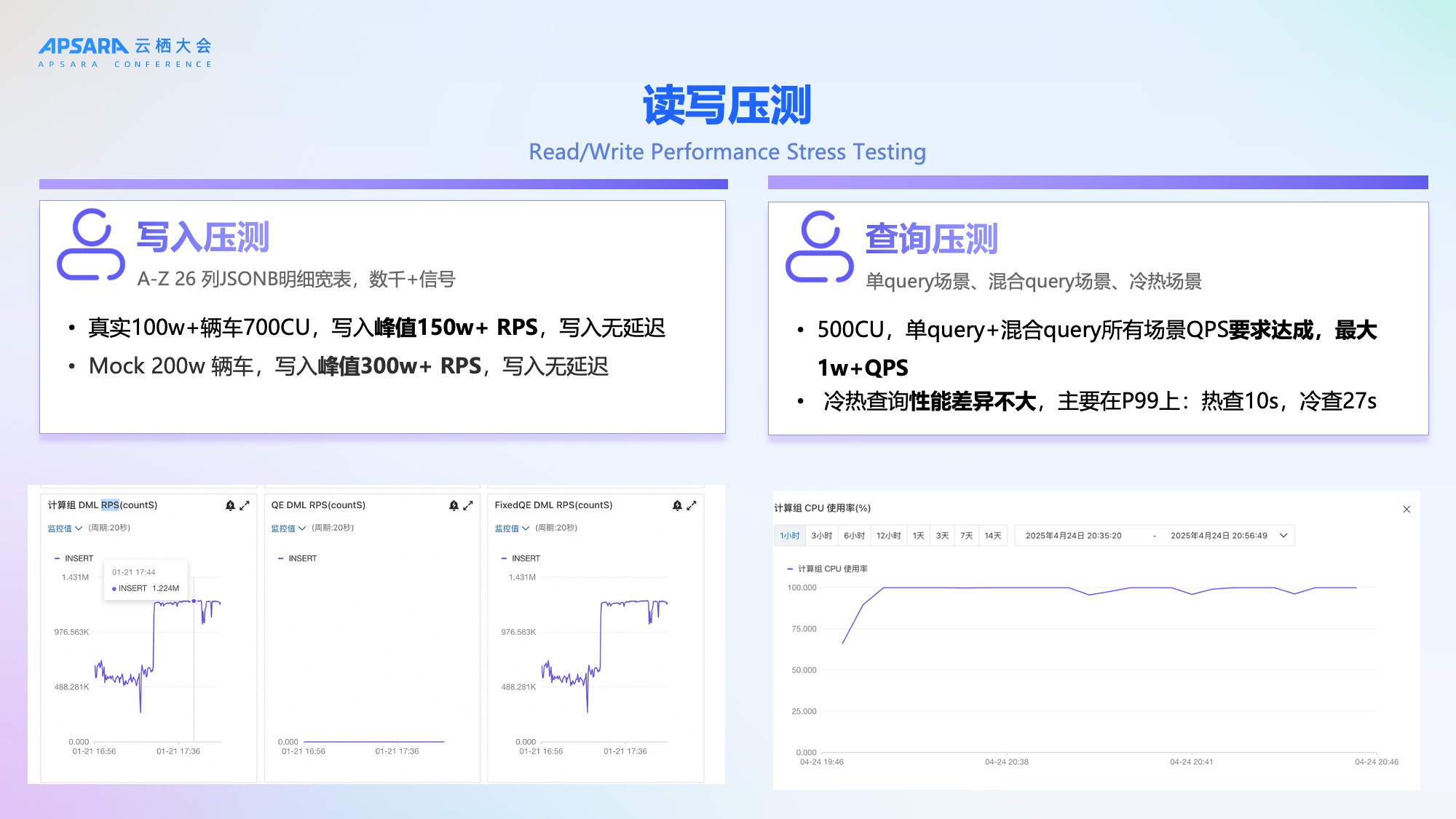
理想汽车对新架构进行了全链路压测,验证其支撑能力:
-
写入压测:
-
真实100万+辆车场景下,700CU资源支撑150万+ RPS,写入无延迟;
-
Mock 200万辆车,写入峰值达300万+ RPS,依然稳定。
-
查询压测:
-
500CU下,单Query与混合Query均满足1万+ QPS需求;
-
冷热查询性能差异可控,热查P99约10秒,冷查约27秒。
压测结果证明,新架构具备支撑未来200万辆车规模的能力,且冷热查询性能均衡,满足业务需求。
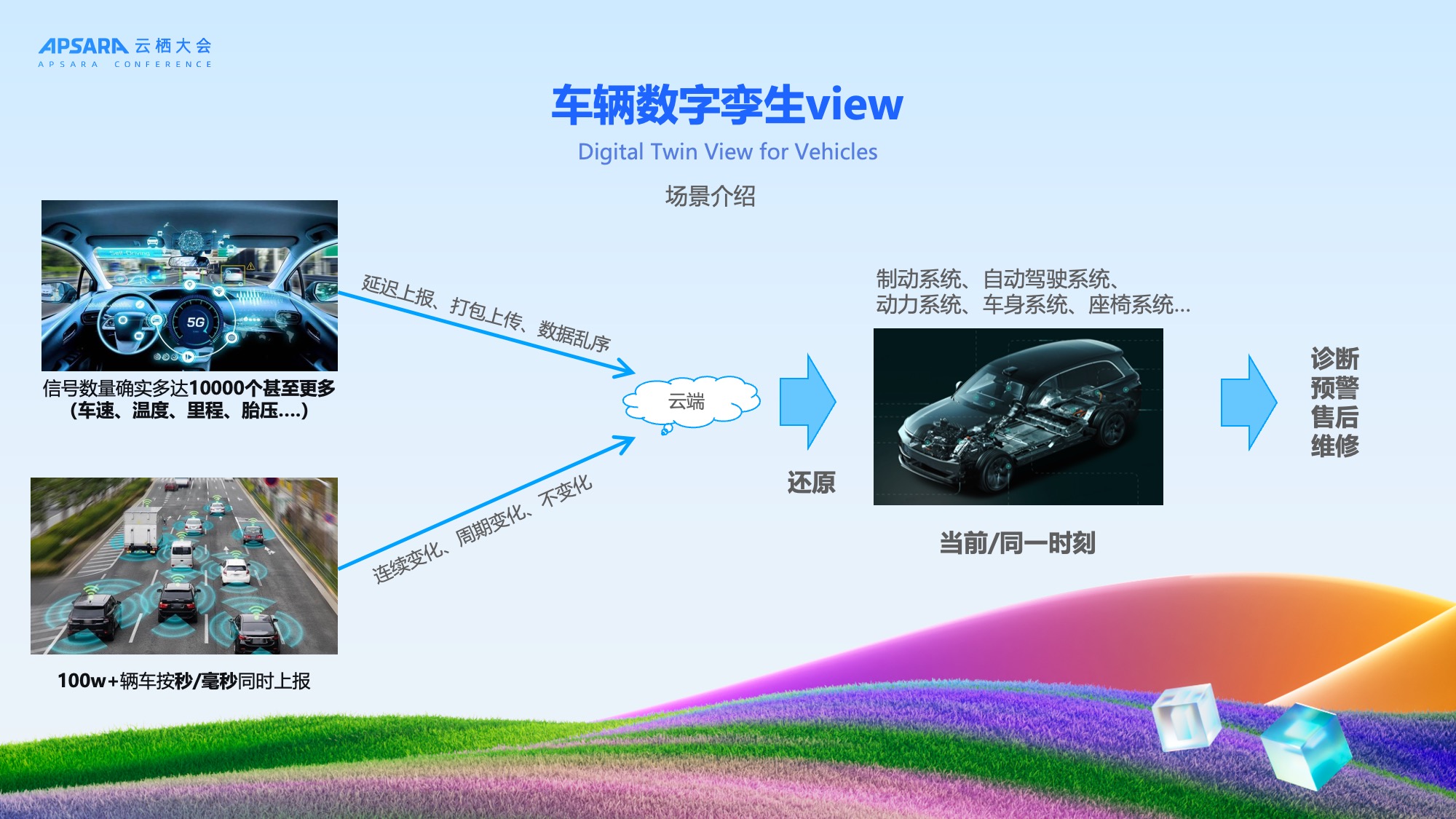
车辆数字孪生View场景测试
"车辆数字孪生View"是理想汽车的核心业务场景:在云端实时还原每一辆车在同一时刻的所有信号状态,用于故障诊断、自动驾驶监控、售后维修支持及工况回放仿真。
该场景极具挑战性:
- 信号数量多达1万个以上;
- 100万+辆车按秒/毫秒同时上报;
- 需要高并发(QPS超1万)、高实时(秒级延迟)、高一致性。
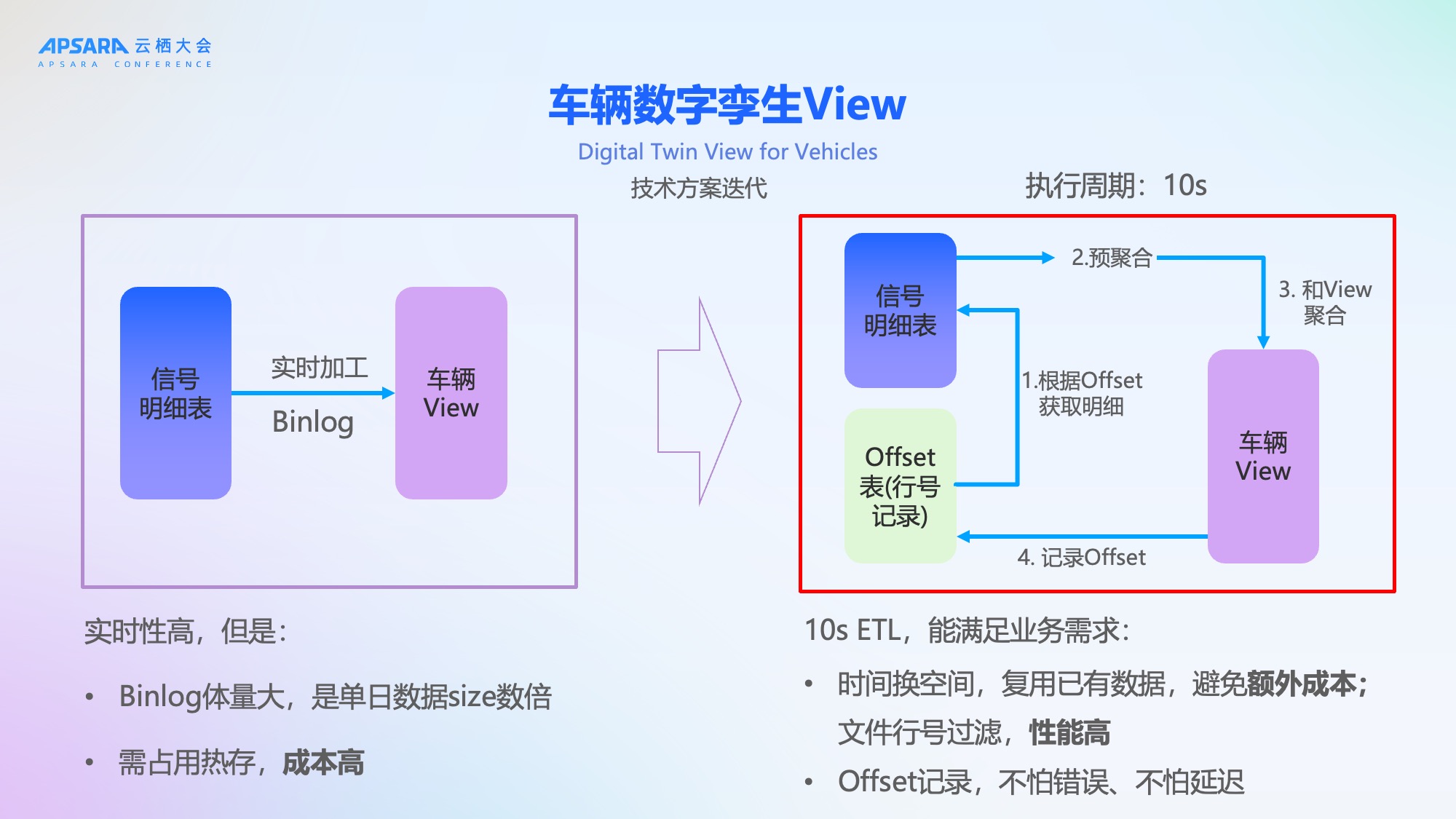
初期方案采用 Hologres Binlog 实时同步,虽能实现高实时性,但由于我们数据量较大,Binlog体量是原始数据的数倍,需长期占用热存储,成本高昂。
车辆数字孪生View场景升级
经与 Hologres 团队联合优化,从左侧的Binlog方案,升级到10秒增量ETL框架,分为四步:
- 根据Offset获取明细:拉取过去10秒的增量数据;
- 预聚合:对增量信号进行初步聚合;
- 与View聚合:将预聚合结果与现有车辆View合并;
- 记录Offset:持久化最新处理位点,支持断点续传。
该方案优势显著:
- 时间换空间:复用已有数据,避免额外存储成本;
- 高性能:基于底层文件行号过滤,性能极高;
- 强容错:Offset机制保障系统异常时可快速恢复数据。
理想汽车通过这个方案实现了成本和效率的一个完美的平衡。既能满足业务的需求,也可以复用现有的数据,避免了额外的成本。而且我们增量的数据获取采用底层文件行号过滤性能非常高,并且有offset的记录。当系统发生错误的时候,可以根据offset实时的追回我们的数据。,有非常好的容错能力。
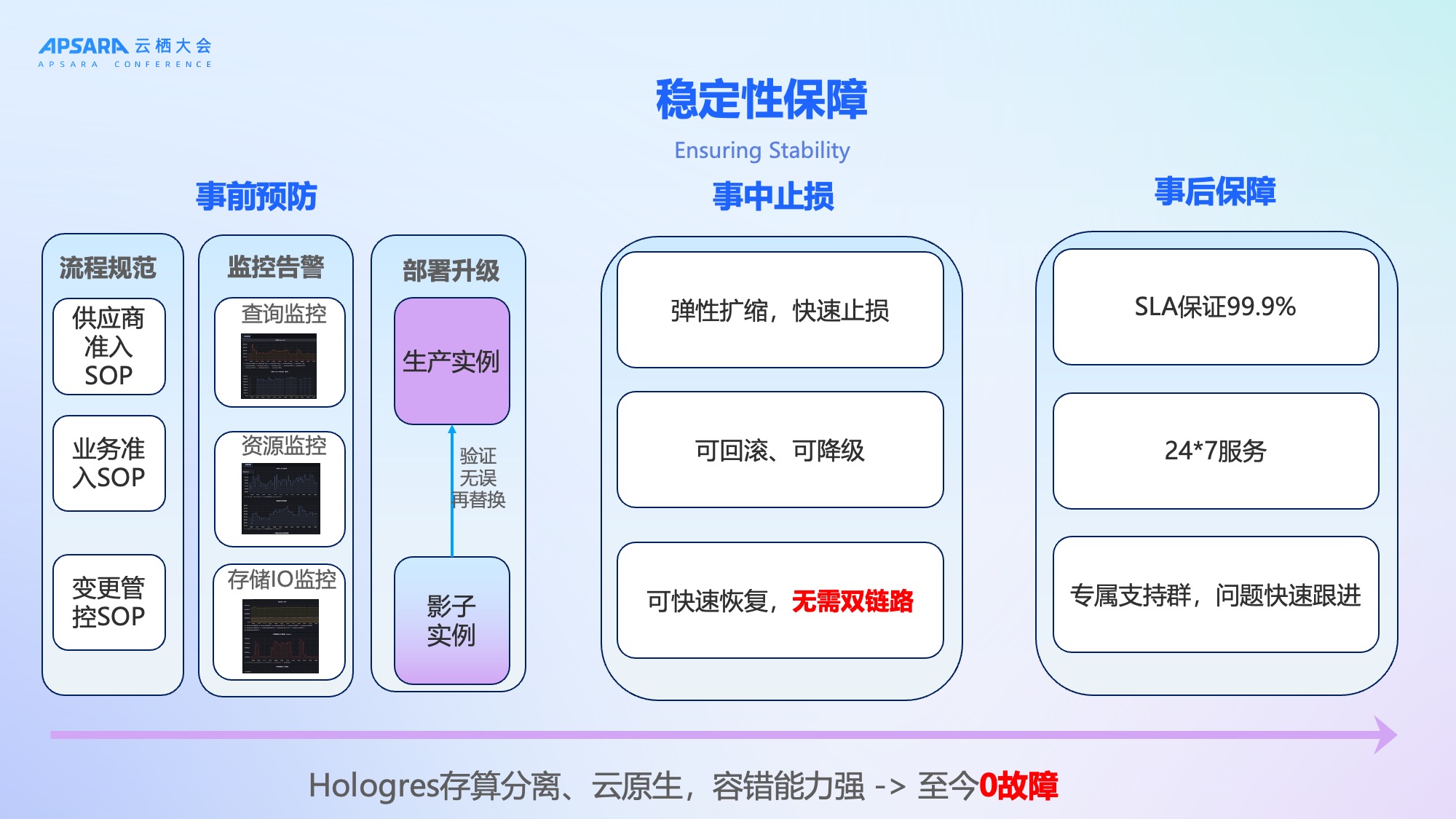
稳定性保障体系
稳定性不仅是产品的能力,更是流程机制的建立。理想汽车基于Hologres 存算分离、云原生架构,系统容错能力强,上线至今0故障,同时在内部构建了"事前预防、事中止损、事后保障"的全链路稳定性体系:
-
事前预防:
-
制定《业务准入SOP》《变更管控SOP》《供应商准入SOP》;
-
完善Hologres监控告警:查询监控、资源监控、存储IO监控全覆盖;
-
使用影子实例验证变更,无误后再上线。
-
事中止损:
-
弹性扩缩:高峰期自动扩容,低峰期缩容;
-
快速回滚:升级异常可秒级回退;
-
服务降级:非核心查询可临时降级,保障核心链路。
-
事后保障:
-
SLA承诺99.9%,7×24小时专属支持;
-
审计日志完善,支持自助分析瓶颈。
Hologres+Flink架构总结
使用了阿里云Hologres+Flink这套技术栈以后,我觉得我们既有现在又有未来。如刚才所说,现在能支持理想汽车一百多万辆车的一个场景,也可以通过扩容去支持未来200万辆车甚至更多的一个场景,不需要做多种集群的拆分。第二方面是效率高,成本低。Hologres具有极致的弹性能力,还有一些这种Serverless Computing这样的弹性资源,大幅提高我们的资源利用率,避免资源浪费。而且Hologres是一个多模态的分析场景,未来还可以扩展到OLAP分析、点查服务、全文检索、向量搜索以及AI推理等多种场景。
最后方面稳定应用。如刚才所说,理想汽车构建了非常完善的稳定性保障的机制,拥有完善的审计日志,让我们可以灵活的自助分析我们系统的瓶颈和风险。

三、理想汽车基于Hologres+Flink构建万亿级车联网信号实时分析平台
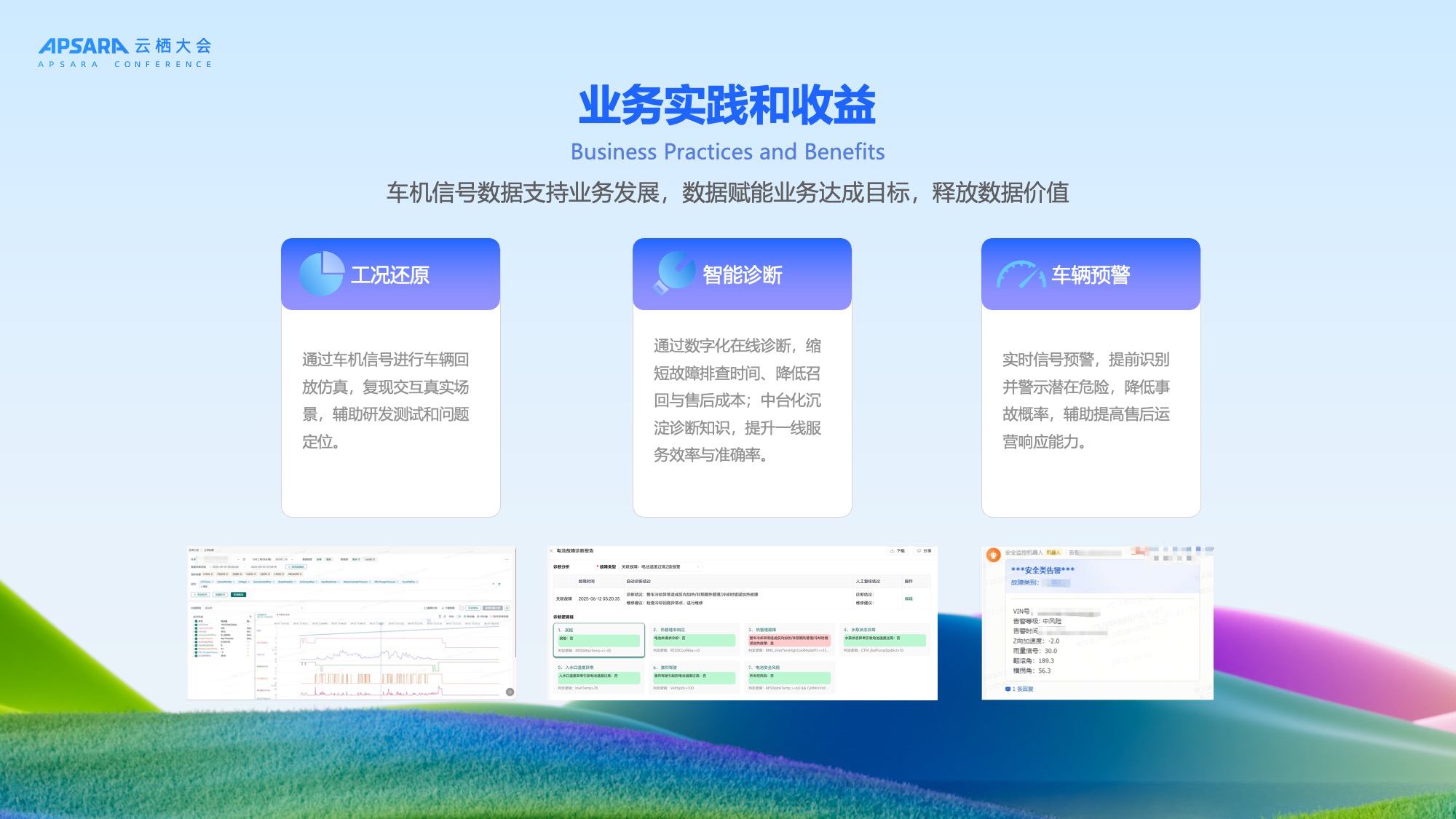
以上是架构设计的思考,后续给大家介绍理想汽车基于Hologres+Flink这套架构在业务上线应用过程中一些情况。包括我们刚才提到了的工况还原、智能诊断、车辆预警等场景。
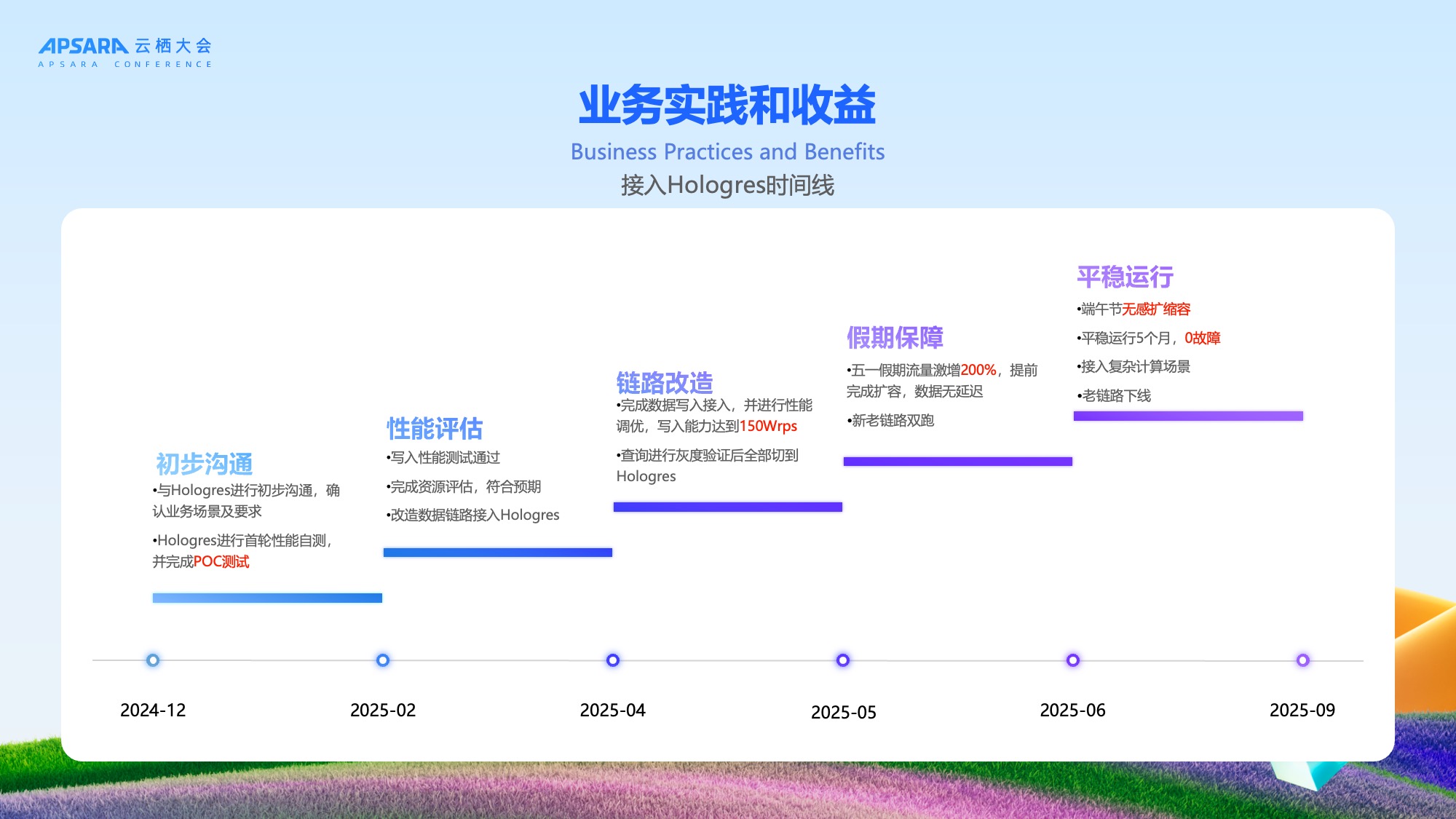
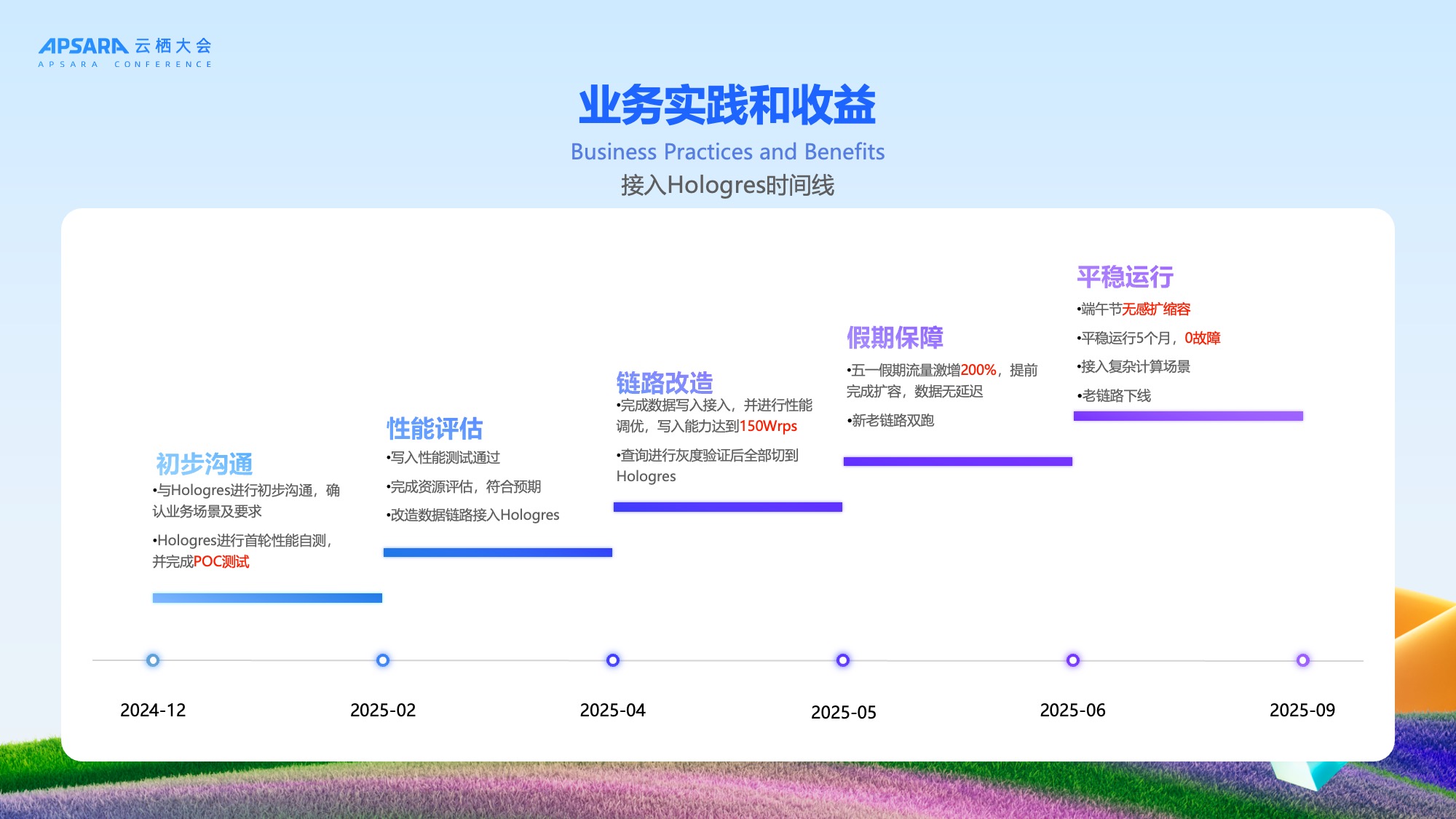
整体接入及上线时间线
理想汽车与 Hologres 的合作按以下时间线推进,我们通过大约6-9个月即完成从最初POC测试到正式上线,整个过程平稳有序,验证了新架构的可靠性。
从最开始24年的12月份跟Hologres做初步对接,Hologres团队其实很快的就完成了POC的这个测试,符合我们性能的诉求。过完年后我们开始在2-4月份去进行全面的压测跟优化,又做了灰度的查询的验证,验证了扩缩容对业务没有影响。因为这次架构的升级要求对业务无感的,5越分开始我们进行了新老链路的双跑,并在五一和端午两个高峰的假期去验证整体的能力,发现Hologres是完全满足假期高峰出行的流量保障要求。端午之后,我们就把老的这个链路给下线了,整个五月期间,也没有发生任何故障,于是我们在实时的链路上又接入了一些复杂的一些计算的场景。
整体业务实践和收益
接入 Hologres 后,理想汽车资源利用率提升,实现性能与成本的完美平衡;响应时间满足SLA:历史工况回溯等场景响应时间达标,SLA达标率99.9%。
- 写入性能提升200%:在成本持平前提下,写入能力翻倍,达150万RPS,零延迟;比方说网络抖动,或者是消费的服务有所异常的情况,导致的信号积压的场景下,我们能快速的恢复跟止损。
- QPS提升32%:热查询使用独立Hologres Warehouse,专注热数据处理,资源利用率比共享池高20%;
- 计算成本降低40%:冷查询虽然频率比较低,但是又有一定的实时要求,采用Hologres Serverless Comuting模式,按量付费,降低成本,也能保证SLA;

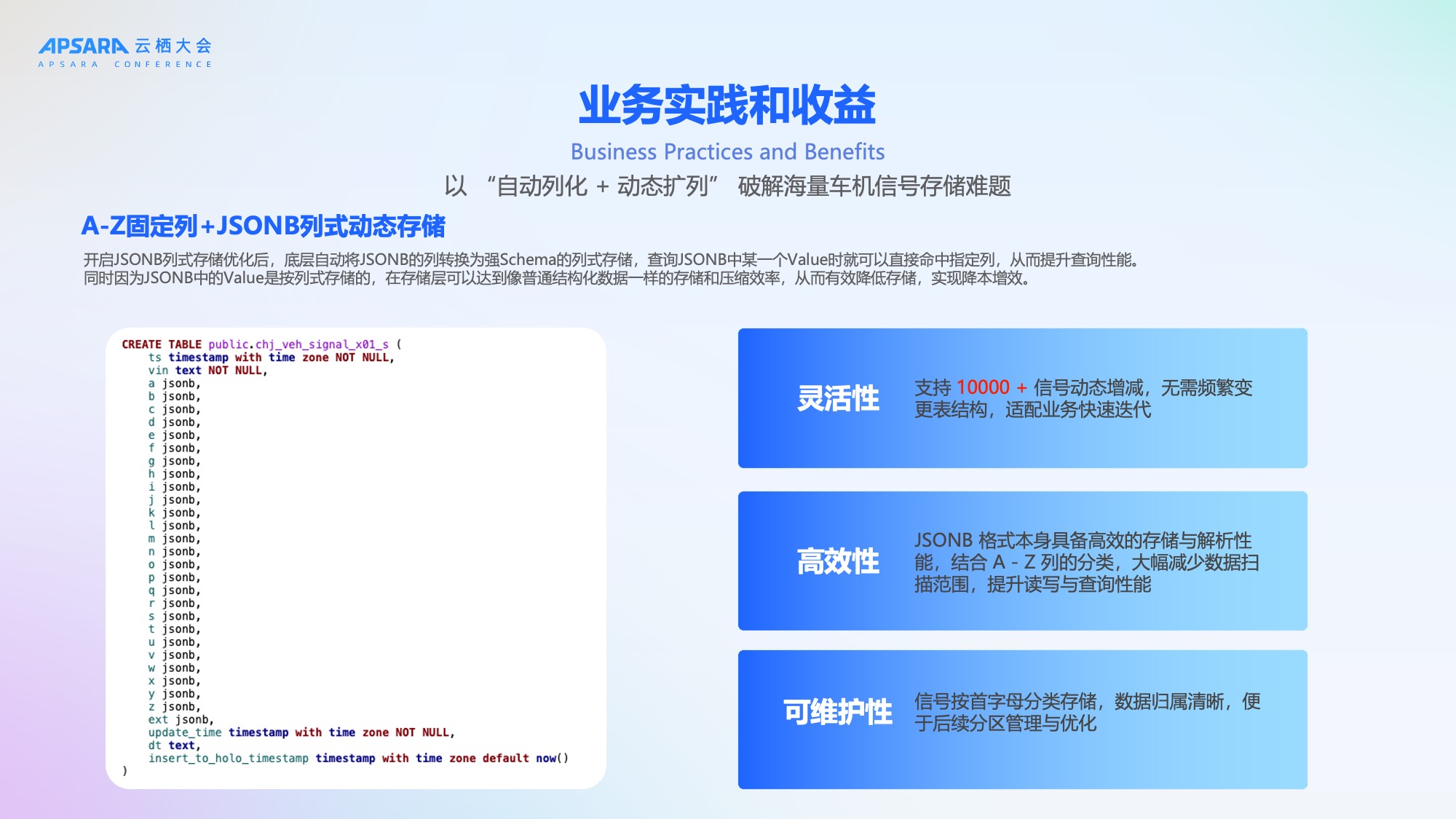
应用一:"自动列化+动态扩列"破解海量车机存储难题
面对100万辆车10000+动态信号,理想汽车设计了"A-Z固定列 + JSONB列式动态存储"方案,Hologres 开启JSONB列式存储优化后,底层自动将JSONB转换为强Schema列式存储,查询时可直接命中指定列,提升性能;同时存储压缩效率高,有效降本增效。
- 灵活性:支持信号动态增减,无需频繁变更表结构,适配业务快速迭代;
- 高效性:JSONB格式具备高效存储与解析性能,结合A-Z列分类,大幅减少数据扫描范围;
- 可维护性:信号按首字母分类存储,数据归属清晰,便于后续分区管理与优化。
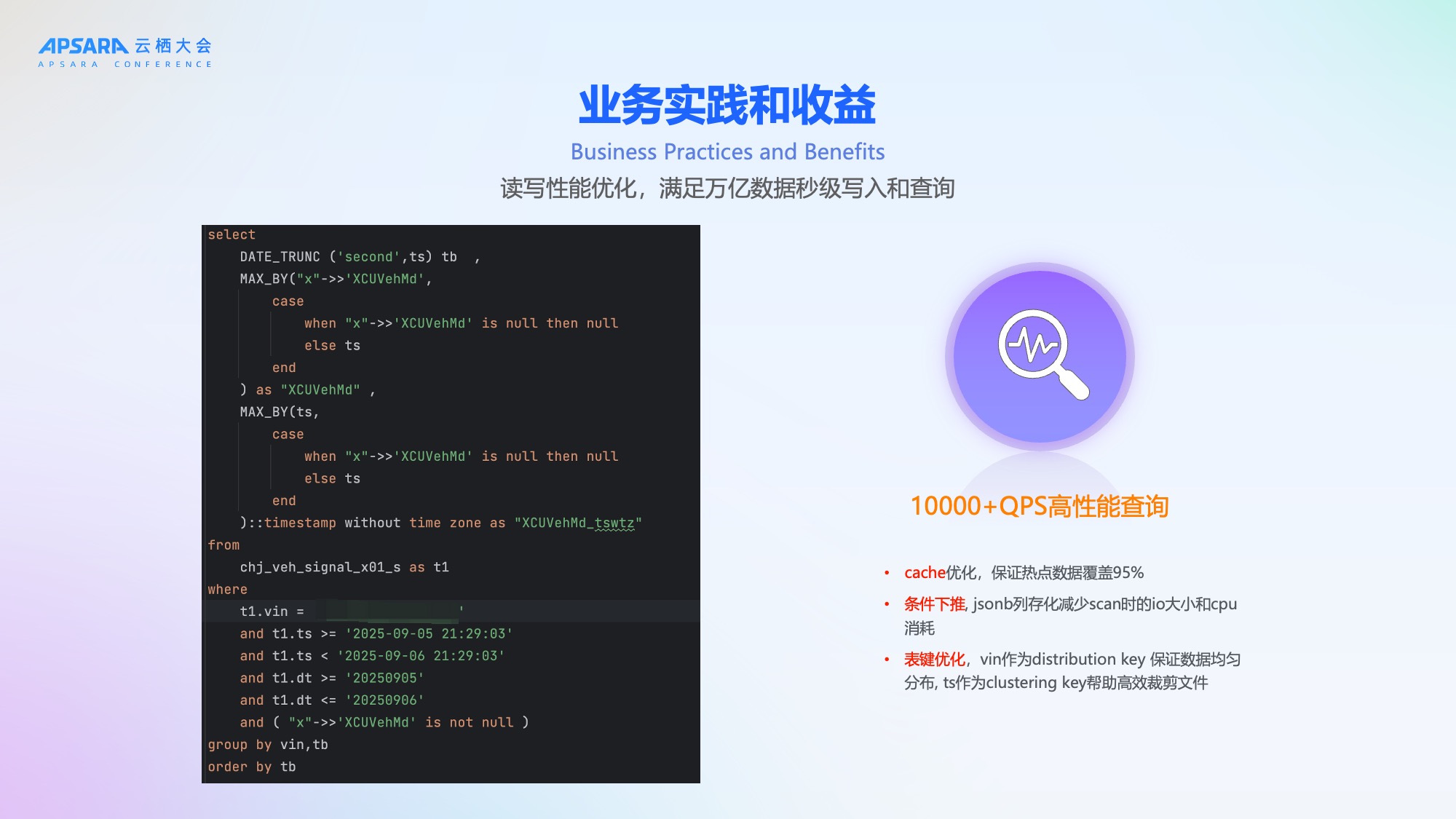
应用二:读写优化,万亿数据秒级写入和查询
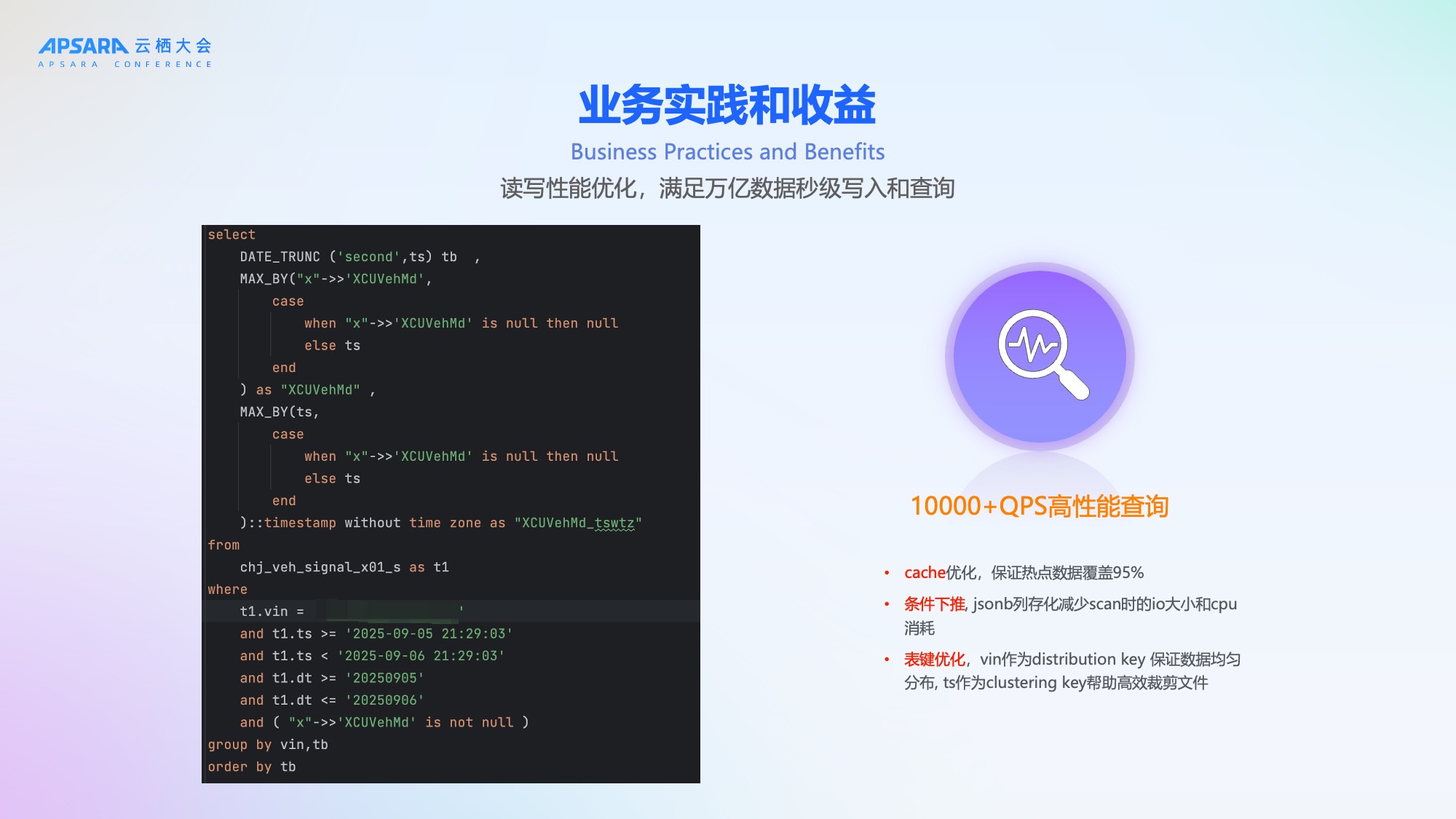
为满足万亿级数据秒级写入,理想汽车基于Hologres采用多项优化:
- Copy模式写入:使用二进制协议,高效写入,写入即可查;
- 连接池 + Table Schema缓存:防止每次Copy创建新连接,减少服务端CPU消耗;
- 攒批Flush:减少close频率,进一步提高性能;Flush与Checkpoint同步,保证消息不丢失;
- 零延迟快照:基于增量视图Union明细表,实现信号最新快照的零延迟查询。
这些优化确保了高吞吐、低延迟、高可靠的数据写入能力。

在查询层面,我们是做到了1万+QPS的秒级返回。主要是基于Hologres的cache优化能力,保证热点数据能覆盖到95%以上。基于条件下推减少了scan的扫描,jsonb列存化减少scan时的io大小和cpu消耗。然后针对这一些大量的点查,vin作为distribution key 保证数据均匀分布, ts作为clustering key帮助高效裁剪文件。
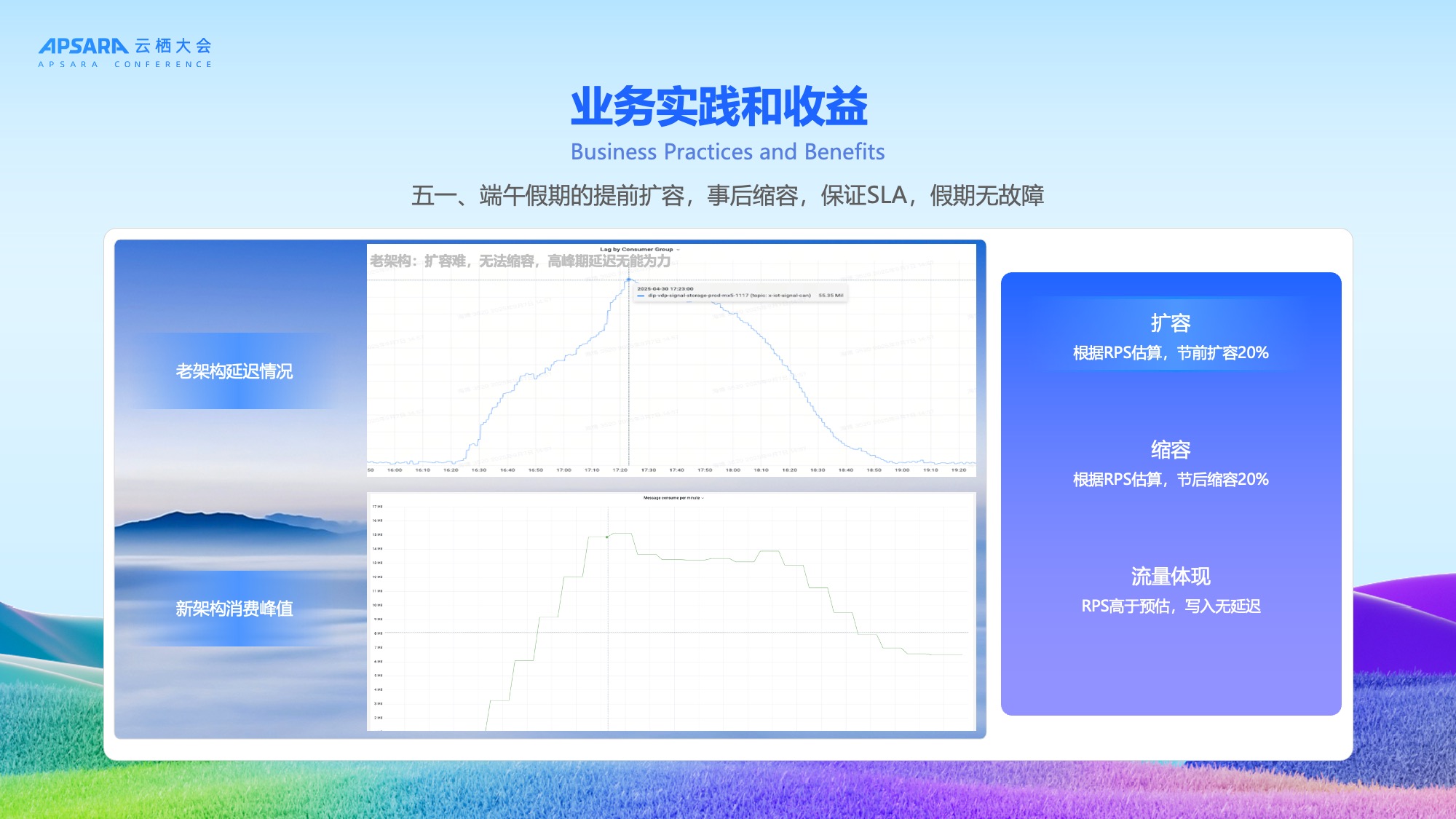
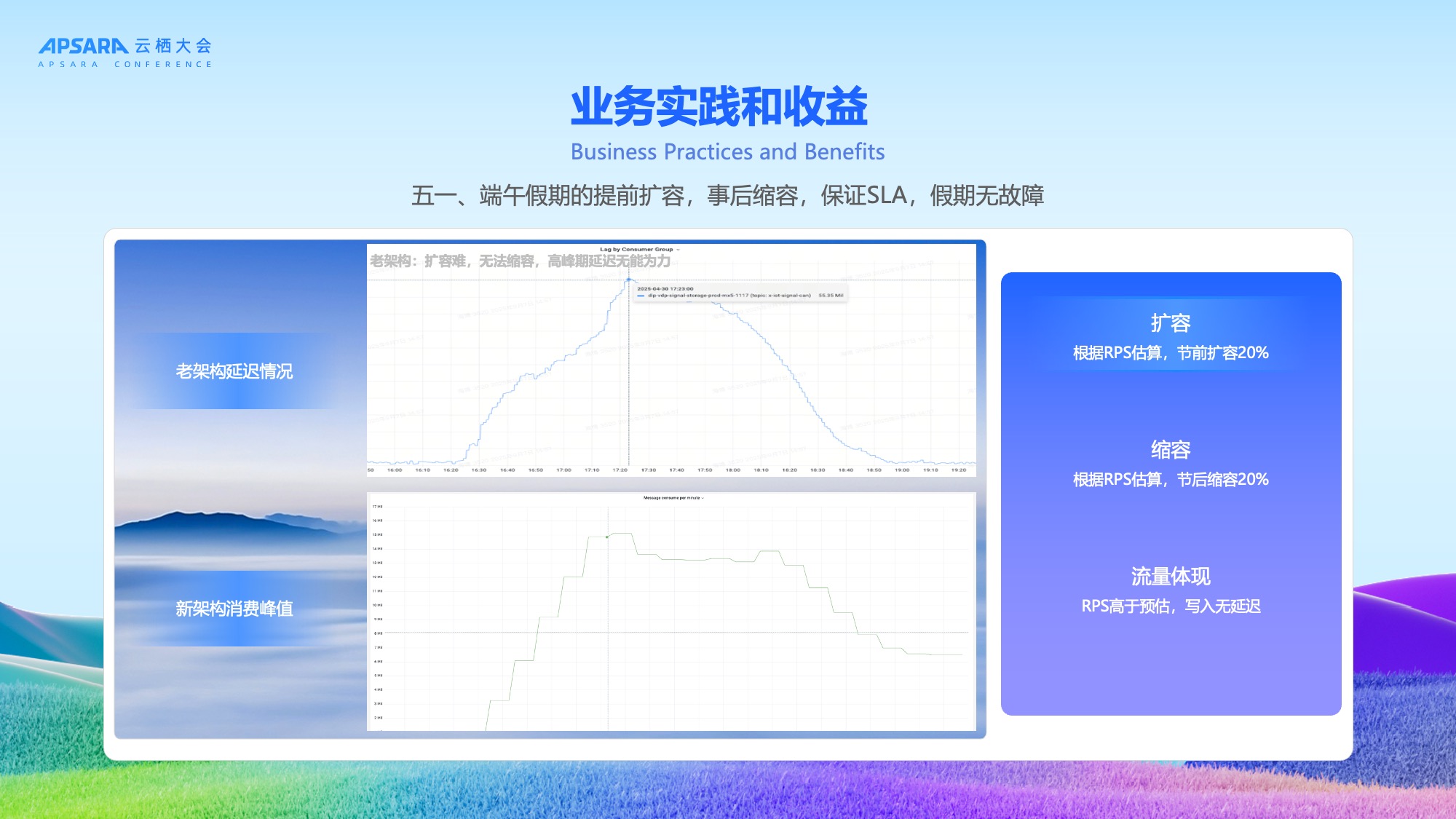
应用三:高峰期稳定性保障
在五一和端午假期期间,理想汽车通过节前扩容20%、节后缩容20%,成功应对流量高峰,保证SLA,假期无故障,写入无延迟,实现10000+ QPS的高性能响应。
应用四:离线场景降本提效
理想汽车还有一些离线场景,我们也将他迁移到Hologres上,有几个典型的场景:
- **数据探查:**数据分析师或者是数据产品在提数据需求时,他可能对数据本身的质量和数据的分布情况其实没有一个感知。需要数仓的同学先做探查,再反复地去沟通,这个时间其实比较耗时,可能会占用我们一半的研发的时间。我们希望把这个数据探查做成一个自助化的,通过Hologres用户可以去自己探查数据后再来提数据的诉求。
- **数据加工:**针对一些简单的数据加工ETL,例如一些信号循环的加工,让业务分析师能够自主的去使用。
- **交叉分析:**加工完循环数据表,包括一些简单的信号的加工之后,业务可以做一些交叉分析。
这些场景以前都比较慢,我们通过Hologres的JsonB全量表+Dynamic Table增量加工+Serverless Computing弹性计算资源,实现了在降低成本的同时,提升了加工效率,并满足了业务对性能的要求。
整体资源的利用率比原先离线的能提高60%,成本是离线场景能下降到35%,下降了35%,整体的这个交付的时间基本上从原来的3到5天能减少到4个小时之内,覆盖了90%离线信号分析场景。

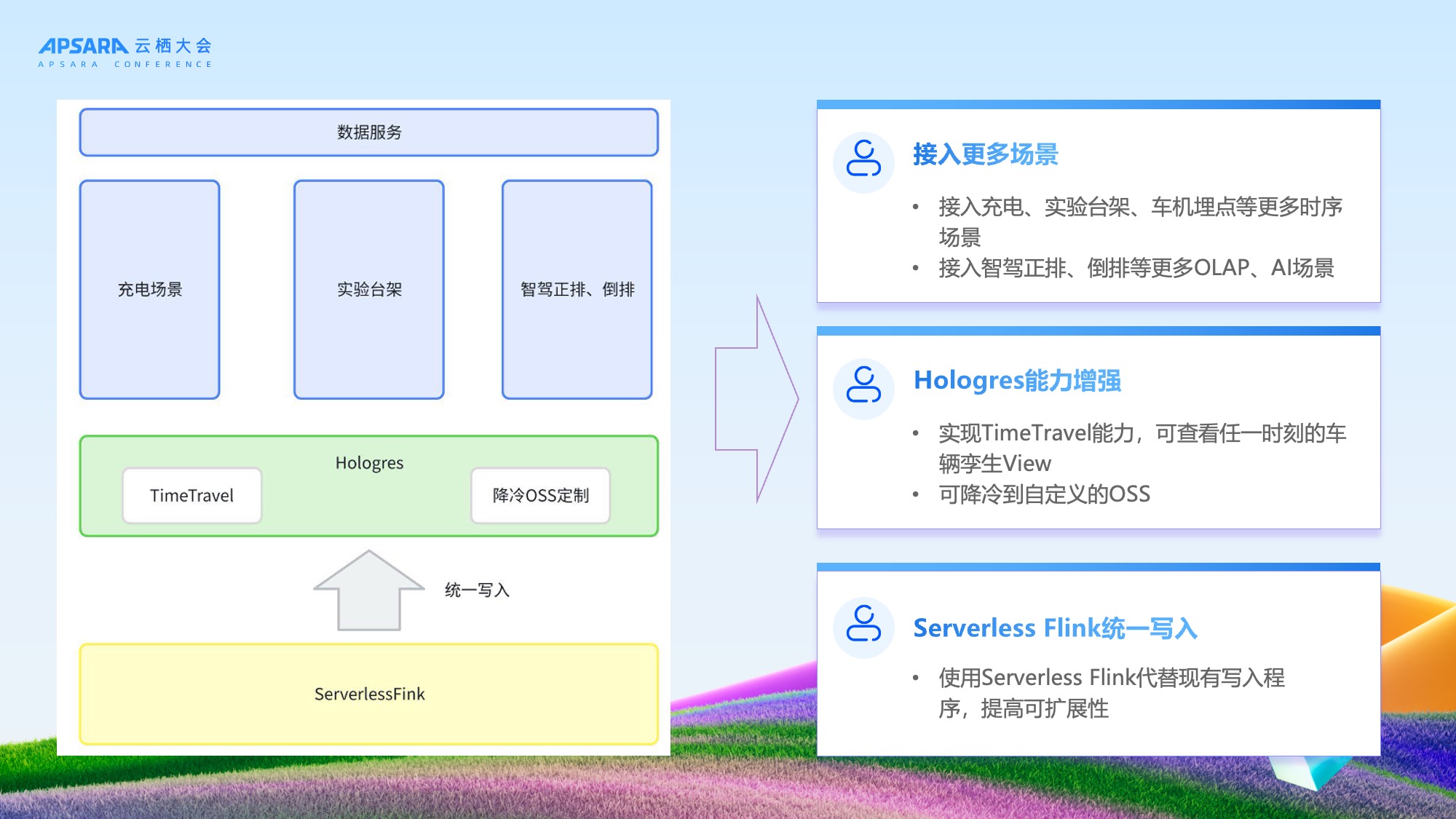
四、未来展望
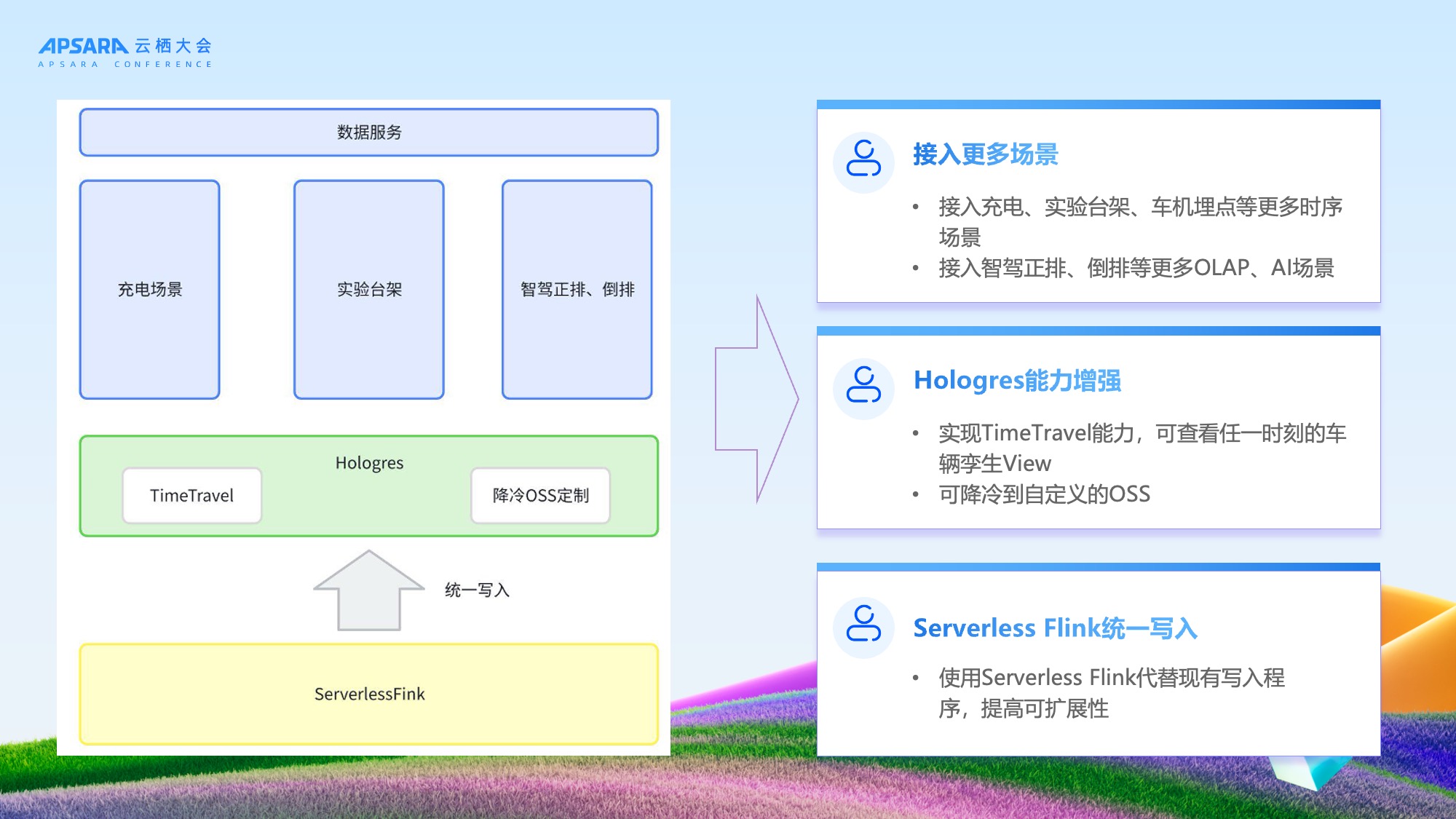
理想汽车与 Hologres 团队将持续深化合作,探索更多创新方向:
- Serverless Flink统一写入:进一步简化架构,提升写入弹性与性能;
- Hologres能力增强:基于新发布能力,探索Time Travel等特性,实现更细粒度的数字孪生与冷存管理;
- 接入更多场景:扩展至充电场站信号、台架测试数据等新信号源,支持自动驾驶、AI训练等复杂OLAP与AI场景。
通过 Hologres + Flink 的深度整合,理想汽车成功构建了稳定、弹性、高效、低成本的万亿级车联网实时分析平台。该平台不仅解决了当前业务痛点,更具备面向未来的扩展能力------可平滑支撑200万辆车甚至更大的业务规模,无需架构重构。理想汽车将与阿里云合作不断深耕大数据+AI场景,为用户提供卓越、稳定、安全的汽车智能驾驶体验。
作者:海博 理想汽车高级大数据工程师、贾天福 理想汽车高级大数据工程师
引言:智能汽车时代的数据挑战
随着电动车和智能汽车的快速普及,车联网信号数据呈现爆发式增长。理想汽车作为国内领先的智能电动汽车企业,已拥有超过100万辆在网车辆,每辆车每秒上报多达上万个信号(如车速、胎压、温度、电池状态等),整体数据规模达到万亿级别。这些数据不仅体量巨大,而且对实时性要求极高------端到端延迟需控制在2秒以内,至少不超过5秒,以支撑数字孪生、智能诊断、车辆预警等关键业务场景。
理想汽车大数据团队面临的核心挑战是如何在保障高实时性的同时,实现系统的高稳定性、高弹性与低成本。为此,团队决定重构数据底座,引入阿里云 Hologres + Flink 技术栈,打造新一代车联网实时分析平台。本文将系统介绍这一实践过程。

一、海量车联网信号的挑战
理想汽车当前拥有100万辆以上存量汽车,每辆车约有1万个信号进行实时的秒级甚至毫秒级上报。这些信号涵盖制动系统、自动驾驶系统、动力系统、车身系统、座椅系统等多个维度,数据灌入实时数据库后,存量数据达万亿行、PB级别,日增数据达数百亿行。
业务对数据链路的实时性要求极高,端到端延迟需控制在2秒以内,至少不超过5秒。为满足这一需求,理想汽车曾构建了一套离线与实时双链路的整体保障方案。然而,随着数据爆炸式增长,进入2025年后,旧有技术栈问题频发,暴露出两大核心挑战:稳定性不足、弹性能力弱/成本高。
挑战一:稳定性不足
数据的持续增长不断触发系统瓶颈,导致故障频发。具体表现为:
- 写入延迟:节假日等流量高峰期间,写入RPS超过150万,系统出现明显延迟,无法满足业务时效性要求;
- 冷查询打满资源:大量30天以上的冷数据查询QPS峰值超1万,占用大量计算资源,影响热数据服务;
- 容错能力弱:系统故障时高度依赖人工处理,恢复效率低,最慢需12小时才能完全恢复;
- 流程不完善:业务接入缺乏准入评估,上线前测试不充分,导致资源错配与线上Bug频出;
- 缺乏兜底机制:升级需停服、难回滚,故障时无法快速止损。
这些问题叠加,使得系统SLA难以保障,严重影响用户体验与业务发展。

挑战二:弹性能力弱、成本高
理想汽车原有架构采用存算一体的非云原生设计,部署在云主机或裸金属服务器上,存在显著缺陷:
- 资源无法弹性扩缩:为应对节假日峰值,需长期按最高负载配置资源,造成大量闲置浪费;
- 存算耦合:存储与计算绑定,无法独立扩展,计算资源利用率低;
- 双集群双链路冗余:为保障稳定性,采用主备双集群 + 实时/离线双链路方案,导致资源成本翻倍;
- 技术栈割裂:实时链路(明细表→物化视图)与离线链路(ODS→DWD→DWS→APP)使用两套技术栈、两套存储,开发运维成本高;
- 集群拆分复杂:单集群无法支撑未来200万辆车规模,拆分带来数据路由、一致性等新问题。
该架构不仅成本高昂,且难以适应立项汽车未来几百万车辆业务的高速增长。
二、基于阿里云Hologres+Flink架构方案
为应对上述挑战,理想汽车于2024年底启动技术架构升级,全面引入阿里云Hologres+ Flink,构建"弹性、高可用、低成本"的新一代车联网数据平台。
新架构自下而上分为四层:
- **写入层:**通过阿里云实时计算Flink版的Serverless实现高性能数据写入,Hologres具备极强的写入能力,写入即可查。
- 存储层:利用 Hologres的冷热分层能力,部分数据放在OSS,将冷热数据比例从2:1提升至5:1,显著降低存储成本;
- 计算层:通过 Hologres计算组实现读写分离 + 负载隔离,写入、加工、查询等分别属于不同计算组,互相不受影像。存在OSS的历史数据,对性能不敏感,搭配Hologres Serverless Computing 弹性资源可以直接进行冷查询或者ETL加工大宽表,成本低,又不会影响其他计算组的稳定性。整体架构可以保障高优业务(如热查询、实时预警)的稳定性;
- 业务层:统一实时与离线链路,实现流批一体,ODS层数据统一存储,存储成本减半。
关键创新在于:不再需要双集群、双链路兜底,Hologres 自身的高可用与弹性能力即可保障SLA。
性能压测验证
理想汽车对新架构进行了全链路压测,验证其支撑能力:
-
写入压测:
-
真实100万+辆车场景下,700CU资源支撑150万+ RPS,写入无延迟;
-
Mock 200万辆车,写入峰值达300万+ RPS,依然稳定。
-
查询压测:
-
500CU下,单Query与混合Query均满足1万+ QPS需求;
-
冷热查询性能差异可控,热查P99约10秒,冷查约27秒。
压测结果证明,新架构具备支撑未来200万辆车规模的能力,且冷热查询性能均衡,满足业务需求。
车辆数字孪生View场景测试
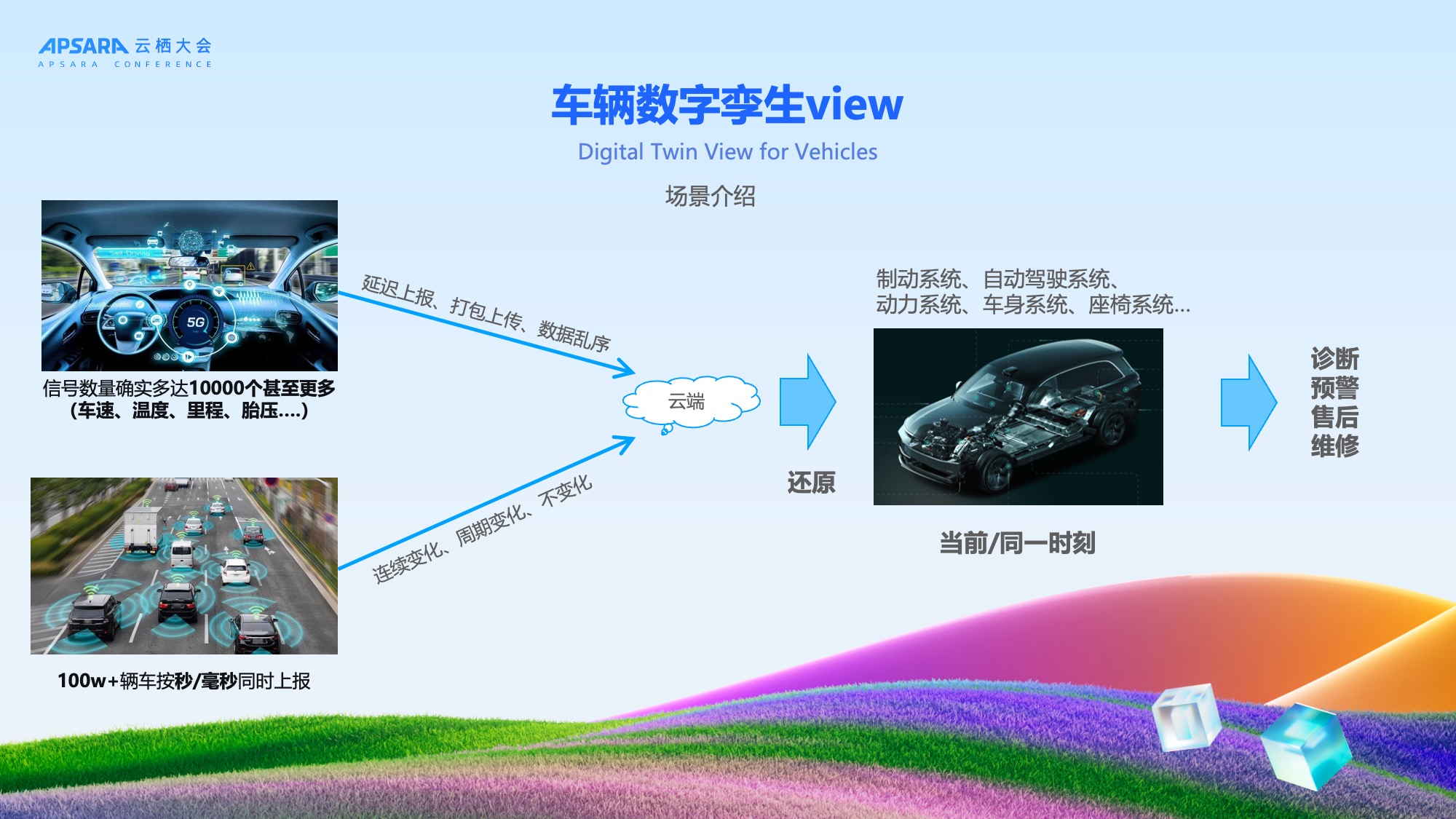
"车辆数字孪生View"是理想汽车的核心业务场景:在云端实时还原每一辆车在同一时刻的所有信号状态,用于故障诊断、自动驾驶监控、售后维修支持及工况回放仿真。
该场景极具挑战性:
- 信号数量多达1万个以上;
- 100万+辆车按秒/毫秒同时上报;
- 需要高并发(QPS超1万)、高实时(秒级延迟)、高一致性。
初期方案采用 Hologres Binlog 实时同步,虽能实现高实时性,但由于我们数据量较大,Binlog体量是原始数据的数倍,需长期占用热存储,成本高昂。
车辆数字孪生View场景升级
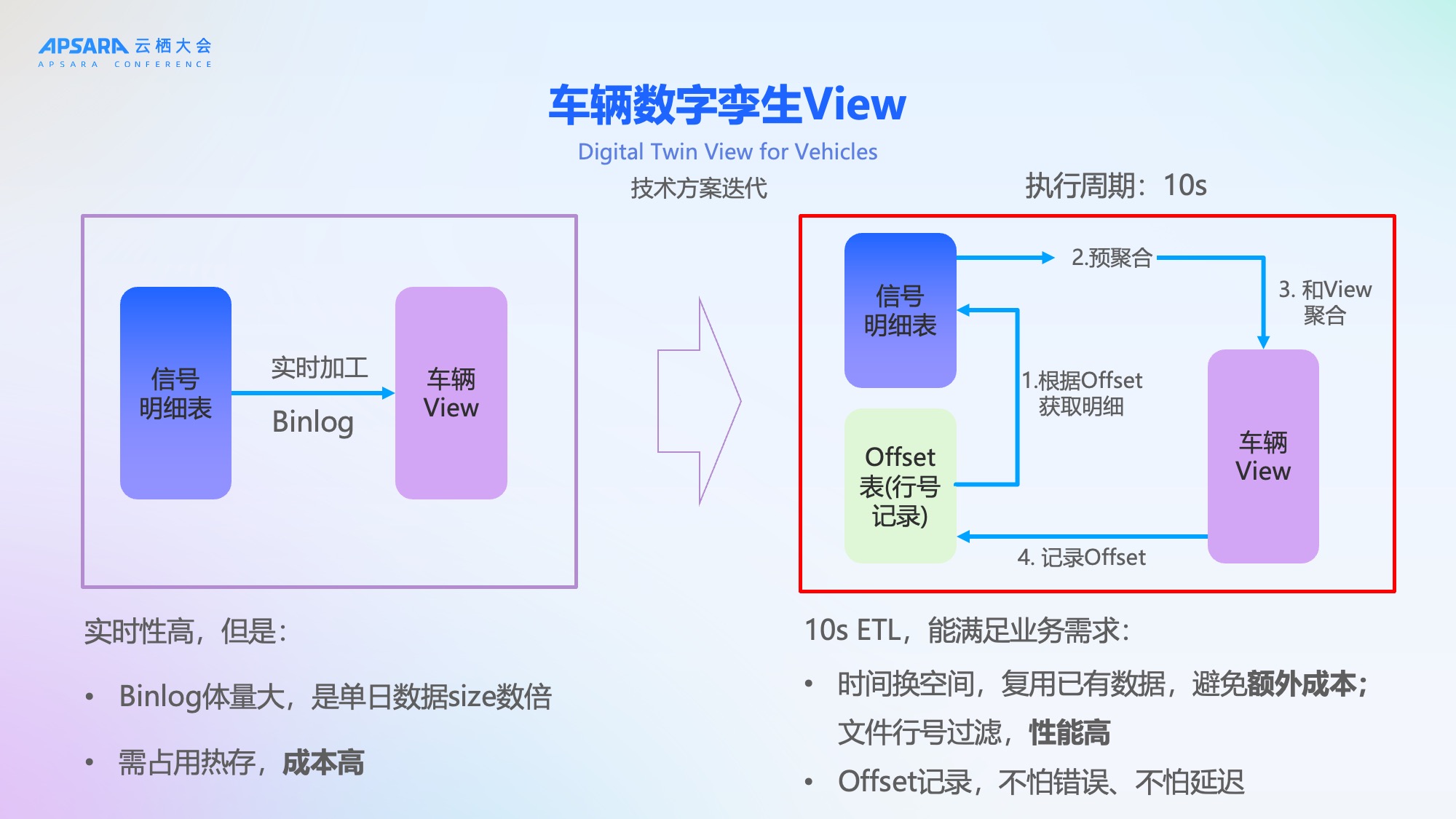
经与 Hologres 团队联合优化,从左侧的Binlog方案,升级到10秒增量ETL框架,分为四步:
- 根据Offset获取明细:拉取过去10秒的增量数据;
- 预聚合:对增量信号进行初步聚合;
- 与View聚合:将预聚合结果与现有车辆View合并;
- 记录Offset:持久化最新处理位点,支持断点续传。
该方案优势显著:
- 时间换空间:复用已有数据,避免额外存储成本;
- 高性能:基于底层文件行号过滤,性能极高;
- 强容错:Offset机制保障系统异常时可快速恢复数据。
理想汽车通过这个方案实现了成本和效率的一个完美的平衡。既能满足业务的需求,也可以复用现有的数据,避免了额外的成本。而且我们增量的数据获取采用底层文件行号过滤性能非常高,并且有offset的记录。当系统发生错误的时候,可以根据offset实时的追回我们的数据。,有非常好的容错能力。
稳定性保障体系
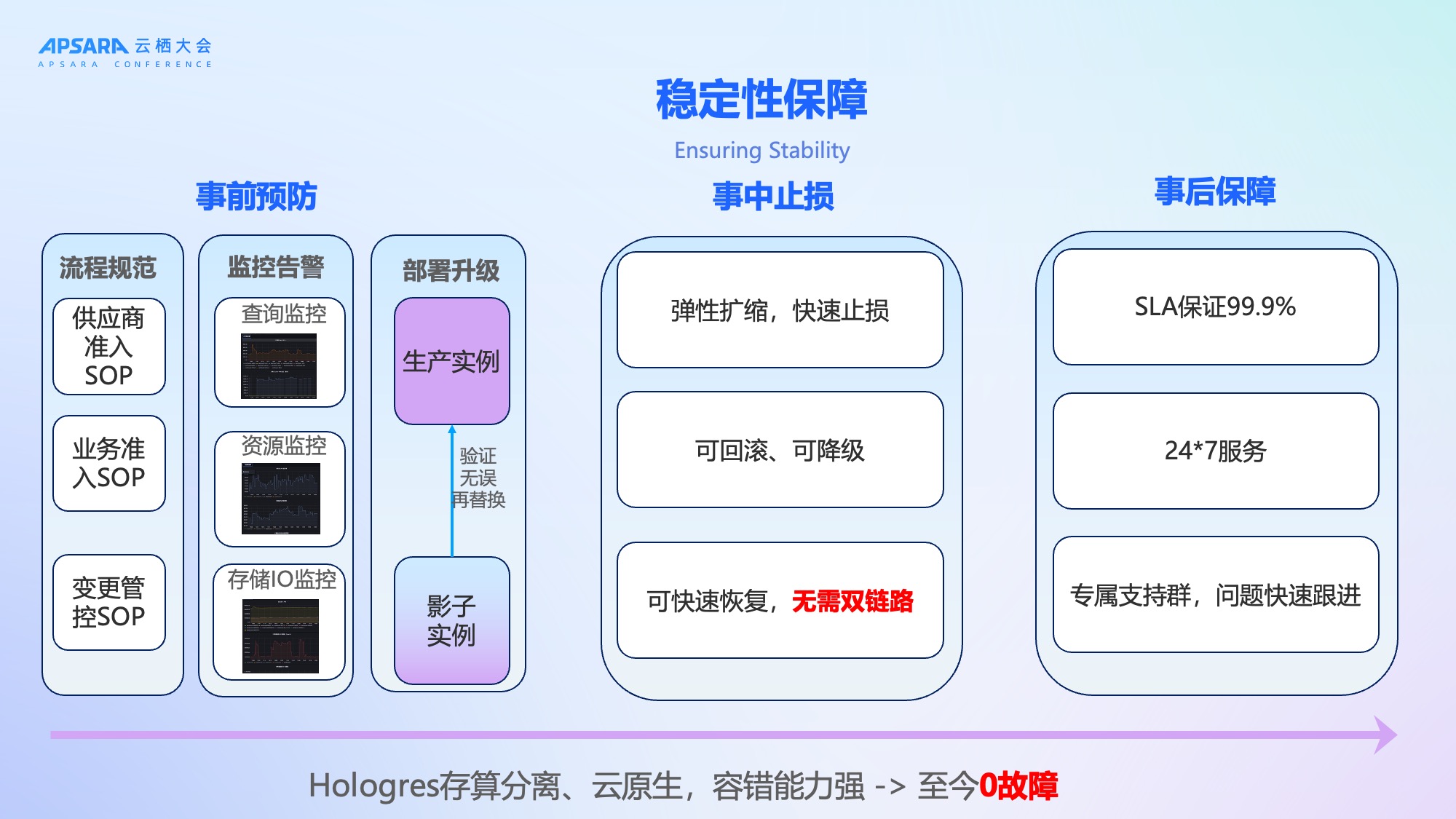
稳定性不仅是产品的能力,更是流程机制的建立。理想汽车基于Hologres 存算分离、云原生架构,系统容错能力强,上线至今0故障,同时在内部构建了"事前预防、事中止损、事后保障"的全链路稳定性体系:
-
事前预防:
-
制定《业务准入SOP》《变更管控SOP》《供应商准入SOP》;
-
完善Hologres监控告警:查询监控、资源监控、存储IO监控全覆盖;
-
使用影子实例验证变更,无误后再上线。
-
事中止损:
-
弹性扩缩:高峰期自动扩容,低峰期缩容;
-
快速回滚:升级异常可秒级回退;
-
服务降级:非核心查询可临时降级,保障核心链路。
-
事后保障:
-
SLA承诺99.9%,7×24小时专属支持;
-
审计日志完善,支持自助分析瓶颈。
Hologres+Flink架构总结
使用了阿里云Hologres+Flink这套技术栈以后,我觉得我们既有现在又有未来。如刚才所说,现在能支持理想汽车一百多万辆车的一个场景,也可以通过扩容去支持未来200万辆车甚至更多的一个场景,不需要做多种集群的拆分。第二方面是效率高,成本低。Hologres具有极致的弹性能力,还有一些这种Serverless Computing这样的弹性资源,大幅提高我们的资源利用率,避免资源浪费。而且Hologres是一个多模态的分析场景,未来还可以扩展到OLAP分析、点查服务、全文检索、向量搜索以及AI推理等多种场景。
最后方面稳定应用。如刚才所说,理想汽车构建了非常完善的稳定性保障的机制,拥有完善的审计日志,让我们可以灵活的自助分析我们系统的瓶颈和风险。

三、理想汽车基于Hologres+Flink构建万亿级车联网信号实时分析平台
以上是架构设计的思考,后续给大家介绍理想汽车基于Hologres+Flink这套架构在业务上线应用过程中一些情况。包括我们刚才提到了的工况还原、智能诊断、车辆预警等场景。
整体接入及上线时间线
理想汽车与 Hologres 的合作按以下时间线推进,我们通过大约6-9个月即完成从最初POC测试到正式上线,整个过程平稳有序,验证了新架构的可靠性。
从最开始24年的12月份跟Hologres做初步对接,Hologres团队其实很快的就完成了POC的这个测试,符合我们性能的诉求。过完年后我们开始在2-4月份去进行全面的压测跟优化,又做了灰度的查询的验证,验证了扩缩容对业务没有影响。因为这次架构的升级要求对业务无感的,5越分开始我们进行了新老链路的双跑,并在五一和端午两个高峰的假期去验证整体的能力,发现Hologres是完全满足假期高峰出行的流量保障要求。端午之后,我们就把老的这个链路给下线了,整个五月期间,也没有发生任何故障,于是我们在实时的链路上又接入了一些复杂的一些计算的场景。
整体业务实践和收益
接入 Hologres 后,理想汽车资源利用率提升,实现性能与成本的完美平衡;响应时间满足SLA:历史工况回溯等场景响应时间达标,SLA达标率99.9%。
- 写入性能提升200%:在成本持平前提下,写入能力翻倍,达150万RPS,零延迟;比方说网络抖动,或者是消费的服务有所异常的情况,导致的信号积压的场景下,我们能快速的恢复跟止损。
- QPS提升32%:热查询使用独立Hologres Warehouse,专注热数据处理,资源利用率比共享池高20%;
- 计算成本降低40%:冷查询虽然频率比较低,但是又有一定的实时要求,采用Hologres Serverless Comuting模式,按量付费,降低成本,也能保证SLA;

应用一:"自动列化+动态扩列"破解海量车机存储难题
面对100万辆车10000+动态信号,理想汽车设计了"A-Z固定列 + JSONB列式动态存储"方案,Hologres 开启JSONB列式存储优化后,底层自动将JSONB转换为强Schema列式存储,查询时可直接命中指定列,提升性能;同时存储压缩效率高,有效降本增效。
- 灵活性:支持信号动态增减,无需频繁变更表结构,适配业务快速迭代;
- 高效性:JSONB格式具备高效存储与解析性能,结合A-Z列分类,大幅减少数据扫描范围;
- 可维护性:信号按首字母分类存储,数据归属清晰,便于后续分区管理与优化。
应用二:读写优化,万亿数据秒级写入和查询
为满足万亿级数据秒级写入,理想汽车基于Hologres采用多项优化:
- Copy模式写入:使用二进制协议,高效写入,写入即可查;
- 连接池 + Table Schema缓存:防止每次Copy创建新连接,减少服务端CPU消耗;
- 攒批Flush:减少close频率,进一步提高性能;Flush与Checkpoint同步,保证消息不丢失;
- 零延迟快照:基于增量视图Union明细表,实现信号最新快照的零延迟查询。
这些优化确保了高吞吐、低延迟、高可靠的数据写入能力。

在查询层面,我们是做到了1万+QPS的秒级返回。主要是基于Hologres的cache优化能力,保证热点数据能覆盖到95%以上。基于条件下推减少了scan的扫描,jsonb列存化减少scan时的io大小和cpu消耗。然后针对这一些大量的点查,vin作为distribution key 保证数据均匀分布, ts作为clustering key帮助高效裁剪文件。
应用三:高峰期稳定性保障
在五一和端午假期期间,理想汽车通过节前扩容20%、节后缩容20%,成功应对流量高峰,保证SLA,假期无故障,写入无延迟,实现10000+ QPS的高性能响应。
应用四:离线场景降本提效
理想汽车还有一些离线场景,我们也将他迁移到Hologres上,有几个典型的场景:
- **数据探查:**数据分析师或者是数据产品在提数据需求时,他可能对数据本身的质量和数据的分布情况其实没有一个感知。需要数仓的同学先做探查,再反复地去沟通,这个时间其实比较耗时,可能会占用我们一半的研发的时间。我们希望把这个数据探查做成一个自助化的,通过Hologres用户可以去自己探查数据后再来提数据的诉求。
- **数据加工:**针对一些简单的数据加工ETL,例如一些信号循环的加工,让业务分析师能够自主的去使用。
- **交叉分析:**加工完循环数据表,包括一些简单的信号的加工之后,业务可以做一些交叉分析。
这些场景以前都比较慢,我们通过Hologres的JsonB全量表+Dynamic Table增量加工+Serverless Computing弹性计算资源,实现了在降低成本的同时,提升了加工效率,并满足了业务对性能的要求。
整体资源的利用率比原先离线的能提高60%,成本是离线场景能下降到35%,下降了35%,整体的这个交付的时间基本上从原来的3到5天能减少到4个小时之内,覆盖了90%离线信号分析场景。

四、未来展望
理想汽车与 Hologres 团队将持续深化合作,探索更多创新方向:
- Serverless Flink统一写入:进一步简化架构,提升写入弹性与性能;
- Hologres能力增强:基于新发布能力,探索Time Travel等特性,实现更细粒度的数字孪生与冷存管理;
- 接入更多场景:扩展至充电场站信号、台架测试数据等新信号源,支持自动驾驶、AI训练等复杂OLAP与AI场景。
通过 Hologres + Flink 的深度整合,理想汽车成功构建了稳定、弹性、高效、低成本的万亿级车联网实时分析平台。该平台不仅解决了当前业务痛点,更具备面向未来的扩展能力------可平滑支撑200万辆车甚至更大的业务规模,无需架构重构。理想汽车将与阿里云合作不断深耕大数据+AI场景,为用户提供卓越、稳定、安全的汽车智能驾驶体验。