目录
- 一、什么是字体文件?
- 二、认识字体文件的构成
-
- [2.1 字体元数据(Font Metadata)](#2.1 字体元数据(Font Metadata))
- [2.2 字形数据(Glyph Data)](#2.2 字形数据(Glyph Data))
- [2.3 字符映射(Character Mapping)](#2.3 字符映射(Character Mapping))
- [2.4 度量信息(Metrics)](#2.4 度量信息(Metrics))
- [2.5 提示信息(Hinting Information)](#2.5 提示信息(Hinting Information))
- [2.6 OpenType 与 TrueType 特性](#2.6 OpenType 与 TrueType 特性)
- 三、字体文件实践与浏览器渲染流程
-
- [3.1 下载并选择字体](#3.1 下载并选择字体)
- [3.2 子集化(删除多余字符)](#3.2 子集化(删除多余字符))
- [3.3 使用 Python + fontTools 转换成 XML](#3.3 使用 Python + fontTools 转换成 XML)
- [3.4 浏览器字体加载与渲染机制](#3.4 浏览器字体加载与渲染机制)
- 四、反爬案例实现
- 五、绕过字体反爬实战
-
- [5.1 某眼案例](#5.1 某眼案例)
- [5.2 某职案例](#5.2 某职案例)
- [5.3 SpiderDemo第8题](#5.3 SpiderDemo第8题)
一、什么是字体文件?
在计算机世界中,字体文件(Font File) 是一种用于存储文字外观信息的文件。它不仅决定了文字的形状、大小、粗细、间距等视觉特征,还包含了字符与图形(glyph)之间的 映射关系 。简单来说,字体文件就像一份 "字形图纸"------告诉系统每个字符该如何被绘制出来。常见的字体格式有:
| 格式 | 全称 | 特点 | 主要用途 |
|---|---|---|---|
| TTF | TrueType Font | 使用 TrueType 轮廓(glyf 表),跨平台兼容性强 | 桌面、网页通用 |
| OTF | OpenType Font | TrueType 的扩展,支持高级排版功能,包含 CFF 轮廓 | 高级排版、印刷 |
| WOFF | Web Open Font Format | 针对网页优化的压缩版 TTF/OTF,加载快 | Web 页面字体 |
| WOFF2 | Web Open Font Format 2 | 进一步提升压缩率,基于 Brotli 压缩算法 | 现代浏览器 Web 字体 |
| EOT | Embedded OpenType | 微软为 IE 设计的嵌入式字体格式 | 旧版 IE 兼容用途 |
字体文件在操作系统与浏览器中的角色:在操作系统层面,字体文件是 系统级资源 。当我们在 Word、记事本或任何桌面程序中输入文字时,系统会调用对应的字体文件,根据字体文件中的字形信息,将 "字符编码" 转换成实际可显示的图形------这就是我们看到的字。而在浏览器中,字体文件的角色更加灵活。网页并不依赖用户本地的字体,而是可以通过 CSS 的 @font-face 规则 动态引入外部字体文件 。这意味着网站开发者可以:使用自定义字体来统一视觉;或者(重点来了)通过自定义字体文件来控制特定字符的显示效果。
二、认识字体文件的构成
在开始研究 字体反爬 之前,我们需要先了解一下字体文件本身的结构。字体文件不仅仅是用来展示文字的,它实际上是一个包含 矢量数据、字符映射、排版信息、渲染提示 等多种信息的复杂容器。
2.1 字体元数据(Font Metadata)
元数据是字体的 "基本信息",描述字体的身份和属性。主要包括:
- 字体名称(Font Family Name) :比如
Times New Roman、Arial、Roboto等。它定义了字体系列的名称,便于系统或应用识别。 - 字体样式(Font Style) : 包括常规(Regular)、粗体(Bold)、斜体(Italic)、粗斜体(Bold Italic)等样式,用于区分同一字体家族下的不同外观。Windows 中的字体文件都存储在位置:
C:\Windows\Fonts

- 版权与许可信息(Copyright / License):标明字体的作者、版权归属、授权范围。比如某些字体只能个人使用,商用需付费。
- 版本号与厂商信息(Version / Vendor):用于区分不同版本的字体更新,以及识别字体供应商。
双击打开 ,Windows 会自动启动字体查看器(Font Viewer); 这个查看器其实只展示了一部分元数据,完整的表(比如 head、name、OS/2、post 等)只能通过专业工具或 Python 代码查看(能用 fontTools 库中的 TTFont 来查看元数据)

2.2 字形数据(Glyph Data)
字形数据是字体文件的 "核心内容",决定了每个字符的实际外观。
- 字形轮廓(Glyph Outline) :每个字符(glyph)的形状通常以 矢量路径(由贝塞尔曲线组成)存储。矢量的好处是------无论放大或缩小都不会失真。
- 点阵数据(Bitmap Data): 一些字体(尤其是旧式位图字体)还会包含固定尺寸的点阵信息,用于特定分辨率下的渲染。不过在现代字体中,这类数据已较少见。
2.3 字符映射(Character Mapping)
字符映射决定了 "某个字符代码对应哪个字形" 。字符编码表(Character Map / cmap):这是字体文件中最重要的表之一,负责定义 Unicode 编码与字体内部 glyph ID 的映射关系。例如:
javascript
// 字符 "A" (Unicode U+0041) → glyph 索引 36
// 字符 "中" (Unicode U+4E2D) → glyph 索引 512浏览器或操作系统在渲染时,就是依靠这张映射表找到对应的字形。
2.4 度量信息(Metrics)
度量信息用于定义字体的排版特征,比如文字的高度、宽度、间距等。
- 基线(Baseline) :所有字符
"站立"的基准线,用于行对齐。 - 上升(Ascender)与下降(Descender) :Ascender 是字符最高部分相对于基线的距离(如
"h"、"b"的上半部分),
Descender 则是最低部分(如"g"、"p"的下半部分)。 - 字距调整对(Kerning Pairs) :定义某些字符组合之间的间距微调规则,比如在排版中,
"AV"通常会稍微靠近,视觉更协调。
2.5 提示信息(Hinting Information)
Hinting 是字体文件中的一种 "智能微调" 机制。在低分辨率或小字号时,字体可能会出现模糊或笔画不均的情况。提示信息会告诉渲染引擎如何调整笔画,使得字体在像素级别下依然清晰。例如: 在 12px 显示下,某条水平线可能会自动对齐到像素网格上,避免出现半像素模糊。
2.6 OpenType 与 TrueType 特性
OpenType 特性(OT Features):主要为排版提供高级功能,如:
- 连字(Ligatures):如
"fi"→"fi" - 替代字符(Alternates):用于美术或特殊排版
- 上下标、分数、旧式数字等高级排版形式
TrueType 指令(TrueType Instructions):TrueType 格式特有的字节码指令,用于控制字体在不同设备、分辨率下的渲染行为(属于 hinting 的一种底层形式)。
三、字体文件实践与浏览器渲染流程
在前一部分中,我们已经系统地认识了字体文件的构成,包括元数据、字形数据、字符映射、度量信息等核心组成部分。理解这些理论后,接下来我们就可以进入到实操环节:通过真实的字体文件,观察其内部结构,并学习浏览器在加载字体时的查找与映射过程。
为此,我们将选择一个 开源字体 ,并通过以下几个步骤进行深入学习:子集化字体(仅保留常用字符 0--9、A--Z、a--z、.、@) → 转换为 XML 格式 → 分析关键表结构 → 理解浏览器字体映射机制。
在本节中,我们将推荐一个合适的开源字体,提供下载链接,并通过子集化和 XML 转换的方式,带你逐步掌握字体文件的结构与映射逻辑。这不仅有助于理解字体在网页中的加载与渲染机制,也为后续的 字体反爬研究 打下坚实的基础。
3.1 下载并选择字体
推荐使用 Inconsolata(一个开源的等宽体字体):Inconsolata 是一个开源字体,设计者为 Raph Levien,授权为 SIL Open Font License(OFL): 可免费用于修改与再分发。 它覆盖 Latin 字母、数字、标点等,比较适合我们去做 "保留常用字符" 练习。官方下载链接(或通过 Google Fonts)都可以获取。https://fonts.google.com/selection 我这里已经上传到百度网盘,大家可以直接从网盘中获取:
text
通过网盘分享的文件:Inconsolata.zip
链接: https://pan.baidu.com/s/1SSZpb2Ksv3M28CSHOryd7A?pwd=sk38 提取码: sk38
--来自百度网盘超级会员v9的分享3.2 子集化(删除多余字符)
打开 FontStore 这类在线工具(或任意子集化工具)来操作。流程如下:
① 上传字体文件
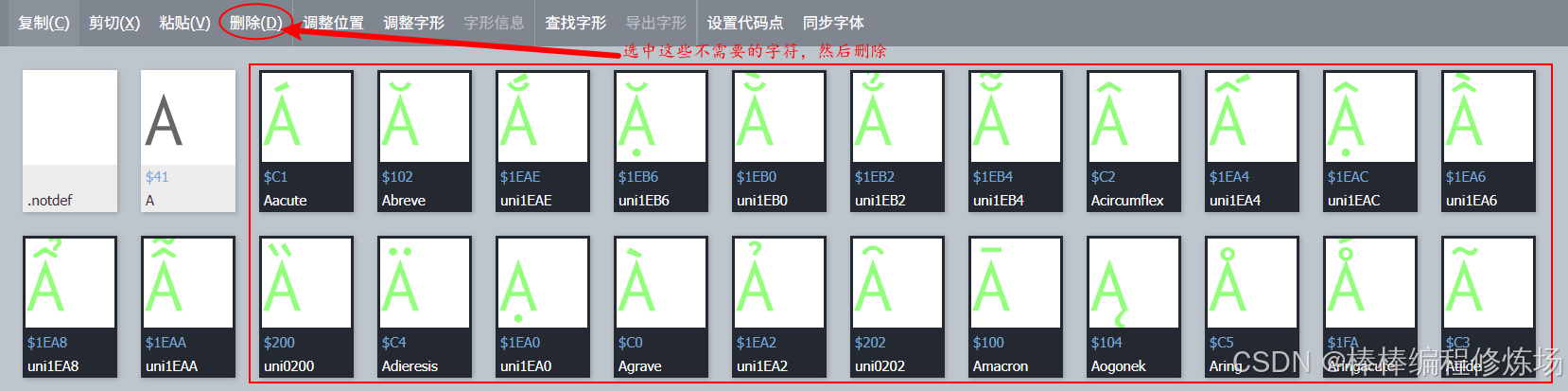
② 在字符集选项中,仅保留需要的字符:数字 0-9、大写字母 A-Z、小写字母 a-z、点号 .、@ 符号,其余的都删除(最前面的 .notdef 这些别动)。删除如下图所示:
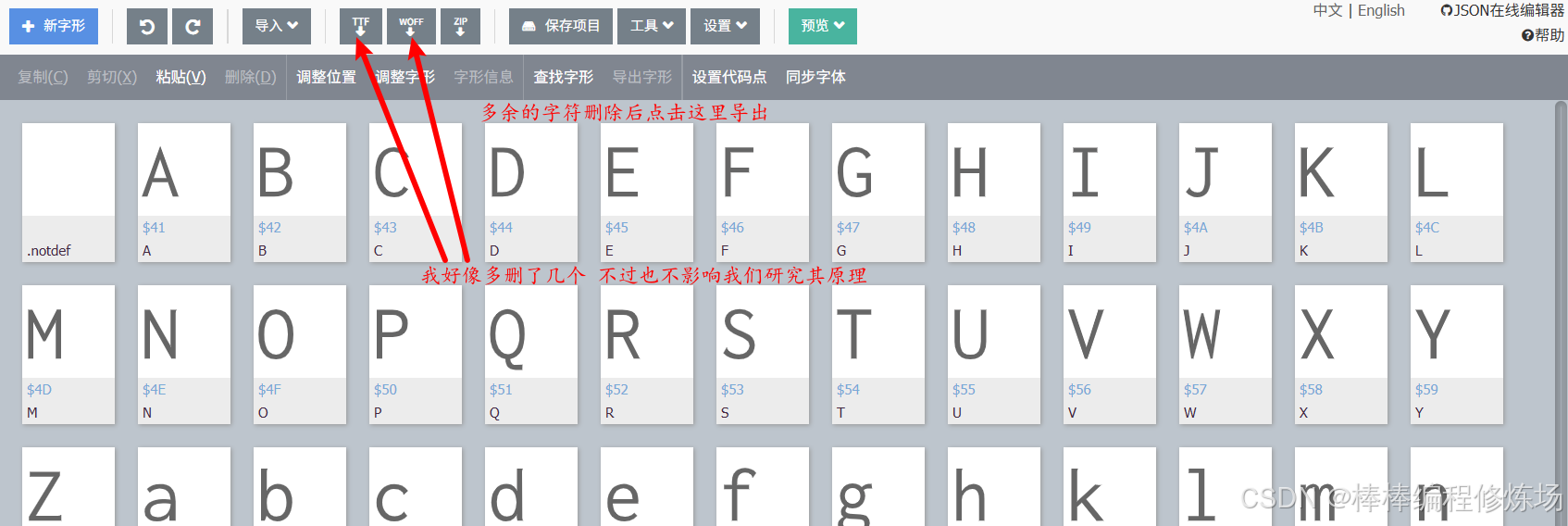
③ 删除完成之后导出子集后的字体,例如 Inconsolata-Subset.ttf 或 .woff2,我们两种格式的都导出一下方便后续研究:
注意: 保留少量字符后,字体文件体积变小,更便于我们观察映射情况。

3.3 使用 Python + fontTools 转换成 XML
注意: WOFF/WOFF2 是 Web 优化压缩格式,需要先解压缩才能生成 XML。fontTools 支持直接加载,但需要 woff2 库支持 WOFF2。安装命令如下:
bash
pip install fonttools[woff]
# 参考文章:
# https://fonttools.readthedocs.io/en/latest/
# https://github.com/fonttools/fonttoolsfontTools 是处理字体文件的 Python 库,支持 TTF、OTF、WOFF、WOFF2 等格式。提供 ttx 命令行工具,可以把字体转换为 XML,也可以把 XML 转回字体。Python 脚本如下:
python
from fontTools.ttLib import TTFont
# ① 加载ttf文件
font = TTFont('Inconsolata.ttf')
# 导出为XML
font.saveXML("font.ttx.xml")
print("TTF 已转换为 XML: font.ttx.xml")
# ② 加载 WOFF/WOFF2 文件
font = TTFont("Inconsolata.woff")
# 导出 XML
font.saveXML("font_woff.ttx.xml")
print("WOFF 已转换为 XML: font_woff.ttx.xml")TTFont 会自动识别 TTF 文件格式。saveXML 方法生成完整 XML 文件,方便后续分析字符和轮廓。同理 TTFont 会自动识别并解压 WOFF/WOFF2 文件。XML 文件中内容结构与 TTF 非常相似,但需要注意:原始 WOFF2 文件可能有压缩优化,XML 展开后才能看到完整字形数据。WOFF2 对字符表、轮廓表内容没有丢失,只是存储格式不同。无论 TTF 还是 WOFF2,XML 的主要结构类似:
xml
<ttFont sfntVersion="OTTO" ttLibVersion="4.39.4">
<GlyphOrder>
...
</GlyphOrder>
<head>
...
</head>
<hhea>
...
</hhea>
<maxp>
...
</maxp>
<OS_2>
...
</OS_2>
<hmtx>
...
</hmtx>
<cmap>
...
</cmap>
<loca>
...
</loca>
<glyf>
...
</glyf>
<name>
...
</name>
<post>
...
</post>
</ttFont>下面详细解释每一部分:
① <GlyphOrder> 作用 :列出字体中所有字形(glyph)的顺序。特点 :这是 glyph 在字体内部索引的顺序。cmap 表会使用索引来映射 Unicode 字符。观察重点:了解哪些字形存在,对子集化后的字体可以快速对比哪些字形被删除了。
xml
<GlyphOrder>
<GlyphID id="0" name=".notdef"/>
<GlyphID id="1" name="A"/>
<GlyphID id="2" name="B"/>
<GlyphID id="3" name="uni4E2D"/>
<GlyphID id="4" name="glyph00004"/>
</GlyphOrder>
<!-- <GlyphOrder> 是一个 总目录 ,列出所有 glyph 的排列顺序 -->
<!-- <GlyphID> 就是一个条目,对应一个具体的 glyph ID 与 glyph 名称 -->② <head>(字体头表)作用 :存储字体全局元信息。主要字段 :unitsPerEm:每个字体单位的基准,比如 1000 或 2048。xMin, yMin, xMax, yMax:字体轮廓的全局边界。created / modified:字体创建和修改时间。观察重点:单位和字体边界,用于绘制时的缩放和定位。
xml
<head>
<!-- Most of this table will be recalculated by the compiler -->
<tableVersion value="1.0"/>
<fontRevision value="3.001"/>
<checkSumAdjustment value="0x6bdefffd"/>
<magicNumber value="0x5f0f3cf5"/>
<flags value="00000000 00001011"/>
<unitsPerEm value="1000"/>
<created value="Wed Dec 11 20:47:13 2019"/>
<modified value="Wed Apr 1 13:10:26 2020"/>
<xMin value="16"/>
<yMin value="-174"/>
<xMax value="488"/>
<yMax value="671"/>
<macStyle value="00000000 00000000"/>
<lowestRecPPEM value="6"/>
<fontDirectionHint value="2"/>
<indexToLocFormat value="0"/>
<glyphDataFormat value="0"/>
</head>③ <hhea>(水平头表)作用 :存储水平排版相关信息。主要字段 :ascender(ascent) / descender(descent):字体上下延伸范围,lineGap:默认行间距,numberOfHMetrics:水平度量数量。观察重点:用于确定文本行高,水平布局计算必读。
xml
<hhea>
<tableVersion value="0x00010000"/>
<ascent value="859"/>
<descent value="-190"/>
<lineGap value="0"/>
<advanceWidthMax value="500"/>
<minLeftSideBearing value="16"/>
<minRightSideBearing value="12"/>
<xMaxExtent value="488"/>
<caretSlopeRise value="1"/>
<caretSlopeRun value="0"/>
<caretOffset value="0"/>
<reserved0 value="0"/>
<reserved1 value="0"/>
<reserved2 value="0"/>
<reserved3 value="0"/>
<metricDataFormat value="0"/>
<numberOfHMetrics value="1"/>
</hhea>④ <maxp>(最大值表)作用 :字体中各种表的最大值信息,供渲染器优化。主要字段 :numGlyphs:字形数量。其他字段:轮廓点最大数、组件最大数等。观察重点:验证字形总数是否符合预期,分析字体复杂度。
xml
<maxp>
<!-- Most of this table will be recalculated by the compiler -->
<tableVersion value="0x10000"/>
<numGlyphs value="62"/>
<maxPoints value="95"/>
<maxContours value="4"/>
<maxCompositePoints value="0"/>
<maxCompositeContours value="0"/>
<maxZones value="2"/>
<maxTwilightPoints value="16"/>
<maxStorage value="47"/>
<maxFunctionDefs value="154"/>
<maxInstructionDefs value="0"/>
<maxStackElements value="731"/>
<maxSizeOfInstructions value="0"/>
<maxComponentElements value="0"/>
<maxComponentDepth value="0"/>
</maxp>⑤ <OS_2>(Windows/OS2 指标表)作用 :包含字体兼容性和外观信息。主要字段 :usWeightClass:字体粗细,usWidthClass:字体宽度,sTypoAscender/Descender:推荐排版用的上/下延伸,fsSelection:样式标记(斜体、粗体等)。观察重点:用于排版引擎选择字体样式,Windows/Office 渲染字体常用。
⑥ <hmtx>(水平度量表)作用 :每个字形的水平宽度信息。主要字段 :advanceWidth(width):字形宽度,lsb(left side bearing):左侧间距。观察重点:绘制字符水平位置,字符间距调整依赖此表。
⑦ <cmap>(字符映射表Character to Glyph Index Mapping Table):是字体中 把字符码(Unicode 或其他编码)映射到字形名称/索引(glyph) 的表。它的作用非常核心:浏览器拿到 "字符码(U+0030)→ 在 cmap 中找到对应 glyph → 用 glyf 表画出形状"。TTX 中的 cmap 大致结构如下:
xml
<cmap>
<tableVersion version="0"/>
<cmap_format_0 platformID="1" platEncID="0" language="0">
<map code="0x0" name=".notdef"/>
...
</cmap_format_0>
<cmap_format_4 platformID="3" platEncID="1" language="0">
<map code="0x30" name="zero"/><!-- DIGIT ZERO -->
<map code="0x31" name="one"/><!-- DIGIT ONE -->
...
</cmap_format_4>
<cmap_format_12 platformID="3" platEncID="10" language="0">
<map code="0x20" name="space"/>
...
</cmap_format_12>
</cmap><tableVersion version="0"/>,表示 cmap 表头版本号,一般恒为 0。用于标识 cmap 的结构格式(OpenType 规定的固定值)。多个 <cmap_format_X> 的意义,字体可能支持 多种编码方案,例如:
| cmap 格式标签 | 平台ID(platformID) | 编码ID(platEncID) | 含义 |
|---|---|---|---|
cmap_format_0 |
1 (Macintosh) | 0 | Macintosh Roman 编码(老系统) |
cmap_format_4 |
3 (Windows) | 1 | Windows Unicode BMP (UCS-2) |
cmap_format_12 |
3 (Windows) | 10 | Windows Unicode UCS-4 (扩展平面) |
多个格式同时存在是为了 兼容不同系统 。浏览器或操作系统一般优先使用 Windows Unicode (platformID=3, platEncID=1 或 10)。<cmap> 下每一行 <map> 表示一个字符码和字形名的映射:
xml
<map code="0x30" name="zero"/><!-- DIGIT ZERO -->
<!-- ① code="0x30": 字符码(16进制 Unicode),例如 0x30 = "0" -->
<!-- ② name="zero": 字形名(glyph name),对应 <GlyphOrder> 和 <glyf> 表 -->
<!-- ③ DIGIT ZERO : 注释(fontTools 自动生成)说明含义 -->⑧ <loca>(字形偏移表)作用 :存储每个字形在 glyf 表中的偏移位置。观察重点:glyph 在文件中的定位,便于快速查找字形轮廓数据。
⑨ <glyf> 表(字形表Glyph Data Table)记录了字体中每个 字形(glyph) 的矢量轮廓数据。每个 glyph 对应一个字符(如 "A"、"B"、"0" 等),而真正的显示形状------线条、曲线、笔画结构,全都在这里。在 TTF/XML 中,它看起来像这样:
xml
<TTGlyph name="A" xMin="16" yMin="0" xMax="484" yMax="634">
<contour>
<pt x="357" y="182" on="1"/>
<pt x="131" y="182" on="1"/>
<pt x="145" y="236" on="1"/>
<pt x="341" y="236" on="1"/>
</contour>
<contour>
<pt x="249" y="474" on="1"/>
<pt x="85" y="0" on="1"/>
<pt x="16" y="0" on="1"/>
<pt x="246" y="634" on="1"/>
<pt x="254" y="634" on="1"/>
<pt x="484" y="0" on="1"/>
<pt x="412" y="0" on="1"/>
</contour>
<instructions/>
</TTGlyph>基本结构:每一个 <TTGlyph> 节点描述一个字形:
| 属性 | 含义 |
|---|---|
name |
字形名称(对应 <cmap> 中的 name) |
xMin, yMin |
字形最小边界坐标(左下角) |
xMax, yMax |
字形最大边界坐标(右上角) |
这四个坐标定义了该 glyph 的边界框(bounding box)。<contour> 与 <pt>(点):每个 <contour> 表示一条封闭的曲线轮廓(类似路径 path),内部 <pt> 是曲线上的控制点或锚点。
xml
<contour>
<pt x="357" y="182" on="1"/>
<pt x="131" y="182" on="1"/>
<pt x="145" y="236" on="1"/>
<pt x="341" y="236" on="1"/>
</contour>TrueType 使用 二次贝塞尔曲线(quadratic Bézier curves),而不是三次曲线。这意味着每个曲线段最多有一个控制点。
| 属性 | 含义 |
|---|---|
x, y |
坐标位置(相对于字体坐标系) |
on |
是否为 "on-curve" 点(1 表示曲线实际经过该点,0 表示二次贝塞尔曲线控制点) |
<instructions>(hinting),<instructions> 存放 TrueType 的 hinting 指令(位图优化指令),用于在小字号下微调笔画,保证字体清晰。例如:
xml
<instructions>
00 01 02 03 04 05 ...
</instructions>这些是字节码指令(TrueType bytecode),在反爬方向中通常 不影响外观分析 ,可以忽略或删除。<component>(复合字形),某些字符并非独立绘制,而是由其他 glyph 组合而成,例如:
xml
<TTGlyph name="Å">
<component glyphName="A" xScale="1.0" yScale="1.0" xOffset="0" yOffset="0"/>
<component glyphName="ring" xScale="1.0" yScale="1.0" xOffset="300" yOffset="600"/>
</TTGlyph>即 "Å" 由 "A" 和 "ring" 两个子 glyph 组成:
| 属性 | 含义 |
|---|---|
glyphName |
被引用的 glyph 名称 |
xScale, yScale |
缩放比例 |
xOffset, yOffset |
平移偏移量 |
字体的坐标系以 "em" 为单位(例如 1000 或 2048 units/em)。坐标原点 (0,0) 通常位于基线(baseline)上。向上是正 y 方向,向右是正 x 方向,如下图所示(简化):
diff
↑ y+
|
| ● (xMax, yMax)
| /|
| / |
---+---•----+----→ x+
(0,0)这也是浏览器渲染字体时用于定位的基础。与其他表的关联:
| 表名 | 与 glyf 的关系 |
|---|---|
maxp |
提供 glyph 总数(numGlyphs) |
loca |
存储每个 glyph 在 glyf 表中的偏移位置(offset) |
hmtx |
定义 glyph 的宽度与左右边距(影响排版) |
cmap |
提供字符码 → glyph name 的映射 |
head |
定义坐标单位、字体方向等参数 |
因此:cmap 告诉你哪个 Unicode 对应哪个 glyph; glyf 告诉你这个 glyph 怎么画; hmtx 告诉你画完后怎么排版间距。
⑩ 字体 XML 中的 <name> 表记录了字体的 名称信息(Naming Table) ,包括:字体的全名(Full Name)、字体家族(Family)、样式(Subfamily)、字体版本、字体制造商、版权信息、字体在系统中显示的名称等。这些信息主要供:操作系统字体管理器识别字体;浏览器或 Office 等程序显示正确的字体名称;字体嵌入时使用元数据。从 .ttx(XML) 中可以看到类似这样的结构:
xml
<name>
<namerecord nameID="1" platformID="3" platEncID="1" langID="0x409">Arial</namerecord>
<namerecord nameID="2" platformID="3" platEncID="1" langID="0x409">Regular</namerecord>
<namerecord nameID="4" platformID="3" platEncID="1" langID="0x409">Arial Regular</namerecord>
<namerecord nameID="5" platformID="3" platEncID="1" langID="0x409">Version 2.95</namerecord>
<namerecord nameID="6" platformID="3" platEncID="1" langID="0x409">Arial-Regular</namerecord>
<namerecord nameID="13" platformID="3" platEncID="1" langID="0x409">http://www.adobe.com/type/legal.html</namerecord>
</name>nameID 表示字段编号,对应特定类型的信息,这是最重要的属性。有些字体只有少数字段,比如 nameID=1,2,4,6,有些字体则包含十几项。
| nameID | 含义 | 示例 |
|---|---|---|
| 0 | Copyright notice | © 2023 Example Foundry |
| 1 | Font Family name(字体家族名) | Arial |
| 2 | Font Subfamily(样式) | Regular / Bold / Italic |
| 3 | Unique font identifier | Arial-Regular-1.00 |
| 4 | Full font name(全名) | Arial Regular |
| 5 | Version string | Version 2.95 |
| 6 | PostScript name | Arial-Regular |
| 7 | Trademark | Arial® |
| 8 | Manufacturer | Microsoft Corporation |
| 9 | Designer | Monotype Design Team |
| 10 | Description | A sans-serif typeface family. |
| 11 | URL Vendor | http://www.microsoft.com |
| 12 | URL Designer | http://www.monotype.com |
| 13 | License Description | Licensed to Microsoft Corp. |
| 14 | License Info URL | http://www.adobe.com/type/legal.html |
| 16 | Preferred Family | Arial |
| 17 | Preferred Subfamily | Regular |
| 18 | Compatible Full(Macintosh only) | Arial Regular |
| 19 | Sample Text | The quick brown fox jumps... |
platformID 表示平台编码体系(一般现代字体使用 platformID="3"(Windows 平台)):
| platformID | 含义 |
|---|---|
| 0 | Unicode |
| 1 | Macintosh |
| 3 | Windows |
platEncID表示编码方式(取决于平台):对于 Windows 平台(platformID=3):0 = Symbol,1 = Unicode BMP (UCS-2),10 = Unicode Full (UTF-32),现代字体多为 platEncID="1"。langID 语言编号,常见为:
| langID | 语言 | 十六进制值 |
|---|---|---|
| 0x409 | English (United States) | en-US |
| 0x804 | Simplified Chinese | zh-CN |
| 0x411 | Japanese | ja-JP |
例如:
xml
<!-- 表示这是简体中文语言下的字体全名 -->
<!-- 用于 CSS font-family 显示;版权、商用信息可查-->
<namerecord nameID="4" platformID="3" platEncID="1" langID="0x804">思源黑体 常规</namerecord>最后一个 <post>(PostScript 表)作用 :PostScript 相关信息,主要字段 :formatType:PostScript 类型(Type 1、Type 2),italicAngle:斜体角度,underlinePosition / underlineThickness。观察重点:绘制斜体和下划线,PostScript 渲染兼容性。
3.4 浏览器字体加载与渲染机制
浏览器字体加载的整体流程图:
diff
HTML + CSS
↓
解析 CSS 中的 @font-face
↓
下载字体文件(TTF/WOFF/WOFF2/OTF)
↓
解析字体元数据(name、cmap、glyf 等)
↓
建立"字符 → glyph"映射表
↓
浏览器字体引擎绘制字形
↓
渲染结果显示到屏幕上核心 CSS 语法:@font-face 与 font-family,定义字体文件:
css
@font-face {
font-family: 'MyFont';
src: url('myfont.woff2') format('woff2'),
url('myfont.ttf') format('truetype');
font-weight: normal;
font-style: normal;
}这段声明告诉浏览器,有一个叫 MyFont 的字体家族,它的字体文件在 myfont.woff2 或 myfont.ttf,支持格式为 woff2 或 truetype,浏览器会优先加载第一个支持的格式(现代浏览器多优先使用 .woff2)。本地新建一个 test.html 文件:
html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
<style>
/*font-face 上面已经解释过了,这里就不在赘述*/
@font-face {
font-family: 'MyFont';
src: url("Inconsolata.ttf") format("truetype"),
url("Inconsolata.woff") format("woff");
font-weight: normal;
font-style: normal;
}
#test-ttf{
font-family: 'MyFont', Arial, sans-serif;
font-size: 100px;
}
</style>
</head>
<body>
<div id="test-ttf">amO666@qq.cOm</div>
</body>
</html>在页面中使用字体:
css
#test-ttf{
font-family: 'MyFont', Arial, sans-serif;
}浏览器渲染文字时,会从左到右查找字体,若 'MyFont' 中有该字符,这个就是我们使用 @font-face 导入的字体名称,我们在 font-family 时直接引用名字就好,就用它;否则回退到系统字体 Arial;还找不到则使用默认 sans-serif。浏览器加载字体文件的过程,当浏览器解析 CSS 时:
| 步骤 | 说明 |
|---|---|
| ① 解析 @font-face | 注册一个新字体族到浏览器字体缓存(Font Face Set) |
| ② 检查缓存 | 如果字体文件已加载,则复用;否则发起下载请求 |
| ③ 下载字体 | 发起 HTTP 请求下载 .woff2 或 .ttf |
| ④ 解码字体 | 解压 WOFF2 / 解包 TTF,解析表结构(head、cmap、glyf等) |
| ⑤ 注册字体 | 把字体注册到内存中,并建立字符映射表 |
| ⑥ 渲染字符 | 当遇到文字时,查找对应 glyph 并绘制到页面上 |
浏览器如何 "找到" 字形并画出来?下面是关键过程,浏览器拿到要渲染的文字,假设 HTML:
html
<div id="test-ttf">amO666@qq.cOm</div>找到当前 CSS 的字体规则,假设样式:
css
/* #test-ttf id选择器 */
#test-ttf{
font-family: 'MyFont', Arial, sans-serif;
}在字体文件中查找映射(cmap 表),cmap 表记录:
xml
<map code="0x61" name="a"/><!-- LATIN SMALL LETTER A -->
<map code="0x6d" name="m"/><!-- LATIN SMALL LETTER M -->
<map code="0x4f" name="O"/><!-- LATIN CAPITAL LETTER O -->
<map code="0x36" name="six"/><!-- DIGIT SIX -->
<map code="0x36" name="six"/><!-- DIGIT SIX -->
<map code="0x36" name="six"/><!-- DIGIT SIX -->
<map code="0x40" name="at"/><!-- COMMERCIAL AT -->
<map code="0x71" name="q"/><!-- LATIN SMALL LETTER Q -->
<map code="0x71" name="q"/><!-- LATIN SMALL LETTER Q -->
<map code="0x2e" name="period"/><!-- FULL STOP -->
<map code="0x63" name="c"/><!-- LATIN SMALL LETTER C -->
<map code="0x4f" name="O"/><!-- LATIN CAPITAL LETTER O -->
<map code="0x6d" name="m"/><!-- LATIN SMALL LETTER M -->浏览器读取字符 a(Unicode 0x61),通过 cmap 查到对应字形名 a。找到对应字形(glyf 表),浏览器进入 <glyf> 表,找到:
xml
<TTGlyph name="a" xMin="49" yMin="-11" xMax="445" yMax="467">
<contour>
<pt x="211" y="-11" on="1"/>
<pt x="133" y="-11" on="0"/>
.......
</contour>
<instructions/>
</TTGlyph>并读取所有点坐标。绘制字形路径(Path),浏览器内部字体引擎(如 Skia , FreeType , DirectWrite 等):将 <pt> 中的点坐标解析为贝塞尔曲线;转换为屏幕像素坐标;根据 hinting / rasterize 渲染出像素点。应用排版信息(hmtx、kern):hmtx(Horizontal Metrics)提供每个字形的宽度与偏移;kern(Kerning)提供特定字符对间距调整;浏览器据此确定每个字的相对位置。绘制到 Canvas / GPU 图层,最终字形路径被交给绘图引擎:转成矢量 → 栅格化 → GPU 缓存;显示到页面上。从字体加载到渲染的关键对应关系小结:
| 层级 | 内容 | 对应表 |
|---|---|---|
| CSS | font-family 名称 |
<name> 表中的 family name (nameID=1 / nameID=4) |
| 字符 | Unicode 编码 | <cmap> |
| 字形 | 绘制路径 | <glyf> |
| 宽度/对齐 | 排版信息 | <hmtx> |
| 渲染优化 | 字节码指令 | <instructions> |
字体渲染流程小结:
-
载入字体文件或内容。网页加载字体的方式有两种,无论哪种方式,本质上都是让浏览器能够正确获取并解析字体内容。
- 外部字体文件:通过字体文件链接由浏览器下载字体,再由 CSS 读取内容。
- Base64 编码字体:将字体文件内容以 Base64 编码嵌入到 CSS 中,浏览器可直接解析使用。
-
使用 @font-face 定义字体,字体文件通常通过
@font-face规则进行声明,定义字体名称和来源,例如:css@font-face { font-family: 'YourWebFontName'; /* 路径 */ src: url('font.ttf'); } @font-face { font-family: 'AntiSpiderFont'; /* Base64 数据 ${base64Font}: 这里引用了变量base64Font的值,其实就是一个base64*/ src: url(data:font/woff2;base64,${base64Font}) format('woff2'); font-weight: normal; font-style: normal; } /* 其中: font-family 用于指定自定义字体的名称 src 指定字体文件的路径或 Base64 数据 */ -
在样式中引用字体,定义好字体后,可以在 CSS 中通过
font-family引用它。例如:css@font-face { font-family: 'YourWebFontName'; src: url('font.ttf'); } div { font-family: 'YourWebFontName'; font-size: 12px; color: red; } /*这里: @font-face 部分负责定义字体;div 的样式负责应用字体。 这样,页面中的 <div> 标签内容就会使用我们自定义的字体显示,字号为 12px,文字颜色为红色。*/ /* 自定义字体显示的过程在上面已经详细讲解过 这里就不再赘述 简单来说就是找到字体后, 会将html中的文字 找到其对应的 Unicode码,然后取字体文件中查cmap映射 */
四、反爬案例实现
知道了原理之后,我们可以实现一个小小的反爬,我们知道页面上的字符是通过 cmp 映射表,来映射的,那么我们改变这个映射表就可以改变其页面上的显示,比如,我把 1 的映射弄到 2 上去,2 反之则用 1 的映射,但是这里有一个点需要注意,在 cmap 下有三个:
xml
<cmap_format_4 platformID="0" platEncID="3" language="0"></cmap_format_4>
<cmap_format_0 platformID="1" platEncID="0" language="0"></cmap_format_0>
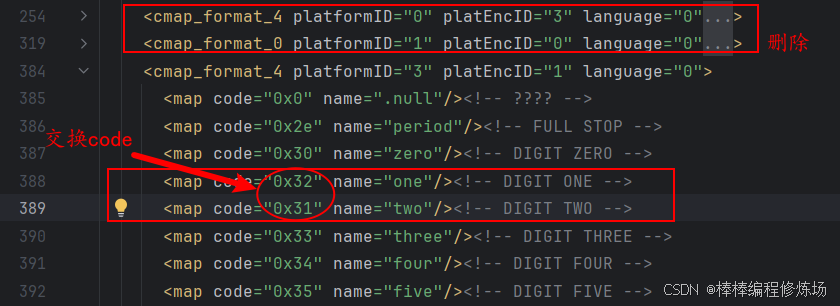
<cmap_format_4 platformID="3" platEncID="1" language="0"></cmap_format_4>前面我们已经说过,浏览器或操作系统一般优先使用 Windows Unicode (platformID=3, platEncID=1 或 10)。所以这里我们需要改第 3 个,当然这个可能会因为操作系统和浏览器不同产生差异,具体你更改哪个生效,需要自行测试,我这里测试浏览器优先使用的第三个,即 platformID="3" platEncID="1",我们将前面两个删除,并且改第三个中 0 和 1 的映射:
xml
<!-- 原始的 -->
<map code="0x31" name="one"/><!-- DIGIT ONE -->
<map code="0x32" name="two"/><!-- DIGIT TWO -->
<!-- 改动之后 -->
<!-- 简单来说如果页面上输入的是 1,对应Unicode为 0x31,但是却找的是two的<glyf>,绘制的是2 -->
<map code="0x32" name="one"/><!-- DIGIT ONE -->
<map code="0x31" name="two"/><!-- DIGIT TWO -->如下图:
手动更改 xml 文件后,使用 fontTools 将 xml 文件转换为字体,然后在页面上进行导入,python 示例代码:
python
from fontTools.ttLib import TTFont
# 1. 读取 XML(TTX)文件并生成字体对象
font = TTFont()
font.importXML("font.ttx.xml")
# 2. 保存为 TTF 格式
font.save("rebuild_font.ttf")
print("字体已成功从 XML 转换回 TTF!")html 代码:
html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
<style>
@font-face {
font-family: 'MyFont';
src: url("rebuild_font.ttf") format("truetype");
font-weight: normal;
font-style: normal;
}
#test{
font-family: "MyFont", Arial, sans-serif;
font-size: 100px;
}
</style>
</head>
<body>
<div id="test">12</div>
</body>
</html>浏览器中查看效果:

有趣的是你此时在浏览器中复制还是 12,上面手动更改映射然后导致页面显示的文字和 html 中的文字不一致是实现动态字体反爬的核心原理。可以通过代码直接更改映射关系:
python
from fontTools.ttLib import TTFont
font = TTFont("Inconsolata.ttf")
cmap_table = font["cmap"].getcmap(3, 1) # 平台ID=3, 编码ID=1(常见)
cmap = cmap_table.cmap
# 交换1(0x41)与2(0x42)的glyph
glyph_1 = cmap[0x31]
glyph_2 = cmap[0x32]
cmap[0x31], cmap[0x32] = glyph_2, glyph_1
font.save("swapped.ttf")在 css 中引入 swapped.ttf,你会发现效果和手动更改 xml 一致。接下来,我们用代码将映射随机打乱就能生成动态的字体了。
-
random_cmap 功能: 打乱字体的
cmap映射表。cmap是一个字典:键是 Unicode 码点,值是字体中的 glyph 名称。打乱后,每个 Unicode 码点会随机对应到另一个 glyph。作用: 实现 字体混淆 ,原本'A'的字符可能显示成'B'的样式,从而干扰爬虫。pythondef random_cmap(cmap): unicode_keys = list(cmap.keys()) glyph_names = list(cmap.values()) random.shuffle(glyph_names) # 生成新的字符映射 new_cmap = dict(zip(unicode_keys, glyph_names)) return new_cmap # 测试 # 要实现动态字体,即改变xml中的映射关系 font = TTFont('Inconsolata.ttf') # 是一个键值对一样的东西 替代之前的font["cmap"].getcmap(3, 1) 省事 cmap = font['cmap'].getBestCmap() print("原有的映射关系 cmap: ", cmap) new_cmap = random_cmap(cmap) print("新的映射关系 new_cmap: ", new_cmap) -
将输入字符串根据新的
cmap映射生成新的编码字符串。内部有一个fft_mapping字典,把"@",".","0-9"转换成对应的 glyph 名称。利用new_cmap_inverted_dict把 glyph 名称转换回 Unicode 码点,再生成字符。作用: 模拟网页或接口中使用混淆字体后显示的字符串编码。比如'123456@qq.com'会被映射成新的字符序列,对应打乱后的字体显示。pythondef map_string(input_str, new_cmap): fft_mapping = { "@": "at", ".": "period", "0": "zero", "1": "one", "2": "two", "3": "three", "4": "four", "5": "five", "6": "six", "7": "seven", "8": "eight", "9": "nine", "nonbreakingspace": " ", } new_cmap_str = '' # input: '@', ==> # 将映射关系key,value反转,这样我们能快速通过某个字符获取其对应的unicode码点 new_cmap_inverted_dict = {value: key for key, value in new_cmap.items()} print(new_cmap_inverted_dict) # 循环处理每一个字符 for char in input_str: # 这里要注意一下,因为我们的映射关系中一些特殊字符是用英文对应的,比如我们传@,但是映射关系里面是用at表示的 # 所以需要有一个 fft_mapping 对其进行转换,这样我们才能在new_cmap_inverted_dict中找到 if char in fft_mapping: # 比如char='@' ,那么转换之后就 char='at' char = fft_mapping[char] # 转换之后 new_cmap_inverted_dict['at'] 就能拿到其码点 'at': 79 # 那接下来我们就要看浏览器中读取哪个字符,得到它的unicode码点之后刚好是79,那么这个字符就是我们要镶嵌在html中的字符了 # chr(79) 转换一下 ==》 O 所以当使用当前这套字体时 页面想显示@,html中需要镶嵌的是 'O'字符 char = chr(new_cmap_inverted_dict[char]) # 79 # 每处理一个字符就进行拼接,那么最后得到字符串就和想要显示在页面中的文字一一对应了 new_cmap_str += char return new_cmap_str -
接下来创建一个新的
cmap表,将字体原来的 Unicode → glyph 映射替换成new_cmap。使用 OpenType 的 subtable 类型 4(常用 Windows 平台编码)。作用: 真正把字体文件中的映射关系更新,使字体文件显示字符对应新的 glyph。pythonfrom fontTools.ttLib import TTFont, newTable from fontTools.ttLib.tables._c_m_a_p import CmapSubtable def update_cmap_table(font, new_cmap): new_cmap_table = newTable('cmap') new_cmap_table.tableVersion = 0 new_cmap_table.tables = [] subtable = CmapSubtable.newSubtable(4) # 这个很熟悉了吧,前面我们操作过platformID于 platEncID # font["cmap"].getcmap(3, 1) # 平台ID=3, 编码ID=1(常见) subtable.platformID = 3 subtable.platEncID = 1 subtable.language = 0 subtable.cmap = new_cmap new_cmap_table.tables.append(subtable) font['cmap'] = new_cmap_table -
测试:
pythondef main(): # 页面上要显示的内容 input_str = '123456@qq.com' # 要实现动态字体,即改变xml中的映射关系 font = TTFont('Inconsolata.ttf') # 是一个键值对一样的东西 替代之前的font["cmap"].getcmap(3, 1) 省事 cmap = font['cmap'].getBestCmap() print("原有的映射关系 cmap: ", cmap) new_cmap = random_cmap(cmap) print("新的映射关系 new_cmap: ", new_cmap) # 之前我们测试的是12 但是页面上显示的是21 因为我们的映射关系是: {0x31: '2', 0x32: '1'} 这里简写了 # 根据字体加载的原理首先 html中的字符为 12 ==> 会将 1 转换成 Unicode 0x31 ==> 找到字体中的映射 对应的是 2 所以画出来的是2 # 根据字体加载的原理首先 html中的字符为 12 ==> 会将 2 转换成 Unicode 0x32 ==> 找到字体中的映射 对应的是 1 所以画出来的是1 # 如果页面上想要显示 123456@qq.com # 那我们就要想了? 什么东西镶嵌在html中 然后经过字体的渲染能变成 ==> 123456@qq.com # 那现在我们有了 123456@qq.com 首先我们要知道每个字符他现在对应的unicode值是啥? 然后现在的unicode值原始对应的字符是啥? # 这样我们就通过 unicode值 对我们要显示的字符和原始字符进行了关联 # 那么当我们在html中嵌入原始字符时,浏览器渲染就会拿到原始字符对应的unicode值,那通过现在的映射关系unicode值就能对上要显示的字符 # 举例: @,新的关系中 @对应的unicode值为82,那么我们就要求出unicode值为82的原始字符 # 结果unicode值为82的原始字符为 'R',那么当我们在html中嵌入R字符时, # 浏览器 R==> 找到unicode码点,82 ==> 然后从字体中找 82码点对应的是 @ 那么页面上就显示出了我们想要的@ # 但是爬虫工程师从源码中拿到的确实 R字符 new_cmap_str = map_string(input_str, new_cmap) print(new_cmap_str) # 用新的映射替换掉原始映射 update_cmap_table(font, new_cmap) font.save('test.ttf') if __name__ == '__main__': main()html:
html<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>Title</title> <style> @font-face { font-family: 'MyFont'; src: url("test.ttf") format("truetype"); font-weight: normal; font-style: normal; } #test{ font-family: "MyFont", Arial, sans-serif; font-size: 100px; } </style> </head> <body> <div id="test">bCQYDuwffXkW1</div> </body> </html>页面上显示的为:
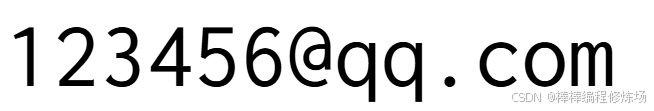
后续你还可以随机修改字体每个 glyph 的坐标。利用 TTGlyphPen 重新生成字形路径。对特殊 glyph (.null, .notdef, nonbreakingspace) 不处理。作用: 增加字体随机性,防止被 OCR 精确识别。改变视觉形态但不影响字体合法性。
python
from fontTools.pens.ttGlyphPen import TTGlyphPen
def modify_glyph_coordinates(font):
glyf_table = font['glyf']
# 修改字型的坐标
for glyph_name in font.getGlyphOrder():
if glyph_name in [".null", ".null#1", "nonbreakingspace", ".notdef"]:
continue
glyph = glyf_table[glyph_name]
new_coordinates = [(x, y + random.randint(-1, 1)) for x, y in glyph.coordinates]
pen = TTGlyphPen(glyf_table)
pen.moveTo(new_coordinates[0])
for coord in new_coordinates[1:]:
pen.lineTo(coord)
pen.closePath()
glyf_table[glyph_name] = pen.glyph()
# 测试: 修改字体文件的坐标
modify_glyph_coordinates(font) 还可以递归删除 XML 中的注释。作用: 清理 XML 文件,防止注释暴露字体信息或增加冗余。
python
import xml.etree.ElementTree as ET
def remove_xml_comments(root):
# 递归删除所有的注释
for element in list(root):
if isinstance(element.tag, str) and element.tag == 'comment':
root.remove(element)
else:
remove_xml_comments(element)将 XML 中的 glyph 名称替换为数字索引。replace_list 包含字母、数字、符号及其名称。
python
def modify_xml_mapping(xml_bytesIO):
replace_list = ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J', 'K', 'L', 'M', 'N', 'O', 'P', 'Q', 'R', 'S', 'T',
'U', 'V', 'W', 'X', 'Y', 'Z', 'a', 'at', 'b', 'c', 'd', 'e', 'eight', 'f', 'five', 'four', 'g', 'h',
'i', 'j', 'k', 'l', 'm', 'n', 'nine', 'nonbreakingspace', 'o', 'one', 'p', 'period', 'q', 'r', 's',
'seven', 'six', 't', 'three', 'two', 'u', 'v', 'w', 'x', 'y', 'z', 'zero']
xml_str = xml_bytesIO.read().decode("utf-8")
for num, char in enumerate(replace_list):
xml_str = xml_str.replace(f'name="{char}"', f'name="{num}"')
xml_bytesIO.seek(0)
xml_bytesIO.write(xml_str.encode())这个就不具体演示了。
五、绕过字体反爬实战
5.1 某眼案例
网站链接:aHR0cHM6Ly93d3cubWFveWFuLmNvbS9maWxtcz9zaG93VHlwZT0y
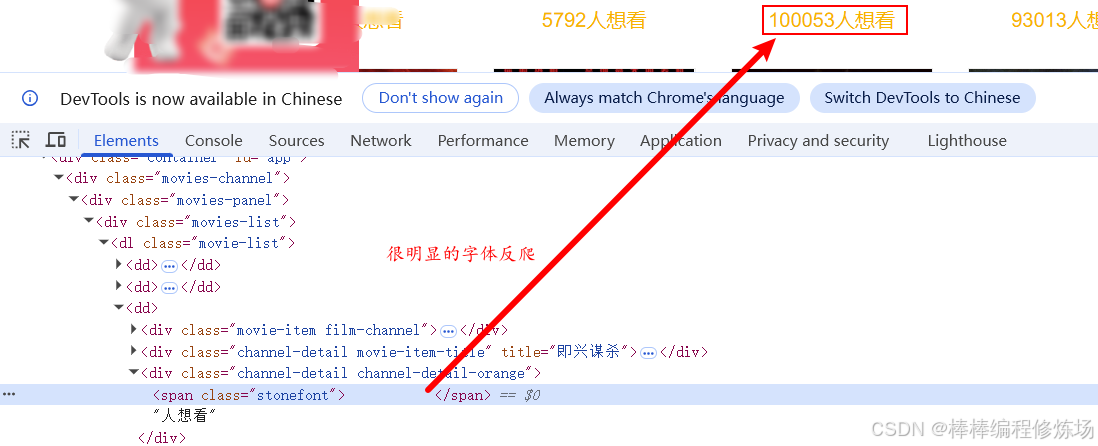
很明显,这是一起典型的字体反爬案例。在理解了原理之后,我们的第一步就是要 定位字体文件的来源 。因此,第一步我们要做的,就是 在页面中搜索字体文件的加载位置 ,判断它是内联的 Base64 数据,还是通过 URL 请求的字体文件。接下来,再去提取页面中显示的 "乱码字符",并结合字体的 cmap 映射关系,分析这些字符在字体文件中实际对应的内容。
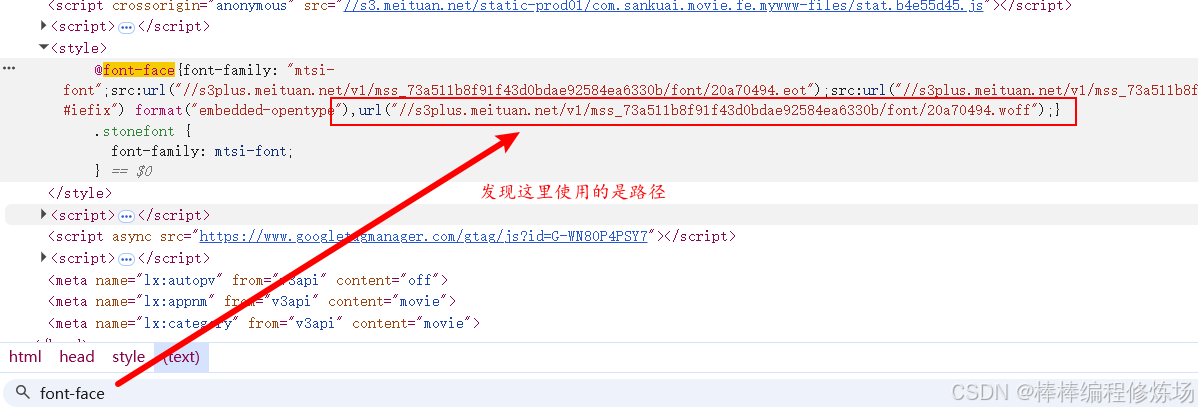
所以我们写一个请求把字体文件下载下来,放到在线工具中观察观察:
python
import requests
headers = {
'accept': '*/*',
'accept-language': 'zh-CN,zh;q=0.9',
'cache-control': 'no-cache',
'origin': 'https://www.maoyan.com',
'pragma': 'no-cache',
'priority': 'u=0',
'referer': 'https://www.maoyan.com/',
'sec-ch-ua': '"Google Chrome";v="141", "Not?A_Brand";v="8", "Chromium";v="141"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
'sec-fetch-dest': 'font',
'sec-fetch-mode': 'cors',
'sec-fetch-site': 'cross-site',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/141.0.0.0 Safari/537.36',
}
response = requests.get(
'https://s3plus.meituan.net/v1/mss_73a511b8f91f43d0bdae92584ea6330b/font/20a70494.woff',
headers=headers,
)
with open('maoyan.woff', 'wb') as f:
f.write(response.content)在线字体编辑器中查看:

接下来我们去看源码中返回的是什么:

这段  到底是什么?这其实是 HTML 实体编码(HTML Entity Encoding),
html
&#xXXXX;&#x 表示后面是一个十六进制 Unicode 编码。e99c 就是 16 进制的 Unicode 值。浏览器在渲染时,会将这个 Unicode 码当作一个字符去显示。如果字体文件(如 .ttf)中存在该码位对应的字形(glyph),浏览器就会使用该字体的绘制结果来展示。我们知道 Unicode 值(code)会通过字体文件的 cmap 表 映射到对应的字形名称(name)。例如:
xml
<map code="0xe99c" name="uniE99C"/>
<!--  这其实等价于下面的 Unicode 写法: uniE99C >
<!-- 或者在 Python / JavaScript 中常见的十六进制数值形式: 0xe99c>这意味着 Unicode 码 0xe99c 对应的字形是 uniE99C。其实结合字体在线编辑器,我们已经可以得出一个映射关系:
python
mapping = {
"uniEB92": 7,
"uniE8D7": 3,
"uniF7FF": 6,
"uniF85E": 1,
"uniE99C": 2,
"uniF1FC": 8,
"uniF726": 7,
"uniE8EE": 4,
"uniE9EA": 9,
"uniECDC": 5,
}但是这样的关系是写死的,如果字体是动态变化的,下次这样就不行了。所以此处介绍一种比较通用的方法,核心思路:**找到 code(Unicode 值) → 找到对应 name → 定位 TTGlyph → 绘制图像 → 识别出真实字符。**详细步骤如下:
-
提取字体文件(Base64 或 URL): 从接口或网页源码中拿到字体文件(如
b64Font或.ttf链接)。 -
解析 cmap 映射表: 使用
fontTools提取cmap表,获得所有code → name的对应关系。 -
根据 name 定位字形(TTGlyph): 每个字形(glyph)包含绘图轮廓坐标数据(
xMin,yMin,contours等)。 -
渲染字形为图像: 利用
PIL.ImageFont或直接用fontTools将字形绘制为图像。 -
OCR 识别真实内容: 使用 OCR(如
ddddocr)识别每个字形对应的真实字符。 -
建立反向映射关系表: 将识别出的真实字符与 Unicode 值(或字形名)建立映射,例如:
python{0xe99c: '3', 0xecdc: '7', ...} -
替换网页源码中的 Unicode: 最终,将网页源码中的
&#x****;批量替换为识别出的真实内容,就能还原出正确的数据。
具体代码实现如下:
① 提取字体文件(Base64 或 URL):
python
import re
import requests
cookies = {
# 写你自己的cookie
}
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36'
' (KHTML, like Gecko) Chrome/141.0.0.0 Safari/537.36',
}
params = {
'showType': '2',
'offset': '18',
}
response = requests.get('https://www.maoyan.com/films', params=params,
cookies=cookies,
headers=headers)
# url("//s3plus.meituan.net/v1/mss_73a511b8f91f43d0bdae92584ea6330b/font/432017e7.woff")
# url("//s3plus.meituan.net/v1/mss_73a511b8f91f43d0bdae92584ea6330b/font/20a70494.woff")
# 每次返回的字体文件都不一样 所以我们要提取 建立动态的映射关系
font_url = 'https:' + re.findall(r'url\(["\']?(//[^"\')]+\.woff)["\']?\)', response.text)[0]
font_res = requests.get(url=font_url, headers=headers)
with open('my.woff', 'wb') as f:
f.write(font_res.content)② 步骤 2 - 6:
python
from fontTools.ttLib import TTFont
import ddddocr
from io import BytesIO
from PIL import Image, ImageDraw, ImageFont
if not hasattr(Image, 'ANTIALIAS'): # 新版本没有这个属性
Image.ANTIALIAS = Image.Resampling.LANCZOS
def convert_cmap_to_image(cmap_code, font_path):
"""
:param cmap_code: 字体的 Unicode 码点(整数,例如 0x41 表示 'A')
:param font_path: 字体文件路径(如 "my.woff")
:return: 返回绘制好的 PIL.Image 图像对象
"""
img_size = 1024 # 设置图片尺寸为 1024×1024 像素
# 准备三要素: image画布 draw画笔 font字体
# 创建一张空白图片(画布)"1": 表示黑白图像(1位深度,即只有黑白两色)
# (img_size, img_size): 大小为 1024×1024
# 255:表示白色背景(在"1"模式下,0是黑,255是白)
img = Image.new("1", (img_size, img_size), 255) # 创建一个黑白图像对象
# 画笔: 这里的 draw(画笔) 是"绑定"在 img(画布)上的
# 画笔需要知道要画到哪张纸上,否则它没法落笔
draw = ImageDraw.Draw(img) # 创建绘图对象
# 字体(ImageFont): 是你手中的 "书法笔",控制文字的样式
font = ImageFont.truetype(font_path, img_size) # 加载字体文件
# 将 cmap code 转换为字符
character = chr(cmap_code)
# print("character: ",character) # 这里只能传 character
bbox = draw.textbbox((0, 0), character, font=font) # 获取文本在图像中的边界框
# 返回一个 四元组 (x_min, y_min, x_max, y_max),代表文字区域的左上角和右下角坐标
# bbox = (200, 100, 824, 900)
# 左上角坐标(200, 100) 右下角坐标(824, 900)
# 宽度 = 824 - 200 = 624 高度 = 900 - 100 = 800
print(bbox)
width = bbox[2] - bbox[0] # 文本的宽度
height = bbox[3] - bbox[1] # 文本的高度
# 正式开始写字了
draw.text(((img_size - width) // 2, (img_size - height) // 2), character, font=font) # 绘制文本,并居中显示
return img
def extract_text_from_font(font_path):
font = TTFont(font_path) # 加载字体文件
# 图像识别的模块: DdddOcr
ocr = ddddocr.DdddOcr() # 实例化 ddddocr 对象
# 获取映射关系
# (120, 'x'), (59455, 'uniE83F'), (59487, 'uniE85F'), (59670, 'uniE916'), (60751, 'uniED4F').....
print("font.getBestCmap().items(): ", font.getBestCmap().items())
font_map = {} # 最后要返回的映射字典
# TODO 1.解析 cmap 映射表
for cmap_code, glyph_name in font.getBestCmap().items():
# TODO 2.定位字形并渲染字形为图像
image = convert_cmap_to_image(cmap_code, font_path)
# TODO 3.OCR识别真实内容
bytes_io = BytesIO()
image.save(bytes_io, "PNG")
text = ocr.classification(bytes_io.getvalue()) # 图像识别
# TODO 4.建立反向映射关系表
font_map[glyph_name] = text
return font_map
if __name__ == '__main__':
# 测试
font_file_path = "my.woff"
# {'x': '', 'uniE83F': '8', 'uniE85F': '3', 'uniE916': '7', 'uniED4F': '5', 'uniED98': '9',
# 'uniEDBA': '1', 'uniEFE9': '4', 'uniF0F0': '2', 'uniF70E': '6', 'uniF7B3': '0'}
print(extract_text_from_font(font_file_path))③ 替换:
python
def main():
for offset in range(0, 90, 18):
params = {'showType': '2','offset': offset,}
response = requests.get('https://www.maoyan.com/films', params=params,
cookies=cookies,
headers=headers)
text = response.text # 网页源码
# TODO 1.动态解析字体
font_url = 'https:' + re.findall(r'url\(["\']?(//[^"\')]+\.woff)["\']?\)', text)[0]
font_res = requests.get(url=font_url, headers=headers)
font_file_path = 'my.woff'
with open(font_file_path, 'wb') as f:
f.write(font_res.content)
# TODO 2.建立映射关系
font_map = extract_text_from_font(font_file_path)
print(font_map)
for k, v in font_map.items():
key = k.lower().replace('uni', '&#x')
if key in text:
text = text.replace(key + ';', v)
# TODO 3.解析数据
selector = Selector(text=text)
dd_list = selector.xpath('//dl[@class="movie-list"]//dd')
for dd in dd_list:
title = dd.xpath('./div[@class="channel-detail movie-item-title"]/@title').extract_first('')
people_watch = ''.join(dd.xpath('./div[@class="channel-detail channel-detail-orange"]//text()').extract())
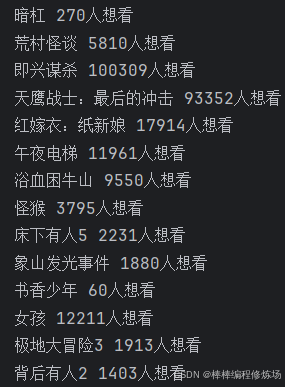
print(title, people_watch)
print("-------------------------------------------------------")测试,与网页上的一致,如下图所示:
5.2 某职案例
网站链接:aHR0cDovL3NoYW56aGkuc3BiZWVuLmNvbS8=
简单看一下:
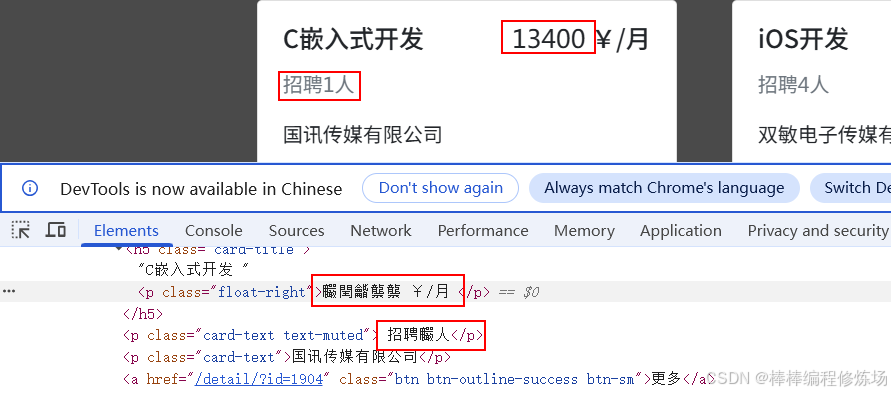
同理看一下页面的源码:

按照 2.4.1 某眼案例 的步骤固定操作,发现返回的映射是这个样子的:

发现这玩意不是 Unicode 形式,那么此处我们就需要灵活变通一下,在 extract_text_from_font 函数中,最后返回的字典映射:
python
# TODO 4.建立反向映射关系表
# 是通过glyph_name设置的键,glyph_name是unicode值形式,所以很方便和我们的源码对应起来
# 但是此处是 glyph00006, glyph00004,所以需要更改一下逻辑
font_map[glyph_name] = text
# 那么我就用 cmap_code 我们之前在研究字体xml文件的时候,其实知道 code也是一个十六进制 只不过是0x开头
# <map code="0x39" name="W"/>
# python中的常用形式,那么我们这里就可以直接用hex()函数将Unicode码值转换为十六进制形式
font_map[hex(cmap_code)] = text执行:

这样就能和源码返回的对应上了,不过替换那里的逻辑需要改一下:

看一下替换后的源码,我这里就不去解析。测试了一下,它首页数据是动态变化的,观察比较麻烦,走它的搜索接口,在页面右上角搜索安卓开发,如下:
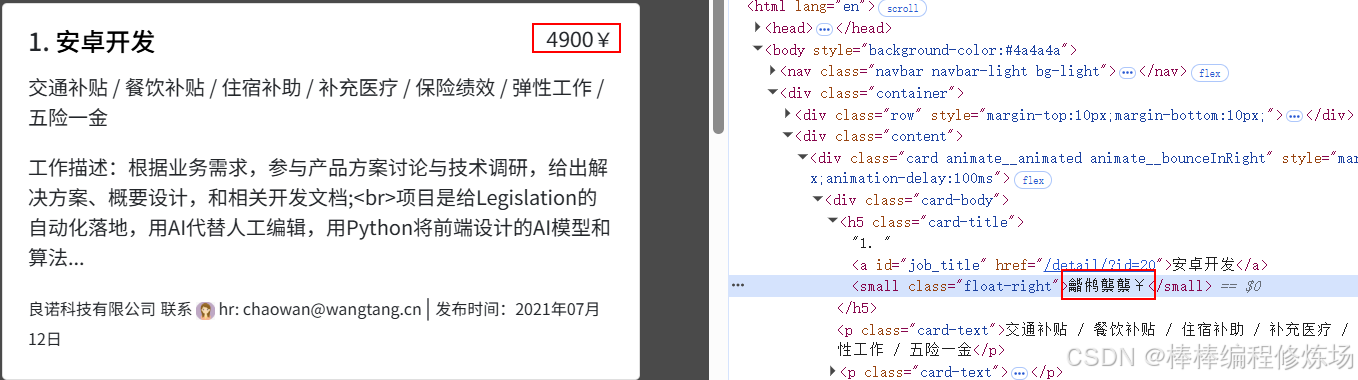
观察接口:
python
http://shanzhi.spbeen.com/api/search/?word=安卓开发&page=1&_=1761583798706
http://shanzhi.spbeen.com/api/search/?word=安卓开发&page=2&_=1761583798706稍微改一下请求的逻辑就好了,首页用来动态解析字体,但这个网站字体不是动态变化的,要替换的源码则是通过搜索接口返回的,上图的薪资解析正确,如下:

5.3 SpiderDemo第8题
https://blog.csdn.net/xw1680/article/details/153992358?spm=1011.2415.3001.5331