本系列教程路线图
本文是《从 0 到 1 打造情感陪伴智能体》系列的第四篇。若你还未阅读前几篇,建议先回顾它们,以便更好地理解本文内容。
| 篇章 | 功能 | 难度 |
|---|---|---|
| 1 | 整体介绍:背景 + 环境准备 + 设备上线 | ★ |
| 2 | 从"命令式控制"到"语义控制":MCP over MQTT 封装设备能力 | ★★ |
| 3 | 接入 LLM,实现"自然语言 → 设备控制" | ★★ |
| 4 | 语音 I/O:麦克风数据上传 + 语音识别 + 语音合成回放 | ★★★ |
| 5 | 人格、情感、记忆:从"控制器"到"陪伴体" | ★★★ |
| 6 | 给智能体增加"眼睛":图像采集 + 多模态理解 | ★★★ |
回顾:接入 LLM 实现「自然语言 → 设备控制」
在上一篇文章中,我们构建了从自然语言指令到设备控制调用的完整链路。通过集成大语言模型结合 MCP over MQTT 的通信协议,实现了设备智能体的雏形。这一智能体不仅能「理解」用户输入的文字,还能根据语义生成函数调用并作用于真实设备。然而,纯文本的交互方式在用户体验上仍存在局限,对用户来说并不直观和自然。
本期我们将实现交互方式的全面升级:通过集成语音识别(ASR)与语音合成(TTS)组件,构建完整的语音交互智能体,让用户可以通过语音方式直接与设备进行沟通。
本篇目标:让智能体能「听」能「说」
我们期望实现这样的场景:
- 你对着智能体说:"我今天有点累了"。
- ESP32 收集你的语音并上传到云端。
- AI 理解你的情感,生成关怀式的回应。
- 智能体用温柔的声音说:"辛苦了,要不要我为你放点轻柔的音乐?"
为此,我们将在原有架构的基础上,新增语音识别与语音合成组件,让智能体具备「听」和「说」的能力。
架构升级与实现路径
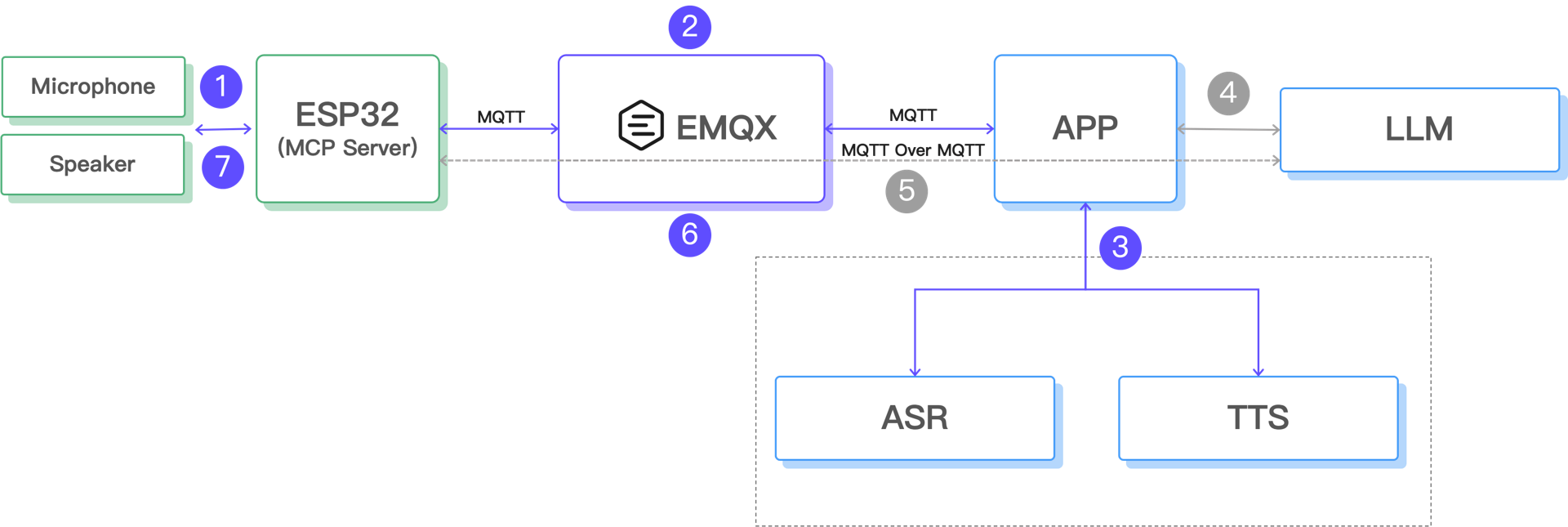
全新架构:新增语音识别(ASR)与语音合成(TTS)组件
- ESP32 调用麦克风模块,录制用户语音,生成本地音频文件;
- ESP32 通过 MQTT 协议把音频数据上传至云端,由 EMQX 数据桥接到 Web Hook,然后由 App 处理;
- App 将音频文件发送至 ASR(语音识别)+ TTS(语音合成服务),生成回复语音;
- 识别出的文本被传送给大语言模型(LLM)
- LLM 理解上下文语义并通过 MCP Over MQTT 调用部署在 ESP32 上的工具,实现设备控制;
- App 将生成的语音压缩为 MP3 格式,编码为 Base64 格式后,再次通过 MQTT 将文件下发至 ESP32;
- ESP32 播放音频文件,实现完整的语音交互闭环。
这种架构充分发挥了 MQTT 在物联网场景下的轻量通信优势,同时借助云端强大的 LLM、ASR 和 TTS 能力,为终端设备提供了自然、上下文感知的语音交互体验。ESP32 保持设备轻量化,只负责音频采集与播放,核心处理任务则由云端完成,从而兼顾了性能与成本。
由于在上一篇文章中已经实现了通过 MCP 协议控制终端设备的能力(上述架构图中的步骤 4 和 5 ),我们本篇文章的主要精力放在语音处理上。
ESP32:智能语音采集
硬件配置
我们需要配置两套 I2S 接口,一套用于录音,一套用于播放。
录音配置(I2S_NUM_0):
c
// 录音引脚配置
#define I2S_REC_BCLK 7 // 时钟信号
#define I2S_REC_LRCL 8 // 左右声道切换
#define I2S_REC_DOUT 9 // 数据输入
// 录音参数
#define I2S_SAMPLE_RATE 8000 // 8kHz采样率,适合语音
#define I2S_SAMPLE_BITS 16 // 16位深度
#define I2S_CHANNEL_NUM 1 // 单声道
#define RECORD_SECONDS 3 // 录音3秒播放配置(I2S_NUM_1):
c
// 播放引脚配置
#define I2S_PLAY_BCLK 2 // 时钟信号
#define I2S_PLAY_LRCL 1 // 左右声道切换
#define I2S_PLAY_DOUT 42 // 数据输出智能语音检测算法
问题的关键在于如何让 ESP32 知道什么时候该开始录音,既要节省设备电量,也要确保录音的完整性。
语音能量检测:
c
uint32_t calculateAudioEnergy(int16_t *samples, size_t count) {
uint64_t sum = 0;
for (size_t i = 0; i < count; i++) {
int32_t s = samples[i];
sum += (uint64_t)(s * s); // 计算音频能量
}
return (uint32_t)(sum / count);
}防误触机制:
c
// 滑动平均过滤噪音
static uint32_t energyHistory[5] = {0, 0, 0, 0, 0};
static int historyIndex = 0;
// 需要至少3个样本都超过阈值才触发录音
int highEnergyCount = 0;
for (int i = 0; i < 5; i++) {
if (energyHistory[i] > ENERGY_THRESHOLD) {
highEnergyCount++;
}
}
if (highEnergyCount >= 3 && avgEnergy > ENERGY_THRESHOLD) {
Serial.println("检测到语音,开始录音!");
performRecording();
}状态机管理
为了避免录音和播放冲突,我们用状态机来管理:
c
enum SystemState {
STATE_IDLE, // 空闲状态(监听语音)
STATE_RECORDING, // 正在录音
STATE_PLAYING, // 正在播放
STATE_COOLDOWN // 播放后冷却期
};防回声循环:
- 播放语音后进入冷却期(3秒)。
- 清空音频缓冲区,避免把回放的声音当成新的语音指令。
- 连续录音限制,避免无限循环对话。
音频数据上传
录音完成后,ESP32 会生成标准的 WAV 文件并通过 MQTT 上传:
c
// 构建 WAV 文件头
typedef struct WAVHeader {
char riff_header[4]; // "RIFF"
uint32_t wav_size; // 文件大小
char wave_header[4]; // "WAVE"
char fmt_header[4]; // "fmt "
uint32_t fmt_chunk_size; // 格式块大小
uint16_t audio_format; // 音频格式(1=PCM)
uint16_t num_channels; // 声道数
uint32_t sample_rate; // 采样率
uint32_t byte_rate; // 字节率
uint16_t block_align; // 块对齐
uint16_t bits_per_sample; // 位深度
char data_header[4]; // "data"
uint32_t data_bytes; // 数据大小
} WAVHeader;
// 通过 MQTT 发送音频
mqtt_client.publish("emqx/esp32/audio", wav_buffer, wav_size);Python:AI 情感处理
服务架构
我们用 FastAPI 构建了异步的音频处理服务:
python
from fastapi import FastAPI, HTTPException, BackgroundTasks
from openai import AsyncOpenAI
import base64
import lameenc
import numpy as np
app = FastAPI(title="语音情感助手API", version="1.0.0")
# 通义千问客户端
openai_client = AsyncOpenAI(
api_key="your-dashscope-api-key",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1"
)情感提示词设计
这是让 AI 理解情感的关键:
OPENAI_PROMPT = """
在这个会话中,您将作为简单的情感助手,依据我提供的语音,生成精简回复。
请注意回复不能超过 20 个字符并且回复的内容应当是对语音内容的情感分析或回应。
"""为什么限制 20 字?
- 让回应更精准,避免啰嗦
- 减少语音合成和传输时间
- 更符合情感陪伴的温暖简洁风格
多模态 AI 调用
这是整个系统的核心,直接用语音输入生成语音输出:
python
async def call_qwen_ai_generate_audio(base64_audio: str) -> bytes:
completion = await openai_client.chat.completions.create(
model="qwen-omni-turbo", # 多模态模型
messages=[
{
"role": "user",
"content": [
{
"type": "input_audio",
"input_audio": {
"data": f"data:;base64,{base64_audio}",
"format": "wav",
},
},
{
"type": "text",
"text": "作为情感助手,用不超过20字回应用户的情感需求"
}
],
}
],
modalities=["text", "audio"], # 同时输出文本和音频
audio={"voice": "Cherry", "format": "wav"}, # 使用 Cherry 音色
stream=True, # 流式处理
stream_options={"include_usage": True}
)
# 接收流式响应
text_string = ""
audio_string = ""
async for chunk in completion:
if not chunk.choices:
continue
if hasattr(chunk.choices[0].delta, "audio"):
audio_string += chunk.choices[0].delta.audio["data"]
elif hasattr(chunk.choices[0].delta, "content"):
text_string += chunk.choices[0].delta.content
# 返回音频数据
decoded_audio = base64.b64decode(audio_string)
return decoded_audio这种方式的优势:
- 端到端处理:语音直接到语音,保持情感连贯性
- 理解更准确:AI 能听出语调、情绪,不只是文字内容
- 回应更自然:生成的语音带有合适的情感色彩
音频格式优化
AI 生成的是 WAV 格式,文件比较大,我们转成 MP3 压缩:
python
def convert_audio_to_mp3(decoded_audio: bytes, output_file: str):
audio_np = np.frombuffer(decoded_audio, dtype=np.int16)
encoder = lameenc.Encoder()
encoder.set_bit_rate(32) # 低码率,减少传输量
encoder.set_in_sample_rate(24000)
encoder.set_channels(1)
encoder.set_quality(7) # 平衡质量与大小
mp3_data = encoder.encode(audio_np.tobytes())
mp3_data += encoder.flush()
# 保存文件并返回 Base64
with open(output_file, 'wb') as f:
f.write(mp3_data)
return base64.b64encode(mp3_data).decode()异步处理流程
为了不阻塞 API 响应,我们用后台任务处理:
python
@app.post("/process_audio")
async def process_audio(request: AudioRequest, background_tasks: BackgroundTasks):
task_id = str(uuid.uuid4())
# 添加后台任务
background_tasks.add_task(
process_audio_task,
request.audio,
task_id
)
return AudioResponse(
success=True,
message="音频处理任务已启动"
)
async def process_audio_task(base64_audio: str, task_id: str):
try:
# 1. 调用 AI 生成语音回应
decoded_audio = await call_qwen_ai_generate_audio(base64_audio)
# 2. 转换为 MP3 格式
output_file = f"audio_response_{task_id}.mp3"
base64_mp3_audio = convert_audio_to_mp3(decoded_audio, output_file)
# 3. 通过 MQTT 发送给 ESP32
await publish_to_mqtt(base64_mp3_audio)
except Exception as e:
logger.error(f"处理音频任务异常: {e}")EMQX:消息代理
Topic 设计
emqx/esp32/audio → ESP32 上传录音
emqx/esp32/playaudio → 下发播放音频Webhook 配置
在 EMQX 控制台配置 Webhook 规则,当收到音频消息时自动转发给 Python 服务:
json
{
"url": "http://your-server:5005/process_audio",
"method": "POST",
"headers": {
"Content-Type": "application/json"
},
"body": {
"audio": "${payload}"
}
}系统部署与配置流程
环境准备
Python 依赖:
pip install fastapi uvicorn httpx lameenc numpy openai pydanticESP32 库依赖:
- WiFi:网络连接
- PubSubClient:MQTT 客户端
- SPIFFS:文件系统(存储临时音频文件)
- ESP32Audio:音频编解码库
配置流程
-
获取通义千问 API Key
- 登录阿里云控制台。
- 开通 DashScope 服务。
- 获取 API Key。
-
配置 EMQX
- 创建设备认证信息。
- 配置 Webhook 规则。
- 设置消息路由。
-
ESP32 配置
c// WiFi 配置 const char *ssid = "your-wifi-name"; const char *password = "your-wifi-password"; // MQTT 配置 const char *mqtt_broker = "broker.emqx.io"; const char *mqtt_username = "emqx"; const char *mqtt_password = "public"; -
Python 服务配置
python# API 配置 openai_client = AsyncOpenAI( api_key="your-dashscope-api-key", base_url="https://dashscope.aliyuncs.com/compatible-mode/v1" ) # EMQX 配置 EMQX_HTTP_API_URL = "http://127.0.0.1:18083" EMQX_USERNAME = "your-username" EMQX_PASSWORD = "your-password"
实测效果与性能表现
示例对话场景
场景一:情感安慰
- 用户(疲惫的语调):"我今天工作好累啊..."
- AI回应(温柔):"辛苦你了,要好好休息哦"
场景二:日常聊天
- 用户(开心):"今天天气真不错!"
- AI回应(活泼):"是呀,心情也变好了呢"
场景三:寻求建议
- 用户(犹豫):"我不知道该怎么办..."
- AI回应(鼓励):"慢慢来,我们一起想想"
性能表现
响应时间:
- 语音检测:实时(<100ms)
- AI处理:1-2 秒
- 音频下发:< 500ms
- 总延迟:约 3 秒内完成整个交互
音质表现:
- Cherry 音色自然温暖
- MP3 32kbps 音质清晰
- 支持情感语调变化
现存问题与解决方案
在实际测试中,我们遇到了几个典型问题:
- 回声循环:ESP32 会把自己播放的声音再次录入,形成无限回放。
我们在播放后增加了 3 秒冷却期,并在每次播放结束后清空 I2S 缓冲区,同时限制连续录音的次数,防止循环放大。
- 录音误触:环境噪音或空调声导致设备频繁启动录音。
我们通过提高能量阈值、加入滑动平均过滤,以及采用多样本确认机制,有效降低了误触发的概率。
- 网络断线:WiFi 不稳定时会导致 MQTT 连接中断。
为保证系统稳定运行,我们实现了自动重连机制、心跳检测和连接状态监控,确保设备在网络波动下依然能够可靠工作。
语音交互的局限与优化
局限性
该方案结构清晰、部署便捷,并充分利用了 MQTT 的稳定传输能力,但由于交互模式的批处理特性,仍存在很多明显的局限:
批处理模式导致高延迟
- 语音采集、LLM 推理、TTS 合成、音频播放必须串行执行,用户需等待整个流程结束。
- 长语音输入或复杂语义解析时,交互延迟会显著增加。
缺乏流式交互能力
- ASR 需完整录音后才开始转写,无法实时逐句识别。
- TTS 必须等待全部文本就绪才生成语音,无法边合成边播放。
- 音频传输依赖完整文件下发,无法实现流式传输。
固定录音时长限制
- 3 秒时长可能导致长句被截断。
- 短句场景下存在无效等待,降低交互效率。
这些因素都限制了方案在生产环境中的实际可用性,与日常智能语音助手的「边说边听、边合成边播放」的体验有明显差距。
优化方向
为了提升语音指令、响应速度和语音交互的自然性,可以从以下几个方向进行优化:
- 动态录音时长:检测到语音结束自动停止录音;
- VAD(Voice Activity Detection):更准确的语音端点检测;
- 音频质量优化:降噪、增强等预处理;
- ASR 实时语音识别(流式转写);
- TTS 音频实时生成与播放;
- MQTT 与 RTP 可协同工作:MQTT 负责可靠的指令和状态交互,RTP 则用于快速传输音频流,使智能体更贴近「实时对话」的体验标准。
下篇预告
在本篇中,我们实现了从自然语言识别到设备播放语音的闭环。然而,一个真正的「智能」体,不止于一般的响应,它还应该懂你、记得你、陪伴你。
下一篇我们将探讨:
- 如何引入「情感」和「人格」机制:让设备不只是冰冷的指令执行器,而具备温度、风格与情绪表达;
- 如何让设备「有记忆」:保留用户上下文、偏好和使用习惯,实现个性化长期记忆;
- 如何结合 LLM 构建人格化代理体:在长期互动中,逐渐演化成「懂你」的数字伙伴。
此外,我们也将讨论不同类型的人设设计,如:安静助理、热情伙伴、严肃专家等,并分析人设如何影响交互体验与应用场景适配。这将是从「设备控制、交互智能体」走向「人格化智能体」的关键一步。敬请期待。
资源
- 源代码 - https://github.com/mqtt-ai/esp32-mcp-mqtt-tutorial/tree/main/samples/blog_4 ,包含:
- ESP32 完整工程文件
- Python 后端服务源码
- EMQX 配置说明
- 部署运行文档
- 通义千问:模型服务灵积 DashScope