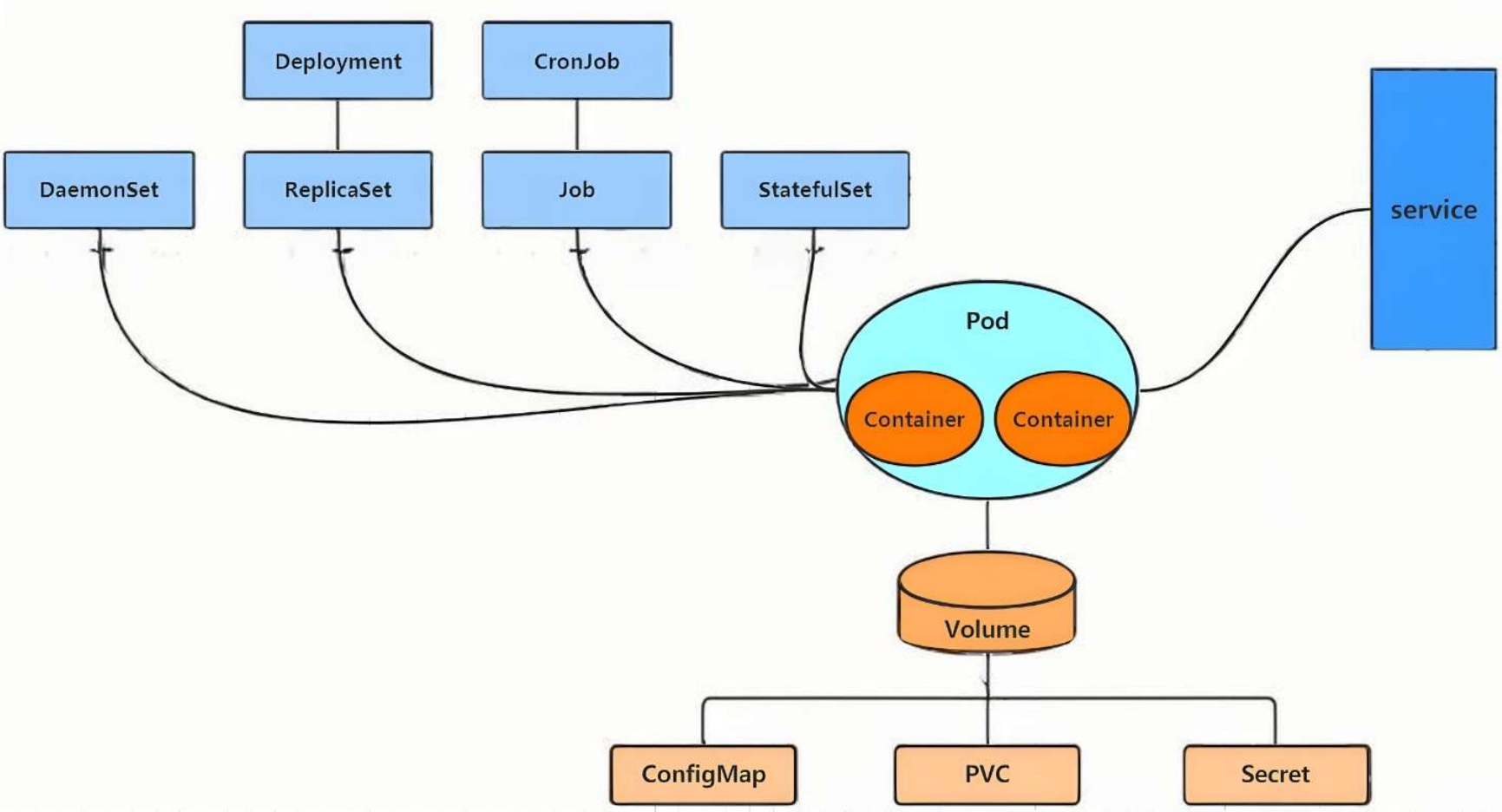
一 什么是微服务
用控制器来完成集群的工作负载,那么应用如何暴漏出去?需要通过微服务暴漏出去后才能被访问
- Service是一组提供相同服务的Pod对外开放的接口。
- 借助Service,应用可以实现服务发现和负载均衡。
- service默认只支持4层负载均衡能力,没有7层功能。(可以通过Ingress实现)
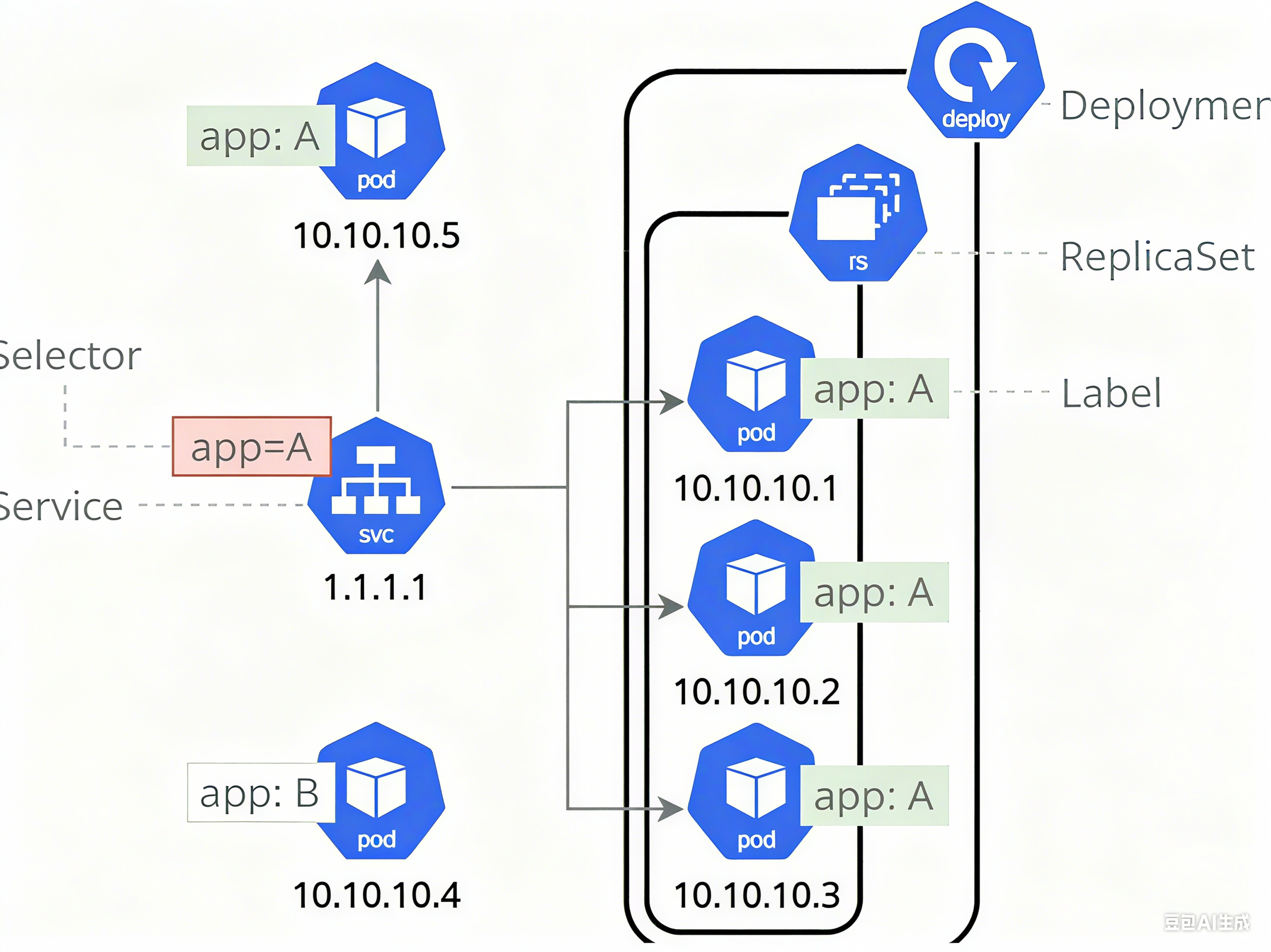
二 微服务的类型
| 微服务类型 | 作用描述 |
|---|---|
| ClusterIP | 默认值,k8s系统给service自动分配的虚拟IP,只能在集群内部访问 |
| NodePort | 将Service通过指定的Node上的端口暴露给外部,访问任意一个NodeIP:nodePort都将路由到ClusterIP |
| LoadBalancer | 在NodePort的基础上,借助cloud provider创建一个外部的负载均衡器,并将请求转发到 NodeIP:NodePort,此模式只能在云服务器上使用 |
| ExternalName | 将服务通过 DNS CNAME 记录方式转发到指定的域名(通过 spec.externlName 设定 |
思路:先建个目录放配置文件,然后生成两个不同版本应用(v1 和 v2)的部署配置,再用配置文件实际创建这两个应用的 Pod。最后检查一下,确认 Pod 都跑起来了,为后续创建 Service 做准备。
示例:
bash
# 创建service目录并进入,用于存放相关配置文件
[root@master ~]# mkdir service
[root@master ~]# cd service/
# 创建myappv1的Deployment配置文件,--dry-run=client表示仅模拟创建不实际执行,-o yaml输出为YAML格式
# --image指定镜像为myapp:v1,--replicas 2表示创建2个pod
[root@master service]# kubectl create deployment myappv1 --image myapp:v1 --replicas 2 --dry-run=client -o yaml > myappv1.yml
# 同理创建myappv2的Deployment配置文件,镜像为myapp:v2,2个pod
[root@master service]# kubectl create deployment myappv2 --image myapp:v2 --replicas 2 --dry-run=client -o yaml > myappv2.yml
[root@master service]# cat myappv1.yml
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: myappv1
name: myappv1
spec:
replicas: 2
selector:
matchLabels:
app: myappv1
template:
metadata:
labels:
app: myappv1
spec:
containers:
- image: myapp:v1
name: myappv1
# 结构与myappv1类似,仅标签和镜像不同
[root@master service]# cat myappv2.yml
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: myappv2
name: myappv2
spec:
replicas: 2
selector:
matchLabels:
app: myappv2
template:
metadata:
labels:
app: myappv2
spec:
containers:
- image: myapp:v2
name: myappv2
[root@master service]# kubectl apply -f myappv1.yml
deployment.apps/myappv1 created
[root@master service]# kubectl apply -f myappv2.yml
deployment.apps/myappv2 created
[root@master service]# kubectl get pods
NAME READY STATUS RESTARTS AGE
myappv1-5c47495d84-7wf98 1/1 Running 0 22s
myappv1-5c47495d84-blzwb 1/1 Running 0 22s
myappv2-67cc8c4845-fjszn 1/1 Running 0 19s
myappv2-67cc8c4845-tdnk9 1/1 Running 0 19s
[root@master service]# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 11d
[root@master service]# kubectl get deployments.apps
NAME READY UP-TO-DATE AVAILABLE AGE
myappv1 2/2 2 2 38s
myappv2 2/2 2 2 35s微服务默认使用iptables调度
bash
# 基于myappv1的Deployment创建ClusterIP类型的Service配置文件
# --port 80表示Service暴露的端口,--target-port 80表示Pod的目标端口
[root@master service]# kubectl expose deployment myappv1 --port 80 --target-port 80 --dry-run=client -o yaml > clusterip.yml
[root@master service]# cat clusterip.yml
apiVersion: v1 # API版本
kind: Service # 资源类型为Service
metadata:
labels:
app: myappv1 # 标签,与Deployment对应
name: myappv1 # Service名称
spec:
ports:
- port: 80 # Service对外暴露的端口
protocol: TCP # 协议为TCP
targetPort: 80 # 目标Pod的端口
selector: # 选择器,匹配标签为app:myappv1的Pod
app: myappv1
[root@master service]# kubectl apply -f clusterip.yml
service/myappv1 created
[root@master service]# kubectl get svc -o wide
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 11d <none>
myappv1 ClusterIP 10.102.136.32 <none> 80/TCP 9s app=myappv1
# 访问Service的ClusterIP,返回第一个Pod的主机名,说明负载均衡生效(轮询策略)
[root@master service]# curl 10.102.136.32/hostname.html
myappv1-5c47495d84-blzwb
# 再次访问,返回第二个Pod的主机名,验证轮询效果
[root@master service]# curl 10.102.136.32/hostname.html
myappv1-5c47495d84-7wf98
# 查看iptables规则,确认Service通过iptables实现负载均衡(匹配Service的ClusterIP和端口)
[root@master service]# iptables -t nat -nL | grep 10.102.136.32
KUBE-SVC-C6HG6NJSMLJLBPCV tcp -- 0.0.0.0/0 10.102.136.32 /* default/myappv1 cluster IP */ tcp dpt:80
KUBE-MARK-MASQ tcp -- !10.244.0.0/16 10.102.136.32 /* default/myappv1 cluster IP */ tcp dpt:80三 ipvs 模式
K8s 中Service的负载均衡有两种底层实现:iptables 和ipvs(IP Virtual Server)。
ipvs是 Linux 内核的负载均衡器,相比iptables,它在大并发、大规模集群场景下性能更优,支持更丰富的调度算法(如轮询、加权轮询、最小连接等)。- Service 是由 kube-proxy 组件,加上 iptables 来共同实现的
- kube-proxy 通过 iptables 处理 Service 的过程,需要在宿主机上设置相当多的 iptables 规则,如果宿主机有大量的Pod,不断刷新iptables规则,会消耗大量的CPU资源
- IPVS模式的service,可以使K8s集群支持更多量级的Pod
3.1 ipvs 模式配置方式
需确保 K8s 的kube-proxy组件启用 ipvs 模式:
- 修改
kube-proxy的配置文件,将mode字段设置为ipvs; - 重启
kube-proxy组件,使其基于 ipvs 规则为Service提供负载均衡。
示例:
1 在所有节点中安装ipvsadm
bash
[root@master service]# yum install ipvsadm --y2 修改master节点的代理配置
bash
[root@master service]# kubectl -n kube-system edit cm kube-proxy
58 metricsBindAddress: ""
59 mode: "ipvs"
60 nftables:3 重启kube-proxy组件pod,在pod运行时配置文件中采用默认配置,当改变配置文件后已经运行的pod状态不会变化,所以要重启pod
bash
# 查找所有kube-proxy的Pod并删除,K8s会自动重建新的Pod应用新配置
[root@master service]# kubectl -n kube-system get pods | awk '/kube-proxy/{system("kubectl -n kube-system delete pods "$1)}'
pod "kube-proxy-b7442" deleted
pod "kube-proxy-d8hbj" deleted
pod "kube-proxy-vrpbk" deleted
# 查看ipvs规则,确认Service通过ipvs实现负载均衡(包含各Service的IP、端口及后端Pod)
[root@master service]# ipvsadm -Ln
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 10.96.0.1:443 rr # kubernetes服务的ClusterIP和端口,轮询调度
-> 192.168.2.60:6443 Masq 1 0 0
TCP 10.96.0.10:53 rr # kube-dns服务的ClusterIP和端口
-> 10.244.1.2:53 Masq 1 0 0
-> 10.244.1.3:53 Masq 1 0 0
TCP 10.96.0.10:9153 rr
-> 10.244.1.2:9153 Masq 1 0 0
-> 10.244.1.3:9153 Masq 1 0 0
TCP 10.102.136.32:80 rr # myappv1服务的ClusterIP和端口,后端对应两个Pod
-> 10.244.1.4:80 Masq 1 0 0
-> 10.244.2.3:80 Masq 1 0 0
UDP 10.96.0.10:53 rr
-> 10.244.1.2:53 Masq 1 0 0
-> 10.244.1.3:53 Masq 1 0 0 !IMPORTANT
切换ipvs模式后,kube-proxy会在宿主机上添加一个虚拟网卡:kube-ipvs0,并分配所有service IP
bash[root@master service]# ip a show kube-ipvs0 5: kube-ipvs0: <BROADCAST,NOARP> mtu 1500 qdisc noop state DOWN group default link/ether c6:b8:af:ea:94:de brd ff:ff:ff:ff:ff:ff inet 10.96.0.10/32 scope global kube-ipvs0 valid_lft forever preferred_lft forever inet 10.96.0.1/32 scope global kube-ipvs0 valid_lft forever preferred_lft forever inet 10.102.136.32/32 scope global kube-ipvs0 valid_lft forever preferred_lft forever
**结果:**通过安装 ipvsadm 工具、修改 kube-proxy 配置为 ipvs 模式并重启组件,成功启用了 ipvs 作为 Service 的负载均衡底层实现。ipvs 规则中显示了各 Service 的调度策略和后端 Pod,且新增了 kube-ipvs0 虚拟网卡绑定所有 Service 的 IP。
四 微服务类型详解(K8s Service 类型)
Service是 K8s 中定义 "服务访问规则" 的核心资源,不同类型对应不同的访问场景:
4.1 ClusterIP
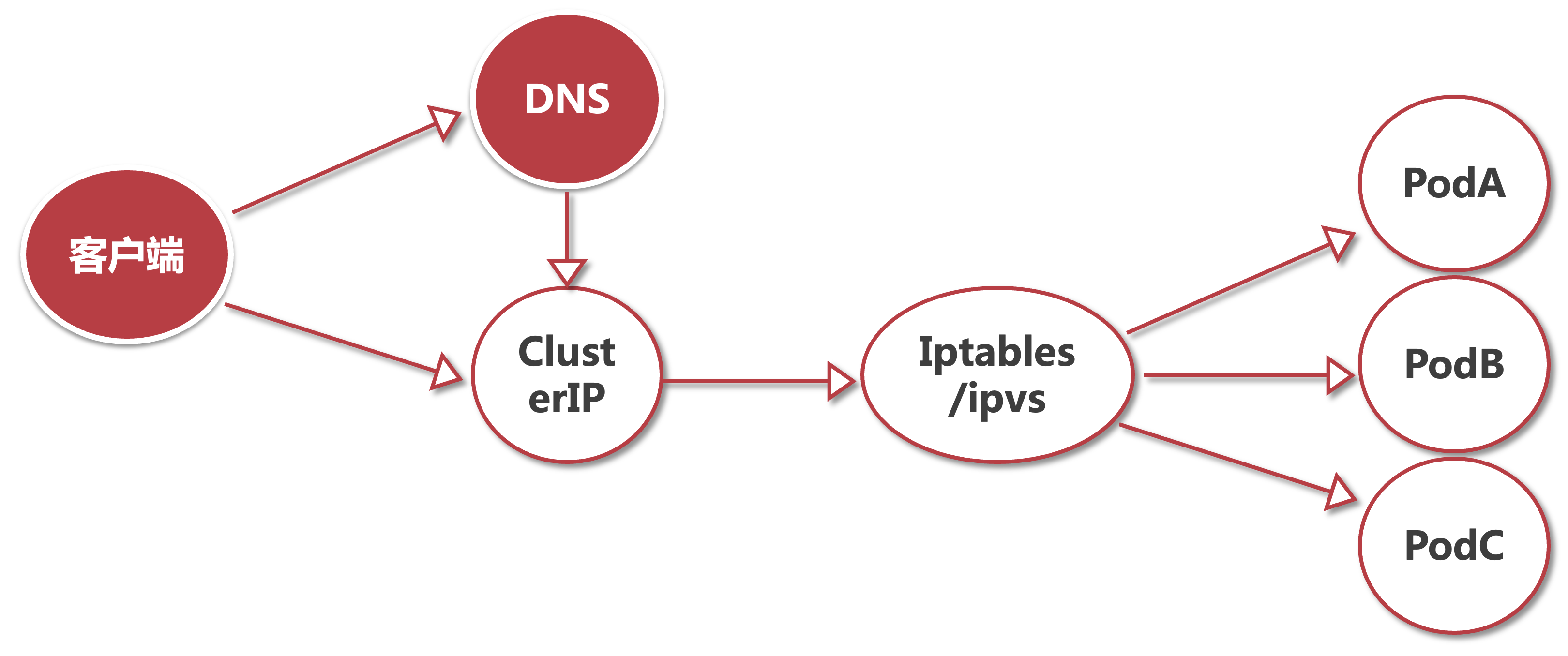
- 是
Service的默认类型 ,为服务分配一个仅集群内部可访问的虚拟 IP(ClusterIP)。 - 用途:集群内部服务间通信,并对集群内的pod提供健康检测和自动发现功能。例如,订单服务通过 ClusterIP 被支付服务调用,无需暴露到外部网络。
!NOTE
健康检测就是pod如果不正常,就会自动把podIP移出去
自动发现就是会把新的podIP加到列表里面
**思路:**ClusterIP 是默认的 Service 类型,只能在集群内部用。配置好后,集群里的应用可以通过它的 IP 或者域名访问对应的 Pod。外面的机器访问不了,适合内部服务之间互相调用。而且集群里有个 DNS 服务,能把服务名转换成 IP,方便记忆和使用。
bash
# 查看ClusterIP类型的Service配置(显式指定type: ClusterIP)
[root@master service]# cat clusterip.yml
apiVersion: v1
kind: Service
metadata:
labels:
app: myappv1
name: myappv1
spec:
ports:
- port: 80
protocol: TCP
targetPort: 80
selector:
app: myappv1
type: ClusterIP # 显式指定Service类型为ClusterIP
# 应用配置文件,更新Service(若已存在则更新)
[root@master service]# kubectl apply -f clusterip.yml
service/myappv1 configured
# 查看Service详情,确认ClusterIP仅集群内部可访问
[root@master service]# kubectl get svc -o wide
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 11d <none>
myappv1 ClusterIP 10.102.136.32 <none> 80/TCP 28m app=myappv1
# 集群内部访问Service的ClusterIP,成功返回应用页面
[root@master service]# curl 10.102.136.32
Hello MyApp | Version: v1 | <a href="hostname.html">Pod Name</a>
# 集群外部(如本地电脑)访问该ClusterIP,失败(超时),验证仅内部可访问
[C:\~]$ curl 10.102.136.32
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
0 0 0 0 0 0 0 0 --:--:-- 0:00:10 --:--:-- 0service创建后集群DNS提供解析
bash
# 查看集群DNS服务(kube-dns),负责Service的域名解析
[root@master service]# kubectl -n kube-system get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kube-dns ClusterIP 10.96.0.10 <none> 53/UDP,53/TCP,9153/TCP 11d
# 通过dig工具查询myappv1的DNS解析,集群内域名格式为<service名称>.<命名空间>.svc.cluster.local
[root@master service]# dig myappv1.default.svc.cluster.local @10.96.0.10 # @指定DNS服务器为kube-dns的ClusterIP
; <<>> DiG 9.16.23-RH <<>> myappv1.default.svc.cluster.local @10.96.0.10
;; global options: +cmd
;; Got answer:
;; WARNING: .local is reserved for Multicast DNS
;; You are currently testing what happens when an mDNS query is leaked to DNS
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 26126
;; flags: qr aa rd; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 1
;; WARNING: recursion requested but not available
;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags:; udp: 4096
; COOKIE: 4ae5f3b515a2fcca (echoed)
;; QUESTION SECTION:
;myappv1.default.svc.cluster.local. IN A # 查询A记录(IP地址)
;; ANSWER SECTION:
myappv1.default.svc.cluster.local. 30 IN A 10.102.136.32 # 解析结果为myappv1的ClusterIP
;; Query time: 3 msec
;; SERVER: 10.96.0.10#53(10.96.0.10)
;; WHEN: Tue Oct 28 19:52:09 CST 2025
;; MSG SIZE rcvd: 123结果 :ClusterIP 类型的 Service 仅允许集群内部访问,外部无法直接访问。集群内部通过 kube-dns 服务提供 DNS 解析,可通过<服务名>.<命名空间>.svc.cluster.local格式的域名访问 Service,解析结果为其 ClusterIP。
4.2 ClusterIP 中的特殊模式:headless
当Service的clusterIP字段设置为None时,即为headless Service。
- 特点:对于无头
Services并不会分配 Cluster IP,kube-proxy不会处理它们, 而且平台也不会为它们进行负载均衡和路由,集群访问通过dns解析直接指向到业务pod上的IP,所有的调度有dns单独完成 - 用途:适用于有状态服务(如数据库集群、中间件集群),需要直接与 Pod 通信或自定义服务发现逻辑的场景(如 StatefulSet 管理的服务,每个 Pod 有唯一标识,可通过 DNS 直接定位)。
**思路:**headless 是 ClusterIP 的一种特殊形式,不给 Service 分配 IP。访问它的时候,DNS 直接返回所有 Pod 的 IP,没有负载均衡。适合那些需要直接和每个 Pod 通信的场景,比如数据库集群,每个 Pod 都有自己的身份,客户端可能需要指定某个 Pod 访问。
bash
# 复制clusterip.yml为headless.yml,用于创建headless Service
[root@master service]# cp clusterip.yml headless.yml
[root@master service]# vim headless.yml # 编辑配置文件
[root@master service]# cat headless.yml
apiVersion: v1
kind: Service
metadata:
labels:
app: myappv1
name: headless # Service名称为headless
spec:
ports:
- port: 80
protocol: TCP
targetPort: 80
selector:
app: myappv1
type: ClusterIP
clusterIP: None # 设置clusterIP为None,即headless模式
# 应用配置文件,创建headless Service
[root@master service]# kubectl apply -f headless.yml
[root@master service]# kubectl get service # 查看Service列表
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
headless ClusterIP None <none> 80/TCP 28s # headless Service无ClusterIP
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 11d
myappv1 ClusterIP 10.102.136.32 <none> 80/TCP 37m
# 查询headless Service的DNS解析,返回所有后端Pod的IP(而非Service的虚拟IP)
[root@master service]# dig headless.default.svc.cluster.local @10.96.0.10
; <<>> DiG 9.16.23-RH <<>> headless.default.svc.cluster.local @10.96.0.10
;; global options: +cmd
;; Got answer:
;; WARNING: .local is reserved for Multicast DNS
;; You are currently testing what happens when an mDNS query is leaked to DNS
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 46920
;; flags: qr aa rd; QUERY: 1, ANSWER: 2, AUTHORITY: 0, ADDITIONAL: 1
;; WARNING: recursion requested but not available
;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags:; udp: 4096
; COOKIE: 1415220227e0cdf7 (echoed)
;; QUESTION SECTION:
;headless.default.svc.cluster.local. IN A
;; ANSWER SECTION:
headless.default.svc.cluster.local. 30 IN A 10.244.1.4 # 第一个Pod的IP
headless.default.svc.cluster.local. 30 IN A 10.244.2.3 # 第二个Pod的IP
;; Query time: 1 msec
;; SERVER: 10.96.0.10#53(10.96.0.10)
;; WHEN: Tue Oct 28 19:58:12 CST 2025
;; MSG SIZE rcvd: 175结果:headless Service 不分配 ClusterIP,DNS 解析直接返回所有后端 Pod 的 IP,而非虚拟 IP。这意味着没有负载均衡,客户端需自行处理与 Pod 的通信(如自定义负载均衡逻辑),适用于有状态服务。
4.3 NodePort
思路:NodePort 能让外面的机器访问集群里的服务,它会在每个节点上开一个端口,外面用 "节点 IP: 这个端口" 就能访问。默认端口范围是 30000 到 32767,不够用的话可以改配置扩大范围。适合开发测试的时候临时暴露服务给外部用。
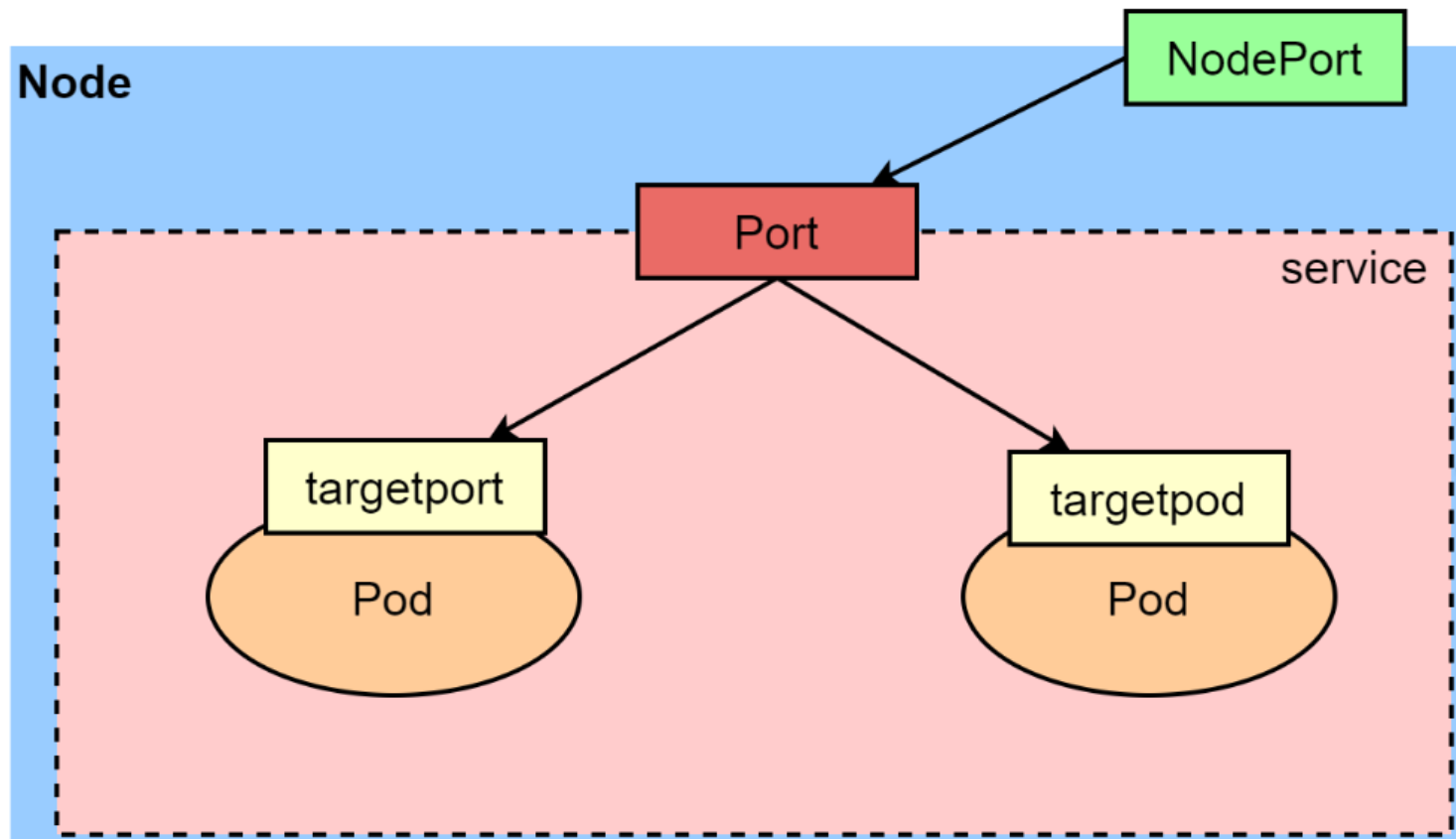
- 在 ClusterIP 基础上,将服务端口映射到集群所有节点的一个静态端口 (端口范围
30000-32767)。 - 用途:临时对外暴露服务 (如开发环境测试),外部可通过
节点IP:NodePort访问服务。
bash
[root@master service]# cp clusterip.yml nodeport.yml
[root@master service]# vim nodeport.yml
[root@master service]# cat nodeport.yml
apiVersion: v1
kind: Service
metadata:
labels:
app: myappv1
name: nodeport # Service名称为nodeport
spec:
ports:
- port: 80
protocol: TCP
targetPort: 80
selector:
app: myappv1
type: NodePort # 指定Service类型为NodePort
[root@master service]# kubectl apply -f nodeport.yml
service/nodeport created
# 查看Service详情,NodePort Service会分配ClusterIP和节点端口(30345)
[root@master service]# kubectl get svc -o wide
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
headless ClusterIP None <none> 80/TCP 8m13s app=myappv1
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 11d <none>
myappv1 ClusterIP 10.102.136.32 <none> 80/TCP 45m app=myappv1
nodeport NodePort 10.111.53.96 <none> 80:30345/TCP 10s app=myappv1
[root@master service]# ipvsadm -Ln
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 172.17.0.1:30345 rr
-> 10.244.1.4:80 Masq 1 0 0
-> 10.244.2.3:80 Masq 1 0 0
TCP 192.168.2.60:30345 rr
-> 10.244.1.4:80 Masq 1 0 0
-> 10.244.2.3:80 Masq 1 0 0
TCP 10.96.0.1:443 rr
-> 192.168.2.60:6443 Masq 1 0 0
TCP 10.96.0.10:53 rr
-> 10.244.1.2:53 Masq 1 0 0
-> 10.244.1.3:53 Masq 1 0 0
TCP 10.96.0.10:9153 rr
-> 10.244.1.2:9153 Masq 1 0 0
-> 10.244.1.3:9153 Masq 1 0 0
TCP 10.102.136.32:80 rr
-> 10.244.1.4:80 Masq 1 0 0
-> 10.244.2.3:80 Masq 1 0 0
TCP 10.111.53.96:80 rr
-> 10.244.1.4:80 Masq 1 0 0
-> 10.244.2.3:80 Masq 1 0 0
TCP 10.244.0.0:30345 rr
-> 10.244.1.4:80 Masq 1 0 0
-> 10.244.2.3:80 Masq 1 0 0
UDP 10.96.0.10:53 rr
-> 10.244.1.2:53 Masq 1 0 0
-> 10.244.1.3:53 Masq 1 0 0
[root@master service]# curl 192.168.2.60:30345/hostname.html
myappv1-5c47495d84-7wf98
[root@master service]# curl 192.168.2.60:30345/hostname.html
myappv1-5c47495d84-blzwb!NOTE
nodeport默认端口
nodeport默认端口是30000-32767,超出会报错
如果需要使用这个范围以外的端口就需要特殊设定
!NOTE
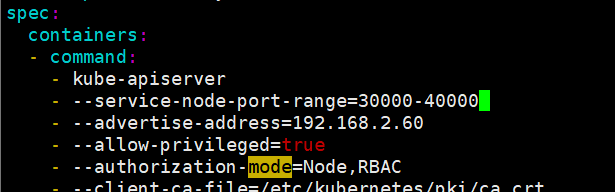
bash[root@master service]# vim /etc/kubernetes/manifests/kube-apiserver.yaml spec: containers: - command: - kube-apiserver - --service-node-port-range=30000-40000 # 自定义NodePort范围为30000-40000 [root@master service]# vim nodeport.yml [root@master service]# cat nodeport.yml apiVersion: v1 kind: Service metadata: labels: app: myappv1 name: nodeport spec: ports: - port: 80 protocol: TCP targetPort: 80 nodePort: 39527 selector: app: myappv1 type: NodePort [root@master service]# kubectl apply -f nodeport.yml service/nodeport configured # 查看Service,确认nodePort已更新为39527 [root@master service]# kubectl get svc -o wide NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR headless ClusterIP None <none> 80/TCP 14m app=myappv1 kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 11d <none> myappv1 ClusterIP 10.102.136.32 <none> 80/TCP 51m app=myappv1 nodeport NodePort 10.111.53.96 <none> 80:39527/TCP 6m51s app=myappv1 [root@master service]# curl 192.168.2.60:39527 Hello MyApp | Version: v1 | <a href="hostname.html">Pod Name</a>添加"--service-node-port-range=" 参数,端口范围可以自定义
修改后api-server会自动重启,等apiserver正常启动后才能操作集群
集群重启自动完成在修改完参数后全程不需要人为干预
结果:NodePort 类型的 Service 在 ClusterIP 基础上,将服务端口映射到集群所有节点的静态端口(默认 30000-32767),外部可通过 "节点 IP:NodePort" 访问服务。支持自定义端口范围(需修改 kube-apiserver 配置)和指定具体节点端口。
4.4 LoadBalancer

- 基于 NodePort,由云服务商(如 AWS、GCP)提供外部负载均衡器,将公网流量转发到 NodePort,如果是裸金属主机那么需要metallb来实现ip的分配。
- 用途:生产环境对外暴露服务(如用户访问的 Web 应用),需云服务商支持。
思路:LoadBalancer 适合生产环境,它在 NodePort 基础上,让云服务商提供一个外部的负载均衡器,外面的流量先到这个负载均衡器,再转发到集群节点。但在自己的服务器(非云环境)上用不了,外部 IP 会一直处于等待状态,这时候就需要用 metallb 来模拟。
bash
[root@master service]# cp clusterip.yml loadbalancer.yml
[root@master service]# vim loadbalancer.yml
[root@master service]# cat loadbalancer.yml
apiVersion: v1
kind: Service
metadata:
labels:
app: myappv1
name: loadbalancer
spec:
ports:
- port: 80
protocol: TCP
targetPort: 80
selector:
app: myappv1
type: LoadBalancer # 指定Service类型为LoadBalancer
[root@master service]# kubectl apply -f loadbalancer.yml
service/loadbalancer created
# 查看Service,外部IP处于<pending>状态(非云环境无云服务商提供负载均衡器)
[root@master service]# kubectl get svc -o wide
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
headless ClusterIP None <none> 80/TCP 17h app=myappv1
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 12d <none>
loadbalancer LoadBalancer 10.105.146.47 <pending> 80:32303/TCP 13s app=myappv1
myappv1 ClusterIP 10.102.136.32 <none> 80/TCP 17h app=myappv1
nodeport NodePort 10.111.53.96 <none> 80:39527/TCP 17h app=myappv1结果:LoadBalancer 类型的 Service 依赖云服务商提供外部负载均衡器,在非云环境中外部 IP 会处于 pending 状态。它基于 NodePort 实现,会自动分配一个 NodePort,等待外部负载均衡器配置完成后即可通过其 IP 访问服务。
4.5 metallLB
- 当 K8s 运行在非云环境(如本地、私有数据中心)时,无云服务商的负载均衡器,metallLB 可作为
LoadBalancer类型的替代方案。 - 功能:通过BGP 或 Layer2 模式 为
LoadBalancer类型的 Service 分配外部 IP,实现本地环境的 "类云负载均衡"。
思路:在自己的服务器上用不了云服务商的负载均衡器,就用 metallb 来模拟。先把 metallb 的镜像传到自己的仓库,然后部署它的组件,再配置一个 IP 地址池(告诉它可以用哪些 IP),最后 LoadBalancer 类型的 Service 就能拿到一个外部 IP,外面就能通过这个 IP 访问服务了。
部署文件:https://raw.githubusercontent.com/metallb/metallb/v0.13.12/config/manifests/metallb-native.yaml
bash
# 部署文件和镜像包
[root@master service]# ls
metallb-native.yaml configmap.yml metalLB.tag.gz
# 修改部署文件中的镜像,改为从harbor仓库拉取
[root@master service]# grep -w image metallb-native.yaml
image: metallb/controller:v0.14.8
image: metallb/speaker:v0.14.8
[root@master service]# docker load -i metalLB.tag.gz
f144bb4c7c7f: Loading layer [==================================================>] 327.7kB/327.7kB
49626df344c9: Loading layer [==================================================>] 40.96kB/40.96kB
945d17be9a3e: Loading layer [==================================================>] 2.396MB/2.396MB
4d049f83d9cf: Loading layer [==================================================>] 1.536kB/1.536kB
af5aa97ebe6c: Loading layer [==================================================>] 2.56kB/2.56kB
ac805962e479: Loading layer [==================================================>] 2.56kB/2.56kB
bbb6cacb8c82: Loading layer [==================================================>] 2.56kB/2.56kB
2a92d6ac9e4f: Loading layer [==================================================>] 1.536kB/1.536kB
1a73b54f556b: Loading layer [==================================================>] 10.24kB/10.24kB
f4aee9e53c42: Loading layer [==================================================>] 3.072kB/3.072kB
b336e209998f: Loading layer [==================================================>] 238.6kB/238.6kB
371134a463a4: Loading layer [==================================================>] 61.38MB/61.38MB
6e64357636e3: Loading layer [==================================================>] 13.31kB/13.31kB
Loaded image: quay.io/metallb/controller:v0.14.8
0b8392a2e3be: Loading layer [==================================================>] 2.137MB/2.137MB
3d5a6e3a17d1: Loading layer [==================================================>] 65.46MB/65.46MB
8311c2bd52ed: Loading layer [==================================================>] 49.76MB/49.76MB
4f4d43efeed6: Loading layer [==================================================>] 3.584kB/3.584kB
881ed6f5069a: Loading layer [==================================================>] 13.31kB/13.31kB
Loaded image: quay.io/metallb/speaker:v0.14.8
# 为镜像打标签(指向私有仓库,方便集群内部拉取)
[root@master service]# docker tag quay.io/metallb/controller:v0.14.8 rch.hjn.com/metallb/controller:v0.14.8
[root@master service]# docker tag quay.io/metallb/speaker:v0.14.8 rch.hjn.com/metallb/speaker:v0.14.8
[root@master service]# docker push rch.hjn.com/metallb/controller:v0.14.8
[root@master service]# docker push rch.hjn.com/metallb/speaker:v0.14.8 
bash
1.设置ipvs模式(metallb在ipvs模式下需开启strictARP)
[root@master service]# kubectl edit cm -n kube-system kube-proxy
apiVersion: kubeproxy.config.k8s.io/v1alpha1
kind: KubeProxyConfiguration
mode: "ipvs"
ipvs:
strictARP: true
2.重启kube-proxy的Pod,使配置生效
[root@master service]# kubectl -n kube-system get pods | awk '/kube-proxy/{system("kubectl -n kube-system delete pods "$1)}'
pod "kube-proxy-87f5f" deleted
pod "kube-proxy-r7zfp" deleted
pod "kube-proxy-vjlpz" deleted
3.部署metallb服务
[root@master service]# kubectl apply -f metallb-native.yaml
[root@master service]# kubectl -n metallb-system get pods
NAME READY STATUS RESTARTS AGE
controller-65957f77c8-858vt 1/1 Running 0 27s
speaker-8t9jm 1/1 Running 0 27s
speaker-grctc 1/1 Running 0 27s
speaker-hdkhr 1/1 Running 0 27s
4.配置metallb的IP地址池(指定可分配的外部IP范围)
[root@master service]# vim configmap.yml
[root@master service]# cat configmap.yml
apiVersion: metallb.io/v1beta1
kind: IPAddressPool
metadata:
name: first-pool
namespace: metallb-system
spec:
addresses:
- 192.168.2.10-192.168.2.20
---
apiVersion: metallb.io/v1beta1
kind: L2Advertisement
metadata:
name: example
namespace: metallb-system
spec:
ipAddressPools:
- first-pool
[root@master service]# kubectl apply -f configmap.yml
ipaddresspool.metallb.io/first-pool created
l2advertisement.metallb.io/example created
[root@master service]# kubectl -n metallb-system get cm
NAME DATA AGE
kube-root-ca.crt 1 3m20s
metallb-excludel2 1 3m20s
[root@master service]# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
headless ClusterIP None <none> 80/TCP 18h
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 12d
loadbalancer LoadBalancer 10.105.146.47 192.168.2.10 80:32303/TCP 44m
myappv1 ClusterIP 10.102.136.32 <none> 80/TCP 18h
nodeport NodePort 10.111.53.96 <none> 80:39527/TCP 17h
[root@master service]# curl 192.168.2.10
Hello MyApp | Version: v1 | <a href="hostname.html">Pod Name</a>结果:metallb 在非云环境中为 LoadBalancer 类型的 Service 提供外部 IP 分配功能。通过部署 metallb 组件、配置 IP 地址池和 L2 模式,成功为 loadbalancer Service 分配了外部 IP(192.168.2.10),实现了本地环境的负载均衡访问。
4.6 ExternalName
- 开启services后,不会被分配IP,而是用dns解析CNAME固定域名来解决ip变化问题
- 一般应用于外部业务和pod沟通或外部业务迁移到pod内时
- 在应用向集群迁移过程中,externalname在过度阶段就可以起作用了。
- 集群外的资源迁移到集群时,在迁移的过程中ip可能会变化,但是域名+dns解析能完美解决此问题
- 通俗的讲,就是你访问我,我把请求通过域名转发到集群外
思路 :ExternalName 就是把集群内的服务请求转发到外部的某个域名。比如创建一个叫 externalname 的 Service,指定转发到www.qq.com,那么在集群里访问 externalname,就相当于访问www.qq.com。适合迁移服务的时候用,比如原来用外部服务,现在慢慢迁到集群里,中间可以用这个过渡。
bash
# 复制clusterip.yml为externalname.yml,用于创建ExternalName类型的Service
[root@master service]# cp clusterip.yml externalname.yml
[root@master service]# vim externalname.yml # 编辑配置文件
[root@master service]# cat externalname.yml
apiVersion: v1
kind: Service
metadata:
labels:
app: myappv1
name: externalname # Service名称为externalname
spec:
ports:
- port: 80
protocol: TCP
targetPort: 80
selector:
app: myappv1
type: ExternalName # 指定Service类型为ExternalName
externalName: www.qq.com # 转发到的外部域名
# 应用配置文件,创建ExternalName Service
[root@master service]# kubectl apply -f externalname.yml
service/externalname created
# 查看Service,ExternalName类型无ClusterIP,关联到www.qq.com
[root@master service]# kubectl get svc -o wide
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
externalname ExternalName <none> www.qq.com 80/TCP 8s app=myappv1
headless ClusterIP None <none> 80/TCP 18h app=myappv1
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 12d <none>
loadbalancer LoadBalancer 10.105.146.47 192.168.2.10 80:32303/TCP 52m app=myappv1
myappv1 ClusterIP 10.102.136.32 <none> 80/TCP 18h app=myappv1
nodeport NodePort 10.111.53.96 <none> 80:39527/TCP 18h app=myappv1
# 在集群内的Pod中访问externalname,实际解析到www.qq.com的IP
[root@master service]# kubectl run -it test --image busyboxplus # 启动一个测试Pod
/ # ping externalname # ping externalname,实际访问www.qq.com
PING externalname (101.91.42.232): 56 data bytes
64 bytes from 101.91.42.232: seq=0 ttl=127 time=27.749 ms
64 bytes from 101.91.42.232: seq=1 ttl=127 time=26.276 ms
# 解析externalname的域名,返回www.qq.com的IP
/ # nslookup externalname.default.svc.cluster.local
Server: 10.96.0.10
Address 1: 10.96.0.10 kube-dns.kube-system.svc.cluster.local
Name: externalname.default.svc.cluster.local
Address 1: 101.91.22.57
Address 2: 101.91.42.232
Address 3: 240e:e1:a800:120::36
Address 4: 240e:e1:a800:120::76
# 在集群外ping www.qq.com,IP与集群内解析一致,验证转发正确
[root@master service]# ping www.qq.com
PING ins-r23tsuuf.ias.tencent-cloud.net (101.91.42.232) 56(84) 比特的数据。
64 比特,来自 101.91.42.232 (101.91.42.232): icmp_seq=1 ttl=128 时间=25.7 毫秒
64 比特,来自 101.91.42.232 (101.91.42.232): icmp_seq=2 ttl=128 时间=26.3 毫秒五 Ingress-nginx
前面介绍的微服务除了ExternalName之外都是四层负载,而Ingress-nginx就是用来做七层负载的。
官网:https://kubernetes.github.io/ingress-nginx/deploy/#bare-metal-clusters
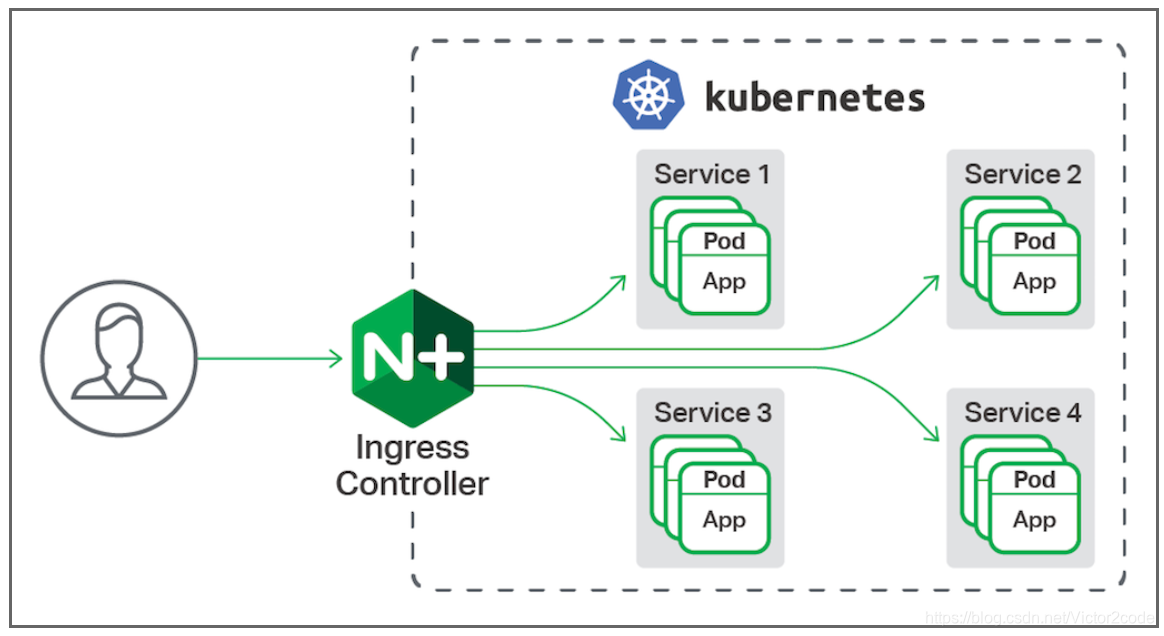
当多个服务需要通过域名或路径统一对外暴露 时,NodePort 或 LoadBalancer 会导致端口管理混乱,Ingress是更优雅的解决方案。ingress-nginx是基于 Nginx 的 Ingress 控制器实现,负责解析 Ingress 规则并转发流量。
5.1 ingress-nginx 功能
- 支持HTTP/HTTPS 流量路由 ,可基于域名、路径分发请求到不同服务;
- 提供TLS 加密、身份认证(如 Basic Auth)、请求重写、限流等高级功能,是集群对外的 "统一流量入口"。
- 一种全局的、为了代理不同后端 Service 而设置的负载均衡服务,支持7层
- Ingress由两部分组成:Ingress controller和Ingress服务
- Ingress Controller 会根据你定义的 Ingress 对象,提供对应的代理能力。
- 业界常用的各种反向代理项目,比如 Nginx、HAProxy、Envoy、Traefik 等,都已经为Kubernetes 专门维护了对应的 Ingress Controller。
5.2 部署 ingress-nginx
思路:Ingress 是七层负载均衡,能根据域名或路径把请求转发到不同服务。先部署 ingress-nginx 控制器,它相当于一个 Nginx 反向代理。然后创建 Ingress 规则,比如把根路径的请求转发到 myappv1。这样外面访问 ingress 的 IP,就能自动转到对应的服务了,比用多个 NodePort 端口方便多了。
5.2.1 下载部署文件
bash
# 下载ingress-nginx的部署文件(适用于裸金属集群)
[root@master ~]# wget https://raw.githubusercontent.com/kubernetes/ingress-nginx/controller-v1.11.2/deploy/static/provider/baremetal/deploy.yaml上传ingress所需镜像到harbor,我本地有镜像,所以上传到目录中来
bash
# 部署文件和镜像包
[root@master service]# ls
deploy.yaml ingress-1.13.3.tar
[root@master service]# docker load -i ingress-1.13.3.tar
Loaded image: registry.k8s.io/ingress-nginx/controller:v1.13.3
Loaded image: registry.k8s.io/ingress-nginx/kube-webhook-certgen:v1.6.3
#在harbor仓库中创建一个公开的项目,名为ingress-nginx
[root@master service]# docker tag registry.k8s.io/ingress-nginx/controller:v1.13.3 rch.hjn.com/ingress-nginx/controller:v1.13.3
[root@master service]# docker tag registry.k8s.io/ingress-nginx/kube-webhook-certgen:v1.6.3 rch.hjn.com/ingress-nginx/kube-webhook-certgen:v1.6.3
[root@master service]# docker push rch.hjn.com/ingress-nginx/controller:v1.13.3
[root@master service]# docker push rch.hjn.com/ingress-nginx/kube-webhook-certgen:v1.6.3 
5.2.2 安装ingress
bash
[root@master service]# vim deploy.yaml
[root@master service]# grep -n -w image deploy.yaml
444: image: ingress-nginx/controller:v1.13.3 # 修改为私有仓库镜像
547: image: ingress-nginx/kube-webhook-certgen:v1.6.3 # 修改为私有仓库镜像
603: image: ingress-nginx/kube-webhook-certgen:v1.6.3 # 修改为私有仓库镜像
[root@master service]# kubectl apply -f deploy.yaml
[root@master service]# kubectl -n ingress-nginx get pods
NAME READY STATUS RESTARTS AGE
ingress-nginx-controller-b6cbfc9f4-5n85j 1/1 Running 0 45s
# 查看ingress-nginx的Service,默认类型为NodePort
[root@master service]# kubectl -n ingress-nginx get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
ingress-nginx-controller NodePort 10.96.189.185 <none> 80:32664/TCP,443:34783/TCP 86s
ingress-nginx-controller-admission ClusterIP 10.101.148.78 <none> 443/TCP 86s
# 编辑ingress-nginx的Service,将类型改为LoadBalancer(结合metallb获取外部IP)
[root@master service]# kubectl -n ingress-nginx edit svc ingress-nginx-controller
type: LoadBalancer
# 查看更新后的Service,External-IP已分配(192.168.2.11,来自metallb的地址池)
[root@master service]# kubectl -n ingress-nginx get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
ingress-nginx-controller LoadBalancer 10.96.189.185 192.168.2.11 80:32664/TCP,443:34783/TCP 5m54s
ingress-nginx-controller-admission ClusterIP 10.101.148.78 <none> 443/TCP 5m54s5.2.3 测试ingress
1.准备服务
bash
# 为myappv1和myappv2的Deployment创建对应的Service配置,并追加到原YAML文件
[root@master service]# kubectl expose deployment myappv1 --port 80 --target-port 80 --dry-run=client -o yaml >> myappv1.yml
[root@master service]# kubectl expose deployment myappv2 --port 80 --target-port 80 --dry-run=client -o yaml >> myappv2.yml
[root@master service]# vim myappv1.yml
[root@master service]# vim myappv2.yml
[root@master service]# cat myappv1.yml
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: myappv1
name: myappv1
spec:
replicas: 2
selector:
matchLabels:
app: myappv1
template:
metadata:
labels:
app: myappv1
spec:
containers:
- image: myapp:v1
name: myappv1
---
apiVersion: v1
kind: Service
metadata:
labels:
app: myappv1
name: myappv1
spec:
ports:
- port: 80
protocol: TCP
targetPort: 80
selector:
app: myappv1
[root@master service]# cat myappv2.yml
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: myappv2
name: myappv2
spec:
replicas: 2
selector:
matchLabels:
app: myappv2
template:
metadata:
labels:
app: myappv2
spec:
containers:
- image: myapp:v2
name: myappv2
---
apiVersion: v1
kind: Service
metadata:
labels:
app: myappv2
name: myappv2
spec:
ports:
- port: 80
protocol: TCP
targetPort: 80
selector:
app: myappv2
[root@master service]# kubectl apply -f myappv1.yml
[root@master service]# kubectl apply -f myappv2.yml
[root@master service]# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
myappv1 ClusterIP 10.102.136.32 <none> 80/TCP 19h
myappv2 ClusterIP 10.109.106.183 <none> 80/TCP 4s
[root@master service]# curl 10.105.146.47
Hello MyApp | Version: v1 | <a href="hostname.html">Pod Name</a>
[root@master service]# curl 10.109.106.183
Hello MyApp | Version: v2 | <a href="hostname.html">Pod Name</a>2.创建ingress
bash
# 创建Ingress配置文件,将所有请求路由到myappv1
[root@master service]# kubectl create ingress webcluster --rule '*/=myappv1:80' --dry-run=client -o yaml > 1-ingress.yml
# 编辑Ingress配置文件,指定ingressClassName和路径类型
[root@master service]# vim 1-ingress.yml
[root@master service]# cat 1-ingress.yml
apiVersion: networking.k8s.io/v1
kind: Ingress # 资源类型为Ingress
metadata:
name: webcluster # Ingress名称
spec:
ingressClassName: nginx # 指定使用nginx类型的Ingress控制器
rules:
- http:
paths:
- backend:
service:
name: myappv1 # 后端Service名称
port:
number: 80 # 后端Service端口
path: / # 匹配根路径
pathType: Prefix # 路径匹配类型:Prefix(前缀匹配),Exact(精确匹配),ImplementationSpecific(特定实现)
# 应用Ingress配置文件
[root@master service]# kubectl apply -f 1-ingress.yml
ingress.networking.k8s.io/webcluster created
# 查看Ingress,确认创建成功
[root@master service]# kubectl get ingress -o wide
NAME CLASS HOSTS ADDRESS PORTS AGE
webcluster nginx * 80 21s
# 查看ingress-nginx的Service,获取外部IP(192.168.2.11)
[root@master service]# kubectl -n ingress-nginx get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
ingress-nginx-controller LoadBalancer 10.96.189.185 192.168.2.11 80:32664/TCP,443:34783/TCP 22m
ingress-nginx-controller-admission ClusterIP 10.101.148.78 <none> 443/TCP 22m
# 通过ingress-nginx的外部IP访问,成功路由到myappv1(v1版本页面)
[root@master service]# curl 192.168.2.11
Hello MyApp | Version: v1 | <a href="hostname.html">Pod Name</a>
[root@master service]# curl 192.168.2.11
Hello MyApp | Version: v1 | <a href="hostname.html">Pod Name</a>!NOTE
ingress必须和输出的service资源处于同一namespace
结果 :成功部署了 ingress-nginx 控制器,并通过 Ingress 规则将外部流量路由到 myappv1 服务。Ingress 基于路径匹配(根路径/),通过 ingress-nginx 的外部 IP(192.168.2.11)可访问到 myappv1 的应用页面,实现了七层负载均衡。
5.3 ingress 的高级用法
5.3.1 基于路径的访问
Ingress 通过路径匹配规则 ,将客户端请求中不同的 URL 路径(如/order、/pay)映射到对应的后端 Service。K8s 会根据 Ingress 资源中定义的path字段,将请求精准路由到匹配路径的服务,实现单域名下多服务的路径级流量分发,提升域名资源的复用性。
思路 :基于路径的访问就是用同一个域名,通过不同的路径访问不同服务。比如配置 Ingress 规则,让www.rch.com/v1转到 myappv1,www.rch.com/v2转到 myappv2。这样只用一个域名和端口,就能访问多个服务,管理起来更方便。
bash
# 查看当前Deployment,myappv1和myappv2均正常运行
[root@master service]# kubectl get deployments.apps
NAME READY UP-TO-DATE AVAILABLE AGE
myappv1 2/2 2 2 19h
myappv2 2/2 2 2 19h
# 查看当前Service,myappv1和myappv2的ClusterIP均正常
[root@master service]# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
myappv1 ClusterIP 10.102.136.32 <none> 80/TCP 19h
myappv2 ClusterIP 10.109.106.183 <none> 80/TCP 18m
# 复制1-ingress.yml为2-ingress.yml,配置基于路径的路由
[root@master service]# cp 1-ingress.yml 2-ingress.yml
[root@master service]# vim 2-ingress.yml
[root@master service]# cat 2-ingress.yml
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: webcluster
annotations:
nginx.ingress.kubernetes.io/rewrite-target: / # 重写路径,将匹配的路径去掉后转发到后端
spec:
ingressClassName: nginx
rules:
- host: www.rch.com # 绑定域名(需在本地 hosts 配置解析到ingress的外部IP)
http:
paths:
- backend:
service:
name: myappv1 # 路径/v1转发到myappv1
port:
number: 80
path: /v1 # 匹配以/v1开头的路径
pathType: Prefix
- backend:
service:
name: myappv2 # 路径/v2转发到myappv2
port:
number: 805.3.2 基于域名的访问
Ingress 支持域名匹配机制 ,通过host字段将不同域名(如order.example.com、pay.example.com)的请求转发到各自对应的后端 Service。这种方式实现了多域名到多服务的流量隔离与分发,让不同业务域名可以共享同一个 Ingress 入口,简化外部访问的域名管理。
bash
[root@master service]# cp 2-ingress.yml 3-ingress.yml
[root@master service]# vim 3-ingress.yml
[root@master service]# cat 3-ingress.yml
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: ingress3
annotations:
# 重写路径,将匹配的路径去掉后转发到后端
nginx.ingress.kubernetes.io/rewrite-target: /
spec:
ingressClassName: nginx
rules: # 定义路由规则
- host: www.rch.com # 第一个域名规则:匹配www.rch.com
http:
paths:
- backend: # 后端服务配置
service:
name: myappv1 # 转发到myappv1服务
port:
number: 80 # 服务端口为80
path: / # 匹配根路径
pathType: Prefix # 路径类型为前缀匹配(以/开头的路径都匹配)
- host: www.hjn.com # 第二个域名规则:匹配www.hjn.com
http:
paths:
- backend:
service:
name: myappv2 # 转发到myappv2服务
port:
number: 80
path: /
pathType: Prefix
[root@master service]# echo "192.168.2.11 www.hjn.com" >> /etc/hosts
[root@master service]# kubectl apply -f 3-ingress.yml
# 查看Ingress详情,确认规则是否生效
[root@master service]# kubectl describe ingress ingress3
Name: ingress3
Labels: <none>
Namespace: default
Address: 192.168.2.63
Ingress Class: nginx
Default backend: <default>
Rules:
Host Path Backends
---- ---- --------
www.rch.com
/ myappv1:80 (10.244.1.4:80,10.244.2.3:80)
www.hjn.com
/ myappv2:80 (10.244.1.5:80,10.244.2.4:80)
Annotations: nginx.ingress.kubernetes.io/rewrite-target: /
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Sync 7s (x2 over 50s) nginx-ingress-controller Scheduled for sync
[root@master service]# curl www.rch.com
Hello MyApp | Version: v1 | <a href="hostname.html">Pod Name</a>
[root@master service]# curl www.hjn.com
Hello MyApp | Version: v2 | <a href="hostname.html">Pod Name</a>结果:用户访问www.rch.com时去 v1 版本的服务,访问www.hjn.com时去 v2 版本的服务。所以在 Ingress 里写两条规则,分别指定每个域名对应哪个服务,再把域名和 Ingress 的 IP 绑定到本地 hosts,这样就能通过域名直接访问了。
5.3.3 建立tls加密
通过在 Ingress 资源中配置TLS 证书(包含公钥和私钥) ,启用 HTTPS 通信协议。客户端与 Ingress 控制器之间的流量会被 TLS 加密,确保数据传输的机密性(防止数据被窃听)和完整性(防止数据被篡改),同时支持域名身份验证(避免中间人攻击)。
bash
# 生成TLS证书和私钥:
# -newkey rsa:2048:生成2048位RSA密钥
# -nodes:不加密私钥
# -keyout tls.key:私钥输出到tls.key文件
# -x509:生成自签名证书
# -days 365:证书有效期365天
# -subj:指定证书主题(CN为域名,O为组织)
# -out tls.crt:证书输出到tls.crt文件
[root@master service]# openssl req -newkey rsa:2048 -nodes -keyout tls.key -x509 -days 365 -subj "/CN=nginxsvc/O=nginxsvc" -out tls.crt
# 查看生成的证书文件
[root@master service]# ll
总用量 546232
-rw-r--r-- 1 root root 1164 10月 29 15:21 tls.crt # 证书文件(公钥)
-rw------- 1 root root 1704 10月 29 15:21 tls.key # 私钥文件将证书抽象为 K8s Secret 资源(方便 Ingress 引用):
bash
# 创建tls类型的Secret,存储证书和私钥
# --key:指定私钥文件
# --cert:指定证书文件
[root@master service]# kubectl create secret tls web-tls-secret --key tls.key --cert tls.crt
secret/web-tls-secret created
# 查看创建的Secret,确认类型为kubernetes.io/tls,包含2个数据(证书和私钥)
[root@master service]# kubectl get secrets
NAME TYPE DATA AGE
web-tls-secret kubernetes.io/tls 2 9s配置 Ingress 启用 TLS:
bash
# 复制基于域名的Ingress配置,修改为带TLS的配置
[root@master service]# cp 3-ingress.yml 4-ingress.yml
# 编辑配置文件
[root@master service]# vim 4-ingress.yml
# 查看配置内容
[root@master service]# cat 4-ingress.yml
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: ingress4
annotations:
nginx.ingress.kubernetes.io/rewrite-target: / # 保留路径重写
spec:
tls: # TLS配置部分
- hosts: # 对哪些域名启用TLS
- www.rchao.com
secretName: web-tls-secret # 引用存储证书的Secret
ingressClassName: nginx
rules:
- host: www.rchao.com # 仅对该域名启用HTTPS
http:
paths:
- backend:
service:
name: myappv1
port:
number: 80
path: /
pathType: Prefix
# 应用Ingress配置
[root@master service]# kubectl apply -f 4-ingress.yml
# 在hosts文件添加www.rchao.com与Ingress IP的映射
[root@master service]# echo "192.168.2.11 www.rchao.com" >> /etc/hosts
# 测试HTTP访问:Ingress会强制跳转到HTTPS,返回308永久重定向
[root@master service]# curl www.rchao.com
<html>
<head><title>308 Permanent Redirect</title></head>
<body>
<center><h1>308 Permanent Redirect</h1></center>
<hr><center>nginx</center>
</body>
</html>
# 测试HTTPS访问:-k忽略证书验证(自签名证书默认不被信任),成功返回v1版本内容
[root@master service]# curl -k https://www.rchao.com
Hello MyApp | Version: v1 | <a href="hostname.html">Pod Name</a>思路:普通 HTTP 传输数据不安全,想改成 HTTPS 加密。步骤就是:先生成一对证书和私钥(相当于加密的钥匙),然后把它们存在 K8s 的 Secret 里(方便 Ingress 取用),最后在 Ingress 里配置 "对www.rchao.com这个域名用 HTTPS",这样访问这个域名就会走加密通道了。
5.3.4 建立 auth 认证
Ingress 支持集成身份认证机制 (如 Basic Auth)。通过配置认证文件(包含用户名和加密后的密码),要求客户端在访问服务前提供有效凭证,只有通过认证的请求才会被转发到后端 Service。这种方式实现了服务访问的身份校验,增强了服务的访问安全性。
bash
# 安装生成认证文件的工具(httpd-tools包含htpasswd命令)
[root@master service]# yum install httpd-tools -y
# 生成认证文件auth:
# -c:创建新文件(首次使用)
# -m:使用MD5加密密码
# rch:用户名
[root@master service]# htpasswd -cm auth rch
New password: #输入密码123
Re-type new password: #再次输入密码123
Adding password for user rch
# 查看认证文件:包含用户名和加密后的密码
[root@master service]# cat auth
rch:$apr1$5V0fQ1Cw$hOylwisCOypDYo10nZX1z1
# 创建存储认证信息的Secret(generic类型,从文件加载数据)
[root@master service]# kubectl create secret generic auth-web --from-file auth
secret/auth-web created
# 查看Secret详情:类型为Opaque,包含auth数据(42字节,即认证文件内容)
[root@master service]# kubectl describe secrets auth-web
Name: auth-web
Namespace: default
Labels: <none>
Annotations: <none>
Type: Opaque # 通用类型,可存储任意键值对
Data
====
auth: 42 bytes # 存储的认证数据配置 Ingress 启用 Basic Auth:
bash
# 编辑5-ingress.yml配置文件
[root@master service]# vim 5-ingress.yml
# 查看配置内容
[root@master service]# cat 5-ingress.yml
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: ingress5
annotations:
# 启用Basic Auth认证
nginx.ingress.kubernetes.io/auth-type: basic
# 引用存储认证信息的Secret
nginx.ingress.kubernetes.io/auth-secret: auth-web
# 认证提示信息(用户访问时看到的提示)
nginx.ingress.kubernetes.io/auth-realm: "Please input username and password"
spec:
tls: # 同时保留TLS加密配置
- hosts:
- www.rchjn.com
secretName: web-tls-secret
ingressClassName: nginx
rules:
- host: www.rchjn.com # 对该域名启用认证+HTTPS
http:
paths:
- backend:
service:
name: myappv1
port:
number: 80
path: /
pathType: Prefix
# 应用Ingress配置
[root@master service]# kubectl apply -f 5-ingress.yml
ingress.networking.k8s.io/ingress5 created
# 在hosts文件添加域名映射
[root@master service]# echo "192.168.2.11 www.rchjn.com" >> /etc/hosts
# 测试未认证访问:返回401 Authorization Required,提示需要认证
[root@master service]# curl -k https://www.rchjn.com
<html>
<head><title>401 Authorization Required</title></head>
<body>
<center><h1>401 Authorization Required</h1></center>
<hr><center>nginx</center>
</body>
</html>
# 测试带认证访问:-u指定用户名和密码(rch:123),成功返回v1版本内容
[root@master service]# curl -k https://www.rchjn.com -urch:123
Hello MyApp | Version: v1 | <a href="hostname.html">Pod Name</a>思路:不想让任何人都能访问服务,得设置个用户名密码。步骤就是:用工具生成一个带密码的文件,存在 Secret 里,然后告诉 Ingress "访问这个域名时要检查这个密码文件",这样用户必须输入正确的用户名密码才能访问。
5.3.5 rewrite 重定向
Ingress 的 rewrite 功能可以修改请求的 URL 路径 。例如,将客户端请求的/old-path重写为/new-path后再转发到后端 Service。该功能适用于路径迁移、路径规范化等场景,确保客户端请求能与后端服务的路径规则正确匹配,提升服务的兼容性和可维护性。
简单路径重定向(根路径跳转)
bash
[root@master service]# cp 5-ingress.yml 6-ingress.yml
[root@master service]# vim 6-ingress.yml
[root@master service]# cat 6-ingress.yml
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: ingress5
annotations:
# 根路径重定向注解:访问/时自动跳转到/hostname.html
nginx.ingress.kubernetes.io/app-root: /hostname.html
# 保留认证配置
nginx.ingress.kubernetes.io/auth-type: basic
nginx.ingress.kubernetes.io/auth-secret: auth-web
nginx.ingress.kubernetes.io/auth-realm: "Please input username and password"
spec:
tls:
- hosts:
- www.rewrite.com
secretName: web-tls-secret
ingressClassName: nginx
rules:
- host: www.rewrite.com
http:
paths:
- backend:
service:
name: myappv1
port:
number: 80
path: /
pathType: Prefix
[root@master service]# echo "192.168.2.11 www.rewrite.com" >> /etc/hosts
[root@master service]# kubectl apply -f 6-ingress.yml
# 测试访问根路径:-L跟随重定向,成功跳转到/hostname.html,返回Pod名称
[root@master service]# curl -Lk https://www.rewrite.com -urch:123
myappv1-5c47495d84-7wf98
# 测试访问无效路径:/sd/hostname.html不存在,返回404
[root@master service]# curl -Lk https://www.rewrite.com/sd/hostname.html -urch:123
<html>
<head><title>404 Not Found</title></head>
<body bgcolor="white">
<center><h1>404 Not Found</h1></center>
<hr><center>nginx/1.12.2</center>
</body>
</html>正则表达式路径重写(解决复杂路径问题)
bash
[root@master service]# vim 7-ingress.yml
[root@master service]# cat 7-ingress.yml
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: ingress7
annotations:
# 正则重写规则:将路径中的分组$2作为新路径(例如/rch/xxx重写为/xxx)
nginx.ingress.kubernetes.io/rewrite-target: /$2
# 启用正则匹配
nginx.ingress.kubernetes.io/use-regex: "true"
# 保留认证配置
nginx.ingress.kubernetes.io/auth-type: basic
nginx.ingress.kubernetes.io/auth-secret: auth-web
nginx.ingress.kubernetes.io/auth-realm: "Please input username and password"
spec:
tls:
- hosts:
- www.rewrite.com
secretName: web-tls-secret
ingressClassName: nginx
rules:
- host: www.rewrite.com
http:
paths:
- backend:
service:
name: myappv1
port:
number: 80
# 正则路径:匹配/rch开头的路径,分为两个分组(/或空、剩余部分)
path: /rch(/|$)(.*)
pathType: ImplementationSpecific # 适配正则匹配的路径类型
[root@master service]# kubectl apply -f 7-ingress.yml
ingress.networking.k8s.io/ingress7 created
# 测试正则重写:访问/rch/hostname.html,被重写为/hostname.html,成功返回Pod名称
[root@master service]# curl -Lk https://www.rewrite.com/rch/hostname.html -urch:123
myappv1-5c47495d84-7wf98六 Canary 金丝雀发布
6.1 什么是金丝雀发布
金丝雀发布是一种灰度发布策略 ,源于 "金丝雀测试" 的传统(早期矿工用金丝雀检测矿井气体,提前发现风险)。在软件发布中,它先将新版本部署到少量用户 / 节点 ("金丝雀实例"),验证其稳定性、性能后,再逐步扩大发布范围。这种方式能降低新版本上线的风险,及时发现问题(如 Bug、性能瓶颈),避免全量发布导致的大规模故障。
6.2 Canary 发布方式

其中header和weiht中的最多
6.2.1 基于 header(http 包头)灰度
通过在 HTTP 请求头中添加自定义标识 (如Canary: always),Ingress 或服务网关会将带该标识的请求路由到新版本服务,其余请求仍路由到旧版本。
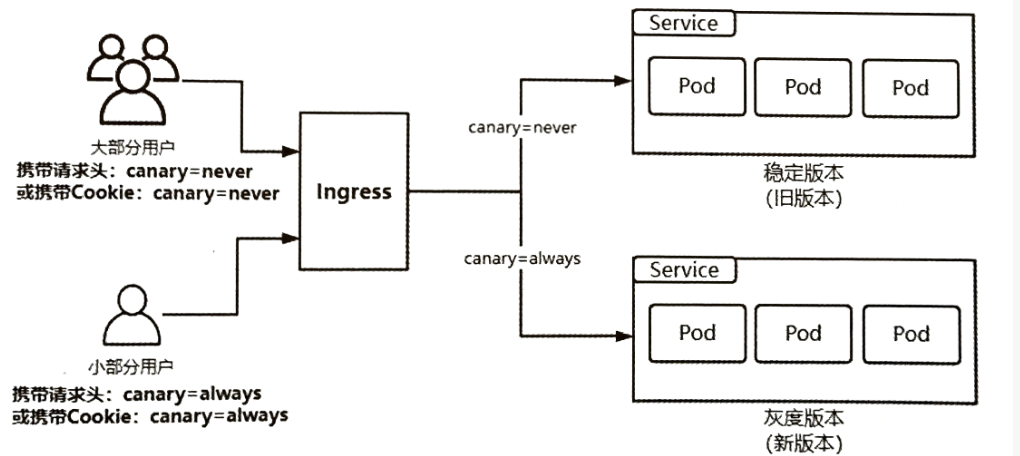
- 通过Annotaion扩展
- 创建灰度ingress,配置灰度头部key以及value
- 灰度流量验证完毕后,切换正式ingress到新版本
- 之前我们在做升级时可以通过控制器做滚动更新,默认25%利用header可以使升级更为平滑,通过key 和vule 测试新的业务体系是否有问题。
建立版本1的ingress
bash
# 建立版本1的基础Ingress(作为默认流量接收方)
[root@master service]# cp 7-ingress.yml 8-ingress.yml
[root@master service]# vim 8-ingress.yml
[root@master service]# cat 8-ingress.yml
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: myapp-v1-ingress # 名称明确为v1版本
spec:
ingressClassName: nginx
rules:
- host: www.rch.com # 与金丝雀Ingress共用域名
http:
paths:
- backend:
service:
name: myappv1 # 指向v1服务
port:
number: 80
path: /
pathType: Prefix
# 应用v1的Ingress
[root@master service]# kubectl apply -f 8-ingress.yml
ingress.networking.k8s.io/myapp-v1-ingress created
# 查看v1的Ingress详情,确认规则正确
[root@master service]# kubectl describe ingress myapp-v1-ingress
Name: myapp-v1-ingress
Labels: <none>
Namespace: default
Address:
Ingress Class: nginx
Default backend: <default>
Rules:
Host Path Backends
---- ---- --------
www.rch.com
/ myappv1:80 (10.244.1.4:80,10.244.2.3:80)
Annotations: <none>
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Sync 12s nginx-ingress-controller Scheduled for sync建立基于 header 的金丝雀 Ingress(新版本流量控制):
bash
# 复制v1的Ingress,修改为v2的金丝雀配置
[root@master service]# cp 8-ingress.yml 9-ingress.yml
[root@master service]# vim 9-ingress.yml
[root@master service]# cat 9-ingress.yml
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: myapp-v2-ingress # 名称明确为v2版本
annotations:
# 标记为金丝雀Ingress
nginx.ingress.kubernetes.io/canary: "true"
# 基于header判断:检查名为version的请求头
nginx.ingress.kubernetes.io/canary-by-header: "version"
# header值为2时,路由到v2服务
nginx.ingress.kubernetes.io/canary-by-header-value: "2"
spec:
ingressClassName: nginx
rules:
- host: www.rch.com # 与v1的Ingress共用域名
http:
paths:
- backend:
service:
name: myappv2 # 指向v2服务
port:
number: 80
path: /
pathType: Prefix
# 应用v2的金丝雀Ingress
[root@master service]# kubectl apply -f 9-ingress.yml
ingress.networking.k8s.io/myapp-v2-ingress created
# 查看v2的Ingress详情,确认金丝雀注解生效
[root@master service]# kubectl describe ingress myapp-v2-ingress
Name: myapp-v2-ingress
Labels: <none>
Namespace: default
Address:
Ingress Class: nginx
Default backend: <default>
Rules:
Host Path Backends
---- ---- --------
www.rch.com
/ myappv2:80 (10.244.1.5:80,10.244.2.4:80)
Annotations: nginx.ingress.kubernetes.io/canary: true
nginx.ingress.kubernetes.io/canary-by-header: version
nginx.ingress.kubernetes.io/canary-by-header-value: 2
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Sync 8s nginx-ingress-controller Scheduled for sync测试基于 header 的灰度:
bash
# 不带header访问:默认路由到v1服务
[root@master service]# curl www.rch.com
Hello MyApp | Version: v1 | <a href="hostname.html">Pod Name</a>
# 带header访问:添加version:2请求头,路由到v2服务
[root@master service]# curl www.rch.com -H "version:2"
Hello MyApp | Version: v2 | <a href="hostname.html">Pod Name</a>思路 :想让测试人员先访问新版本,普通用户继续用旧版本。所以设置两个 Ingress:v1 接收默认流量,v2 作为金丝雀,只接收带version:2请求头的流量。这样测试人员在请求里加个特殊标记,就能访问新版本,其他人不受影响。
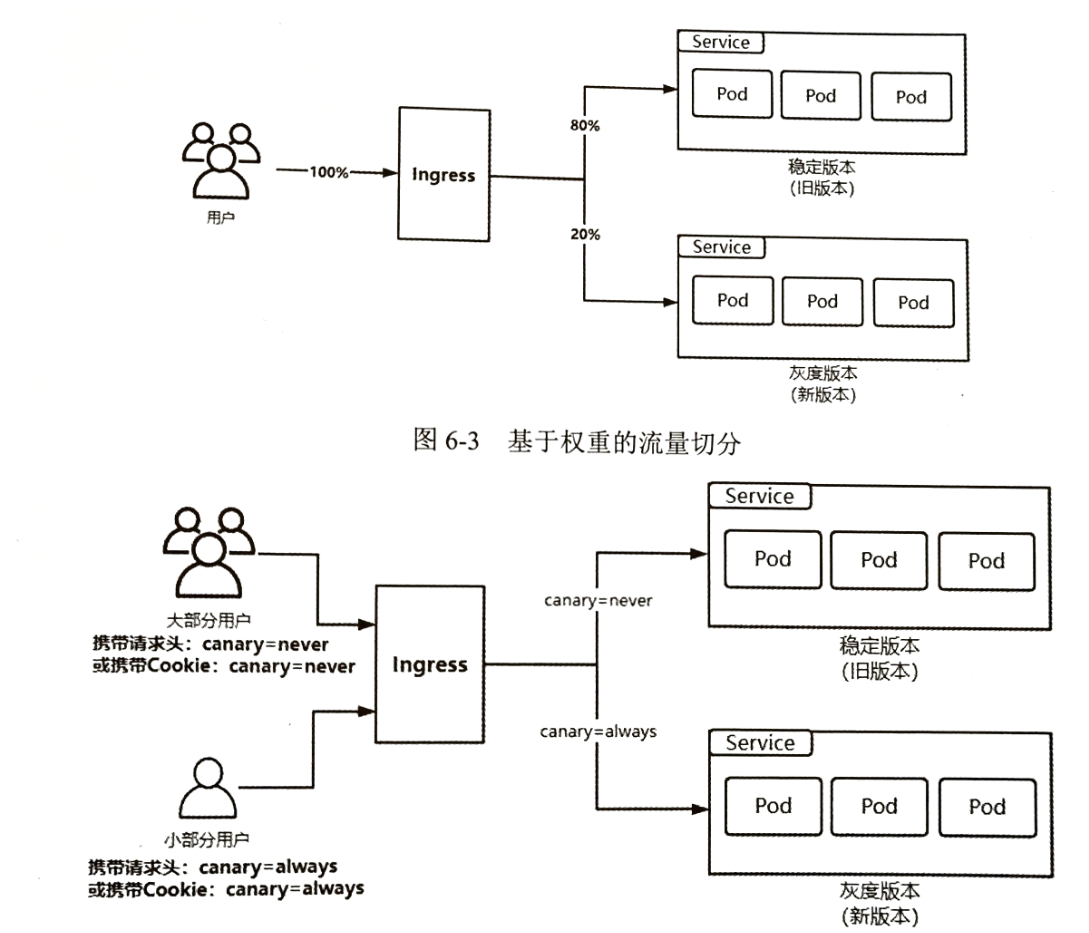
6.2.2 基于权重的灰度发布
为新旧版本服务分配流量权重比例(如旧版本 90%、新版本 10%),K8s 通过 Service 或 Ingress 的流量管理能力,将对应比例的请求转发到新旧版本。
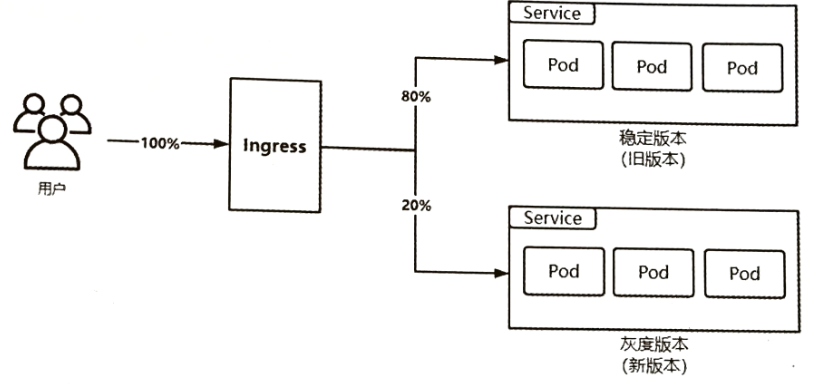
- 通过Annotaion拓展
- 创建灰度ingress,配置灰度权重以及总权重
- 灰度流量验证完毕后,切换正式ingress到新版本
bash
# 修改9-ingress.yml,配置基于权重的金丝雀
[root@master service]# vim 9-ingress.yml
[root@master service]# cat 9-ingress.yml
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: myapp-v2-ingress
annotations:
nginx.ingress.kubernetes.io/canary: "true" # 仍为金丝雀Ingress
nginx.ingress.kubernetes.io/canary-weight: "10" # 新版本接收10%流量
nginx.ingress.kubernetes.io/canary-weight-total: "100" # 总权重100
spec:
ingressClassName: nginx
rules:
- host: www.rch.com
http:
paths:
- backend:
service:
name: myappv2
port:
number: 80
path: /
pathType: Prefix
# 应用修改后的配置
[root@master service]# kubectl apply -f 9-ingress.yml
ingress.networking.k8s.io/myapp-v2-ingress created写个脚本来测试一下
bash
# 创建测试脚本check.sh
[root@master service]# vim check.sh
[root@master service]# cat check.sh
#!/bin/bash
read -p "请输入要测试的次数:" count # 接收用户输入的测试次数
v1=0 # 统计v1版本的响应次数
v2=0 # 统计v2版本的响应次数
# 循环发送请求
for ((i=1;i<=$count;i++))
do
# 发送请求并检查响应中是否包含v1(-s静默模式,不输出额外信息)
response=$(curl -s www.rch.com |grep -c v1)
if [ $response -eq 1 ] # 如果包含v1,v1计数+1
then
((v1++))
else # 否则为v2,v2计数+1
((v2++))
fi
done
# 输出统计结果
echo "v1版本有$v1次,v2版本有$v2次"
# 测试100次:v2约占10%
[root@master service]# sh check.sh
请输入要测试的次数:100
v1版本有94次,v2版本有6次 # 接近10%比例(误差由概率导致)
# 测试1000次:v2更接近10%
[root@master service]# sh check.sh
请输入要测试的次数:1000
v1版本有900次,v2版本有100次
# 修改权重为80(v2接收80%流量)
[root@master service]# kubectl edit -f 9-ingress.yml
nginx.ingress.kubernetes.io/canary: "true"
nginx.ingress.kubernetes.io/canary-weight: "80" # 改为80%
nginx.ingress.kubernetes.io/canary-weight-total: "100"
# 测试100次:v2约占80%
[root@master service]# sh check.sh
请输入要测试的次数:100
v1版本有23次,v2版本有77次
# 测试1000次:更接近80%
[root@master service]# sh check.sh
请输入要测试的次数:1000
v1版本有204次,v2版本有796次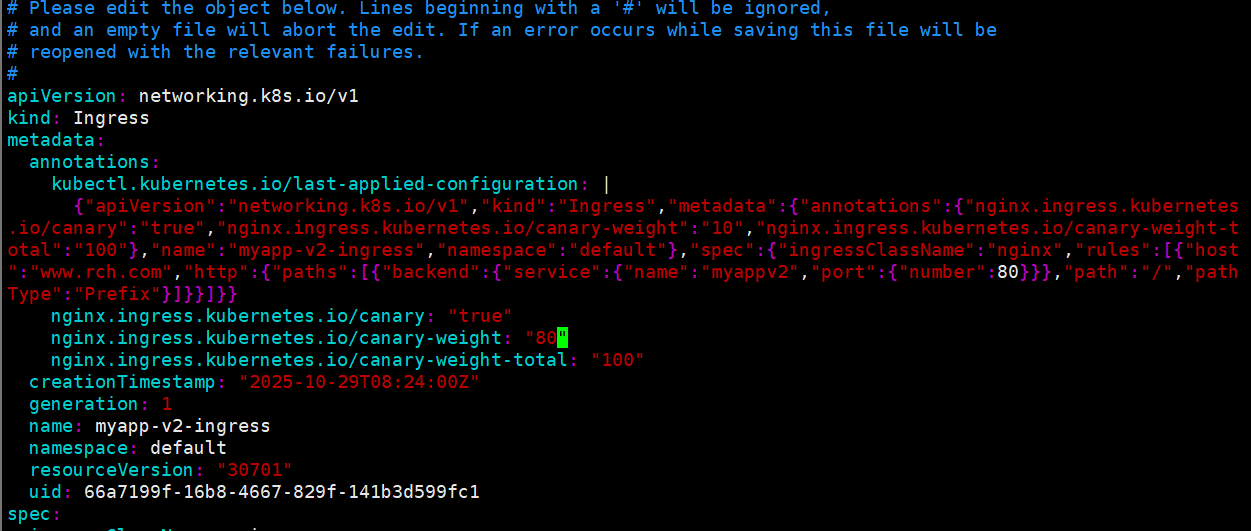
思路:想慢慢把用户流量切到新版本,先让 10% 的用户用新版本,没问题再升到 80%,最后全量切换。所以在金丝雀 Ingress 里配置权重,比如 10% 就表示 10% 的请求去 v2,90% 去 v1,用脚本多测几次,就能看到流量确实按比例分配了。