一、背景
ai编程场景里,文本转语音,可以使用第三方的云服务,需要收费。(天下没有免费的午餐)
如果你想要自己做一些实验,而又不想付费,可以自己部署一套系统。
推荐index-tts,原因是它有成熟的docker部署方案,其次它支持模仿真人的音色。
很好地适用于听书等音频制作,不过想要免费部署,要求的配置高,特别是内存。
二、docker部署
bash
docker run -d --name index-tts \
--platform linux/amd64 \
-p 7860:7860 \
-v ~/index-tts-data:/app/data \
--shm-size=2g \
luojiecong/index-tts:1.5-20250727-9098497第一次,因为内存不足,运行出错。
bash
2025-11-14 08:52:58,434 WETEXT INFO building fst for zh_normalizer ...
/tmp/tmpi7r4wi67: line 3: 35 Killed python webui.py --model_dir /checkpoints --host 0.0.0.0 --port 7860
ERROR conda.cli.main_run:execute(127): `conda run python webui.py --model_dir /checkpoints --host 0.0.0.0 --port 7860` failed. (See above for error)我本机是采用docker desktop桌面版,机器是mac book pro m3,内存仅18G。
这里调大些资源配置,主要是内存,我这里指定申请6G内存。
bash
docker run -d --name index-tts \
--platform linux/amd64 \
-p 7860:7860 \
-v ~/index-tts-data:/app/data \
--memory=12g --memory-swap=12g \
--shm-size=2g \
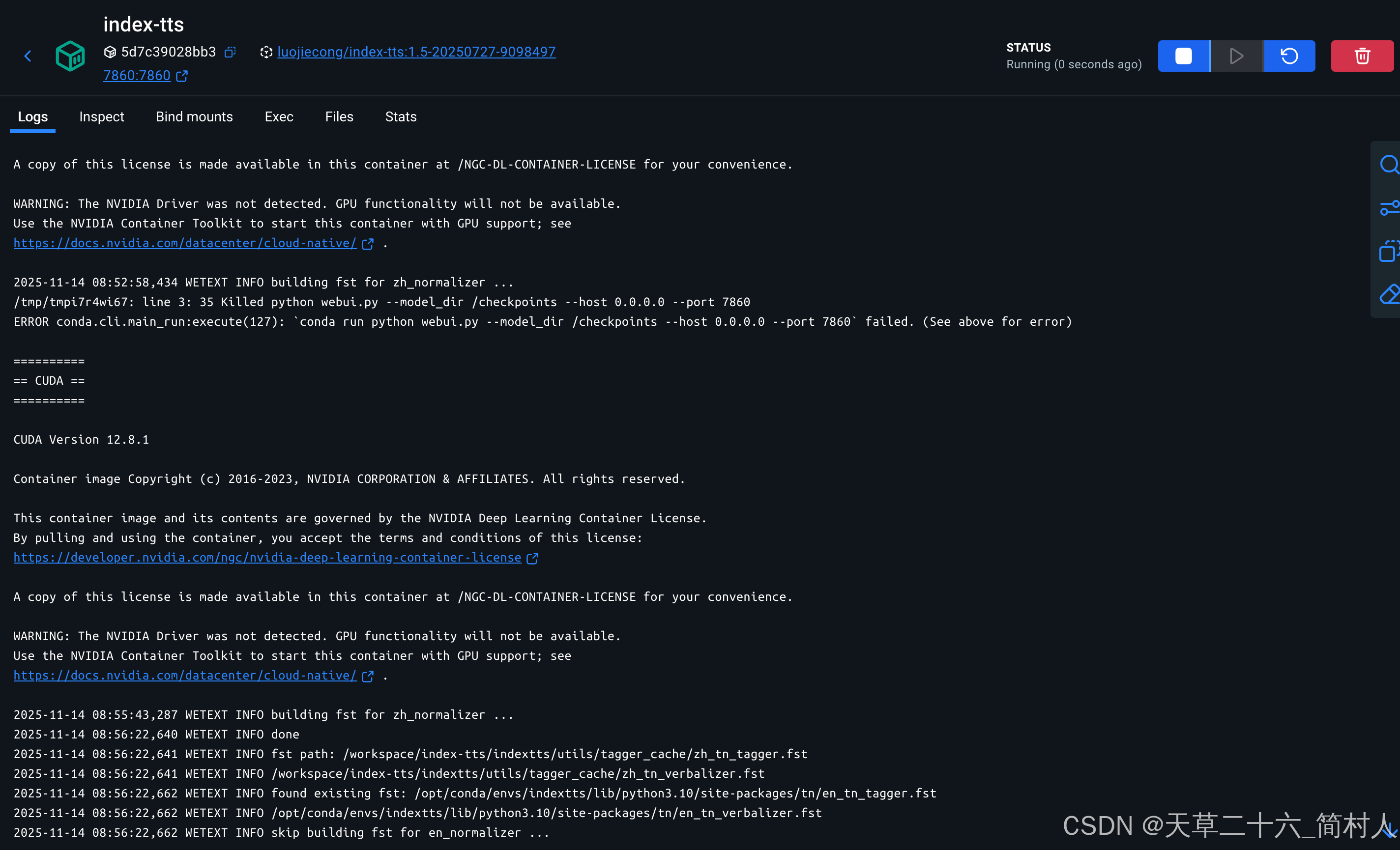
luojiecong/index-tts:1.5-20250727-9098497再次运行。
bash
2025-11-14 08:55:43,287 WETEXT INFO building fst for zh_normalizer ...
2025-11-14 08:56:22,640 WETEXT INFO done
2025-11-14 08:56:22,641 WETEXT INFO fst path: /workspace/index-tts/indextts/utils/tagger_cache/zh_tn_tagger.fst
2025-11-14 08:56:22,641 WETEXT INFO /workspace/index-tts/indextts/utils/tagger_cache/zh_tn_verbalizer.fst
2025-11-14 08:56:22,662 WETEXT INFO found existing fst: /opt/conda/envs/indextts/lib/python3.10/site-packages/tn/en_tn_tagger.fst
2025-11-14 08:56:22,662 WETEXT INFO /opt/conda/envs/indextts/lib/python3.10/site-packages/tn/en_tn_verbalizer.fst
2025-11-14 08:56:22,662 WETEXT INFO skip building fst for en_normalizer ...这次终于运行正常。
配置低,在文本转语音的时候,有个明显吃亏的地方是,转换时长久。
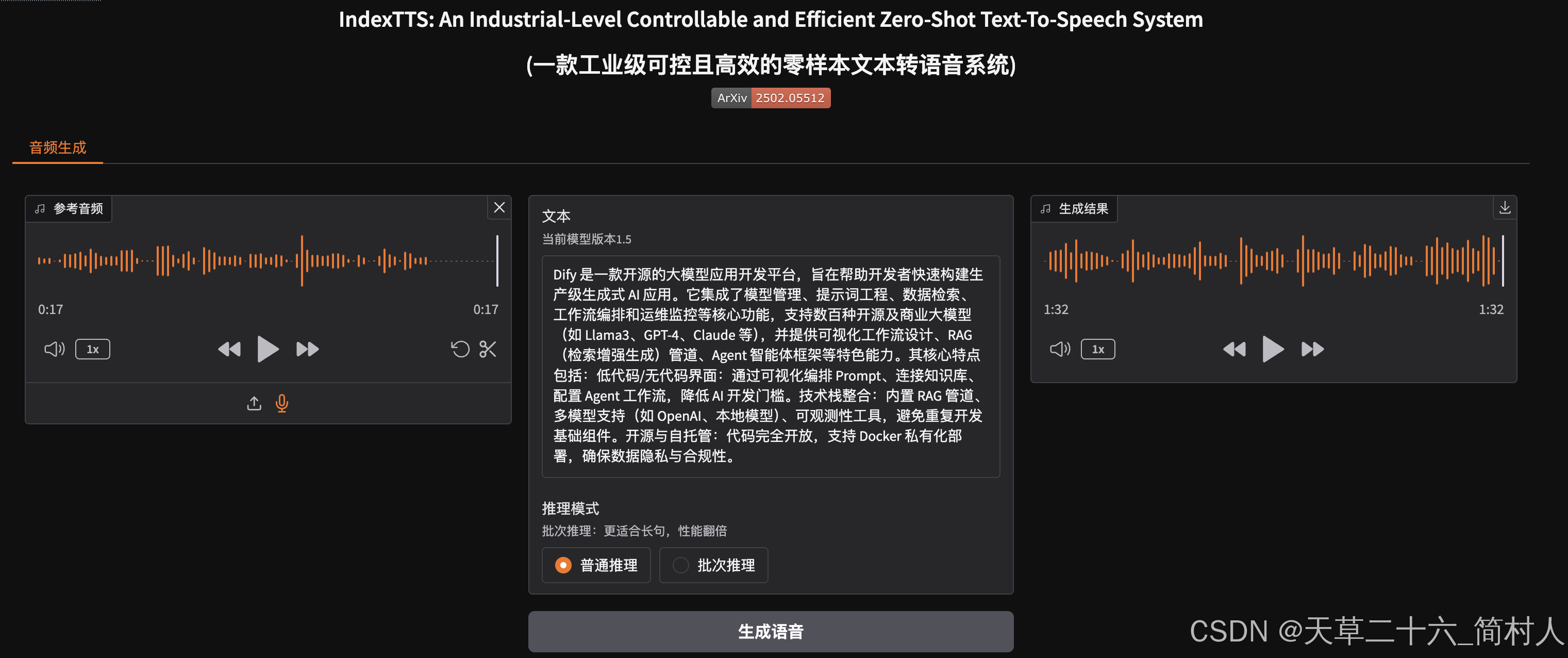
参考音频,就是你自己上传或者录制的声音。
生成的音频就会根据前者,对文本进行转换至语音。
三、API编程
见UI底部,你可以详细查看其API接口。这里就不往后延伸。
http://localhost:7860/?view=api
你也可以通过mcp对接index-tts。
四、总结
在选择index-tts前,我还动手部署了一把spark-tts,当然还是采用docker部署。
发现要打开文本转语音的UI界面,难于登天,尝试了好几个镜像,无论是lite版本还是full版本,都无济于事。
因为不想让你去踩坑,就不细描述当时是如何部署spark-tts了。
没有UI界面,打开了其swagger文档http://localhost:7860/docs
spark-tts的镜像地址:https://hub.docker.com/r/breakstring/spark-tts
下载并安装:
bash
docker run -d --name spark-tts \
--platform linux/amd64 \
-p 7860:7860 \
-v ~/spark-tts-data:/app/data \
--shm-size=2g \
breakstring/spark-tts:latest-lite