集群概念
单机场景
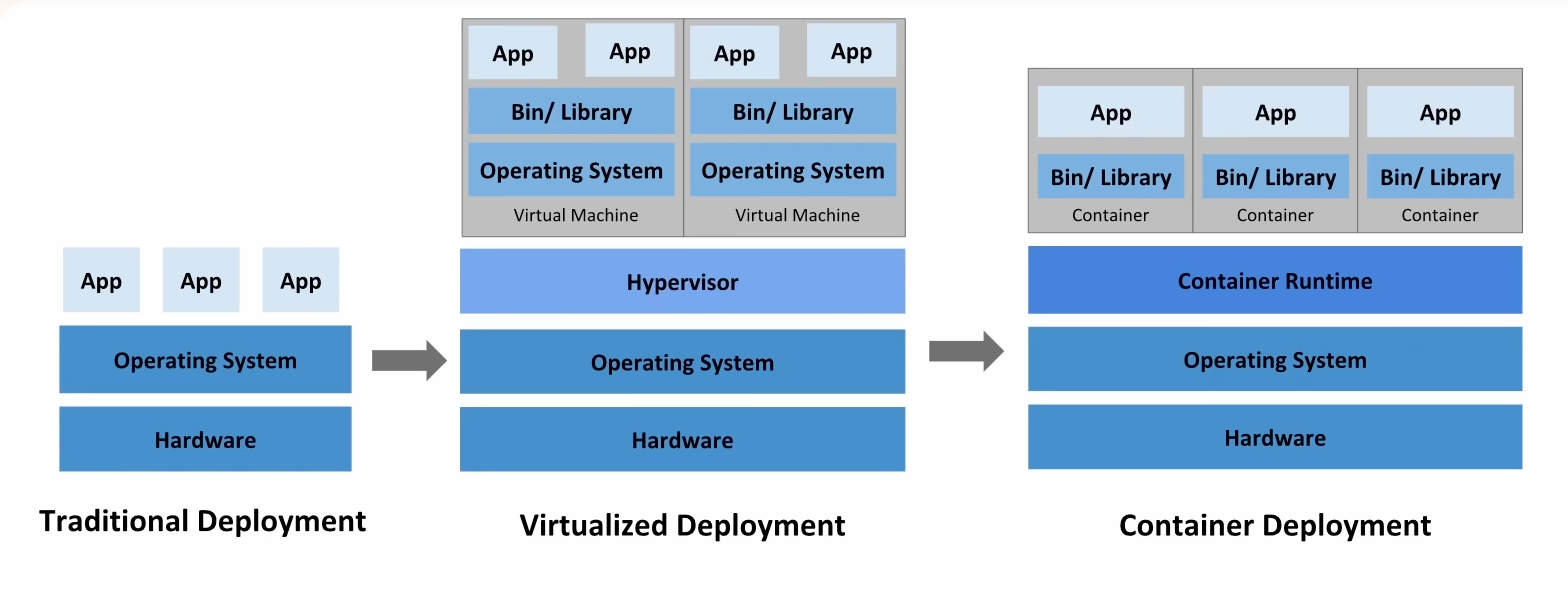
传统部署------》 硬件 ------》操作系统------》软件应用
- 快速部署
- 不够安全,软件相互影响
虚拟化部署------〉硬件------》操作系统 ------〉虚拟化集成------》虚拟机 1、虚拟机 2...
- 虚拟机相对独立,安全性更高
- 因为相对独立,每个虚拟机都有一个操作系统、资源消耗的不可控
容器化部署------》硬件------〉操作系统------》容器------〉容器
- 相对传统更安全
- 资源效率最高
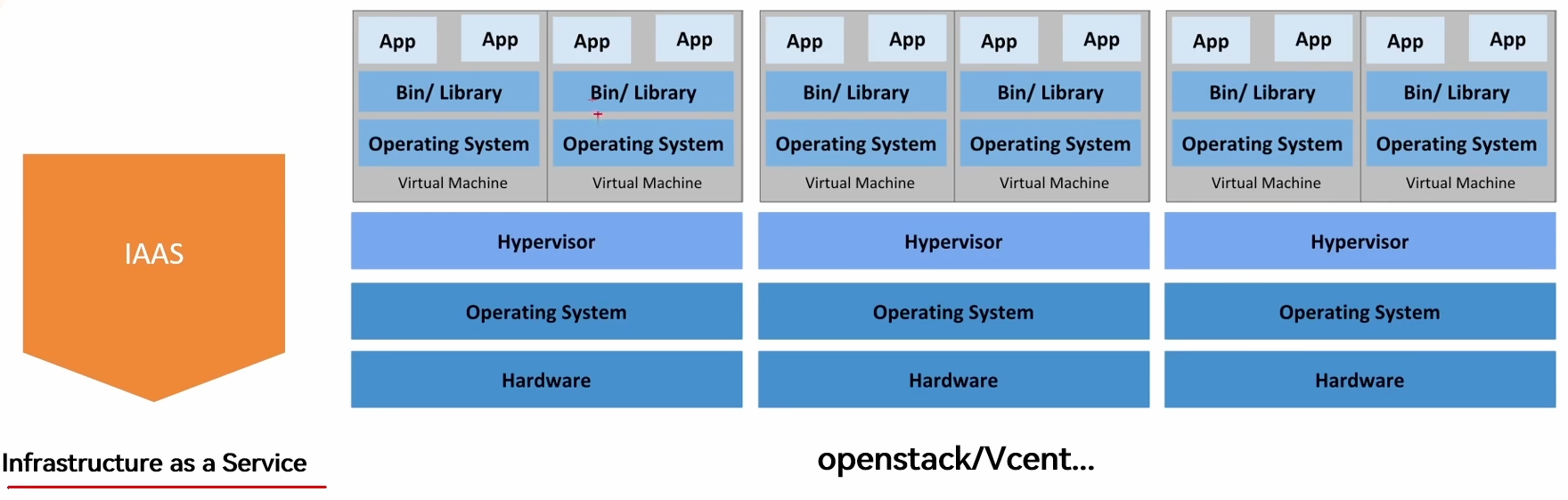
集群场景 IaaS
Infrastructure as a Service
基础架构即服务
用户能从中申请到硬件或虚拟硬件,包括裸机或虚拟机,然后在上边安装操作系统或其他应用程序
OpenStack 自动从机房服务器中寻找资源充裕的机器,在上面部署虚拟机,给用户
几大上游云服务商垄断、平台越大、成本越低、技术越深
通过虚拟机实现、openStack、VCenter 等
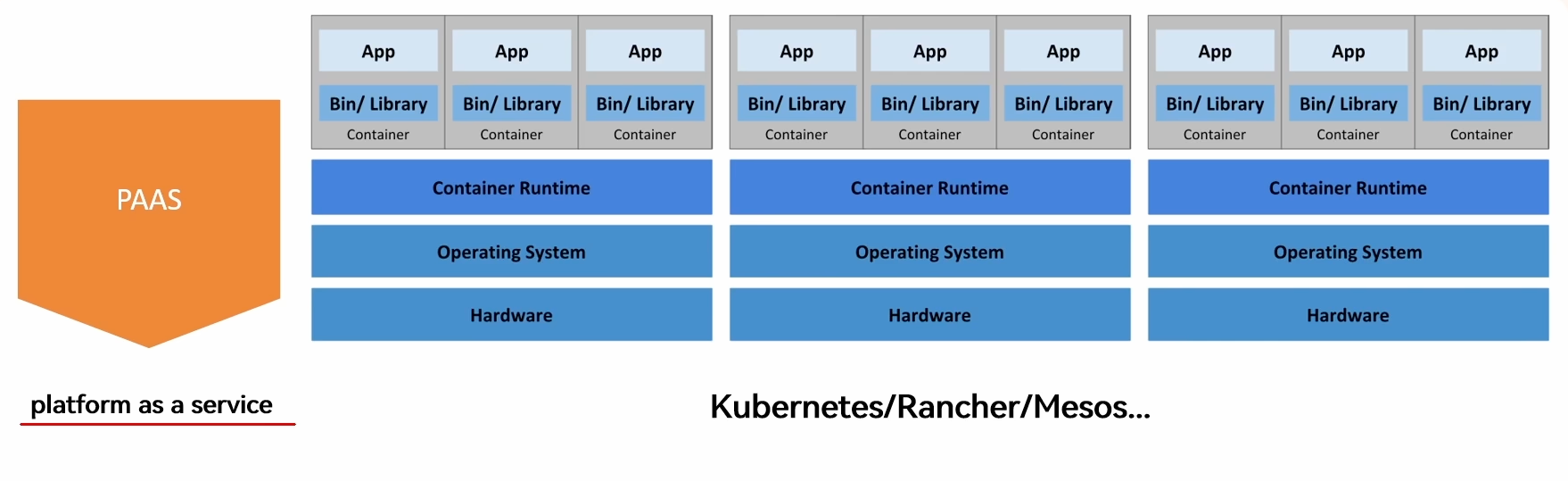
集群场景 PaaS
Platform as a Service
用户能从中申请到一个安装了操作系统以及支撑应用程序运行所需要的运行库等软件的物理机或虚拟机,然后在上边安装其他应用程序,但不能修改已经预装好的操作系统和运行环境。
通过容器实现、K8s、OpenShift 等
集群场景 SaaS
Software as a Service
软件即服务
用户可以通过网络以租赁的方式来使用,比如在线 office、邮箱服务等,全部由服务商提供

PaaS 平台对比
Docker Swarm
docker 官方提供,学习成本低,方便、功能性差,需要二次开发
MESOS
Apache Mesos
基本没人用了
kubernetes
谷歌
- 服务发现、负载均衡
- 存储编排
- 自动部署和回滚
- 自动分配 CPU/内存资源-弹性伸缩
- 自我修复(需要时、丢掉旧容器,启新容器,成本很低)
- Secret 相关配置
- 大型规模支持(单个节点 Pod 数量 110、节点数不超过 5000、Pod 总数不超过 150000、容器总数不超过 300000)
- 开源
Kubernetes
Kubernetes 架构
宏观
- Master(节点)
- Node(作业)
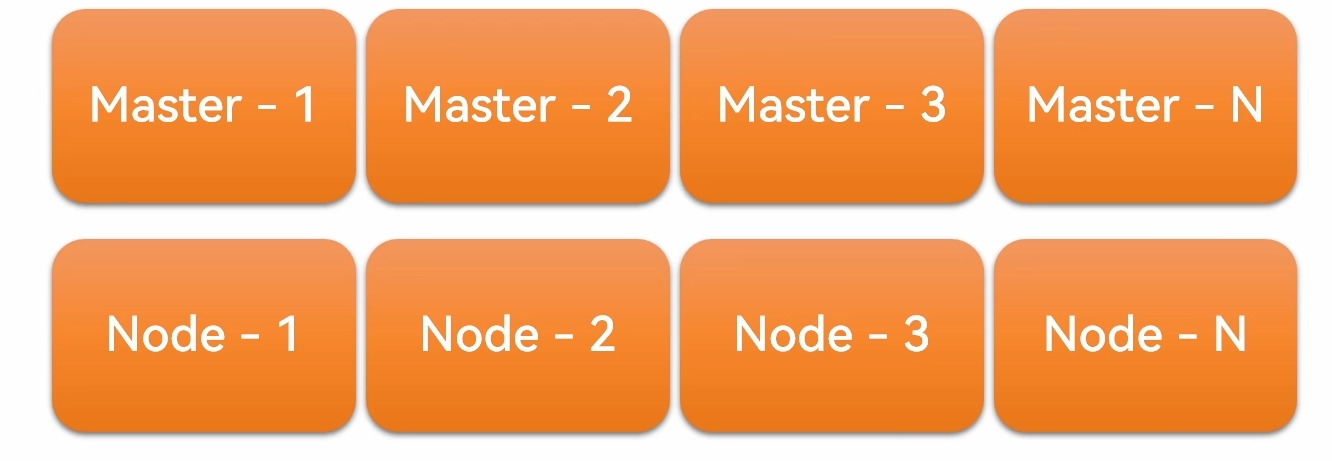
微观
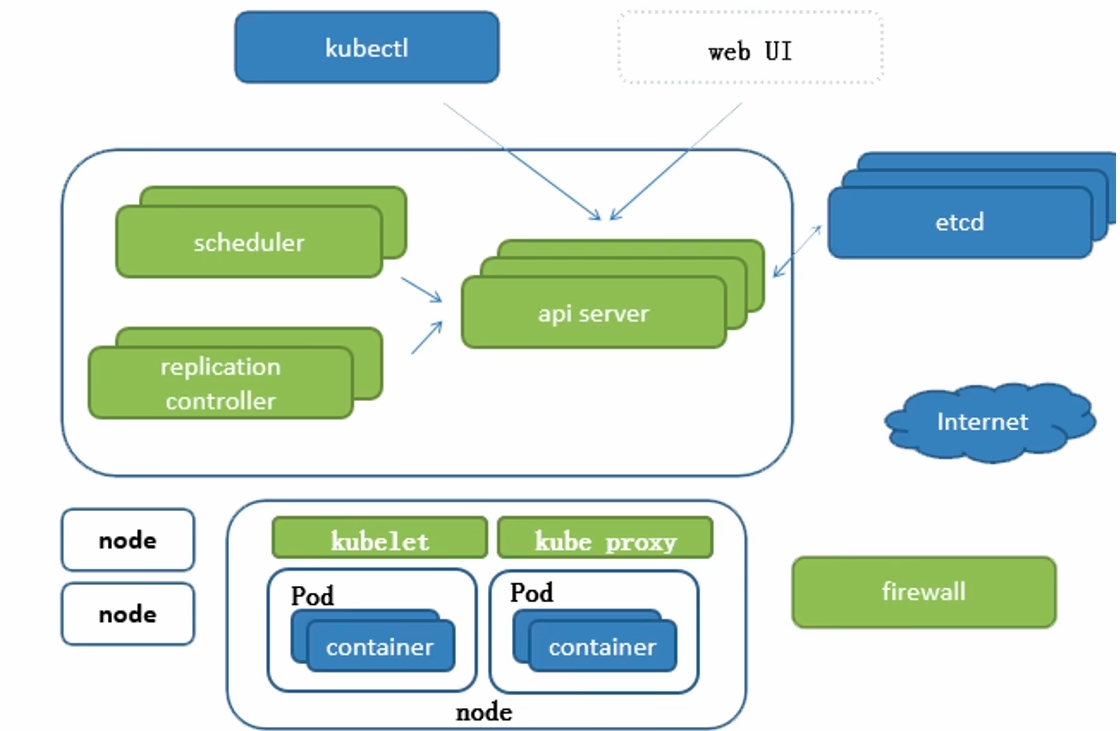
master 组件
APi-server
RESTful 是一种概念,不是一种技术

认证、鉴权、准入控制
etcd
键值对数据库
当前集群的信息配置、参数都会放在这里
scheduler
调度器
调度器绑定容器,由调度器使用 apiserver 调 etcd 配置
Controller mannager(replication controller,RC)
控制器
持续从 API Server(间接就是 etcd)监听资源变化事件
node 组件
kubelet
调用,docker、podman 等其它 CRI 容器运行时
kube proxy
节点网络、负载均衡问题
Pod
容器组,最小调度单元,包含一个以上容器,共享网络命名空间(IP、端口)、存储卷、生命周期(一起创建、一起销毁)
container
容器
插件
Docker
- 容器
CoreDNS
- 私有域名解析服务
Ingress Controller
- 7 层负载均衡功能
...
附件
Prometheus
- 普罗米修斯
Dashboard
- 仪表盘
Federation
- 多集群管理能力
...
Pod 概念
容器组

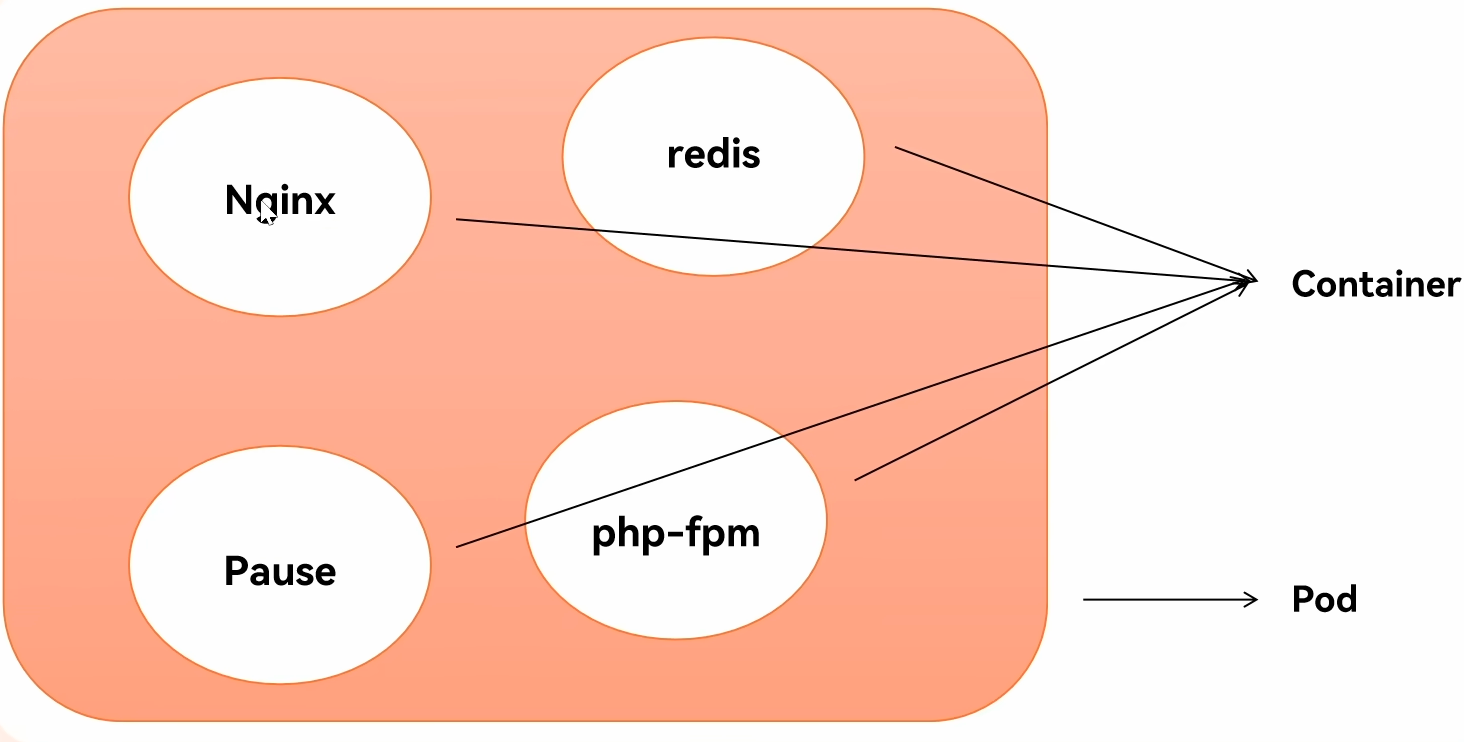
Pause 容器
- Pos 内部第一个启动的容器
- 它启动后初始化 网络栈
- 挂在需要的存储卷
- 回收僵尸进程
一个 Pod 内的容器,命名空间(namespace(Network、PID、IPC 等))
具体的实现是由 Pause 实现
Pod 是逻辑概念、是一个概念
即使你不实用 k8s,就使用原生的 docker 也可以使用 pod 这个概念
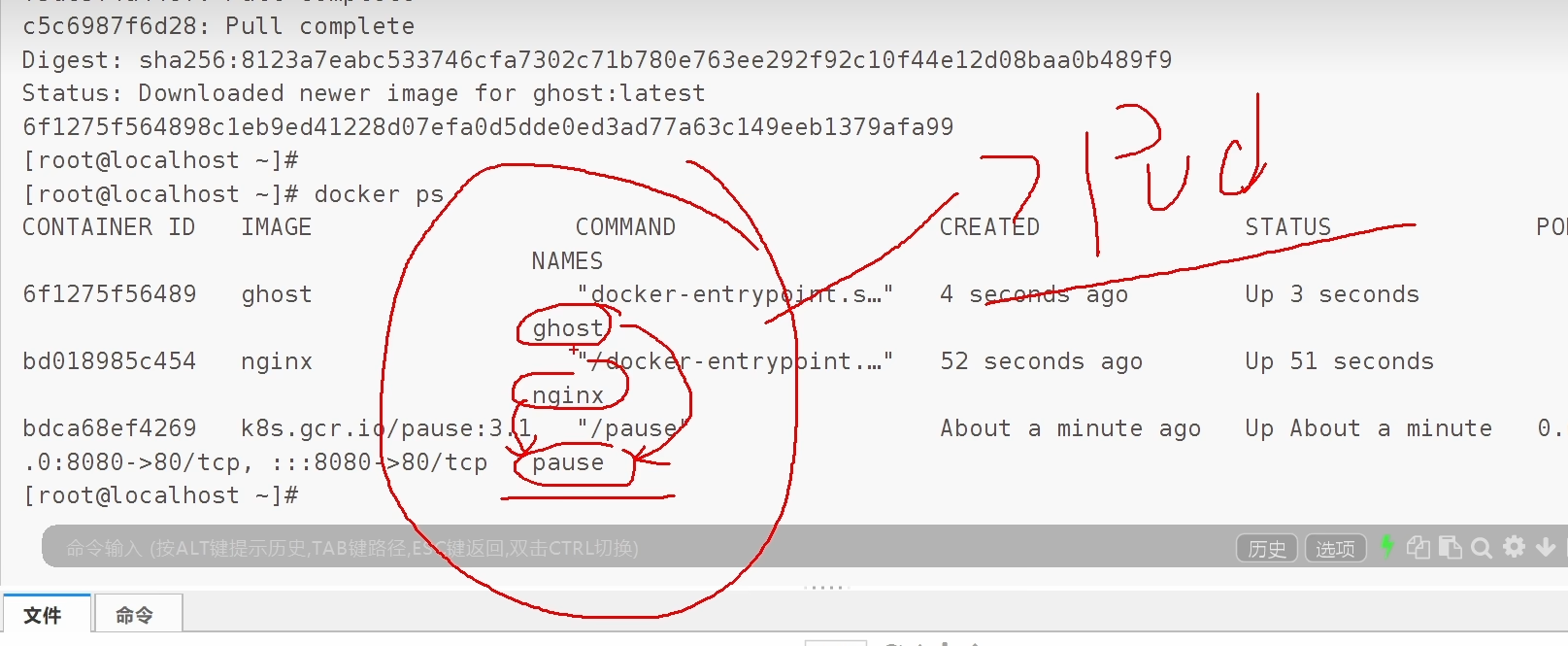
比如一个项目,nignx 做反代、一个 ghost 跑 web 服务、在引入一个 pause,这就是可以看作一个 pod
pause 最先启动,然后启动 nginx,在启动 ghost 博客
nginx 反代到 ghost
docker 原生支持以 container name 的方式进行网络通信,但是本质还是两个容器
ghost 与 nginx 两个的 network、pid、ipc、都共享给 pause,这让两个容器相当于是一个主机的概念,所以 nignx.conf 的反向代理,代理的是本地 127.0.0.1 的地址。
用 pause 是为了稳定,docker 原生支持,如果其中一个容器死了,那整个系统就跟着死了
- 使用 pause 更加稳定
- pause 有回收僵尸进程的功能,其它容器默认没有
K8s 网络
跟 docker 类似,扁平网络空间
网络模型原则
- 在不使用 NAT 的情况下,集群中的 Pod 能够与任意其它 Pod 进行通信
- 在不使用 NAT 的情况下,在集群节点上运行的程序能与同一节点上的任意 Pod 进行通信
- 每个 Pod 都有自己的 IP 地址,并且任意其它 Pod 都可以通过相同的这个地址访问
CNI 标准
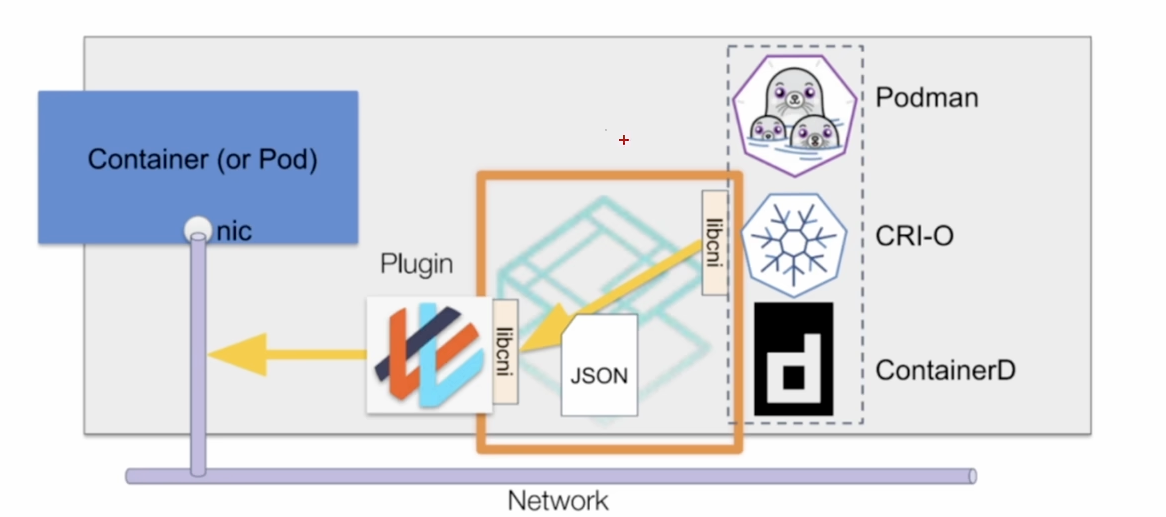
CNI 接口是指可执行程序的调用,k8s 节点默认 CNI 插件路径是 /opt/cni/bin
CNI 通过 json 格式配置网络配置,由容器运行时负责执行 CNI 插件,通过 CNI 插件的标准输入(stdin)来传递配置文件信息,通过标准输出(stdout)接收插件的执行结果,从网络插件功能分五类:

Main 插件
创建具体的网络设备
- bridge:桥接,连接 container 和 host
- ipvlan:为容器增加 ipvlan 网卡;
- loopback:io 设备
- macvlan:为容器创建一个 MAC 地址
- ptp:创建一对 VethPair
- vlan:分配一个 vlan 设备
- host-device:将已存在的设备移入容器内
IPAM 插件
负责分配 IP 地址
- dhcp:容器向 DHCP 服务器发起请求,给 Pod 发放或回收 IP 地址
- host-local:使用预先配置的 IP 地址段来进行分配
- static:为容器分配一个静态 IPv4/IPv6 地址主要用于 debug
META 插件
其它功能插件
- tuning:通过 sysctl 调整网络设备参数
- portmap:通过 iptables 配置端口映射
- bandwidth:使用 Token Bucket Filter 来限流
- sbr:为网卡设置 source basedrouting
- firewall:通过 iptables 给容器网络的进出流量进行限制
Windwos 插件
专门为 Windows 平台的 CNI 插件
- win-bridge
- win-overlay
第三方网络插件
Flannel
Calico
Clium
OVN
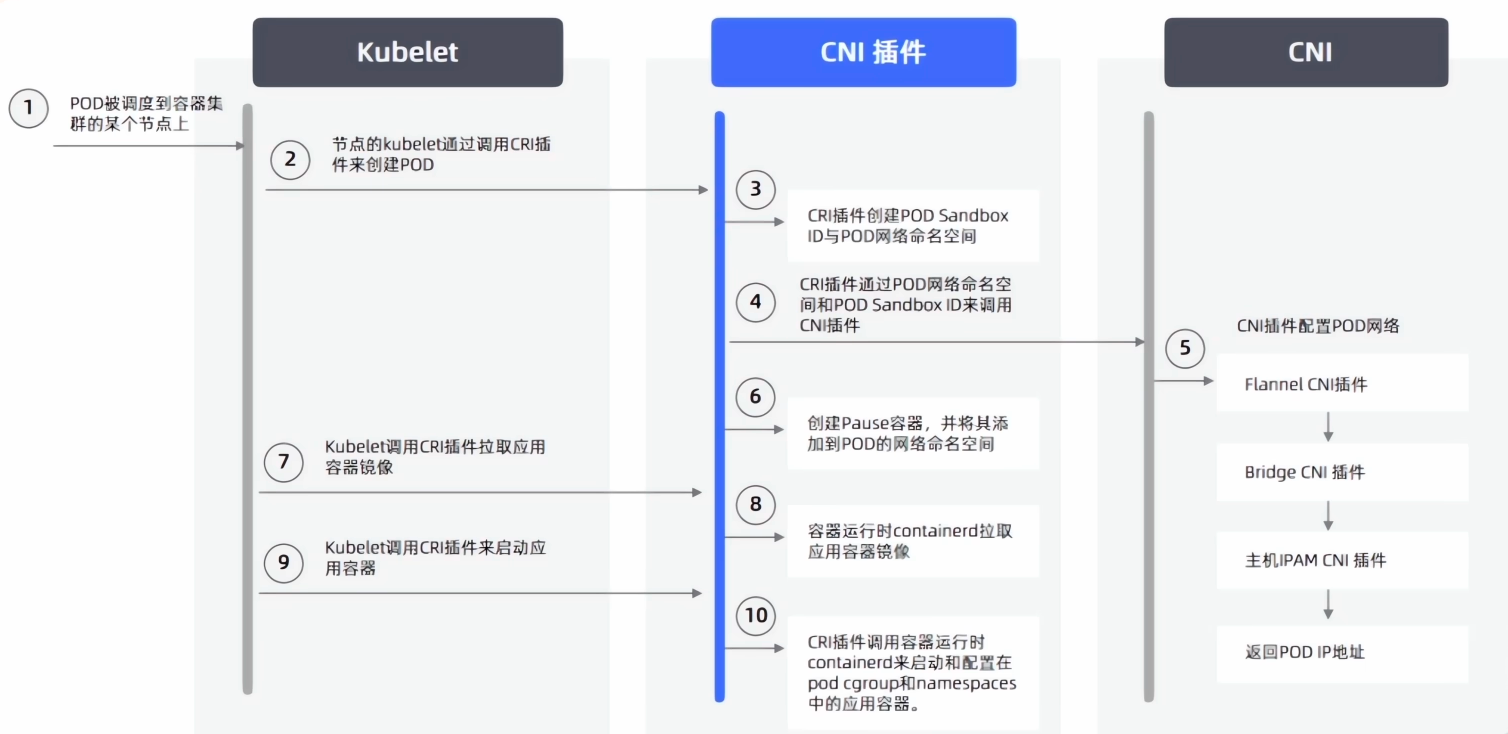
谷歌原生的 GCE 给 k8s 扁平化网络做了兼容优化,但是我们在阿里云或者本地 itc 机房环境下,只能使用网络插件来实现扁平化网络的构建,主要是用 flannel、canal、calico 等,它们都是开源的
flannel
calico
cilium
插件的能力
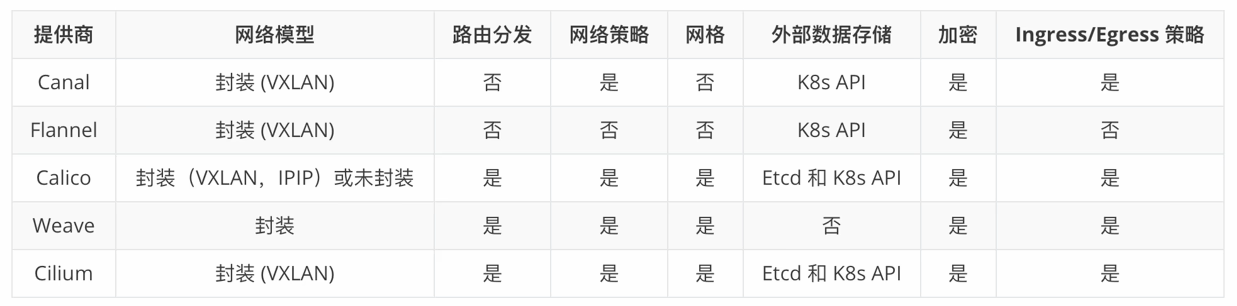
网格模型
underlay network(非封装网络)
- 显示的物理基础层网络设备
- underlay 就是数据中心场景的基础物理设施,保证任何两个点路由可达,其中包含了传统网络技术
overlay network(封装网络)
- 一个基于物理网络之上构建的逻辑网络
- overlay 是一种网络架构上叠加的虚拟化技术模式,TRILL、VxLan、GRE、NVGRE 等隧道
非封装网络
10.42.0.2pod 地址------》docker0------〉bgp 学习到的路由------》192.168.34.10------〉192.168.34.11------》docker0)------〉10.42.1.2
全是物理转发
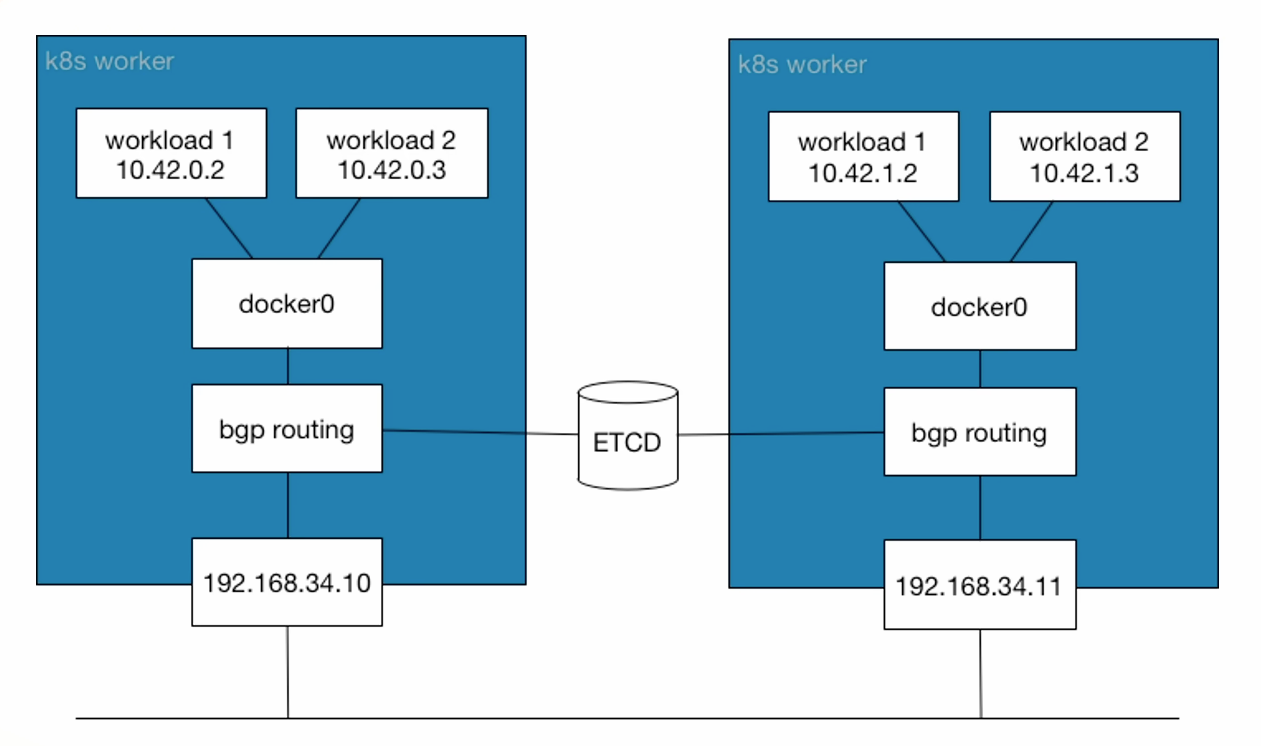
封装网络
10.42.0.2pod 地址------》docker0------〉flanneld 封装,封装为当前 node 的物理地址------》封装后的地址为 192.168.34.10------〉192.168.34.11------》flanneld 解封装,发现地址是 10.42.1.2------〉 docker0------〉10.42.1.2
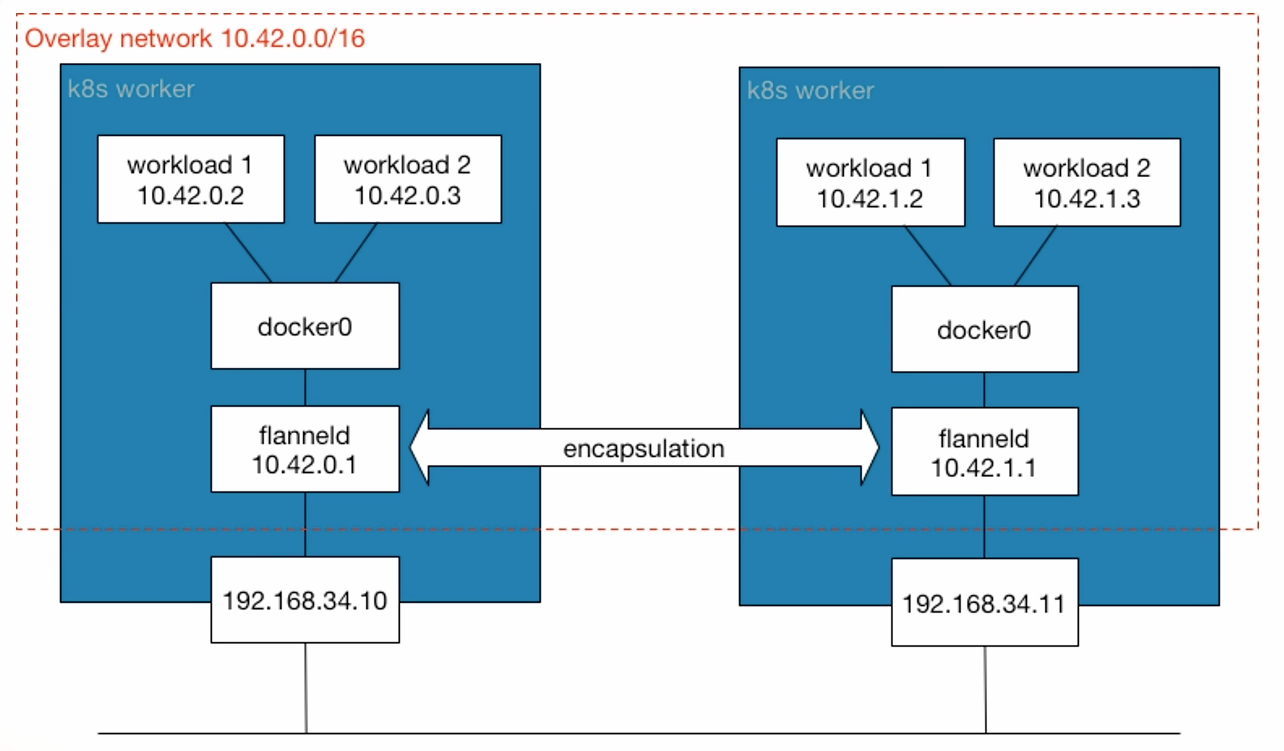
ps:k8s 的 pod 不一定用 docker0 网桥,CNI 会自己创建接口
路由分发
一种外部网关协议,用于在互联网上交换路由和可达信息。BGP 可以帮助进行集群 pod 之间的网络。此功能对未封装的 CNI 网络插件是必须的,并且通常有 BGP 完成。
网络策略
因为 Flannel 不支持,后逐渐被淘汰,现大部分业务都用 Calico,就是字面意思
网格
允许在不同 Kubernetes 集群间进行 service 之间的网络通信
外部数据存储
具有此功能的 CNI 网格插件需要一个外部数据存储来存储数据,一般用 k8sapi
加密
允许加密通信
Ingress/Egress 策略
管理 K8s 和非 K8s 通信
Calico
calico 架构
纯三层虚拟网络,没有复用 docker 的 docker0 网桥,是自己实现的,可以不对数据包进行额外的封装,不需要 NAT 和端口映射,也可以封装。
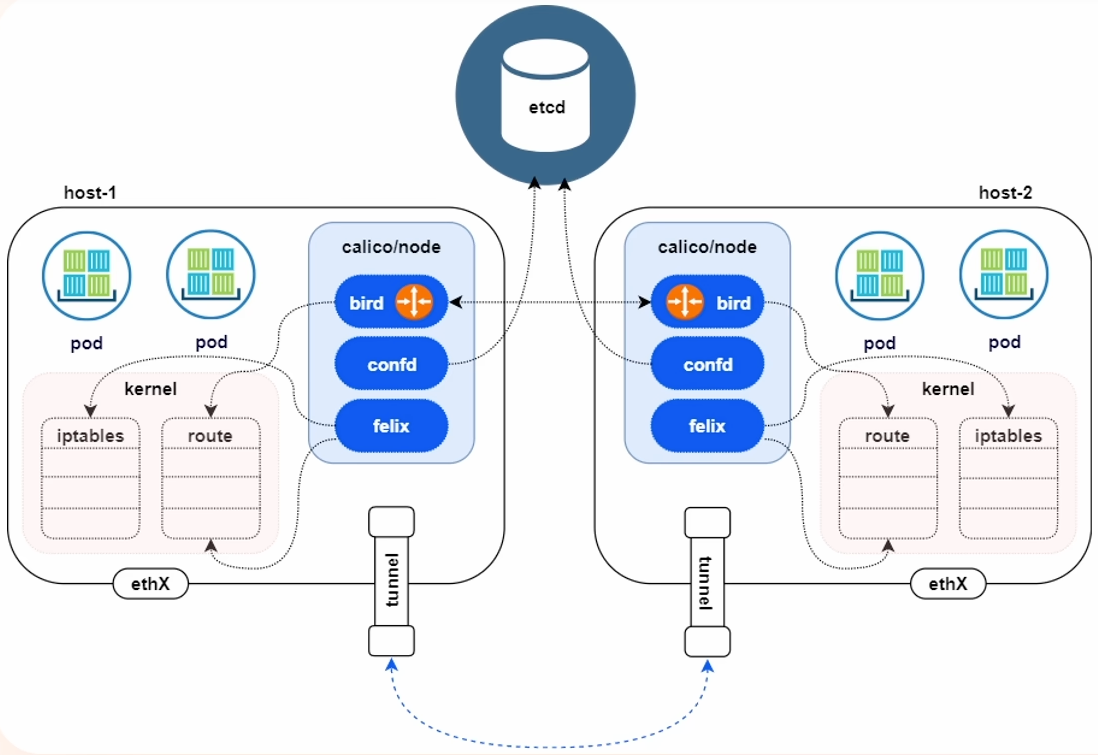
Felix
- 管理网络接口
- 编写路由
- 编写 ACL
- 报告状态
bird(BGP Clenet)
- BGPClient 将通过 BGP 协议广播告诉其它的 calico 节点,从而实现网络互通
confd
- 通过监听 etcd 以了解 BGp 配置和全局默认值的更改。Confd 根据 ETCD 中数据的更新,动态生成 BIRD 配置文件。
BGP
Calico 默认是基于 BGP 的
非封装

优点
性能较好,非封装
缺点
跨网段配置配置较为麻烦,需打通整个多广播域网络
VXLAN
Calico 基于 Vxlan 模式
虚拟可拓展局域网,是 Linux 本身支持的一种网络虚拟化技术。Vxlan 可以完全在内核态实现封装和解封装工作,通过隧道机制,实现封装网络
基于三层的"二层"通信,在二层通过 MAC 寻址通信,三层用于跨节点通信
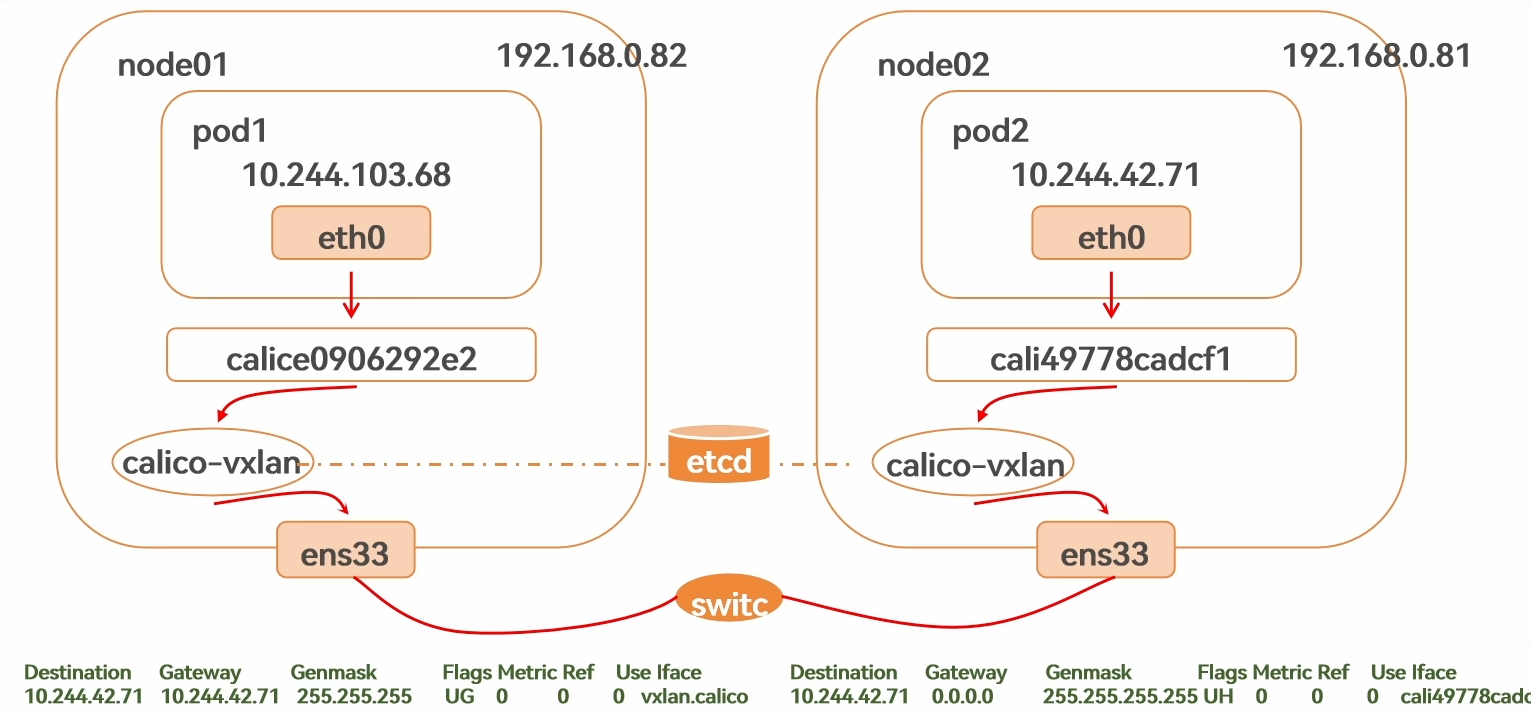
vxlan 封装的是自己的 MAC 信息和对方的 MAC 地址信息

基于三层的"二层"实现
封包:在 vxlan 设备上将 pod 发来的数据包源、目的 mac 替换为本机的 vxlan 网卡和对端点点 vxlan 网卡的 mac 地址。外层 udp 目的 ip 地址根据路由和对端 vxlan 的 mac 查 fdb(mac、ip 对应表) 表获取
-
Pod 发出的原始二层帧
- 源 MAC = Pod 的虚拟网卡 MAC
- 目的 MAC = 目标 Pod 的 MAC
- 内层 IP 包 = Pod 的源 IP → 目标 Pod 的 IP
-
VXLAN 设备进行封装
- 源 MAC = 本机 VTEP 的 MAC
- 目的 MAC = 对端 VTEP 的 MAC(通过 FDB 表查询)
- 外层 UDP 目的 IP = 对端 VTEP 的 IP(通过 FDB 表查询)
-
Pod 发出的是三层包(IP)
- 源 ip = Pod 的 ip
- 目的 ip = 目标 Pod 的 ip
-
VXLAN 设备进行封装
- 源 MAC = Pod 的虚拟网卡 MAC
- 目的 MAC = 目标 Pod 的 MAC(通过 ARP 或邻居表获取目标 MAC)
-
在封装 VXLAN
- 外层源 MAC = 本机 VTEP 的 MAC
- 外层目的 MAC = 对端 VTEP 的 MAC(通过 FDB 表查询)
- 外层 UDP 目的 IP = 对端 VTEP 的 IP(通过 FDB 表查询)
不管是二层以太网帧还是三层数据包,都会进行封装,且只发三层包的情况很少,理论上都需要遵循 osi 模型进行通信,这里列出来只是说明这种概念,这是 VXLAN 的核心
优点
对主机网关路由没有特殊要求
缺点
理论上存在一定性能损耗,因为封包与解包
IPIP
Linux 原生内核支持
相比 vxlan 相对简单,将当前 ip 封装到新的 ip 包当中,所以叫 ipip
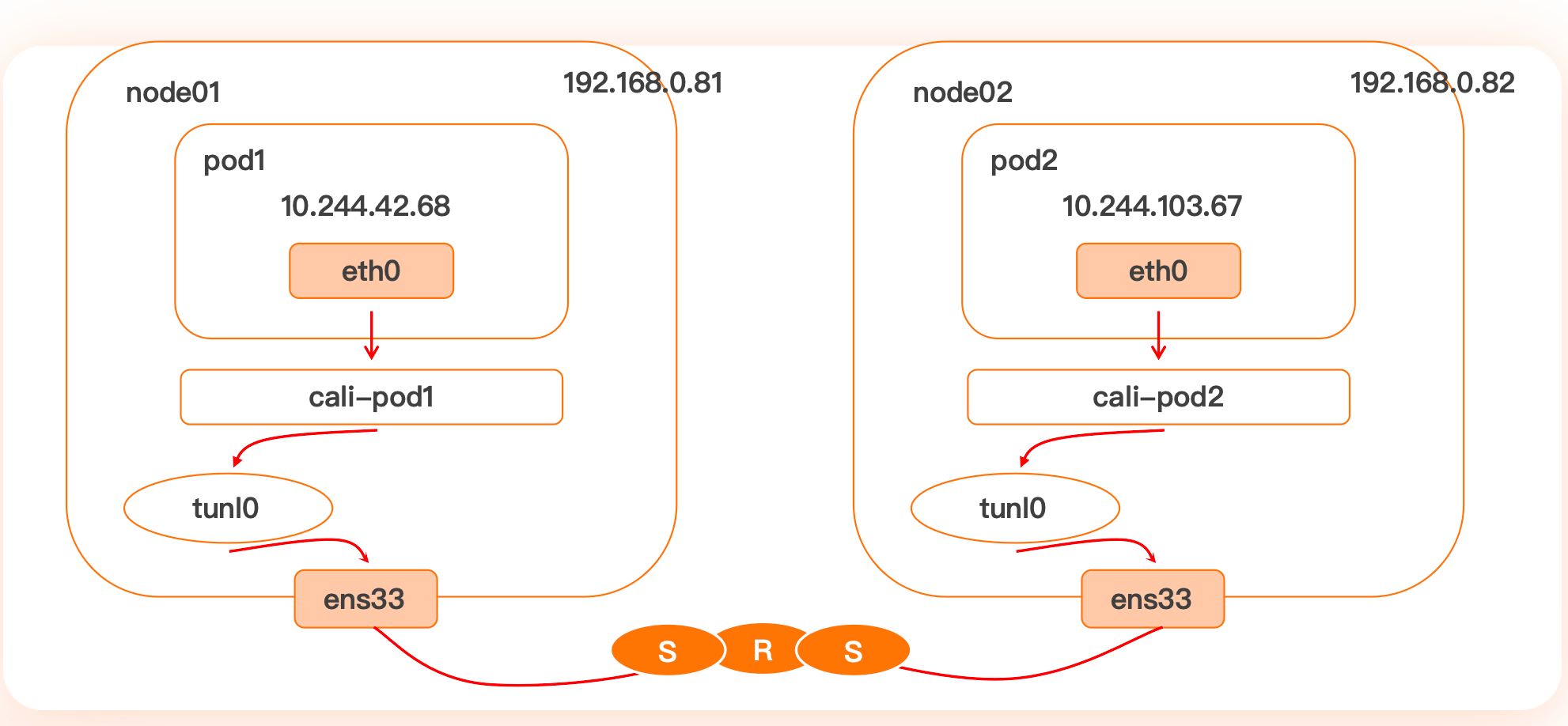
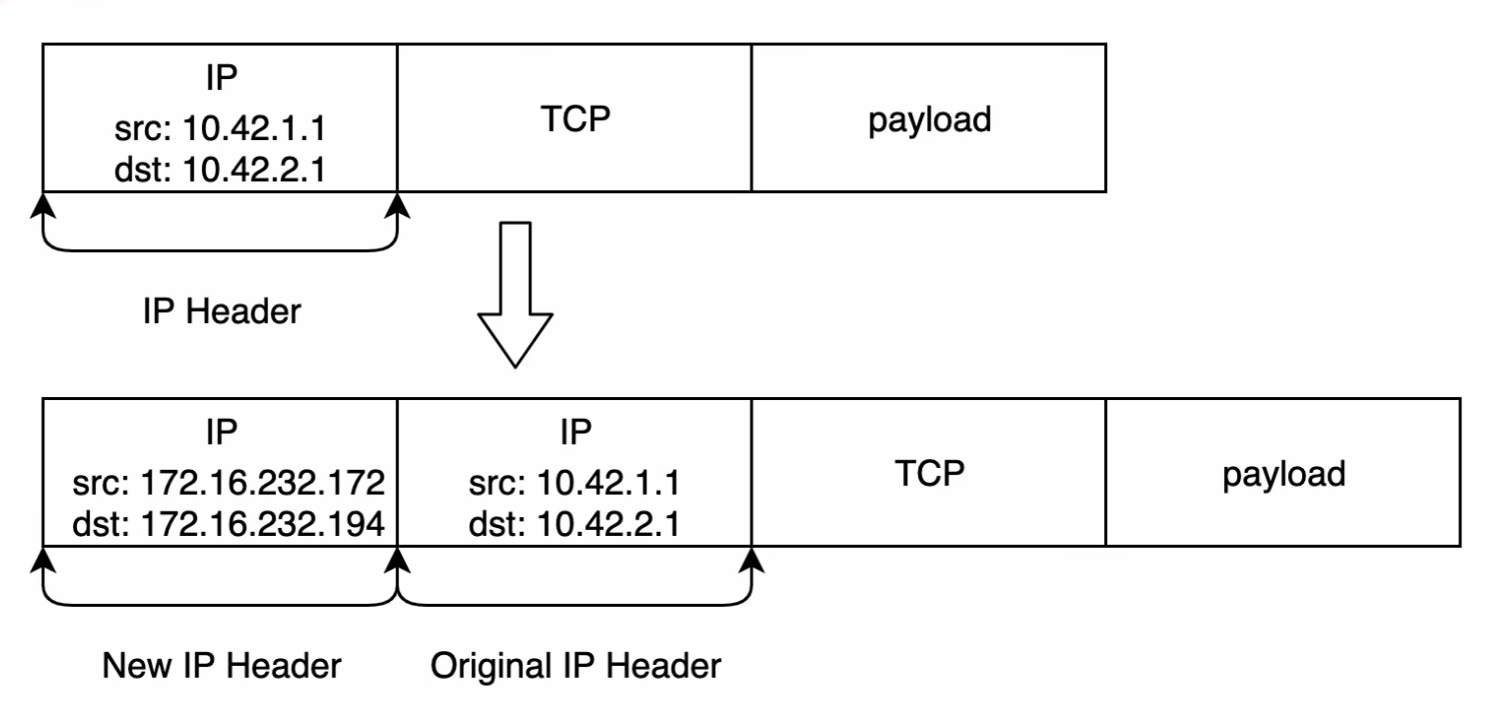
数据包封包:在 tunl0 设备上将 pod 发来的数据包的 mac 层去掉,留下 ip 层封包,外层数据包目的 ip 地址根据路由得到
优点
只需要 k8s 节点间三层互通,可跨网段
可跨 ipv4、ipv6
缺点
也存在一定性能损失,封解包,需要 BGP 支持路由