🍨 本文为🔗365天深度学习训练营中的学习记录博客
🍖 原作者:K同学啊
一、数据预处理
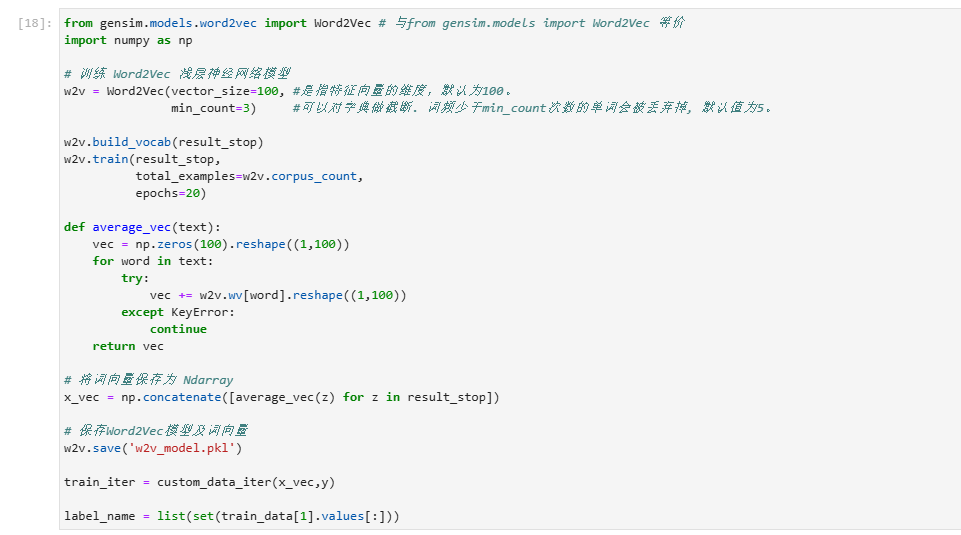
本次将加入Word2vec使用PyTorch实现中文文本分类,Word2Vec则是其中的一种词嵌入方去,是一种用于生成词向量的浅层神经网络模型,由Tomas Mikolov及其团队于2013年提出。 Word2Vec通过学习大量文本数据,将每个单词表示为一个连续的向量,这些向量可以捕捉单词之间的语义和句法关系。数据示例如下:


python
#构建模型
from torch import nn
class TextClassificationModel(nn.Module):
def __init__(self,num_class):
super(TextClassificationModel,self).__init__()
self.fc = nn.Linear(100,num_class)
def forward(self,text):
return self.fc(text)
num_class = len(label_name)
model = TextClassificationModel(num_class).to(device)
import time
def train(dataloader):
model.train()
total_acc,train_loss,total_count = 0,0,0
log_interval = 50
start_time = time.time()
for idx,(text,label) in enumerate(dataloader):
predicted_label = model(text)
optimizer.zero_grad()
loss = criterion(predicted_label,label)
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(),0.1) # 梯度裁剪
optimizer.step()
total_acc += (predicted_label.argmax(1)==label).sum().item()
train_loss += loss.item()*label.size(0)
total_count += label.size(0)
if idx % log_interval == 0 and idx > 0:
elapsed = time.time() - start_time
print('| epoch {:1d} | {:4d}/{:4d} batches '
'| train_acc {:4.3f} train_loss {:4.5f}'.format(epoch, idx, len(dataloader),
total_acc/total_count, train_loss/total_count))
total_acc, train_loss, total_count = 0, 0, 0
start_time = time.time()
def evaluate(dataloader):
model.eval()
total_acc,test_loss,total_count =0,0,0
with torch.no_grad():
for idx,(text,label) in enumerate(dataloader):
predicted_label = model(text)
loss = criterion(predicted_label,label)
total_acc += (predicted_label.argmax(1)==label).sum().item()
test_loss += loss.item()*label.size(0)
total_count += label.size(0)
return total_acc/total_count,test_loss/total_count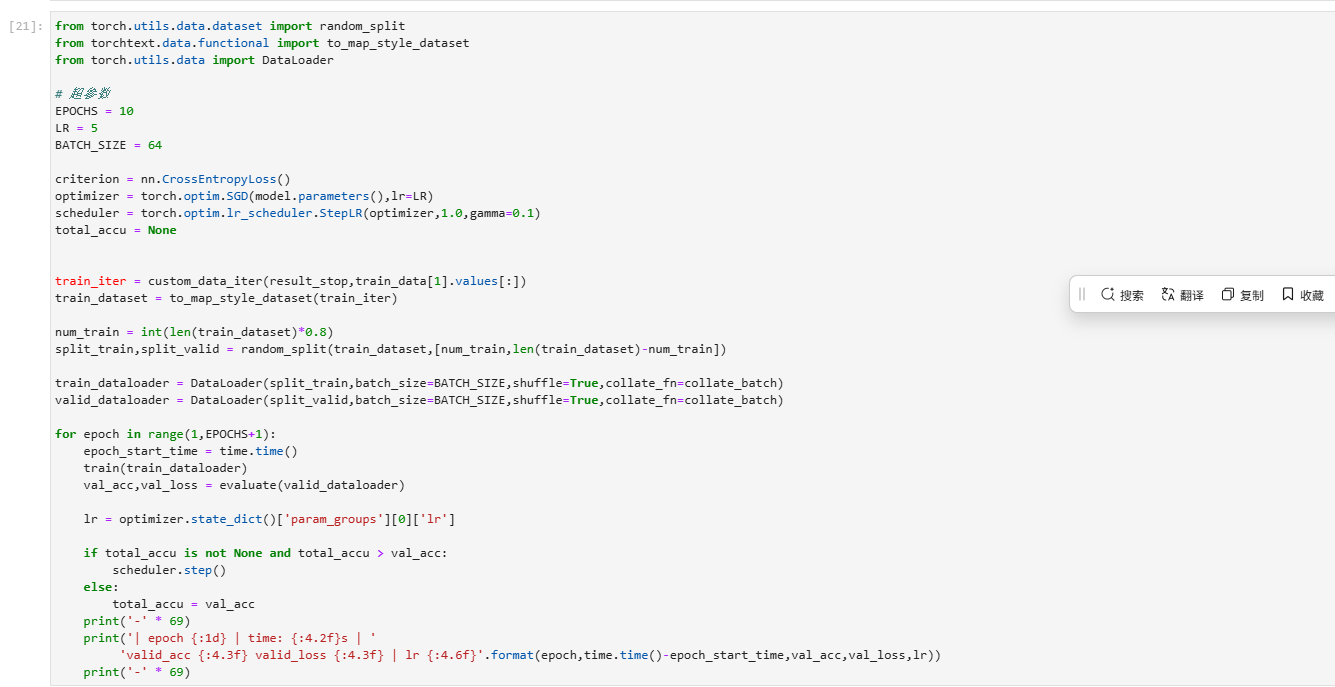

二、总结
Word2Vec为文本分类提供了有效的词级别特征表示,通过将词语映射到低维空间,保留了语义信息并减少了数据稀疏性。结合适当的分类模型,能够实现高效准确的文本分类任务。随着NLP技术的发展,Word2Vec可以与其他先进方法结合,进一步提升分类性能。