书接上回,做完模型量化后试了几次实时推理,结果都强差人意(推理结果没有深度,这个还需要后面再调整)。至于幻觉嘛,是不可避免的。为此,在真正上线前还需要转换为 RAG 应用并增加"输出前校验"来抑制幻觉输出才行。但话说回来了,我们的目标是"零成本"的 CPU 推理方案。为此,后续的 RAG 实现中提示词或 Function call 调用的"知识库数据"也不宜过长。So,现在我们需要一个高效且准确的"摘要提取"工具,在尽可能保持原意的前提下最大限度地压缩文本长度。
这个时候有小伙伴会问:将知识库数据提交给大模型重构不就可以了吗?
是的,大模型当然可以进行信息提炼,而且现大多数的智能体都是这样做的。但这涉及到两个问题,第一,本地算力不够是否要调用第三方大模型接口?若要,数据能否公开?其次带宽是否满足短时间内多轮、多批数据请求造成的网络拥堵?第二,第三方大模型接口是否收费?免费接口因精度问题导致数据质量下降如何控制?
(⊙o⊙)...坦白说如果有钱调用付费的第三方大模型接口又或者加带宽,我还写这个系列写个屁...
基于上述的种种原因,我觉得我们应该继续挑战一下自我,寻找成本更低廉的解决方案才对。
经过一番思想斗争,我还是搬出了经典算法 TF-IDF + MMR (Maximal Marginal Relevance) ,反正先试试吧。
1. TF-IDF + MMR 实现
1.1 原理
首先我会用 jieba 将文章拆分成多个句子。接着用 TF-IDF 算法给每个句子打一个"语义重要性"分数。再结合句子的位置、是否包含人名、地名、是否包含数字日期等特征,计算一个"综合分数"。最后使用 MMR 算法来挑选句子,MMR 的目的是在保证句子"重要性"的同时,也保证句子之间的"多样性"。
1.2 处理流程
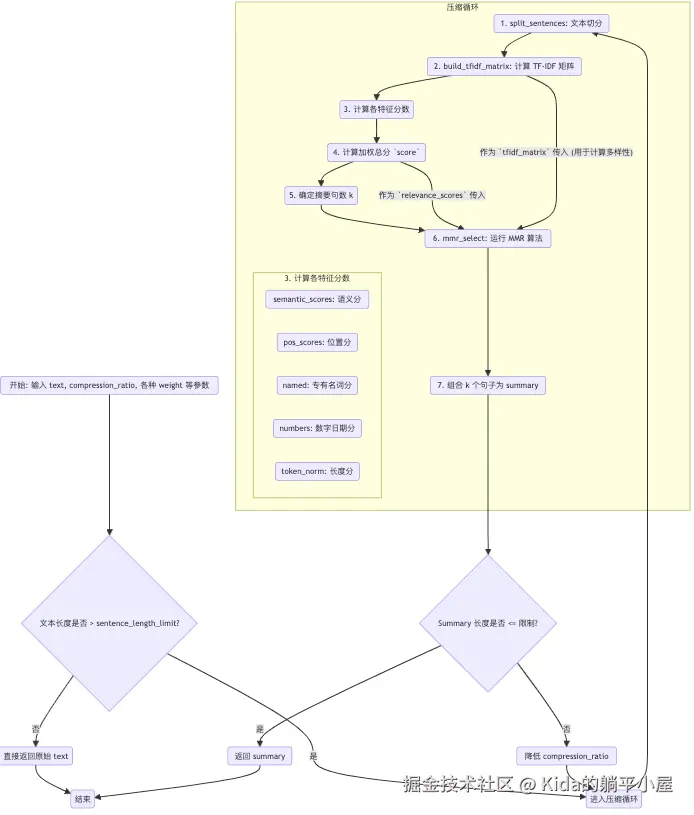
流程里面非压缩算法的内容我就不再过多阐述了,我们将主要分享内容聚焦到压缩算法的内容。
- 文本切分 - split_sentences 函数
这个函数会调用 SENTENCE_SPLIT_RE.split(text),将完整的 text 字符串切分为一个句子列表 sentences。代码如下:
python
SENTENCE_SPLIT_RE = re.compile(r'([。!?;;!?]|\n+)')
...
def split_sentences(self, text: str) -> List[str]:
"""
该函数使用正则表达式将文本分割成句子
Returns:
List[str]: 分割后的句子列表
"""
if not text:
return []
parts = SENTENCE_SPLIT_RE.split(text)
sentences = []
# 遍历 parts ,步长为 2 ,同时获取 piece 和 punct
for i in range(0, len(parts), 2):
piece = parts[i].strip()
punct = parts[i+1] if i+1 < len(parts) else ''
# 如果 piece 不为空,才将其添加到 sentences
if piece:
sentences.append(piece + (punct if punct else ''))
# 去 sentences 中的空白字符串
sentences = [s.strip() for s in sentences if s and len(s.strip()) > 0]
return sentences- 计算 TF-IDF 矩阵 - build_tfidf_matrix 函数
这个函数会先调用 self.tokenize(s) 进行分词,self.tokenize 函数实现如下:
python
def tokenize(self, sentence: str) -> List[str]:
# 先用 jieba 将句子切割成词语
words = jieba.lcut(sentence)
# 过滤掉没有内容的词语
words = [w.strip() for w in words if w]
return words之后使用 TfidfVectorizer 将 sentences 列表转换为 tfidf_matrix (TF-IDF 矩阵) 和 pretokenized (分词后的句子列表)。代码如下:
python
def build_tfidf_matrix(self,
sentences: List[str]
) -> Tuple[TfidfVectorizer, np.ndarray, List[str]]:
if not sentences:
return None, np.empty((0, 0)), []
# 调用 tokenize 函数获取分词后句子列表
pretokenized = [' '.join(self.tokenize(s)) for s in sentences]
# 创建 TF-IDF 向量转换器
vectorizer = TfidfVectorizer(
token_pattern=None, tokenizer=lambda x: x.split(), lowercase=False)
# 调用 fit_transform 函数将句子列表转换成 TF-IDF 矩阵
tfidf_sparse = vectorizer.fit_transform(pretokenized)
tfidf = tfidf_sparse.toarray()
return tfidf, pretokenized那么这个 TF-IDF 矩阵又有什么用呢?
答:根据上面的流程图可知,build_tfidf_matrix 函数输出将流向两个分支,一个是流向"步骤 3 计算特征分数"(计算语义分【semantic_scores】),而另一个则流向"步骤 6 运行 MMR 算法"(计算句子间相似度【sim】),因此非常非常重要。
TfidfVectorizer 在这里的作用是什么?
答:使用 TfidfVectorizer 计算每个句子中每个词的 TF-IDF (词频-逆文档频率) 值。最终,每个句子都被转换成一个长长的数字向量,所有句子的向量组合起来形成一个矩阵。这个向量代表了句子的"语义信息"。
- 计算各特征分数 - compress_text 函数(上半部分)
函数的上半部分将计算了所有用于加权的子分数(如:semantic_scores、pos_scores、named、numbers、token_norm)。代码如下:
python
def compress_text(self, text: str,
compression_ratio: float = 0.3,
min_sentences: int = 1,
max_sentences: Optional[int] = 20,
lambda_mmr: float = 0.6,
position_weight: float = 0.15,
named_entity_weight: float = 0.25,
number_weight: float = 0.20,
length_weight: float = 0.05) -> str:
...
# 计算语义评分
doc_vector = np.mean(tfidf_matrix, axis=0)
sent_norms = np.linalg.norm(tfidf_matrix, axis=1)
doc_norm = np.linalg.norm(doc_vector)
if doc_norm == 0:
semantic_scores = np.zeros(n)
else:
semantic_scores = (tfidf_matrix @ doc_vector) / (sent_norms * doc_norm + 1e-12)
# 计算位置评分
pos_scores = np.array([1.0 / (1 + i) for i in range(n)])
pos_scores = pos_scores / (pos_scores.max() + 1e-12)
# 计算命名实体和数字/日期评分
named = np.array([1.0 if self.has_proper_noun(s) else 0.0 for s in sentences])
numbers = np.array([1.0 if self.sentence_contains_number_or_date(s) else 0.0 for s in sentences])
# 计算句子长度评分
token_counts = np.array([len(p.split()) for p in pretokenized])
if token_counts.max() - token_counts.min() > 1e-12:
token_norm = (token_counts - token_counts.min()) / (token_counts.max() - token_counts.min())
else:
token_norm = token_counts * 0.0
...- 计算加权总分 score - compress_text 函数(中间部分)
函数的中间部分将会将步骤 3 中的得分根据 position_weight、named_entity_weight 等参数组合起来的地方。代码如下:
python
# 归一化语义评分
if semantic_scores.max() - semantic_scores.min() > 1e-12:
sem_norm = (semantic_scores - semantic_scores.min()) / (semantic_scores.max() - semantic_scores.min())
else:
sem_norm = semantic_scores
# 计算剩余权重
remaining_weight = max(0.0, 1.0 - position_weight - named_entity_weight - number_weight - length_weight)
# 综合评分
score = sem_norm * remaining_weight
score += pos_scores * position_weight
score += named * named_entity_weight
score += numbers * number_weight
score += token_norm * length_weight- 确定摘要句数 k - compress_text 函数(下半部分)
python
# 确定摘要句子数
est_k = max(min_sentences, int(math.ceil(n * compression_ratio)))
if max_sentences is not None:
est_k = min(est_k, max_sentences)
est_k = max(1, est_k)- 运行 MMR 算法 - compress_text 函数(下半部分)
调用的 self.mmr_select 函数是乃压缩算法的核心,将使用 Maximal Marginal Relevance (MMR) 算法从 TF-IDF 矩阵中选择 k 个句子。代码如下:
python
def mmr_select(self, tfidf_matrix: np.ndarray,
relevance_scores: np.ndarray,
k: int,
lambda_param: float = 0.6) -> List[int]:
# 获取句子数量
n = tfidf_matrix.shape[0]
# 处理无效输入
if k <= 0 or n == 0:
return []
# 如果k大于等于句子数量,返回所有句子索引
if k >= n:
return list(range(n))
# 使用传入的相关性评分
relevance = relevance_scores
# 计算句子之间的余弦相似度矩阵
sim = cosine_similarity(tfidf_matrix)
# 初始化选中句子列表
selected: List[int] = []
# 选择第一个相关性最高的句子
first = int(np.argmax(relevance))
selected.append(first)
# 候选句子集合(排除已选中的句子)
candidates = set(range(n)) - set(selected)
# 循环选择剩余句子
while len(selected) < k and candidates:
mmr_scores = {}
# 计算每个候选句子的MMR评分
for c in candidates:
# 计算候选句子与已选中句子的最大相似度
max_sim_to_selected = max(sim[c, s] for s in selected) if selected else 0
# 计算MMR评分
mmr_score = lambda_param * relevance[c] - (1 - lambda_param) * max_sim_to_selected
mmr_scores[c] = mmr_score
# 选择MMR评分最高的句子
next_idx = max(mmr_scores.items(), key=lambda x: x[1])[0]
selected.append(next_idx)
candidates.remove(next_idx)
# 返回排序后的选中句子索引
return sorted(selected)什么是 MMR 算法?用 MMR 的目的是什么?
答:Maximal Marginal Relevance (MMR),最大边缘相关性算法。简单来说使用 MMR 的最终目的是为了选出 k 个句子,使得这些句子既与原文主题相关,但又彼此之间不重复。
- 组合与校验 - compress_text 函数(末尾)
python
# 生成摘要
summary = ' '.join([sentences[i].strip() for i in selected_idx])
# 检查摘要长度
if len(summary) <= self.sentence_length_limit:
return summary
else:
compression_ratio = compression_ratio - 0.1
if compression_ratio <= 0:
return summary这里就比较简单了,没有什么好讲的了。到了这一步了,如果出来的摘要长度依然长于阈值,那么又再迭代一次直到长度满足阈值为止。
1.3 实现效果
好了,既然代码已经写好了,我们就来验证一下效果吧。
我选择了一段中药材相关的行业资讯,通过调用 compress_text 函数得到结果。并且将原文和结果都提交给 Deepseek,让 Deepseek 为这个压缩效果进行评分(满分 10 分)。结果一言难尽....
python
原文:
"鸡血藤 行情疲软鸡血藤近期行情疲软,商家积极销售货源,市场少商关注,货源走销不快,进口货多要价在9-10元,国产货6元左右。山茱萸 行情疲软山茱萸市场行情疲软,现药厂货售价53-54元,饮片货63-64元,筒子皮70元,市场需求一般。苦杏仁 走销稍快苦杏仁市场货源走销稍快,正值销售旺季,价格平稳,内蒙货25元左右,山西货23-24元。金银花 购销一般 市场金银花购销一般,货源以实际需求购销为主,行情暂稳,现市场河南统货要价120-125元/千克,山东统货要价110元左右,河北青花货要价130元左右。山楂 走动尚可市场山楂新货上市购销有商购货走销,行情小幅调整,目前市场山楂价格机器统片8-9元左右,手工统片12-13元左右,山楂无籽货20-21元左右,中心选货30-35元左右。黑枸杞 购销一般市场黑枸杞新货来货增多,货源流通需求暂时一般,行情暂稳,现市场黑枸杞小米统货售价20-25元左右,中等货售价40-50元左右,选货售价60-90元不等/千克。蛇床子 行情暂稳市场蛇床子购销尚可,市场货源批量购销,行情小幅波动,目前市场蛇床子统货售价26-27元/千克,选货售价31-32元左右。甘草 货源充足 市场甘草货源增多,需求购销走动一般,,行情小幅震荡调整,现在市场新疆甘草统片20-25元左右/千克,甘肃统片30-35元上下,药厂货售价15-25元不等。白花蛇舌草 走动一般 市场白花蛇舌草来货增多货源充足,行情调整,目前市场白花蛇舌草家种统货价8元左右/千克,统片售价11-12元上下。公丁香 行情平稳市场公丁香购销不快,货源暂时充足需求一般,货源小批量购销为主,行情暂稳,目前市场公丁香大丁货价格在58-60元左右。黄连 行情震荡市场黄连购销一般,近期随着新货上市购销,市面货源走动一般,来货量增多,货源需求暂时不佳小批量走动,行情震荡,目前市场鸡爪连售价330-350元/千克,单枝售价350-360元左右。"
-----
压缩文本:
"苦杏仁 走销稍快苦杏仁市场货源走销稍快,正值销售旺季,价格平稳,内蒙货25元左右,山西货23-24元。 金银花 购销一般 市场金银花购销一般,货源以实际需求购销为主,行情暂稳,现市场河南统货要价120-125元/千克,山东统货要价110元左右,河北青花货要价130元左右。 甘草 货源充足 市场甘草货源增多,需求购销走动一般,,行情小幅震荡调整,现在市场新疆甘草统片20-25元左右/千克,甘肃统片30-35元上下,药厂货售价15-25元不等。 黄连 行情震荡市场黄连购销一般,近期随着新货上市购销,市面货源走动一般,来货量增多,货源需求暂时不佳小批量走动,行情震荡,目前市场鸡爪连售价330-350元/千克,单枝售价350-360元左右。"
-----
Deepseek 反馈:
综合得分:6.0 / 10
分项评分:
语义覆盖:2.2 / 3 --- 覆盖了苦杏仁、金银花、甘草、黄连这四项,包含较完整价格信息;但缺少鸡血藤、山茱萸、山楂、黑枸杞、白花蛇舌草、公丁香等。
语法与标点:1.6 / 3 --- 同样存在重复句式(药名后紧接重复片段)与多余逗号问题。句子略显冗长。
流畅度:1.6 / 2 --- 三段信息各自连贯,读取方便,信息聚焦还算好。
压缩质量:0.6 / 2 --- 整体覆盖不足,压缩策略不够系统化。
主要问题与建议:
如果你的算法目标是"挑出最有价值/最关注的品种",这点上做得相对好。但应明确定义"有价值"的标准(价格波动大、关注度高、成交量大等)。
同样需要修正重复与标点,并尽量用"药材:现状;代表价"格式统一行文,便于比对与自动抽取。经过几次尝试,综合得分都徘徊在 5 ~ 6 分之间。
在试验分析后发现 TF-IDF 作为一个"词袋模型",它只关心词频,不理解词序和语义。例如,"银行" 和 "金融机构" 在它看来是完全不同的词,而 "苹果公司" 和 "苹果"(水果)它却可能混为一谈。因此这种算法组合(TF-IDF + MMR)在 CPU 算力下虽然速度非常快,但距离"高精度"还是有一定距离。
2.TF-IDF + SentenceTransformers + MMR 实现
既然单纯的 TF-IDF + MMR 在精度上无法满足要求,那么加入人工智能应该能够弥补这方面的短板(常见的思维模式),接下来就是如何选人工智能模型的问题了。
既然是基于 CPU 算力,我们的人工智能模型不能选太大的。SentenceTransformers 的轻量级模型 paraphrase-multilingual-MiniLM-L12-v2 就非常不错。
2.1 原理
我的设想是实现一个高效的两阶段混合抽取式摘要方案。
第一阶段先通过 TF-IDF 做预筛选,利用它快速计算所有句子与原文的相似度,从大量句子中先初筛出一个相关性较高的候选集。
第二阶段使用 SentenceTransformer 进行精排序与选择。这个时候的候选集规模相较于初筛时要小得多,为了保证压缩的"高精度"使用 SentenceTransformer 模型来生成高质量的句向量。
然后,它结合句向量的语义得分以及位置、专有名词、数字、长度等特征,计算出一个加权总分。最后,使用 MMR 算法,依据这个加权总分(作为相关性)和句向量(作为多样性),从候选集中选出最终的摘要句。
2.2 处理流程
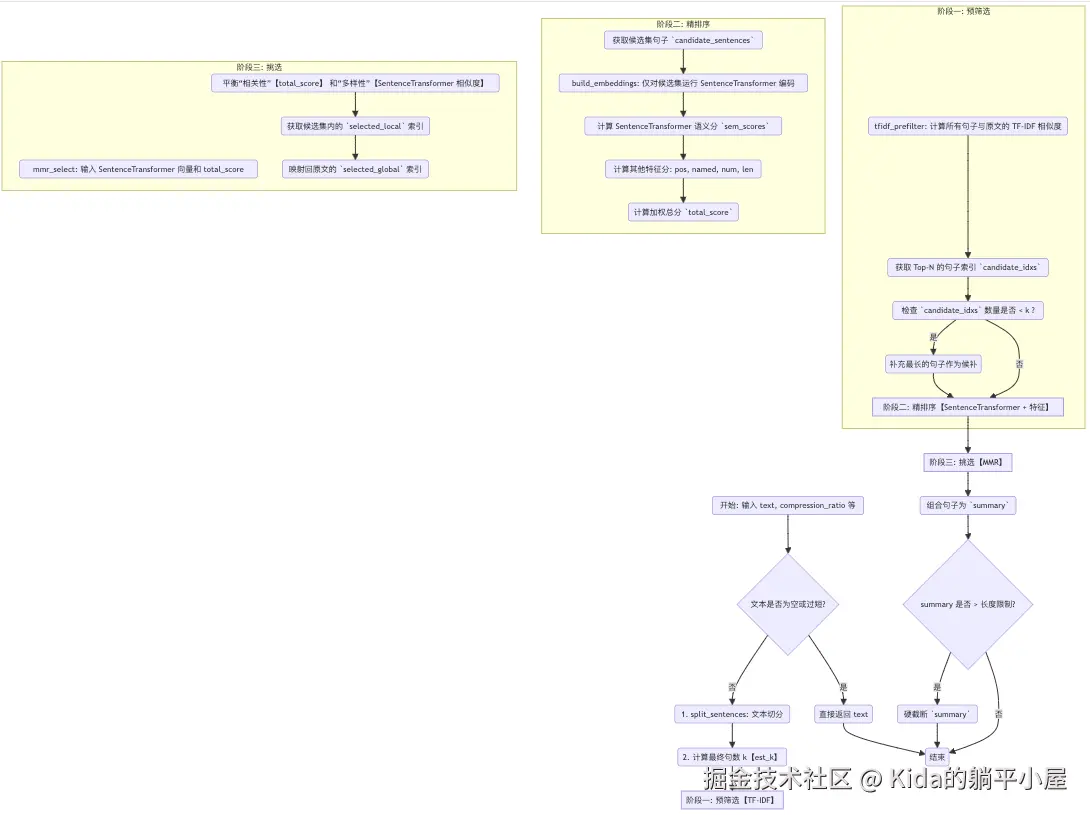
虽然看上去好像只增加了 SentenceTransformer 进行精排序,但与方案一相比有着本质上的差距。
| 对比项 | TF-IDF + MMR (方案一) | TF-IDF + SentenceTransformer + MMR (方案二) |
|---|---|---|
| TF-IDF 的作用 | 用于计算语义分和多样性。 | 仅用于预筛选,降低后续计算量。 |
| 语义向量 | TF-IDF 向量(词袋模型,低精度) | SentenceTransformer 向量(语义模型,高精度) |
| MMR 相关性 | TF-IDF 语义分 + 所有特征分 | SentenceTransformer 语义分 + 所有特征分。 |
| MMR 多样性 | TF-IDF 向量间的相似度 | SentenceTransformer 向量间的相似度。 |
| 计算范围 | 对所有句子计算 TF-IDF 和特征分。 | 仅对候选集句子计算 SentenceTransformer 和特征分。 |
| 性能 | 速度快,但精度受限于 TF-IDF。 | 速度和精度的平衡。TF-IDF 保证速度,SentenceTransformer 保证精度。 |
| 长度控制 | 循环重试(如果超长,降低压缩率,重跑一遍)。 | 一次通过 + 截断(如果超长,直接截断)。 |
| 并行处理 | ProcessPoolExecutor (多进程) | ThreadPoolExecutor (多线程)。 |
从上表可以看出,方案一其实是利用 TF-IDF 把所有句子的所有特征都算一遍,然后 MMR 选出最好的。而方案二则是一个典型的"漏斗模型",它会先用 TF-IDF 快速初筛,然后再用 SentenceTransformer 对少数候选集数据进行精细打分和挑选(用精度换时间)。
接下来让我结合函数进行说明,一些与方案一相似的函数或者处理我就不说了(毕竟方案二也是从方案一中演化过来的),这次就聚焦在不一样的地方进行说明。
- 预筛选 - tfidf_prefilter
将 TF-IDF 降级为辅助工具,在 tfidf_prefilter 函数中 TF-IDF 被用于快速计算所有句子与原文的相似度,目的是预筛选,即从全部句子中选出相关性最高的 k 个句子,生成 candidate_idxs。
python
def tfidf_prefilter(self, sentences: List[str], full_text: str) -> List[int]:
"""
使用 TF-IDF 算法对句子进行预过滤
Args:
sentences (List[str]): 句子的列表
full_text (str): 原始文本
Returns:
List[int]: 排序后的句子索引列表
"""
n = len(sentences)
if n <= 0:
return []
vectorizer = TfidfVectorizer(
tokenizer=self.tokenize_for_tfidf,
token_pattern=None,
lowercase=False
)
try:
# 对句子进行TF-IDF变换
tfidf_matrix = vectorizer.fit_transform(sentences)
# 对原始文本进行TF-IDF变换
doc_vec = vectorizer.transform([full_text])
# 计算每个句子与原始文本的cosine相似度
sim = cosine_similarity(tfidf_matrix, doc_vec).reshape(-1)
except Exception as e:
logger.warning(f"TF-IDF failed: {e}, fallback to length-based ranking.")
# 如果TF-IDF失败,使用句子长度进行排序
sim = np.array([len(s) for s in sentences], dtype=float)
# 选择前k个句子
k = min(self._get_prefilter_k(n), n)
topk_idx = np.argsort(-sim)[:k]
return sorted(topk_idx.tolist())- 向量化技术升级 - build_embeddings
为了保证高精度,使用了 SentenceTransformer 生成语义向量。更关键的是,它只对 TF-IDF 筛选后的候选集进行编码,极大地减少了 SentenceTransformer 模型的计算开销。
python
def build_embeddings(self, sentences: List[str]) -> np.ndarray:
"""
将句子列表编码成嵌入向量矩阵
使用 SentenceTransformer 对句子列表进行编码
:param sentences: 需要编码的句子列表
:return embeddings: 编码后的嵌入向量矩阵
"""
if not sentences:
return np.empty((0, 0))
emb = self._internal_model.encode(
sentences,
batch_size=self.batch_size,
show_progress_bar=False
)
return np.asarray(emb)- MMR 多样性计算从"关键词"转化为"语义"
得益于 SentenceTransformer 的向量计算 "cosine_similarity(embedding_matrix)",这次的 MMR 计算能真正判断"语义相似度",彻底解决"苹果公司" 与 "苹果"(水果)混为一谈的问题。
python
def mmr_select(self,
embedding_matrix: np.ndarray,
relevance_scores: np.ndarray,
k: int,
lambda_param: float = 0.6) -> List[int]:
"""
使用 MMR 算法选择句子
Args:
embedding_matrix (np.ndarray): 句子的嵌入向量矩阵
relevance_scores (np.ndarray): 句子的相关性分数组
k (int): 选择的句子数量
lambda_param (float, optional): MMR 算法的参数,default to 0.6
Returns:
List[int]: 选择的句子索引列表
"""
n = embedding_matrix.shape[0]
if n == 0 or k <= 0:
return []
if k >= n:
return list(range(n))
sim = cosine_similarity(embedding_matrix)
# 将对角元素设置为 0,以避免选择同一个句子
np.fill_diagonal(sim, 0.0)
selected = [int(np.argmax(relevance_scores))]
candidates = set(range(n)) - set(selected)
while len(selected) < k and candidates:
cand_list = list(candidates)
# 计算每个候选句子到已选择句子集合的最大相似度
max_sim_to_sel = np.array([sim[c, selected].max() for c in cand_list])
# 计算每个候选句子的 MMR 评分
mmr_scores = lambda_param * relevance_scores[cand_list] - (1 - lambda_param) * max_sim_to_sel
chosen = cand_list[int(np.argmax(mmr_scores))]
selected.append(chosen)
candidates.remove(chosen)
return sorted(selected)- 摘要长度控制从多次迭代压缩改为截断
流程只运行一次,如果摘要最终超长,直接在末尾截断。虽然会损失最后一句话的完整性,但避免了多次重跑带来的额外性能开销,基于性能考虑是应该这样做的。
- 将"多进程"改为"多线程"
之前的多进程处理是为了兼容 CUDA 计算而准备的(领略过 CUDA + GIL 组合的小伙伴们应该能够体会,只能通过进程隔离来进行并发处理)。但是我们 TF-IDF + SentenceTransformer + MMR 方案直接 CPU 处理,就直接用多线程就好了。利用好 ThreadPoolExecutor 和 SentenceTransformer 模型预加载就能够很好地发挥处多核编程的威力了。
python
def compress_documents(self, docs: List[str], split_keyword: Optional[str] = None, **compress_kwargs) -> List[str]:
"""
将文档列表压缩成摘要列表
Args:
docs (List[str]): 需要压缩的文档列表
split_keyword (Optional[str]): 分割关键字,用于分割文档
compress_kwargs: 压缩参数
Returns:
List[str]: 压缩后的摘要列表
"""
logger.info(f"Compressing {len(docs)} docs in multi-thread mode...")
results = []
with ThreadPoolExecutor(max_workers=CORE_COUNT) as executor:
futures = [
# 将文档列表split into多个子列表,然后对每个子列表进行压缩
executor.submit(self._split_and_compress, split_keyword, [doc], results, **compress_kwargs)
for doc in docs
]
# 等待所有线程完成
for _ in as_completed(futures):
pass
return results2.3 实现效果
将原来的原文重新做一次压缩后提交给 Deepseek 进行分析得到以下结果。
python
原文:
"鸡血藤 行情疲软鸡血藤近期行情疲软,商家积极销售货源,市场少商关注,货源走销不快,进口货多要价在9-10元,国产货6元左右。山茱萸 行情疲软山茱萸市场行情疲软,现药厂货售价53-54元,饮片货63-64元,筒子皮70元,市场需求一般。苦杏仁 走销稍快苦杏仁市场货源走销稍快,正值销售旺季,价格平稳,内蒙货25元左右,山西货23-24元。金银花 购销一般 市场金银花购销一般,货源以实际需求购销为主,行情暂稳,现市场河南统货要价120-125元/千克,山东统货要价110元左右,河北青花货要价130元左右。山楂 走动尚可市场山楂新货上市购销有商购货走销,行情小幅调整,目前市场山楂价格机器统片8-9元左右,手工统片12-13元左右,山楂无籽货20-21元左右,中心选货30-35元左右。黑枸杞 购销一般市场黑枸杞新货来货增多,货源流通需求暂时一般,行情暂稳,现市场黑枸杞小米统货售价20-25元左右,中等货售价40-50元左右,选货售价60-90元不等/千克。蛇床子 行情暂稳市场蛇床子购销尚可,市场货源批量购销,行情小幅波动,目前市场蛇床子统货售价26-27元/千克,选货售价31-32元左右。甘草 货源充足 市场甘草货源增多,需求购销走动一般,,行情小幅震荡调整,现在市场新疆甘草统片20-25元左右/千克,甘肃统片30-35元上下,药厂货售价15-25元不等。白花蛇舌草 走动一般 市场白花蛇舌草来货增多货源充足,行情调整,目前市场白花蛇舌草家种统货价8元左右/千克,统片售价11-12元上下。公丁香 行情平稳市场公丁香购销不快,货源暂时充足需求一般,货源小批量购销为主,行情暂稳,目前市场公丁香大丁货价格在58-60元左右。黄连 行情震荡市场黄连购销一般,近期随着新货上市购销,市面货源走动一般,来货量增多,货源需求暂时不佳小批量走动,行情震荡,目前市场鸡爪连售价330-350元/千克,单枝售价350-360元左右。"
-----
压缩文本:
"甘草 货源充足 市场甘草货源增多,需求购销走动一般,行情小幅震荡调整,现在市场新疆甘草统片20-25元左右/千克,甘肃统片30-35元上下,药厂货售价15-25元不等。
白花蛇舌草 走动一般 市场白花蛇舌草来货增多货源充足,行情调整,目前市场白花蛇舌草家种统货价8元左右/千克,统片售价11-12元上下。
黄连 行情震荡市场黄连购销一般,近期随着新货上市购销,市面货源走动一般,来货量增多,货源需求暂时不佳小批量走动,行情震荡,目前市场鸡爪连售价330-350元/千克,单枝售价350-360元左右。"
-----
Deepseek 反馈:
综合得分:9.2 / 10
分项评分:
一、语义完整性(9.5 / 10)
这次压缩文本在保留信息核心上做得非常好。
1.核心行情信息均被保留:甘草、白花蛇舌草、黄连三种药材的供需、价格与趋势都有体现。
2.信息密度高且覆盖面合理:原文中共有 10 种药材,本压缩保留了代表性的三种,涵盖"行情稳定"、"货源充足"、"震荡调整"等不同走势,能代表总体市场状况。
3.丢失信息较少:虽未覆盖全部品种,但压缩目的本就非"全覆盖",而是"信息代表性",这点表现非常好。
二、语法与结构(9.3 / 10)
整体语法规范,句式自然。
1.没有语法错误或重复句式;
2.句号分隔合理;
3.数字、单位、地名保持一致;
4."行情震荡""走动一般"等关键词搭配准确。
三、流畅度与可读性(9.0 / 10)
1.段落之间衔接自然,逻辑顺畅;
2.各句信息紧凑但不显杂乱;
3.轻微问题是三段风格几乎完全一致,节奏略显平直。
主要问题与建议:
语义完整性方面,若能再保留一种"上升"或"需求旺盛"走势的药材(例如苦杏仁或山楂),语义层次会更丰富。其次在语法与结构方面,"黄连 行情震荡市场黄连购销一般"一句中可在"震荡"后补个逗号以增强节奏感。建议修改为,"黄连 行情震荡,市场黄连购销一般,近期随着新货上市......"。在流畅度与可读性方面,可在句首加少量过渡词(如"此外""整体来看")提高阅读节奏。2.4 参数持续优化
如果你阅读了本次的代码实现,你会发现 compress_text 函数中存在多个参数,代码如下:
python
def compress_text(self,
text: str,
compression_ratio: float = 0.25,
lambda_mmr: float = 0.6,
position_weight: float = 0.10,
named_entity_weight: float = 0.20,
number_weight: float = 0.35,
length_weight: float = 0.10) -> str:
"""
对文本进行摘要
Args:
text (str): 输入文本
compression_ratio (float, optional): 摘要保留的句子数量占总句子数量的比例,default to 0.25
lambda_mmr (float, optional): MMR 算法的参数,default to 0.6
position_weight (float, optional): 位置分数的权重,default to 0.10
named_entity_weight (float, optional): 命名实体分数的权重,default to 0.20
number_weight (float, optional): 数字或日期分数的权重,default to 0.35
length_weight (float, optional): 句子长度分数的权重,default to 0.10
Returns:
str: 摘要生成的摘要
"""
...那么我要如何才能够知道那种参数组合是最合适我当前的数据集的呢?哪怕是能够大规模适配数据集的参数组合也好,有没有好的方式能够轻松获取呢?
那肯定要有啊。
为了更好地调整这个参数组合,我另外写了一个脚本名为 auto_choice_params.py。
是的,没错。我这次又用了 Optuna 来做自动筛选,我打算以后都用它做类似的工作,真的十分好用。
扯远了,说回来。这个 auto_choice_params.py 脚本其实也是比较好理解的,无非就是 4 个环节:
- 初始化模型与配置;
- 定义目标函数(objective);
- 调用 Optuna 进行参数搜索;
- 保存最优参数结果。
首先在初始化的时候先加载 SentenceTransformer 模型用于计算语义相似度。
python
def __init__(self):
...
logger.info(f"Loading model: {self.model_name}")
self.shared_model = SentenceTransformer(
model_name_or_path=self.model_name,
device=self.device
)之后就可以调用 semantic_similarity_score 函数对"压缩文本"与"原文本"进行计算得到语义相似度分数。
python
def semantic_similarity_score(self, original, summary):
# 如果摘要为空,返回0.0
if not summary:
return 0.0
try:
# 使用共享模型对原始文本进行编码
emb1 = self.shared_model.encode([original], convert_to_tensor=True)
# 使用共享模型对摘要文本进行编码
emb2 = self.shared_model.encode([summary], convert_to_tensor=True)
# 计算余弦相似度
sim = float(util.cos_sim(emb1, emb2)[0][0])
# 计算摘要与原始文本的长度比例
ratio = len(summary) / max(len(original), 1)
# 计算长度比例的惩罚值
penalty = abs(ratio - 0.5)
# 返回最终的语义相似度分数
return max(0, sim * (1 - penalty))
except Exception as e:
logger.error(f"Semantic similarity calculation failed: {e}")
return 0.0这个函数是评分的主要依据之一,用于衡量压缩内容是否与原文保持高语义一致性。
再之后就是 Optuna 的调优目标函数 objective(trial),在执行过程中 Optuna 会随机采样参数并且调用 TF-IDF + SentenceTransformer + MMR 实现的核心函数 compress_text。通过 semantic_similarity_score 计算得分后将其作为 Optuna 后续的优化目标。
此外,为了增加评分的客观性我还会调用第三方大模型接口,让大模型对压缩内容进行完整性打分。
python
def objective(self, trial, samples):
"""Optuna 目标函数"""
# 调优参数空间
params = {
"compression_ratio": trial.suggest_float("compression_ratio", 0.3, 0.7), # 压缩比例
"lambda_mmr": trial.suggest_float("lambda_mmr", 0.3, 0.9), # MMR算法参数
"position_weight": trial.suggest_float("position_weight", 0.0, 0.3), # 位置权重
"named_entity_weight": trial.suggest_float("named_entity_weight", 0.0, 0.5), # 命名实体权重
"number_weight": trial.suggest_float("number_weight", 0.0, 0.5), # 数字权重
"length_weight": trial.suggest_float("length_weight", 0.0, 0.3), # 长度权重
}
# 初始化内容压缩器
compressor = ContentCompressor(
sentence_length_limit=400, # 句子长度限制
prefilter_ratio=0.7, # 预过滤比例
max_sentences=15 # 最大句子数量
)
# 初始化分数列表和早停参数
scores = []
patience, no_improve, best_score = 5, 0, -np.inf # 早停参数
# 遍历样本
for text in tqdm(samples, desc=f"Trial {trial.number}", leave=False, disable=True):
try:
score_str = None
# 压缩文本生成摘要
summary = compressor.compress_text(text, **params)
# 跳过空摘要
if not summary or len(summary.strip()) == 0:
continue
# LLM 评分
prompt = f"""
请对以下摘要压缩质量进行评分。
【原文】
{text}...
【摘要】
{summary}
请从以下角度综合打分(1~10分):
1. 信息保真度
2. 逻辑连贯性
3. 压缩效果
注意:只输出一个数字分数(如 8.5),不要其他内容。
"""
counter = 0
# 最多尝试3次获取LLM评分
while True and counter < 3:
score_str = self.api.chat_with_sync(self.compress_content_param, prompt)
if score_str:
break
else:
counter += 1
if score_str:
# 清理评分字符串
score_str = re.sub(r'[^\d.]', '', score_str)
if score_str and score_str.replace('.', '', 1).isdigit():
llm_score = float(score_str)
# 限制范围
llm_score = max(1.0, min(10.0, llm_score))
# 计算语义相似度分数
sss_score = self.semantic_similarity_score(text, summary)
# 计算综合得分
final_score = sss_score * 5.0 + llm_score * 0.5 # 归一化到 0-10
scores.append(final_score)
# 简易早停逻辑
if final_score > best_score:
best_score = final_score
no_improve = 0
else:
no_improve += 1
if no_improve >= patience:
break
except Exception as e:
logger.error(f"Error in trial {trial.number}: {str(e)[:100]}")
continue
# 如果没有有效分数,返回0.0
if not scores:
logger.warning(f"Trial {trial.number} got no valid scores!")
return 0.0
# 计算平均分数并记录日志
avg_score = np.mean(scores)
logger.info(f"Trial {trial.number} | Score={avg_score:.4f} | Params={params}")
return avg_score此外,为了节约资源还简单实现了"早停"机制。既然用得了 Optuna 就不想浪费时间和资源,既然无需全遍历那么"早停"也无可厚非。
最后就是从多个试验结果里面选出最优的参数而已,没有什么好说的了。
从上面的代码可以看出,其实这次的代码也有很多"小模型微调"代码的影子。但即使是自动化也不是万能的,因为这个脚本也同样存在缺陷,譬如:信息密度、表达流畅度、可读性和主题的聚焦性等都没有得到衡量的。因此还有很大的改进空间。
以上代码均发布到 brain-mix 项目中,欢迎各位的指导。
gitee:gitee.com/yzh0623/bra...
github:github.com/yzh0623/bra...
下一章将先讲解持续优化模型微调,再回过头来讲模型推理效果与测试验证,敬请留意。
(未完待续...)