
引言
Tokio作为Rust生态中最重要的异步运行时,其多线程调度器是支撑高并发应用的基石。与传统线程池不同,Tokio采用work-stealing算法和任务分片技术,在保证公平性的同时实现了极致性能。深入理解Tokio调度器的架构设计,不仅有助于编写高效的异步代码,更能让我们洞察现代并发编程的核心理念。本文将从调度器的设计哲学出发,结合源码分析和实践案例,全面剖析Tokio多线程调度器的工作原理。
Work-Stealing调度模型的设计哲学
Tokio的多线程调度器建立在work-stealing算法之上,这是一种经过实践验证的负载均衡策略。每个工作线程维护自己的本地任务队列,当队列为空时,线程会尝试从其他线程的队列中"窃取"任务。这种设计的精妙之处在于最小化了线程间的同步开销------大部分情况下,线程只需要访问自己的本地队列,只有在队列耗尽时才需要进行跨线程操作。
与简单的全局队列模式相比,work-stealing在缓存局部性方面具有显著优势。当任务倾向于产生相关的子任务时,这些子任务会优先在同一线程上执行,从而充分利用CPU缓存。同时,窃取机制确保了即使任务分布不均,空闲线程也能快速找到工作,避免资源浪费。
Tokio的实现在标准work-stealing基础上做了诸多优化。本地队列使用了特殊的LIFO语义,新产生的任务被推入队列头部,而窃取总是从尾部进行。这种设计基于一个观察:最近产生的任务更可能与当前执行上下文相关,在同一线程执行能获得更好的缓存命中率。而被窃取的任务往往是较早产生的,已经相对独立,适合迁移到其他线程。
rust
use tokio::runtime::Builder;
use std::time::Duration;
fn main() {
// 创建自定义配置的多线程运行时
let runtime = Builder::new_multi_thread()
.worker_threads(4)
.thread_name("tokio-worker")
.thread_stack_size(3 * 1024 * 1024)
.build()
.unwrap();
runtime.block_on(async {
demonstrate_work_stealing().await;
});
}
async fn demonstrate_work_stealing() {
let handles: Vec<_> = (0..100).map(|i| {
tokio::spawn(async move {
// 模拟计算密集型任务
let mut sum = 0;
for j in 0..1000 {
sum += i * j;
// 定期让出执行权,允许调度器介入
if j % 100 == 0 {
tokio::task::yield_now().await;
}
}
sum
})
}).collect();
for (i, handle) in handles.into_iter().enumerate() {
let result = handle.await.unwrap();
if i % 20 == 0 {
println!("Task {} completed with result: {}", i, result);
}
}
}任务的生命周期与状态转换
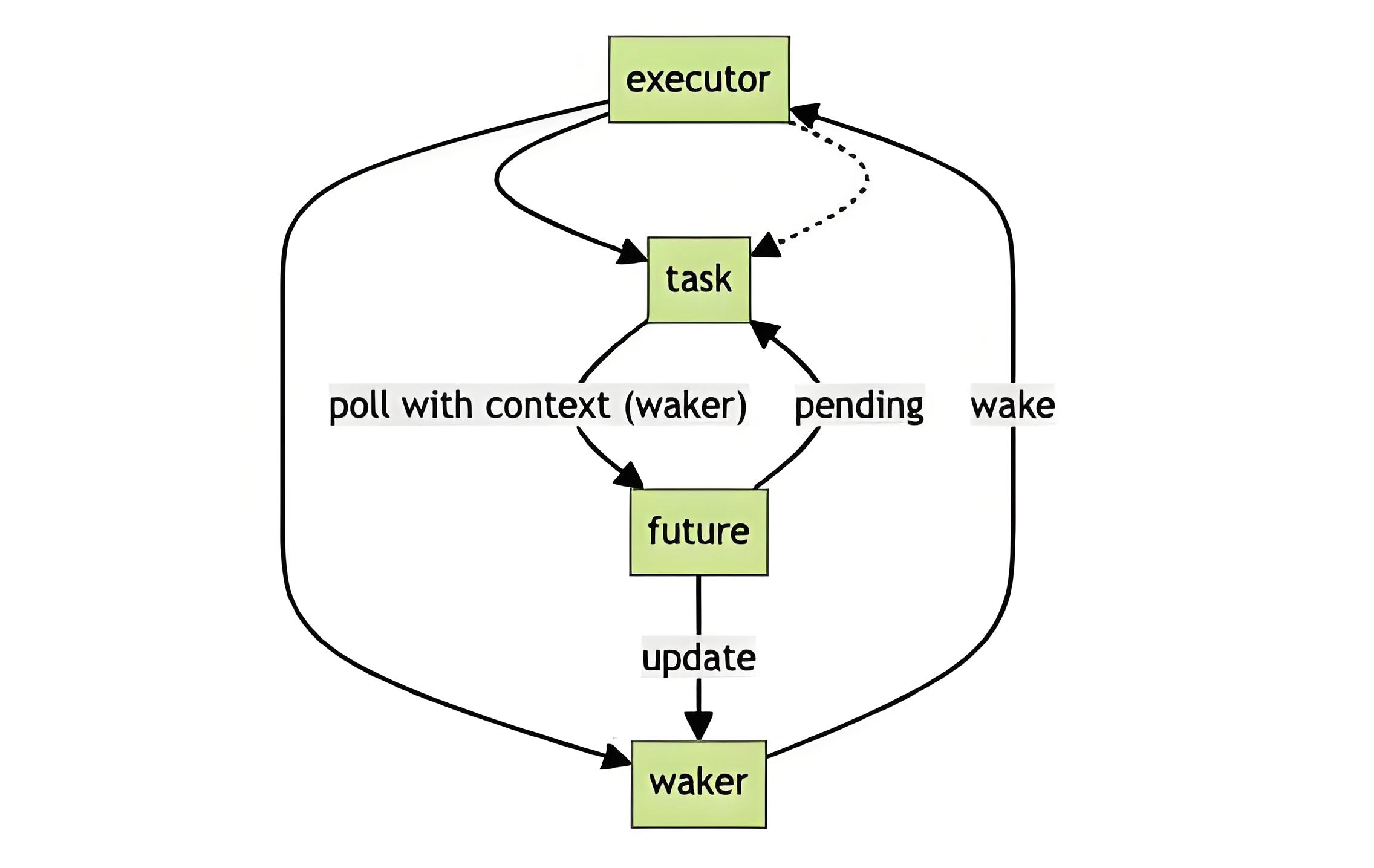
在Tokio中,每个异步任务都封装在一个Task结构中,经历着复杂的状态转换。从创建、调度、执行到完成,任务在不同的队列和线程之间流转。理解这个生命周期对于诊断性能问题和避免常见陷阱至关重要。
当我们通过tokio::spawn创建任务时,它首先被包装成可执行单元,包含了Future本身以及必要的元数据。调度器会根据当前负载情况决定将任务放入哪个队列。如果在运行时上下文内创建任务,通常会选择当前线程的本地队列;否则会选择全局注入队列。这个决策虽然简单,但对任务的初始执行延迟有直接影响。
任务的执行遵循协作式调度原则,每个任务通过返回Poll::Pending主动让出控制权。这与操作系统的抢占式调度形成鲜明对比,要求程序员必须确保任务不会长时间阻塞。Tokio通过预算机制限制单个任务的连续执行时间,当任务消耗完预算后,即使返回Poll::Ready,也会被重新放入队列末尾,给其他任务执行机会。
rust
use tokio::time::{sleep, Duration, Instant};
use std::sync::Arc;
use std::sync::atomic::{AtomicUsize, Ordering};
async fn task_lifecycle_analysis() {
let counter = Arc::new(AtomicUsize::new(0));
let start = Instant::now();
let tasks: Vec<_> = (0..10).map(|id| {
let counter = counter.clone();
tokio::spawn(async move {
for i in 0..5 {
counter.fetch_add(1, Ordering::Relaxed);
println!("[Task {}] Iteration {}, Thread: {:?}",
id, i, std::thread::current().id());
// 模拟IO等待,触发任务调度
sleep(Duration::from_millis(10)).await;
}
id
})
}).collect();
// 等待所有任务完成
for handle in tasks {
let id = handle.await.unwrap();
println!("Task {} finished", id);
}
let elapsed = start.elapsed();
let total_iterations = counter.load(Ordering::Relaxed);
println!("\nTotal iterations: {}, Time: {:?}", total_iterations, elapsed);
}队列结构与任务注入策略
Tokio的队列系统采用了多层次架构。每个工作线程拥有一个固定大小的本地队列(通常为256个任务槽位),此外还有一个全局的注入队列。当本地队列满时,新任务会被放入全局队列;当本地队列空时,线程会依次尝试从本地队列、全局队列、以及其他线程的队列中获取任务。
这种分层设计背后有深刻的权衡考量。本地队列使用无锁的单生产者单消费者队列实现,操作延迟极低;而全局队列需要支持多生产者多消费者场景,使用了基于锁的实现,但通过批量操作降低了锁竞争的影响。工作窃取时,线程会从目标队列的尾部批量窃取多个任务,减少窃取的频率。
任务注入策略直接影响系统的响应性和吞吐量。对于大量短生命周期任务的场景,频繁的全局队列访问会成为瓶颈;而对于长生命周期任务,本地队列的局部性优势则更为明显。Tokio通过动态调整注入策略和窃取阈值来适应不同的工作负载特征。
rust
use tokio::runtime::Handle;
use std::sync::Arc;
use std::sync::atomic::{AtomicU64, Ordering};
async fn queue_injection_demo() {
let metrics = Arc::new(TaskMetrics::new());
// 场景1:大量短任务(快速注入场景)
println!("=== Scenario 1: Many short tasks ===");
let metrics1 = metrics.clone();
for i in 0..1000 {
let metrics = metrics1.clone();
tokio::spawn(async move {
metrics.increment_spawned();
// 极短任务
let _ = i * 2;
metrics.increment_completed();
});
}
sleep(Duration::from_millis(100)).await;
metrics.print_stats("Short tasks");
metrics.reset();
// 场景2:少量长任务(本地队列优势场景)
println!("\n=== Scenario 2: Few long tasks ===");
let handles: Vec<_> = (0..10).map(|i| {
let metrics = metrics.clone();
tokio::spawn(async move {
metrics.increment_spawned();
for _ in 0..100 {
sleep(Duration::from_millis(1)).await;
}
metrics.increment_completed();
i
})
}).collect();
for handle in handles {
handle.await.unwrap();
}
metrics.print_stats("Long tasks");
}
struct TaskMetrics {
spawned: AtomicU64,
completed: AtomicU64,
}
impl TaskMetrics {
fn new() -> Self {
Self {
spawned: AtomicU64::new(0),
completed: AtomicU64::new(0),
}
}
fn increment_spawned(&self) {
self.spawned.fetch_add(1, Ordering::Relaxed);
}
fn increment_completed(&self) {
self.completed.fetch_add(1, Ordering::Relaxed);
}
fn print_stats(&self, label: &str) {
println!("{}: Spawned={}, Completed={}",
label,
self.spawned.load(Ordering::Relaxed),
self.completed.load(Ordering::Relaxed)
);
}
fn reset(&self) {
self.spawned.store(0, Ordering::Relaxed);
self.completed.store(0, Ordering::Relaxed);
}
}线程停放与唤醒机制
当工作线程无法找到任何可执行任务时,它不会忙等待而是进入休眠状态,这个过程称为线程停放(parking)。Tokio使用条件变量和原子操作的组合实现了高效的停放机制。线程在休眠前会将自己标记为空闲状态,当有新任务注入时,调度器会唤醒一个或多个空闲线程。
这个机制看似简单,实则蕴含着精妙的并发控制逻辑。为了避免丢失唤醒信号,Tokio在停放前后都会进行多次检查,确保在标记为空闲和实际休眠之间的窗口期内注入的任务能被及时发现。同时,唤醒策略也经过仔细调优------通常只唤醒一个线程来处理新任务,避免雷鸣群(thundering herd)效应。
rust
use tokio::sync::Semaphore;
use std::sync::Arc;
async fn parking_demonstration() {
let semaphore = Arc::new(Semaphore::new(2));
println!("Starting parking demo with 2 permits");
// 创建多个任务竞争有限资源
let handles: Vec<_> = (0..5).map(|id| {
let sem = semaphore.clone();
tokio::spawn(async move {
println!("[Task {}] Waiting for permit...", id);
let permit = sem.acquire().await.unwrap();
println!("[Task {}] Acquired permit, working...", id);
// 模拟工作
sleep(Duration::from_secs(1)).await;
println!("[Task {}] Releasing permit", id);
drop(permit); // 显式释放
})
}).collect();
for handle in handles {
handle.await.unwrap();
}
}专业思考:性能优化与最佳实践
在实际应用中,充分发挥Tokio调度器的性能需要遵循一些最佳实践。首先是避免在异步任务中进行阻塞操作,任何同步IO或长时间计算都应该通过spawn_blocking转移到专用的阻塞线程池。其次是合理控制任务粒度,过细的任务会增加调度开销,过粗的任务会影响响应性和公平性。
另一个关键点是理解任务亲和性。虽然work-stealing能够动态平衡负载,但频繁的任务迁移会破坏缓存局部性。对于有状态的任务,考虑使用LocalSet将相关任务绑定到同一线程执行。同时,监控运行时的度量指标(如队列深度、窃取频率)可以帮助识别性能瓶颈。
最后,要认识到调度器配置没有银弹。工作线程数量、队列大小等参数需要根据具体工作负载进行调优。CPU密集型应用通常使用与CPU核心数相同的线程数,而IO密集型应用可能需要更多线程以隐藏IO延迟。通过系统化的性能测试和分析,找到最适合自己应用场景的配置。
rust
use tokio::runtime::Builder;
fn create_optimized_runtime() {
let num_cpus = num_cpus::get();
let runtime = Builder::new_multi_thread()
.worker_threads(num_cpus)
.max_blocking_threads(num_cpus * 4)
.thread_keep_alive(Duration::from_secs(10))
.global_queue_interval(31)
.event_interval(61)
.build()
.unwrap();
runtime.block_on(async {
// 混合工作负载示例
let mut handles = vec![];
// CPU密集型任务
for i in 0..num_cpus {
handles.push(tokio::spawn(async move {
let result = fibonacci(30 + i);
println!("Fibonacci result: {}", result);
}));
}
// IO密集型任务
for i in 0..num_cpus * 2 {
handles.push(tokio::spawn(async move {
sleep(Duration::from_millis(100)).await;
println!("IO task {} completed", i);
}));
}
// 阻塞操作
handles.push(tokio::task::spawn_blocking(|| {
std::thread::sleep(Duration::from_secs(1));
println!("Blocking operation completed");
}));
for handle in handles {
handle.await.unwrap();
}
});
}
fn fibonacci(n: usize) -> u64 {
match n {
0 => 0,
1 => 1,
_ => fibonacci(n - 1) + fibonacci(n - 2),
}
}结语
Tokio的多线程调度器代表了现代异步运行时设计的巅峰水平。通过work-stealing算法、分层队列架构和精细的停放机制,它在保持简洁API的同时实现了卓越的性能。深入理解调度器的工作原理,不仅能帮助我们写出更高效的异步代码,更能培养对并发系统的深刻洞察。随着Rust异步生态的不断成熟,掌握Tokio调度器必将成为高级Rust开发者的必备技能。
希望这篇文章能帮助你深入理解Tokio调度器的架构设计和实践应用!🦀⚡