本文将通过一个实际项目,带你了解如何使用 Spring AI Alibaba 构建一个智能的 Text-To-SQL 系统,让自然语言成为你与数据库交互的桥梁。
什么是 Text-To-SQL 系统
Text-To-SQL 系统是一种将自然语言问题自动转换为结构化查询语言(SQL)的技术。简单来说,它充当了人类语言与数据库之间的翻译官,让用户无需掌握专业的 SQL 知识,只需用日常语言描述需求,系统便能自动生成对应的 SQL 查询语句并返回结果。
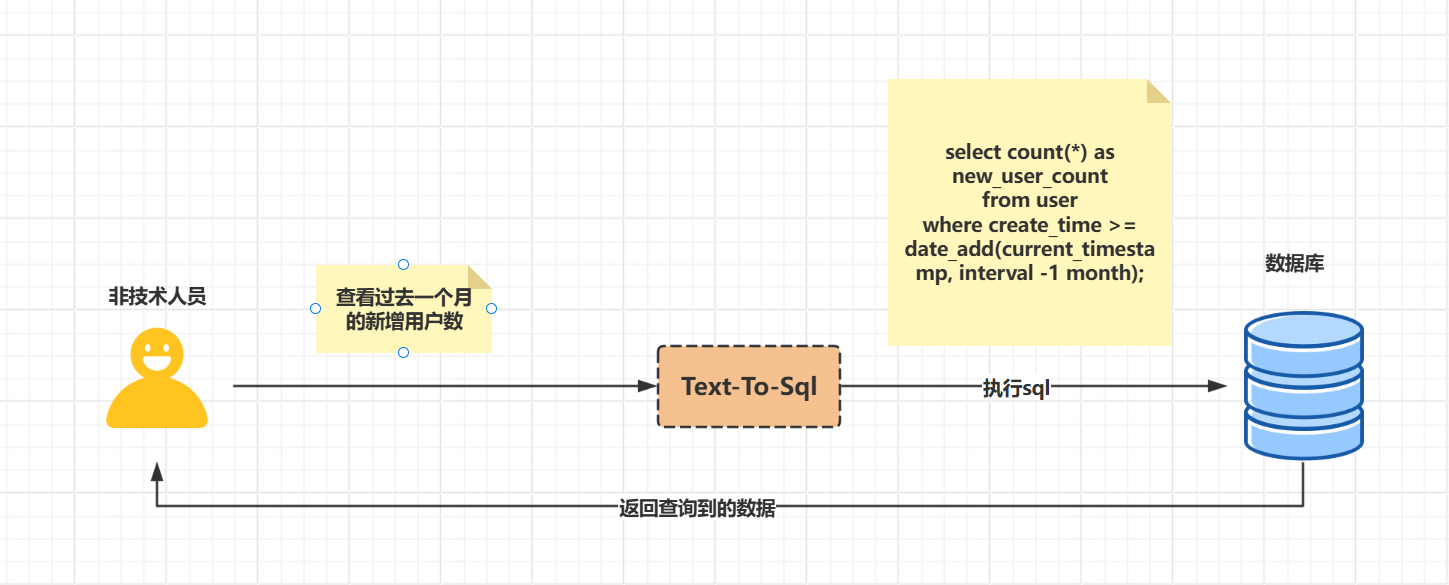
这项技术的核心价值在于降低数据查询的门槛 。在传统工作流程中,业务人员需要向技术人员提出数据需求,技术人员编写 SQL 后再返回结果,整个过程耗时且效率低下。而 Text-To-SQL 系统实现了数据访问的民主化,使分析师、业务人员等非技术背景的用户也能独立获取所需信息。
想象一下,在医院的场景中,医护人员只需询问"病人 X 的最新实验室结果是什么?",系统便能立即检索相关数据,而不需要手动浏览复杂的软件界面。同样,在金融领域,分析师可以通过"显示过去三年的收入"这样的简单问题,快速获得财务分析所需的数据。
现有开源 Text-To-SQL 系统
Chat2DB
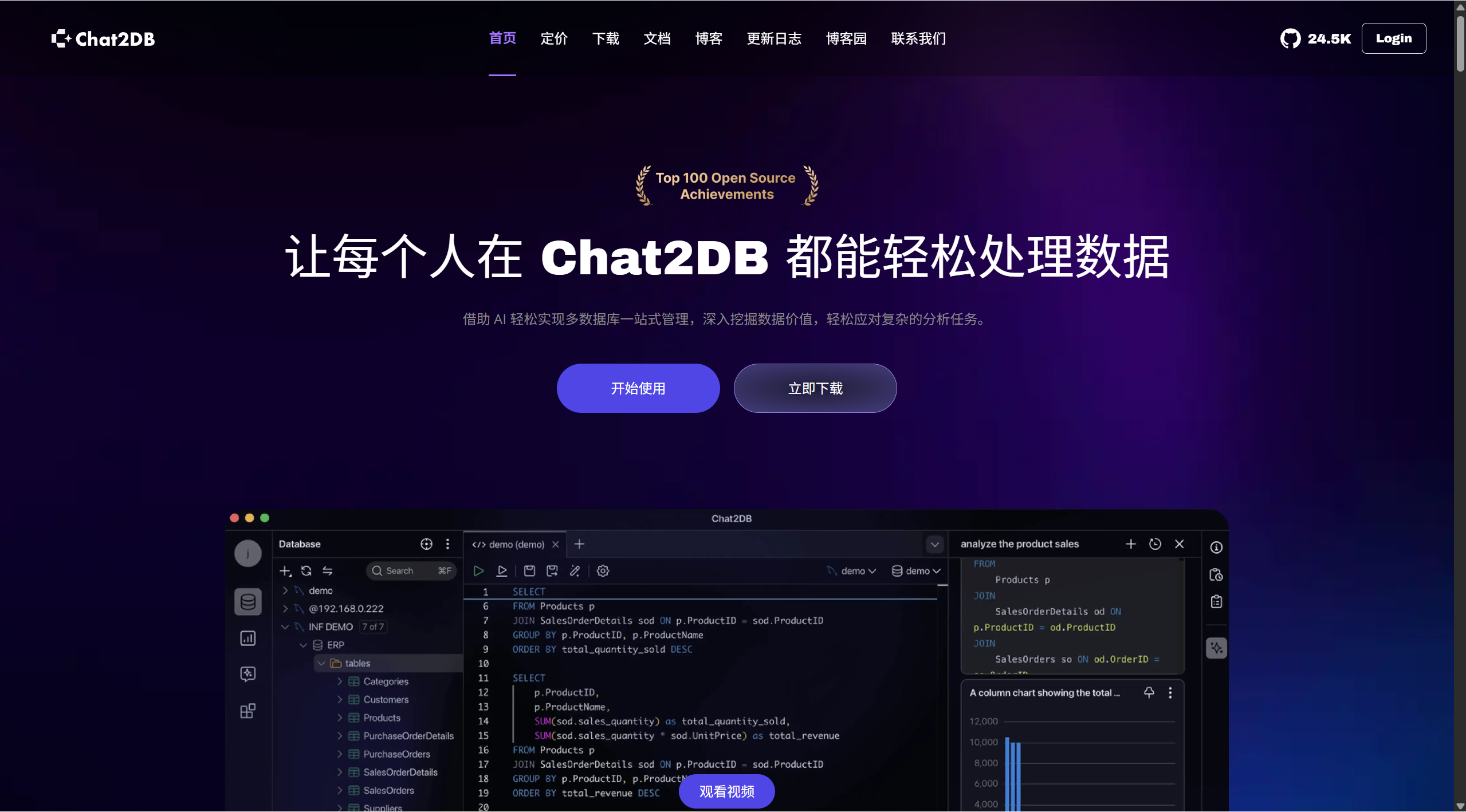
Chat2DB 是一款AI first的数据管理、开发、分析工具,它的核心是AIGC(Artificial Intelligence Generation Code)能力,它可以将自然语言转换为SQL,也可以将SQL转换为自然语言,也可以自动生成报表,极大的提升人员的效率。通过一个产品可以实现数据管理、数据开发、数据分析的能力,即使不懂SQL的运营业务也可以使用快速查询业务数据、生成报表能力。
主要特点:
- 多数据库支持:兼容 MySQL、PostgreSQL、Oracle、SQL Server、SQLite、ClickHouse、OceanBase、Hive、MongoDB、Redis、Snowflake 等多种数据库。
- AI 驱动 SQL:从自然语言快速生成可执行 SQL,降低技术门槛。
- 报表与可视化:分析结果可直接生成报告或大屏可视化,方便展示。
核心原理:
- RAG 增强的两阶段生成:通过检索增强生成(RAG)自动匹配数据库表。首先构建表摘要和历史查询的向量索引,用户提问时生成问题嵌入,与索引进行相似性搜索,推断出 Top-N 候选表。再由 LLM 筛选出 Top-K 表并验证,最终生成 SQL。
SQL Chat

SQL Chat 是一个基于聊天的 SQL 客户端,使用自然语言与数据库以沟通的方式,实现对数据库的查询、修改、新增、删除等操作。
主要特点:
- 畅聊式界面 ------ 不再被复杂界面卡住,只需一句话,就能驱动数据库操作,顺滑又高效。
- 多库支持 ------ 目前兼容 MySQL、PostgreSQL、MSSQL 以及 TiDB Cloud,未来有望扩展更多类型。
- 技术栈现代 ------ 基于 Next.js 构建,可以快速部署到 Vercel,也可选择自托管方案。
核心原理:
- 提示词工程驱动的大模型生成:通过动态注入数据库类型和表结构构建约束提示词,调用大模型流式生成 SQL,再经语法与操作类型校验确保安全性,最终输出可执行 SQL。
Vanna
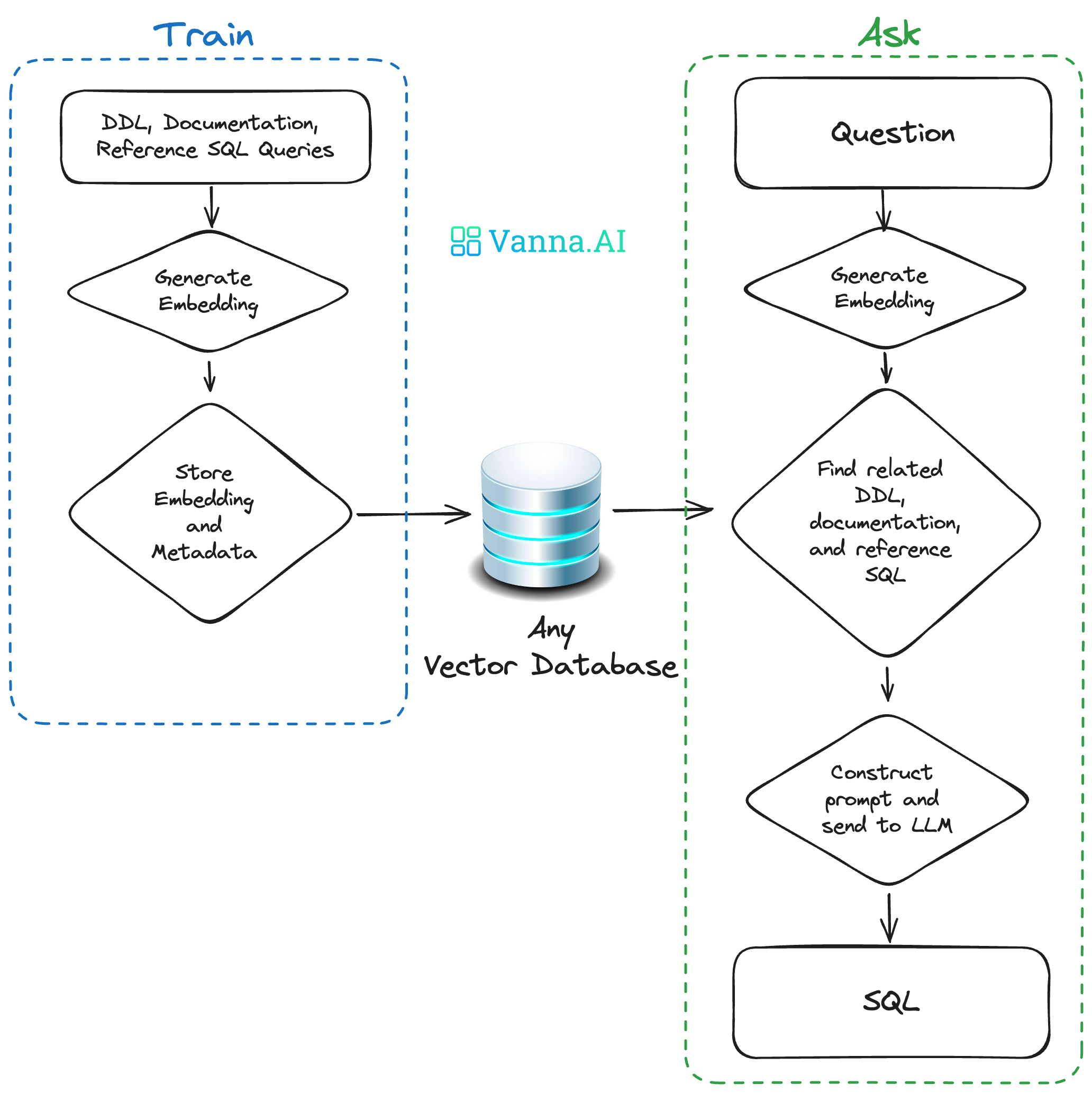
Vanna是一个MIT许可的开源Python RAG(检索增强生成)框架,用于SQL生成和相关功能。
主要特点:
- 高精度适配复杂数据集 ------ 性能与训练数据量紧密相关,更多训练数据可提升大型复杂数据集的 SQL 生成精度。
- 安全隐私保障 ------ 数据库内容不会发送至 LLM 或向量数据库,SQL 执行在本地环境进行,确保数据安全。
- 自学习能力 ------ Jupyter 环境支持 "自动训练",基于成功执行的查询学习;其他接口可通过用户反馈收集有效 "问题 - SQL" 对,持续优化结果。
- 多数据库兼容 ------ 支持所有 Python 可访问的 SQL 数据库,包括 PostgreSQL、MySQL、Snowflake、BigQuery、SQLite 等。
核心原理:
- 基于 RAG 框架实现转换:通过训练构建知识库,将 DDL、文档、SQL 示例处理为向量存储;用户提问时,检索相关数据构建上下文,调用 LLM 生成 SQL,经提取和清理确保可执行。
- 自学习迭代优化:成功执行的 SQL 会被加入训练数据,不断积累有效 "问题 - SQL" 对,提升后续检索精度和 LLM 生成效果,逐步提高转换准确性。
Text-To-SQL 系统基本架构
结合上述开源项目的实现,Text-To-SQL 的核心原理如下
- 用户提出分析性问题。
- 将问题、选定的 SQL 方言和表 Schema 编译成一个 Text-To-SQL 提示词(Prompt)。
- 提示词被输入到 LLM(大型语言模型)中。
- 生成并向用户显示流式响应。
对应的示意图:
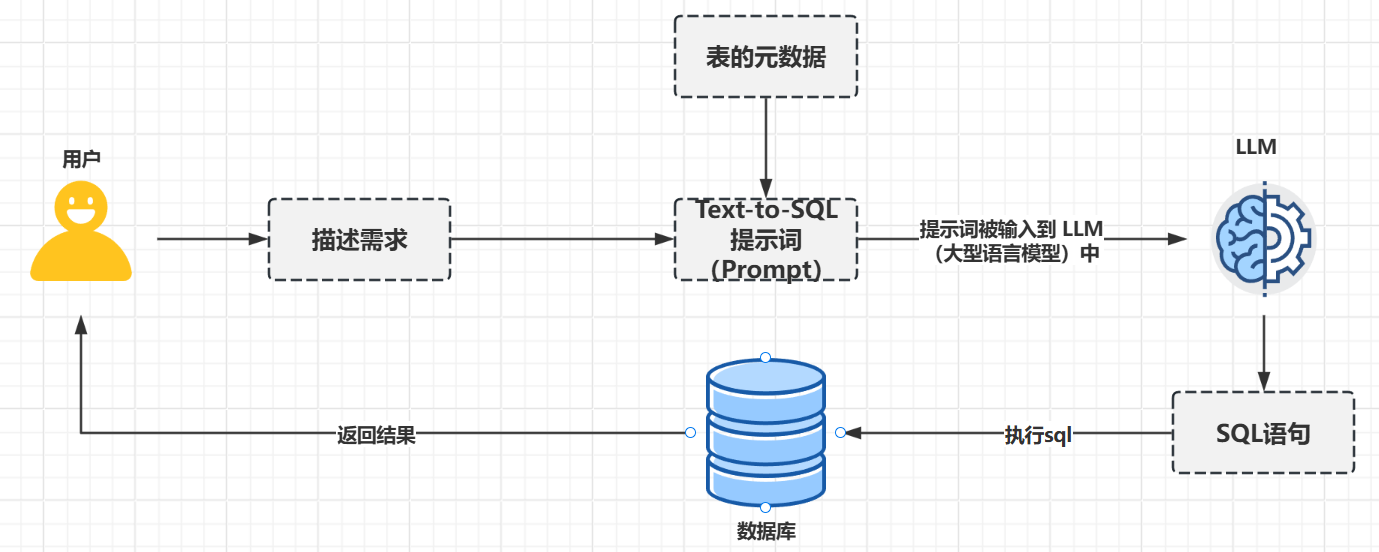
图中存在一个问题:怎么拿到表的元数据
如何获取表的元数据(Schema)
方案一:直接检索出所有表的元数据作为提示词的一部分输入给 AI
优点:
- 自动化程度高:无需用户干预,系统自动获取全量元数据(表名、字段、关系等),适合用户对数据库结构完全不了解的场景。
- 覆盖全面:理论上不会遗漏任何可能相关的表,避免因 "漏选表" 导致的 SQL 生成错误(如多表关联场景)。
缺点:
- 信息过载:当数据库表数量多(如数百张表)或表结构复杂(如宽表含数十列)时,元数据文本量会超出 LLM 的上下文窗口限制,导致模型无法完整处理。
- 噪音干扰:大量无关表的元数据(如与用户问题无关的日志表、历史表)会稀释核心信息,增加 LLM 的理解难度,可能生成包含错误表 / 字段的 SQL(如误关联无关表)。
- 效率低下:全量元数据会延长提示词长度,增加 LLM 的处理时间,降低响应速度。
方案二:由用户选择对应的表,再从数据库中查询出表的元数据输入给 AI
优点:
- 针对性强:用户明确选择相关表,元数据聚焦于目标表,提示词简洁,减少噪音干扰,LLM 生成 SQL 的准确率更高(尤其单表或已知表关联场景)。
- 可控性高:用户可根据业务经验筛选表,避免系统误判无关表,适合数据库结构稳定、用户熟悉表逻辑的场景。
缺点:
- 依赖用户专业度:若用户不熟悉数据库结构(如非技术人员),可能选错表(如混淆 "订单表" 和 "订单明细表"),或漏选关联表(如查询 "用户订单金额" 时漏选 "用户表"),直接导致 SQL 错误。
- 操作复杂度高:多表关联场景下,用户需手动选择所有相关表,增加交互成本(如 "查询各区域的产品销售额" 需选择 "区域表""产品表""销售表"),降低体验流畅度。
方案三:基于 RAG 找出与用户问题最相关的一些表的元素据输入给 AI
优点:
- 解决 "信息过载" 与 "噪音干扰":RAG 通过向量检索(将用户问题与表元数据的语义向量匹配),仅筛选出与问题高度相关的表(如用户问 "近 30 天的订单量",自动匹配 "订单表" 而非 "库存表"),避免全量元数据的冗余输入,确保提示词简洁且聚焦核心信息,提升 LLM 的理解效率。
- 降低对用户专业度的依赖:无需用户手动选择表,系统通过语义匹配自动识别相关表(即使用户用业务术语描述问题,如 "查活跃用户数" 对应 "用户表" 和 "登录记录表"),尤其适合非技术用户或复杂数据库场景(用户难以记住所有表结构)。
缺点:
- 向量数据库的搭建与维护复杂需部署专门的向量数据库(如 Chroma、PgVector、Pinecone 等),并设计适配表元数据的存储结构(如为每张表的 "表名 + 字段名 + 注释 + 示例值" 创建向量条目)。同时需处理向量索引优化(如 IVF、HNSW 索引)以提升检索速度,还需实现元数据变更后的向量自动更新(如监听数据库 DDL 操作触发重新嵌入),这对底层存储和运维能力要求较高。
- 依赖嵌入模型的语义理解能力,存在 "检索偏差" 风险 RAG 的核心是通过向量相似度匹配表元数据与用户问题,但嵌入模型对领域术语、模糊表达或复杂语义的理解可能存在偏差:
-
- 例如,用户问 "查客单价"(业务术语,指 "平均订单金额"),若表元数据中字段名为 "avg_order_amount" 且注释缺失,嵌入模型可能无法将 "客单价" 与该字段关联,导致检索不到相关的 "订单表"。
- 对多义词(如 "苹果" 可能指水果或公司),若上下文不足,嵌入模型可能匹配错误的表(如误将 "产品表" 中的 "苹果手机" 关联到 "水果库存表")。
方案 3 通过 RAG 的 "语义自动匹配" 机制,既规避了方案 1 的信息冗余问题,又解决了方案 2 对用户专业度的强依赖,是复杂数据库场景下实现高效、准确 Text-To-SQL 转换的核心方案。
基于 RAG 语义自动匹配机制实现 Text-To-SQL 架构
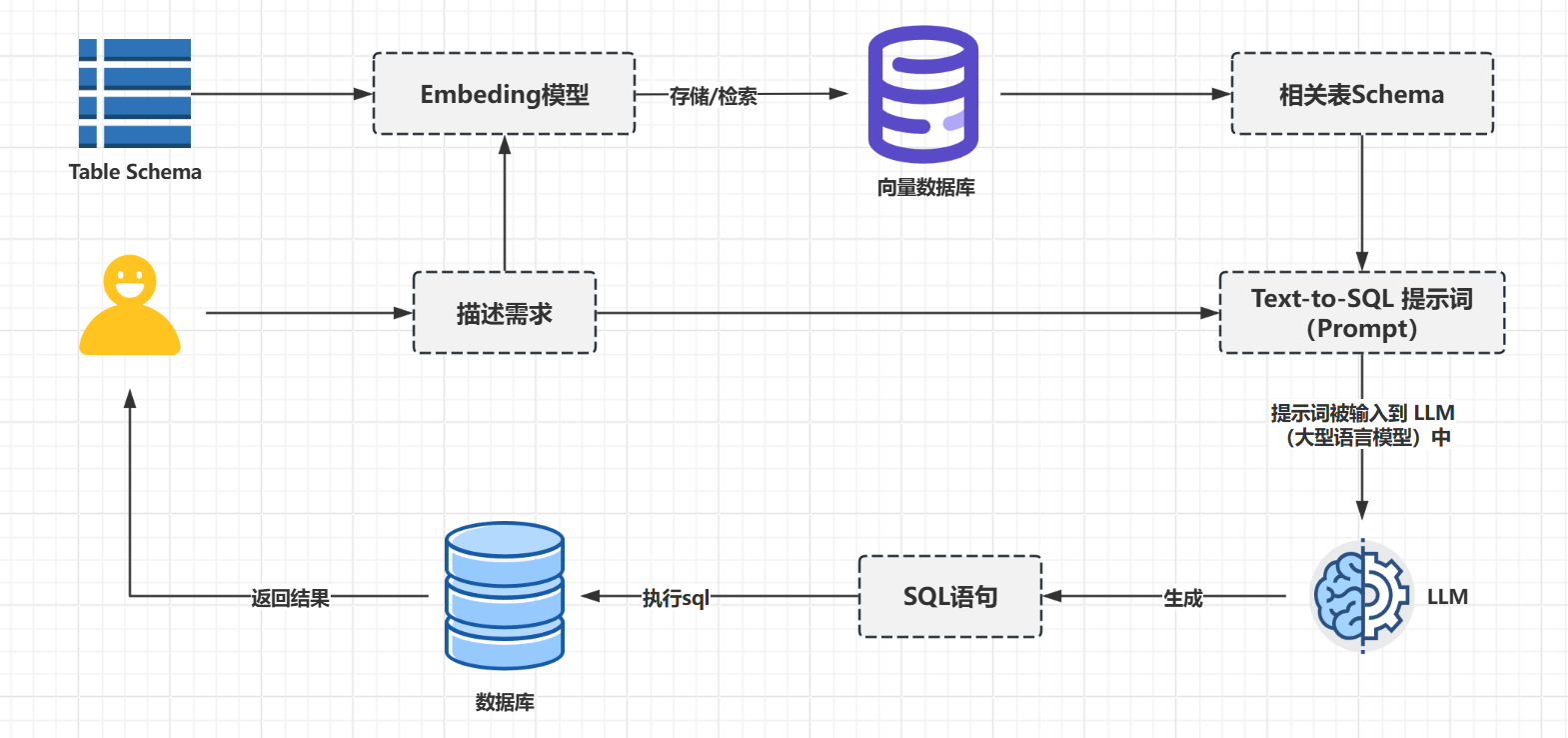
表结构预处理阶段(离线 / 初始化环节)
- 输入 :系统首先获取数据库的
Table Schema(表结构,包括表名、字段名、字段类型、注释、表间关系等元数据)。 - 向量转换与存储 :
Table Schema被输入Embedding模型,转换为具有语义信息的向量(数值表示),随后这些向量被存储到向量数据库中,形成 "表结构向量知识库"。(此阶段为离线准备,目的是将结构化的表元数据转化为可用于语义匹配的向量,为后续检索做准备。)
用户需求处理与检索阶段(实时交互环节)
- 用户输入:用户通过 "描述需求" 模块输入自然语言问题(如 "查询 2023 年各地区的销售额")。
- 双路径处理:
-
- 一方面,用户需求直接作为生成提示词的基础素材;
- 另一方面,用户需求被同步输入
Embedding模型,转换为与表结构向量同维度的 "需求向量"。
- 语义匹配检索 :
向量数据库接收 "需求向量" 后,通过语义相似度计算(如余弦相似度),从 "表结构向量知识库" 中检索出与用户需求最相关的相关表Schema(如 "地区表""销售表" 的结构元数据)。
SQL 生成与执行阶段(核心转换环节)
- 提示词构建 :检索到的
相关表Schema与用户的 "描述需求" 结合,形成Text-To-SQL提示词(Prompt)------ 提示词中既包含用户的自然语言意图,又明确了所需的表结构信息(字段、类型、关系等),为 LLM 提供精准约束。 - LLM 生成 SQL :
提示词被输入LLM(大型语言模型),模型基于提示词中的上下文(用户需求 + 相关表结构),生成符合语法规范且匹配业务逻辑的SQL语句。 - 执行与反馈 :生成的
SQL语句被发送到实际数据库中执行,执行结果最终返回给用户,完成从自然语言到数据结果的闭环
上述方案已经具备实现一个初级 Text-To-SQL 系统的要求,但距离实现一个企业级的 Text-To-SQL 系统还有待优化的方面主要分为两个方面:Table Schema 检索优化、SQL 生成优化
Table Schema 检索优化
方案引入了 RAG 机制实现 Table Schema 的智能检索,但是使用的是最原始的 RAG 架构,其存在以下几个问题:
- **无差别触发 RAG 检索,无效消耗且降低效率:**原始 RAG 对所有用户输入都执行向量检索,但用户输入可能包含非检索意图(如寒暄 "你好"、系统指令 "帮助"、错误输入 "abc"),若直接触发 RAG 会浪费资源(如向量检索、LLM 调用)。
- **未处理口语化 / 专业化术语差异,匹配精准度低:**用户输入可能存在模糊表达(如 "最近的销售数据")、行业黑话(如电商的 "GMV""SKU")或口语化描述(如 "买了好几次的用户"),直接用于检索会导致向量匹配偏差。
- **仅按相似度排序,未过滤冗余 / 低相关片段:**基础 RAG 仅通过语义相似度返回 Top-N 表,可能包含无关表(如用户问 "订单金额" 却返回 "库存表")或排序不合理(次要表排在前面)。
- **未判断检索出的元数据是否满足查询要求:**会直接导致 LLM 生成 SQL 时由于信息缺失,生成的SQL中可能会存未知的表和字段,最终导致 SQL 执行失败或返回错误结果。
优化方案:
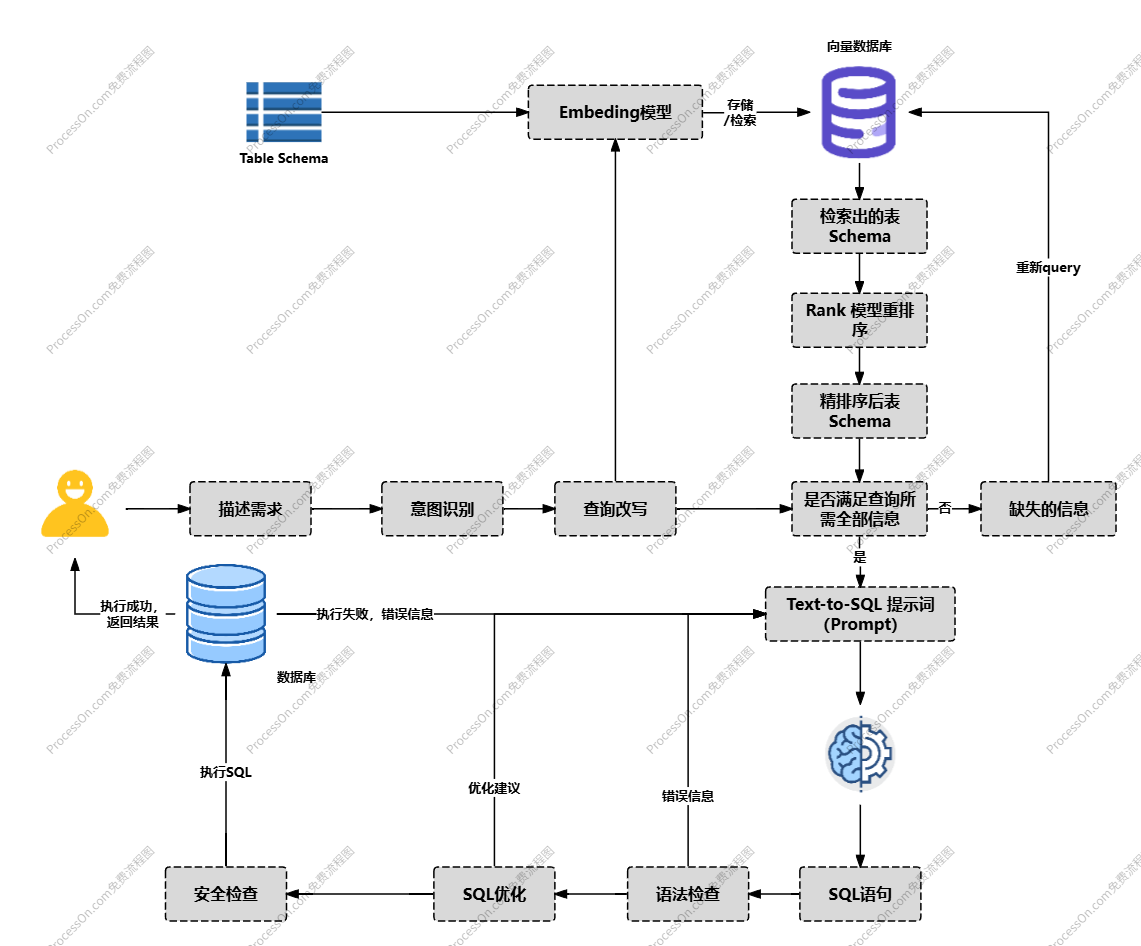
针对 1、2 两点,通过预设前置校验模块,对用户原始输入进行意图识别:
- 先通过规则库与轻量意图识别模型判断输入是否为检索意图。规则库预设寒暄词(如 "你好")、系统指令词(如 "帮助")、无效字符组合(如 "abc@#")等非检索特征,模型对模糊输入做二分类判断(需检索 / 无需检索),非检索意图直接返回对应响应,避免无效 RAG 触发。
- 对判定为检索意图的输入,启动术语标准化处理。基于行业术语库(如 "GMV"→"商品交易总额")、口语 - 业务映射表(如 "买了好几次"→"高频购买用户")微调后的模型自动完成术语转换、意图补全,生成与元数据语义对齐的检索文本,提升向量匹配精度。
针对第 3 点,使用 rank 模型结合业务规则进行排序过滤:
- 向量检索先召回 Top-N 候选表元数据,再通过业务规则粗筛(如 "订单金额" 查询过滤 "库存表" 等无关表)。
- 引入轻量 rank 模型(如 CrossBERT),融合文本相似度、业务域匹配度、字段必要性等特征计算相关度得分,同时叠加规则权重(含明确字段的表优先级 + 30%,关联表 + 20%),最终返回 Top-N 核心表,剔除冗余并优化排序。
针对第 4 点,预设后置校验模块,判断元数据是否满足查询要求:
- 解析查询所需元数据类型(如单表查询需表名、字段名及类型,多表查询需关联字段),逐项校验召回结果。
- 若存在缺失(如字段无枚举注释、关联关系未明确),生成补充检索 query 二次调用 RAG 避免 LLM 因信息不全生成错误 SQL。
SQL 生成优化
在流程中,LLM 生成 SQL 后就直接扔到数据库中执行没有经过任何校验,是一种很危险的操作存在一下问题:
- **LLM 生成的 SQL 可能存在语法错误:**LLM 可能因元数据理解偏差(如字段名拼写错误)或 SQL 语法规则混淆(如 MySQL 与 PostgreSQL 语法差异),生成语法错误的 SQL(如 "SELEC * FROM user" 少写 T、"GROUP BY" 缺字段),直接执行会触发数据库语法报错,浪费资源且影响体验。
- LLM 生成的 SQL 包含危险操作: LLM 可能因用户查询歧义(如 "删除所有未付款的订单" 被误解为 "删除订单表所有数据")或自身逻辑偏差,生成
DROP、TRUNCATE、DELETE(无 WHERE 条件)等危险操作,直接执行会导致数据丢失;也可能生成ALTER TABLE、CREATE INDEX等 DDL 操作,破坏数据库结构。 - **未校验 SQL 是否可以优化:**LLM 生成的 SQL 可能存在 "全表扫描""Join 顺序不合理""缺少索引利用" 等隐性性能问题,这些 SQL 语法合法、逻辑正确,但执行时会占用大量数据库资源(如扫描 100 万行数据仅返回 10 行结果),直接执行会拖慢数据库整体响应速度。
优化方案:
针对第 1 点(语法错误),构建语法校验与方言适配模块:
- 添加语法校验节点,使用 LLM 对生成 SQL 结合 SQL 方言数据库版本进行语法校验,列出存在的问题以及解决办法交由 SQL 生成 LLM 重新生成 SQL。
针对第 2 点(危险操作),建立危险操作拦截与权限管控模块:
- 基于危险操作黑名单拦截绝对风险 SQL:直接阻断含 DROP、TRUNCATE、ALTER TABLE 等 DDL 操作,以及无 WHERE 条件的 DELETE/UPDATE、SELECT (敏感字段)等 DML 操作。
- 对高风险但非绝对禁止的操作(如带 WHERE 条件的 DELETE),触发用户二次确认。
针对第 3 点(性能优化),设计性能瓶颈识别与自动优化模块:
- 基于自动优化规则库改写 SQL:消除 SELECT * 保留必要字段、调整 Join 顺序为 "小表 Join 大表"、适配索引调整 WHERE 条件顺序,复杂场景(如多层子查询)调用 LLM 辅助优化并返回优化理由。
优化后的架构
具体实现方案
接下我从实现一个最简单的 Text-To-SQl 系统(将用户原始输入和全部 Table Schema 作为提示词输入给 LLM )开始,一步步优化最终实现一个企业级的 Text-To-SQl 系统。