📚 系统架构说明
🎯 各组件的作用
1. Milvus - 向量数据库核心
- 作用: 存储和检索向量数据(embeddings)
- 为什么需要: 传统数据库存储文字,Milvus存储"语义",可以找到意思相近的内容
- 端口: 19530 (主服务)
2. Attu - Milvus可视化管理界面(需按照我的配置)
- 访问地址: http://localhost:3000
- 作用 :
- 可视化查看 Milvus 中的所有集合(Collection,类似数据库中的表)
- 查看向量数据、索引状态
- 监控系统性能和资源使用
- 方便调试:可以看到你插入了多少条数据,数据的结构等
- 什么时候用: 当你想直观地看看 Milvus 里存了什么数据,或者排查问题时
3. MinIO - 对象存储(Milvus自带)
- 访问地址: http://localhost:9001 (9000: API 端口(用于程序访问)、9001: 控制台端口(用于网页访问))
- 默认账号: minioadmin / minioadmin
- 作用 :
- Milvus 用它来存储索引文件、日志文件等
- 类似于 AWS S3,但是在本地运行
- 存储大文件和向量索引数据
- 什么时候用: 一般不需要直接操作,但如果想备份数据或查看存储空间使用情况可以访问,如果放文件的话也可以直接用
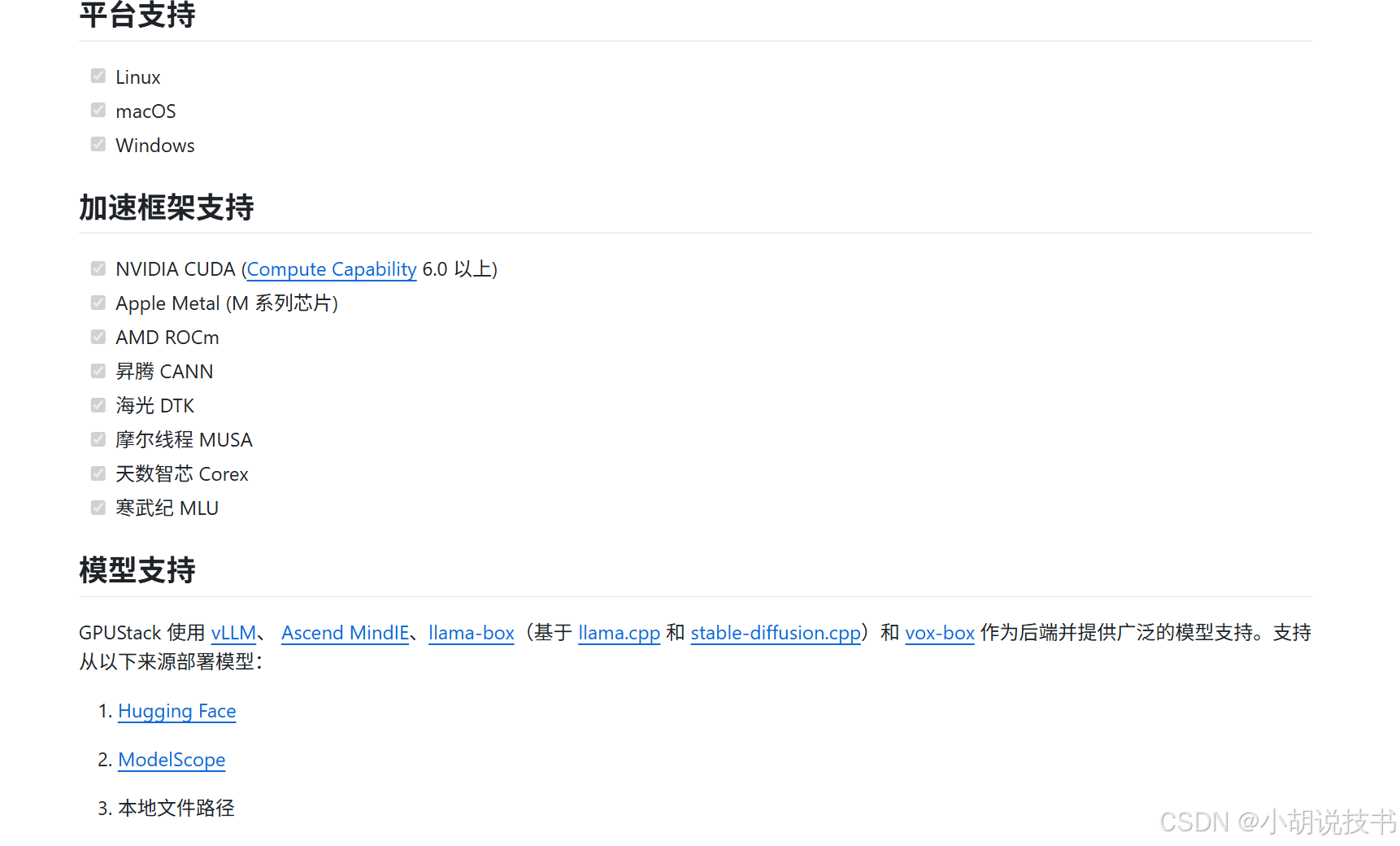
4. GPUStack - AI 模型推理服务
- API 地址: http://localhost:9999/v1-openai
- 作用 :
- 提供 LLM 对话能力(qwen3)
- 提供文本嵌入能力(qwen3-embedding)
- 提供重排序能力(bge-reranker-v2-m3)
- 兼容性: 使用 OpenAI 标准接口,可以用 OpenAI 的 SDK
熟悉完后可以整合dify:使用 Milvus 部署 Dify;
统计用Directus自动生成REST API 和 GraphQL API接口,完整的 CRUD 功能;https://directus.io/
Directus和Dify后端都用PostgreSQL(存大模型返回的json+地图),同时在结合图数据库Neo4j(图谱构建),前端用vue3+TS+EP(Cursor辅助写),结合中小企业内部数据(互联网没有,数据安全不太严格)也能做出不错的应用。当然是使用人数少(几百我感觉)+内部使用的情况下。
一、docker安装Milvus + GPUStack 模型下载
1.1 Milvus
新建一个文件夹,创建docker-compose.yml,把以下的内容复制。GPU 内存池大小(单位:MB)我默认注释了,可以根据自己显卡的容量更改。本版本是单机版GPU版。
yaml
version: '3.5'
services:
# ==================== etcd 服务 ====================
# etcd 是分布式键值存储,Milvus 用它存储元数据(集合信息、索引信息等)
etcd:
container_name: milvus-etcd
image: quay.io/coreos/etcd:v3.5.18
environment:
# 自动压缩模式:基于版本号压缩
- ETCD_AUTO_COMPACTION_MODE=revision
# 保留最近1000个版本
- ETCD_AUTO_COMPACTION_RETENTION=1000
# 后端数据库配额:4GB
- ETCD_QUOTA_BACKEND_BYTES=4294967296
# 快照触发阈值:每5万次操作创建一次快照
- ETCD_SNAPSHOT_COUNT=50000
volumes:
# 持久化存储:将 etcd 数据挂载到本地 volumes/etcd 目录
- ${DOCKER_VOLUME_DIRECTORY:-.}/volumes/etcd:/etcd
command: etcd -advertise-client-urls=http://etcd:2379 -listen-client-urls http://0.0.0.0:2379 --data-dir /etcd
healthcheck:
# 健康检查:每30秒检查一次 etcd 是否正常
test: ["CMD", "etcdctl", "endpoint", "health"]
interval: 30s
timeout: 20s
retries: 3
# ==================== MinIO 服务 ====================
# MinIO 是对象存储,Milvus 用它存储向量数据、索引文件、日志等
minio:
container_name: milvus-minio
image: minio/minio:RELEASE.2024-12-18T13-15-44Z
environment:
# MinIO 访问密钥(默认账号密码,生产环境需修改)
MINIO_ACCESS_KEY: minioadmin
MINIO_SECRET_KEY: minioadmin
ports:
# 9001: MinIO Web 控制台端口(浏览器访问 http://localhost:9001)
- "9001:9001"
# 9000: MinIO API 端口(Milvus 通过此端口访问对象存储)
- "9000:9000"
volumes:
# 持久化存储:将 MinIO 数据挂载到本地 volumes/minio 目录
- ${DOCKER_VOLUME_DIRECTORY:-.}/volumes/minio:/minio_data
command: minio server /minio_data --console-address ":9001"
healthcheck:
# 健康检查:每30秒检查一次 MinIO 是否正常
test: ["CMD", "curl", "-f", "http://localhost:9000/minio/health/live"]
interval: 30s
timeout: 20s
retries: 3
# ==================== Milvus 主服务 ====================
# Milvus 单机版(Standalone):包含所有功能的一体化服务
standalone:
container_name: milvus-standalone
image: milvusdb/milvus:v2.6.4-gpu # GPU 版本,支持 GPU 加速向量搜索
command: ["milvus", "run", "standalone"]
security_opt:
# 安全配置:允许容器使用更多系统调用(GPU 需要)
- seccomp:unconfined
environment:
# etcd 连接地址
ETCD_ENDPOINTS: etcd:2379
# MinIO 连接地址
MINIO_ADDRESS: minio:9000
# 消息队列类型:woodpecker(Milvus 2.6+ 内置轻量级 MQ)
MQ_TYPE: woodpecker
# 可选:GPU 内存池大小(单位:MB)
# KNOWHERE_GPU_MEM_POOL_SIZE: 8192 # 根据显卡显存调整
volumes:
# 持久化存储:将 Milvus 数据挂载到本地 volumes/milvus 目录
- ${DOCKER_VOLUME_DIRECTORY:-.}/volumes/milvus:/var/lib/milvus
ports:
# 19530: Milvus gRPC 端口(客户端连接端口)
- "19530:19530"
# 9091: Milvus Metrics 端口(监控指标,Prometheus 可采集)
- "9091:9091"
deploy:
resources:
reservations:
devices:
# GPU 配置:使用第一块显卡(device_ids: ["0"])
- driver: nvidia
capabilities: ["gpu"]
device_ids: ["0"] # 如有多块显卡,可改为 ["0","1"]
depends_on:
# 依赖关系:先启动 etcd 和 minio,再启动 Milvus
- "etcd"
- "minio"
# ==================== Attu 可视化界面 ====================
# Attu 是 Milvus 的官方图形化管理工具,提供 Web UI
attu:
container_name: milvus-attu
image: zilliz/attu:latest
environment:
# Milvus 连接地址(容器间通信使用服务名)
MILVUS_URL: milvus-standalone:19530
ports:
# 3000: Attu Web 界面端口(浏览器访问 http://localhost:3000)
- "3000:3000"
depends_on:
# 依赖 Milvus 主服务
- "standalone"
# ==================== 网络配置 ====================
# 创建自定义网络,所有服务在同一网络中可以通过服务名互相访问
networks:
default:
name: milvus配置说明总结
| 服务 | 端口 | 用途 | 数据目录 |
|---|---|---|---|
| etcd | 2379 | 元数据存储 | ./volumes/etcd |
| minio | 9000/9001 | 对象存储 | ./volumes/minio |
| standalone | 19530/9091 | Milvus 主服务 | ./volumes/milvus |
| attu | 3000 | Web 管理界面 | 无需持久化 |
启动命令
bash
# 启动所有服务
docker-compose up -d
# 查看服务状态
docker-compose ps
# 查看日志
docker-compose logs -f访问地址
- Milvus 服务 :
localhost:19530(客户端连接) - Attu 管理界面:http://localhost:3000
- MinIO 控制台:http://localhost:9001(账号密码:minioadmin/minioadmin)
- Prometheus 指标:http://localhost:9091/metrics
Attu 连接配置
打开 http://localhost:3000 后:
- Milvus Address :
milvus-standalone:19530(容器内)或localhost:19530(宿主机) - 无需认证(默认配置)
GPU 显存优化
如果需要限制 GPU 显存使用,取消注释并修改:
yaml
environment:
KNOWHERE_GPU_MEM_POOL_SIZE: 8192 # 8GB 显存搞定!现在可以 docker-compose up -d 一键启动了!🚀
GPUStack
bash
docker run -d --gpus all -p 9999:80 -v gpustack-data:/var/lib/gpustack --name gpustack gpustack/gpustack获取初始密码
bash
docker exec gpustack cat /var/lib/gpustack/initial_admin_password
等评估完后,可以再点击确定。
然后是获取api秘钥,保存好:
二、Anaconda测试(其他也可以,这里为本人习惯)
🚀 环境准备
步骤 1: 安装依赖
python
# 需要管理员运行
pip install pymilvus openai minio步骤 2: 导入库和配置
python
from pymilvus import connections, Collection, FieldSchema, CollectionSchema, DataType, utility
from openai import OpenAI
import numpy as np
import time
# GPUStack 配置(OpenAI 兼容接口)
client = OpenAI(
base_url="http://localhost:9999/v1-openai",
api_key="fake-key" # 刚才获取的
)
# Milvus 配置
MILVUS_HOST = "localhost"
MILVUS_PORT = "19530"
print("✅ 配置完成!")🧪 测试 GPUStack 各个模型
测试 1: LLM 对话模型(qwen3)
python
# 测试 qwen3 聊天模型
print("🤖 测试 qwen3 聊天模型...")
response = client.chat.completions.create(
model="qwen3",
messages=[
{"role": "system", "content": "你是一个友好的AI助手。"},
{"role": "user", "content": "用一句话解释什么是向量数据库?"}
],
temperature=0.7,
max_tokens=4000
)
answer = response.choices[0].message.content
print(f"✅ qwen3 回答: {answer}\n")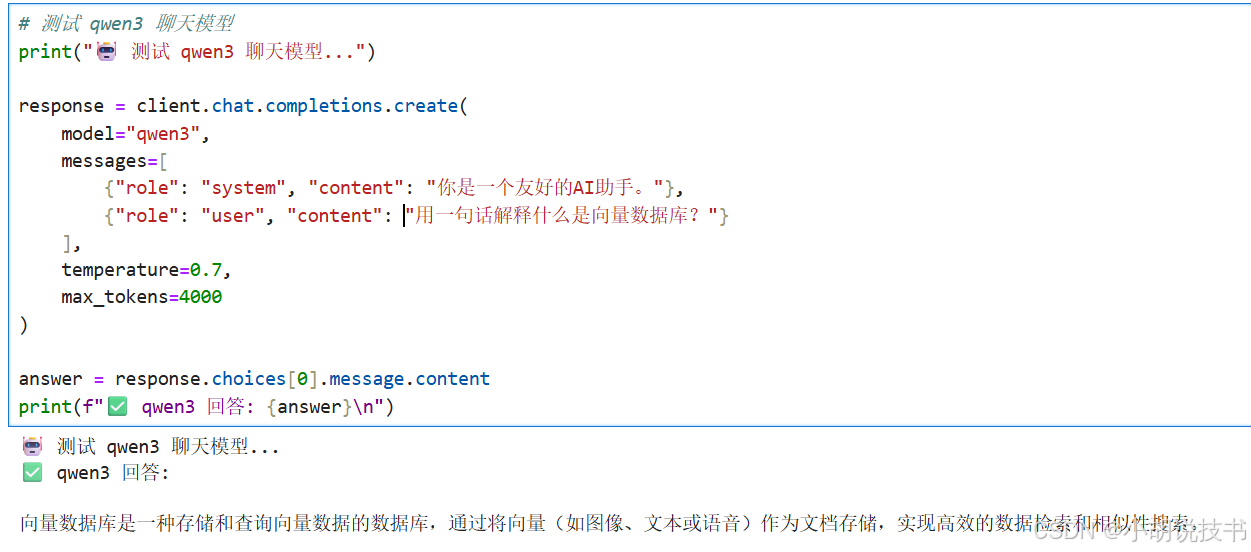
测试 2: 嵌入模型(qwen3-embedding)
python
# 测试 qwen3-embedding 嵌入模型
print("📊 测试 qwen3-embedding 嵌入模型...")
test_texts = [
"人工智能正在改变世界",
"AI is transforming the world",
"今天天气真好"
]
response = client.embeddings.create(
model="qwen3-embedding",
input=test_texts
)
for i, embedding in enumerate(response.data):
vector = embedding.embedding
print(f"✅ 文本 {i+1}: '{test_texts[i]}'")
print(f" 向量维度: {len(vector)}")
print(f" 向量前5维: {vector[:5]}\n")
# 保存维度信息,后面创建 Milvus 集合时需要
EMBEDDING_DIM = len(response.data[0].embedding)
print(f"📏 嵌入向量维度: {EMBEDDING_DIM}")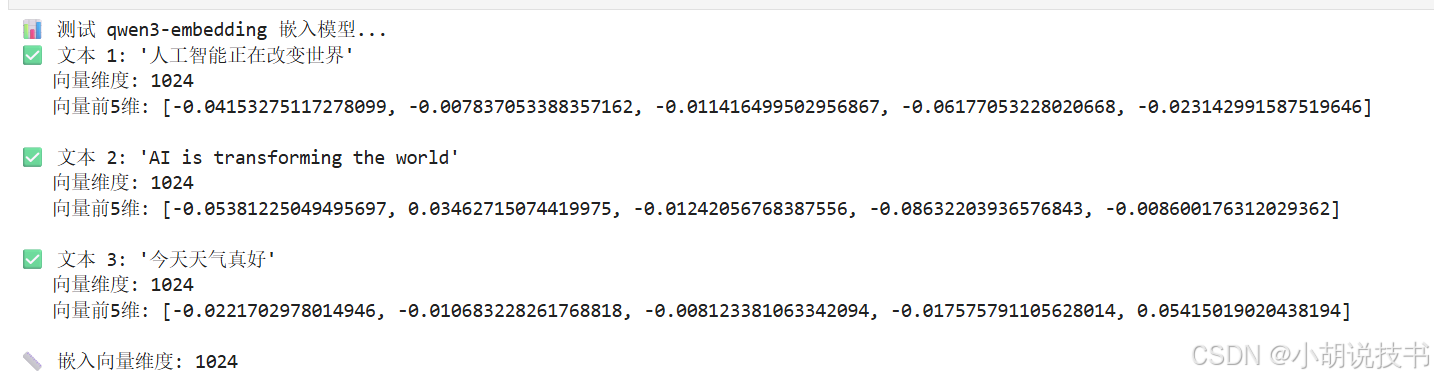
测试 3: 检查可用模型
python
# 检查 GPUStack 上可用的模型列表
print("📋 检查 GPUStack 可用模型...")
try:
models = client.models.list()
print("\n✅ 可用模型列表:\n")
for model in models.data:
print(f" - {model.id}")
except Exception as e:
print(f"❌ 获取模型列表失败: {e}")
print("\n💡 说明: 重排序模型通常不通过 chat/completions 接口调用")
print(" 在实际 RAG 应用中,我们会在下面的案例中展示如何手动实现重排序")
测试 3 补充: 手动实现简单重排序
python
# 使用嵌入向量相似度实现简单的重排序
print("\n🔄 演示手动重排序逻辑...")
import numpy as np
def cosine_similarity(vec1, vec2):
"""计算余弦相似度"""
return np.dot(vec1, vec2) / (np.linalg.norm(vec1) * np.linalg.norm(vec2))
query = "如何学习机器学习?"
documents = [
"机器学习入门需要先学习Python编程",
"今天天气很好,适合出去玩",
"深度学习是机器学习的一个重要分支",
"我喜欢吃苹果"
]
# 生成查询和文档的嵌入
print("生成嵌入向量...")
all_texts = [query] + documents
response = client.embeddings.create(
model="qwen3-embedding",
input=all_texts
)
query_embedding = np.array(response.data[0].embedding)
doc_embeddings = [np.array(item.embedding) for item in response.data[1:]]
# 计算相似度并排序
scores = []
for i, doc_emb in enumerate(doc_embeddings):
similarity = cosine_similarity(query_embedding, doc_emb)
scores.append((documents[i], similarity))
# 按相似度降序排序
scores.sort(key=lambda x: x[1], reverse=True)
print(f"\n查询: {query}\n")
print("重排序结果 (按相关性从高到低):\n")
for i, (doc, score) in enumerate(scores):
print(f"{i+1}. 相似度: {score:.4f}")
print(f" 文档: {doc}\n")
🗄️ 测试 Milvus 连接和基本操作
步骤 1: 连接 Milvus
python
# 连接到 Milvus
print("🔌 连接 Milvus...")
connections.connect(
alias="default",
host=MILVUS_HOST,
port=MILVUS_PORT
)
print("✅ Milvus 连接成功!")
print(f"📋 当前集合列表: {utility.list_collections()}")
步骤 2: 创建集合(Collection)
python
# 创建一个简单的文档集合
COLLECTION_NAME = "demo_documents"
# 如果集合已存在,先删除
if utility.has_collection(COLLECTION_NAME):
utility.drop_collection(COLLECTION_NAME)
print(f"🗑️ 删除旧集合: {COLLECTION_NAME}")
# 定义集合的字段(Schema)
fields = [
FieldSchema(name="id", dtype=DataType.INT64, is_primary=True, auto_id=True),
FieldSchema(name="text", dtype=DataType.VARCHAR, max_length=1000),
FieldSchema(name="embedding", dtype=DataType.FLOAT_VECTOR, dim=EMBEDDING_DIM)
]
schema = CollectionSchema(fields=fields, description="测试文档集合")
# 创建集合
collection = Collection(name=COLLECTION_NAME, schema=schema)
print(f"✅ 创建集合成功: {COLLECTION_NAME}")
print(f"📊 集合字段: {[field.name for field in schema.fields]}")
步骤 3: 插入数据
python
# 准备一些测试文档
documents = [
"机器学习是人工智能的一个分支,让计算机从数据中学习。",
"深度学习使用神经网络来处理复杂的模式识别任务。",
"自然语言处理帮助计算机理解和生成人类语言。",
"计算机视觉让机器能够识别和理解图像中的内容。",
"Python是数据科学和机器学习最流行的编程语言。"
]
print("📝 生成文档的嵌入向量...")
# 使用 GPUStack 生成嵌入向量
response = client.embeddings.create(
model="qwen3-embedding",
input=documents
)
embeddings = [item.embedding for item in response.data]
print(f"✅ 生成了 {len(embeddings)} 个嵌入向量")
# 插入数据到 Milvus
print("💾 插入数据到 Milvus...")
insert_data = [
documents, # text 字段
embeddings # embedding 字段
]
collection.insert(insert_data)
collection.flush() # 确保数据写入
print(f"✅ 成功插入 {len(documents)} 条文档")
print(f"📊 集合中的文档数量: {collection.num_entities}")
步骤 4: 创建索引
python
# 为向量字段创建索引,加速搜索
print("🔧 创建向量索引...")
index_params = {
"index_type": "IVF_FLAT",
"metric_type": "L2", # 欧氏距离
"params": {"nlist": 128}
}
collection.create_index(
field_name="embedding",
index_params=index_params
)
print("✅ 索引创建成功!")
# 加载集合到内存,准备搜索
collection.load()
print("✅ 集合已加载到内存")
步骤 5: 向量搜索
python
# 搜索相似文档
search_query = "如何学习编程?"
print(f"🔍 搜索查询: '{search_query}'")
print("生成查询向量...")
# 生成查询的嵌入向量
query_response = client.embeddings.create(
model="qwen3-embedding",
input=[search_query]
)
query_vector = [query_response.data[0].embedding]
# 在 Milvus 中搜索
search_params = {"metric_type": "L2", "params": {"nprobe": 10}}
results = collection.search(
data=query_vector,
anns_field="embedding",
param=search_params,
limit=3, # 返回top3结果
output_fields=["text"] # 返回文本内容
)
print(f"\n📋 搜索结果 (Top 3):\n")
for i, hit in enumerate(results[0]):
print(f"{i+1}. 距离: {hit.distance:.4f}")
print(f" 文本: {hit.entity.get('text')}\n")
🎯 综合案例:完整的 RAG 流程
基础版 RAG
python
def rag_query(question: str, top_k: int = 3):
"""
完整的 RAG (检索增强生成) 流程
步骤:
1. 将问题转换为向量
2. 在 Milvus 中检索相关文档
3. 使用 LLM 基于检索结果生成回答
"""
print(f"❓ 用户问题: {question}\n")
# 1️⃣ 生成问题的嵌入向量
print("1️⃣ 生成问题向量...")
query_response = client.embeddings.create(
model="qwen3-embedding",
input=[question]
)
query_vector = [query_response.data[0].embedding]
# 2️⃣ 在 Milvus 中检索相关文档
print("2️⃣ 检索相关文档...")
search_params = {"metric_type": "L2", "params": {"nprobe": 10}}
results = collection.search(
data=query_vector,
anns_field="embedding",
param=search_params,
limit=top_k,
output_fields=["text"]
)
# 提取检索到的文档
retrieved_docs = [hit.entity.get('text') for hit in results[0]]
print(f" 找到 {len(retrieved_docs)} 个相关文档\n")
for i, doc in enumerate(retrieved_docs):
print(f" 📄 文档 {i+1}: {doc}")
# 3️⃣ 构造 prompt 并用 LLM 生成回答
print("\n3️⃣ 生成回答...")
context = "\n".join([f"- {doc}" for doc in retrieved_docs])
prompt = f"""基于以下参考文档回答问题。如果文档中没有相关信息,请说"根据提供的信息无法回答"。
参考文档:
{context}
问题:{question}
请用简洁的语言回答:"""
response = client.chat.completions.create(
model="qwen3",
messages=[
{"role": "system", "content": "你是一个专业的AI助手,基于提供的参考文档回答问题。"},
{"role": "user", "content": prompt}
],
temperature=0.3,
max_tokens=300
)
answer = response.choices[0].message.content
print("\n" + "="*60)
print(f"🤖 AI 回答:\n{answer}")
print("="*60 + "\n")
return answer
# 测试基础 RAG 系统
print("🎯 测试基础 RAG 流程\n")
test_questions = [
"什么是深度学习?",
"Python 在 AI 领域有什么作用?",
]
for question in test_questions:
rag_query(question)
print("\n" + "-"*80 + "\n")
增强版 RAG(带重排序)
python
def rag_query_with_rerank(question: str, initial_k: int = 5, final_k: int = 3):
"""
带重排序的增强 RAG 流程
步骤:
1. 将问题转换为向量
2. 在 Milvus 中检索更多候选文档(initial_k)
3. 使用余弦相似度重排序,选出最相关的文档(final_k)
4. 使用 LLM 基于重排序后的结果生成回答
"""
print(f"❓ 用户问题: {question}\n")
# 1️⃣ 生成问题的嵌入向量
print("1️⃣ 生成问题向量...")
query_response = client.embeddings.create(
model="qwen3-embedding",
input=[question]
)
query_vector = [query_response.data[0].embedding]
query_embedding = np.array(query_response.data[0].embedding)
# 2️⃣ 在 Milvus 中检索更多候选文档
print(f"2️⃣ 检索 {initial_k} 个候选文档...")
search_params = {"metric_type": "L2", "params": {"nprobe": 10}}
results = collection.search(
data=query_vector,
anns_field="embedding",
param=search_params,
limit=initial_k,
output_fields=["text"]
)
# 提取候选文档
candidate_docs = [hit.entity.get('text') for hit in results[0]]
# 3️⃣ 重排序:计算精确的余弦相似度
print(f"3️⃣ 重排序,选出最相关的 {final_k} 个文档...")
# 为候选文档生成嵌入
docs_response = client.embeddings.create(
model="qwen3-embedding",
input=candidate_docs
)
# 计算余弦相似度
scores = []
for i, doc_data in enumerate(docs_response.data):
doc_embedding = np.array(doc_data.embedding)
similarity = np.dot(query_embedding, doc_embedding) / (
np.linalg.norm(query_embedding) * np.linalg.norm(doc_embedding)
)
scores.append((candidate_docs[i], similarity))
# 按相似度降序排序,取 top final_k
scores.sort(key=lambda x: x[1], reverse=True)
reranked_docs = [doc for doc, _ in scores[:final_k]]
print(f" 重排序后的文档:\n")
for i, (doc, score) in enumerate(scores[:final_k]):
print(f" 📄 {i+1}. (相似度: {score:.4f}) {doc}")
# 4️⃣ 构造 prompt 并用 LLM 生成回答
print("\n4️⃣ 生成回答...")
context = "\n".join([f"- {doc}" for doc in reranked_docs])
prompt = f"""基于以下参考文档回答问题。如果文档中没有相关信息,请说"根据提供的信息无法回答"。
参考文档:
{context}
问题:{question}
请用简洁的语言回答:"""
response = client.chat.completions.create(
model="qwen3",
messages=[
{"role": "system", "content": "你是一个专业的AI助手,基于提供的参考文档回答问题。"},
{"role": "user", "content": prompt}
],
temperature=0.3,
max_tokens=300
)
answer = response.choices[0].message.content
print("\n" + "="*60)
print(f"🤖 AI 回答:\n{answer}")
print("="*60 + "\n")
return answer
# 测试增强版 RAG(带重排序)
print("🎯 测试增强版 RAG(带重排序)\n")
test_question = "如何理解自然语言?"
rag_query_with_rerank(test_question, initial_k=5, final_k=3)
🧹 清理资源
python
# 运行完测试后,可以选择清理资源
# 释放集合
collection.release()
print("✅ 集合已从内存卸载")
# 如果想删除集合(谨慎使用!)
# utility.drop_collection(COLLECTION_NAME)
# print(f"🗑️ 已删除集合: {COLLECTION_NAME}")
# 断开连接
connections.disconnect("default")
print("✅ 已断开 Milvus 连接")📊 在 Attu 中查看结果
运行完上面的代码后,你可以:
- 打开 Attu: 访问 http://localhost:3000
- 查看集合 : 在左侧菜单找到
demo_documents集合 - 查看数据 :
- 点击集合名称,如果刚才释放了,可以右键加载。
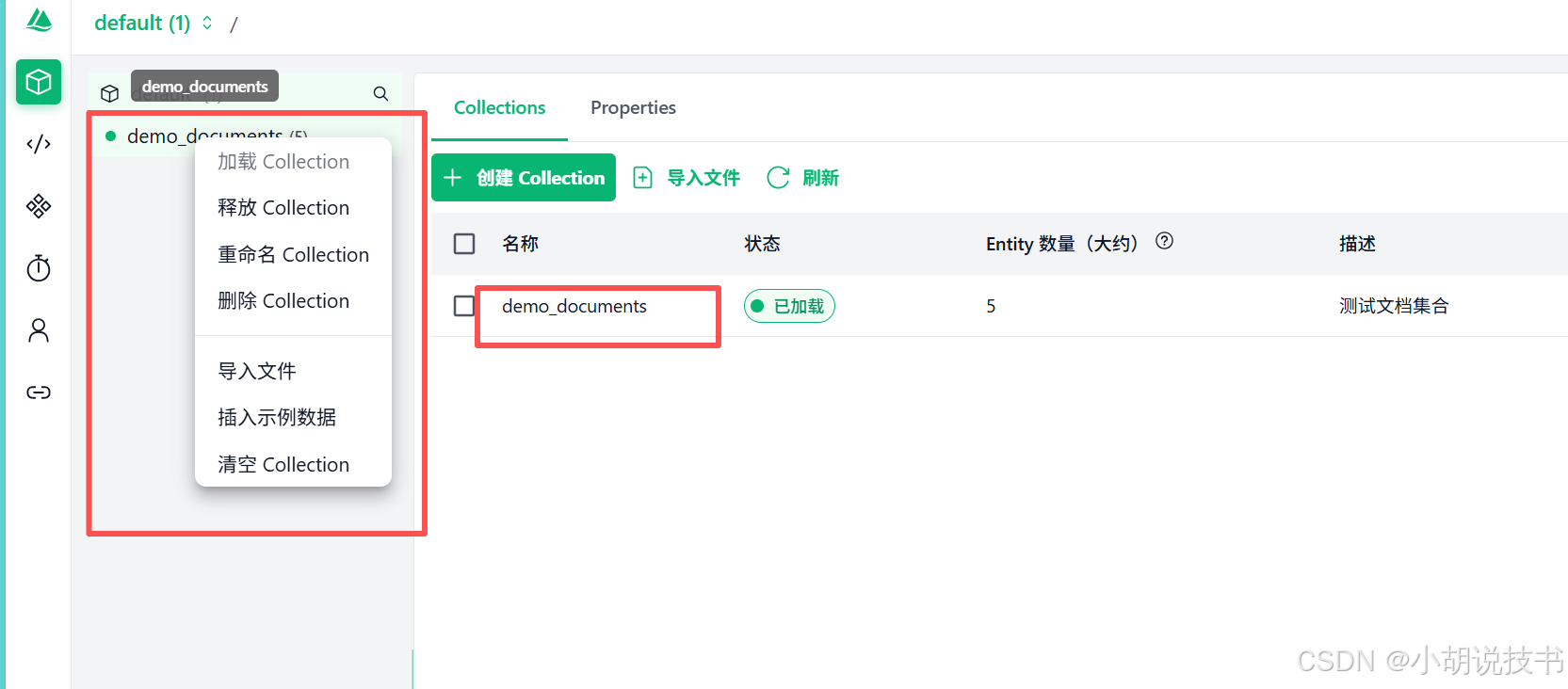
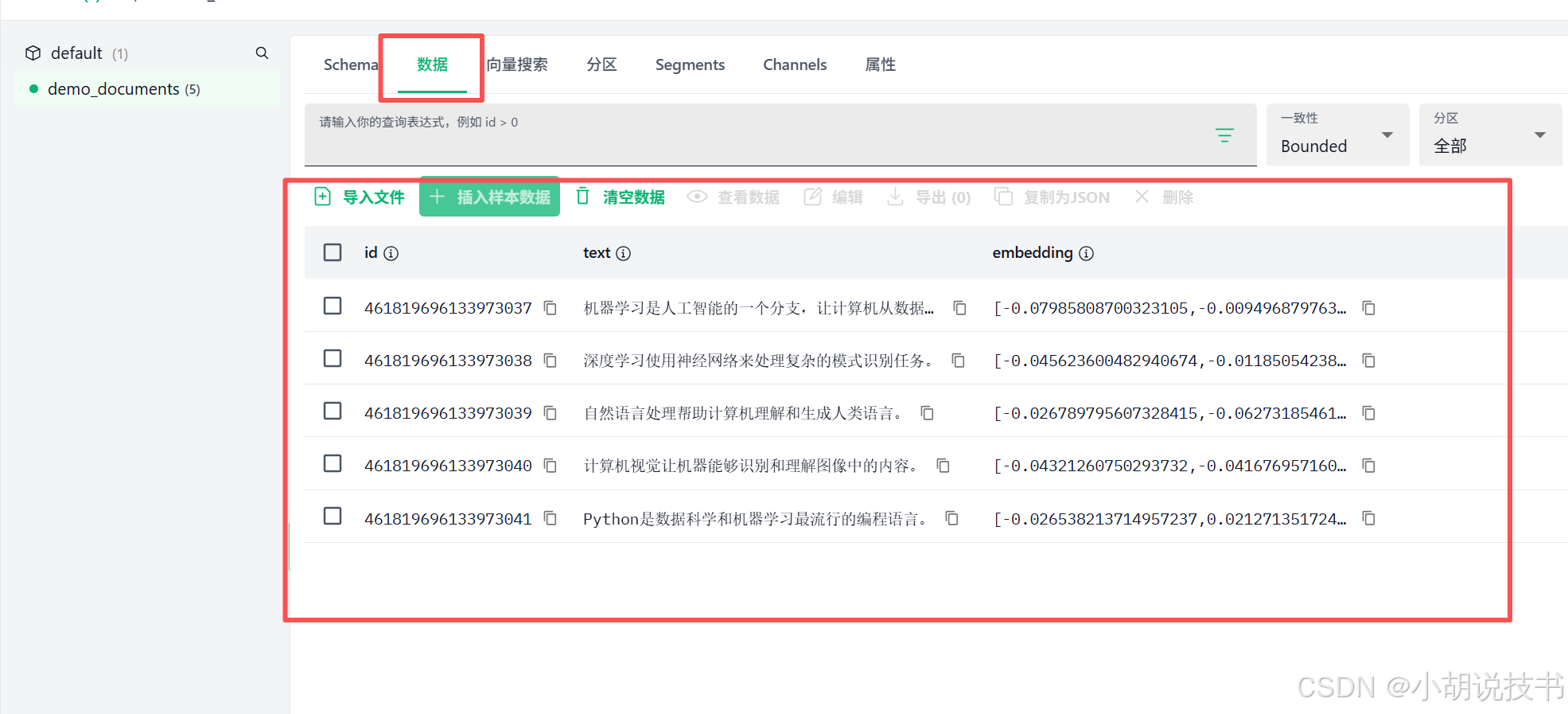
- 可以看到你插入的5条文档
- 查看每条数据的 id、text 和 embedding
- 查看索引:
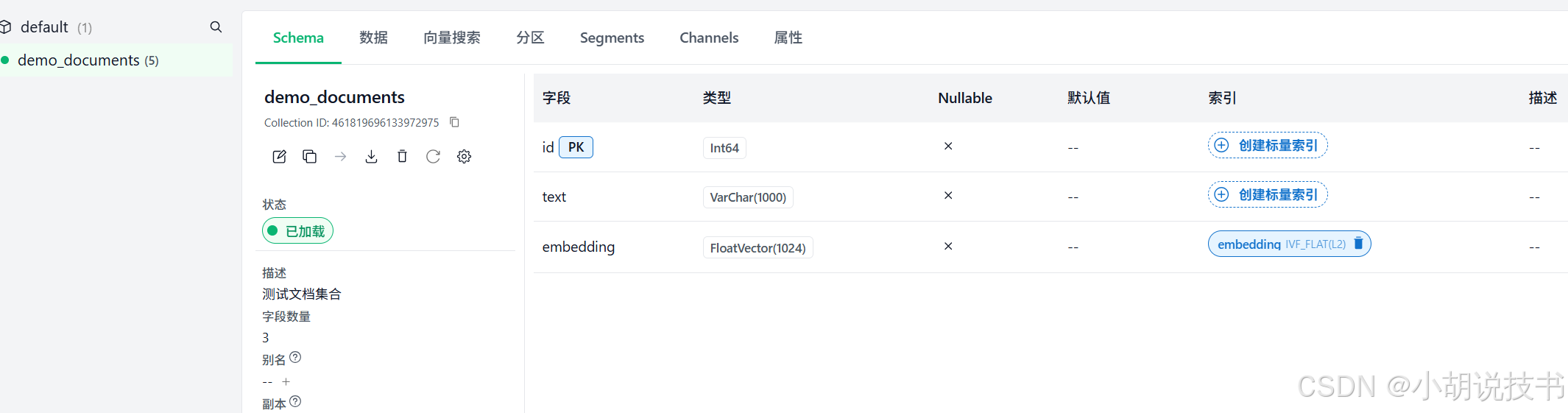
🔍 两种索引的区别:
┌─────────────────────────────────────────────────┐
│ 向量索引 (Vector Index) - 已创建 ✅ │
├─────────────────────────────────────────────────┤
│ 字段: embedding │
│ 类型: IVF_FLAT │
│ 用途: 向量相似度搜索 │
│ 场景: "找到语义相似的文档" │
│ 必需: ✅ 是(向量搜索必须有) │
└─────────────────────────────────────────────────┘
┌─────────────────────────────────────────────────┐
│ 标量索引 (Scalar Index) - 未创建 ⚪ │
├─────────────────────────────────────────────────┤
│ 字段: id, text │
│ 类型: INVERTED (倒排索引) │
│ 用途: 精确匹配、范围查询、关键词过滤 │
│ 场景: "找到 id > 100 且包含'机器学习'的文档" │
│ 必需: ⚪ 可选(但推荐) │
└─────────────────────────────────────────────────┘
- 监控性能 :
- 在 "System View" 查看 Milvus 的内存和 CPU 使用情况
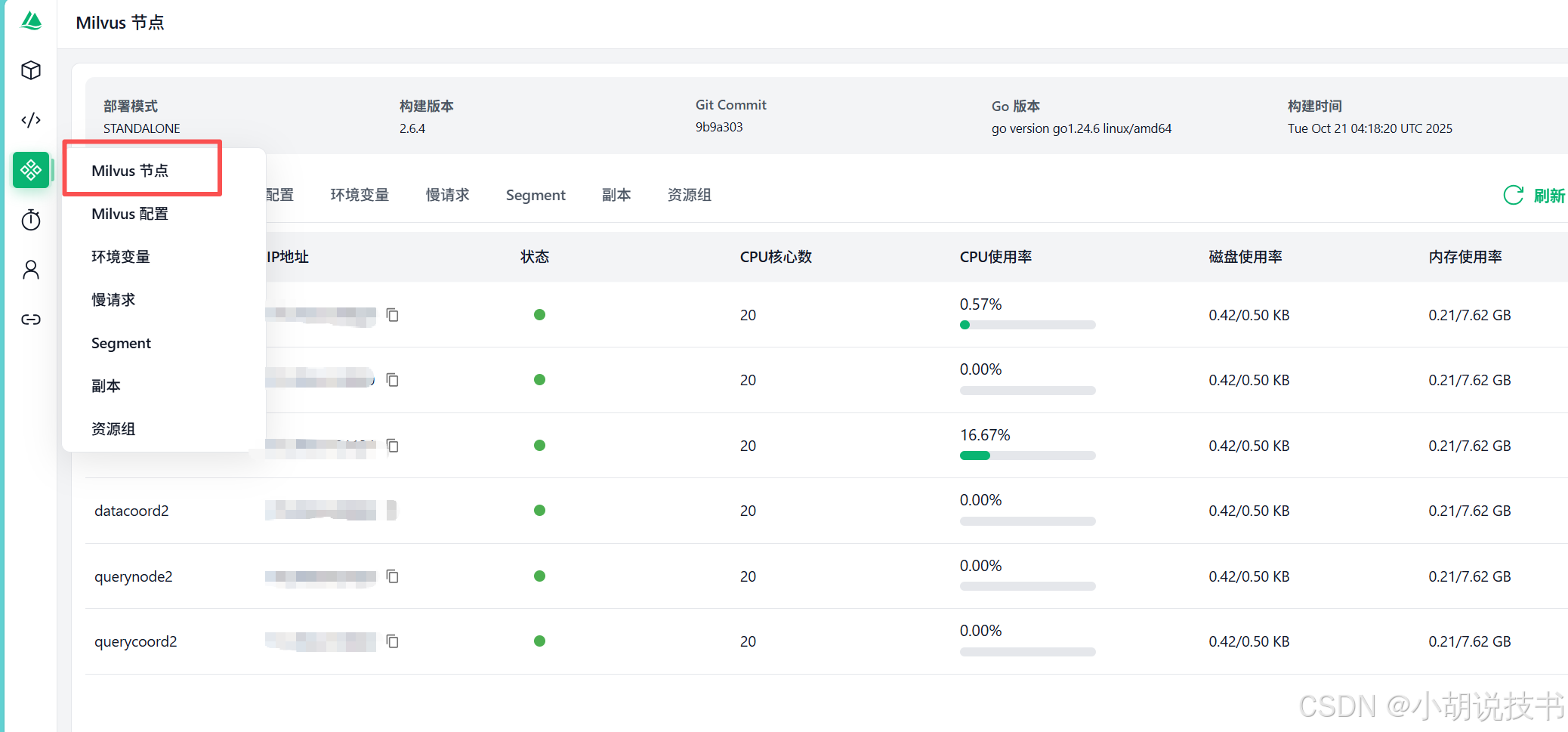
然后minio也可以监控。
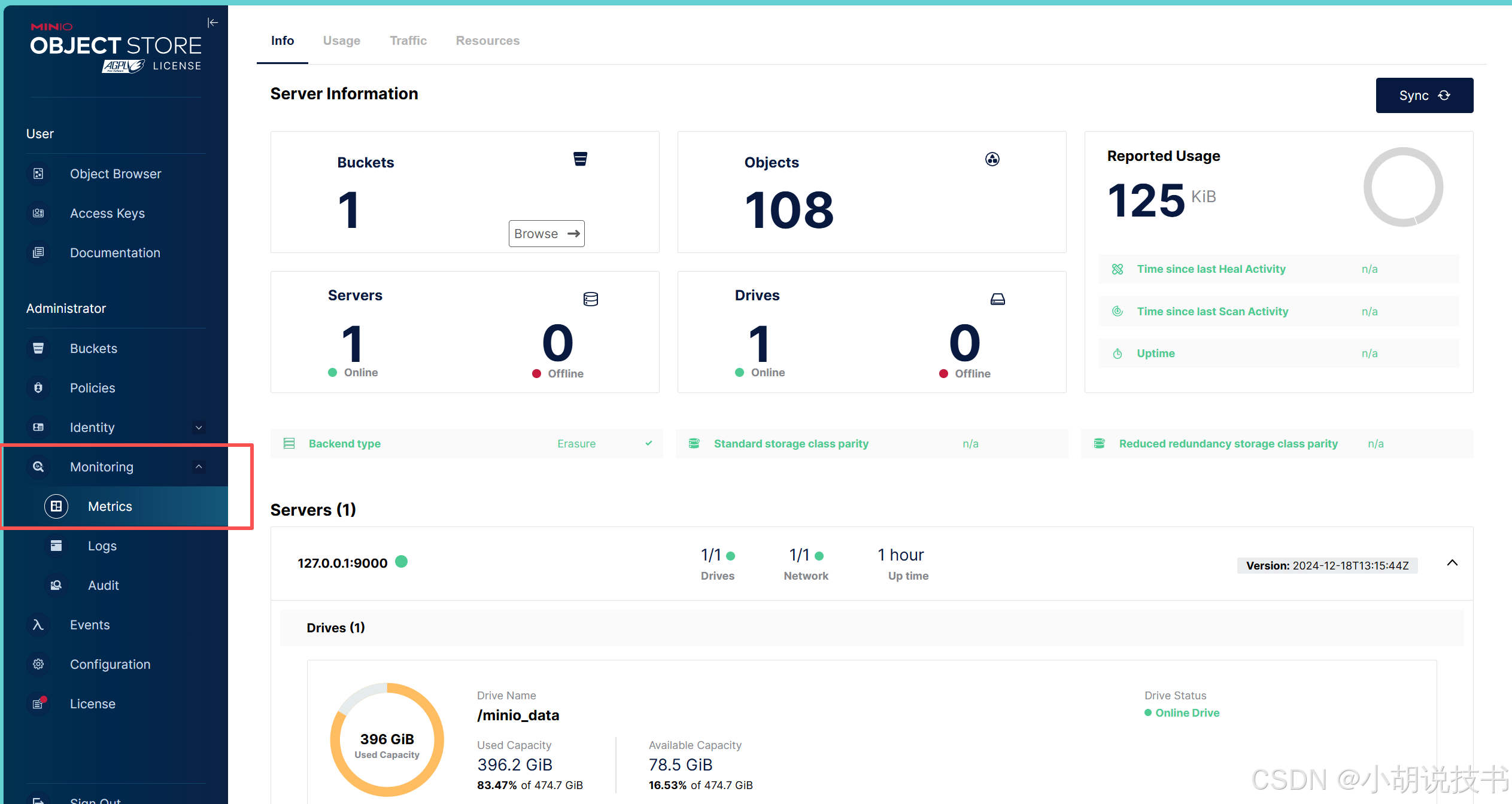
- 在 "System View" 查看 Milvus 的内存和 CPU 使用情况
🎓 核心概念总结
1. 嵌入(Embedding)
- 将文本转换为数字向量
- 语义相近的文本,向量也接近
- qwen3-embedding 生成的向量维度是固定的(运行代码可以看到具体维度)
2. 向量数据库(Milvus)
- 存储和检索向量数据
- 使用特殊的索引算法(如 IVF_FLAT)加速搜索
- 通过计算向量距离找到相似内容
3. RAG(检索增强生成)
- Retrieval: 先从知识库检索相关信息
- Augmented: 用检索结果增强 prompt
- Generation: LLM 基于增强后的信息生成回答
- 好处:让 LLM 基于你的私有数据回答问题
4. 重排序(Reranking)
- 第一步:向量搜索快速找到候选文档(可能有噪声)
- 第二步:使用更精确的方法(如计算余弦相似度或专门的重排序模型)评分
- 本教程中: 我们用余弦相似度实现了简单的重排序
- 生产环境: 如果 GPUStack 提供了专门的 rerank API,可以用 bge-reranker-v2-m3
- 通常用于需要高精度的场景
🚀 下一步建议
- 尝试更多数据: 插入更多文档,测试检索效果
- 调整参数 : 尝试不同的
top_k、temperature等参数 - 添加重排序: 在 RAG 中加入 bge-reranker 提升精度
- 实际应用: 用自己的文档数据构建知识库
🎉 恭喜!你已经完成了 Milvus + GPUStack 的基础入门!