分支结构分为if-else语句 与switch-case语句
一、if-else
练习:

代码实现:
c
#include<stdio.h>
int main(){
int n;
scanf("%d", &n);
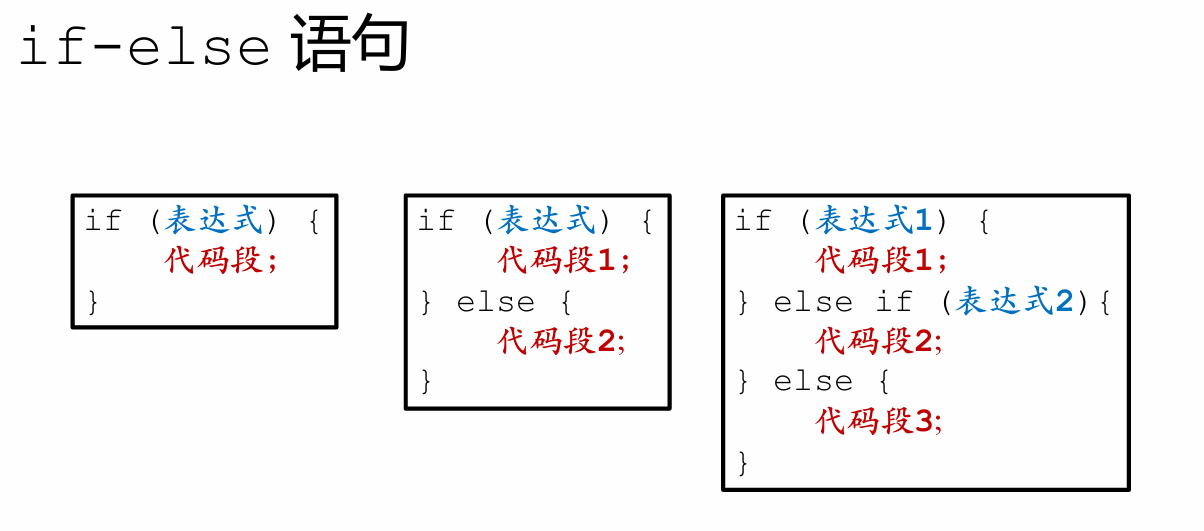
if (n == 0){
printf("HEHE");
} else if (n > 0 && n < 60){
printf("FAIL");
} else if (n >= 60 && n < 75){
printf("MEDIUM");
} else if (n >= 75 && n <= 100){
printf("GOOD");
}
printf("\n"); //在最后不要漏掉换行符
return 0;
}还可以这么写,充分利用else的否定意义,简洁精准
c
#include<stdio.h>
int main() {
int n;
scanf("%d", &n);
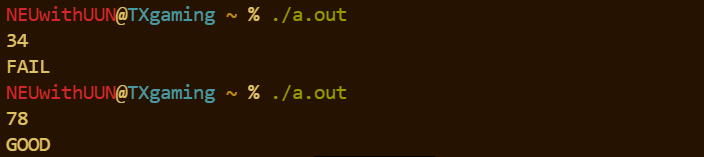
if (n == 0) printf("HEHE\n");
else if (n < 60) printf("FAIL\n");
else if (n < 75) printf("MEDIUM\n");
else if (n <= 100) printf("GOOD\n");
return 0;
}效果:
补充:
c
scanf("%d%d", &a, &b);
if (a < b) printf("YES\n");
else printf("NO\n");
//如果只是想要实现一条简单的语句,就可以使用不带{}的格式
//但是如果涉及到多步操作,我们就需要用上{}并且使用复合语句
if (a < b) {
c = a * b;
printf("c = %d\n", c);
//此处虽然有两条语句,但是他们在同一个大括号内,算作复合语句。
//此外语句之间应当用';'分隔
}
return 0;二、switch-case语句

a为一个表达式
这里表达式的值
如果等于v1,那么执行代码块1,再执行代码块2,依次类推;
如果等于v2,那么执行代码块2,再执行代码块3;
如果等于v3,那么执行代码块3;
在case v3下面可能还会有一条语句: default :代码块4
这条语句的作用:如果上述case都不满足,就执行代码块4;
break相当于出口,可以让语句提前结束
以上引用自@初猿°
练习1:

代码实现:
c
#include<stdio.h>
int main(){
int n;
scanf("%d", &n);
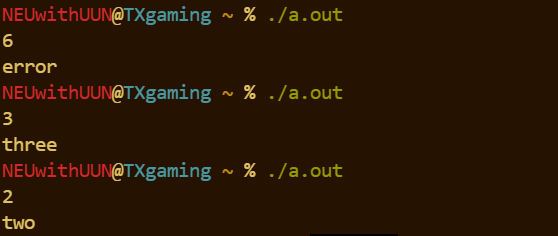
switch(n){
case 1: printf("one\n"); break;
case 2: printf("two\n"); break;
case 3: printf("three\n"); break;
default : printf("error\n"); break;
}
return 0;
}效果:
练习2:

代码实现:
c
#include<stdio.h>
int main(){
int y, m;
scanf("%d%d", &y, &m);
//读入年份和月份
//接下来对m进行分类讨论
if (m == 2){
//这里非常容易错,因为要对闰年的定义有一个清晰的理解;
//如果是整百年份,应当模400才算闰年;
//如果不是,则应当模4才算闰年;
//为避免if表达式嵌套if语句,我采用了&、|、==、!=进行多重判断;
//意思就是:要么y模400,要么y模4且不是100的倍数,输出29;
//其实这里的!= 0可以省略,因为本来就是非0为真;
if(y % 400 == 0 || y % 4 == 0 && y % 100 != 0) printf("29");
else printf("28");
//接下来表达m = 1或3或5或......也是一门技术活,需要将==和||结合起来进行判断
} else if (m == 1 || m == 3 || m == 5 || m == 7 || m == 8 || m == 10 || m == 12){
printf("31");
} else if (m == 4 || m == 6 || m == 9 || m ==11 ){
printf("30");
}
printf("\n");
return 0;
}效果: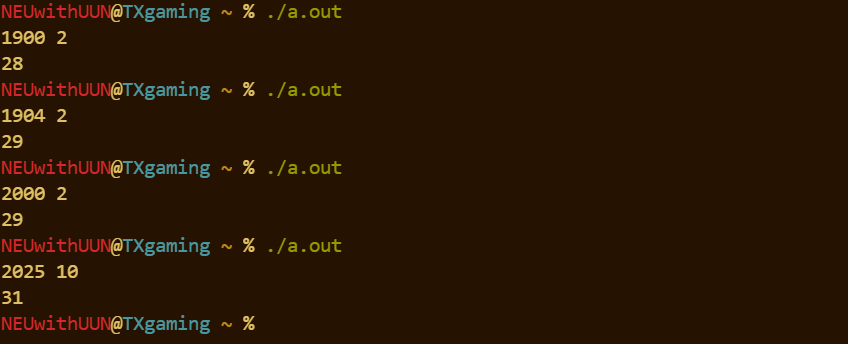
三、CPU中的分支预测(深入)
- 代码中的分支预测实例与优化
首先通过一个实际案例------LeetCode第9题"回文数"------引出分支预测的应用。

在编写代码时,作者在条件判断中添加了expect宏,用于提示编译器和CPU:某个条件(如x<0)大概率为真或假。这样做的目的是优化程序的运行速度,通过硬件预判减少分支跳转带来的性能损失。

- 宏定义likely和unlikely的底层原理
接着,视频深入分析了两个关键的宏定义------likely和unlikely。在Linux内核中,likely x和unlikely x分别用宏定义替换为特定的指令,如:
__builtin_expect(!!(x), 1)

这告诉编译器,条件x很可能为真(或为假),从而引导CPU在流水线中做好相应的预处理准备。视频还详细讲解了双重逻辑非(!!)的作用,即将各种逻辑值归一化为0或1,确保预测信息的准确性。这一机制大大提高了分支预测的准确率,降低了流水线的误预测命令,从而提升整体性能。
- CPU流水线的基本原理与流水线优化

为了理解分支预测的作用,视频阐述了CPU流水线的基础知识。通常,CPU的指令执行可以分为五个步骤:取指(F)、译码(D1、D2)、执行(EX)、写回(WB)。流水线技术让多条指令重叠执行,极大提升吞吐率。以非流水线和流水线操作对比说明:
非流水线:每条指令完整执行需要5个步骤,总共两条指令需10个时间周期。
流水线:指令划分成阶段,每阶段可同时进行,两条指令的执行可以重叠完成,显著减少所需时间
。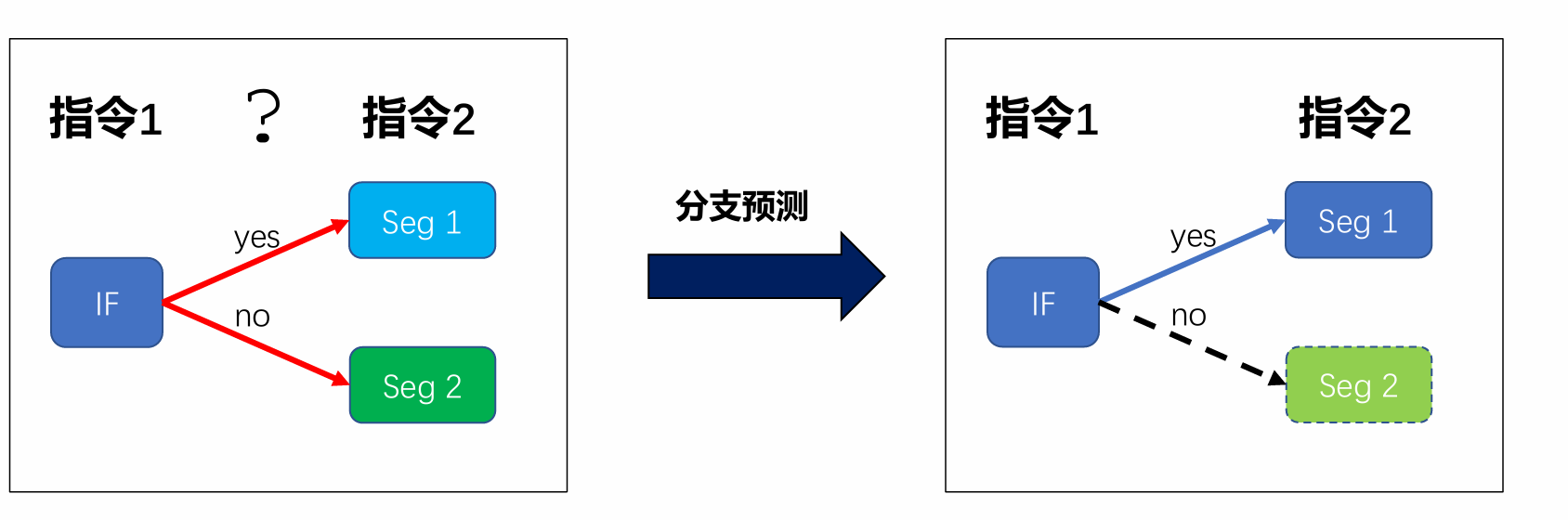
- 分支预测在流水线中的关键作用
视频指出,流水线的最大威胁就是分支结构。如果条件判断在流水线尚未完成时提前加载了错误的指令,就会导致流水线冲突、错误转入,从而降低效率甚至引起性能崩溃。CPU利用分支预测提前猜测条件是否满足,如果预测正确,流水线即可顺利继续;否则,必须进行"错误预测修正",浪费时间。正因为如此,分支预测的准确性直接关系到流水线的利用率。