LTX-2 是由 Lightricks 推出的开源音视频生成模型,它的最大特点是能在同一个模型里同时生成"画面"和"声音",让视频和音频自然同步。它支持文本、图片甚至音频作为输入,能快速生成对应的视频或音频内容。
下载地址:点此下载
模型特点
音视频一体化:不像传统模型只做视频或音频,LTX-2 可以在一个框架里同时生成两者,保证画面和声音的协调。
多模态输入:支持文字转视频、图片转视频、文字转音频、音频转视频等多种组合方式。
开源可训练:提供完整代码和权重,用户可以在本地训练或微调,甚至用 LoRA 技术快速定制风格。
高效推理:有精简版(distilled)和量化版(fp8、fp4),在不同硬件环境下都能运行。
分辨率与帧率提升:配套的空间和时间"upscaler"可以让视频更清晰、帧率更高。
兼容生态:支持 PyTorch、Diffusers 库,也能在 ComfyUI 里直接调用。
应用领域
创意视频制作:输入文字或图片,快速生成短视频,用于广告、社交媒体或艺术创作。
教育与培训:老师可以用文字提示生成教学视频,配合音频讲解。
游戏与虚拟世界:为角色或场景生成动态视频和音效,提升沉浸感。
多媒体内容创作:播客、短片、音乐视频,都可以用 LTX-2 来自动生成或辅助制作。
个性化定制:通过微调模型,快速生成符合特定风格或品牌需求的内容。
使用教程: (建议N卡,显存16G起,支持50系显卡)
整合包包含所需所有节点,下载主程序和模型(ComfyUI文件夹),解压主程序一键包,将ComfyUI文件夹移动到主程序目录下即可。
双击启动ComfyUI,进入页面,点击左侧工作流,加载工作流。
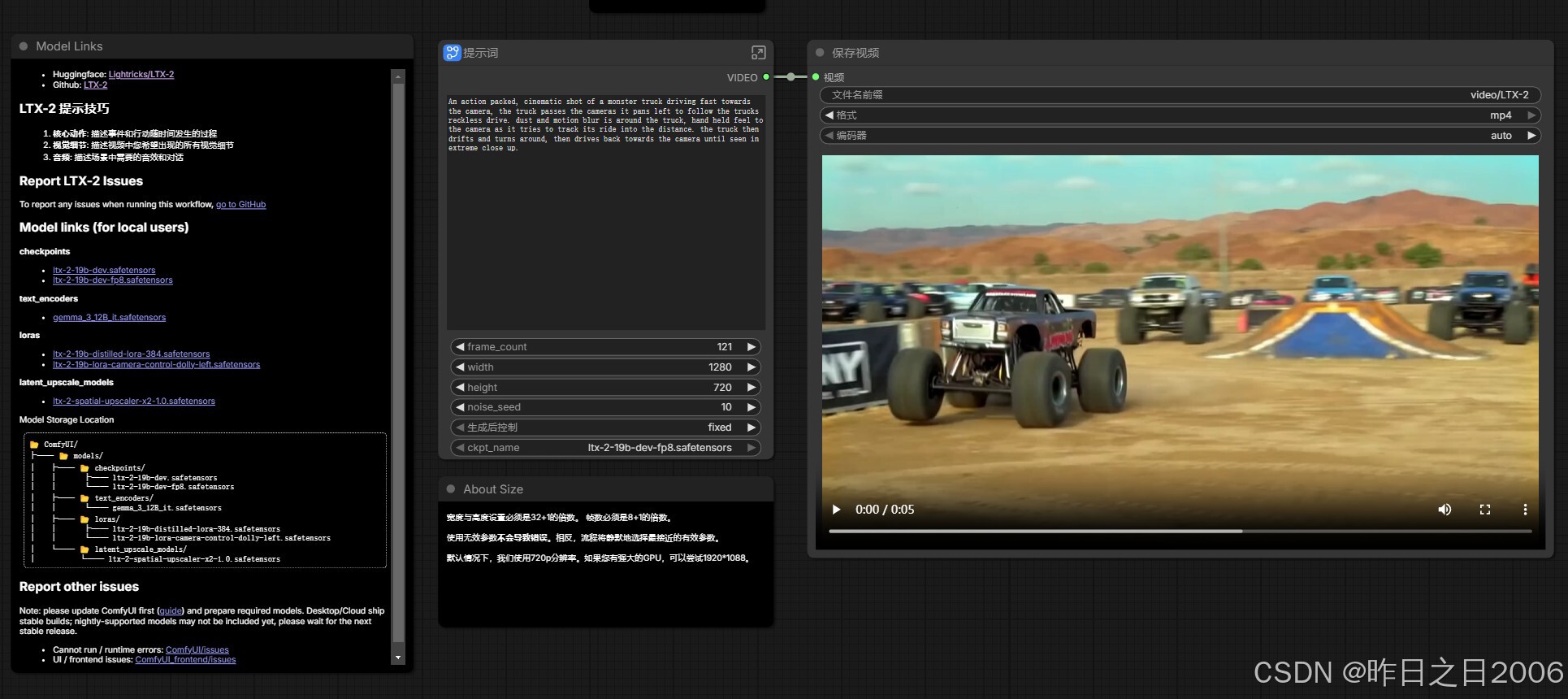
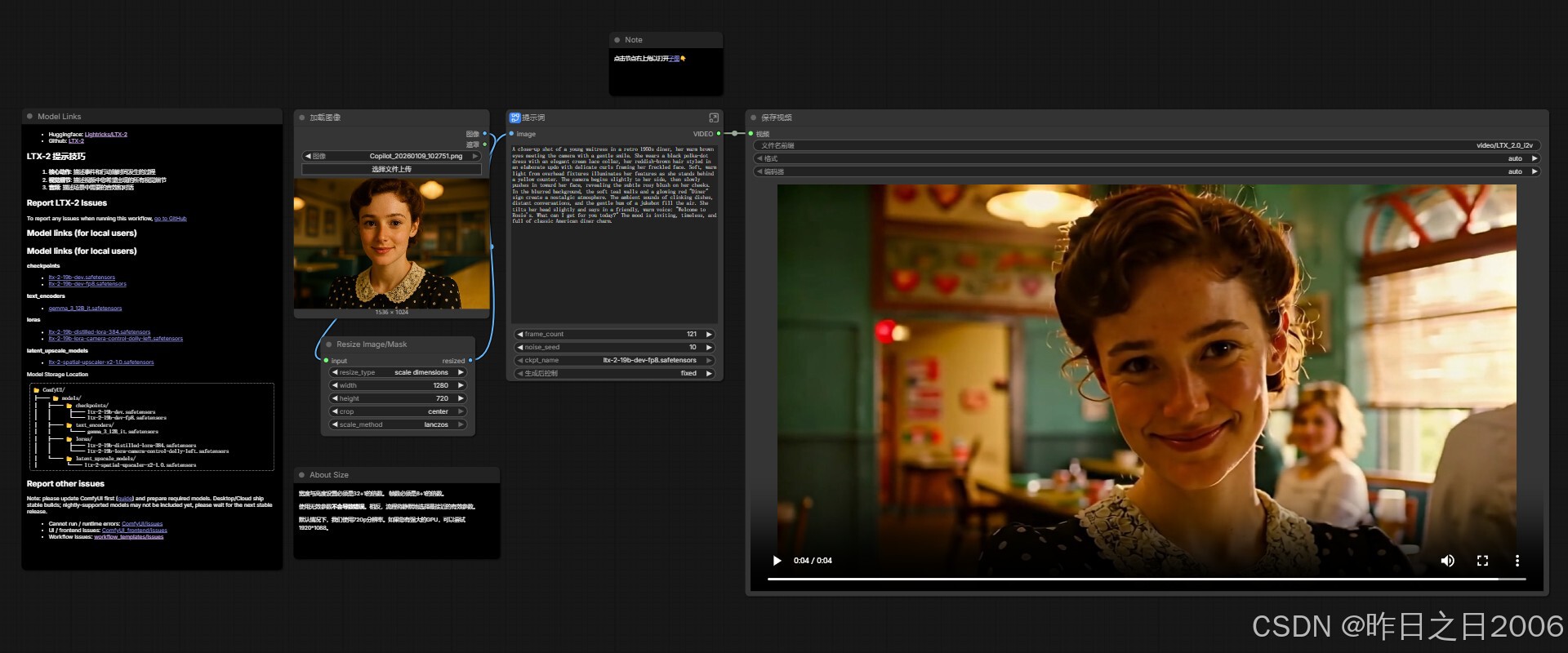
支持文生视频和图生视频,进入对应的工作流,输入提示词/上传图像输入提示词,设置宽高等参数,运行即可。
因19B模型参数量较大,虽然都是使用量化的fp8规格,但对硬件要求还是很高,建议显存16G起体验,看到有12G显存+64G运存也可以跑,但速度略慢。后期有更好的方案,再做更新。
显卡不好的用户,可以优先使用最新的 Wan2GP V36 ,支持8G显存运行LTX-2,蒸馏版速度更快。
官方提示词使用技巧:
在撰写写作提示时,应着重于对动作与场景的详细、按时间顺序的描述。需包含具体的动作、外貌特征、镜头角度以及环境细节------所有这些内容都应整合在一段流畅的段落中。直接从动作开始描述,保持描述的客观性与精确性。可以想象自己是一名电影摄影师,在为拍摄清单撰写详细说明。字数控制在200字以内。为获得最佳效果,请按照以下结构来撰写提示:
-
用一句话概括核心动作;
-
添加关于动作与姿势的具体细节;
-
准确描述人物/物体的外貌特征;
-
描述背景与环境细节;
-
指明镜头角度与拍摄方式;
-
描述光影与色彩效果;
-
注意任何可能发生的变化或突发事件。
默认帧率是24/FPS,设置帧数应该是总帧数+1,比如要生成5秒的视频,总帧数应该是 24*5+1=121