编者按: 我们今天为大家带来的文章,作者的观点是:GPT-5 通过引入"智能路由器"架构,实现了按需调用不同专家模型的动态协作机制,标志着大模型正从"全能单体架构"迈向"专业化协同架构"的新范式。
文章深入剖析了 GPT-5 路由机制的四大决策支柱 ------ 对话类型、任务复杂度、工具需求与用户显性意图,并对比了其相较于 GPT-4、Toolformer 及早期插件系统的突破性进步。作者还详细拆解了该架构的技术实现路径、核心优势(如响应速度提升、资源成本优化、可解释性)以及潜在挑战(如延迟叠加、路由误判、调试困难)。尤为难得的是,文中还提供了基于开源工具构建轻量级 GPT-5 式路由器的可行方案,为开发者指明了实践方向。
作者 | Bhavishya Pandit
编译 | 岳扬
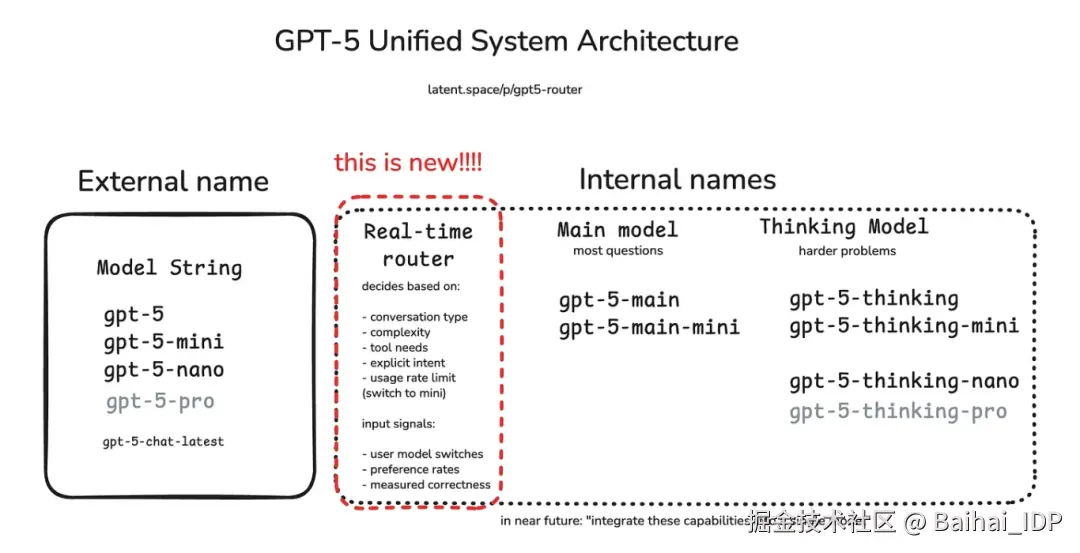
初次与 GPT-5 对话时,我就意识到它不仅是在回答问题,更在精心选择回应方式。其背后的智能"路由器"会将每个问题分配给最合适的处理模块:轻量级核心模型瞬间处理各类简单问题和总结摘要类任务,重量级的 GPT-5 思考模型则专攻复杂推理,而需要工具支持时,"路由器"会启动计算器或外部检索功能。

这种架构变革的意义十分重大。如今的 GPT-5 不再是一个单一系统,更像是由"路由器"协调的专家网络。在本期《Where's The Future in Tech》中,我将解析其运行机制,对比历代模型的差异,并探讨其中预示的人工智能设计新方向。
01 为什么路由机制现在非常重要?
坦白说,早在 GPT-4 面世时,我们就已发现一个比较严重的问题 ------ 无论是创作莎士比亚风格的诗歌还是检查是否有拼写错误,人们都在使用同一个庞然大物。这简直就是用火箭发动机烤面包 ------ 虽然可行,但既浪费资源、成本高昂,又常常大材小用。
GPT-5 的路由机制彻底改变了这种局面。它不再每次都启动火箭引擎,而是通过路由系统快速分析请求并分配到合适的处理路径:
- 简单闲聊? → 分流至快速的轻量级模型
- 复杂推理? → 导向 GPT-5 的核心思考模块
- 数理逻辑? → 转至 symbolic tool(译者注:利用传统编程和数学规则来保证结果精确性的工具)或计算器
- 结构化任务(SQL、API)? → 分配给专用任务执行器
02 路由机制的四大支柱
GPT-5 在决定启动哪个"大脑"时究竟考量哪些因素?通过日常使用并研读 OpenAI 的技术文档后,我发现其核心逻辑可归纳为四大要素:对话类型(conversation type)、任务复杂度(task complexity)、工具需求(tool needs)及显性的用户意图(explicit user intent)。
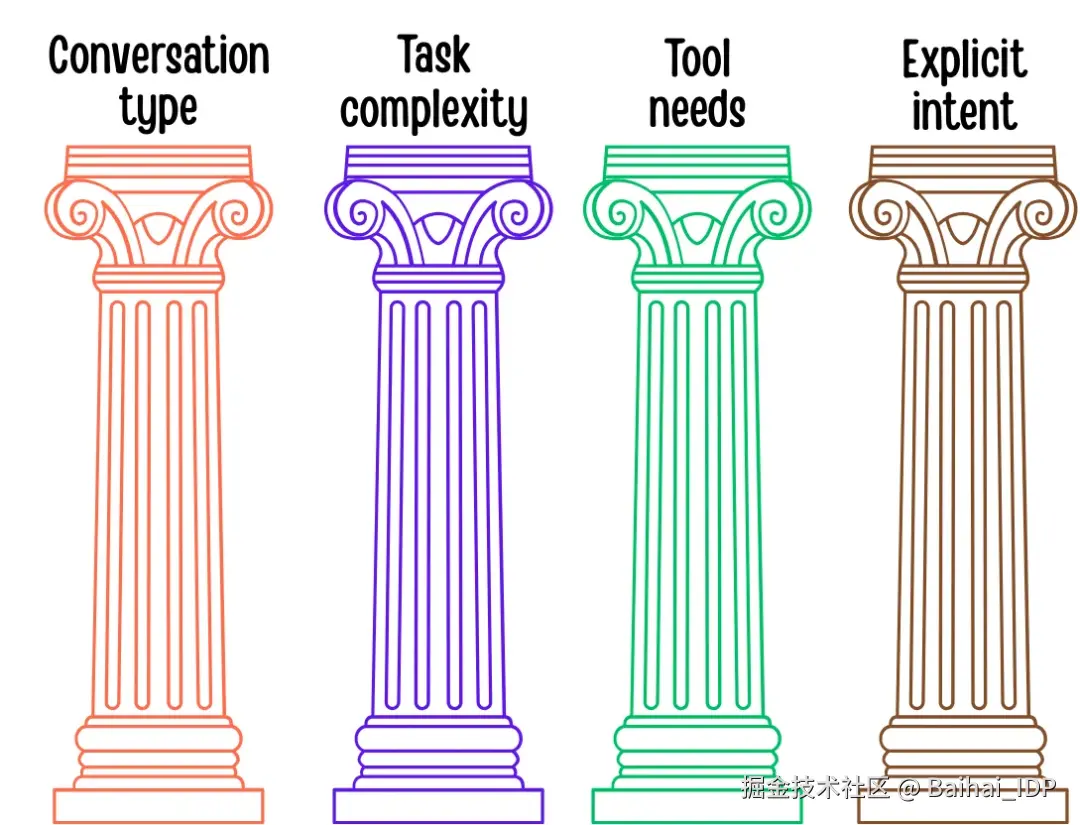
1. 对话类型
当前对话是随意闲聊,还是代码审查、数学证明或故事草稿等结构化任务?GPT-5 已学会为不同对话类型匹配最优的处理模型。例如关于周末计划的闲聊会启用高速响应模式,而分步骤推导定理则会立即激活深度思考模式。
2. 任务复杂度
当指令看起来比较复杂时,GPT-5 会立即调用重量级推理模型。用技术术语来说,路由器能识别出你话语中隐含的、关于任务难度的细微信号,并分配更强大的模型来处理。正如 AIMultiple 所指:GPT-5采用多模型混合架构,根据提示词复杂度与响应速度需求进行路由 ------ 既避免在简单任务上耗费算力,也确保复杂需求得到充分解决。
3. 工具需求
一旦指令中出现"计算"、"查询"或"起草邮件"等关键词,路由器会自动调度配备专用工具的模型。与早期需手动启用插件的系统不同,现在的 GPT-5 会隐形处理这一过程:若查询明显需要执行代码或访问数据库,系统将自动移交专属模型。早期测试显示,凭借更精准的路由与专业化分工,GPT-5 的工具调用错误率较 GPT-4 降低近 50%。
4. 显性的用户意图
一般情况下,路由器会直接响应用户指令。若输入"请深入思考",系统会立即启动深度推理模式。笔者测试过"快速总结"与"深度剖析"等具有细微差异的不同措辞,能清晰观察到 GPT-5 在实时切换处理模式 ------ 这仿佛解锁了新的"软指令"层,用户措辞对路由决策的影响程度,已不亚于系统内置的启发式规则。
03 超越 Toolformer 与内置插件的一次飞跃
有些人可能还记得 Toolformer1:那是 2023 年的一篇论文,这项研究让语言模型在训练中自学通过 API 调用外部工具。这个想法很聪明,但却是静态的 ------ 模型仅能从数据集中的信号 tokens 学习固定的规则,比如"此处使用计算器"。部署完成后,它就无法超越自己的记忆范围进行适配。
GPT-5 的路由器则截然不同,它能在运行时动态做出决策。它不会机械地复述预设指令,而是像一位实时在线的助手 ------ 听到你的问题后,能当场判断:"我现在应该调用计算器了。"
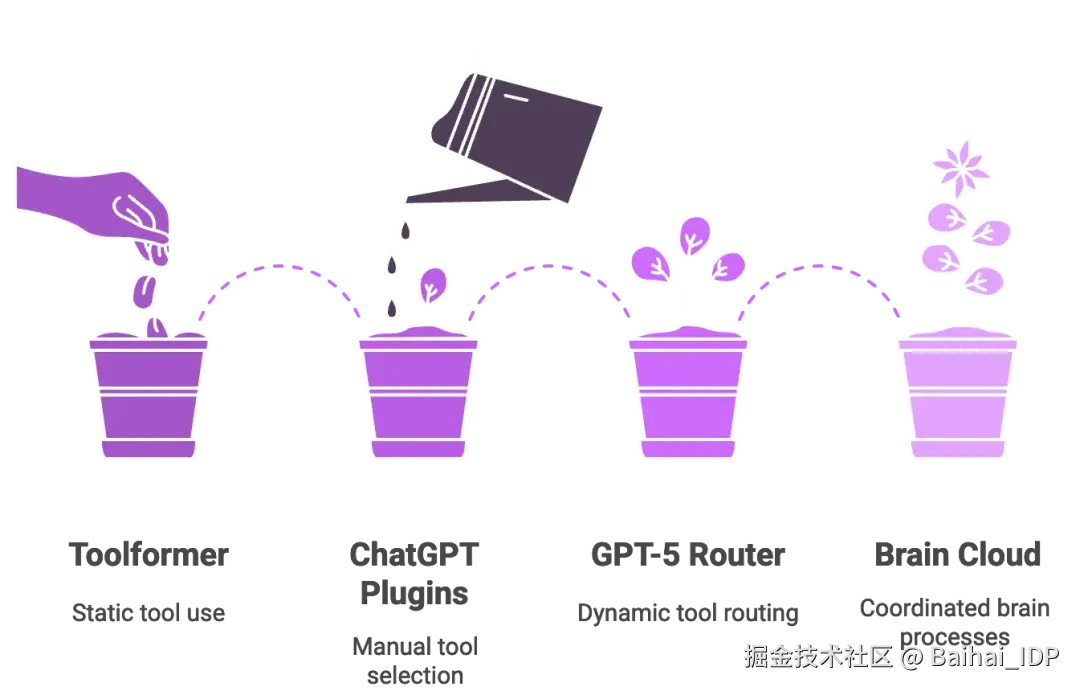
ChatGPT 曾经的插件同样存在类似的局限:用户必须手动启用插件,并明确指示"用 Wolfram Alpha 进行数学计算"。GPT-5 则用一个内置的策略层取代了这种模式。只要用户查询需要调用工具,路由器就会直接将请求路由到已连接相应工具的合适模型。即便是新 API 中推出的自定义工具,其后端也依赖这套路由系统。
简言之,GPT-5 融合了 Toolformer 的自主工具调用能力与 ChatGPT 的插件生态,但在中间加入了一位实时的"交通指挥员"。如果说 GPT-4 像一台独立的超级计算机,那么 GPT-5 则更像是由路由器协调的一组云端脑处理单元(cloud of brain processes)。如果你曾经调试过微服务,立刻就能明白这个比喻为何如此贴切。
04 构建属于你自己的 GPT-5 式路由器
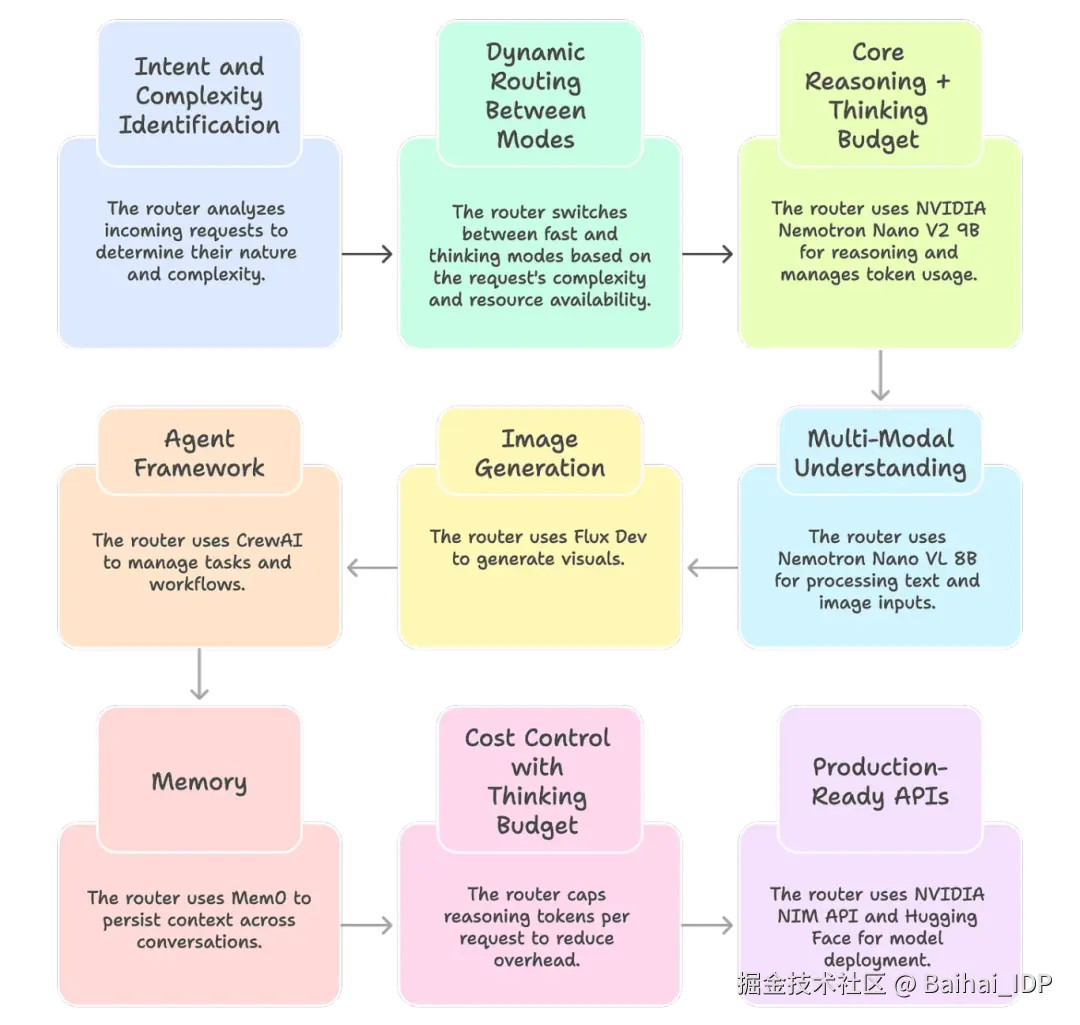
现在,我知道你可能会想:"这个概念很酷,但我到底该怎么自己动手做出类似的东西呢?"幸运的是,你并不需要像 OpenAI 那样拥有无限算力才能尝试。借助当前的开源生态,你完全可以在自己的机器上搭建一个轻量级的 GPT-5 式路由器。以下是一种可行的实现思路:
1. 用户意图与请求复杂度识别
路由器必须首先理解请求的类型:是快速的事实信息查询、需要大量推理过程的数学证明题、还是图像生成需求,还是需要浏览网页呢?一个轻量级的分类器(甚至小型 LLM)即可完成这项工作。
2. 不同模式间的动态路由
路由器会智能地在不同模式间进行切换,而非一致地处理所有查询:
- 快速模式:将查询发送给低延迟模型以获取快速响应
- 思考模式:启用推理 token 进行更长时间的思考,以便处理需要深度逻辑分析、权衡多种因素、或通过多个步骤才能解决的复杂问题
- 备用模式:当 GPU 显存紧张时,就将请求路由到更小的备用模型,从而确保系统永不宕机
3. 底层技术架构
以下是一套可落地的开源方案:
- 核心推理引擎 + 资源限制机制(thinking budget) → NVIDIA2 Nemotron Nano V2 9B(一款混合了 Mamba 与 Transformer 架构的模型,兼容 RTX 显卡,支持 token 使用量调控)
- 多模态理解 → Nemotron Nano VL 8B(支持文本 + 图像输入)
- 图像生成 → Flux Dev(视觉内容生成)
- 智能体框架 → CrewAI3(任务管理与工作流管理)
- 记忆模块 → Mem04(跨对话上下文持久化)
仅凭该技术栈,我们就能构建出与 GPT-5 底层运作极为相似的路由器系统。
4. 通过资源限制机制(thinking budget)控制成本
并非每个指令都需要"耗费万枚 token 的深度思考"。通过限制单次请求的推理 token 上限,可大幅降低开销。采用这种方法的团队报告称,该方法最高可节省 60% 成本,因为路由器只在真正需要的地方投入算力。
5. 面向生产的 API
NVIDIA 已通过 NIM API 和 Hugging Face 提供这些模型。这意味着你无需从头训练,现在即可接入模型开始实验。
05 GPT-5 路由器的核心优势
- 效率与速度
- 大多数查询默认交给快速模型处理,大幅节省算力
- 轻量级任务不再占用深度推理引擎资源
- OpenAI 曾暗示,当系统负载过高时,"mini"模型可以接手低优先级的用户查询,实现弹性扩展
- 响应速度
- 对于基础问题,GPT-5 能"即时"作答,在基准测试中通常比 GPT-4 Turbo 快 2--3 倍
- 自动路由机制意味着用户无需手动切换模型 ------ 需要速度时自动给出快速回答,需要深度时则提供深入分析
- 保留"快速模式/思考模式"的手动切换开关,满足用户精准控制的需求
- 可解释性与模块化设计
- 每个子模型都专注于特定领域,支持独立迭代升级
- 错误定位更精准:可区分"路由选择失误"与"模型推理错误"
- 这就像 AI 流水线中的微服务架构 ------ 模块化、职责清晰、更易维护
- 专业化 = 更高质量
- 子模型针对特定场景进行了专项优化:例如,"thinking" 模型用于多步骤推理,"main" 模型用于简洁准确的知识输出
- 兼顾两者优势:兼具 GPT-4 级别的知识深度与 GPT-3 级别的响应速度
- 支持对话中无缝切换模式,比如从头脑风暴无缝切换到代码处理,无需用户显式指令
06 隐忧与挑战:局限性分析
- 调试困难
- 错误溯源困难:问题究竟源于路由器选错模型,还是所选模型自身的失误?
- 调试过程更接近分布式系统,而非单一单体架构
- 需借助专用追踪工具(借鉴 Amazon Bedrock 框架)记录每个环节:路由决策、工具调用、中间结果、最终的输出整合
- 任何环节出错都意味着"需要检查的动态部件更多了"
- 延迟叠加
- 每一次额外的跳转(例如主模型→思考模型→数学工具→返回计算结果→最终答案)都会增加延迟
- 简单问题通常会绕过中间层,但复杂查询可能会明显变慢
- Amazon 的多智能体报告就曾警告过这一点:串行推理链越长,开销越大
- 缓解方案:并行调用(parallelizing calls) + 结果缓存(caching results),但多工具工作流的响应速度仍可能低于单次 GPT-4 调用
- 资源成本
- 多个小型模型有时反而比单个大模型消耗更多算力,必须精细调整路由器的阈值,确保边界任务被分配给更快的模型
- 第三方研究发现,ChatGPT-5 在某些查询中使用的 token 数量是 GPT-4 的两倍,原因在于编排过程带来的额外开销
- OpenAI 也承认 GPT-5 虽追求效率,但可能"更耗算力"
- 本质是更智能的资源分配与更高的系统复杂度之间的权衡
- 用户体验偏差
- 一些用户已经注意到语气差异:思考模式(正式、严谨) vs 主模式(自然、流畅)
- 通过"人格过滤器"对输出进行风格对齐,确保用户感知到的始终是一个连贯、统一、有辨识度的对话伙伴
- 若未经调优,对话可能感觉像多个风格略有差异的 AI 在轮流发言
- 正如一句调侃所说:"GPT-5 的大脑很聪明,但可能存在身份认知危机"
- 路由失误
- 路由器有时会误判:该用"深度模式"的问题却选择了"快速模式",反之亦然
- 通过"模型切换"事件进行检测(例如用户点击"重新生成"答案时)
- 最终补救措施仍是用户点击"重新生成",然后期待路由器作出不同选择
- 每次切换都需重新加载静态提示词,既增加延迟,又增加 token 消耗
- 实际应用中,回答过程中的模式切换会破坏"流畅对话"的体验
07 这一技术将如何影响 AI 的未来发展?
GPT-5 的"路由器 + 多模型"架构讲述了一个更大的故事:AI 正在告别"一刀切"的单一模型时代。研究人员长期以来一直在探讨模块化与 Agentic AI,而 GPT-5 正是这一转变正在发生的最清晰例证之一。正如某份分析所言,GPT-5 的"多智能体架构(路由器 + 模型)"暗示了我们未来可能会如何设计模块化的 AI 系统,来突破单一模型的局限。用通俗的话说,未来大语言模型系统将由专家网络构成,而不是依赖一个"全能的"通用模型。
未来的 AI 很可能会变得更像多个智能体协同工作,而非由单一模型包揽一切。我们或许很快会看到更加细粒度的专家模型(一些实验室已在测试"100-expert LLMs"),由一个中央控制器协调调度。GPT-5 已经证明,只要硬件持续进化,这种因为协调过程而产生的开销是值得的。因此,如果 GPT-6 或 Gemini Next 配备了一个超强路由器,管理数十个子模型,或者插件演变为由元模型(metamodel)按需调用的自主"智能体",你也不必感到惊讶。
前方的挑战
当然,模块化并非没有代价。GPT-5 也凸显了我们必须解决的几大挑战:
- 未来需要统一的模型,最终将各种专业化角色融合进一个"大脑"中。
- 通过更智能的缓存技术,来避免路由过程中因重复加载静态提示词而产生的额外开销。
- 需要更强大的溯源工具,来帮助开发者调试由多个智能体协同完成的复杂对话。
- 采用更高级的路由器训练方法(例如强化学习),让路由器真正学会最优的决策策略。
尽管如此,GPT-5 的设计清楚地表明了一点:模块化已成定局。这种架构正反映了人类组织知识的方式------由专业化专家团队协作完成复杂任务。如今,AI 终于开始迎头赶上。
08 Final thoughts
在使用 GPT-5 数月之后,我既感到兴奋,也心怀敬畏。实时路由器已将这个模型从一个孤独的"天才",转变为一个由多个专家组成的协作集体。 路由器和专家模型的分工架构在带来效率和能力提升的同时,也带来了一个挑战:如何让这个分布式系统中的所有部件保持协调一致、同步工作。就像乐队成员必须听从指挥、节奏统一,否则再厉害的乐手也奏不出和谐乐章。
最让我兴奋的是,GPT-5 证明了人工智能不必是一个单一、庞大的整体。我们可以实现"按需专业化" ------ 系统不仅能学会如何学习,还能针对每个查询动态调整自己的策略。作为一名开发者,我甚至学会了如何"与路由器对话"------ 通过类似 "Auto mode" 或 "Fast" 这样的提示词来引导它。展望未来,如果 GPT-6 的表现更像一个"心智社会"(译者注:society of minds,是一个在人工智能和认知科学领域非常著名且富有诗意的概念,由 Marvin Minsky 提出。它认为智能并非源于一个单一的、统一的处理器,而是由大量简单的、各司其职的"智能体"通过交互、协作与竞争涌现出来的。),我也不会感到意外。但就目前而言,GPT-5 的路由机制已经是一个令人着迷的里程碑,我很庆幸自己有机会深入探索它。
END
本期互动内容 🍻
❓你觉得 AI 的"人格一致性"重要吗?如果一次对话中因为调用不同模块导致语气不同,你会觉得割裂吗?
文中链接
本文经原作者授权,由 Baihai IDP 编译。如需转载译文,请联系获取授权。
原文链接: