文章目录
- [1 概述](#1 概述)
-
- [1.1 术语说明](#1.1 术语说明)
- [1.2 Why 集成学习](#1.2 Why 集成学习)
-
- [1.2.1 偏差-方差均衡](#1.2.1 偏差-方差均衡)
- [1.2.1 多模型优势](#1.2.1 多模型优势)
- [2 算法分类](#2 算法分类)
-
- [2.1 Bagging](#2.1 Bagging)
- [2.2 Boosting](#2.2 Boosting)
- [2.3 Stacking](#2.3 Stacking)
- [3 随机森林](#3 随机森林)
- [4 Boosting](#4 Boosting)
-
- [4.1 AdaBoost](#4.1 AdaBoost)
- [4.2 GBDT](#4.2 GBDT)
- [4.3 XGBoost](#4.3 XGBoost)
- [4.4 LightBGM](#4.4 LightBGM)
1 概述
集成学习(Ensemble Learning)并不是一种具体的算法,而是一种思想:将多个单模型组合成一个综合模型,从而克服单一模型可能存在的局限性,提高准确性和稳定性,获得比单一模型更好的泛化能力。
1.1 术语说明
基学习器 (base learner)、基模型(base model)、基估计器 (base estimator),指的是集成学习中的单个模型。
进一步将基学习器分为弱学习器 (weak learner)和强学习器(strong learner) ,弱学习器是表现略优于随机猜测的学习器。对于二元分类问题,弱分类器定义为准确率约为 50% 的分类器;强学习器则是实现了出色的预测性能,在二元分类问题中准确率大于等于 80%。
注意:很多资料将基学习器和弱学习器混为一谈,因为集成学习(尤其是串行方法)可以有效地将弱学习器提升为强学习器。
1.2 Why 集成学习
1.2.1 偏差-方差均衡
为了减少测试误差而增加训练误差的做法被称为偏差-方差权衡,也是许多正则化技术背后的驱动原则。
- 偏差(Bias) 衡量的是预测值与真实值之间的平均差异。偏差越大,模型在训练集上的预测准确率就越低。高偏差是指训练过程中的误差较大,优化意味着尝试降低偏差。
- 方差(Variance) 衡量的是给定模型在不同实现之间的预测差异。方差越大,模型对未知数据的预测准确率越低。高方差是指测试和验证过程中的误差较大,泛化是指试图降低方差。
偏差和方差分别反向代表了模型在训练集和测试集上的准确率,我们希望同时降低模型偏差和方差,但同时降低两者并不总是可行的,因此需要进行正则化。正则化会降低模型方差,但代价是增加偏差。
模型总误差由偏差、方差和数据集随机性导致的不可约误差构成:
E r r o r = B i a s 2 + V a r i a n c e + I r r e d u c i b l e E r r o r Error=Bias^2+Variance+Irreducible\;Error Error=Bias2+Variance+IrreducibleError
1.2.1 多模型优势
任何一种模型都包含众多变量,例如训练数据、超参数等,这些变量会影响最终模型的总误差。因此,即使是单一训练算法也可能产生不同的模型,每个模型都有各自的偏差、方差和不可约误差。通过组合多个不同的模型,集成算法可以降低总体误差,保留每个模型自身的复杂性和优势,例如对特定数据子集的低偏差。
一般来说,组合模型之间的多样性越大,最终的集成模型就越准确。由多种欠正则化模型,即与训练数据过拟合的模型,组成的集成模型性能优于单一正则化模型(集成森林中的决策树不需要剪枝)。集成学习还可以帮助解决高维数据引发的问题,有效替代降维方法。
2 算法分类
集成学习主要分为并行和串行两种方法:
- 并行方法会将每个基学习器与其他基学习器分开单独训练
- 串行方法训练一个新的基础学习器,使其能够最小化前一步训练的模型所犯的错误
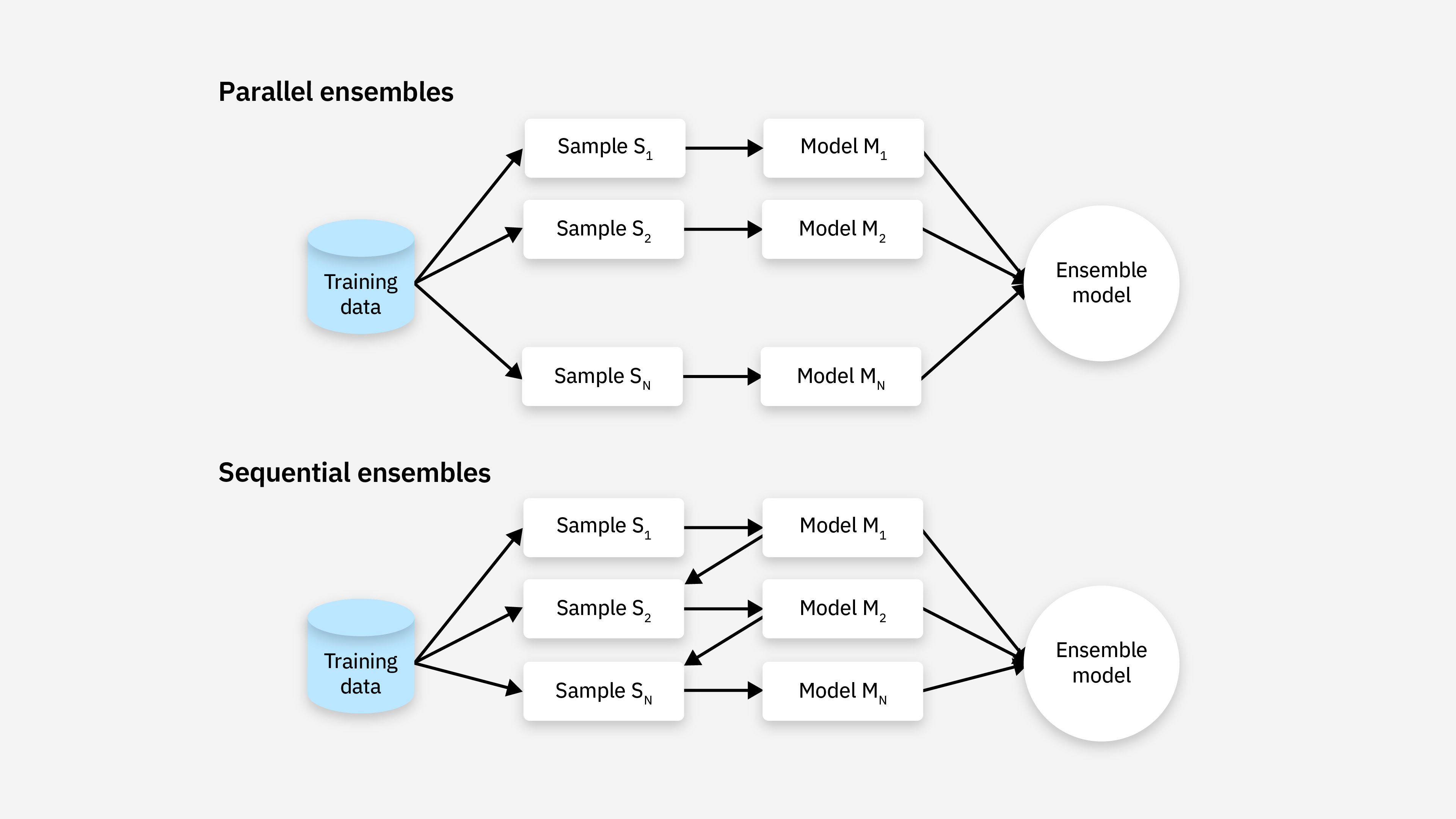
并行方法进一步分为同质学习器和异质学习器,而串行方法通常使用同质学习器。
- 同质(Homogeneous):使用相同的基础学习算法来生成基学习器
- 异质(Heterogeneous):使用不同的基础学习算法来生成基学习器
目前最流行的三种集成学习技术是 Bagging、Boosting 和 Stacking。
2.1 Bagging
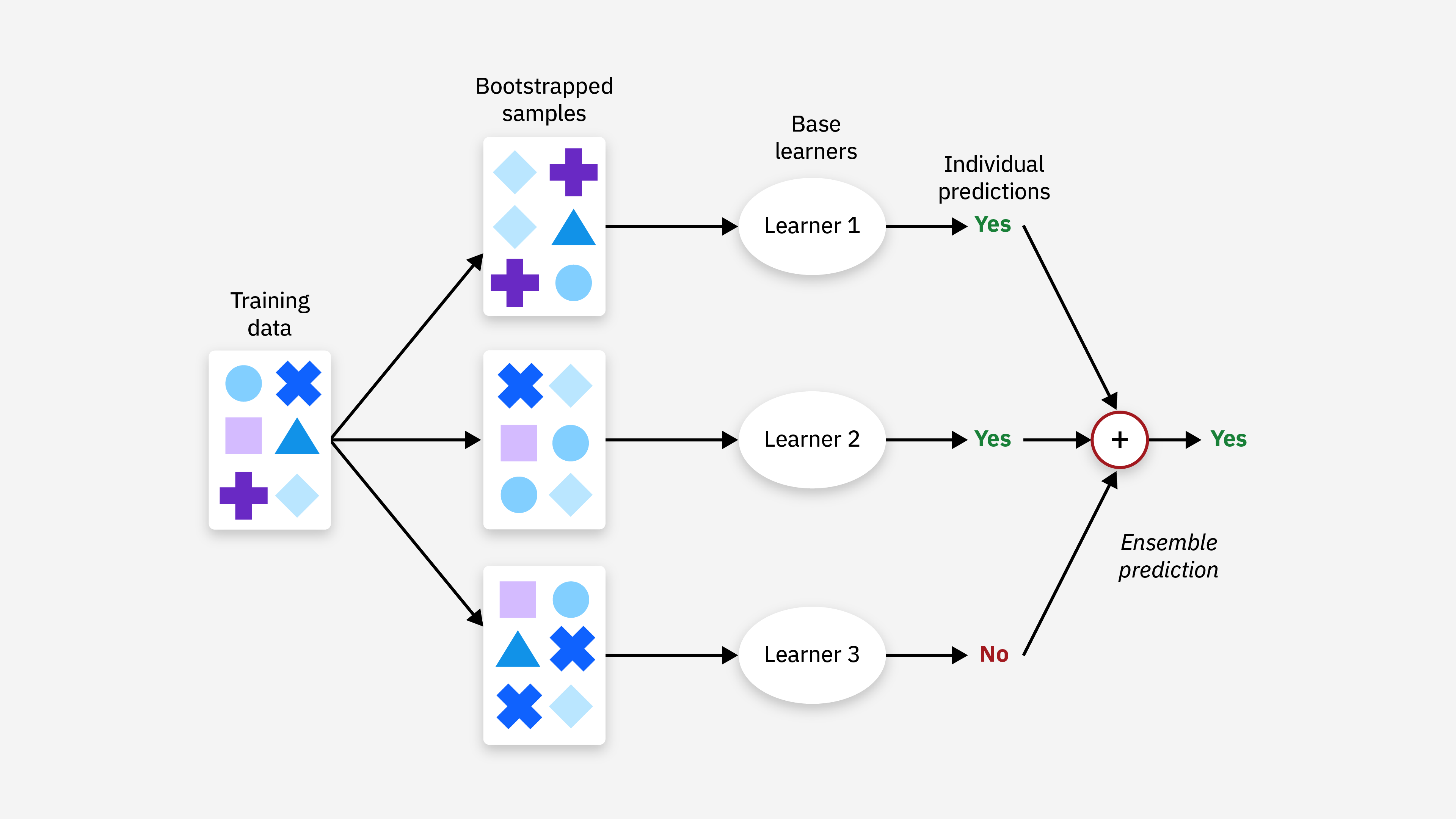
Bagging(Bootstrap Aggregating,自助聚合)通过自助采样(bootstrap)构建多个基学习器,然后将这些基学习器的预测结果进行组合(分类问题采用投票法,回归问题采用平均法)
特点:Bagging 旨在减少方差,尤其在基学习器存在较大方差时效果显著。
典型算法:
- 随机森林(Random Forest):通过构建大量决策树并进行投票来提高分类性能。
2.2 Boosting
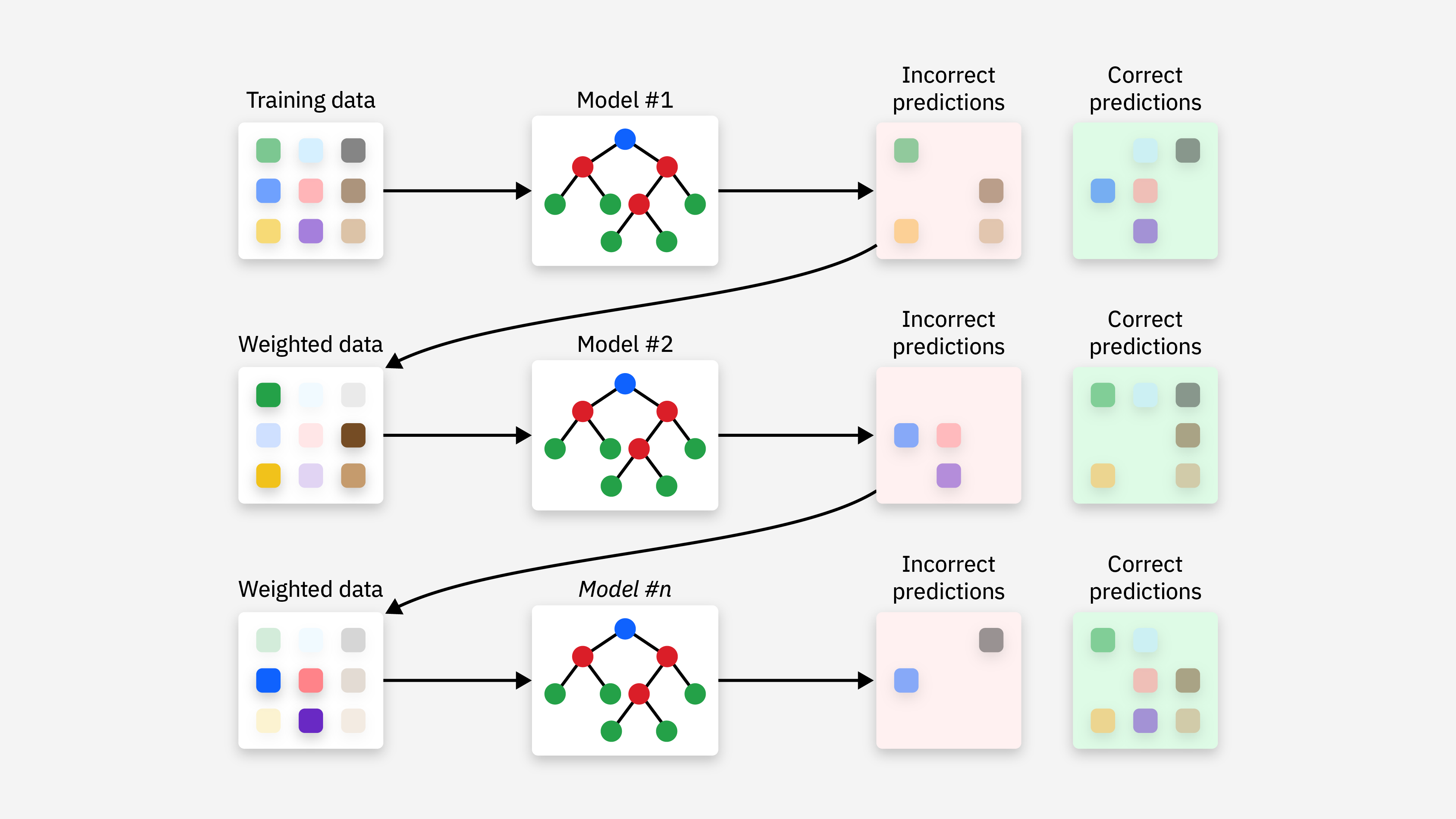
Boosting(提升)是一种迭代方法,模型是按顺序训练的,每个新模型都试图纠正先前模型的错误,最后通过对所有模型的预测进行加权平均。
特点:Boosting 旨在减少偏差,通过逐步改进模型提高预测的准确性,常常应用于简单的基学习器(如决策树桩)。
典型算法:
- AdaBoost (Adaptive Boosting):为每个训练样本分配一个权重,并在每次迭代中调整这些权重。
- Gradient Boosting Machine (GBM):GBM 是一种更通用的 Boosting 算法,它使用梯度下降来优化损失函数。
- XGBoost (Extreme Gradient Boosting):GBM 的一种优化版本,在效率、精度上都有很大的提升。
- LightGBM (Light Gradient Boosting Machine):另一种 GBM 的优化版本,它使用基于直方图的算法来加速训练过程,并减少内存使用,特别适用于处理大规模数据集。
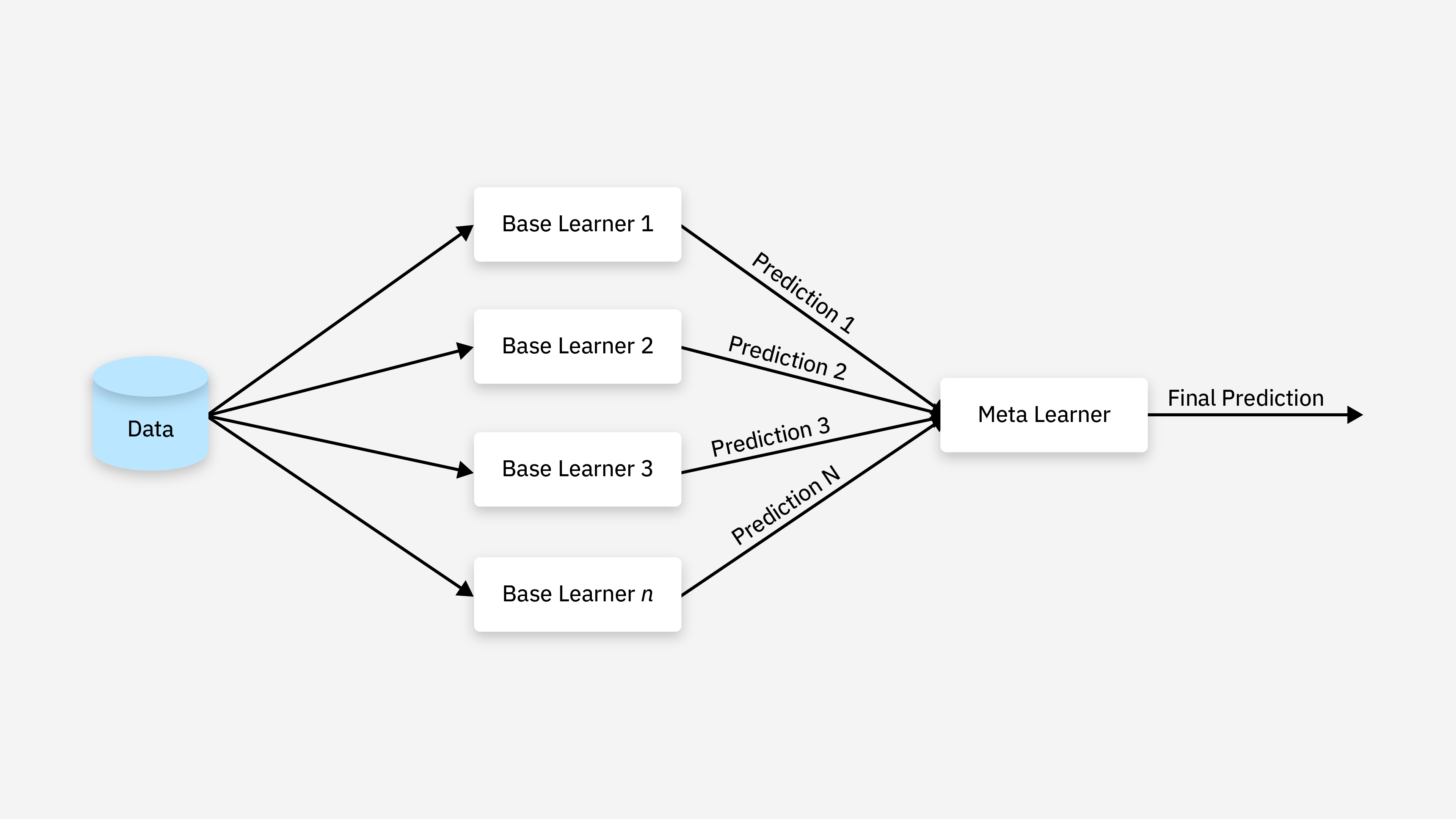
2.3 Stacking
Stacking(堆叠)是将多个基模型的预测结果作为新的特征输入到元学习器(Meta Learner)中进行训练,元学习器的目标是学习如何最好地组合基学习器的预测结果。
特点:利用不同模型的优势,获得比单个模型更好的性能。
3 随机森林
随机森林是 Bagging 的一个变体,在以决策树为基学习器构建 Bagging 集成的基础上,进一步在决策树训练过程中引入了随机特征选择,更加增强了模型的多样性。
- Bootstrap采样: 从原始数据集中使用 Bootstrap 有放回抽样,形成多个子集,每个子集用于训练一颗决策树
- 构建决策树:每棵树进行节点分裂时,不必考虑所有特征,而是随机选取一部分特征进行分裂
- 集成学习:分类任务采用投票法,回归任务采用平均法
python
from sklearn.ensemble import RandomForestClassifier
model = RandomForestClassifier()n_estimators: 决策树数量,(default = 10)Criterion: entropy、 或者 gini, (default = gini)max_depth:指定树的最大深度, (default = None 表示树会尽可能的生长)max_features="auto",决策树构建时使用的最大特征数量- "auto":
max _ features=sqrt(n _ features) - "sqrt":
max _ features=sqrt (n_ features)(same as "auto") - "log2":
max _features=log2(n_features) - None:
max _ features=n_features
- "auto":
bootstrap:是否采用有放回抽样,如果为 False 将会使用全部训练样本,(default = True)
随机森林通过集成多个决策树提高了泛化能力且对噪声数据不敏感,适合解决复杂问题。
4 Boosting
4.1 AdaBoost
Adaptive Boosting(自适应提升)是基于 Boosting 思想实现集成学习算法,自适应体现在根据前一轮模型的错误调整样本的权重。主要有两个特点:
- 提高上一轮被弱学习器分类错误的样本权重
- 对弱学习器进行线性组合,提高分类效果好的弱学习器权重
AdaBoost 训练过程:
- 初始化样本权重 :给每个样本分配一个相等的初始权重,对于 N N N 个样本,初始权重为:
w i ( 1 ) = 1 N w_i^{(1)}=\frac{1}{N} wi(1)=N1 - 训练弱学习器 :根据当前样本权重训练一个弱学习器,目标是最小化加权误差,第 t t t 轮得到的弱学习器加权误差为:
ε t = ∑ i = 1 N w i ( t ) ⋅ I ( y i ≠ h t ( x i ) ) \varepsilon_{t} = \sum_{i=1}^{N} w_{i}^{(t)} \cdot I(y_{i} \neq h_{t}(x_{i})) εt=i=1∑Nwi(t)⋅I(yi=ht(xi))
- ε t \varepsilon_{t} εt: 第 t t t 轮弱分类器的加权错误率。
- N N N: 训练样本的总数。
- w i ( t ) w_{i}^{(t)} wi(t): 第 t t t 轮中第 i i i 个样本的权重。权重在每轮迭代中都会根据前一轮的表现进行调整(分错的样本权重增加,分对的样本权重减少)。
- I ( ⋅ ) I(\cdot) I(⋅): 指示函数 (Indicator Function)。
- 如果括号内的条件 ( y i ≠ h t ( x i ) y_{i} \neq h_{t}(x_{i}) yi=ht(xi)) 为真(即弱分类器 h t h_{t} ht 分错了样本 x i x_{i} xi),则函数值为 1 1 1。
- 如果条件为假(即弱分类器 h t h_{t} ht 分对了样本 x i x_{i} xi),则函数值为 0 0 0。
- y i y_{i} yi: 第 i i i 个样本的真实标签。
- h t ( x i ) h_{t}(x_{i}) ht(xi): 第 t t t 轮弱分类器对第 i i i 个样本的预测结果。
- 更新学习器权重 :计算第 t t t 轮弱学习器的权重,该弱学习器误差越小,权重越大,第 t t t 轮的弱学习器 α t \alpha_t αt 的权重为:
α t = 1 2 l n ( 1 − ε t ε t ) \alpha_{t} = \frac{1}{2} ln \left( \frac{1 - \varepsilon_{t}}{\varepsilon_{t}} \right) αt=21ln(εt1−εt) - 更新样本权重 :根据当前学习器的表现,更新样本权重,误分类样本的权重会增加,正确分类样本的权重会降低,权重更新公式为:
w i ( t + 1 ) = w i ( t ) ⋅ e − α t y i h t ( x i ) w_{i}^{(t + 1)} = w_{i}^{(t)} \cdot e^{-\alpha_{t} y_{i} h_{t}(x_{i})} wi(t+1)=wi(t)⋅e−αtyiht(xi) - 归一化权重:对所有样本的权重进行归一化,使所有样本权重和为 1。
- 构建强学习器:对所有弱学习器进行加权组合,预测时通过加权投票确定最终类别。
python
from sklearn.ensemble import AdaBoostClassifier, AdaBoostRegressorAdaBoost 简单易实现,但是对异常值敏感,容易过拟合。
4.2 GBDT
GBDT(Gradient Boosting Decision Trees)梯度提升树使用梯度提升的思想,通过迭代训练一系列决策树(通常是 CART 树),每次训练时通过减少前一个模型的误差(拟合残差)来提升模型的性能。
GBDT 使用梯度下降的方式来最小化损失函数。回归任务通常是均方误差(MSE),分类任务通常是对数损失(Log Loss)。
- 初始化 :初始化一个弱学习器,通常是一个常数(训练集的平均标签值)
y ^ 0 = 1 n ∑ i = 1 n y i \hat{y}0=\frac{1}{n}\sum{i=1}^ny_i y^0=n1i=1∑nyi - 计算负梯度(残差):计算损失函数在当前模型预测值处的负梯度,作为残差的近似值
- 训练决策树:构建一颗新的决策树,新决策树并不是拟合真实标签,而是尽可能地拟合残差
- 更新模型 :将新树的预测结果乘以学习率 η \eta η 后加入到现有模型中
F m + 1 ( x ) = F m ( x ) + η h m ( x ) F_{m + 1}(x) = F_{m}(x) + \eta h_{m}(x) Fm+1(x)=Fm(x)+ηhm(x) - 得到强学习器:最终将所有树的预测值求和得到最终结果
python
from sklearn.ensemble import GradientBoostingClassifier, GradientBoostingRegressor4.3 XGBoost
XGBoost 算法是 GBDT 算法的一种改进和优化,引入了由陈天奇在其论文《XGBoost: A Scalable Tree Boosting System》中提出。
XGBoost 的算法流程与 GBDT 类似,但做了一些改进:
- 损失函数:引入正则化项,可以防止过拟合
- 梯度提升:使用二阶泰勒展开近似损失函数,可以更精确地计算梯度和残差
- 分裂点查找:实现了精确贪心算法和近似贪心算法,可以高效地查找最佳分裂点
- 缺失值处理:可以自动学习缺失值的分裂方向
- 运行速度:使用了加权分位数 sketch 和稀疏感知算法,通过缓存优化和模型并行来提高算法速度
python
import xgboost as xgb
# 将数据处理成数据集格式DMatrix格式
# DMatrix数据结构 支持缺失值,优化存储和计算,,并且可以加速训练
dm_train = xgb.DMatrix(X_train, y_train)
dm_test = xgb.DMatrix(X_test)
# 设置模型参数
params = {
'booster': 'gbtree', # 用于训练的基学习器类型
'objective': 'multi:softmax', # 指定模型的损失函数
'num_class': 3, # 类别的数量
'gamma': 0.1, # 控制每次分裂的最小损失函数减少量
'max_depth': 6, # 决策树最大深度
'lambda': 2, # L2正则化权重
'subsample': 0.8, # 控制每棵树训练时随机选取的样本比例
'colsample_bytree': 0.8, # 用于控制每棵树或每个节点的特征选择比例
'eta': 0.001, # 学习率
'seed': 10, # 设置随机数生成器的种子
'nthread': 16, # 指定了训练时并行使用的线程数
}
# num_boost_round 代表 boosting 过程的迭代次数,也就是弱学习器的数量
model = xgb.train(params, dm_train, num_boost_round=200)
# 模型预测
y_pred = model.predict(dm_test)params的参数:
booster:指定用于训练的基学习器类型,默认值为'gbtree',表示使用传统的决策树作为基学习器;其他的选项包括'gblinear'和'dart',前者表示使用线性回归或逻辑回归,后者也是基于决策树的模型,但具有丢弃树的机制,降低过拟合风险。通常'gbtree'适用于大多数问题,尤其涉及到非线性关系;'dart'适用于复杂数据集,尤其是在出现过拟合时。如果数据集较小或线性关系较强,可以尝试使用'gblinear'。objective:指定模型的损失函数(优化目标),常见的选项包括:'reg:squarederror':回归任务中的均方误差(MSE),用于回归任务。'reg:logistic':回归任务中的逻辑回归,通常用于二分类任务。'binary:logistic':二分类任务中的逻辑回归,输出概率值。'binary:logitraw':二分类任务中的逻辑回归,输出未经过 Sigmoid 处理的原始值。'multi:softmax':多分类任务,输出为每个类别的最大概率。'multi:softprob':多分类任务,输出为每个类别的概率分布。
eta/learning_rate:XGBoost 中的学习率,默认值为 0.3,推荐将初始值设置为 0.01 到 0.1。alpha和lambda:前者控制 L1 正则化项(Lasso)的强度,默认为0;后者控制 L2 正则化项(Ridge)的强度,默认为1。scale_pos_weight:用于处理类别不平衡问题,尤其是二分类问题。在类别严重不平衡的情况下,通过调整这个参数来加大少数类的权重,使得模型更关注少数类样本,默认值为 1。gamma:用来控制每次分裂的最小损失函数减少量,该参数控制树的生长,越大的gamma会使得树更小,减小过拟合的风险,默认值为 0,意味着模型不会受到分裂的限制,树会尽可能深,直到节点中没有足够的样本。num_class:用于多分类任务的参数,表示类别的数量。对于二分类任务,无需设置该参数。colsample_bytree/colsample_bylevel/colsample_bynode:控制在每棵树、每一层、每个节点上采样特征的比例。这些参数用于控制模型的复杂度。较小的值会增加模型的随机性,从而防止过拟合;较大的值则意味着每棵树使用更多的特征,可能导致过拟合。colsample_bytree:每棵树使用的特征比例(默认为 1.0)。colsample_bylevel:每一层使用的特征比例(默认为 1.0)。colsample_bynode:每个节点使用的特征比例(默认为 1.0)。
除了 param字典提供的模型参数外,train函数也有一些超参数:
num_boost_round:树的训练轮数,设置较小的learning_rate并增加训练轮数可以提高模型的稳定性。early_stopping_rounds:用于实现早期停止机制。当指定轮次的训练中,验证集上的损失函数不再减少时,训练会自动停止,避免过拟合。feval:设置用户自定义的评估函数,这种方式允许用户灵活地使用任何适合特定任务的评估指标,需要注意的是评估函数有两个参数,一个表示模型预测值(NumPy 的ndarray对象),一个是训练数据(XGBoost 的DMatrix对象);函数返回一个二元组(name, value),其中name是评估指标的名称,value是指标的值。obj:设置用户自定义的目标函数,目标函数用于计算每一步的梯度和二阶导数,从而指导模型的优化过程,有兴趣的读者可以自行研究。evals:用于指定一个或多个验证集,其值是包含一个或多个(data, label)元组的列表,每个元组代表一个评估数据集,数据集需要是DMatrix对象。在训练过程中,XGBoost 会在每一轮迭代后评估验证集上的性能,通常用于监控训练过程中的过拟合或调整超参数。eval_results:存储在训练过程中计算的所有评估结果,通常传入一个字典。verbose_eval:控制训练过程中评估结果的输出频率,可以设置为一个整数,表示多少轮迭代输出一次评估结果,也可以设置为True或False,表示每轮都输出或不输出任何评估结果。xgb_model:用于加载之前训练好的模型,以便从中断点继续训练。你可以指定一个xgb_model文件或者传入一个Booster对象。callbacks:在训练过程中添加自定义的回调函数,回调函数可以在每一轮迭代时提供额外的控制,如自动停止训练、调整学习。
可以通过 plot_importance 查看每个特征的重要性。
python
fig, ax = plt.subplots(figsize=(10, 15))
# ax 可以指定坐标系,此外还可以设置 max_num_features 限制特征数量
xgb.plot_importance(model, ax=ax)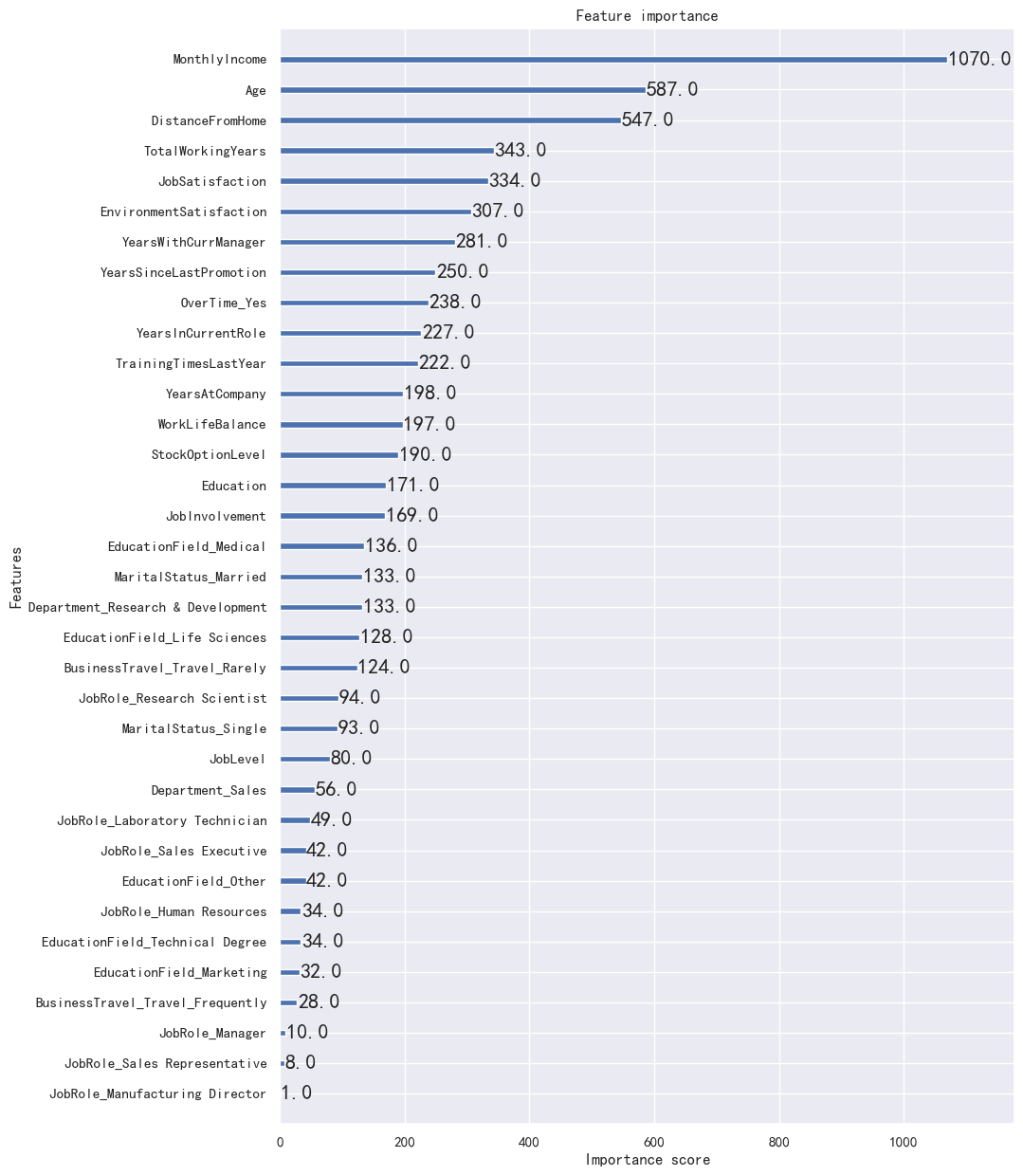
4.4 LightBGM
LightGBM(Light Gradient Boosting Machine)是由微软开发的梯度提升算法,相较于 GBDT,有更快的训练速度,更低的内存消耗,更高的准确率,支持大规模数据和并行学习。
核心技术:
- 基于直方图的算法 (Histogram-based Algorithm)
- 基本思想: 将连续的特征值离散化成若干个 bins (桶),然后使用这些 bins 来构建直方图。在寻找最佳分裂点时,只需遍历直方图中的 bins,而不需要遍历所有的数据点。
- 优点:
- 减少了寻找最佳分裂点的计算量,提高了训练速度。
- 降低了内存消耗,因为只需要存储直方图,而不需要存储原始的特征值。
- 缺点:
- 离散化可能会损失一些信息,但通常情况下,这种损失可以忽略不计。
- Leaf-wise 的生长策略 (Leaf-wise Tree Growth)
- 基本思想: 每次从当前所有的叶子节点中,选择分裂收益最大的节点进行分裂,而不是像 level-wise 那样,每次分裂所有的叶子节点。
- 优点:
- 可以生成更复杂的树模型,因为 leaf-wise 每次只分裂一个节点,可以更精细地拟合数据。
- 通常情况下,leaf-wise 的准确率比 level-wise 更高。
- 缺点:
- 容易过拟合,特别是当数据集较小的时候。可以通过设置
max_depth参数来限制树的深度,防止过拟合。
- 容易过拟合,特别是当数据集较小的时候。可以通过设置
- 直接支持类别特征 (Direct Support for Categorical Features)
- 基本思想: LightGBM 可以直接处理类别特征,不需要进行 one-hot 编码。
- 优点:
- 节省了内存空间,因为不需要存储大量的 one-hot 编码。
- 提高了训练速度,因为不需要对类别特征进行额外的处理。
- Gradient-based One-Side Sampling (GOSS)
- 基本思想: 在每次迭代中,LightGBM 不是使用所有的样本来计算梯度,而是只使用一部分样本。GOSS 算法选择梯度绝对值较大的样本(这些样本的梯度比较重要),并随机选择梯度绝对值较小的样本。
- 优点:
- 减少了计算梯度的样本数量,提高了训练速度。
python
import lightgbm as lgb
# 将数据转化为 LightGBM 的数据格式
train_data = lgb.Dataset(X_train, y_train)
test_data = lgb.Dataset(X_test, y_test, reference=train_data)
# 设置模型参数
params = {
'objective': 'multiclass', # 多分类问题
'num_class': 3, # 类别数量
'metric': 'multi_logloss', # 多分类对数损失函数
'boosting_type': 'gbdt', # 使用梯度提升树算法
'num_leaves': 31, # 叶子节点数
'learning_rate': 0.05, # 学习率
'feature_fraction': 0.75, # 每次训练时随机选择特征的比例
'early_stopping_rounds': 10 # 连续多少论没有性能提升就停止迭代
}
# 模型训练
model = lgb.train(params=params, train_set=train_data, num_boost_round=200, valid_sets=[test_data])
# 模型预测,结果为各标签的概率值,类似 sklearn 的 predict_proba
y_proba = model.predict(X_test, num_iteration=model.best_iteration)
# 将预测结果处理成标签
y_pred= np.argmax(y_proba, axis=1)objective:设置优化目标函数(损失函数),可选值有:'regression':回归任务。'binary':二分类任务。'multiclass':多分类任务。'multiclassova':多分类任务,使用一对多的策略。'rank_xendcg'、'lambdarank':排名任务。
metric:评估模型性能的指标,可选值有:'l2'、'mean_squared_error':回归任务中的均方误差。'binary_error':二分类错误率。'multi_logloss':多分类对数损失。'auc':二分类任务中的 AUC。'precision'、'recall'、'f1':精度、召回率、F1分数。
boosting_type:设置提升类型,可选值有:'gbdt':传统的梯度提升树。'dart':具有随机丢弃树机制来防止过拟合的决策树。'goss':通过单边梯度抽样来加速训练。'rf':随机森林。
num_leaves/max_depth:决策树的叶子节点数 / 决策树的最大深度,控制树的复杂度。lambda_l1/lambda_l2:L1 和 L2 正则化参数,用于控制模型的复杂度,防止过拟合。max_bin: 用于分割连续特征(数据分箱)的最大箱子数。feature_fraction:每次训练时随机选择特征的比例。early_stopping_rounds: 设置评估指标在连续多少轮迭代中没有改进时,训练会提前停止。
learning_rate:学习率。n_estimators:弱学习器的数量。