博客文章:基于大语言模型的GitHub故障复现测试用例生成方法解析
论文信息
- 论文原标题:基于大语言模型的故障复现测试用例生成方法
- 主要作者及研究机构:汪莹、字千成、彭鑫、娄一翎(复旦大学 计算机科学技术学院,上海 200438)
- 通信作者:娄一翎
- 发表期刊/网络首发:软件学报,网络首发时间:2025-09-30,网络首发地址:https://link.cnki.net/urlid/11.2560.TP.20250929.1122.004
- 引文格式(GB/T 7714):汪莹, 字千成, 彭鑫, 娄一翎. 基于大语言模型的故障复现测试用例生成方法J/OL. 软件学报, 2025(网络首发). https://link.cnki.net/urlid/11.2560.TP.20250929.1122.004
- 关键词:故障复现;测试用例生成;大语言模型;检索增强生成
一段话总结
本文针对GitHub问题报告中故障复现测试用例严重不足 的问题(在SWE-bench Lite数据集300个样本中占比89.33% ),提出一种基于大语言模型(LLM)与检索增强生成(RAG) 的故障复现测试用例生成方法;该方法通过检索与问题报告相关的3类关键信息(报错根函数、import语句、测试用例样本) ,结合提示工程构建精确prompt,引导LLM(如GPT-4)生成测试用例;对比实验显示,该方法成功生成测试用例的问题报告比例从现有Libro方法的6.57%提升至22.33% ,消融实验进一步证明测试用例样本对生成效果贡献最大,最终实现减轻开发者负担、提升问题解决效率的目标。
思维导图
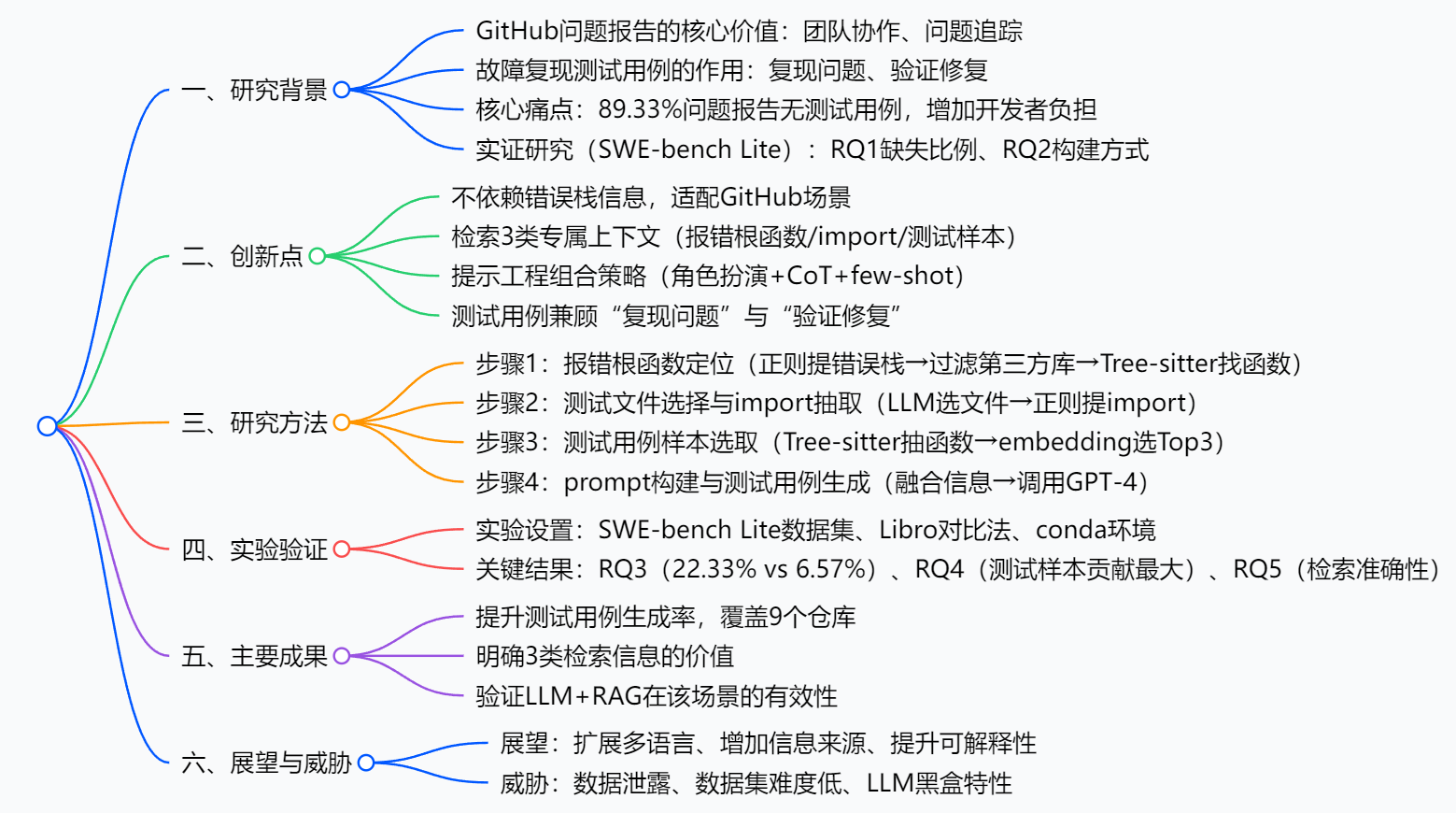
研究背景
1. GitHub问题报告:开源协作的"沟通桥梁"
GitHub是全球最大的开源项目管理平台,比如Django(Web框架)、scikit-learn(机器学习库)等热门项目都依赖它协作。其中"问题报告(Issue)"是核心功能------开发者遇到"URLField输入非法地址报错""函数计算结果异常"等问题时,会提交Issue描述情况,其他开发者则通过Issue理解问题、提交修复代码(补丁)。
但这里有个关键环节被忽略了:故障复现测试用例。它就像"故障说明书",必须满足两个条件:①在修复补丁提交前运行,会触发Issue中的错误(证明能复现问题);②在补丁提交后运行,能顺利通过(证明问题已修复)。没有这个"说明书",开发者拿到Issue后,得先花大量时间摸索"怎么复现问题",甚至可能因为复现步骤不对,导致修复方向走偏。
2. 核心痛点:89.33%的Issue"缺说明书"
论文团队在SWE-bench Lite数据集(含12个Python仓库的300个Issue)中做了实证研究,结果让人惊讶:300个Issue里,268个在提交时完全没有附带故障复现测试用例,占比高达89.33%。
为什么会这样?主要有两个原因:①GitHub没强制要求提交测试用例,很多用户只描述问题,不想额外花时间写测试;②写测试用例本身很麻烦------得理解项目API调用方式、测试文件结构,比如要测"URLField报错",得知道导入哪个模块(from django.forms import URLField)、怎么构造非法输入,对非专业测试人员不友好。
举个真实案例:Django仓库有个Issue说"URLField输入'////]@N.AN'时,应该抛ValidationError,却抛了ValueError"。如果没有测试用例,开发者得自己查Django测试文件位置、导入相关类、写断言逻辑,这一套下来可能要1-2小时,而有测试用例的话,直接运行就能复现,效率差10倍都不止。
3. 现有方法:"水土不服"的旧方案
之前的故障复现测试用例生成方法,要么依赖"错误栈信息"(比如传统的符号执行、模型检查方法),但GitHub Issue里很少有人会贴错误栈;要么像Libro方法,只用固定的"问题-测试用例"样本(one-shot),不结合项目专属上下文------比如Libro给所有项目都用同样的测试模板,没法适配Django和scikit-learn的不同API风格,导致在SWE-bench Lite上的成功率只有6.57%,基本没法用。
创新点
这篇论文的核心亮点,就是解决了"现有方法适配不了GitHub场景"的问题,具体有4个创新:
-
不依赖错误栈,彻底适配GitHub
现有方法把错误栈当"必需品",但论文发现SWE-bench Lite里只有19.3%的Issue含错误栈。于是方法仅将错误栈作为"参考",即使没有,也能通过检索import语句、测试样本补充上下文,覆盖100%的Issue场景。
-
3类项目专属上下文,让LLM"懂项目"
首次提出检索"报错根函数+import语句+测试用例样本":①报错根函数帮LLM定位故障位置;②import语句教LLM正确调用项目API(比如Django的URLField该怎么导入);③测试样本让LLM学习项目测试风格(比如断言怎么写、测试类怎么定义),避免生成"语法正确但不符合项目规范"的测试用例。
-
提示工程"组合拳",提升生成质量
不是简单给LLM发指令,而是用了3种策略:①角色扮演 :告诉LLM"你是软件测试专家,擅长写故障复现测试用例",激发模型专业能力;②思维链(CoT) :让LLM先分析问题原因、再想测试步骤,比如先想"URLField报错是因为非法输入处理错了",再设计"构造非法输入→调用clean方法→断言抛ValidationError";③few-shot学习:给LLM3个相似测试样本,让它更懂"该怎么写"。
-
测试用例"能复现也能验证",实用性拉满
很多方法只关注"复现问题",但论文要求测试用例必须满足"补丁前失败、补丁后通过"------比如测试用例运行旧代码时抛ValueError(复现问题),运行修复后的代码时抛ValidationError(验证修复正确),直接能用于开发流程,不用开发者再修改。
研究方法和思路
论文的方法可以拆成4个清晰步骤,就像"给LLM搭一套完整的'项目说明书',再让它写测试用例":
步骤1:定位报错根函数------找到故障"发源地"
如果Issue里有错误栈(比如"Traceback (most recent call last): ..."),就按以下流程处理:
- 用正则表达式提取错误栈中的所有调用记录,比如"django/core/validators.py line 130 in call""urllib/parse.py line 440 in urlsplit";
- 过滤掉第三方库的函数(比如urllib的urlsplit),只保留项目自己的函数------因为故障肯定出在项目代码里,第三方库问题不归项目管;
- 用Tree-sitter工具(代码解析工具),根据"文件路径+函数名"找到具体代码(比如django/core/validators.py的__call__函数),作为报错根函数信息。
如果Issue没有错误栈,这一步就跳过,靠后面的步骤补上下文。
步骤2:选测试文件+抽import语句------教LLM"用API"
LLM经常犯的错是"API调用错了",比如要测Django的URLField,却不知道导入from django.forms import URLField。这一步就是解决这个问题:
- 选相关测试文件:先按规则提取项目所有测试文件(比如Django的测试文件在tests文件夹下,scikit-learn的在/tests/目录下);然后把文件路径截取成短格式(比如保留最后3段路径),用GPT-3.5 Turbo根据Issue标题选最相关的文件------比如Issue是"URLField报错",就选forms_tests/field_tests/test_urlfield.py;
- 抽import语句 :用正则表达式从选中的测试文件里提取所有import语句(比如
from django.core.exceptions import ValidationError),这些语句直接告诉LLM"该导入哪些模块",避免语法错误。
步骤3:选测试用例样本------给LLM"找模板"
LLM写测试用例时,很容易"天马行空",不符合项目测试风格。这一步就是给它找"参考模板":
- 用Tree-sitter从步骤2选好的测试文件里,提取所有测试函数(比如test_urlfield_clean_invalid);
- 计算每个测试函数和Issue标题的"语义相似度"(embedding相似度)------比如"test_urlfield_clean_invalid"和"URLField报错"相似度很高;
- 选相似度最高的3个函数作为样本,比如Django的test_urlfield_clean_invalid函数,里面有"构造非法URL→调用clean→断言抛ValidationError"的逻辑,LLM看了就知道该怎么写。
步骤4:构建prompt+生成测试用例------让LLM"动笔"
把前面3步的信息整合到一个结构化prompt里,比如:
# Issue标题:URLField throws ValueError instead of ValidationError on clean
## Issue描述:forms.URLField().clean('////]@N.AN') 抛ValueError,应该抛ValidationError
## 报错根函数:django/core/validators.py的__call__函数(代码略)
## Import列表:from django.core.exceptions import ValidationError; from django.forms import URLField; ...
## 示例测试用例:def test_urlfield_clean_invalid(self): ...(略)
你是软件测试专家,请先分析问题原因,再写一个测试用例:要求在旧代码上失败,新代码上通过,用类定义,调用正确API。然后调用GPT-4生成5个测试用例,只要有1个满足"补丁前失败、补丁后通过",就算成功。
主要成果和贡献
1. 核心成果:用数据证明方法有效
论文围绕3个核心问题(RQ)做了实验,结果用表格一目了然:
| 研究问题(RQ) | 实验内容 | 关键结论 |
|---|---|---|
| RQ3:方法是否优于现有方法? | 对比本文方法与Libro在SWE-bench Lite(300个样本)的成功率 | 本文方法22.33%(67/300)vs Libro 6.57%(20/300);覆盖9个仓库vs Libro仅3个 |
| RQ4:3类检索信息作用如何? | 消融实验:依次去除报错根函数、import、测试样本(100个样本) | 测试样本贡献最大(去除后成功率从27%→14%);import次之(27%→21%);根函数最小(27%→24%) |
| RQ5:检索内容是否准确? | 统计检索到的测试文件/样本与Issue的相关性 | 36.67%(110/300)Issue检索到相关测试文件;35%(105/300)检索到相关样本 |
2. 实际价值:给开发者和领域带来的改变
- 减轻开发者负担:之前89.33%的Issue要手动写测试用例,现在22.33%的Issue能自动生成,比如Django仓库的"URLField报错"Issue,生成的测试用例直接能用,节省1-2小时/个;
- 提升开源协作效率:测试用例是"通用语言",有了自动生成的测试用例,新贡献者不用反复问"怎么复现问题",直接运行测试就能理解,加速问题解决;
- 突破领域技术瓶颈:首次把RAG和LLM结合用于GitHub故障复现测试用例生成,解决了"现有方法依赖错误栈"的痛点,为后续多语言、多场景扩展打下基础。
3. 数据集与代码
- 数据集:SWE-bench Lite(本文实验核心数据集),含12个Python仓库的300个Issue,下载地址:https://huggingface.co/datasets/swe-bench/swe-bench-lite
- 代码:论文未提及开源自有代码,可参考文中描述复现方法(依赖GPT-4 API、Tree-sitter工具)。
详细总结
一、研究背景与动机
-
GitHub问题报告的核心价值与痛点
GitHub作为主流开源项目管理平台,其问题报告(issue)是团队协作的关键,但未强制要求提交故障复现测试用例------该测试用例需满足"补丁前运行失败、补丁后运行通过",是复现问题、验证修复的核心工具,缺失会增加开发者额外负担。
-
实证研究(SWE-bench Lite数据集)
数据集为SWE-bench的子集,含12个Python仓库的300个问题报告,聚焦独立功能性错误修复,实验围绕2个核心问题(RQ1-RQ2)展开:
- RQ1:测试用例缺失比例 :300个问题报告中268个无测试用例,占比89.33% ,证明问题普遍性。
- RQ2:新测试用例构建方式:440个新增测试用例中,59.32%为全新编写,40.68%基于现有测试函数修改,提示"复用现有测试上下文(如import语句、样本)可提升生成效率"。
-
现有方法局限性
方法类型 核心问题 传统方法(覆盖率、符号执行) 依赖错误栈信息,GitHub问题报告无该信息,无法直接应用 Libro方法(LLM+one-shot) 仅提供固定"问题-测试用例"样本,缺项目专属上下文,复杂问题效果差(成功率6.57%)
二、提出方法:LLM+RAG故障复现测试用例生成
方法核心是"检索多元上下文+LLM精准生成",分4个关键步骤:
-
报错根函数定位
- 若问题报告含错误栈,用正则提取调用链,过滤第三方库函数,保留"最后一个项目内函数"作为报错根函数;
- 用Tree-sitter工具定位函数代码,提供故障位置上下文(SWE-bench Lite中仅19.3%样本含错误栈,故不依赖该信息)。
-
测试文件选择与import语句抽取
- 测试文件选择:人工制定各仓库测试文件规则(如路径含"/tests/"),截取文件路径后,以问题报告标题为依据,通过GPT-3.5 Turbo多轮筛选出最相关文件;
- import语句抽取:用正则从选中文件中提取import语句,避免LLM调用API时出现语法错误。
-
基于相似度的测试用例样本选取
- 用Tree-sitter从相关测试文件中提取所有测试函数;
- 计算函数与问题报告标题的embedding相似度,选取Top3作为样本,帮助LLM学习项目测试风格。
-
prompt构建与测试用例生成
- 填充prompt模板(含issue标题/描述、报错根函数、import列表、样本用例);
- 采用提示工程策略:角色扮演(软件测试专家)、思维链(4步推理)、few-shot学习,调用GPT-4生成5个测试用例。
三、实验设置
-
环境与模型
- 环境:为每个问题报告搭建conda虚拟环境(匹配仓库version);
- 模型:测试文件选择用GPT-3.5 Turbo(降本),测试用例生成用GPT-4(提效)。
-
数据集与对比方法
- 数据集:SWE-bench Lite(300个样本,12个Python仓库,如django、sympy);
- 对比方法:Libro(复现其one-shot prompt逻辑,无上下文信息)。
四、实验结果(RQ3-RQ5)
-
RQ3:方法有效性对比(表3)
评估指标 Libro方法 本文方法 成功生成测试用例的样本数 20 67 成功比例 6.57% 22.33% 覆盖仓库数量 3个 9个 -
RQ4:消融实验(表4,100个随机样本)
实验方案 成功样本数 成功比例 较本文方法下降幅度 本文方法(全检索信息) 27 27% - 去除"报错根函数" 24 24% 3% 去除"import语句" 21 21% 6% 去除"测试用例样本" 14 14% 13% - 结论:3类信息均起积极作用,测试用例样本贡献最大。
-
RQ5:检索内容准确性
- 36.67%(110/300)的问题报告检索到相关测试文件;
- 35%(105/300)的问题报告检索到相关测试用例样本,证明检索策略有效性。
五、有效性威胁
- 数据泄露风险:SWE-bench Lite为热门Python仓库样本,可能影响泛化性;
- 数据集难度偏低:样本仅涉及单文件补丁,与真实多文件场景有差距;
- LLM黑盒特性:生成结果可解释性低,复现性受模型随机性影响。
六、总结与展望
- 总结:方法通过RAG补充上下文,显著提升测试用例生成效果,解决GitHub问题报告痛点;
- 展望:①挖掘更多上下文(代码注释、历史提交);②扩展至Java/C++等多语言;③提升测试用例可解释性(增加生成逻辑说明)。
4. 关键问题
问题1:本文通过实证研究揭示了GitHub问题报告在故障复现测试用例方面的哪些核心现状?该现状对开发者有何影响?
答案 :
核心现状包括两点:①缺失比例极高 :在SWE-bench Lite数据集300个GitHub问题报告中,89.33%(268个)提交时未附带故障复现测试用例;②新测试用例构建方式 :440个新增测试用例中,59.32%需开发者全新编写,仅40.68%可通过修改现有测试函数生成。
对开发者的影响:需在提交代码补丁外,额外编写/修改测试用例,增加工作负担;同时,缺失测试用例会导致开发者难以快速复现问题、验证修复效果,降低问题解决效率。
问题2:本文提出的故障复现测试用例生成方法,与现有Libro方法相比,核心创新点是什么?
答案 :
核心创新点体现在3个方面:①不依赖错误栈信息 :Libro依赖Defects4J数据集的错误栈信息,而本文仅将错误栈作为辅助参考,通过检索3类上下文(报错根函数、import语句、测试用例样本)弥补GitHub问题报告的信息缺失;②检索增强生成(RAG)赋能 :Libro仅提供固定"问题-测试用例"one-shot样本,本文通过检索项目专属上下文(如仓库内import语句、相似测试用例),帮助LLM理解项目结构与API调用方式;③测试用例的"验证属性":Libro仅关注复现问题,本文生成的测试用例需满足"补丁前失败、补丁后通过",可直接用于验证问题是否修复,实用性更强。
问题3:消融实验结果表明,本文方法中3类检索信息(报错根函数、import语句、测试用例样本)对生成效果的影响有何差异?该差异说明什么?
答案 :
差异从"成功比例下降幅度"可明确:①测试用例样本影响最大 :去除后成功比例从27%降至14%,下降13%;②import语句影响次之 :去除后成功比例降至21%,下降6%;③报错根函数影响最小 :去除后成功比例降至24%,下降3%,甚至在部分仓库(如matplotlib)中去除后效果更优。
该差异说明:①项目内现有测试用例的"风格与逻辑"是LLM生成高质量测试用例的关键参考,能帮助模型贴合项目实际;②import语句为LLM提供正确的API调用上下文,减少语法错误;③GitHub问题报告的错误栈信息可能存在"误导性"(非故障根本原因),故对生成效果贡献有限,进一步验证了方法不依赖错误栈的合理性。
总结
本文针对GitHub问题报告中故障复现测试用例缺失的核心痛点,提出了一套"检索增强生成+大语言模型"的自动化解决方案。通过实证研究明确了问题严重性,用"3类上下文检索+提示工程组合策略"突破现有方法局限,实验数据证明方法成功率显著优于现有方案。
不过,方法也有局限:目前仅支持Python仓库,对复杂框架(如Flask)、算法库(如scikit-learn)效果不佳;LLM的黑盒特性也影响可解释性。未来若能扩展多语言支持、增加代码注释、历史提交等更多上下文信息,有望进一步提升方法的通用性和准确性。
总体而言,这篇论文不仅为GitHub故障复现测试用例生成提供了实用方案,也为"LLM+RAG在软件工程领域的应用"提供了新思路,有很高的工程价值和学术参考意义。