论文链接:https://arxiv.org/abs/2406.14896
Code: https://github.com/ChongQingNoSubway/SelfReg-UNet
来源: Medical Image Computing and Computer Assisted Intervention -- MICCAI 2024
摘要:
自从UNet被提出以来,它在医学图像分割任务中一直占据主导地位。虽然之后有许多研究试图提升UNet的性能,但很少有人深入分析UNet在医学分割中的工作机制。本文通过分析发现,UNet的性能可能受到两个因素的影响:
- 因监督不对称导致模型学到一些无关的特征
- 特征图中存在大量冗余信息
为了解决这些问题,作者提出了一种方法,通过平衡编码器和解码器之间的监督,以及利用特征蒸馏技术,从最后一层包含最多语义信息的特征图中,向其他网络块提供额外的监督,从而减少冗余信息。该方法可以很方便地集成到现有的UNet架构中,且几乎没有额外的计算成本。实验结果表明,这一方法在四个医学图像分割数据集上都能稳定提升UNet的性能。
1. 引言
医学图像分割的重要性:医学图像分割是辅助诊断和引导系统的关键应用,近年来深度学习成为该领域的主流方法,主要归功于UNet架构的突破。
UNet的基本架构:UNet利用编码器提取语义信息,将其传递到解码器,通过逐步上采样生成分割掩码。这一思想在后续的研究中得到了扩展,包括引入注意力机制、改进跳跃连接(如Unet++)和分析不同连接方式(如UCTransNet)。
引入ViT(视觉变换器)与混合模型的出现:为了克服CNN在捕获长距离依赖上的局限,一些方法结合ViT的自注意力机制以增强模型能力。这些混合模型虽然有效,但带来了更大的计算复杂度和参数量,且深度学习中的参数过多导致特征冗余和表现不佳的问题尚未得到充分研究。
模型架构优化方向:除了引入新技术外,也有研究试图通过调整架构(如注意力机制、改进跳跃连接)优化UNet,但这些改动主要关注从编码器到解码器的信息流。
作者的研究发现和亮点:
- 信息流的新的视角:作者指出,事实上"应更关注解码器反馈给编码器"的信息传播,因为解码器接受的监督更多,能更有效过滤无关信息。
- 实证分析 :在标准UNet和SwinUNet方面,发现两个关键问题:
- 特征冗余:浅层特征更丰富,而深层特征容易重复冗余。
- 不对称监督导致的语义损失:编码器和解码器之间的监督不平衡会导致模型学习到不准确的语义,从而影响性能。这与其他视觉任务中的趋势不同(通常深层特征更 discriminative)。
解决方案及贡献:
- 提出语义一致性正则化:用更准确的解码器特征监督编码器,缓解语义信息丢失。
- 提出特征蒸馏:从浅层传导有用信息到深层,提高特征的质量。
- 这些方法可以在现有UNet架构(包括CNN和ViT变体)中无缝集成,成本低,但效果显著。
2. 方法
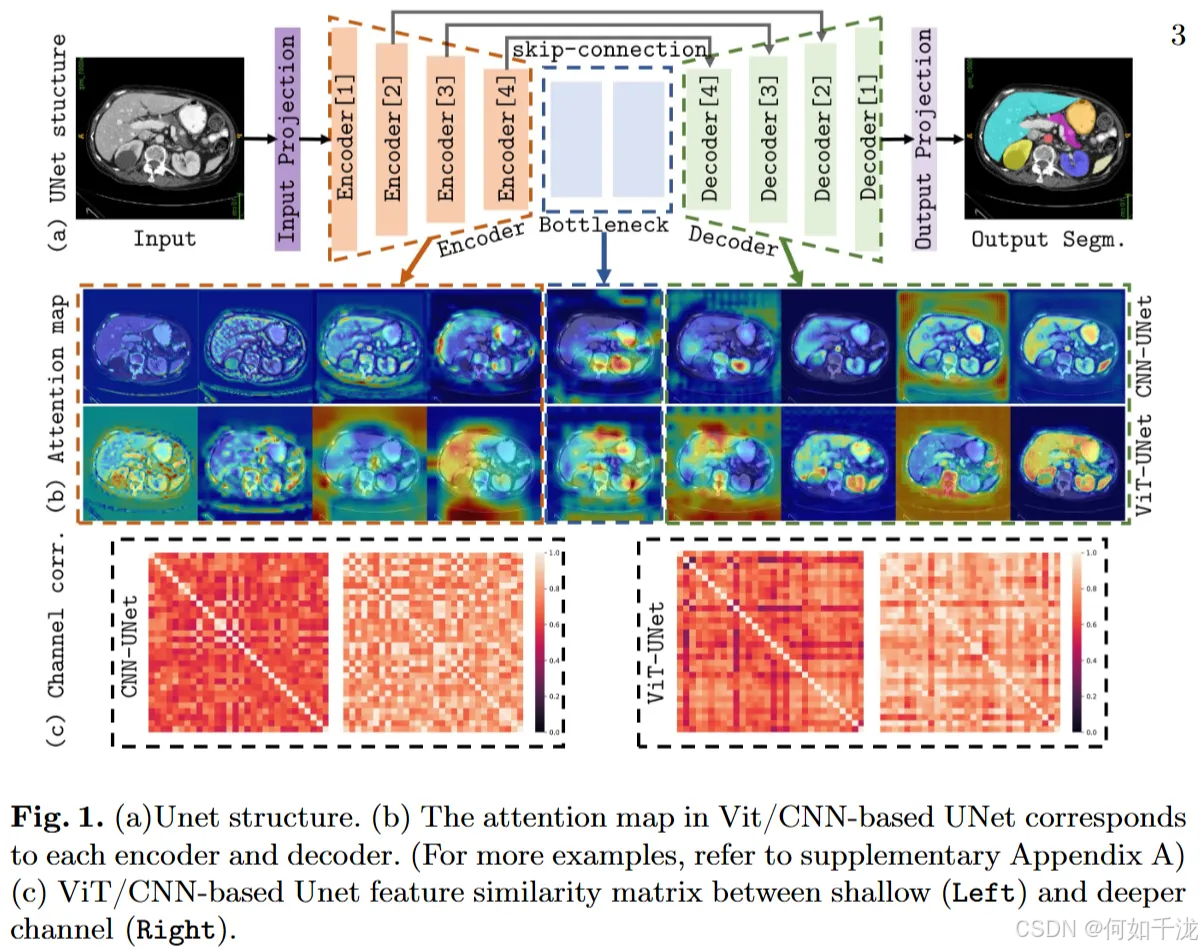
2.1 基本结构介绍
模型选择:作者以经典的UNet作为示例,深度为5层,进行研究。这个结构也是许多变体的基础。
统一结构:为了便于比较和分析,作者考虑了基于卷积(CNN)和基于视觉变换器(ViT)的UNet结构,都采用统一的设计,即:
- 输入和输出投影块(Input/output projection)
- 4个编码器(encoder)块和4个解码器(decoder)块
- 一个瓶颈(bottleneck)
具体定义:
- 在ViT-UNet中,patch embedding block是输入投影块和第一个编码器块的结合体。
- 最后一个 上采样(up-sampling) 块(即最后一层扩展patch的部分)也被视为解码器中的最后一层。
- 每个编码器/解码器块由两个连续的卷积或Transformer子块组成(L=2)。
- 输出投影层是一个卷积层,用于将最后的特征图映射到分割掩码上。
符号表示:
- E m ( l ) E_m^{(l)} Em(l) 和 D m ( l ) D_m^{(l)} Dm(l) 表示第 l l l层的第 m m m个编码器或解码器块
- B ( l ) B^{(l)} B(l)表示瓶颈
- 相关特征图用 F m l F_m^l Fml 表示,从编码器到解码器按顺序排列(如 E 1 ( 1 ) , E 1 ( 2 ) , ... , D 2 ( 2 ) , D 1 ( 1 ) E_1^{(1)}, E_1^{(2)}, ..., D_2^{(2)}, D_1^{(1)} E1(1),E1(2),...,D2(2),D1(1))。
2.2 模型特征分析
分析工具:使用两个常见技术:
- Grad-CAM(梯度加权类别激活映射)
- 特征图的相似性分析
观察的现象:不对称的监督(Asymmetric supervision):
- 发现一 :编码器和解码器的学习方式存在不对称性(见Fig. 1(b))
- 解码器部分较好地识别出真实的目标区域(分割区域)
- 编码器倾向于捕获无关信息(例如 E 3 , E 4 E_3,E_4 E3,E4),导致分割兴趣分散在边界附近
- 发现二 :在解码器中,最靠近输出的较深层(D1)表现出较深刻的理解(靠近真值),而较早的解码块( D 2 , D 4 D_2, D_4 D2,D4)学习到无关信息
根本原因 :这主要由不同的监督信号强度引起。由输出逐层监督,信号逐渐减弱,导致语义信息流失,出现抗真值激活的情况。
- 冗余特征(Redundant features):由于模型的过参数化,容易学习到冗余的无关特征
进行相似度分析:
- 在浅层(较早的层)中,不同通道特征具有较大差异(相似性低)
- 在深层(较后层)中,通道特征高度相似(相似性高),表明冗余
结果:深层冗余特征可能引入无关信息,导致性能下降和计算冗余。
2.3 解决方法
语义一致性正则化(SCR)
- 背景:在自然图像处理任务中,为了弥补语义信息的流失,研究者采用了知识蒸馏和特征对齐等策略,利用丰富的"准确"特征指导"不太准确"的特征,从而提高整体表现。受此启发,作者提出以 包含最多语义信息的特征图(如最后解码块的 D 1 D_1 D1)作为"教师"特征,为其他网络中的各个块提供"额外监督"。
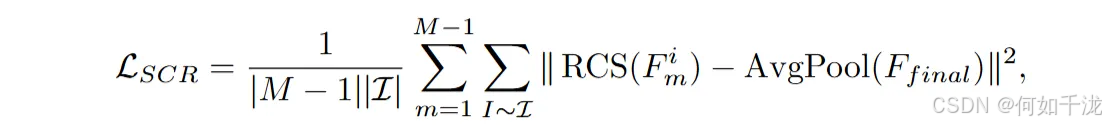
- 方法:
- 通过特征蒸馏机制,目标是让各个块的特征与最后解码块的特征保持一致。
- 使用均方误差(MSE)作为距离度量(也可以用其他蒸馏方式如KL散度)。
- 公式中, F f i n a l F_{final} Ffinal为最后解码块的特征图, F m i F_m^i Fmi是第 m m m个块中第 i i i层的特征图。
- 为了对齐特征的通道和空间维度,采用平均池化(AvgPool)和随机通道选择(RSC)操作(减少计算量,避免语义冲突,示意图在Fig.2(a)中)。
- 损失函数 L S C R L_{SCR} LSCR为所有块和层的特征差异的平均,使用L2范数。
SCR旨在让网络中不同块的特征保持语义一致,通过引导浅层特征学习到更丰富的语义信息。
内部特征蒸馏(IFD)
- 背景: 深层网络中存在特征冗余问题,即不同通道学习到高度相似的特征,导致性能下降和计算浪费。某些通道收缩方法(如剪枝)通过L_p范数推动特征稀疏化,用以突出重要通道
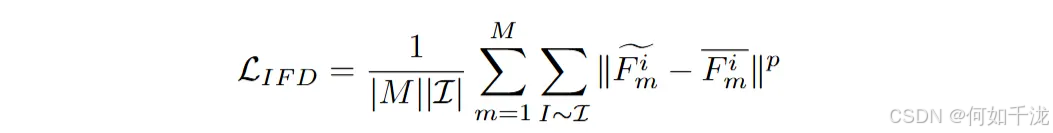
- 方法:
- 模仿这种思想,将浅层特征(顶部通道)与深层特征(底部通道)进行信息蒸馏。
- 具体做法是:将通道分为上半部分(浅层)和下半部分(深层),对它们进行 L p L_p Lp范数约束(在此用L2范数)以引导深层特征学到有用的上下文信息。
- 公式中, F ‾ i m \overline F_i^m Fim为第m个块第 i i i层的浅层特征, F ~ m i \tilde F_m^i F~mi为对应的深层特征(由浅层特征引导),差异通过范数衡量。
目的:通过在浅深特征之间引入蒸馏机制,减少特征冗余,获得更具信息量的深层特征。
**损失函数:**最终的训练目标是将三部分结合起来:
- L c d L_{cd} Lcd:传统的交叉熵和Dice损失,用于监督分割准确性。
- L S C R L_{SCR} LSCR:语义一致性正则化损失。
- L I F D L_{IFD} LIFD:内部特征蒸馏损失。
公式: L = L c d + λ 1 ∗ L S C R + λ 2 ∗ L I F D L = L_{cd} + λ_1 * L_{SCR} + λ_2 * L_{IFD} L=Lcd+λ1∗LSCR+λ2∗LIFD
其中, λ 1 λ_1 λ1和 λ 2 λ_2 λ2为调节不同项贡献的超参数。
3. 实验和结果
3.1 数据集
- Synapse多器官分割数据集:该数据集包括30个病例,共计3779张轴向腹部CT图像。研究中,将其中的18个样本用作训练,12个用作测试。模型性能使用平均Dice相似系数(DSC)进行评估,评估八个腹部器官的分割效果。
- 自动心脏诊断挑战(ACDC)数据集:该数据集包含100个不同患者的心脏MRI扫描图像,每个图像被标注了左心室(LV)、右心室(RV)和心肌(MYO)。其中,70个病例(1930个轴向切片)用于训练,10个用于验证,20个用于测试。性能评价同样采用DSC指标。
- 核细胞和腺体分割数据集 :
- GlaS(Gland Segmentation)数据集:85张用于训练,80张用于测试。
- MoNuSeg(Multi-Organ Nucleus Segmentation)数据集:30张用于训练,14张用于测试。
实验中采用三次5折交叉验证(三次重复重复的5折交叉验证),以确保结果的稳定性。评价指标包括平均DSC和交并比(IoU)。
3.2 实验设置
- 所有实验使用输入图像尺寸224×224,且遵循先前研究的训练策略(数据增强、预处理等)。
- 训练由Nvidia GTX3090显卡(24GB内存)完成。
- SwinUnet模型使用ImageNet预训练权重,Unet模型从头训练。
3.3 结果
实验结果显示:在Table 1(Synapse数据集)、Table 2(ACDC数据集)和Table 3(Glas和MoNuSeg数据集)中,作者的提出的损失函数(proposed loss)表现出明显的有效性,带来了显著的性能提升。
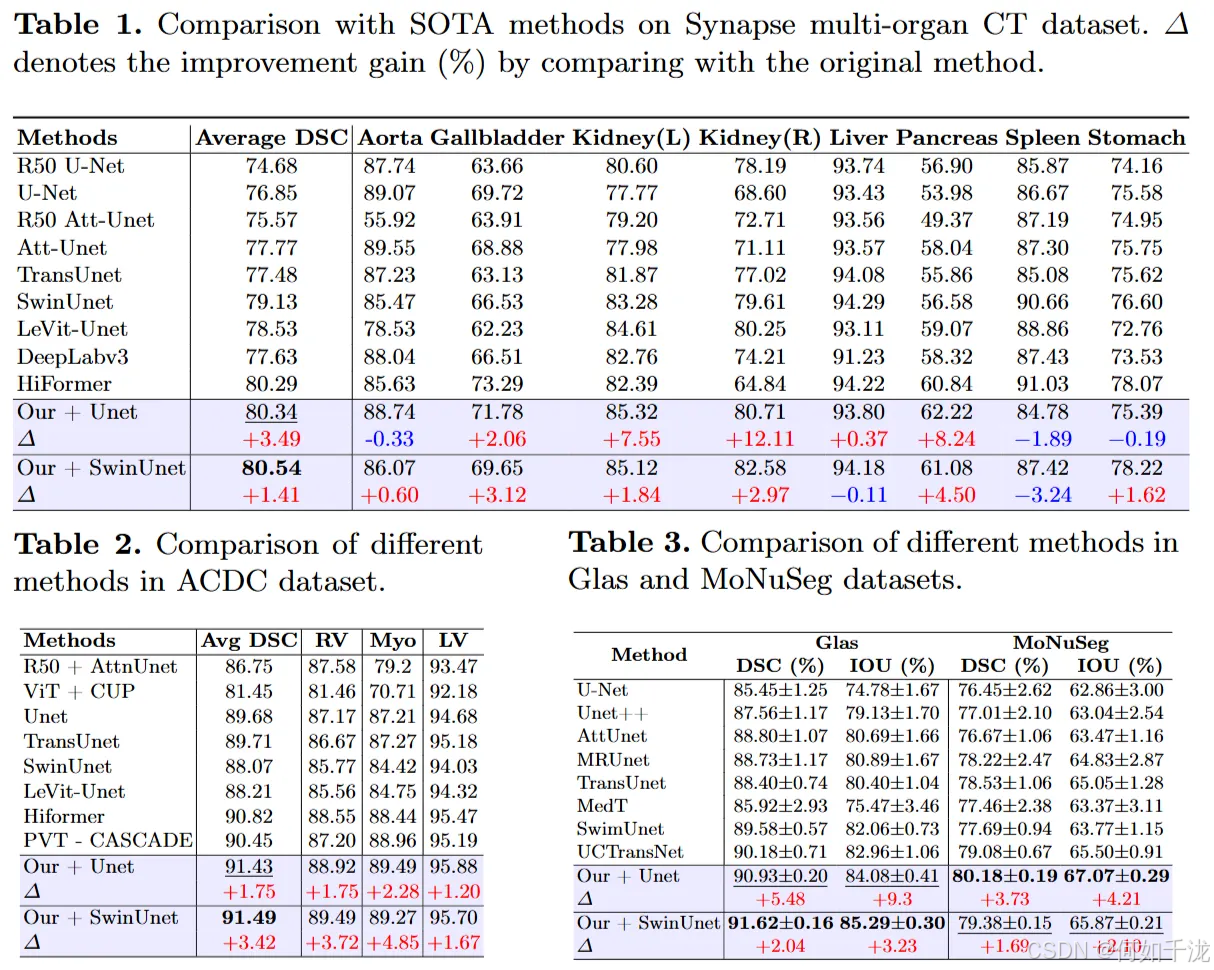
性能提升的具体数字:
- 利用该损失函数,Unet模型在四个数据集上的平均DSC(Dice相似系数)分别提高了:
- 3.49%(Synapse)
- 1.75%(ACDC)
- 5.48%(Glas)
- 3.73%(MoNuSeg)
- SwinUnet模型也有所提升,分别为:
- 1.41%
- 3.42%
- 2.04%
- 1.69%
整体对比:经过增强的模型(改进的Unet和SwinUnet)总体优于之前的最新(SOTA)方法。例如,增强的Unet和SwinUnet在平均DSC方面分别比之前的模型(如Hiformer、TransUnet、UCTransNet等)表现出0.05%和0.25%的微小提升。
解决的难题:作者强调这些改进尤其体现在难以分割的器官上,比如胆囊、左右肾和胰腺(如图3和表1所示)。

- 在ACDC数据集上的表现:与SOTA的HiFormer模型相比,增强的Unet和SwinUnet分别提高了0.6%和0.67%的平均DSC,展现出继续的优越性。
- 在Glas和MoNuSeg数据集上的表现:方法超越了之前的UCTransNet模型,分别获得0.7%和1.1%的DSC提升。
- 图4示意:作者还指出,在Glas数据集的例子中,原有的优化skip连接的模型(如UCTTransNet)会出现误分割和不完整的形状,尤其是背景类似的区域。而借助他们提出的loss后,SwinUnet的分割结果能更接近真实,显示出完整的形状和清晰的背景,特别是在难以改善的样本中(如图4中的第三行)。
3.4 消融实验
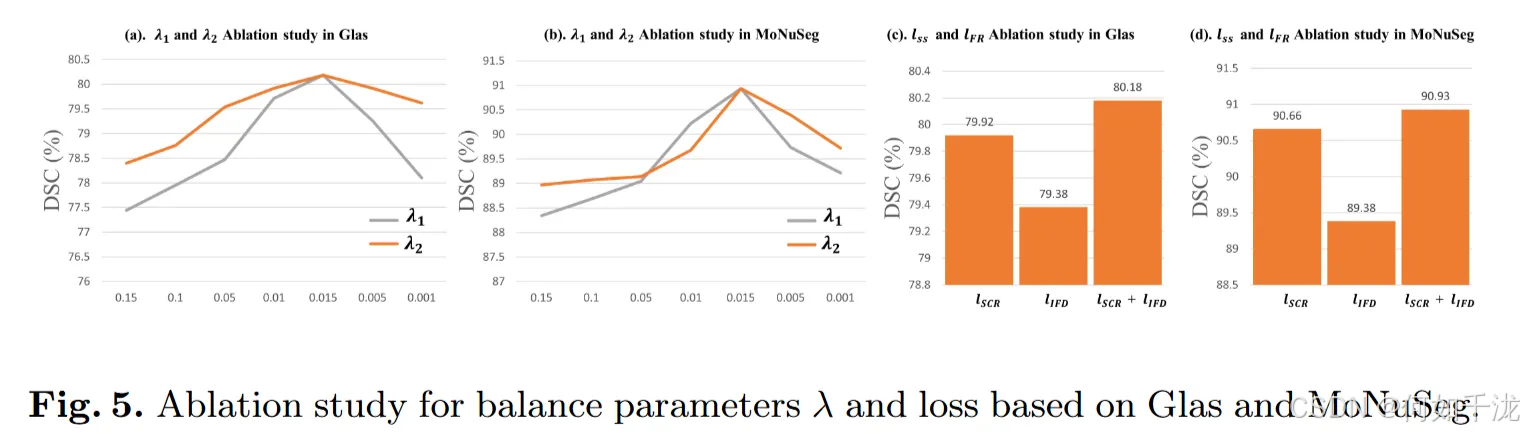
实验对象与数据集:采用Unet模型在Glas和MoNuSeg两个数据集上进行测试。
超参数调节(Loss balance hyperparameters):作者调整了两个超参数λ1和λ2的值(在图5(a,b)中展示)。
- 结果显示,最佳设置是λ1 = 0.015和λ2 = 0.015。
- 当λ1的权重减小时(即在lSCR中降低λ1的值),模型性能迅速下降,说明没有足够的语义监督会导致性能下降。
- 这说明两个超参数对于模型表现的平衡非常重要,正确的语义监督(由λ1和λ2调节)是性能提升的关键。
不同损失函数的效果(Effectiveness of the proposed losses):作者比较了只使用部分损失或全部同时使用的效果(在图5(c,d)中展示)。
- 两个数据集的结果一致。
- 发现在同时使用两个损失函数时,模型能达到最优性能。
4. 结论
作者揭示了基于Unet的医学图像分割中存在的问题,包括不对称的监督(asymmetric supervision)和特征冗余(feature redundancy)。
针对这些问题,作者提出了一种新的优化方法,结合语义一致性正则化(semantic consistency regularization)和内部特征蒸馏(internal feature distillation)。
实验结果显示,解决这两个问题确实能有效提升基于ViT或CNN的UNet模型的表现。作者相信,这个方法在多种医学图像分割任务中都具有潜力。