导读
本文聚焦百度电商风控场景,针对传统机审多模态识别弱、语义模糊难区分、审核体验差等痛点,推进原有机审流程向AI化流程改造,基于业界MultiAgent范式在审核场景落地应用,提出 "多模态大模型 + 规则 + 知识库" 协同的机审 Agent 方案。通过:1. 审核标准体系化、大模型化;2. 多模态大模型在领域典型问题上的抽象技术方案;3. 针对场景化问题精准优化。产出标杆式业务落地效果,为电商风控大模型落地提供可迁移能力强的技术方案。
01 背景与问题
1.1 背景
"百度优选"是百度旗下电商品牌,伴随着近年百度电商的快速成长,在 "人、货、场" 高速运转的背后,风控体系始终面临 "安全 - 效率 - 体验" 的三角挑战:
-
对平台:风控是 "生命线"若未能准确及时的管控风险,可能引发监管处罚、用户信任流失,甚至影响百度的商誉。
-
对商家:"快过审 + 明理由" 是核心诉求,在传统人工审核流程中,商家提交信息后需等待2-4 小时(峰值期甚至 1 天),若被拒审仅收到 "内容违规" 的模糊反馈(在历史的商家访谈中,部分不满意指向了 "审核慢、理由不清")。
-
对用户:"看到靠谱内容" 是关键,若平台出现了不可靠或者低质的信息,用户可能会因 "被骗" 损失利益,从而进一步导致用户的流失 。
作为百度电商风控技术团队,我们的目标很明确:用大模型重构机审体系,实现 "全机审覆盖 + 即时反馈 + 高可解释性",让平台 "安全"、商家 "高效"、用户 "放心"。
1.2 面临的问题
在大模型落地前,我们的传统风控流程是 "商家提交→机审(规则+小模型过滤)→人审(人工判定)",这种模式在业务快速增长下:
-
问题 1:人审瓶颈刚性,无法支撑业务增长
-
问题 2:机审能力薄弱,为保证风险不露出人审覆盖面大,审核时效长(小时级,极端情况下甚至长达1天)
-
传统机审依赖规则引擎(如关键词匹配 "最佳""第一" 判定虚假宣传),但无法处理复杂场景:
-
多模态违规:主图显示 "Nike"品牌,详情页显示为"山寨品牌"------ 规则无法识别图文不一致;
-
模糊语义:"本品有助于睡眠"(合规)vs "本品治愈失眠"(违规)------ 规则无法区分 "程度差异";
-
问题 3:审核体验差,商家申诉率高
-
传统机审拒审理由模糊,商家需反复猜测修改方向。
为了解决上述提到的问题,本文将详细介绍本次最佳实践
02 技术方案
针对传统流程的痛点,我们提出 "大模型 + 规则 + 知识库" 协同的机审 Agent 方案,核心逻辑是:让模型做 "语义理解"(擅长的事),规则做 "确定性判断"(稳定的事),知识库补 "外部信息"(精准的事)。
2.1 整体技术方案
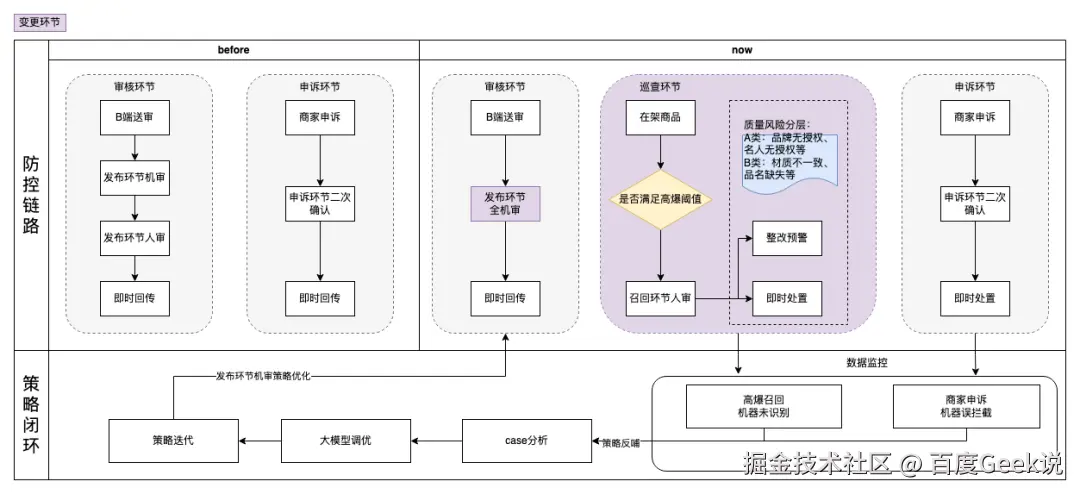
流程上,我们重构了整个审核流程,实现了 "全机审覆盖 + 即时反馈 + 动态校准":
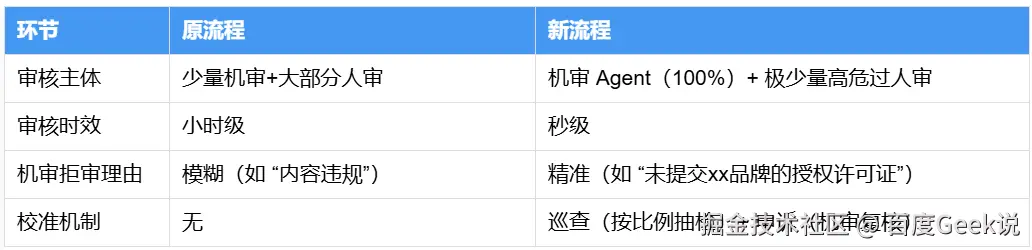
原流程 vs 新流程对比
2.2 亮点
2.2.1 审核标准对齐
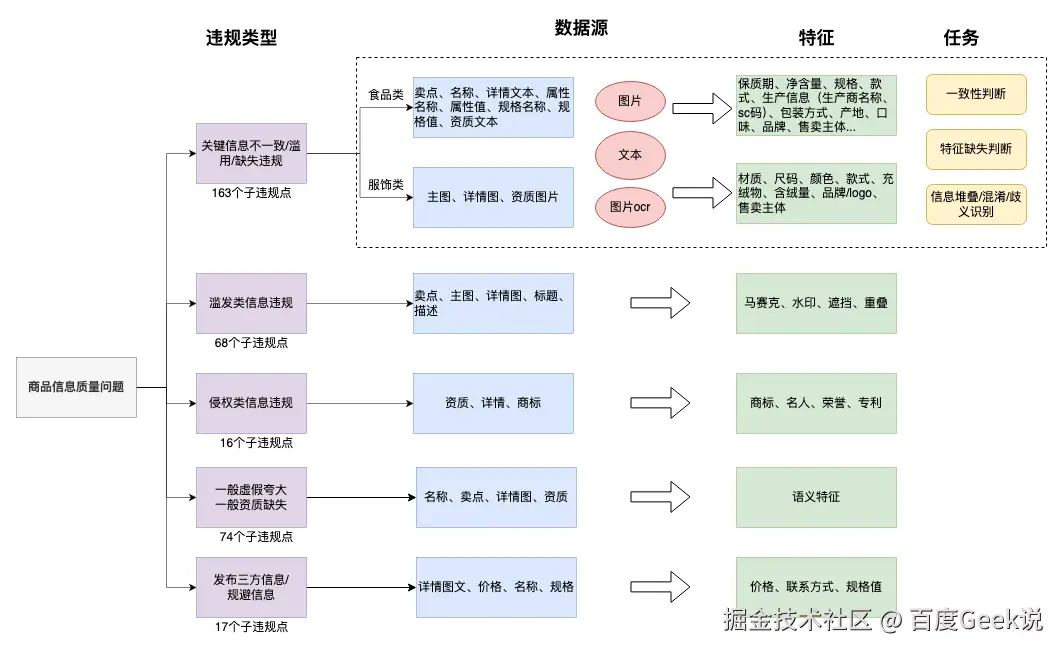
要实现全机审,"人审标准可量化" 是前提。我们通过 "风险梳理→标准优化→动态更新" 三步,将 700 余个零散风险点整合成 24 组核心风险,覆盖了95%+的线上违规问题。
步骤 1:风险点梳理 ------ 做 "减法"
我们采集2025年Q1的全部人审记录,
-
相似风险合并:采用层次聚类将相似违规进行归类。
-
风险分层:对"风险严重程度"较低,且不直接影响商品价值和用户购买决策的风险暂时不纳入机审(人工巡查覆盖)。
-
长尾剪枝:对"发生频率"较低的风险暂时不纳入机审(人工巡查覆盖)。
步骤 2:审核标准优化 ------ "规范化"
我们把人审识别的风险划分为三部分,明确违规/明确不违规/边界样本

步骤 3:动态更新 ------ 做 "迭代"
我们每月例行巡查、回收商家申诉和人审处理数据,若发现新违规类型,则补充到风险组,及时更新线上机审agent。
2.2.2 基于多模态大模型的机审agent设计
大模型是机审 Agent 的 "大脑",我们选择大语言模型+多模态大模型为基础,辅助知识库(品牌授权库、类目树、资质库),实现 "多模态理解 + 精准判定"。
输入层:多模态数据整合
接收商家提交的全量商品数据,包括:
-
文本数据:商品标题、详情页描述、规格参数、商家资质名称;
-
图像数据:主图、详情图、资质图片(如《授权许可证》);
-
结构化数据:商家资质库(如品牌授权记录、进口报关单)、平台类目树、风险规则库。
特征抽取层:多模态特征融合
特征抽取是机审的 "感知层",我们采用 "规则抽取 + LLM 文本理解 + 多模态模型图像理解" 的组合方式,覆盖所有维度的商品信息:
-
规则抽取:用正则表达式提取标题中的品牌(如 "Nike")、类目(如 "运动鞋")、关键词(如 "进口");
-
LLM 文本理解:用文心大模型提取详情页中的模糊语义(如 "治愈失眠" 的违规表述)、逻辑矛盾(如 "进口商品" 但未提报关单);
-
多模态大模型图像理解:使用多模态大模型模型识别主图中的品牌 logo(如 Nike 的 Swoosh 标志)、资质图片中的 OCR 信息(如《授权许可证》编号)。
风险判定层:大模型 + 规则 + 知识库协同
风险判定是机审的 "决策层",核心逻辑是 "让专业的模块做专业的事":
-
规则引擎处理确定性逻辑:针对 "绝对化用语""资质必填项" 等确定性规则,直接用代码判断(如 "含'进口'关键词必须提交《进口报关单》");
-
知识库查询外部信息:关联商家资质库、平台类目树等领域知识(如查询商家是否有 Nike 的授权记录);
-
LLM 综合判定:融合多模态特征、规则结果、知识库信息,输出最终结论(如 "主图含 Nike logo + 无授权记录 → 品牌侵权违规")。
输出层:精准反馈 + 可解释性
输出层是机审的 "交互层",需满足商家的 "明理由、能整改" 需求:
-
审核结果:通过 / 拒绝;
-
拒审理由:自然语言描述(如 "您发布的商品主图含 Nike 品牌 logo,但未提交 Nike 品牌的《授权销售许可证》");
-
整改建议:输出给发品端前端,提供自动整改能力(如删掉对应违规位置违规信息)。
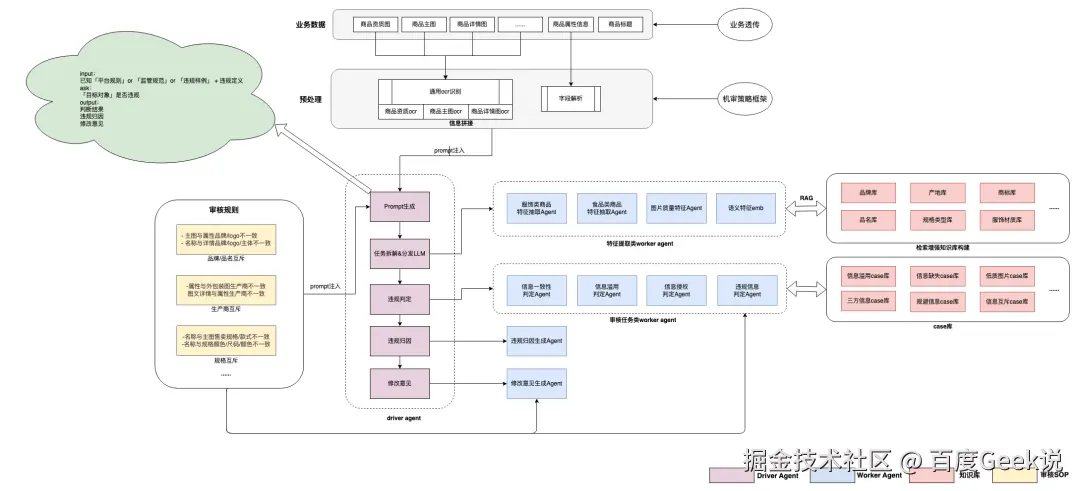
任务拆分:让模型 "专注擅长的事"
我们将机审任务拆分为三类,以同时保证审核结果的高召回,高准确,清晰可解释:
-
特征抽取:提取商品的关键信息(如从主图提取品牌 logo、从详情页提取材质等);
-
风险判定:规则引擎结合知识库,判断特征是否违规(如 "logo 是 Nike,但无授权→侵权");
-
理由生成:模型生成自然语言拒审理由(如 "未提交xx品牌的授权许可证,请补充")。
03 实践案例
在典型问题的文本问题判定,图片问题判定,图文融合问题判定上,经过我们的技术方案演进,均可达到几乎对标人审能力的效果。
3.1 资质缺失风险判定
场景描述
针对高危商品行业如三品一械行业,售卖相关商品时要求商家提供清晰可辨、且信息完整的对应资质(如《保健食品批准证书》、《国产特殊用途化妆品行政许可批件》、《医疗器械备案证明》、《委托进口协议》等)。
传统流程痛点
-
规则策略:仅能检查 "是否含'进口'关键词",无法关联商家资质库,漏检率高;
-
人审需人工查询和核对资质,耗时长,易因 "漏看" 导致误判。
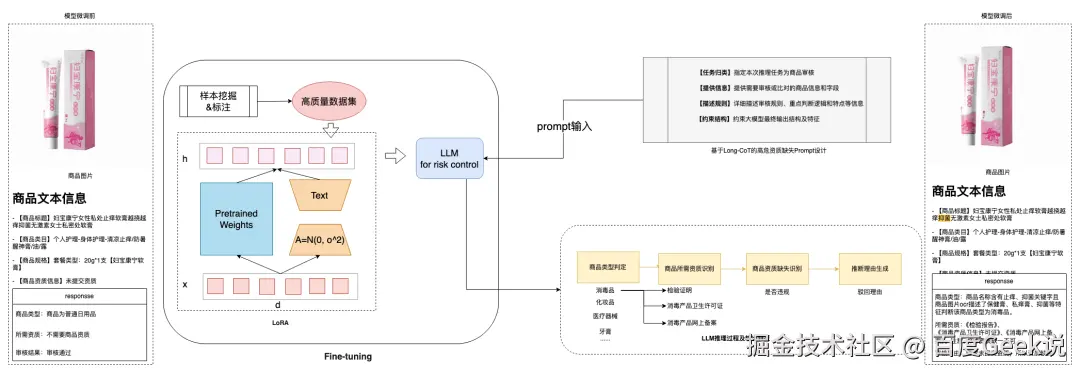
机审方案:领域微调 + Prompt Engineering
对于此类复杂判定类问题,领域知识深度深,我们基于基座模型进行了模型微调,通过高质量样本收集 -> Prompt Engineering -> 数据增强 -> 模型微调 得到了专注于电商风控场景的领域AI模型
-
高质量样本收集 :我们将真实场景下经人工核验的高质量样本沉淀为模型训练语料。这一环节是模型训练的核心,保障了训练数据的真实性、多样性,以及对各类场景的覆盖丰富度。
-
Prompt Engineering:基于不同样本类别,设计场景化提示词,引导模型关注风控领域知识:
-
数据增强:我们采用SOTA思考模型,动态生成Cot并对生成内容进行精细化纠偏,提升模型的推理能力:
-
模型微调:对比百度自研文心基座模型和开源Qwen系列模型,我们分别对比和采用了全参数微调和指令微调方式,加速训练过程,进一步提升模型效果,获得风控领域专家模型。
3.2 品牌授权风险判别
场景描述
商家发布的商品信息,涉及限售品牌,但实际未获得品牌授权(易引发假货投诉等体验问题)
传统流程痛点
-
"山寨 logo"较难以识别(如 "Nlke" 冒充 "Nike");
-
授权书需人工手动核验,耗时久,漏检率较高;
-
管控品牌库变动升级较多
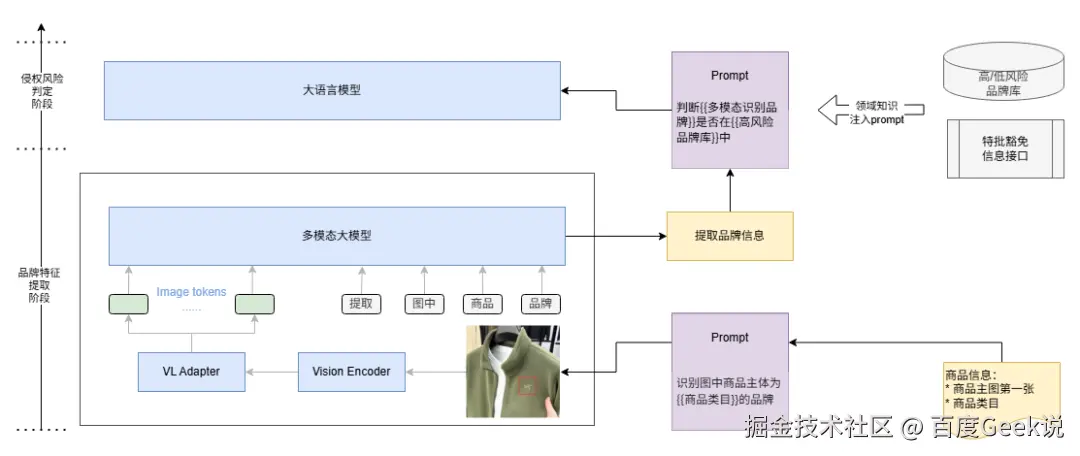
机审方案:多模态特征匹配 + 知识库关联
采用 "多模态模型图像识别 + LLM 字符相似度对比 + 知识库查询" 的方案:
-
多模态模型图像识别:采用多模态模型提取主图中的 logo 特征;
-
知识库查询:关联限售品牌库,确认品牌是否限售,是否有授权记录;
-
LLM 图文信息融合判断:确认提取品牌信息是否限售且无授权;
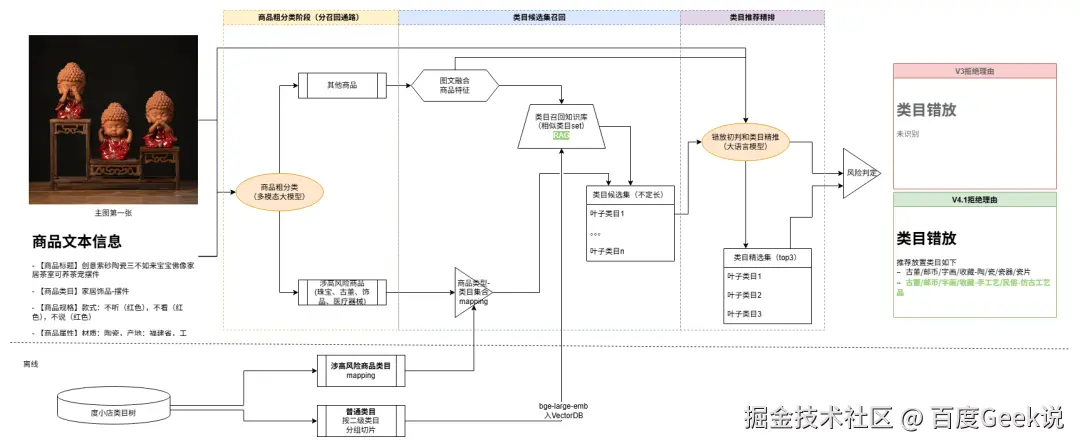
3.3 类目错放风险判定
场景描述
1)因电商商业流量推荐等场景中列类目特征权重极高,类目准确性严重影响流量变现效率;2)平台佣金政策和资质/定向准入等管控要求与类目强关联;因此要求商家发布商品必须选择到平台类目体系内最准确的类目;
传统流程痛点
-
图文特征融合困难:传统方案一般仅使用标题识别类目,商家对抗后容易绕过机审
-
平台类目庞杂:审核员需非常了解平台近5000个类目结构,极容易误审
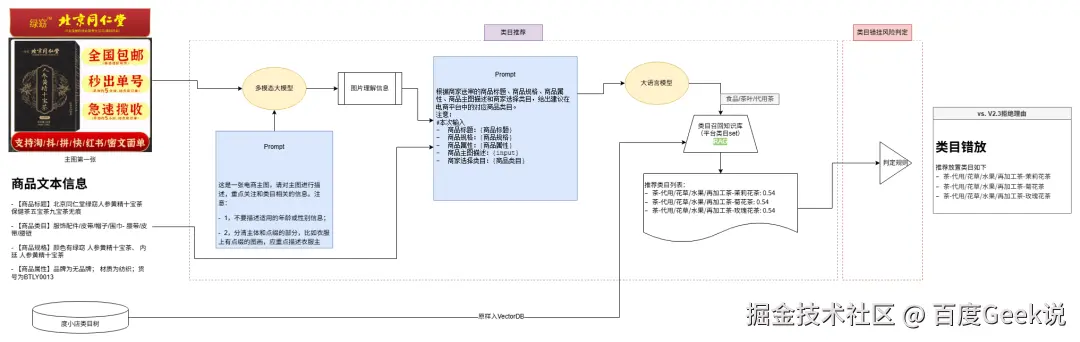
方案演进
方案一:基础方案
- 图文特征融合推荐平台top相似度类目
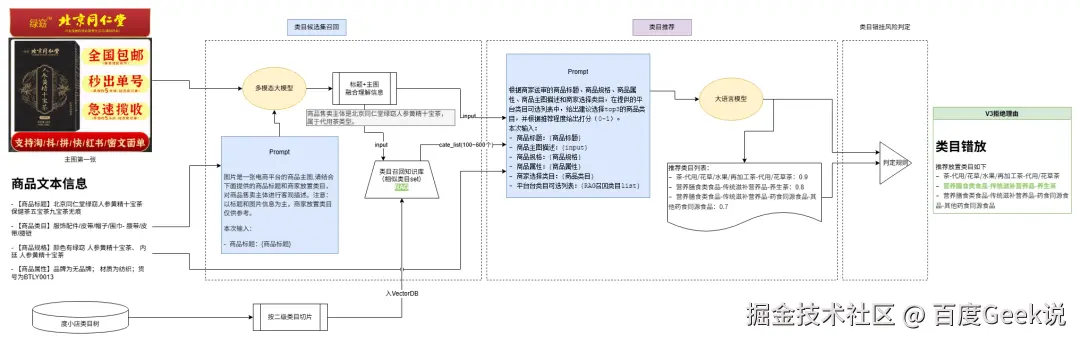
方案二:解决类目推荐不准确问题
-
改为召回+rank 两阶段方案,提升精准选择类目可能性
-
升级相似度计算模型为bge-large-emb,解决部分情况下相似度召回精准不足问题
方案三:解决部分高风险商品在第一轮候选集召回不足问题
-
增加定向召回通路,提升高风险商品召回能力
-
升级风险判定方案,结合大模型判定和识别规则,进一步提升精准判别能力
04 总结与展望
4.1 落地效果
超预期的 "三升三降"
三升
-
机审覆盖率提升
-
审核时效提升
-
商家满意度提升
三降:
-
人审量减少
-
申诉率减少
-
用户投诉率减少
4.2 经验总结
大模型不是 "取代人",而是 "解放人"------ 让审核人员从 "重复劳动" 转向 "标准制定、风险预判"。
本次落地实践较为成功的要点
-
多模态融合:电商数据 80% 是多模态的,单模态模型无法覆盖所有场景;
-
可解释性优先:大模型的自然语言生成能力是提升商家体验的关键 ------ 传统规则的 "内容违规" 无法让商家整改,而 LLM 生成的 "未提交 Nike 授权许可证" 能直接指向问题,进一步的我们业务团队为商家提供了一键整改功能,大大提升商家使用平台工具的满意度;
-
闭环迭代:用巡查、申诉数据持续优化模型,形成 "数据→模型→效果提升" 的飞轮;
4.3 展望
agent的自我优化:利用大模型生成能力生成难样本,解决风控场景的大难题------小样本问题,辅助少量人工干预使得agent自我演进和优化。
05 结语
过去的1年里,大模型技术突飞猛进的发展,为电商风控带来了 "质的飞跃"------ 从 "被动堵风险" 转向 "主动防风险"。在百度电商风控技术的实践中,我们乘着时代的技术红利,落地 "多模态大模型 + 规则 + 知识库" 解决了传统机审的痛点,实现了 "平台安全、商家高效、用户放心" 的平衡。未来,我们将继续探索 "AI + 风控" 的边界,提供可快速迁移的大模型落地方案。