一、概述
本文提出 RIVAL(Reinforcement Learning with Iterative and Adversarial Optimization),一种针对机器翻译(MT)的迭代对抗强化学习框架。我们发现基于人类反馈的强化学习(RLHF)在口语化字幕翻译任务中表现不佳,主要是因为奖励模型(RM)与翻译模型(LLM)之间存在分布偏移,导致训练失效。RIVAL通过以下创新解决该问题:
- 对抗博弈机制:将RM与LLM的优化过程建模为最小化-最大化博弈,RM负责区分强弱翻译,LLM负责优化弱翻译,以缩小与强翻译的质量差距。
- 双奖励设计:结合语义对齐的定性偏好奖励与定量偏好奖励(如:BLEU分数),提升迭代强化学习训练的稳定性与泛化性。
实验表明,RIVAL在口语字幕和WMT数据集上显著优于监督微调(SFT)和专用翻译模型(如:Tower-7B-v0.2),同时保持跨语言泛化能力。
论文已被EMNLP 2025收录,链接:arxiv.org/abs/2506.05...
二、动机
大语言模型(LLM)在多任务中展现出突破性能力,其强大的多语言理解与生成能力为MT提供了新范式。大部分研究是基于极大似然估计的SFT,这种方法容易受到暴露偏差的影响,导致错误累积与翻译质量退化。同时,有限的句子级上下文建模能力难以保证全局连贯性。所以另一种可选的方案是RLHF。当前MT研究主要聚焦于正式的书面语,而口语化字幕翻译面临独特挑战:口语化字幕具有高度非正式性(如俚语、语气词、语法省略)、结构松散及多领域混杂性等特点,在真实场景中缺乏高质量平行语料,传统依赖人工标注的评估方法(如BLEU)在语义对齐优先的场景中失效。为填补这一空白,我们首次构建了大规模口语化字幕数据集,并尝试应用RLHF优化翻译质量。
我们在探索LLM在机器翻译中的应用时,发现使用RLHF优化口语化字幕翻译任务的效果不佳。具体示例如下:LLM对源文本翻译完成后,又额外补充了"It's ok! It's great!"的正向翻译,但源文本中并没有对应的原文。这种"投机行为"导致翻译失真,违背语义忠实性原则,是典型的Reward Hacking问题。

Reward Hacking示例
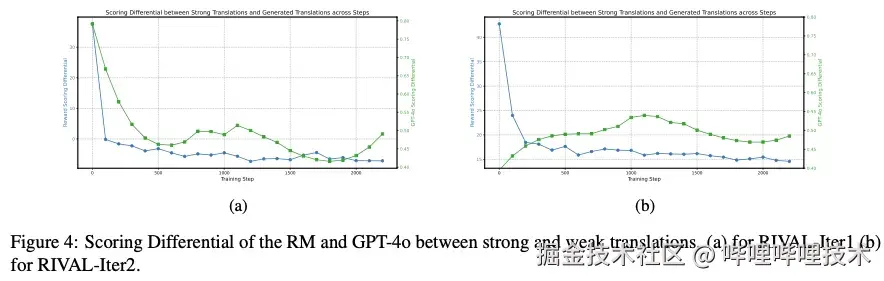
为了探究出现Reward Hacking的原因,我们对比了RM与GPT-4o的评分差异。我们发现RM的评分差(强翻译-弱翻译)持续下降:随着LLM优化,评分差越来越大,RM误判弱翻译的质量越来越好。然而,GPT-4o的评分差先降后升,表明真实的弱翻译质量先因初始正确的奖励信号不断提升,后因翻译模型过拟合RM而偏离真实的质量评分。追溯其根本原因,离线RM是基于初始的弱翻译训练得到的,无法适应LLM优化过程中数据的分布偏移,导致给出的奖励信号失效。
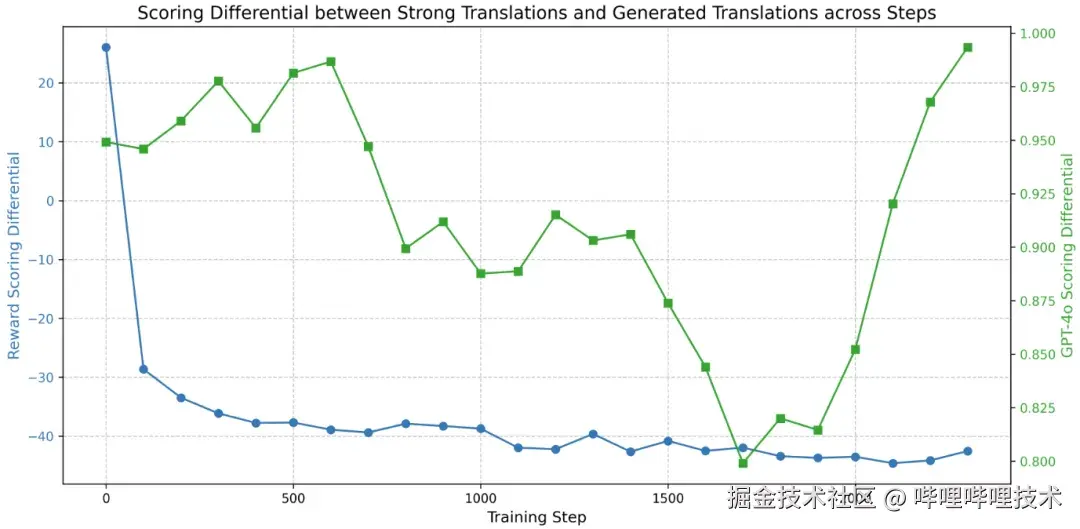
RM和GPT-4o对强弱翻译的评分差
受生成对抗网络(GAN)的启发,我们提出RIVAL框架:将RM与LLM的优化过程建模为最小化-最大化博弈,二者可通过博弈共同进化,离线RM被转化为在线RM,从而避免数据分布偏移问题。
三、 方法
3.1 RIVAL框架:对抗式迭代优化范式
RIVAL框架将传统RLHF的两阶段训练重构为RM与LLM的对抗博弈。其核心思想源自GAN的生成-判别机制,形式化为以下最小化-最大化目标:
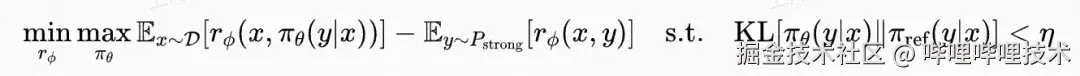
其中,r_Phi是奖励模型,作为判别器来区分强弱翻译,pi_theta是翻译模型,作为生成器逼近来强翻译分布P_strong,pi_ref是参考模型,即初始化的模型,通过KL散度约束防止模型过度偏移。通过不断地迭代优化,并且利用当前轮的LLM构造RM的训练数据,RM能够有效地学习并适应新的数据分布。同时,LLM也能在准确的奖励信号监督下不断探索新的动作空间,从而逐渐变成强翻译模型。RIVAL框架的示意图如下:
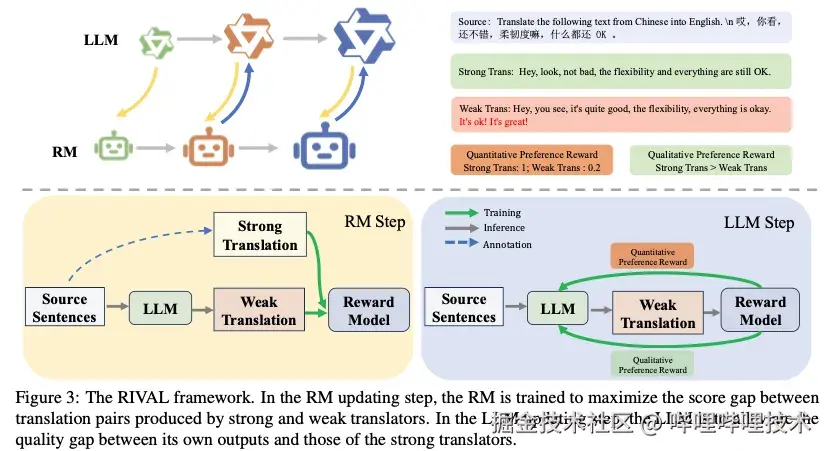
RIVAL框架
3.2 RM和LLM优化
在RM优化时,固定LLM的参数,其优化目标简化为:
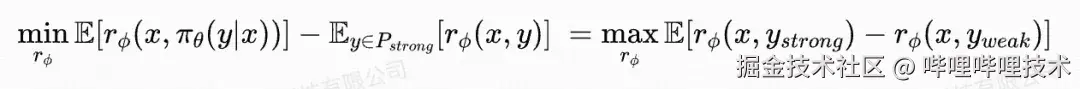
其中,x 是输入的源文本,y_strong是GPT-4o生成的强翻译,y_weak是当前LLM生成的弱翻译。其物理含义为尽可能增大强弱翻译之间的差距,损失函数的形式为rank loss。在本文中,我们将其命名为定性的偏好损失。此外,在每一轮的迭代训练中,我们不仅只利用当前轮LLM生成的弱翻译,也会回放历史轮数据,来增强数据的多样性以及防止数据分布偏移。
相似地,LLM优化时,我们需要固定RM的参数。其优化目标被简化为:
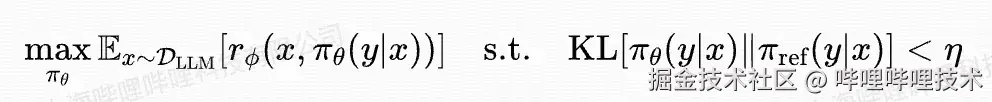
其物理含义为尽可能最大化RM给出的奖励分数。我们采用GRPO算法来优化LLM模型。
3.3 结合定量偏好奖励
由于翻译任务的动作探索空间比较大,在GRPO训练中,只依赖定性偏好奖励可能会导致训练不稳定。另外,考虑到计算开销,我们设计了多头RM,一个输出头用来预测定性偏好奖励,另一个输出头用来预测定量偏好奖励,例如:BLEU分数。所以,最终我们的RM损失函数除来上述介绍的rank loss,还包含了对BLEU分数预测的mae loss。具体形式如下:
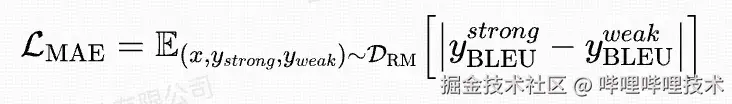
详细的算法流程图如下:

RIVAL算法流程图
四、 实验
我们在自建的口语字幕数据集和WMT标准数据集上验证RIVAL框架的有效性。针对两个任务的特性,我们选用了不同的评估指标:口语字幕任务采用GPT-4o多维度评分(准确性、完整性、连贯性、风格一致性)和COMETKiwi指标,因为更侧重语义对齐而非字面匹配;WMT任务则同时使用BLEU和COMETKiwi,以兼顾词汇忠实度与语义充分性。
在口语字幕翻译任务中,RIVAL框架展现出显著优势。仅使用定性偏好奖励的RIVAL-Iter1模型在GPT-4o评估中达到3.68的平均分,较基线模型提升5.5%,COMETKiwi指标同步改善至66.27。然而,迭代至第三轮时GPT-4o的评分出现回落(平均分3.53),表明纯定性偏好奖励在开放空间中的优化方向存在不稳定性。WMT翻译任务的实验进一步验证了双奖励机制的必要性。当引入定量偏好奖励(BLEU)后,RIVAL-Iter2-Qual+Quant在英中和中英翻译任务上的BLEU分数和COMETKiwi指标都优于使用单独的定性偏好奖励优化的模型。这种提升源于双奖励的协同作用:定量奖励锚定词汇对齐,定性奖励保障语义质量。
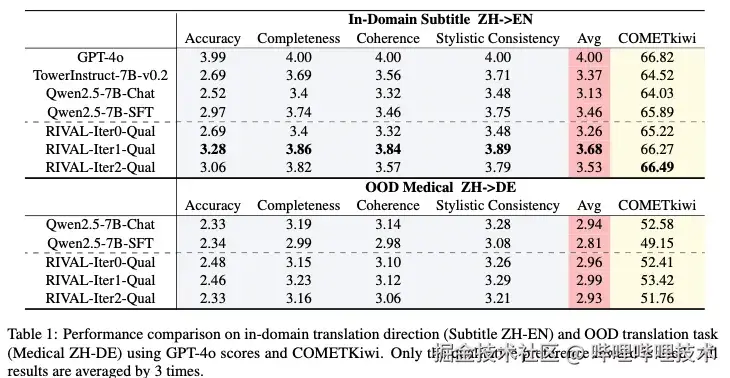
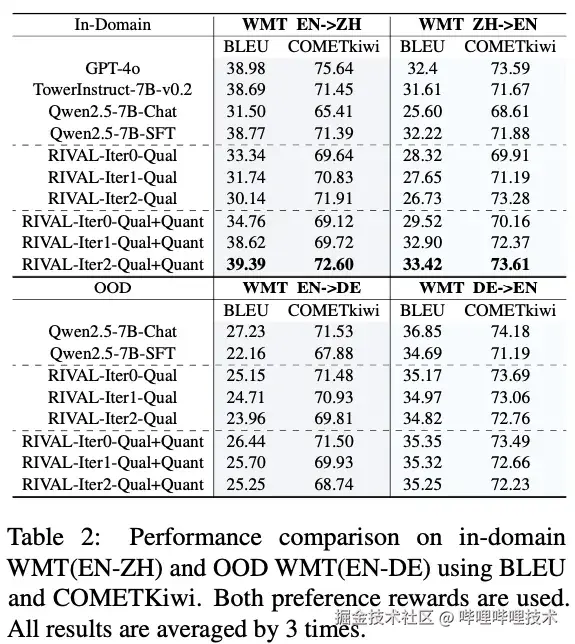
RIVAL框架在字幕翻译和WMT翻译任务上的效果
在跨语言泛化性测试中,RIVAL展现出优于SFT的鲁棒性。以医疗领域的中德翻译为例,SFT模型在OOD场景下COMETKiwi降至49.15,显著低于原始模型(52.58),而RIVAL-Iter1仍保持53.42的优异表现,甚至在部分OOD任务上超越原始模型,证明其通过探索有效翻译策略而非模式记忆实现泛化。
我们也画了后两轮迭代过程中RM和GPT-4o对强弱翻译的评分差,从图中可以看到,RIVAL通过对抗机制将评分差稳定维持在较小范围,有效缓解了奖励模型与翻译模型间的分布偏移问题。
五、总结
本文提出 RIVAL 框架,通过对抗式迭代优化解决了RLHF在口语字幕翻译中的分布偏移问题。RIVAL将LLM和RM的优化建模为最小化-最大化博弈:RM最大化强弱翻译评分差距,LLM缩小与强翻译质量差距,并创新引入双奖励机制使得训练更稳定。我们在口语字幕翻译任务和WMT英中翻译任务中,验证了RIVAL方法相较基线、SFT模型和专用翻译模型的优越性。此外,RIVAL在OOD测试中的性能也超越SFT,证明其通过探索有效策略避免灾难性遗忘。尽管迭代上限与计算成本仍需优化,但该框架为机器翻译甚至后训练方法提供了兼具理论创新与实用价值的新范式。
参考文献
1 Ouyang L, Wu J, Jiang X, et al. Training language models to follow instructions with human feedbackJ. Advances in neural information processing systems, 2022, 35: 27730-27744.
2 Luo W, Li H, Zhang Z, et al. Sambo-rl: Shifts-aware model-based offline reinforcement learningJ. arXiv preprint arXiv:2408.12830, 2024.
3 Goodfellow I J, Pouget-Abadie J, Mirza M, et al. Generative adversarial netsJ. Advances in neural information processing systems, 2014, 27.
4 Shao Z, Wang P, Zhu Q, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language modelsJ. arXiv preprint arXiv:2402.03300, 2024.
5 Achiam J, Adler S, Agarwal S, et al. Gpt-4 technical reportJ. arXiv preprint arXiv:2303.08774, 2023.
6 Rei R, Treviso M, Guerreiro N M, et al. CometKiwi: IST-unbabel 2022 submission for the quality estimation shared taskJ. arXiv preprint arXiv:2209.06243, 2022.
7 Shoeybi M, Patwary M, Puri R, et al. Megatron-lm: Training multi-billion parameter language models using model parallelismJ. arXiv preprint arXiv:1909.08053, 2019.
8 Sheng G, Zhang C, Ye Z, et al. Hybridflow: A flexible and efficient rlhf frameworkC//Proceedings of the Twentieth European Conference on Computer Systems. 2025: 1279-1297.
9 Guo D, Yang D, Zhang H, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learningJ. arXiv preprint arXiv:2501.12948, 2025.
10 Alves D M, Pombal J, Guerreiro N M, et al. Tower: An open multilingual large language model for translation-related tasksJ. arXiv preprint arXiv:2402.17733, 2024.
-End-
作者丨Index MT Team