目录

写在前面
现在的AI模型看短视频还行,但一旦视频变长,比如超过几分钟甚至几小时,它们就容易"看懵",因为视频信息量太大,模型记不住也处理不过来。传统方法要么需要花大量时间和算力重新训练模型,要么得依赖收费高昂的商用API(比如GPT-4)。而Video-RAG提出了一种免训练、低成本、即插即用的新思路,让普通开源模型也能高效理解长视频。
简单说,Video-RAG就像给视频理解模型配了一个"智能小助手",能自动从视频里提取关键文字信息来帮忙,让模型看得更明白、答得更准。
论文地址: https://arxiv.org/abs/2411.13093
github链接: https://github.com/Leon1207/Video-RAG-master
一、最大的优点:又轻便又强大,还省资源
**1.轻量省资源:**它只需要在现有模型基础上额外增加约8GB的显存,处理一个视频问题平均只多花5秒左右。
**2.兼容性强:**像插件一样,能直接搭配任何开源视频理解模型使用,不需要重新训练。
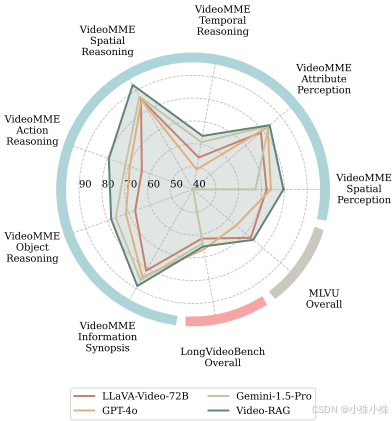
**3.效果提升明显:**在多个长视频测试集上,给模型加上Video-RAG后,性能平均提升了8%。尤其当它配合720亿参数的大模型时,效果甚至超过了谷歌的Gemini-1.5-Pro和OpenAI的GPT-4o这类顶尖商用模型。
二、核心方法:给模型配个"信息提取小助手"
Video-RAG的工作流程分三步,核心是自动从视频中提取三类辅助文字信息:
第一步:解析问题,生成信息需求
当用户提问后,模型先自动分析问题,判断需要从视频里找哪些类型的辅助信息。比如它会生成三类检索请求:
**语音转文字需求:**是否需要提取视频里的对话或旁白?
**物体检测需求:**是否需要识别视频中出现的特定物体?
**物体关系需求:**是否需要知道物体的位置、数量或它们之间的空间关系?
第二步:并行提取与检索关键文字信息
系统会同时调用三个开源工具处理视频,建立三个信息库:
**OCR文字库:**用EasyOCR识别视频帧中出现的所有文字(比如路牌、标题)。
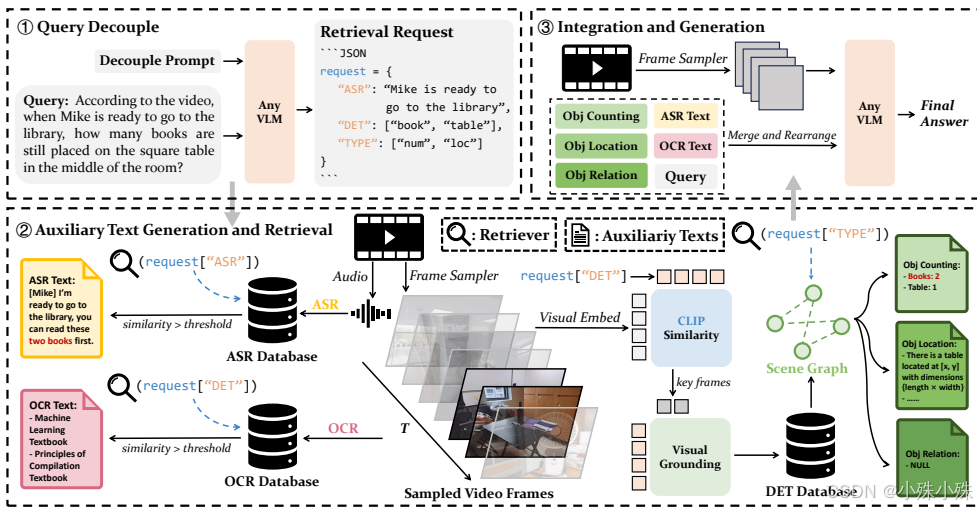
**ASR语音库:**用Whisper把视频里的音频转成文字字幕。
**物体信息库:**用目标检测模型找出关键帧里的物体,并用场景图描述它们的位置、数量和相互关系(比如"杯子在桌子左边")。
接着,用检索系统从这些信息库中精准找出和用户问题最相关的文字片段,避免信息过载。
第三步:组合信息,生成最终答案
把检索到的关键辅助文字按时间顺序整理好,和原始视频帧、用户问题一起交给模型,模型就能给出更准确的答案了。
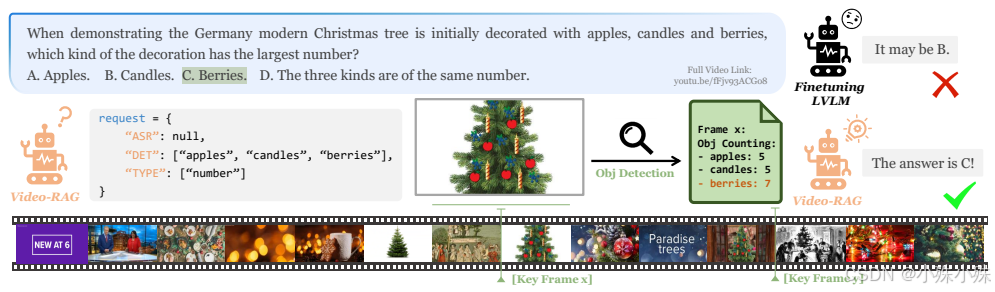
三、为什么效果好?辅助文字帮大忙
这些提取出的辅助文字(OCR、ASR、物体描述)之所以有效,是因为:
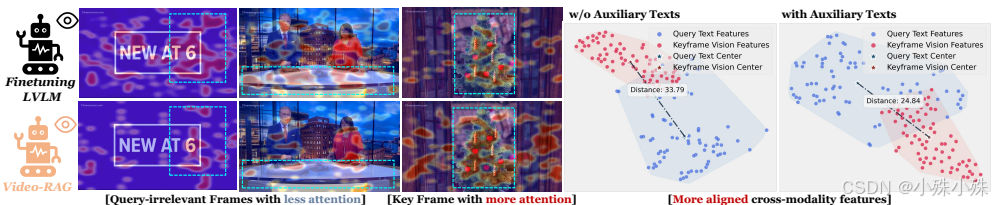
**补充视觉盲区:**视频画面可能看不清的字幕、重要的背景对话,都能通过文字补充进来。
**促进多模态对齐:**辅助文字像"桥梁",帮助模型更好地把用户的语言问题与对应的视频画面关联起来。
减少模型幻觉:明确的文字信息能有效纠正模型"瞎猜"的情况,比如准确数出视频里出现了几个人,而不是凭空想象。
总之,Video-RAG提供了一种非常实用且高效的思路,让资源有限的开源模型也能在长视频理解任务中表现出色,大大降低了技术使用的门槛和成本。
关注不迷路(*^▽^*),暴富入口==》 https://bbs.csdn.net/topics/619691583