本节课介绍了大模型架构不同模块的各种变体,超参数的设置,稳定模型训练的技巧,以及减少计算资源使用的一些方法;
Architecture variations
Pre-vs-post norm
虽然原始 transformer 论文中使用的是 post norm,但是现在使用 pre norm 已经成为了共识
甚至出现了 double norm:模块前后都加上归一化
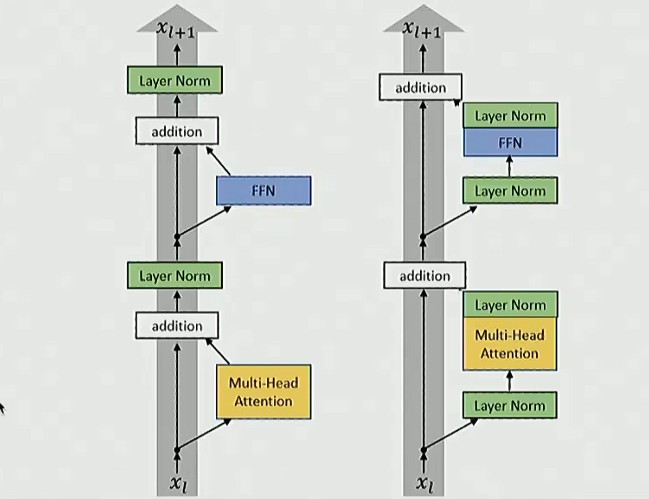
为什么残差连接不适合做层归一化:
残差连接提供了恒等映射,从网络最顶层开始贯穿到最底层,在训练神经网络时,这种结果使梯度传播变得非常顺畅(反向传播);如果在中间加入层归一化,就可能破坏这种梯度传播特性
Layernorm vs RMSNorm
LayerNorm:输入激活值后,先减去均值,再除以方差,进行缩放,最后偏移调整
RMSNorm:无需减去均值,也无需添加偏置项,效果差异相当(可以简化模型)
优势:速度快,并且需要从内存加载的参数数量也随之减少

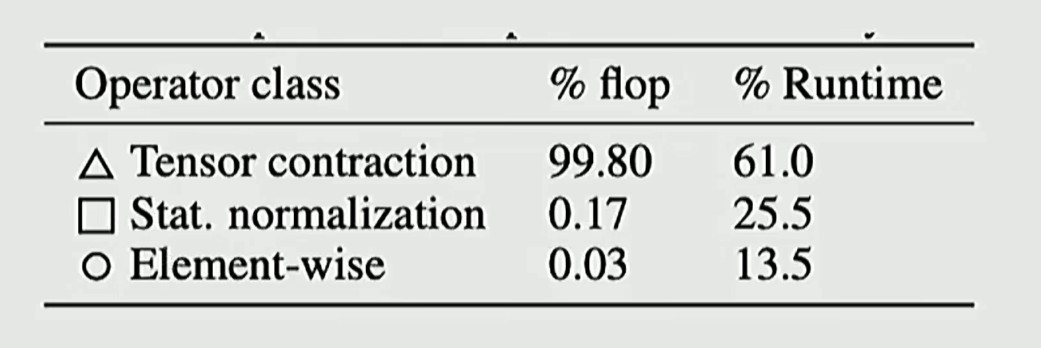
虽然矩阵乘法运算占比非常高(99.8%),但是架构要考虑的还有内存移动优化
可以看到虽然归一化运算在浮点运算占比低,但是运行时间却占了 1/4,归一化操作仍然会带来巨大的内存搬运开销(内存优化和计算性能同等重要)
现代 transformers 的另一个共识:去除偏置项,仅保留纯粹的矩阵乘法运算
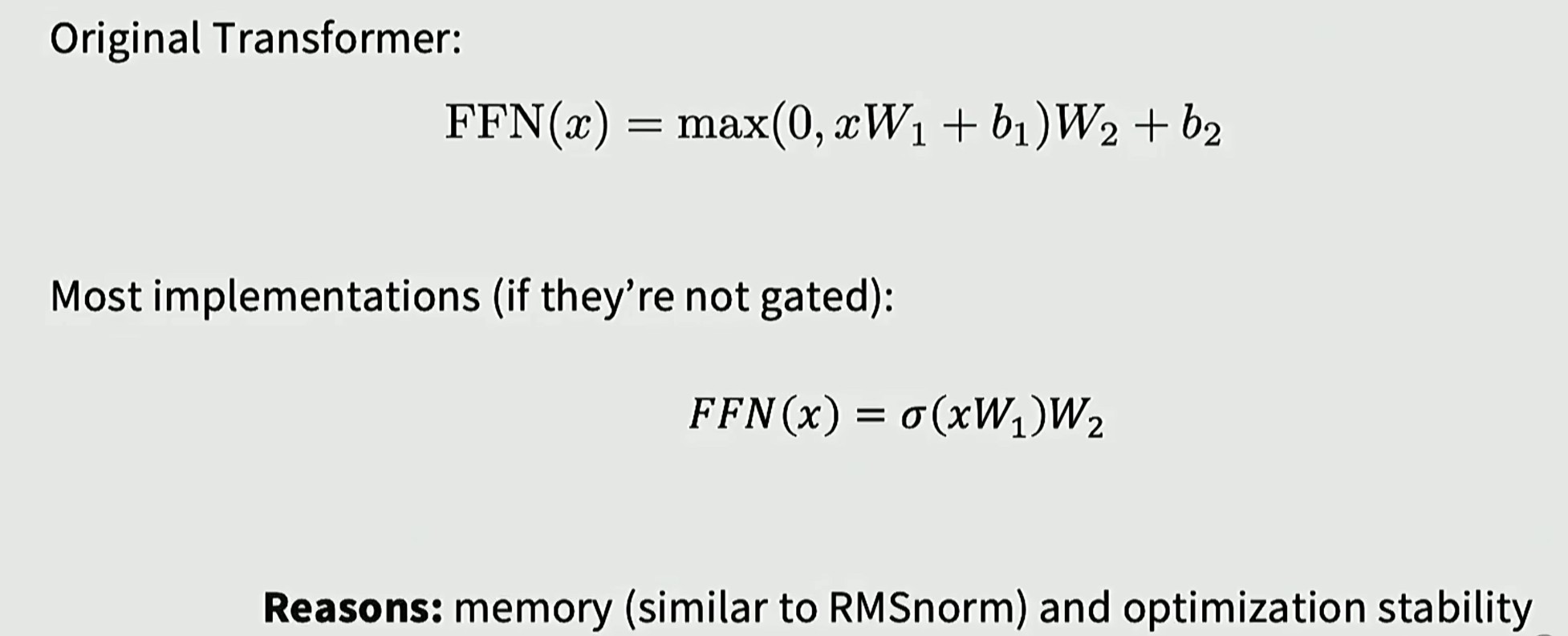
Activations
下面讲解几个常用的激活函数,图像如下:
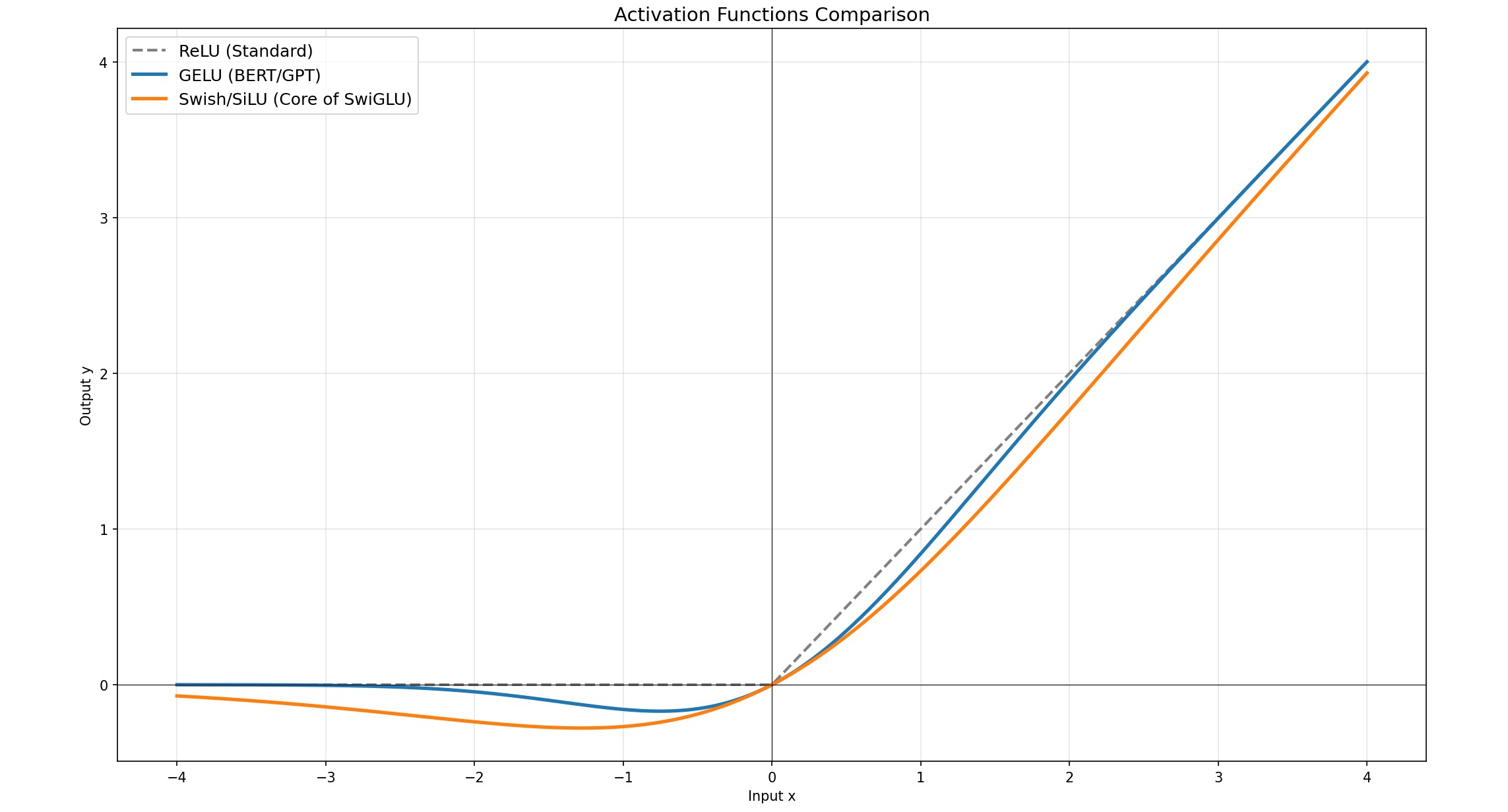
ReLU
优点:
计算极快(无指数运算),稀疏性(部分神经元不激活);
解决梯度消失问题(正区间梯度为1)
缺点:
Dead ReLU:负区间梯度为0,神经元可能永久死亡;
输出非零中心化:这会导致下一层的输入也恒为正,使得反向传播时权重的更新方向呈现"锯齿状"(要么全往正方向更新,要么全往负方向),收敛速度慢
GeLU
ReLU 是粗暴的 "小于0就关掉",GELU 则是根据输入的值有多大,按概率来决定保留多少
其中 是高斯分布的累积分布函数(输入 x 越小,归零概率越大,x 越大越接近线性输出)
优点:
平滑性(Smoothness):ReLU 在零点处是尖锐的(不可导),而 GELU 是处处光滑可导的。这种平滑性有助于优化过程,使训练更稳定,收敛得更好
处理负值:GELU 在负值区域不是直接变 0,而是允许微小的负梯度流过(曲线在 0 附近会先稍微下沉一点点,再回到 0),这比 ReLU 保留了更多的信息
GLU(Gated Linear Unit)
门控线性单元:是一种神经网络层结构,作用是让神经网络学会"自我控制",根据输入的内容决定要把多少信息传递到下一层
信息路:A = xW + b,是原始的线性变换(承载数据)
门控路:B = σ(xV + c),经过了 Sigmoid 激活函数,输出的是数据的通过率(0 表示关门,丢弃数据,1 表示开门,数据完全通过)
逐元素相乘:,A 和 B 对应位置相乘,通过门控 B 来控制数据 A 的过滤情况
对于 GLU 来说,只需缩小各维度,就能保持参数量一致
GeGLU / SwiGLU(*GLU)
ReLU 和 GeLU 是纯粹的激活函数,而 GeGLU / SwiGLU 实际上是 GLU(门控线性单元的变体)
Transformer 中使用的是 GeLU,而现在的版本答案是 SwiGLU(Swish = x * sigmoid(x))
不同 GLU 的变体:

Serial vs Parallel layers
传统的 transformer 采用串行设计,但是会增加计算难度(但还是串行更流行)
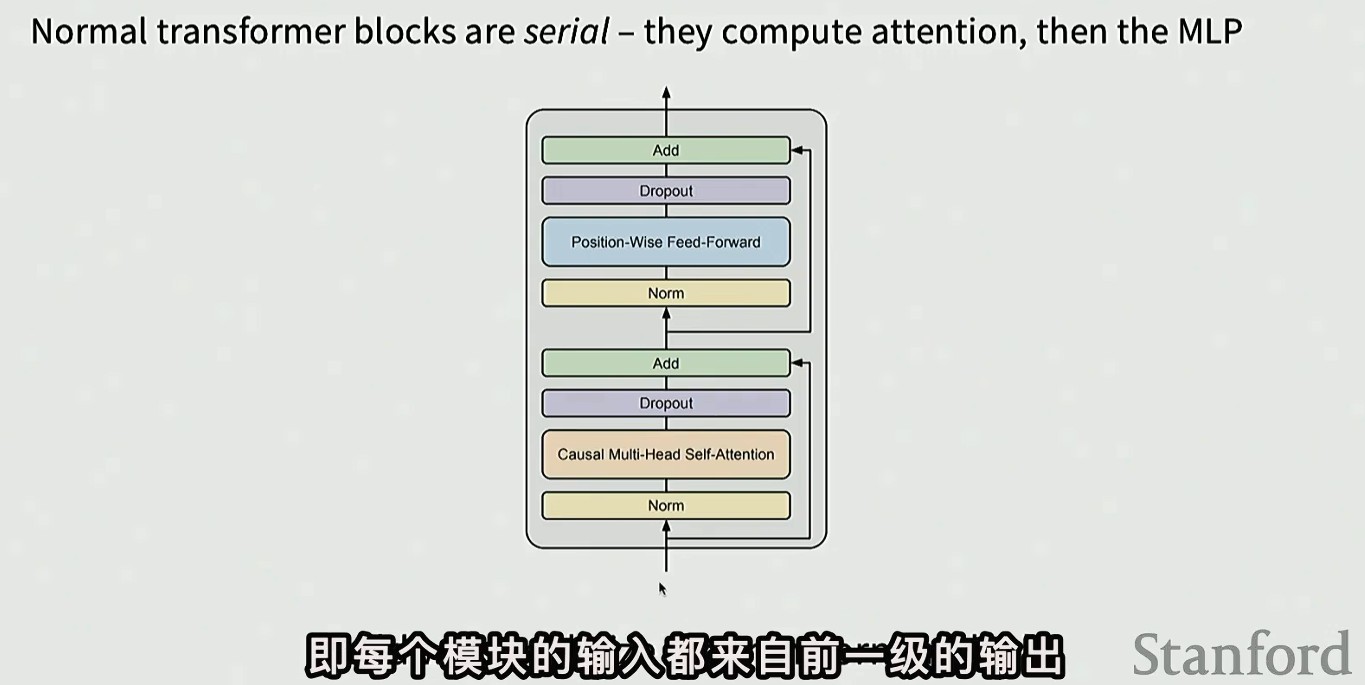
部分模型采用并行结构,并行计算 MLP 和自注意力,一同加到残差流中(更高效)

Position Embeddings
位置编码:符号嵌入 -> 绝对位置嵌入(简单地添加一个位置信息,将学习得到的位置向量融入词嵌入) -> 相对位置嵌入(在注意力机制的计算过程中添加特定向量)
现在最流行的则是 RoPE(相对位置编码技术,Rotary Positional Embeddingss)
核心设计理念:向量之间的相对位置关系

假设我们有一个嵌入函数 f(x, i),x 表示需要被嵌入的词语,i 表示位置索引
存在某个函数 F,计算这些向量内积时,可以表示为另一个函数 G(讨论的是位置相关性,这个定义强制要求绝对位置不变性,只关注两个词语之间的距离)
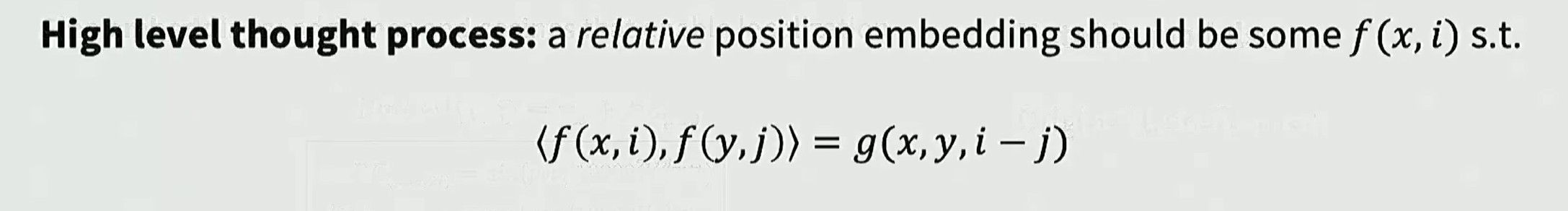
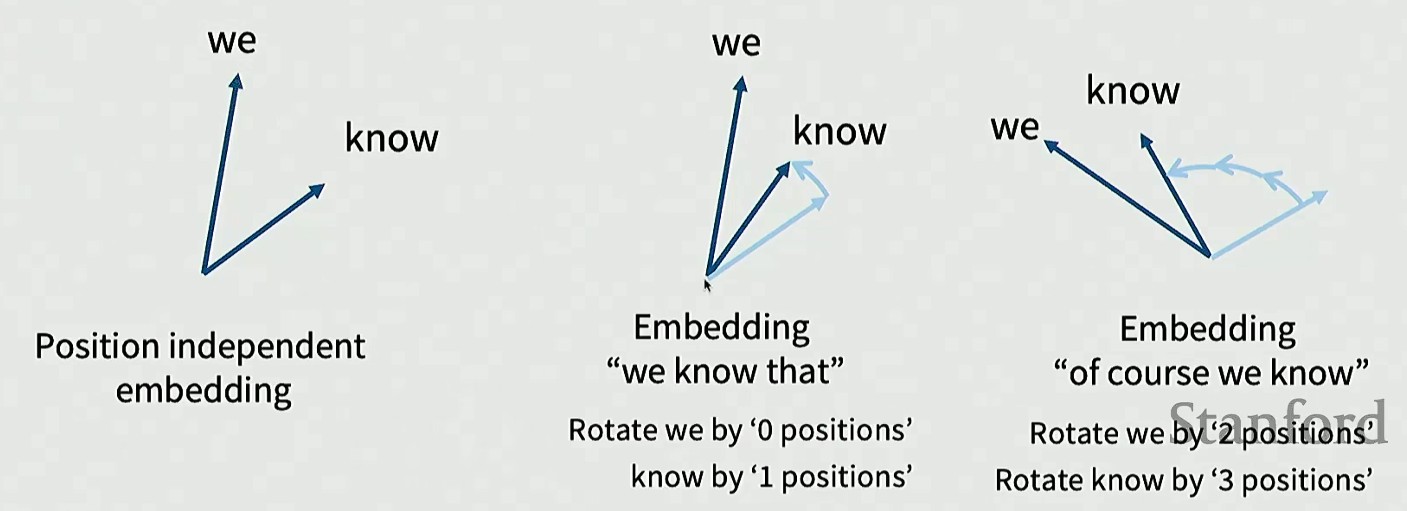
RoPE 确实掌握了一个不变性:旋转,它独立于绝对位置(内积具有选择不变性)
从最开始两个独立向量,到 'we know' 的嵌入表示(从左往右,0 开始计数),只有 know 需要旋转一次,到后面嵌入序列 'of course we know',两个向量的相对位置保持不变(夹角),一起旋转了两次
RoPE 只根据词位置决定旋转角度来转动向量,内积运算不受相对旋转影响(内积值仅与位置间距相关)
二维平面的旋转是很容易的,我们将(Query,Key)进行旋转得到位置嵌入版的二维坐标
多维情况下,我们将维度两两分组,得到(x1,x2),并且每队独立旋转
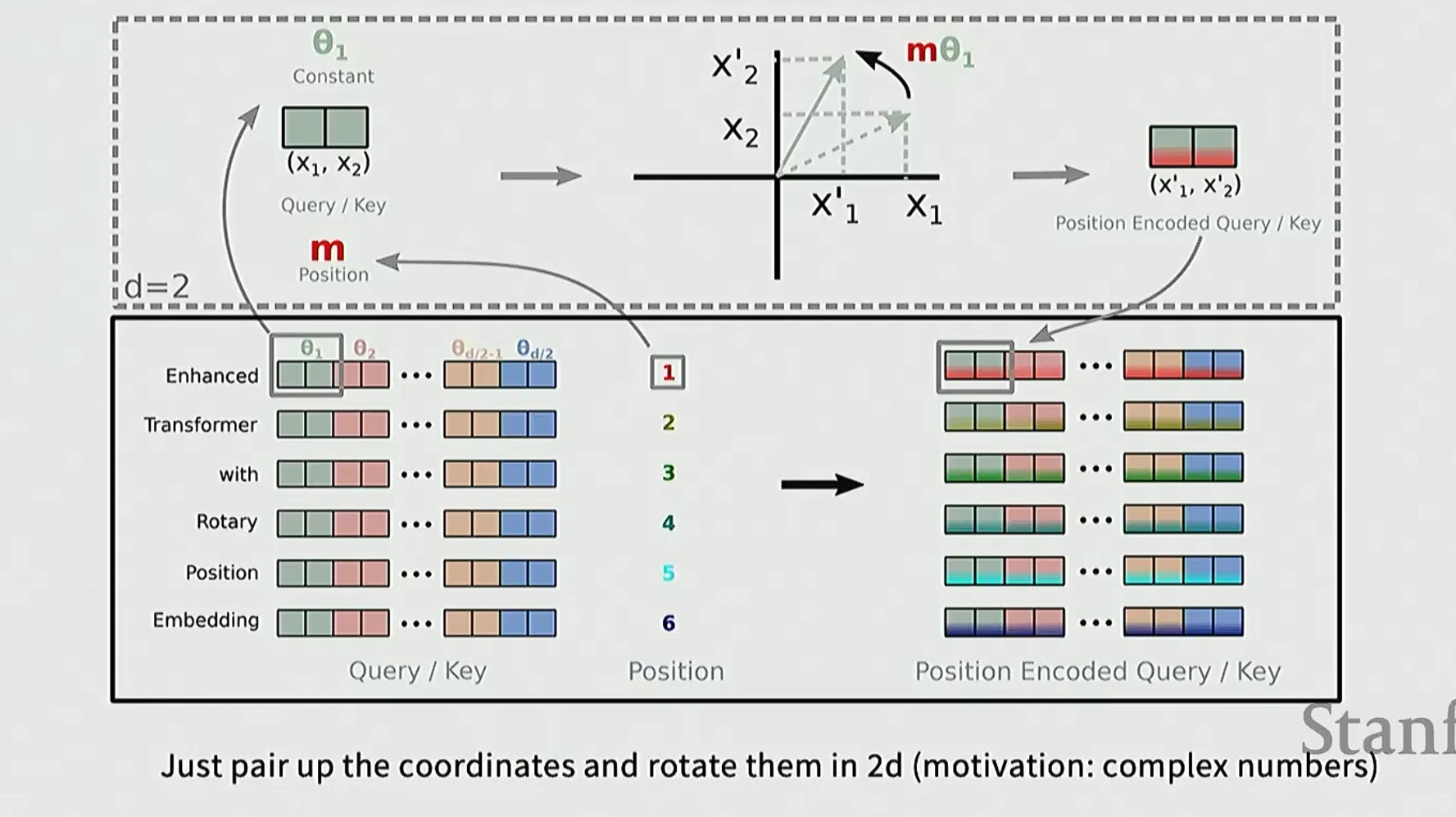
数学原理:不过是与各种正弦余弦旋转矩阵相乘而已

RoPE 中,正弦余弦嵌入是在自注意力层中发挥作用,而不是在底部添加位置嵌入
普通的位置编码是在输入嵌入后一次性添加的,而 RoPE 在每次计算注意力 Query/Key 时,都执行旋转操作,这样能让模型处理序列时,始终保持对"相对位置"的敏感性,同时保持位置不变性

Hyperparameters
FFN
前馈神经网络层(含偏置):两个关键超参数,一个是 ,表示输入 x 的维度(MLP 的输入维度),一个是
,表示隐藏层维度(MLP 输入层的隐藏维度),最终会投影回
维度
维度变化: ->
->
通常取值: =
*
例外1:GLU 变体需要缩放 2/3, =
*
(目的是保持参数量基本不变)
例外2:T5 模型大胆采用了 64 倍的比例,在这种情况下也能工作,但是 T5 v1.1 又改回了 2.5 倍
Multi-head self-attention
Transformer 的多头注意力把 拆分为若干头,每个头的维度是
,头数是
理论上这两者乘积不一定要相等,但是实践中都遵循 *
=
规则

比如 GPT3 头数为 96,每个头维度为 128,相乘结果就等于模型维度 12288
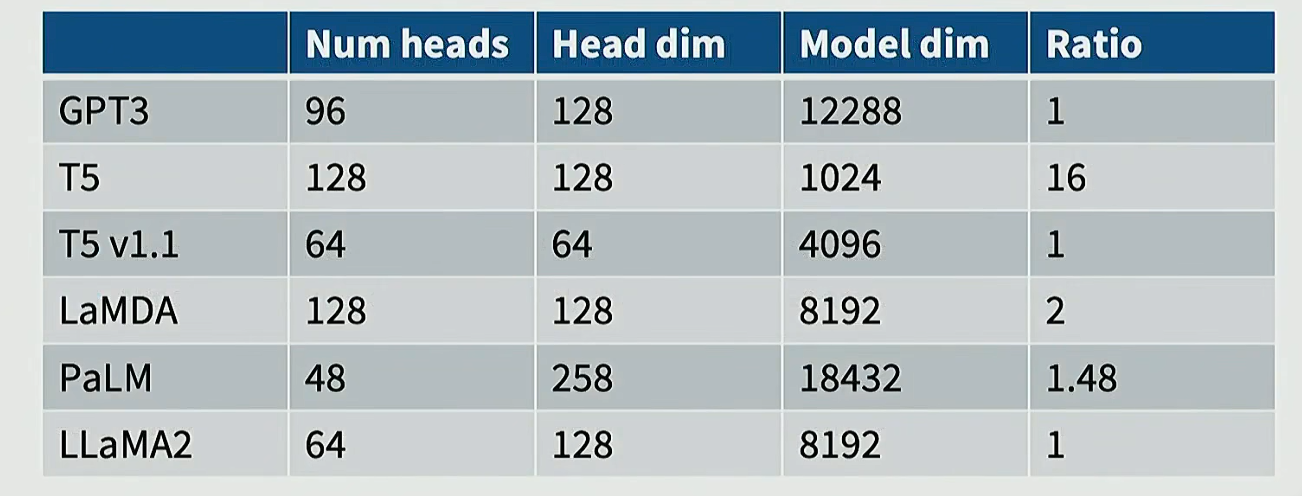
Aspect ratios
核心问题:是选择每一层的隐藏维度大(),还是选择层数多(
)
层数多,理论上表达力更强,但是在分布式训练和推理时难以运行,存在高延迟
层数少,而维度过大的模型容易出现训练不稳定,梯度难以传播
业内普遍将每层 128 个隐藏维度作为最佳选择
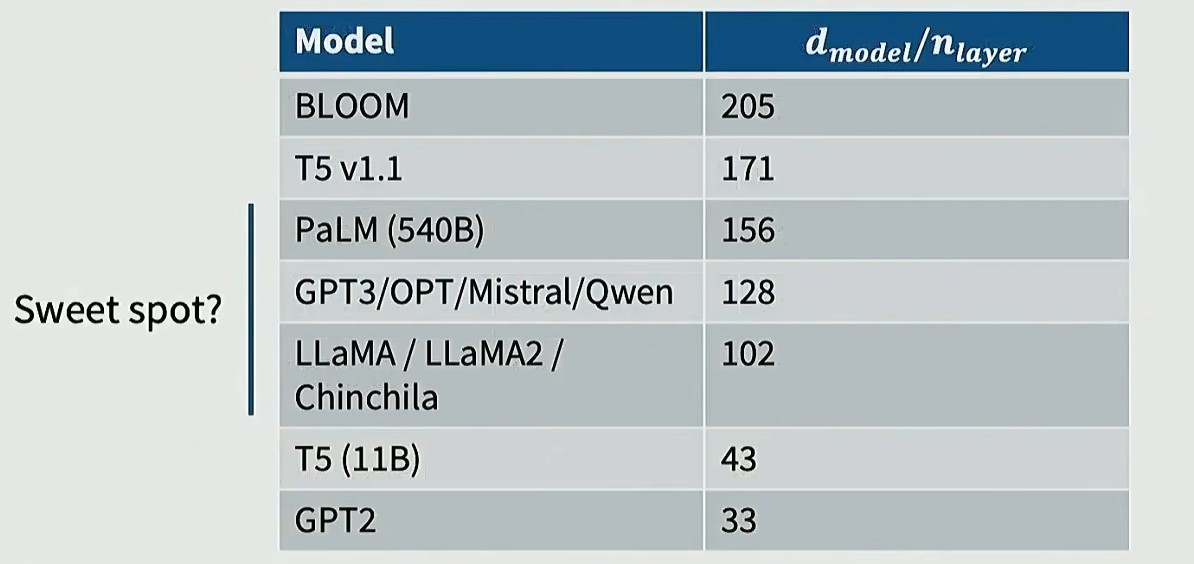
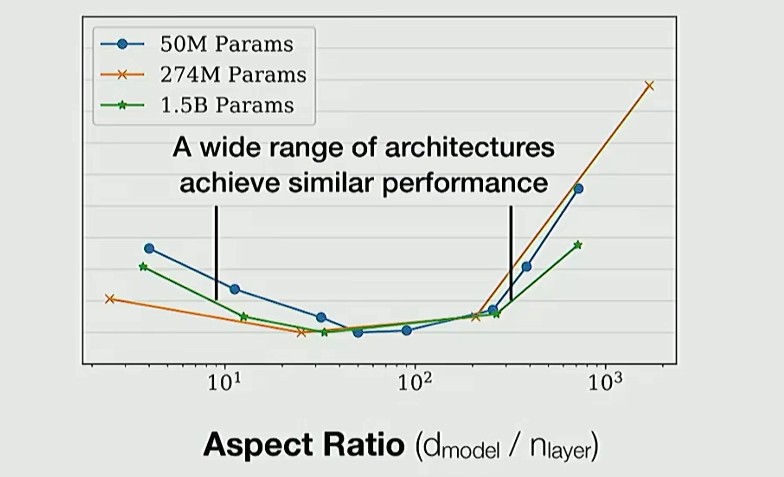
实验结果可以看出(纵轴是 loss),最优区间就在100 - 200 之间:
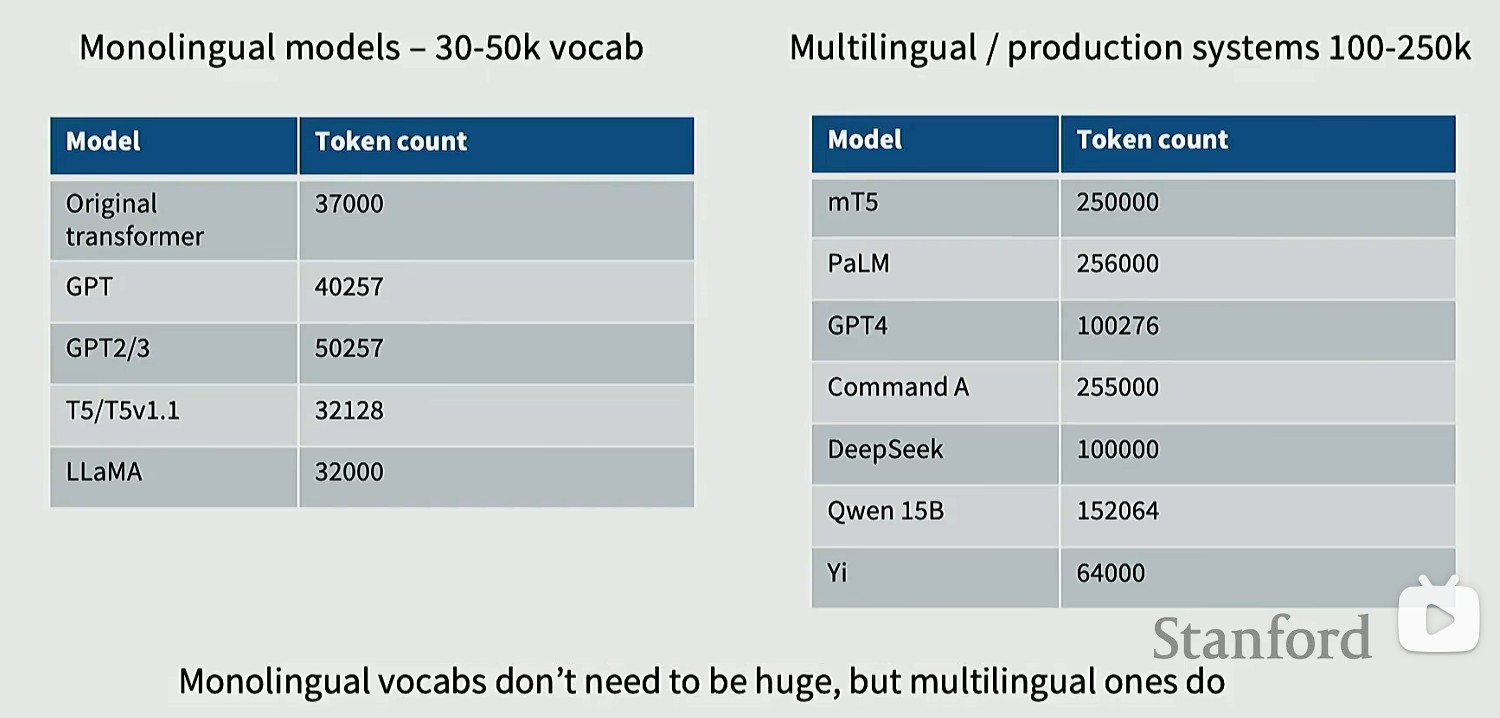
Vocabulary sizes
单语言模型:25-50K
多语言模型:100-250K
Regularization
Dropout 和其他正则化方法:通过在损失函数中加入惩罚项,限制模型参数复杂度,让模型优先学习数据的通用规律而非噪声,提升泛化能力,避免过拟合
预训练不需要正则化,因为只有一轮 epoch(数据量太大了),这种情况基本不会出现过拟合
Dropout 已经有点过时了,但是 Weight decay (权重 w 衰减,防止参数变大)确实是很多人仍在持续使用的方法
如今正则化的作用并非"防止过拟合",而是通过优化训练损失函数值来提升性能(稳定优化轨迹)
图 1 表示 Weight decay 并没有控制模型过拟合,图 2 和图 3 表示用 Weight decay 训练的模型会出现隐式加速(训练初期蓝线 loss 比红线高,但是训练末期 loss 更低,有助于模型稳定性)
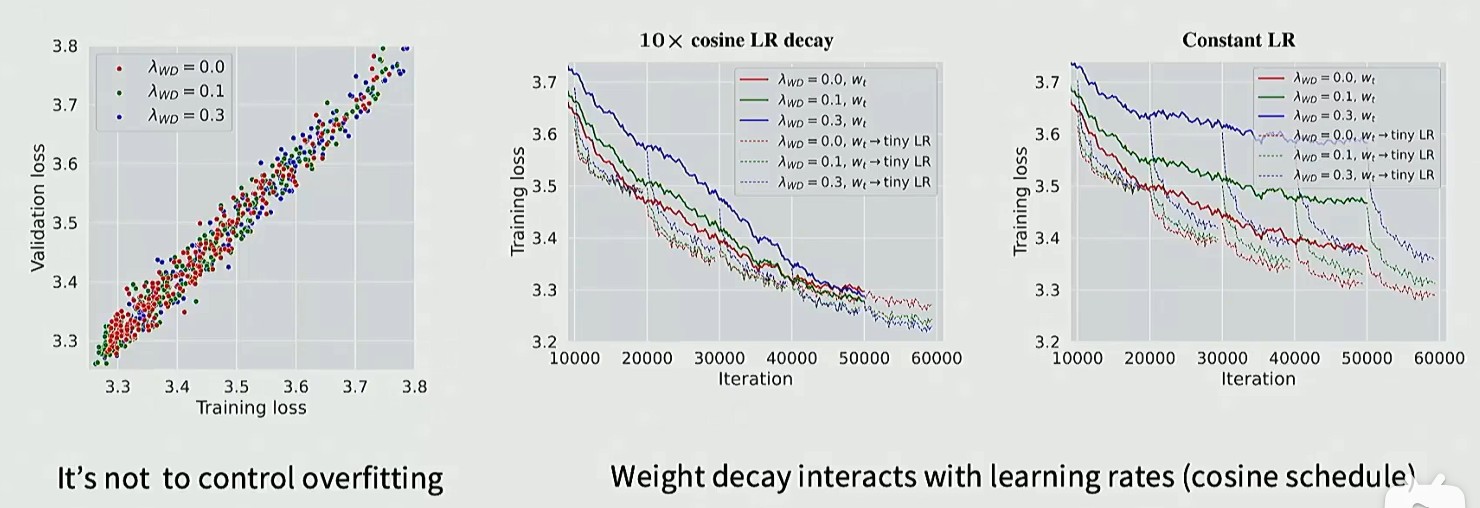
Stability tricks
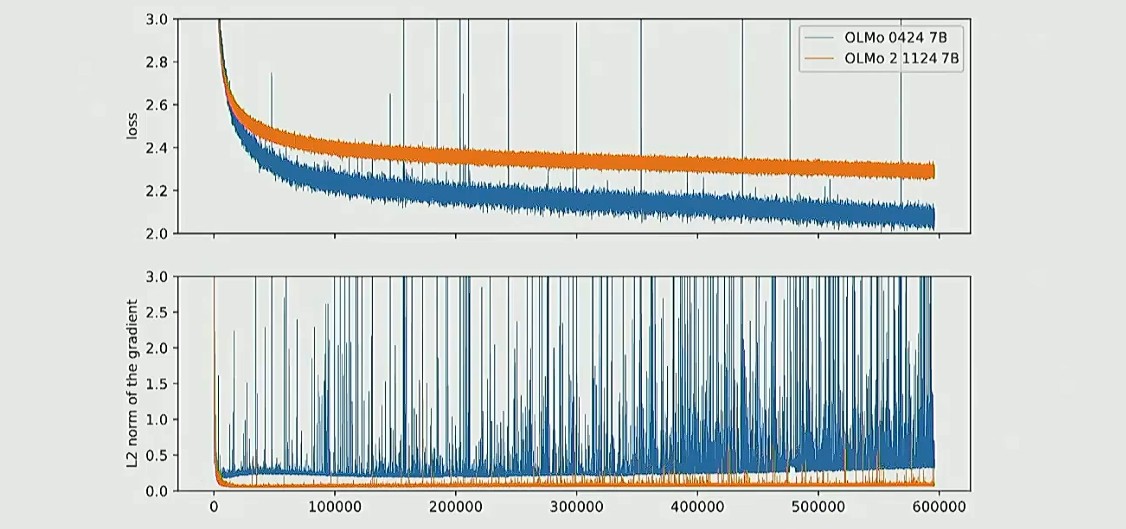
训练稳定性:模型规模越大,越容易在训练中翻车,表项为 loss 曲线突然爆炸,梯度不可控
图 1 为 loss 曲线,图 2 为梯度曲线
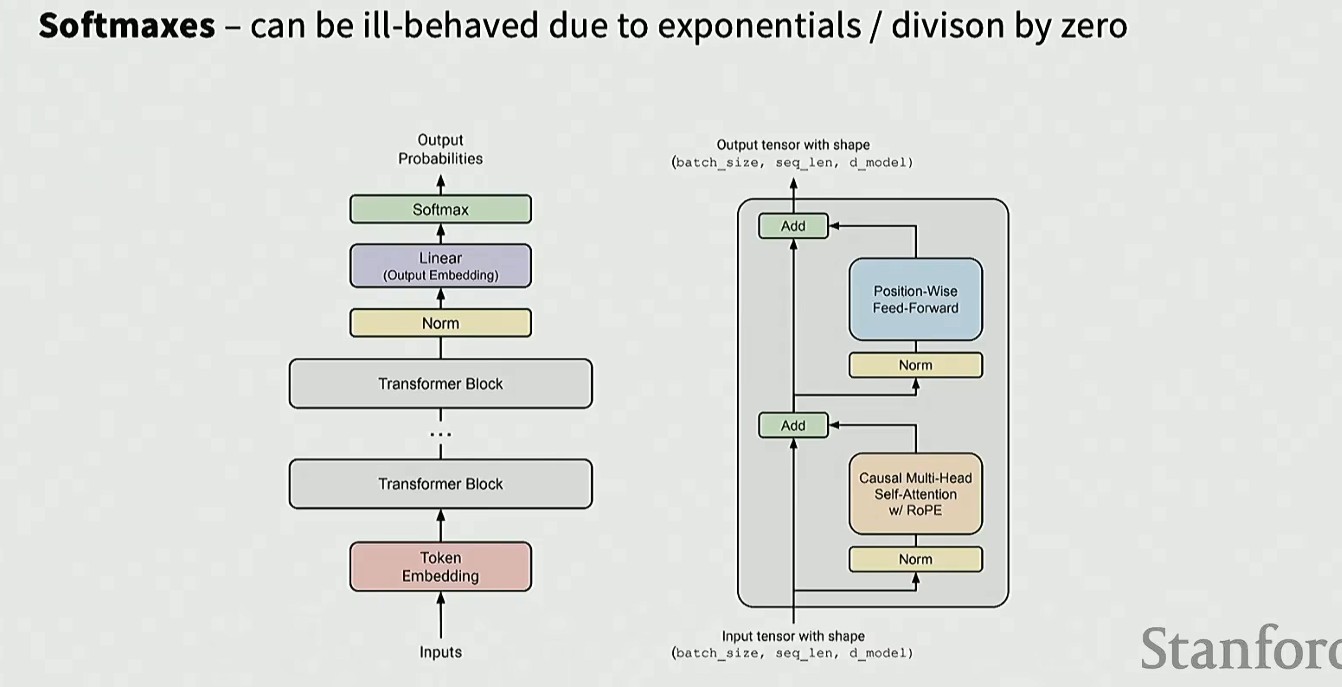
这种情况通常来源于 Softmax,其中包含了指数运算,容易出现数值不稳定,并且还有除法运算,可能除零错误(存在于模型输出端,以及注意力机制中)
Z-loss
对于输出端的 Softmax,,
,引入一个辅助损失项
,此时
要让 Loss 最小,就是让 log(Z(x)) = 0,即 Z(x) = 1,这样 ,这种运算具有很好的数值稳定性

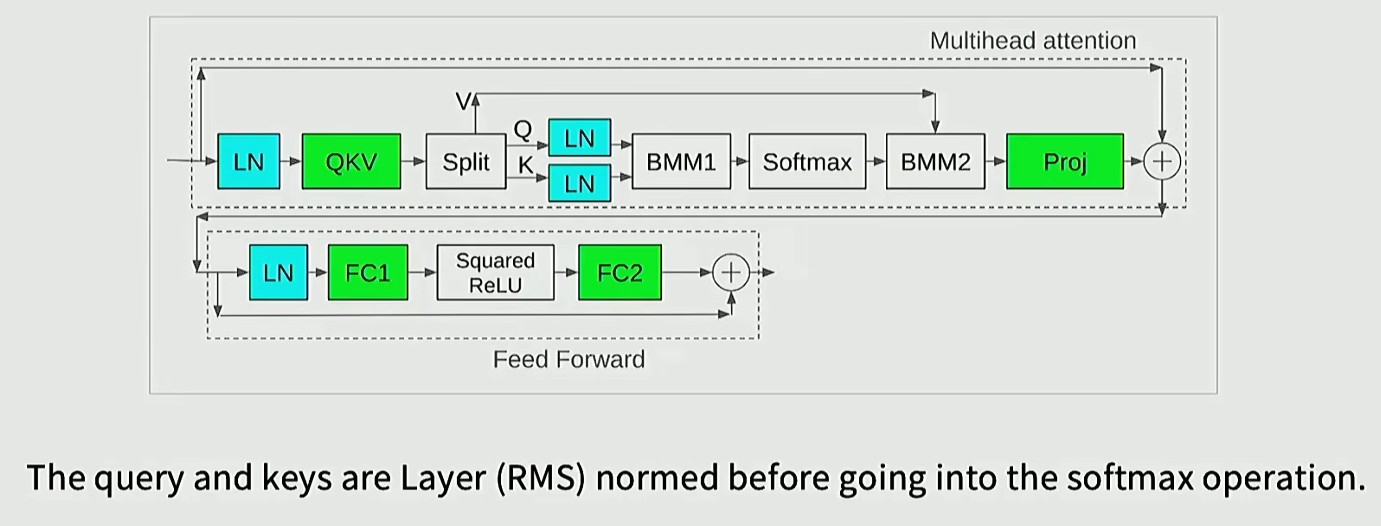
QK norm
先提取 Q、K 向量,然后经过层归一化处理,在 Softmax 前求取内积,这种方法不直接调节归一化参数 Z,而是通过约束 Softmax 的输入参数,将其数值范围限制在一定区间内。从而自动实现调控效果
在稳定性干预方面,层归一化的效果十分显著,从放在区块部分之前,到输出端,再到 QK 分量中
Logit soft-capping
对 logits 做软截断:用 tanh 把 logits 压缩到 -1,1 区间,防止梯度爆炸,但副作用是削弱模型的表达力(不推荐使用)

Reducing attention head cost
KV Cache
自回归大模型:每次根据已知的 token 预测下一个 token
如果要生成一个长度 1000 的 token 序列,当我们生成第 1000 个 token 的时候,第一个 token 的 K 和 V 已经计算了 999 次,第二个计算了 998 次,这造成了巨大的计算浪费
解决方法:把计算好的 K 和 V 缓存起来,以供后续调用,这就是 KV Cache
为什么不缓存 Q:因为 Q 没有被重复计算,每次只算当前的最后一个已知 token 的 Q
MQA
大模型要用 GPU,但是 GPU 每张卡的显存有限,如果 KV Cache 就用完了,我们就无法存放模型参数和前向函数的激活值,因此要对其进行优化
既然重复计算了很多 KV,那么直接让所有的注意力头都共用一套 KV,理论上 KV Cache 减少到原来的
GQA
本质上就是把 MHA 和 MQA 做了一个折中,将所有头分为 g 个组(g 可以整除 h),每组共用一套 KV
g = h 等价于 MHA(1 个头 1 套),g = 1 等价于 MQA(全部共用 1 套)
g 一般取 8,考虑到了推理效率,每张卡负责计算一个组内的注意力头
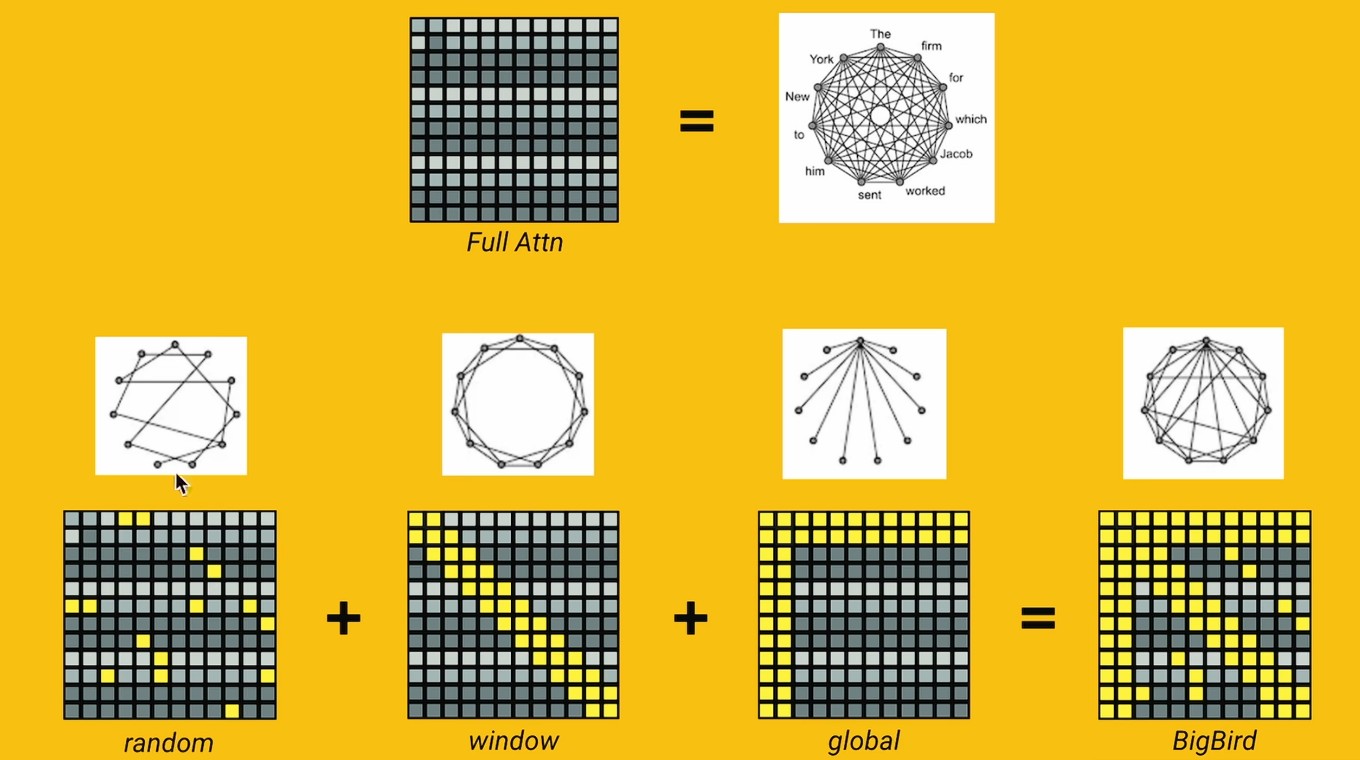
Sparse Attention
稀疏注意力:核心在于只选取注意力矩阵的一部分进行计算
随机选取 + 窗口(和临近 token 计算)+ global(起始 token 和所有 token 计算)-> 稀疏注意力矩阵
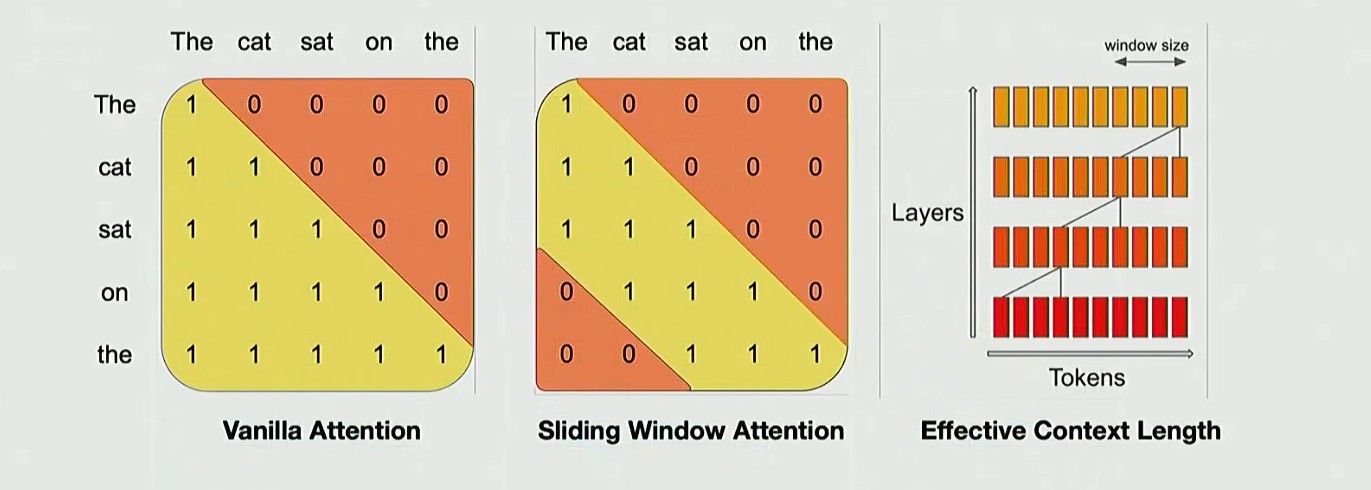
Sliding window attention
滑动窗口注意力机制(SWA):在每一层中,系统仅需处理当前位置附近的局部区域,这种方式还能控制整体所需的计算资源,从而可以处理更长上下文序列
实际有效的感受野变为局部范围乘以网络层数
Full and LR attention
现代 LLM 为了兼顾"处理长文本"和"计算效率",在注意力机制上用了一个混合技巧
核心思路:full attention 和 SWA 间隔使用
前三层使用 SWA,保证计算快、可以处理长文本,第四层使用 full attention,让模型捕捉全局信息关联
长距离信息:使用 NoPE(无位置编码)
短距离信息:使用 RoPE + SWA,保证局部信息的精准捕捉
