本文较长,建议点赞收藏。更多AI大模型应用开发学习视频及资料,在智泊AI。

大模型(如GPT-4、Llama、文心一言等)的研发是一个极其复杂、耗资巨大的系统工程,涉及多个学科领域。其核心研发流程可以概括为以下几个关键阶段:
- 设计与规划 (
Design & Planning) - 数据准备 (
Data Preparation) - 模型训练 (
Model Training) - 评估与迭代 (
Evaluation & Iteration) - 部署与服务 (
Deployment & Serving) - 持续学习与维护 (
Continuous Learning & Maintenance)
一、设计与规划 (Design & Planning)
这是所有工作的起点,决定模型的目标和能力。
- 定义目标: 要解决什么任务?(如:通用对话、代码生成、多模态理解)
- 架构选择: 目前绝大多数大模型都基于
Transformer架构(尤其是Decoder-only模型,如GPT系列)。团队会决定模型的规模(参数量)、层数、注意力头数等超参数。 - 资源评估: 评估所需的计算资源(算力)、数据资源、资金和人力资源。训练一个千亿级参数的模型可能需要数百万美元的计算成本和数月时间。
二、数据准备 (Data Preparation)
数据是大模型的"燃料",其质量和数量直接决定模型的性能上限。这个阶段通常占整个项目60%以上的时间。
1)数据收集: 从互联网、书籍、代码库、专业数据库等渠道收集海量的文本(或图像、音频)数据。数据量可达TB甚至PB级别。
2)数据清洗与预处理:
- 去重: 去除重复内容,防止模型过拟合。
- 质量过滤: 去除低质量、有害、包含敏感信息或大量错误的内容。
- 毒性过滤: 移除涉及暴力、仇恨、歧视等有毒内容。
- 隐私脱敏: 去除个人信息、隐私数据等。
3)数据标注: 对于监督微调阶段,需要人工标注或利用更高级的模型(如通过"宪法AI"方式)来生成高质量的指令-回答对数据。
三、模型训练 (Model Training)
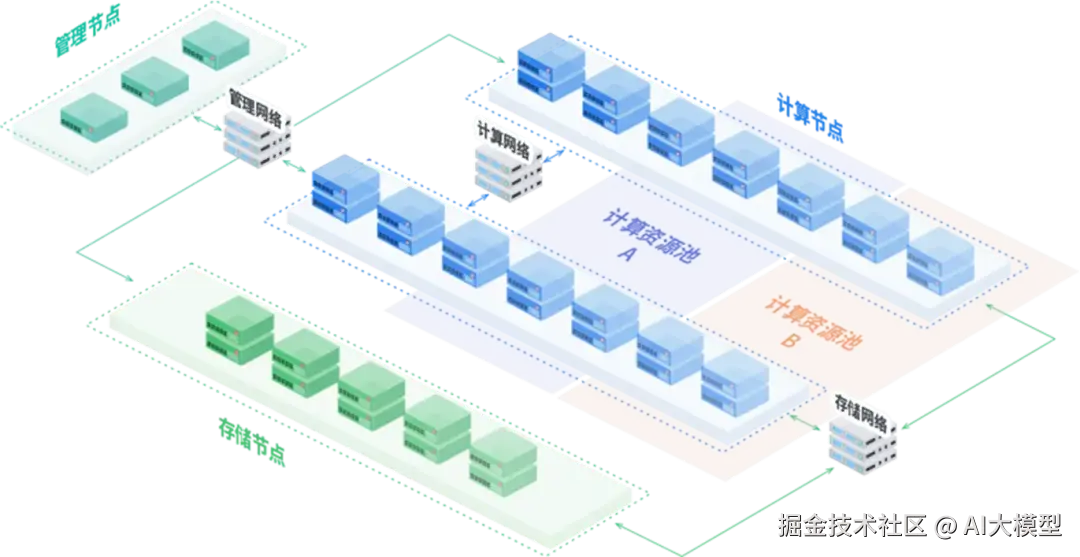
这是最核心、最耗费算力的阶段,通常需要在拥有成千上万个GPU/TPU的大型集群上完成。通常,除了GPU计算服务器之外,还涉及到集群管理节点、存储节点,以及对应的网络设施,更需要配合GPU集群管理软件完成,例如国内厂商的GPU集群软件https://cluster.aigate.cc/。训练过程通常分为多个阶段:
1)预训练 (Pre-training) - 核心阶段
- 目标: 让模型学习数据的基础统计规律和世界知识。这是一个自监督学习过程。
- 方法: 通常采用下一个令牌预测 (
Next Token Prediction) 的任务。模型被输入一段文本,并被要求预测下一个最可能出现的词(Token)。通过数十亿甚至数万亿次的预测和参数调整,模型逐渐学会了语法、句法、事实知识以及一定的推理能力。 - 耗时: 此阶段可能持续数周甚至数月。
2)有监督微调 (Supervised Fine-Tuning, SFT) - 对齐阶段1
- 目标: 让模型学会理解和遵循人类的指令。预训练模型虽然知识渊博,但可能不会以"有用、可靠"的方式回答问题。
- 方法: 使用人工标注的高质量指令数据集(如:"写一首关于春天的诗"、"用
Python实现一个排序算法"),对模型进行微调,教会它如何以对话的形式回应人类的请求。
3)奖励模型训练 (Reward Model Training) - 对齐阶段2的准备工作
- 目标: 训练一个能够评判模型回答好坏的"裁判"模型。
- 方法: 向人类标注员展示同一个问题的多个不同回答,让他们对这些回答进行排序(从好到坏)。利用这些排序数据训练一个奖励模型(
RM),这个RM学会给"好回答"打高分,给"坏回答"打低分。
4)强化学习优化 (Reinforcement Learning from Human Feedback, RLHF) - 对齐阶段2
- 目标: 根据人类的偏好进一步优化模型,使其回答更加有用、诚实、无害。
- 方法: 使用近端策略优化(
PPO) 等强化学习算法。让SFT模型针对问题生成回答,然后用奖励模型(RM)给这个回答打分。这个分数作为奖励信号,反馈给模型,指导模型参数更新,使其更倾向于生成能获得高分的回答。这是让大模型行为与人类价值观对齐的关键技术。
四、评估与迭代 (Evaluation & Iteration)
模型训练不是一蹴而就的,需要持续评估和优化。
- 评估基准: 使用一系列标准化的学术基准(如
MMLU用于测试Massive Multitask Language Understanding)来评估模型在数学、法律、编程、常识推理等各个领域的能力。 - 红队测试 (
Red Teaming): 组织内部或外部团队主动寻找模型的漏洞,例如尝试让其生成有害内容、泄露隐私信息或回答危险问题,从而针对性地进行修复。 - 迭代: 根据评估结果,返回之前的步骤(调整数据配方、修改模型架构、调整训练参数等)进行新一轮的训练,不断提升模型性能。
五、部署与服务 (Deployment & Serving)

将训练好的模型推向实际应用。
- 模型压缩: 为了降低推理成本,常对模型进行量化(降低权重精度,如从
FP32到INT8)、剪枝(移除不重要的参数)和蒸馏(用大模型训练一个小模型)。 - 高效推理: 开发高效的推理引擎(如
vLLM、TensorRT-LLM),通过连续批处理、张量并行等技术,提高服务吞吐量,降低延迟。 - 服务上线: 将模型封装成
API或集成到产品中,向用户提供服务。
六、持续学习与维护 (Continuous Learning & Maintenance)
模型上线后,工作并未结束。
- 监控: 持续监控模型的输出,处理用户反馈,发现并记录模型的新缺陷或偏见。
- 安全更新: 定期发布更新,修补安全漏洞,过滤新的有害内容。
- 版本迭代: 收集新的数据,研发能力更强、更安全的新一代模型。
七、总结
大模型的研发是一个数据、算法、算力三位一体的密集型工程:
- 数据是基础: 海量、高质量、清洗过的数据。
- 算法是核心:
Transformer架构、RLHF等关键技术。 - 算力是保障: 强大的
AI芯片(GPU/TPU)集群提供训练和推理所需的计算能力。
整个流程环环相扣,任何一个环节的不足都会直接影响最终模型的表现。
学习资源推荐
如果你想更深入地学习大模型,以下是一些非常有价值的学习资源,这些资源将帮助你从不同角度学习大模型,提升你的实践能力。
本文较长,建议点赞收藏。更多AI大模型应用开发学习视频及资料,在智泊AI。