ch01 大语言模型简介
word2vec 利用了神经网络(neural network)技术。
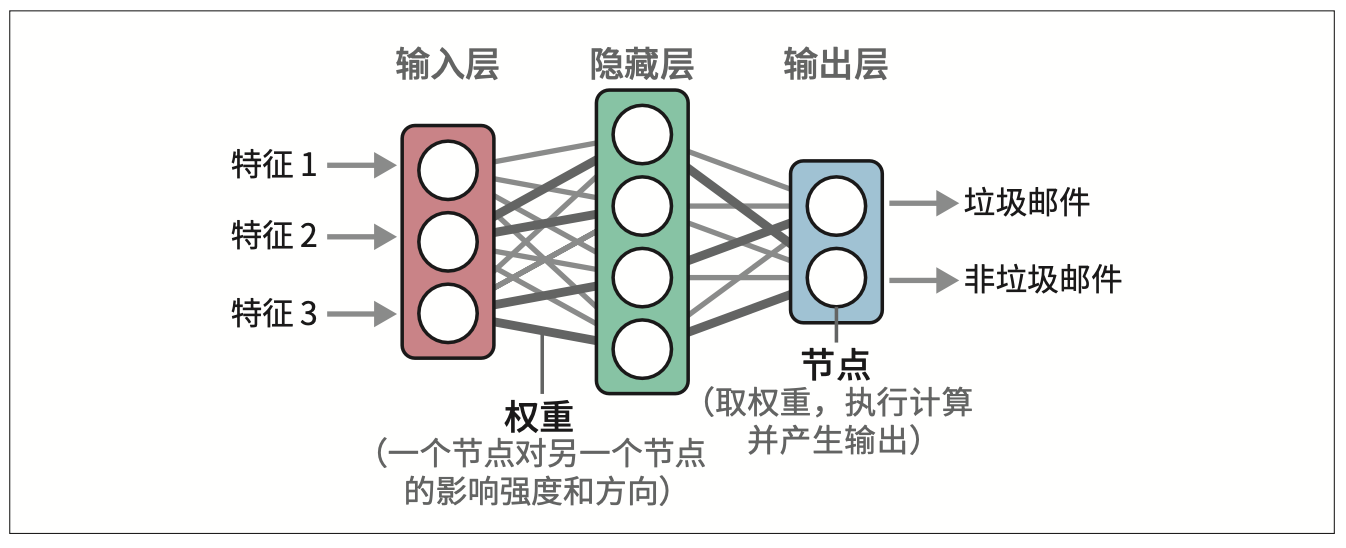
神经网络由处理信息的多层互连节点组成。神经网络可以有多个"层",每个连接都有一定的权重,这些权重通常被称为模型的参数。神经网络由互连的多层节点组层,每个连接都是一个线性方程。
词嵌入可以用多种属性来表示一个词的含义。这些属性组合在一起,是将人类语言转换为计算机语言行之有效的方式。
词嵌入使我们能够衡量两个词的语义相似度。使用各种距离度量方法, 可以判断一个词与另一个词的接近程度,含义相似的词往往会更接近。
可以为不同类型的输入创建嵌入,如词嵌入和句子嵌入,它们用于表示不同层次的抽象 (词与句子)。
RNN(recurrent neural network),循环神经网络。RNN的序列特性不利于模型训练过程中的并行化。
自回归(auto-regressive),在生成下一个词时,需要使用先前生成的词作为输入。
Transformer中的编码器块由两部分组成:自注意力(self-attention)和前馈神经网络(feed-forward neural network)。
原始的 Transformer 论文将注意力分为自注意力和交叉注意力。
- 自注意力表示解码器层在生成一个词元时,与它之前已经生成的词元序列之间的关系,以及编码器层处理的输入序列内部的关系;
- 而交叉注意力表示编码器层处理的输入序列和解码器层处理的输出序列之间的关系。
从 GPT 开始,如今的大模型几乎都采用仅解码器架构,这意味着它们只使用自注意力机制。
Transformer模型如此成功的原因,包括多头注意力(multi-head attention)、位置嵌入(positional embeddings)和层归一化(layer normalization)。
python
from transformers import AutoModelForCausalLM, AutoTokenizer
from transformers import pipeline
model = AutoModelForCausalLM.from_pretrained(
"/ssd3/models/Qwen2.5-0.5B-Instruct/",
device_map="cuda",
torch_dtype="auto",
)
tokenizer = AutoTokenizer.from_pretrained("/ssd3/models/Qwen2.5-0.5B-Instruct/")
generator = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
return_full_text=False,
max_new_tokens=10,
do_sample=False
)
messages = [
{"role": "user", "content": "Beijing is"}
]
output = generator(messages)
print(output)
"""
[{'generated_text': "As an AI language model, I don't have"}]
"""ch03 LLM的内部机制
每个Transformer块由两个组件构成:
-
自注意力层:负责整合来自其他输入词元和位置的相关信息。自注意力整合了上下文信息,使模型能够更好地捕捉语言的细微差别。
-
注意力过程分为两个主要步骤:相关性评分;信息组合。
-
在所有注意力头或一组注意力头(分组查询注意力)之间共享键矩阵和值矩阵,可以加速注意力计算。
-
Flash Attention 是一种广受欢迎的方法和实现,可以显著提升 GPU 上 Transformer LLM 的训练和推理速度。它通过优化 GPU 共享内存(GPU's shared memory,SRAM)和高带宽内存 (high bandwidth memory,HBM)之间的数据加载和迁移来加速注意力计算。
-
-
前馈神经网络:包含模型的主要处理能力。它能够存储信息,并根据训练数据进行预测和插值。
-
归一化发生在自注意力层和前 馈神经网络层之前。据称,这种方式可以减少所需的训练时间(参见论文"On Layer Normalization in the Transformer Architecture")。
-
归 一 化 的 另 一 个 改 进 是 使 用 RMSNorm,它比原始 Transformer 中使用的 LayerNorm 更简单、更高效(参见论文"Root Mean Square Layer Normalization")。
-
相比原始 Transformer 的 ReLU 激活函数,现在像 SwiGLU 这样的新变体(参见论文"GLU Variants Improve Transformer")更为常见。
ch04 文本分类
余弦相似度是两个向量夹角的余弦值,通过嵌入向量的点积除以它们长度的乘积来计算。
余弦相似度是向量间夹角的余弦值,其计算方式为嵌入向量的点积除以各自长度的乘积。