文章目录
- 一、论文信息
- 二、论文摘要
- 三、论文创新点
- 四、论文动机
- 五、方法
- 六、实验分析
-
- [6.1 实验指标:](#6.1 实验指标:)
- [6.2 实验结果](#6.2 实验结果)
-
- [6.2.1 SAR图像描述任务](#6.2.1 SAR图像描述任务)
- [6.2.2 SAR图像VQA任务](#6.2.2 SAR图像VQA任务)
- [6.2.3 SAR图像预处理实验](#6.2.3 SAR图像预处理实验)
- 七.结论
- 八.个人声明
一、论文信息
- 题目:SARLANG-1M: A Benchmark for Vision-Language Modeling in
SAR Image Understanding - 作者:Yimin Weia, Aoran Xiao, Yexian Ren, Yuting Zhu, Hongruixuan Chen, Junshi Xiab and Naoto Yokoya∗
- 单位:The University of Tokyo;RIKEN Center for Advanced Intelligence Project (AIP);Nanjing University of Information Science and Technology;Sun Yat-sen University
- 期刊:arXiv
- 代码链接:https://github.com/Jimmyxichen/SARLANG-1M?tab=readme-ov-file
二、论文摘要
合成孔径雷达(SAR)是一项关键的遥感技术,具备强地表穿透能力,可实现全天候、全天时观测,能用于精准且持续的环境监测与分析。然而,由于SAR复杂的物理成像机制,以及其视觉表现与人类感知存在显著差异,SAR图像解译仍面临诸多挑战。近年来,视觉语言模型(VLMs)在RGB图像理解领域取得了显著成效,可提供强大的开放词汇解译能力与灵活的语言交互功能。但由于其训练数据分布中缺乏SAR专属知识,这些模型在SAR图像上的应用受到严重限制,导致性能欠佳。
为解决这一局限,我们提出了SARLANG-1M------一个专为SAR图像多模态理解设计的大规模基准数据集 ,其核心目标是实现SAR与文本模态的融合。SARLANG-1M包含从全球59多个城市收集的100多万对高质量SAR图像-文本对,具备以下特点:层级化分辨率(范围为0.1至25米) 、细粒度语义描述(包括简洁型和详细型两种描述文本) 、丰富的遥感类别(1696种物体类型和16种土地覆盖类型),以及涵盖7类应用场景、1012种问题类型的多任务问答对。
针对主流视觉语言模型(VLMs)的大量实验表明,使用SARLANG-1M进行微调后,这些模型在SAR图像解译任务中的性能显著提升,达到与人类专家相当的水平。该数据集及相关代码将在以下链接公开:https://github.com/Jimmyxichen/SARLANG-1M。
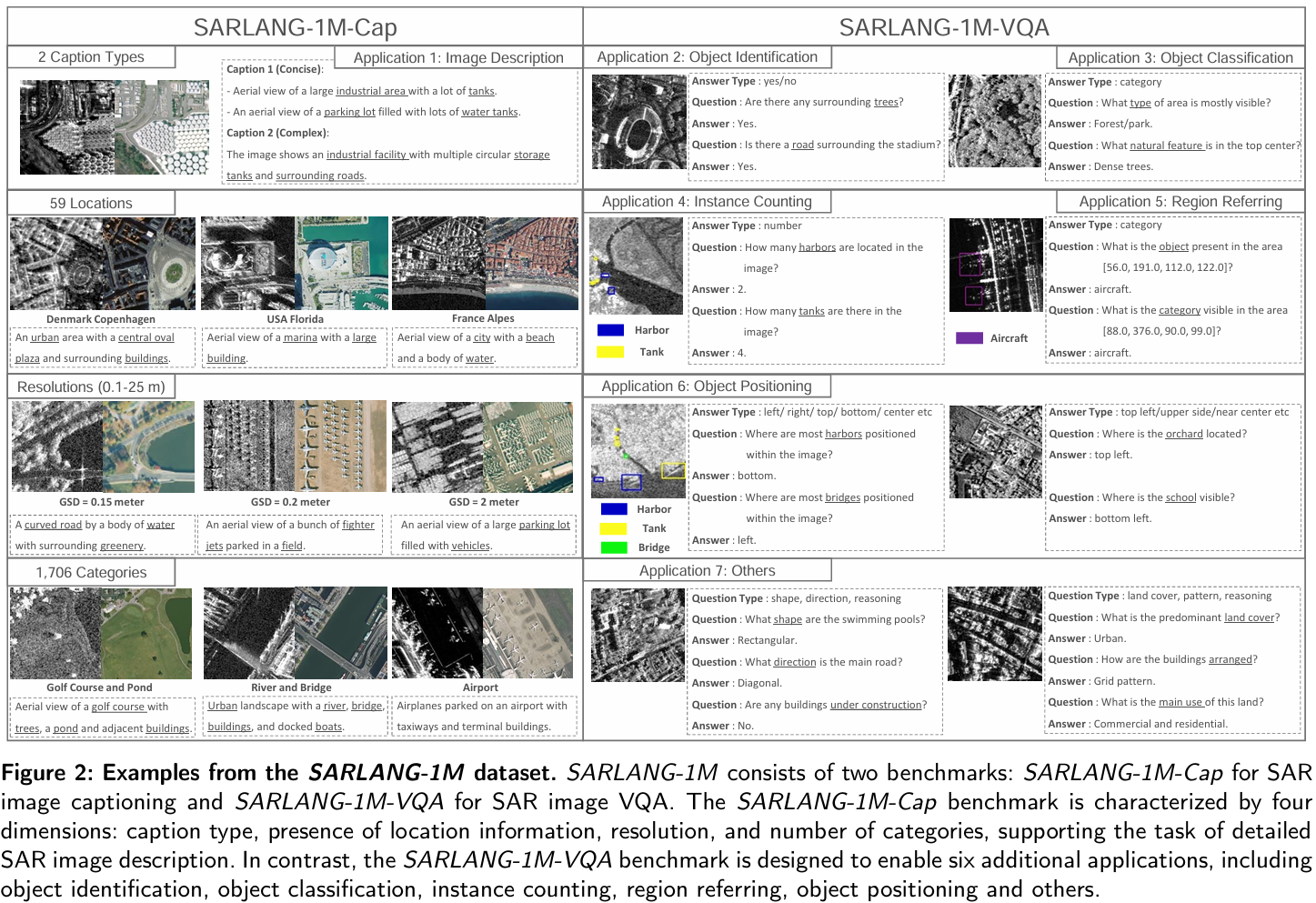
三、论文创新点
- 全面的大规模数据集:SARLANG1M包含118,331张多分辨率合成孔径雷达(SAR)图像 ,提供了1,080,627个高质量的图文对以及来自全球59多个城市的45,650条详细描述 。该数据集涵盖0.1至25米的多尺度分辨率,包含细粒度的语义描述(既有简洁描述也有详细描述)、多样的遥感类别(1,696个对象类别和16种土地覆盖类型),以及涉及1,012种问题类型的多任务问答对。
- 视觉-语言任务基准:SARLANG-1M基准包含两个关键组成部分:用于图像captioning任务的SARLANG-1M-Cap 和用于VQA任务的SARLANG1M-VQA 。作为迄今为止最大的合成孔径雷达(SAR)图像-文本数据集,它支持七个关键的遥感应用,包括图像描述、目标识别、目标分类、实例计数、区域指代和目标定位。
- 广泛的模型评估与改进:我们使用SARLANG-1M进行了全面的性能评估,对两个最先进的传统模型和十个视觉语言模型(VLMs)进行了评估 。实验结果表明在SARLANG-1M上对主流视觉语言模型进行微调,能显著提升它们在特定于合成孔径雷达的视觉语言任务上的性能,取得的结果可与人类专家媲美。
四、论文动机
- 合成孔径雷达(SAR)是关键遥感技术但解译难度高 ,主流视觉语言模型(VLMs)虽在RGB图像理解中表现优异 ,却因缺乏SAR领域训练知识难以适配SAR图像。
- 现有SAR数据集规模小、无高质量文本标注,无法支撑VLMs训练需求,因此需构建新的数据集以填补这一空白。
五、方法
1.数据集描述
-
核心任务是:SAR 图像描述(SARLANG-1M-Cap) ;SAR 图像视觉问答(SARLANG-1M-VQA)
-
VQA的主要问题是:
物体识别 :判断 SAR 图像中是否存在特定类别物体(如船舶、桥梁、机场等),或特定位置是否有目标物体,输出 "是 / 否"(Yes/No)类型答案。
物体分类 :识别 SAR 图像中主要可见的物体类别,或指定场景下的核心物体类型,输出具体类别名称(如 "飞机""港口""坦克" 等)。
实例计数 :针对指定物体类别,量化其在 SAR 图像中的出现数量,输出具体数字(如 "2""4" 等)。
区域指向 :给定 SAR 图像中具体坐标范围(如 56.0, 191.0, 112.0, 122.0),判断该局部区域内的物体类别,输出对应类别名称。
物体定位 :确定特定物体类别在 SAR 图像中的大致方位,输出 "左 / 右 / 上 / 下 / 中心" 等方位描述。
通用查询 :涵盖 SAR 遥感领域的其他常见推理任务,包括物体形状判断、方向识别、土地覆盖分类、空间格局分析、逻辑推理等,输出适配具体问题的描述性答案(如 "矩形""网格状""城市用地" 等)。
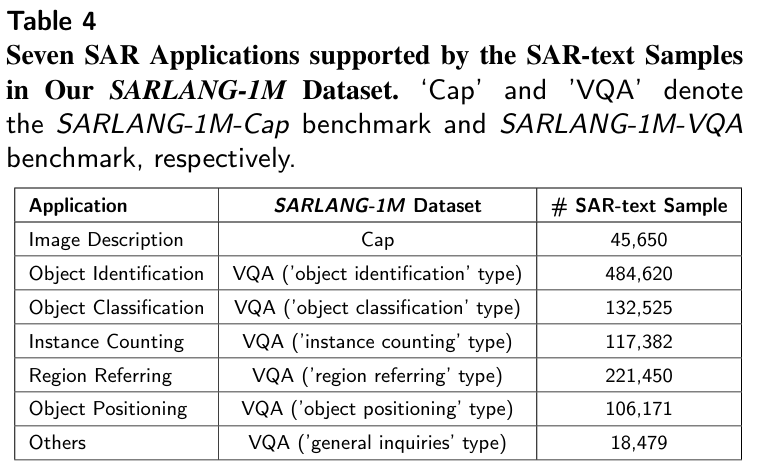
-
SARLANG-1M包含了高质量的文本描述 ,先前的SAR数据集都没有。

-
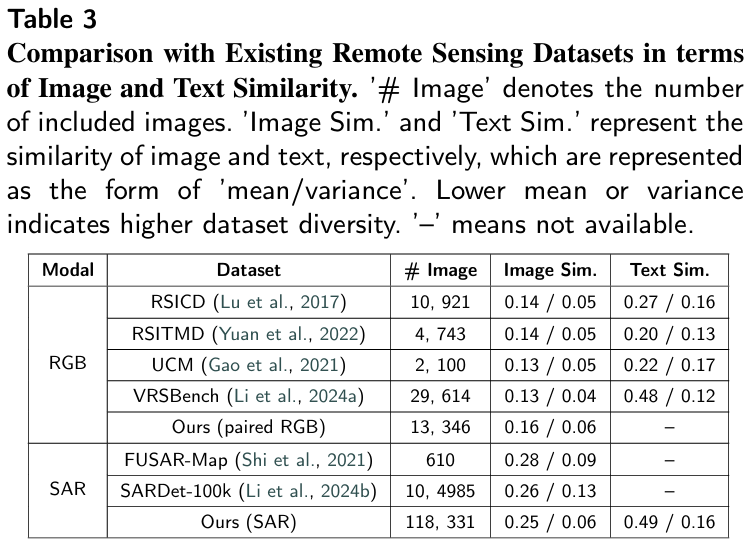
衡量数据集的整体相似度,分为图像的和文本的,分别在RGB和SAR的数据集进行对比。
2.数据集构建
SARLANG-1M数据中的SAR图像没有额外获取新的图像,是对原有的四个公开数据集的SAR图像进行了处理。
2.1 对SAR图像进行预处理:
论文中预处理操作分两种情况,核心是"是否已完成基础处理":
- 针对SARDet-100k数据集:无需额外预处理,直接复用原始数据(该数据集已自带去噪、裁剪为512×512像素块的操作)。
- 针对SpaceNet6、DFC2023、OpenEarthMap-SAR数据集:需执行"三步骤标准化处理",解决这类数据的低对比度、高噪声问题。
1. 单通道极化选择:统一图像格式
- 操作:从SAR图像的多极化(HH、VV、HV、VH)中选择一个波段作为单通道图像。
- 目的:避免多极化数据的冗余和格式混乱,降低VLM处理难度,保证数据集一致性。
- 细节:单极化数据选HH/VV(同极化),因这类极化信号强、目标轮廓清晰,适配论文中"人造目标识别"的核心任务。
| 极化方式 | 极化类型 | 核心特点 | 信号强度 | 典型应用场景 |
|---|---|---|---|---|
| HH | 同极化(发射=接收方向) | 相干性好、稳定性高,受地表粗糙度影响小,物体结构轮廓清晰 | 强 | 人造目标识别(桥梁、港口、坦克、飞机)、裸地边界提取、水面轮廓监测 |
| VV | 同极化(发射=接收方向) | 穿透性略优,对大面积均匀场景的一致性表现好 | 强 | 海洋波浪观测、冰层监测、城市密集区结构分析、农田边界识别 |
| HV | 交叉极化(发射≠接收方向) | 对物体粗糙度、湿度、介电特性敏感,不同地物区分度高 | 弱 | 植被类型区分(森林vs农田)、土壤湿度反演、植被覆盖下目标探测 |
| VH | 交叉极化(发射≠接收方向) | 与HV原理一致,对地表细微差异敏感,抗干扰性略优于HV | 弱 | 隐蔽目标探测、湿地分类、农作物长势监测 |
2. 去噪处理:消除斑点噪声
- 操作:采用精炼Lee滤波(Refined Lee Filter) 对单通道图像去噪。
- 目的:SAR图像天生存在"乘性斑点噪声"(类似图像上的颗粒感),会模糊目标轮廓,去噪后能提升图像清晰度。
- 原理:精炼Lee滤波是SAR领域专用去噪方法,能在保留目标边缘细节的同时,抑制噪声干扰(比普通滤波更适配SAR图像特性)。
3. 对比度拉伸:突出关键目标
- 操作:先对图像做对数变换 ,再执行线性拉伸。
- 目的:解决SAR图像"整体偏暗、目标与背景对比度低"的问题,让桥梁、港口、飞机等关键目标更突出,便于VLM识别。
- 原理:对数变换能压缩图像的亮度动态范围,线性拉伸则将图像灰度值映射到更合理的区间,增强目标与背景的差异。

2.2 文本标注生成
-
针对 SARLANG-1M-Cap 基准,我们采用模态迁移法 :先为配对的 RGB 图像生成文本描述 ,再将其与对应的 SAR 图像对齐 。由于配对的 RGB 图像与 SAR 图像描绘的是相同内容,这种方法能够实现语义信息从技术成熟的 RGB 领域向 SAR 领域的迁移。
- 具体而言,为生成丰富、高质量的描述文本,我们借助三种具有代表性的视觉语言模型(VLMs),基于配对的 RGB-SAR 图像开展工作:
- BLIP:以 ViT-Large/16为骨干网络,在 1400 万张图像上完成预训练,训练数据包括 COCO、Visual Genome等两个人工标注数据集,以及 Conceptual Captions、Conceptual 12M、SBU Captions等三个网络规模数据集。
- CLIP:先在大规模 LAION-2B 数据集上预训练,再在 MSCOCO数据集上微调,非常适用于开放域视觉语言理解任务。
- GPT-4o:一款最先进的多模态模型,凭借其先进的语言建模能力,能够生成贴合上下文且细节丰富的图像描述。
- 具体而言,为生成丰富、高质量的描述文本,我们借助三种具有代表性的视觉语言模型(VLMs),基于配对的 RGB-SAR 图像开展工作:
-
针对 SARLANG-1M-VQA 基准(该任务聚焦细粒度 SAR 图像理解,核心包含目标定位与指代等任务),我们直接基于现有 SAR 数据集中的边界框标注生成文本描述。这一过程构建了全新的文本语料库,专门作为 SAR 视觉问答任务的标注资源。
- 具体而言,为生成高质量的文本标注(需对 SAR 图像中可见物体进行精准量化和坐标标定),我们构建了全新的文本语料库,定义了五种主要的问题模板及对应的答案形式:
- 物体识别(Object Identification):旨在判断图像中是否存在 "船舶""坦克""飞机""桥梁""汽车""港口" 等特定物体,答案为 "是 / 否"(Yes/No)。(看边界框标注是否有这类)
- 物体分类(Object Classification):旨在识别 SAR 图像中占主导地位的物体类别,答案从 "船舶""坦克""飞机""桥梁""汽车""港口" 这一集合中选取。(看边界框标注的类别)
- 实例计数(Instance Counting):旨在统计 SAR 图像中特定类别的物体数量,答案为具体数字。(看边界框标注类别相同的不同边框数量)
- 物体定位(Object Positioning):旨在确定某一类物体的大致位置,答案为 "左""右""上""下""中心" 中的一种。(看指定类别的边界框标注相较于图片的位置)
- 区域指向(Region Referring):旨在识别指定区域内的物体类别,答案从 "船舶""坦克""飞机""桥梁""汽车""港口" 这六个潜在类别中选取。(看在指定范围内的边界框标注框的类别)
- 为进一步丰富问答模式,并突破 SAR 目标检测数据集中物体类别的限制、拓展遥感类别范围,我们采用了类似的模态迁移法生成视觉问答标注 。向 GPT-4o模型输入多种提示词,生成了大量多样化的问答对,提升了文本的解读深度 。除了丰富语料库中五种已定义问题类型的文本标注外,其余视觉问答标签构成了 "通用查询" 类问题。这类问题涵盖了土地覆盖分类、推理判断、物体形状预测等新型遥感应用场景。
- 具体而言,为生成高质量的文本标注(需对 SAR 图像中可见物体进行精准量化和坐标标定),我们构建了全新的文本语料库,定义了五种主要的问题模板及对应的答案形式:
2.3 . 质量控制
尽管自动化文本生成流程为 SAR 图像标注提供了可扩展的解决方案,但仍存在局限性:一方面,SAR 图像本身不包含颜色信息,若直接沿用从配对 RGB 图像中生成的含颜色属性描述,会导致标注与 SAR 图像不匹配 ;另一方面,当前视觉语言模型对遥感 RGB 图像的理解能力有限,生成的文本标注并非完全准确,将其迁移至 SAR 图像时可能出现错误。
为确保 SARLANG-1M 数据集中文本标注的高质量,我们由领域专家开展了严格的人工审核与筛选工作,识别并修正不准确、不一致或不相关的描述。
六、实验分析
6.1 实验指标:
实验中采用的指标均为视觉语言领域的标准化指标,且针对SAR多模态场景做了适配,核心分为SAR图像描述任务指标 和SAR图像VQA任务指标两类,共4个关键指标,详细拆解如下:
-
SAR图像描述任务指标(3个)
核心作用:衡量模型生成的SAR图像描述文本(简洁/复杂caption)与真实标签的匹配度、连贯性和语义准确性,分数越高表示生成文本质量越好。
-
BLEU(Bilingual Evaluation Understudy)
- 核心定义 :基于"n-gram精确率"的评估指标,聚焦生成文本与真实标签的词汇重叠度。
- 计算逻辑 :
- n-gram指连续的n个单词(论文中明确采用1-gram至4-gram,即单个词、双词、三词、四词组合)。
- 统计生成文本中与真实标签匹配的n-gram数量,除以生成文本的总n-gram数量,得到精确率;最终分数为1-4 gram精确率的加权平均值。
- 分数解读:取值范围0-100(论文中以百分比形式呈现),分数越高,说明生成文本的词汇与真实标签的重叠度越高,描述越贴合图像内容。
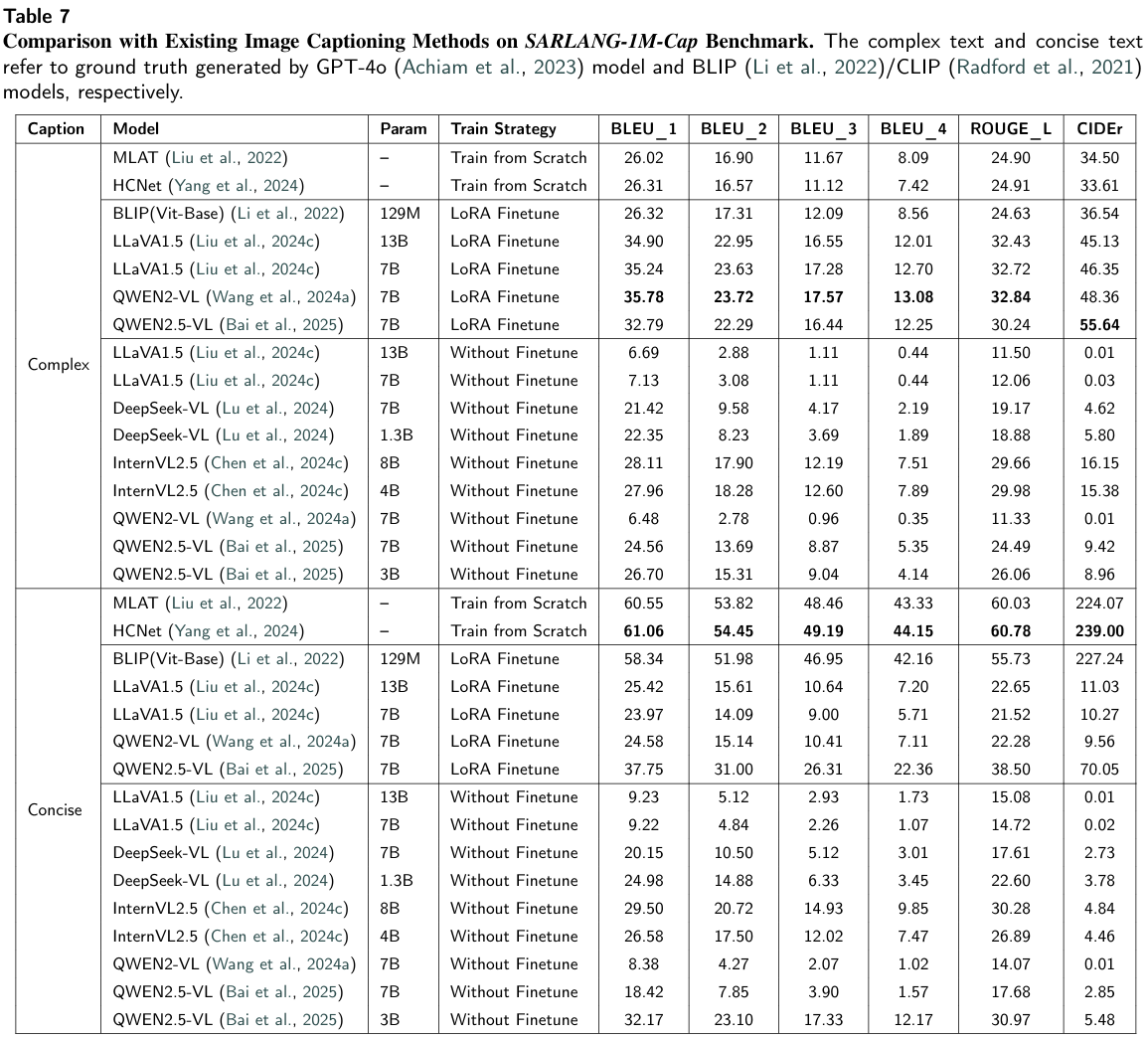
- 论文应用:用于对比不同模型(VLMs+传统模型)生成的简洁/复杂描述与真实标签的词汇匹配度,例如QWEN2-VL-7B微调后复杂描述的BLEU_1达35.78,体现词汇层面的精准性。
-
ROUGE_L(Recall-Oriented Understudy for Gisting Evaluation-L)
- 核心定义 :基于"最长公共子序列(LCS)"的评估指标,聚焦生成文本与真实标签的结构连贯性和语义关联性(而非单纯词汇重叠)。
- 计算逻辑 :
- 最长公共子序列指两个文本中不连续但顺序一致的最长单词序列(例如"工业设施 储罐"是"工业港口的圆形储罐"与"工业设施含多个储罐"的LCS)。
- 分数由LCS长度与真实标签长度的比值(召回率)和与生成文本长度的比值(精确率)调和得到。
- 分数解读:取值范围0-100,分数越高,说明生成文本的语义结构、逻辑顺序与真实标签越一致,连贯性越强。
- 论文应用:弥补BLEU仅关注词汇重叠的不足,例如HCNet模型简洁描述的ROUGE_L达60.78,说明其生成文本的结构与真实标签高度契合。
-
CIDEr(Consensus-Based Image Description Evaluation)
- 核心定义 :基于"共识"的评估指标,更贴合人类对描述质量的判断,聚焦生成文本是否捕捉到真实标签中的核心语义关键词。
- 计算逻辑 :
- 统计多个真实标签中高频出现的关键词(如SAR图像中的"储罐""港口""桥梁"),并赋予这些关键词更高权重。
- 计算生成文本中这些高权重关键词的出现频率与真实标签的匹配度,最终得到分数。
- 分数解读:取值范围0-∞(论文中数值越大越好),分数越高,说明生成文本越精准地捕捉了SAR图像的核心语义(如关键物体、场景类型),质量越优。
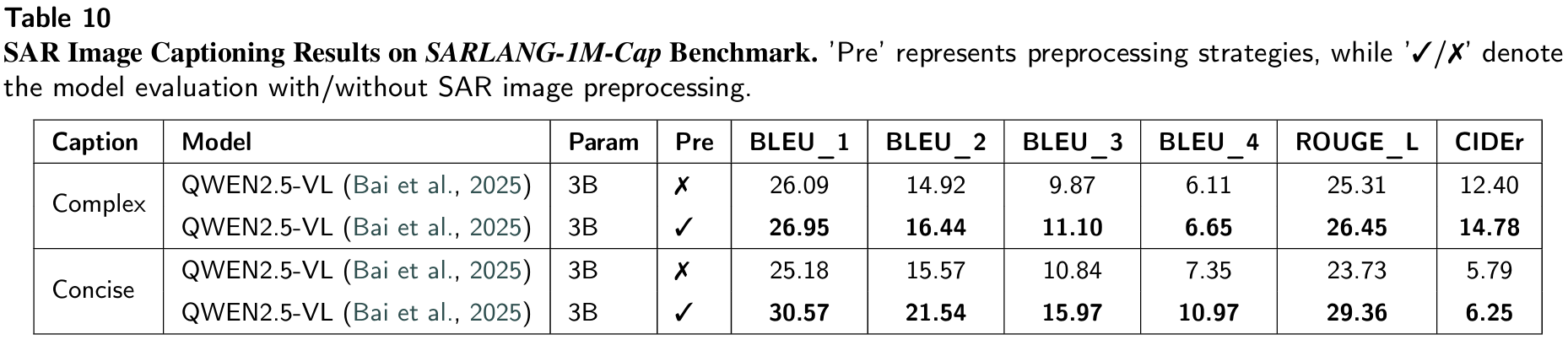
- 论文应用:是描述任务的核心指标之一,论文中提到微调后CIDEr提升67.20%,直接证明模型生成描述的核心语义精准度大幅提升。
-
-
SAR图像VQA任务指标(1个)
核心作用:衡量模型基于SAR图像回答问题的准确性,解决传统准确率"字面匹配"的局限,适配SAR领域语义理解需求。
- GPT-4基于的总体准确率(Overall Accuracy)
- 核心定义:利用GPT-4的语义理解能力,判断模型预测答案与真实标签的"语义匹配度",而非字面完全一致,是更严谨的VQA评估指标。
- 计算逻辑 :
- 输入Prompt:明确要求GPT-4基于"语义含义"判断,同义词(如"椭圆形"与"圆形")、同义表达(如"池塘"与"游泳池")均视为匹配。
- 统计结果:对所有测试集问题,GPT-4判断"匹配"记1分,"不匹配"记0分,总体准确率=匹配次数÷总问题数×100%。
- 分数解读:取值范围0-100,分数越高,说明模型对SAR图像的细节推理、语义理解能力越强,VQA性能越优。
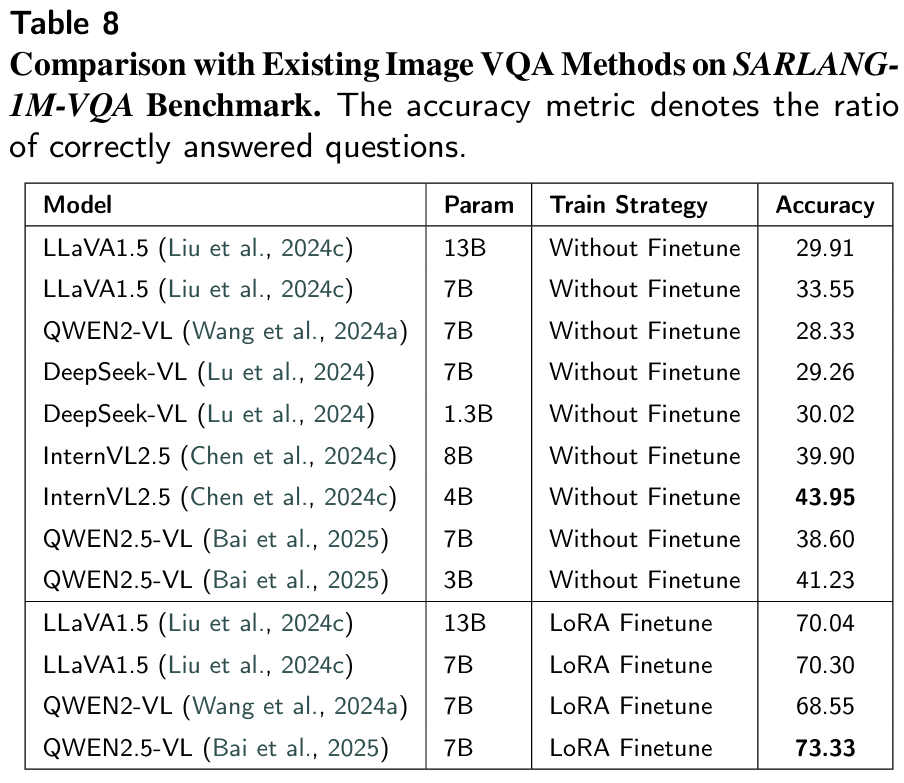
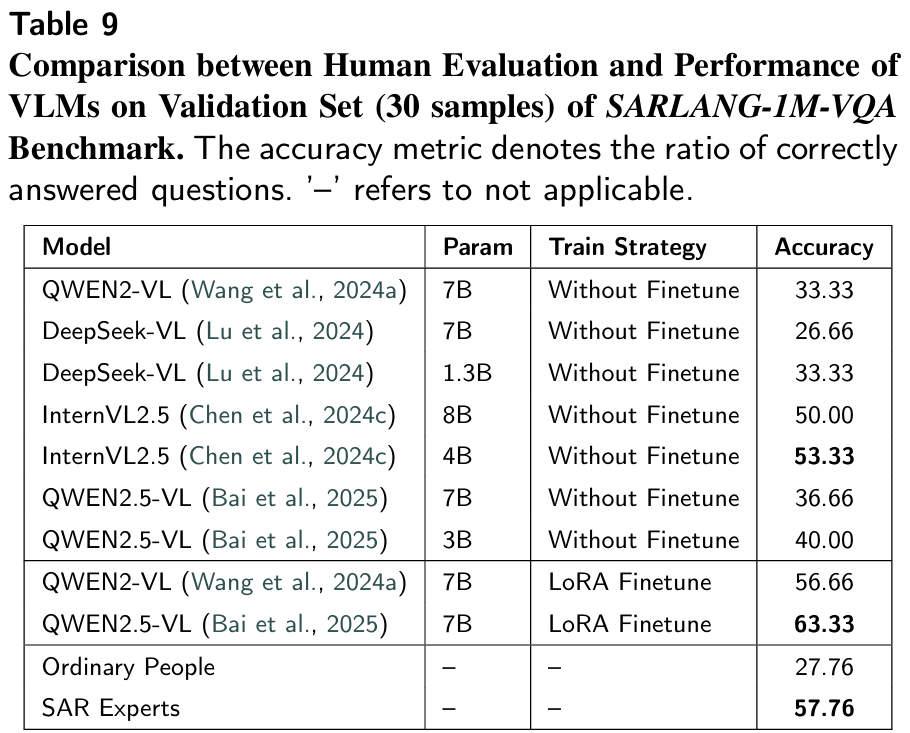
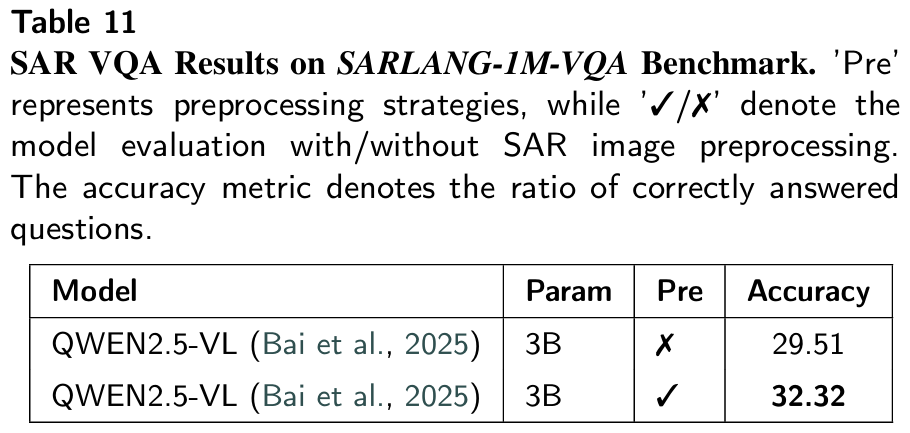
- 论文应用:是VQA任务的唯一评估指标,论文中微调后模型准确率最高达73.33%(超过SAR专家的57.76%),直接证明模型的SAR问答能力达到专家级水平。
- GPT-4基于的总体准确率(Overall Accuracy)
| 指标 | 核心优势 | 适配场景 |
|---|---|---|
| BLEU | 词汇层面匹配度,计算高效 | 快速对比文本表层一致性 |
| ROUGE_L | 语义结构连贯性,贴近文本逻辑 | 评估描述的流畅性和逻辑性 |
| CIDEr | 核心语义精准度,契合人类判断 | 衡量描述的实用价值 |
| GPT-4准确率 | 语义级匹配,避免字面误差 | SAR VQA的复杂推理评估 |
6.2 实验结果
6.2.1 SAR图像描述任务
6.2.2 SAR图像VQA任务
6.2.3 SAR图像预处理实验
七.结论
该数据集设 SARLANG-1M-Cap(图像描述)与 SARLANG-1M-VQA(视觉问答)两大基准,支持图像描述、物体识别等七大核心遥感场景。实验证实,经其微调的 VLMs,SAR 图像理解性能显著提升至人类专家水平,而本文提出的 SAR 图像预处理策略也有效增强了 VLMs 的解译能力。
八.个人声明
本文旨在分享作者对原论文的学习理解与心得体会。受限于个人知识水平和认知能力,文中对原论文的解读可能仍有不够完善之处,具体内容以原论文为准。本文仅用于学术交流与知识传播,所有内容均由作者独立整理。
如文中引用的文字、图片或其他素材在版权或相关事宜上存在争议,欢迎及时联系作者,作者将第一时间予以回复并妥善处理。