
🧔 这里是九年义务漏网鲨鱼,研究生在读,主要研究方向是人脸伪造检测,长期致力于研究多模态大模型技术;国家奖学金获得者,国家级大创项目一项,发明专利一篇,多篇论文在投,蓝桥杯国家级奖项、妈妈杯一等奖。
✍ 博客主要内容为大模型技术的学习以及相关面经,本人已得到B站、百度、唯品会等多段多模态大模型的实习offer,为了能够紧跟前沿知识,决定写一个"从零学习 RL"主题的专栏。这个专栏将记录我个人的主观学习过程,因此会存在错误,若有出错,欢迎大家在评论区帮助我指出。除此之外,博客内容也会分享一些我在本科期间的一些知识以及项目经验。
🌎 Github仓库地址:Baby Awesome Reinforcement Learning for LLMs and Agentic AI
📩 有兴趣合作的研究者可以联系我:yirongzzz@163.com
【Agentic RL 专题】二、Agentic RL------Memory
文章目录
- [【Agentic RL 专题】二、Agentic RL------Memory](#【Agentic RL 专题】二、Agentic RL——Memory)
-
- 一、前言
- 二、Memory的发展
-
- [2.1 有记忆性不一定就是Agent](#2.1 有记忆性不一定就是Agent)
- [2.2 LLM-Agent→Agentic RL](#2.2 LLM-Agent→Agentic RL)
- [2.3 Agentic RL Memory Type](#2.3 Agentic RL Memory Type)
- 三、代码实战
- 四、总结
一、前言
我们现在在大模型交互的过程中,往往会给我们一种感觉,LLM本身就已经有了记忆模块,例如我们常用的Deepseek, GPT, Gemini。
- 以
Gemini 2.5pro为例,开启一个对话框,让他记住我们的名字 - 重启一个对话框,询问模型我是谁时

-
同样的以
GPT5为例,开启一个对话框,让他记住我们的名字

-
重启一个对话框,询问模型我是谁时,

可以发现Gemini 2.5pro无法记忆多个会话的信息。相反的,尽管是不同的对话窗口,GPT5仍然可以记住我们的名字。为什么会有这样子的区别呢?这是不是就是智能体中的Memory模块呢,如果不是,那这个与agent中的Memory模块又有什么区别?带着这些问题,我们将开启智能体------Memory篇章的学习!
二、Memory的发展
2.1 有记忆性不一定就是Agent
上述过程我们可以发现,不同的模型有着不同的记忆能力,有的模型只能在单个窗口中记忆信息,有的模型可以实现跨窗口的记忆信息。这两种记忆信息有什么不同呢?
- 单个窗口记忆信息
Gemini 2.5pro
本质上只是上下文的信息,当达到上下文窗口上限时,会自动去除早期的记忆; - 多个窗口记忆信息
GPT5
✍ 它的"记忆"并不是我们现在所说的智能体上的 Memory 模块,更像是一个外部记事本,本质上是一个 外部数据库或用户画像缓存。外部缓存可以让模型"记得"一些事实,例如用户的名字或偏好,但它并不参与模型的推理或决策过程。
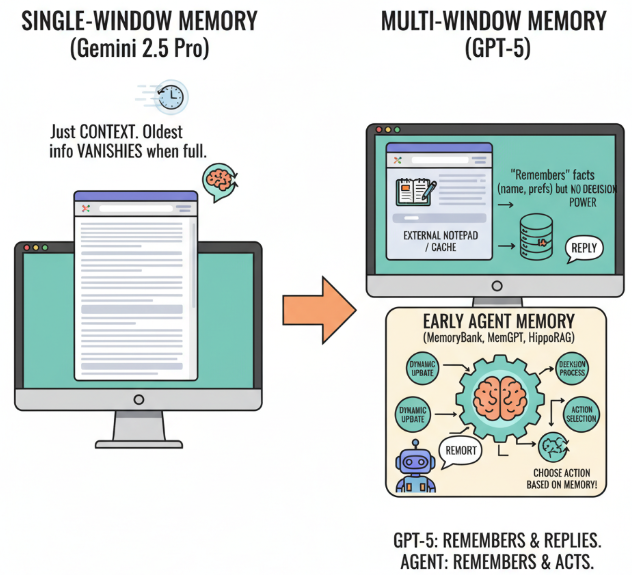
🤖 而早期的Agent中Memory模块(MemoryBank, MemGPT , and Hip-poRAG)不仅仅是记忆外部的缓存,他是参与了整个决策过程的模块。记忆的内容会被动态更新,决定记忆信息的记忆和遗忘,并且影响着Agent决策的过程。
例如智能体在做出动作选择时,会根据当前的记忆进行决策,而
GPT5只是根据记忆进行回复,不做任何的行动决策
2.2 LLM-Agent→Agentic RL
在早期Agent的Memory模块中,记忆依然可以被认为是静态的外部存储,主要是帮助语言模型在多轮交互中检索过去的信息,让模型看起来"记得住"一些上下文。
例如:MemoryBank, MemGPT , and Hip-poRAG。这些方法仍然采用了预定义的内存管理策略调用记忆,属于**RAG-style Memory。
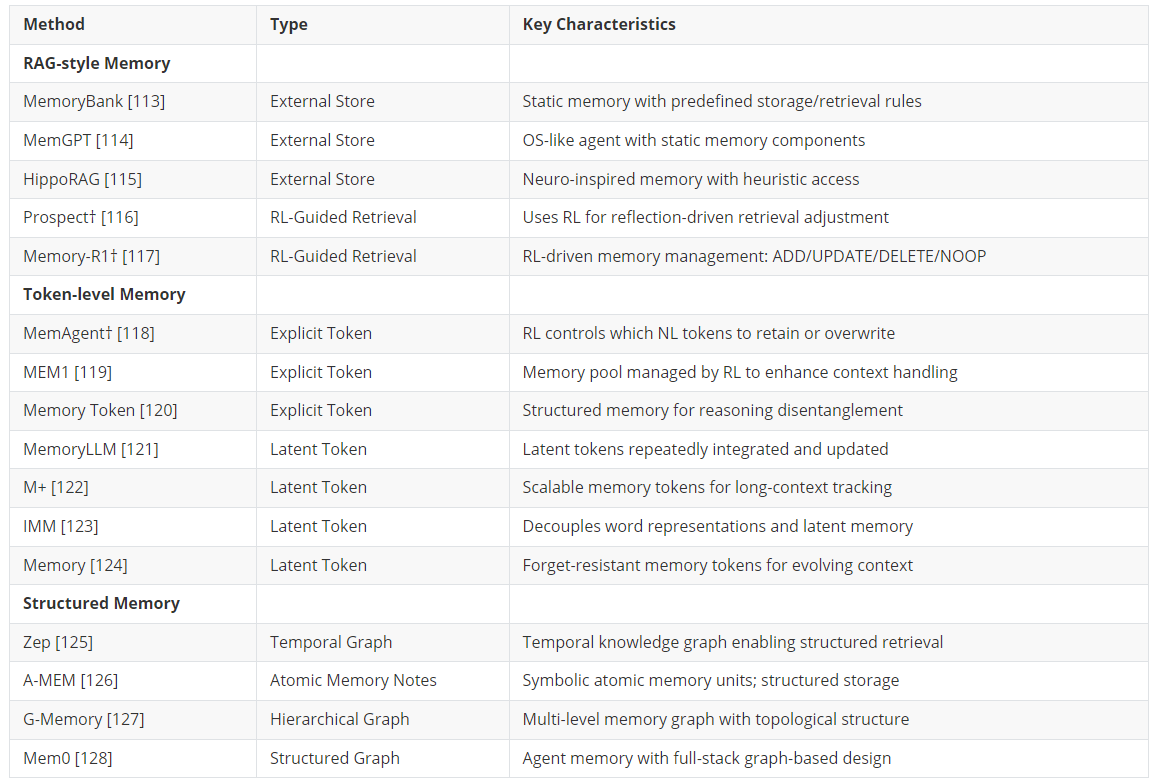
| 模块 | 类型 | 特征 | 是否使用 RL |
|---|---|---|---|
| MemoryBank (2023) | 外部存储(RAG-style) | 通过向量数据库保存会话摘要、任务结果 | ❌ 无 RL |
| MemGPT (2023) | 外部 + 系统式内存 | 模拟操作系统的"主存储+外存",LLM 主动在两者间读写 | ❌ 无 RL |
| HippoRAG (2024) | 外部神经启发记忆 | 用神经启发(Hippocampus-like)机制来组织知识图谱 | ❌ 无 RL |
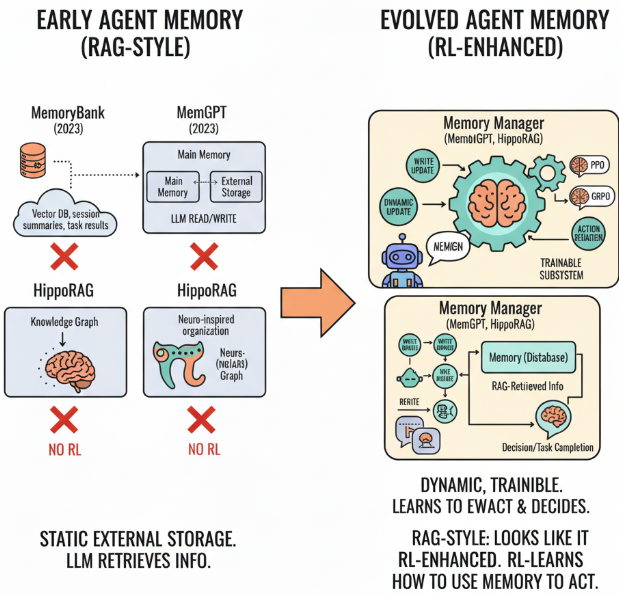
随着强化学习技术不断发展,研究者开始将强化学习的特性作为一个功能组件结合到记忆模块中,Memory模块不再只是简单的外部缓存,而是一个可训练的子系统 :通过奖励信号学习何时写入、更新、删除或保留记忆,从而更好地支持下游决策和任务完成。例如,在 Memory-R1 框架中,Memory Manager 使用PPO或GRPO来动态调整记忆操作,而 Answer Agent 则通过 Memory Distillation 对 RAG 检索到的信息进行推理和回答。
2.3 Agentic RL Memory Type
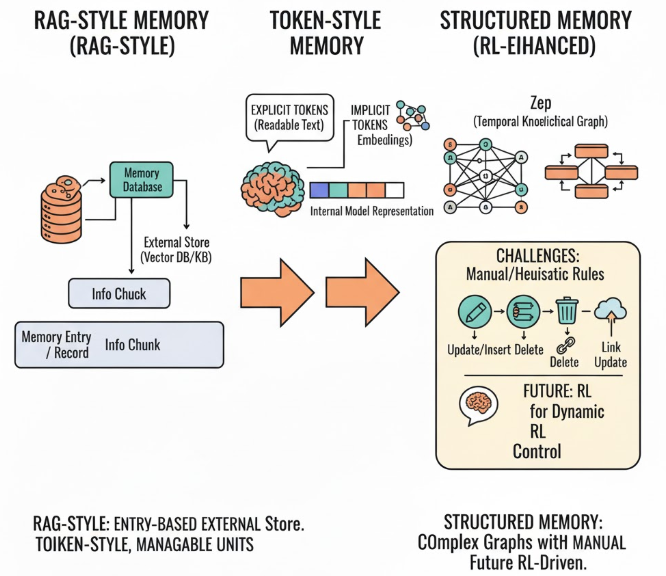
① RAG-style Memory 的记忆模块是以条目/条记录为单位(通常对应一个摘要或信息块)记忆是外部存储(external store),通常是向量数据库或知识库。随着技术的发展,开始衍生出了 Token-style Memory 和 Structured Memory 。
② Token-style Memory
智能体开始可以不通过外部记忆系统管理模型的记忆状态了,记忆直接嵌入到模型的内部表示中,每个 token 可以被单独管理。主要可以分为explicit tokens以及implicit tokens。
explicit tokens对应的是自然语言,对于我们来说是可读的;
implicit tokens对应的是隐式 embedding,不可直接读出;
③ Structured Memory
随着技术的发展,记忆模块已经超越了平面级的 token 序列,逐步转向更复杂的结构化表示。例如,Zep 引入了时序知识图谱,G-memory 则采用分层图存储器来管理信息。通过这些结构化记忆,智能体能够捕捉更为丰富的关系、时间和层次信息,从而进行更精细的推理和决策。
然而,管理这些复杂的结构化记忆依然存在挑战,尤其是在 记忆更新、插入、删除、抽象化以及链接更新 等方面。目前,这些操作主要依赖手工设计的规则或启发式方法,虽然有效,但缺乏灵活性和适应性。因此,未来的研究可以探索使用 强化学习 (RL) 来动态控制这些记忆模块的构建和调整。
三、代码实战
- RAG-STYLE MEMORY
python
import faiss
import numpy as np
from sentence_transformers import SentenceTransformer
class RAGMemoryAgent:
def __init__(self, embedding_dim=384, memory_size=100):
self.memory_size = memory_size
self.embedding_dim = embedding_dim
self.memory = [] # 外部存储的记忆
self.model = SentenceTransformer('paraphrase-MiniLM-L6-v2') # 使用预训练模型
self.index = faiss.IndexFlatL2(self.embedding_dim) # 向量检索索引
def encode(self, text):
"""将文本编码为固定维度的向量(384维)"""
vector = self.model.encode([text]) # 生成 384 维向量
return vector.astype(np.float32)
def add_to_memory(self, text):
"""将新的记忆添加到外部存储中"""
vector = self.encode(text)
self.memory.append(text)
self.index.add(vector) # 将向量添加到 FAISS 索引中
def retrieve_memory(self, query, top_k=1):
"""根据查询检索最相关的记忆"""
query_vector = self.encode(query)
D, I = self.index.search(query_vector, top_k) # 检索最相关的记忆
return [self.memory[i] for i in I[0]] # 返回检索到的记忆
# 测试 RAG-style 记忆
agent = RAGMemoryAgent(embedding_dim=384)
agent.add_to_memory("My name is Alice and I love playing chess.")
agent.add_to_memory("I enjoy hiking in the mountains during the weekend.")
agent.add_to_memory("I am learning reinforcement learning to improve my skills.")
query = "What is your name?"
retrieved_memory = agent.retrieve_memory(query)
print("Retrieved Memory:", retrieved_memory)返回:Retrieved Memory: My name is Alice and I love playing chess."
- TOKEN-STYLE MEMORY
python
import numpy as np
from sentence_transformers import SentenceTransformer
class TokenMemoryAgent:
def __init__(self, embedding_dim=128):
self.memory = [] # 存储每个 token 的记忆
self.embedding_dim = embedding_dim # 嵌入维度
self.model = SentenceTransformer('paraphrase-MiniLM-L6-v2') # 使用预训练模型
def encode(self, text):
"""将文本编码为嵌入向量"""
vector = self.model.encode([text]) # 生成向量
return vector[0] # 取第一个(单一文本的嵌入)
def add_token_memory(self, token):
"""将一个 token 存储到记忆中"""
token_embedding = self.encode(token)
self.memory.append(token_embedding)
def update_token_memory(self, token_index, new_token):
"""更新已有的 token 记忆"""
token_embedding = self.encode(new_token)
self.memory[token_index] = token_embedding
def retrieve_memory(self, query_token):
"""检索与查询 token 最相关的记忆"""
query_embedding = self.encode(query_token)
similarities = [np.dot(query_embedding, token) for token in self.memory]
best_match_index = np.argmax(similarities)
return self.memory[best_match_index]
# 测试 Token-style 记忆
agent = TokenMemoryAgent(embedding_dim=128)
agent.add_token_memory("Alice loves chess.")
agent.add_token_memory("Weekend hiking is fun.")
query = "What does Alice like?"
retrieved_memory = agent.retrieve_memory(query)
print("Retrieved Token Memory:", retrieved_memory)返回的是token embedding向量
- 加入RL训练环境
python
import numpy as np
from sentence_transformers import SentenceTransformer
from stable_baselines3 import PPO
from stable_baselines3.common.envs import DummyVecEnv
from stable_baselines3.common.callbacks import BaseCallback
class TokenMemoryManagementCallback(BaseCallback):
def __init__(self, memory_agent, verbose=0):
super().__init__(verbose)
self.memory_agent = memory_agent
def _on_step(self):
# 在每一步中,使用 RL 策略来决定是否更新/删除token
if self.training_env.get_attr("step") % 100 == 0:
action = np.random.choice(["retain", "discard", "add"])
if action == "add":
self.memory_agent.add_token("New token information")
elif action == "discard":
self.memory_agent.remove_token()
elif action == "retain":
pass
return True
class TokenMemoryAgent:
def __init__(self, embedding_dim=128):
self.memory = [] # 存储每个 token 的记忆
self.embedding_dim = embedding_dim
self.model = SentenceTransformer('paraphrase-MiniLM-L6-v2')
def encode(self, text):
"""将文本编码为嵌入向量"""
vector = self.model.encode([text])
return vector[0] # 取第一个(单一文本的嵌入)
def add_token(self, token):
"""将一个 token 存储到记忆中"""
token_embedding = self.encode(token)
self.memory.append(token_embedding)
def remove_token(self):
"""从记忆中移除一个 token"""
if self.memory:
self.memory.pop(np.random.choice(len(self.memory)))
print("Token removed.")
def retrieve_memory(self, query_token):
"""检索与查询 token 最相关的记忆"""
query_embedding = self.encode(query_token)
similarities = [np.dot(query_embedding, token) for token in self.memory]
best_match_index = np.argmax(similarities)
return self.memory[best_match_index]
# 训练环境设置
env = DummyVecEnv([lambda: gym.make('CartPole-v1')]) # 选择合适的 RL 环境
token_agent = TokenMemoryAgent()
# 使用 PPO 算法进行训练
model = PPO("MlpPolicy", env, verbose=1)
token_callback = TokenMemoryManagementCallback(token_agent)
model.learn(total_timesteps=20000, callback=token_callback)
# 测试 Token-style 记忆
query = "What should I remember?"
retrieved_memory = token_agent.retrieve_memory(query)
print("Retrieved Token Memory:", retrieved_memory)四、总结
本文详细探讨了智能体中的记忆模块(Memory Module)及其在强化学习(RL)中的应用。通过对比不同的大型语言模型(如Gemini 2.5pro和GPT-5)的记忆能力,我们明确了"记忆"这一概念的多样性,揭示了它在智能体决策过程中的核心作用。区分了不同记忆模块,对早期的上下文记忆到早期的Agent Memory 模块再到Agentic RL的Memory 模块作了详细的分析,并且对Agentic RL的Memory 模块做了三种不同风格的更细致的划分,最后通过代码实现了RAG和Token风格的记忆模块。