摘要
6 月底,GMI Cloud 技术 VP YujingQian 受邀参与了由 InfoQ 举办的 AICon 北京大会,在大会上Yujing发表了主题为《GMI Cloud Inference Engine 全球化高性能分布式推理服务构建实践》的演讲,本文是他的演讲总结。
越来越多的企业将自己的 AI 应用拓展到海外市场时,在推理服务方面遭遇诸多挑战。例如用户跨地域分布,单个集群难以平衡低时延与高覆盖,可能导致部分区域用户推理响应延迟过高;推理业务负载增加后,现有集群会因为资源弹性不足出现算力瓶颈,影响服务稳定性等。
解决这些问题需要从全球化资源调度、弹性算力管理等多个维度入手,结合对不同地区网络环境、用户需求的深度理解,构建灵活且高效的分布式推理架构。而在这一领域,那些深耕全球化云服务,且在 AI 推理场景有过大量实践的企业,往往积累了更丰富的经验。
所以,为了得到这些问题的答案,InfoQ 特别邀请到在全球化高性能分布式推理服务构建方面有深度实践经验的 GMI Cloud,参加 InfoQ 极客传媒举办的 AICon 全球人工智能与开发大会·北京站。GMI Cloud VP of Engineering Yujing Qian在本次会议上发表了主题为《GMI Cloud Inference Engine 全球化高性能分布式推理服务构建实践》的演讲。
演讲主要围绕 AI 出海企业在 AI 推理方面的技术挑战与行业趋势展开,例如推理服务的及时性、扩展性、稳定性成为核心挑战;随着企业的多节点推理需求爆发,P/D 分离、EP 两大技术成主流。Yujing Qian 也深入解析了集群级别的自动扩容技术架构的设计逻辑与核心要素,包括负载均衡、扩容策略、冷启动加速等。他还介绍了摒弃派工程师现场调研这种传统方案的原因,并提供了推理引擎优化器的技术原理、应用场景与 Benchmark 工具,该工具可根据实际需求动态地对推理引擎进行管理和调控,同时还能支持基准测试、结果存储等。
InfoQ 对其演讲内容进行了整理,以期帮助从业者清晰认知 AI 出海企业在推理服务上的各种情况,为出海企业核心决策者提供基础设施构建的新视角与技术路径参考。
以下是演讲实录:
Part 1
全球AI应用推理的趋势与挑战
在 AI 应用全球化服务的趋势下,推理服务的及时性、扩展性、稳定性成为核心挑战。
以主打全球化服务的客户为例,其用户分布在美西、美东、东南亚等全球各地,仅靠单一点位的算力集群,无法为跨区域用户提供低延时服务。
面对AI应用的突然火爆,用户访问在短时间内暴增,现有的集群就会难以承受。目前 GMI Cloud 接触的多个语言模型、视频模型的客户,都曾遇到过类似问题------大模型突然走红,但用户等待时间变长,这该如何解决?
除此之外,常被忽视的挑战还有服务稳定性,这是用户留存的关键。GPU 集群的稳定性制约着应用扩张,虽然海外 GPU 资源丰富,但能稳定提供服务的却不多。然而,在当前情况下,很多企业可能难以获取最新的高端 GPU 资源以用于测试和部署工作,同时还会面临合规性问题。
在"挑战"之外,AI推理还呈现出两个趋势。第一个是 AI 应用的流量高峰常常不期而至,推理服务及时弹性扩容变得至关重要。就像 Manus 上线七天,使用申请等候名单增加到 200 万人,邀请码一度"一码难求";北美知名的视频生成网站 Higgsfield,发布当天有几十万人在排队,若此时告知用户,生成视频需等待数小时,那留存率就难以保证了。
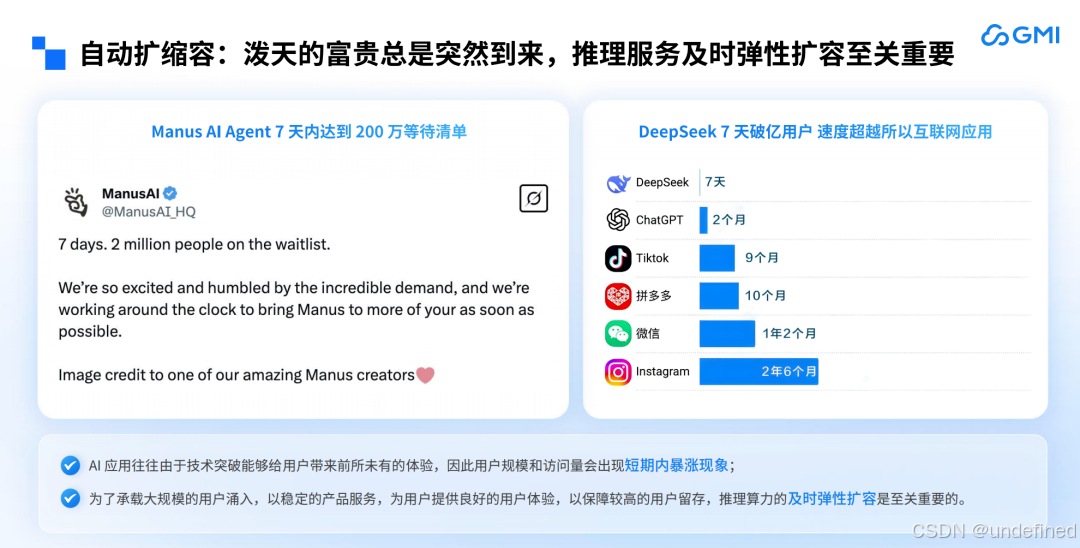
第二个是企业的多节点推理需求爆发,P/D 分离、EP 两大技术成主流。以 DeepSeek-R1 671B 为例,每个 H100 节点(8个GPU)的吞吐量从 1 月到 5 月增长了 20 多倍。这种爆发式增长反映了大模型推理对算力规模的刚性需求,而单卡或单节点推理在面对高并发流量、复杂模型运算时,已难以满足实时性与效率要求。
从技术逻辑看,多节点场景下的推理效率提升离不开技术与架构的创新:P/D 分离技术通过将参数存储与计算逻辑解耦,有效解决了多节点间数据同步的性能瓶颈;而 EP 架构则通过将模型参数分配至不同节点,实现了算力资源的精细化调度。两者结合使大模型在多节点部署时能充分释放硬件潜力。
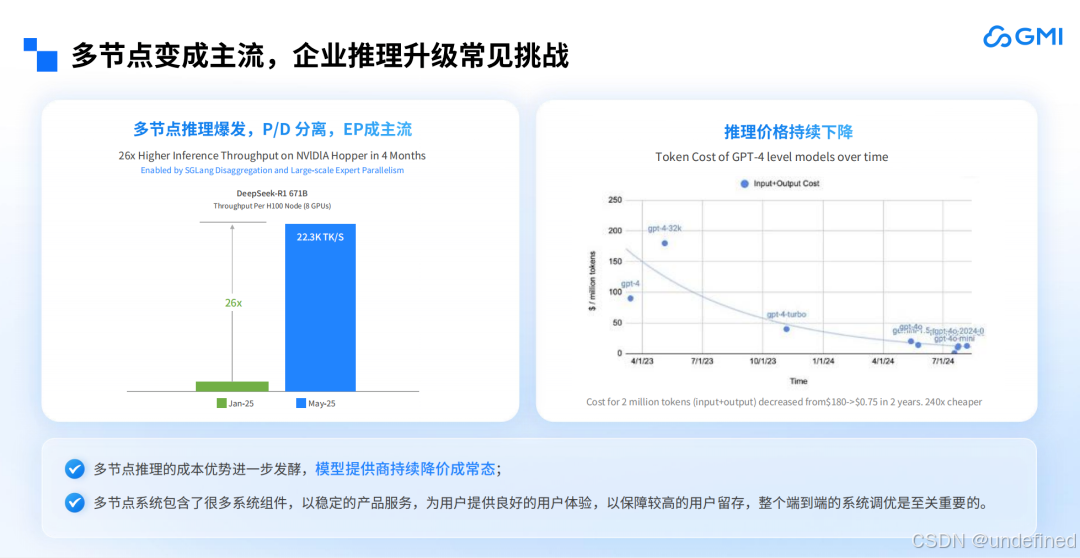
另外,随着多节点推理的成本优势进一步发酵,模型提供商的价格也在不断下降。此时,企业若有部署模型的需求,就不需要花费大量资金做单节点部署了。
对于有自研模型且有出海需求的企业而言,必然有推理升级的需求。GMI Cloud 希望能助力企业完成 AI 应用的推理升级,无论是托管还是部署需求,都能满足。
Part 2
GMI Cloud 的推理服务架构解析
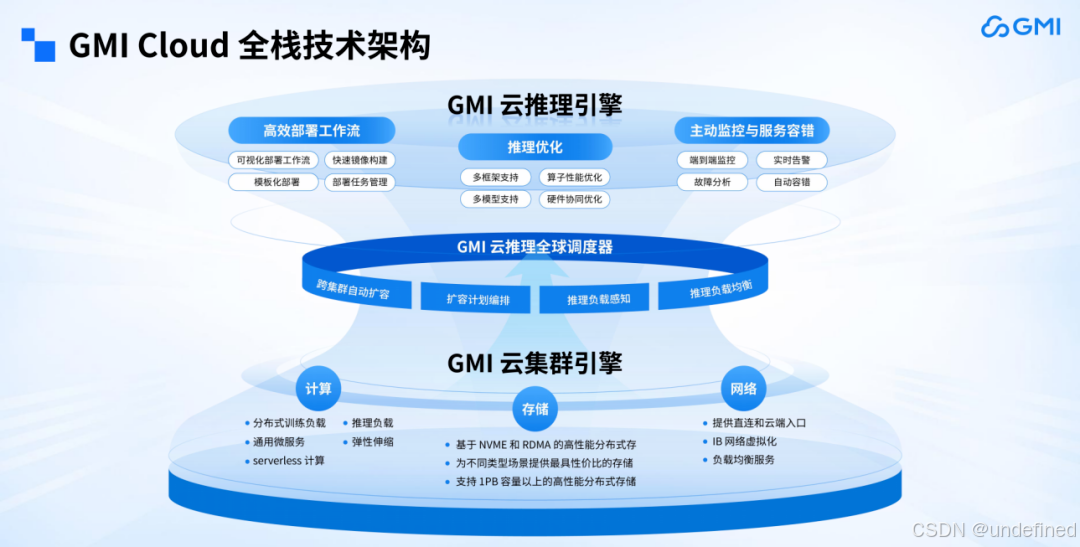
GMI Cloud 的全栈技术架构主要分为两层,底层是 IaaS 层,提供 GMI 云集群引擎(Cluster Engine),包含三个部分:首先是计算,核心载体就是 GPU;其次是存储,无论是做大模型还是生成类模型,存储都必不可少,可用于存放 KV Cache、日志等;最后是网络,无论是训练还是构建多机推理系统,若网络不通,即便部署众多节点也无济于事。因此,GMI Cloud 会为客户搭建好这三层,并提供统一的网络接口。
上层是 MaaS 层,提供 GMI 云推理引擎平台(Inference Engine),具备三大功能:一是高效的部署工作流,客户无需自行搭建整套推理框架,也无需思考更新问题,直接使用 GMI Cloud 的部署工作流即可轻松完成,且负责后续的维护与升级;二是支持模型推理的优化,无论是语言模型还是视频模型,GMI Cloud 都能实现较优的性能表现;三是支持主动监控与服务容错,在整个技术栈中,GMI Cloud 支持全栈(即端到端)的监控埋点,无论是 IaaS 层还是推理层,都能提供实时监控服务,并保障服务水平协议(SLA)。
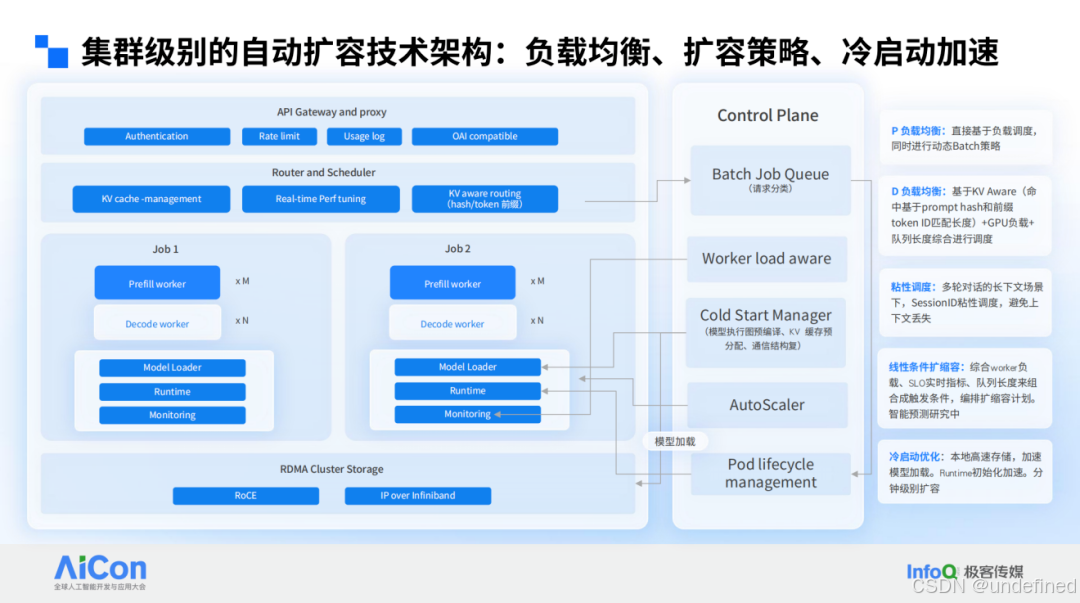
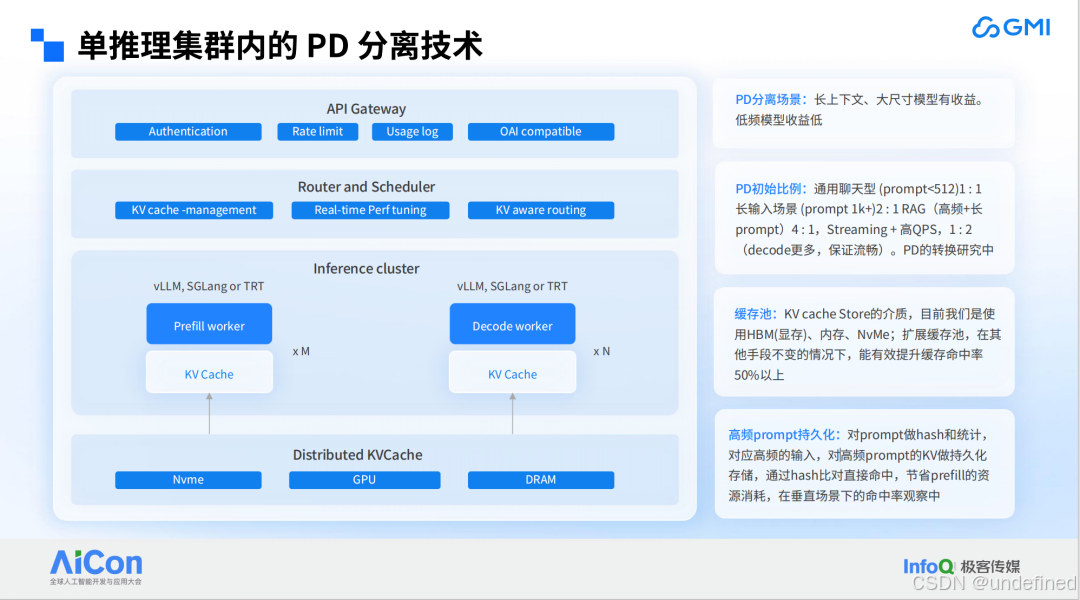
下图是一个集群级别的自动扩容技术架构,自上而下,GMI Cloud 都遵循行业通用的最佳实践。最上层是 API Gateway 层,帮助客户处理请求验证、限流及使用记录;中间是负载均衡层和调度层,针对预填充(prefill)和解码(decode)阶段分别实现负载均衡,并支持 KV Aware 路由策略(命中基于 prompt hash 和前缀 token ID 匹配长度进行命中)。
再往下是客户各自的 Worker Load(工作负载)层,以 P/D 分离架构为例,当前多数客户在 GMI Cloud 上托管的是非专家模型(如传统 32B 模型),尽管专家模型是行业热点,但非专家模型仍占主流。
最底层是存储层,支持 KV Aware 迁移与模型存储优化,实现快速冷启动能力 。 以 DeepSeek 这样规模的模型为例,可在分钟级完成集群拉起。这一优势在单集群场景下相对容易,而多集群间的高效同步机制在行业内较为少见,GMI Cloud 通过存储层优化,大幅缩短了多集群环境下的模型启动与同步耗时。
从架构设计来看,GMI Cloud 具备异构算力整合能力,将企业自有算力资源(包括自建集群与公有云集群)纳入统一管理体系,通过全球调度服务实现算力资源的协同调度。具体而言,客户可优先利用自有集群完成推理任务,当自有集群资源利用率达到阈值时,系统将自动触发资源扩容机制,无缝调用 GMI Cloud 的算力池持续支撑业务运行。
GMI Cloud 的算力是基于 Karmada 的混合云弹性部署(如下图所示),通过 Karmada 控制平面管理各集群的扩缩容能力,无论集群位于何处,只要接入 GMI Cloud 控制层即可实现弹性扩缩容。这在应对突发流量时非常有用,尤其是对延迟要求不高或能预测流量的模型,GMI Cloud 能在几分钟内调配资源以应对峰值流量,且客户无需提前预订大量资源来保障 SLA。
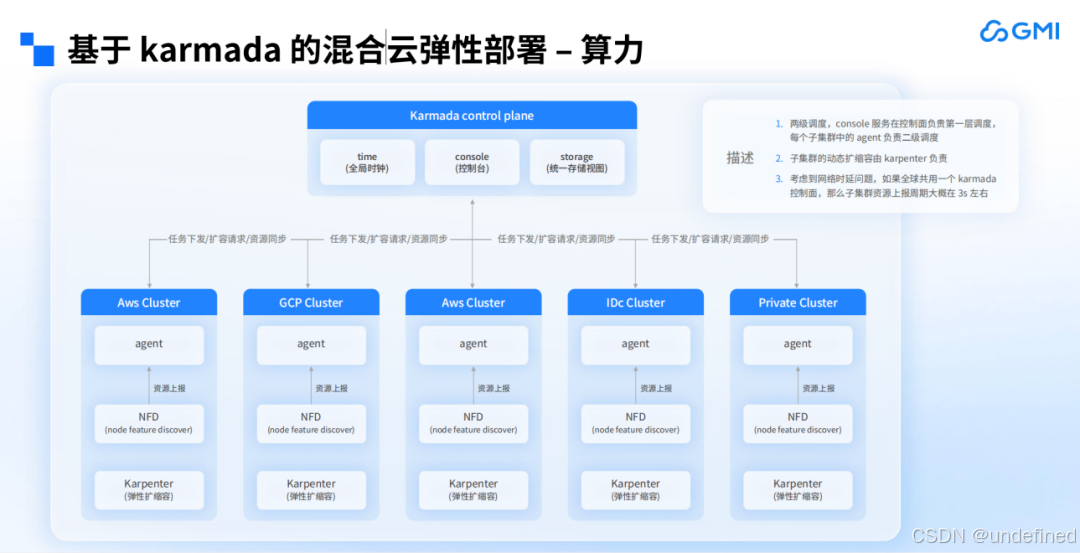
计算与存储密不可分,实现弹性扩缩容的前提是存储能随计算节点同步调整。因此,GMI Cloud 不仅实现了计算节点的扩缩容,还在底层实现了存储的扩缩容。这一解决方案是 GMI Cloud 与 JuiceFS 合作完成,目前将存储池划分为北美、亚太和欧洲三个区域,其中亚太和欧洲区域是北美区域的镜像。这样,无论客户数据产生于何处,都能根据配置及时将数据拷贝至其他区域集群。
除了存储方面的优化,对于单推理集群内的 P/D 分离技术,GMI Cloud 也进行了大量优化。其中,较为有用的一点是高频 prompt 持久化,这在 AI Agent 场景中尤为实用。我们对prompt做hash和统计,对高频 prompt 的 KV 做持久化存储,通过 hash 比对直接命中,节省 prefill 的资源消耗。从垂直场景的命中观察来看,该机制能有效降低新建集群的计算负载,实现 "以存储换计算"的优化目标。
如下图所示,若客户业务遍布北美大区,美国区客户产生的 KV Cache 可通过我们的持久化存储与加拿大区客户共享。这样,在加拿大新开集群时,就无需从零开始积累 KV Cache。
介绍完具体技术架构后,再介绍一下其他的功能,例如模型部署可视化工作流,实现部署运维一体化。
对于推理平台而言,若客户自行搭建,需要配置的组件众多。而使用 GMI Cloud 的托管平台,客户可实现一键搭建,涵盖从 Dockerfile 上传、模型上传、镜像安装,到推理副本设置、地区设置,再到服务管理和监控等整个链路。GMI Cloud 都可以提供解决方案,并配合底层 IaaS 层实现主动端到端监控,客户不仅能查看推理服务流量和延迟,还能了解运行服务的 GPU 状态。
Part 3
GMI Cloud 推理引擎 Benchmark:
开发者友好的推理调优器
接下来,我再为大家介绍一下 GMI Cloud 发布的一款对开发者极为友好的推理调优器。
过去的几个月里,企业在模型部署过程中频繁提出相同的问题。比如,同样的模型和负载,从 A100 迁移到 H100 需要多少张卡才能保持性能持平,最终是否节省成本?如果将精度从 fp16 降低到 fp8,能节省多少成本?针对我的工作负载或模型,最优的推理引擎及其配置是什么?
还有些企业客户,可能是刚获得融资并完成了概念验证(POC),他们会问:我设计的每个 Agent 需要达到特定的用户吞吐量和首次响应时间(TTFT)目标,需要多少张 GPU 卡,才能实现预期的每秒查询数(QPS)?
面对这些问题,行业内的传统方案是派工程师根据用户场景,手动测试数周甚至数月,然后告知客户所需 GPU 卡的数量。但是,这种方法无法保证结果的绝对准确性和高效性。因为推理框架更新迅速,推理参数众多,在不同参数设置下,吞吐、TTFT、TPOT 有非常大的差别,需要根据模型大小、用户场景输入和输出长度来进行性能评测,选择最优的框架和参数。此外,派人现场调研成本较高。
以 vLLM 或 SGLang 为例,每次推理参数多达十几、二十甚至三十个,哪些参数有效?哪些参数应优化设置?这都需要大量实验才能得出经验,而这些实验的管理,哪些该做哪些不该做,对 Infra 提供方而言极具挑战。特别是像我们这样的云平台,不可能为每个客户都配备专门的调优工程师,然后告知客户一个配置方案。
为解决这些问题,GMI Cloud 推出了推理引擎调优工具------ Benchmark ,该工具分为两个版本:第一个是开源社区版,我们与 vLLM 社区合作,主要负责对不同开源大模型推理引擎(如 vLLM、SGLang、Ollama )进行基准测试。该版本已开源,主要覆盖单节点命令部署,例如如何用一台 H100 或 A100 部署模型并达到预期吞吐。

目前,开源社区版的 Inference Engine 提供了已测出的所有 Benchmark 数据。企业在社区版上得出的结果,均可在 GMI Cloud 平台一键部署,确保 1:1 复现。
另一个是 GMI Cloud 云版本,针对企业级用户,提供生产级推理方式的集群部署评估。平台对 vLLM 生产栈、SGLang 多节点部署、NVIDIA Dynamo 等技术进行深度优化,确保测试结果与生产环境高度一致。
Benchmark 这一工具可以解决模型推理引擎的 7 个关键问题:

首先,实现按需引擎管理的需求,无需提前占用 GPU,即可启动、停止、列举和管理所有经过 GMI Cloud 测试的推理引擎。过去,企业做实验可能需要先申请 20 个节点,再探索最优节点配比,但这不是最优方法,因为会发现 12 台节点就能达到最高性能,其余8台机器闲置,或者先约了 4 台机器,后来发现需要8台才能覆盖所有场景,这给商务和资源管理带来诸多反复。现在 GMI Cloud 提供按需引擎管理,无论企业想试 4 台、8台还是12台机器,都无需提前预订,可直接在GMI Cloud平台上测试,省去了提前预约的麻烦。
其次,提供了丰富的基准测试数据集。当然,也支持企业在Benchmark上上传自己的数据集,因为大部分客户都有自己独特的数据集,与开源数据集存在差异。
第三,支持全面的指标采集,Benchmark 会自动收集输入吞吐量、输出吞吐量、TPOT、TTFT 以及百万 token的成本。
第四,支持结果存储,即 Benchmark 帮助客户统一存储和管理所有测试集的测试结果。
第五,Benchmark与vLLM社区共同开发了一整套 YAML 配置文件,使基准测试变得更简单。企业只需要通过 YAML 文件定义好测试颗粒度,系统就能根据行业经验帮企业自动优化指标评估顺序,实现推理成本的优化。
此外,Benchmark 还提供交互式可视化仪表盘,展示客户的测试进度和分析所有历史基准测试结果;企业还可以将自己的引擎配置上传到 Arena 排行榜,分享特定情况下的最优配置。
总之,GMI Cloud 的目标是帮助企业以更贴近自身工况的方式,快速找到最优的引擎配比。