TL;DR
- 场景:两台以上 ClickHouse 节点做同步副本,要求写入可在任意副本执行且最终一致。
- 结论:按本文 SOP,你能在 10--15 分钟完成副本创建、日志复制校验与故障回滚。
- 产出:配置文件、整个过程、ON CLUSTER DDL、排障速查等。
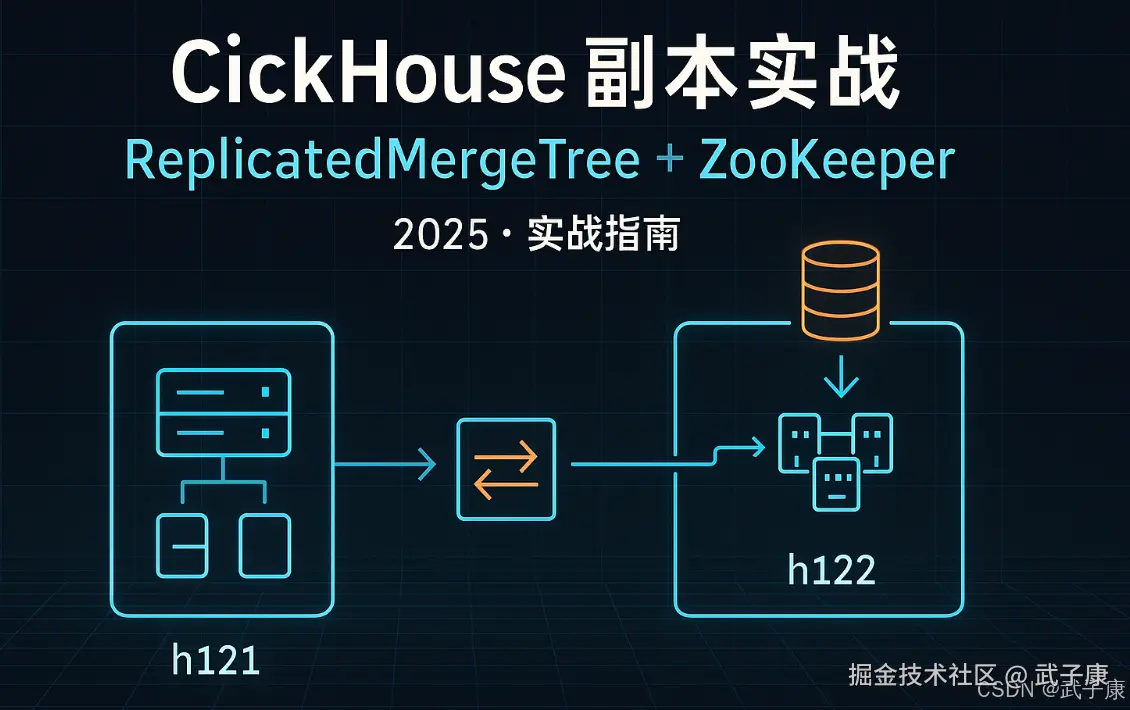
副本介绍
ReplicatedMergeTree ZooKeeper:实现多个实例之间的通信。
副本的特点
作为数据副本的主要载体,ReplicatedMergeTree在设计上有一些缺点:
- 依赖ZooKeeper: 在执行INSERT和ALTER查询的时候,ReplicatedMergeTree需要借助ZooKeeper的分布式协同功能,以实现多个副本之间的同步。但是在查询副本的时候,并不需要ZooKeeper。
- 表级别的副本:副本是在表级别定义的,所以每张表的副本配置都可以按照它的实际需求进行个性化定义,包括副本的数量,以及副本在集群内的分布位置等。
- 多主架构(Multi Master):可以在任意一个副本上执行INSERT和ALTER查询,他们效果是相同的,这些操作会借助ZooKeeper的协同能力被分发至每个副本以本地的形式执行。
- Block数据块,在执行INSERT命令写入数据时,会依据max_block_size的大小(默认1048576行)将数据切分成 若干个Block数据块。所以Block数据块是数据写入的基本单元,并且具有写入的原子性和唯一性。
- 原子性:在数据写入时,一个Block块内的数据要么全部写入成功,要不全部失败。
- 唯一性:在写一个Block数据块的时候,会按照当前Block数据块的数据顺序、数据行和数据大小等指标,计算Hash信息摘要并记录在案。在此之后,如果某个待写入的Block数据块与先前被写入的Block数据块拥有相同的Hash摘要(Block数据块内数据顺序、数据大小和数据行均相同),则该Block数据块会被忽略,这项设计可以预防由异常原因引起的Block数据块重复写入问题。
ZK的配置
之前配置 之前章节我们已经配置过了ZK,配置好了集群模式。 这里简单提一下,如果你没有做好,你需要回去之前的章节完成。
xml
<yandex>
<zookeeper-servers>
<node index="1">
<host>h121.wzk.icu</host>
<port>2181</port>
</node>
<node index="2">
<host>h122.wzk.icu</host>
<port>2181</port>
</node>
<node index="3">
<host>h123.wzk.icu</host>
<port>2181</port>
</node>
</zookeeper-servers>
</yandex>开启ZK
但是我们没有开启ZK,我们需要在配置文件中开启:
shell
vim /etc/clickhouse-server/config.xml
# 在之前配置的地方,再加入一行
<include_from>/etc/clickhouse-server/config.d/metrika.xml</include_from>
# 之前没有下面的一行
<zookeeper incl="zookeeper-servers" optional="true" />配置结果如下图所示: 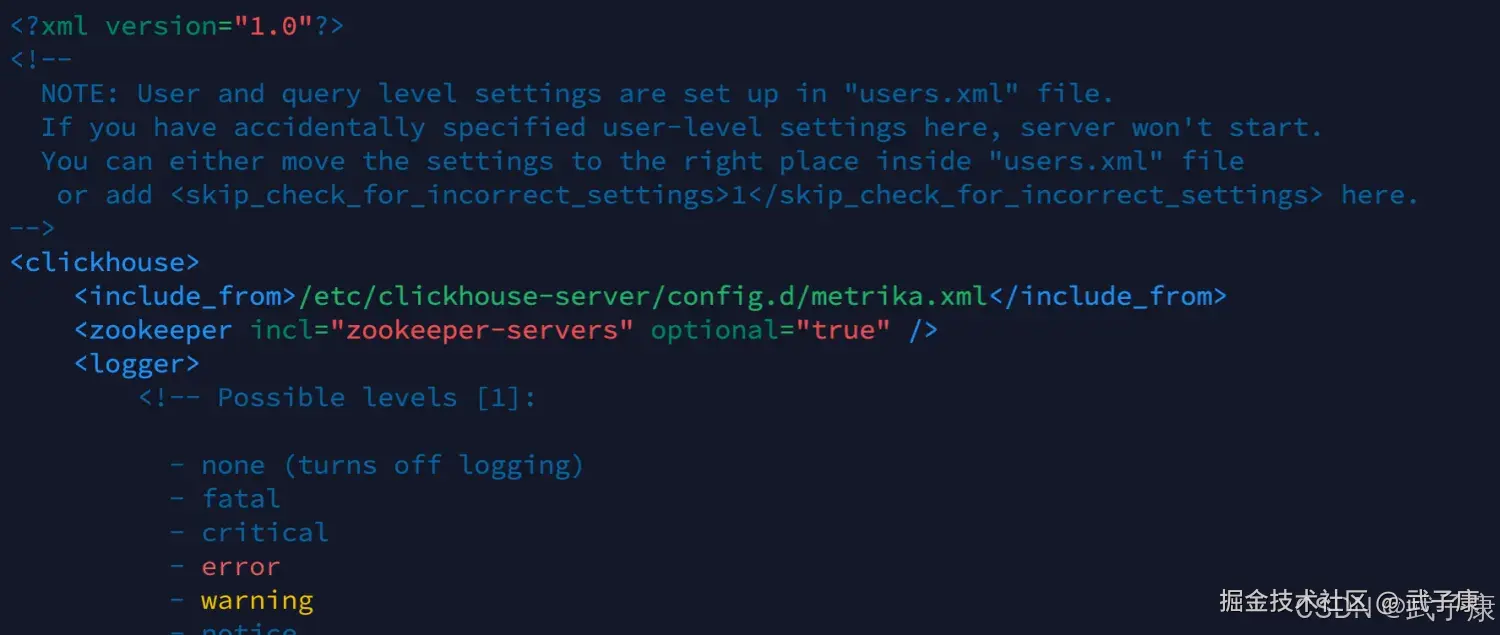
重启服务
shell
systemctl restart clickhouse-server检验结果
shell
# 连接到ClickHouse
clickhouse-client -m --host h121.wzk.icu --port 9001 --user default --password clickhouse@wzk.icu接着执行SQL检查是否成功链接到了 ZooKeeper
shell
SELECT * FROM system.zookeeper WHERE path = '/';执行结果如下图,如果你也是这样的没有报错,说明配置ZooKeeper服务成功! 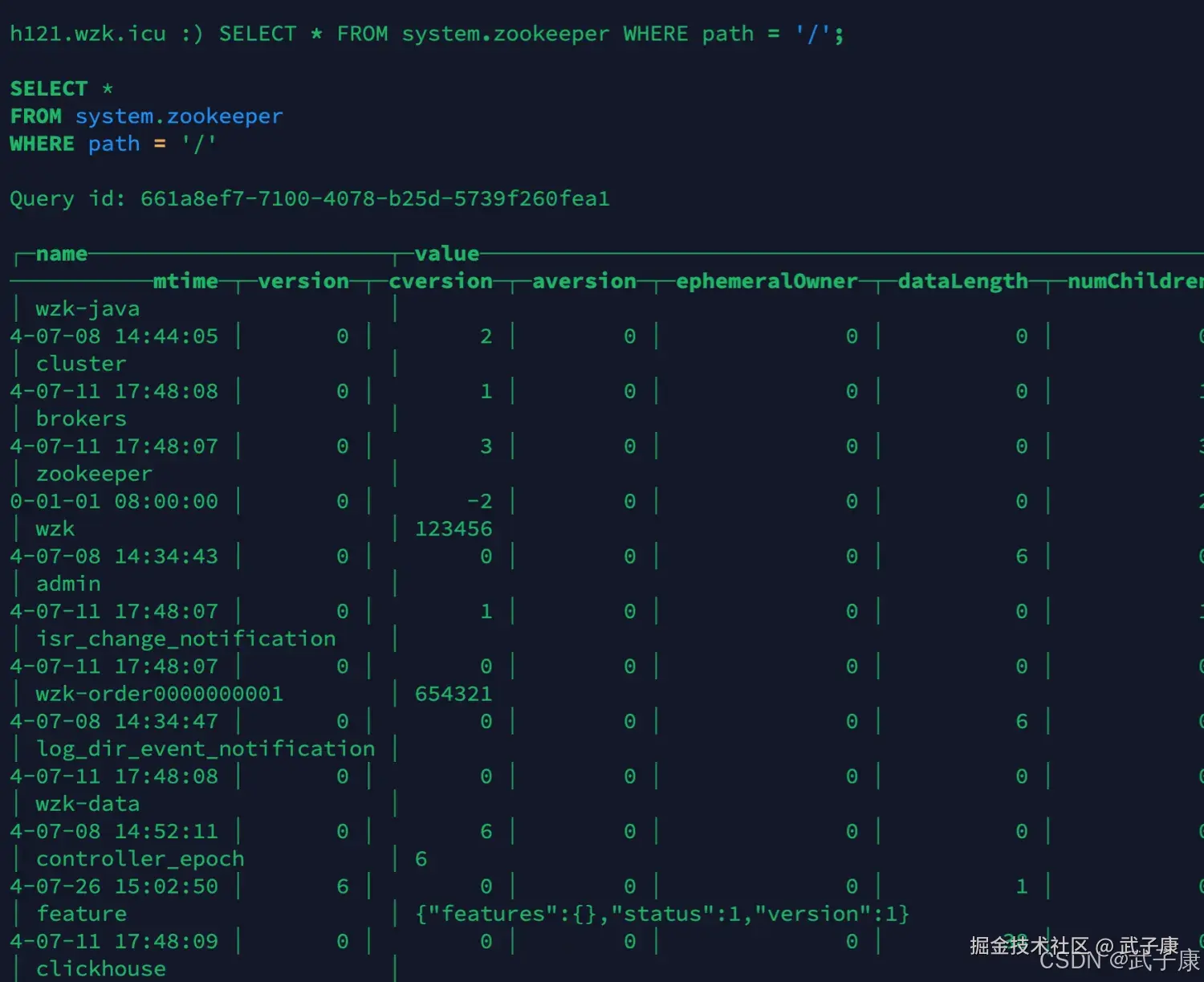
集群配置
如果有需要,记得将其他的节点都按照如上配置方式配置完毕。
副本定义形式
创建新表
sql
CREATE TABLE replicated_sales_5(
`id` String,
`price` Float64,
`create_time` DateTime
) ENGINE = ReplicatedMergeTree('/clickhouse/tables/01/replicated_sales_5', 'h121.wzk.icu')
PARTITION BY toYYYYMM(create_time)
ORDER BY id;- /clickhouse/tables 约定俗成的路径
- /01/ 分片编号
- replicated_sales_5 数据表的名字 建议与物理表名字相同
- h121.wzk.icu 在ZK中创建副本的名称,约定俗成是服务器的名称
执行结果如下图所示: 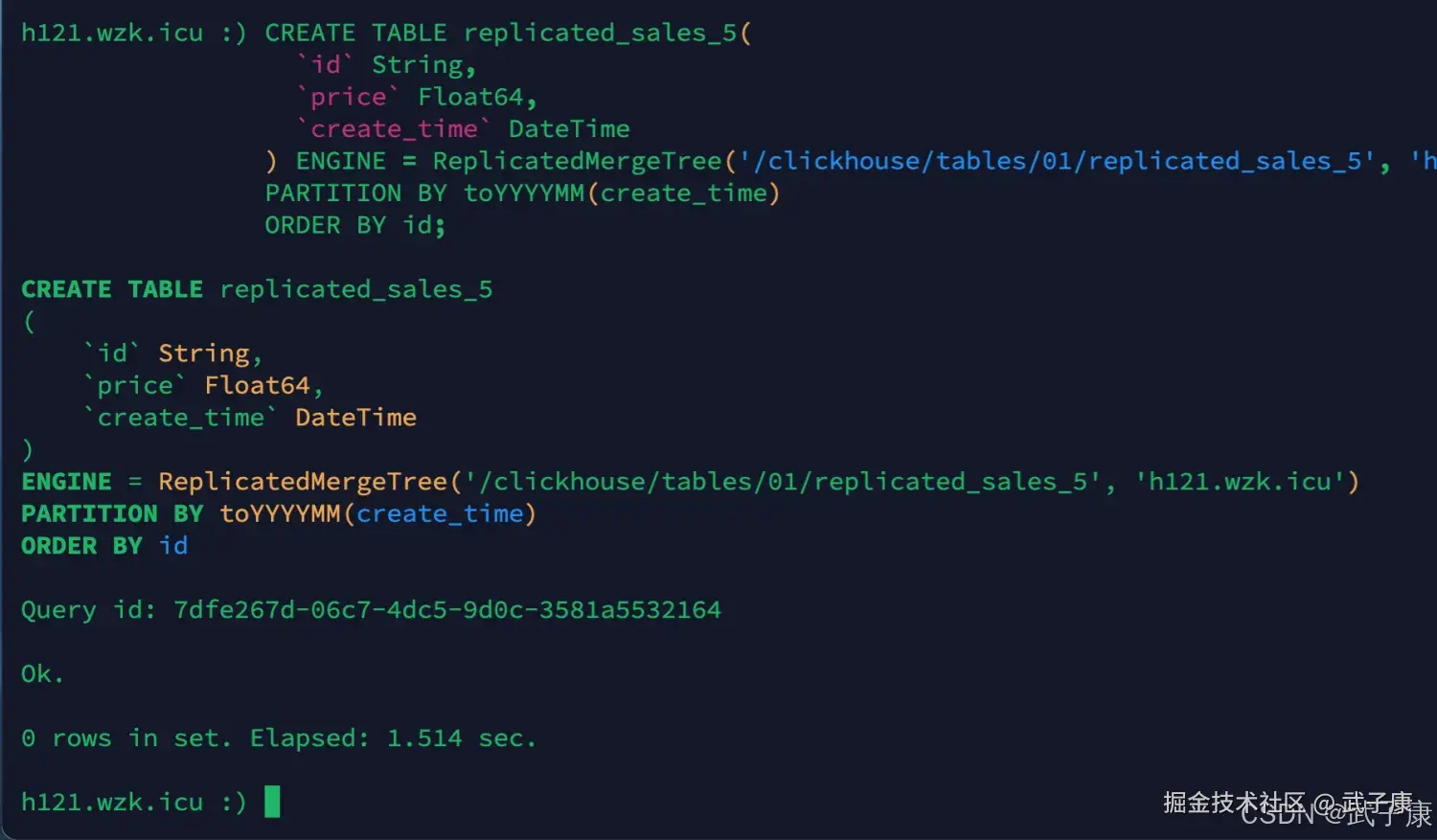
查询结果
可以检查刚才的操作结果:
sql
select * from system.zookeeper where path = '/clickhouse';执行结果内容如下: 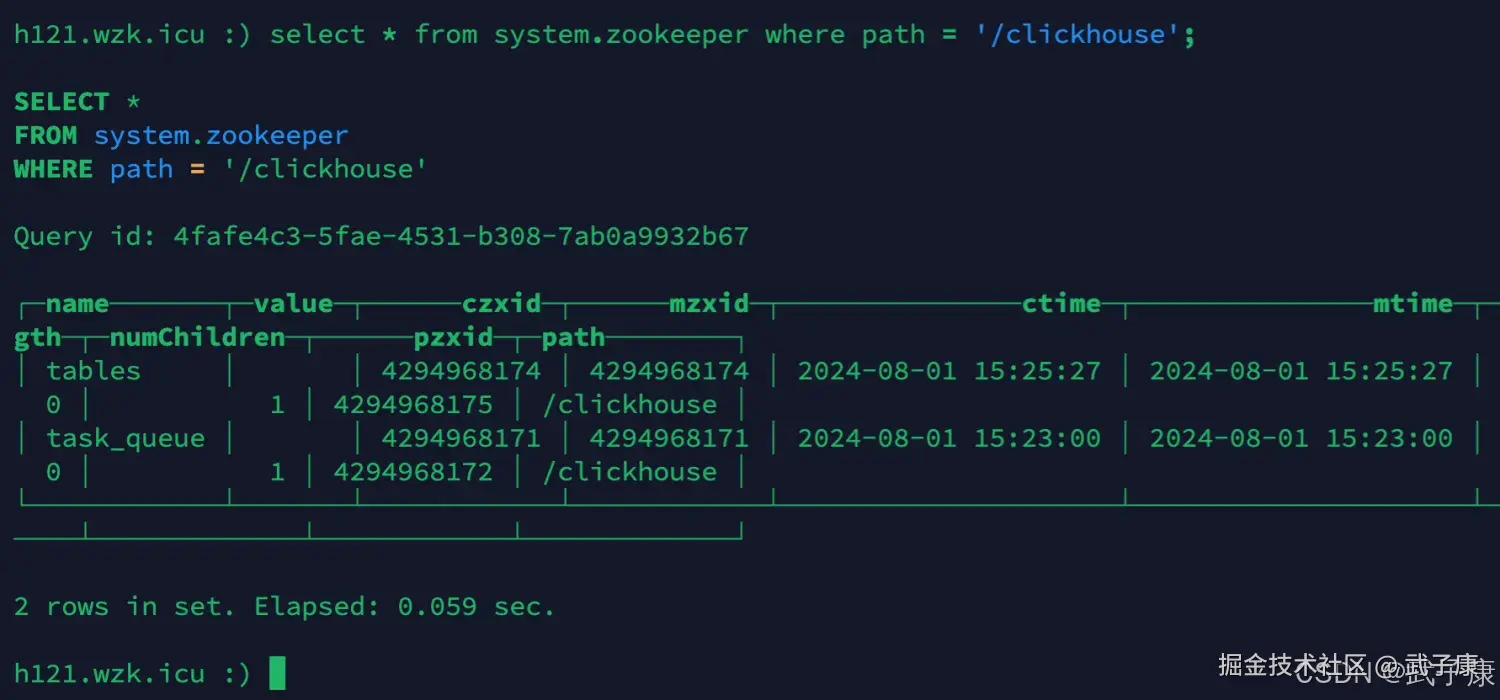
查看ZK
进入到ZK中,对数据进行查看:
shell
zkCli.sh执行结果如下图所示: 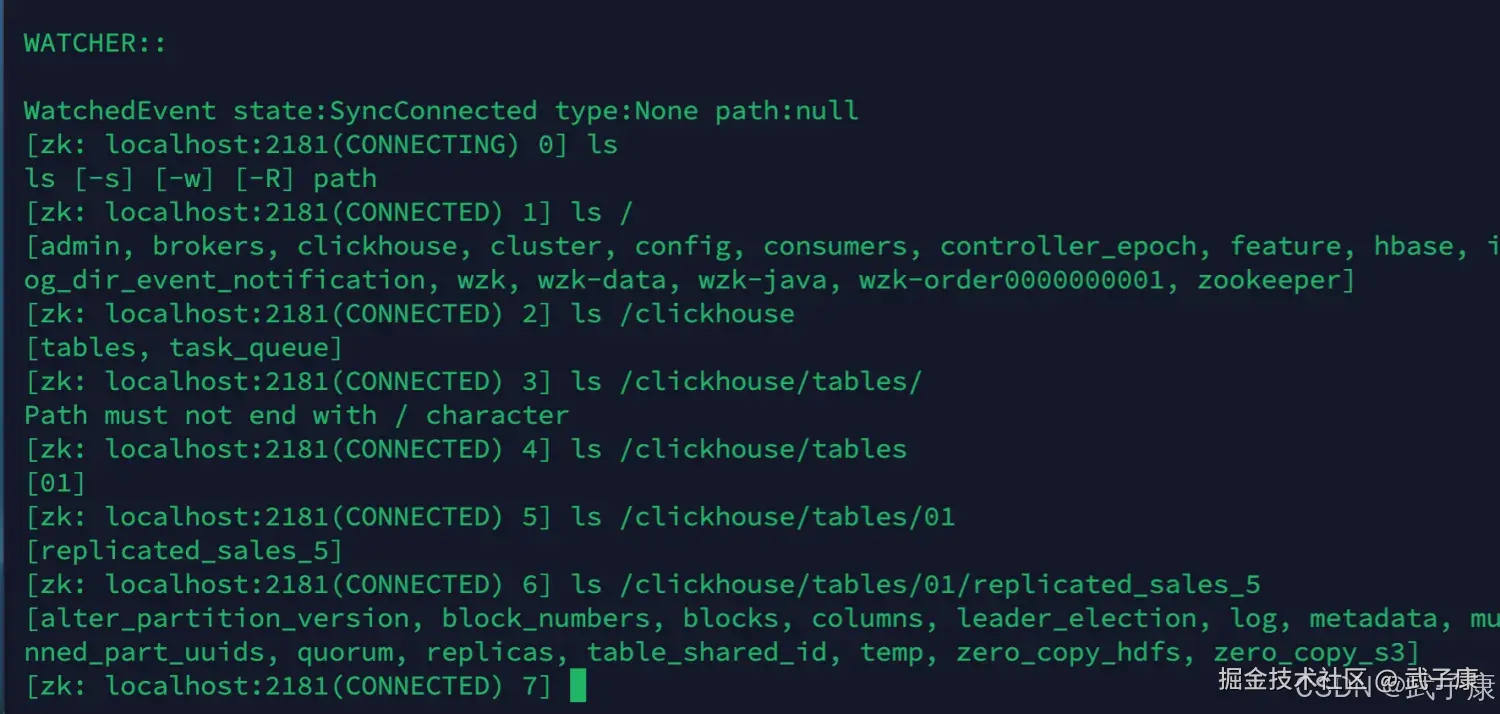
ReplicatedMergeTree原理
数据结构
shell
[zk: localhost:2181(CONNECTED) 7] ls /clickhouse/tables/01/replicated_sales_5
[alter_partition_version, block_numbers, blocks, columns, leader_election, log, metadata, mutations, nonincrement_block_numbers, part_moves_shard, pinned_part_uuids, quorum, replicas, table_shared_id, temp, zero_copy_hdfs, zero_copy_s3]
[zk: localhost:2181(CONNECTED) 8] 元数据:
- metadata:元数信息 主键、采样表达式、分区键
- columns:列的字段的数据类型、字段名
- replicats:副本的名称
标志:
- leader_eletion:主副本的选举路径
- blocks:hash值(复制数据重复插入)、partition_id
- max_insert_block_size: 1048576行
- block_numbers:在同一分区下block的顺序
- quorum:副本的数据量
操作类:
- log:log-000000 常规操作
- mutations:delete update
创建新表1
在当前机器上建立新表:
sql
CREATE TABLE a1(
id String,
price Float64,
create_time DateTime
) ENGINE = ReplicatedMergeTree('/clickhouse/tables/01/a1', 'h121.wzk.icu')
PARTITION BY toYYYYMM(create_time)
ORDER BY id;- 根据zk_path初始化所有的zk节点
- 在replicas节点下注册自己的副本实例 h121.wzk.icu
- 启动监听任务 监听LOG日志节点
- 参与副本选举,选出主副本,选举的方式是向 leader_election 插入子节点,第一个插入成功的副本就是主副本
执行结果如下图所示: 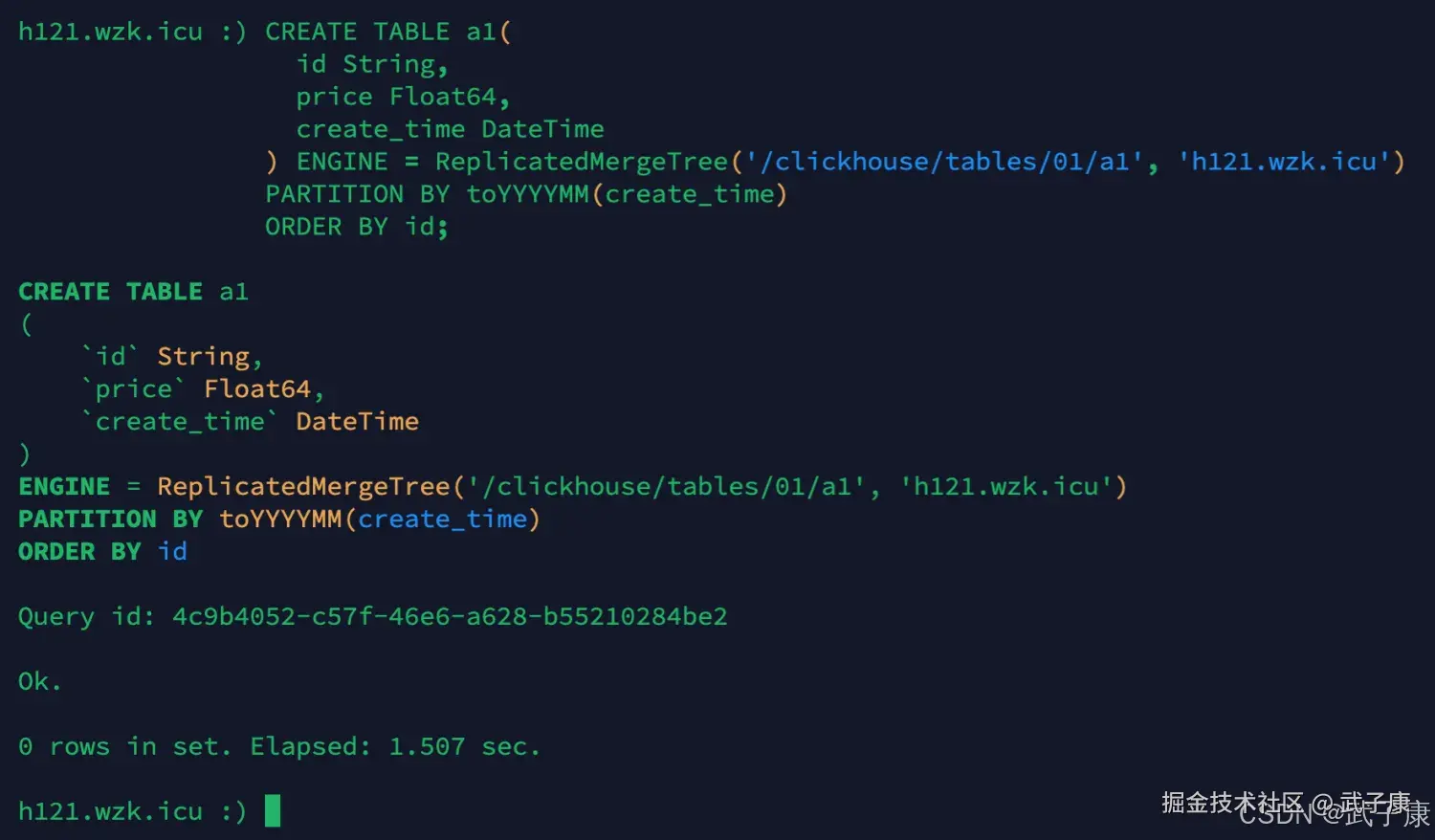
创建新表2
创建第二个副本实例(注意,当前我们需要连接到 h122 节点上):
shell
clickhouse-client -m --host h122.wzk.icu --port 9001 --user default --password clickhouse@wzk.icu执行对应的 SQL:
sql
CREATE TABLE a1(
id String,
price Float64,
create_time DateTime
) ENGINE = ReplicatedMergeTree('/clickhouse/tables/01/a1', 'h122.wzk.icu')
PARTITION BY toYYYYMM(create_time)
ORDER BY id;执行的结果如下图所示: 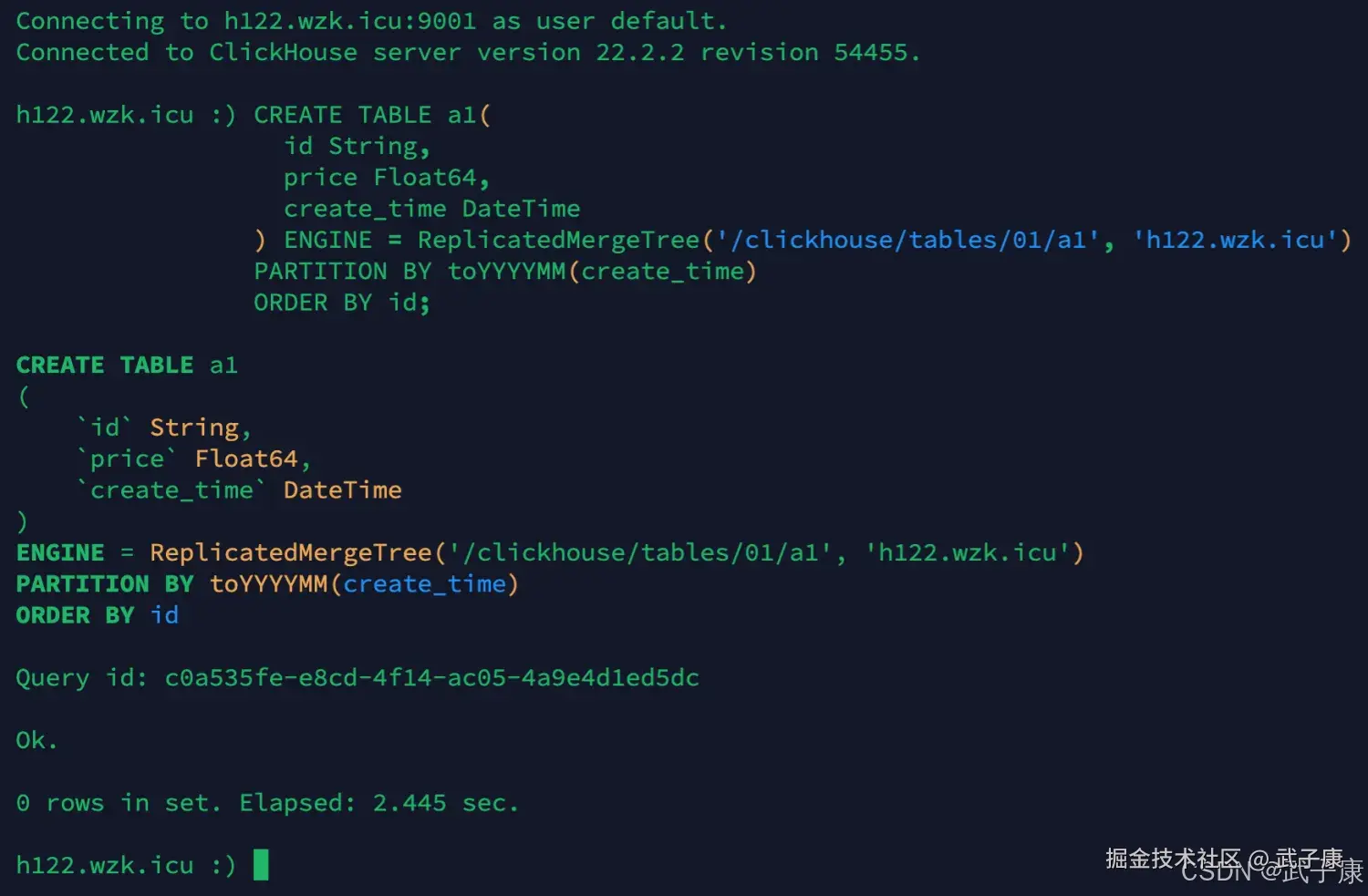
此时参与副本选举,h121.wzk.icu 副本成为了主副本。
插入数据1
目前我们在 h121.wzk.icu 插入数据:
sql
insert into table a1 values('A001',100,'2024-08-20 08:00:00');执行上述内容结果为: 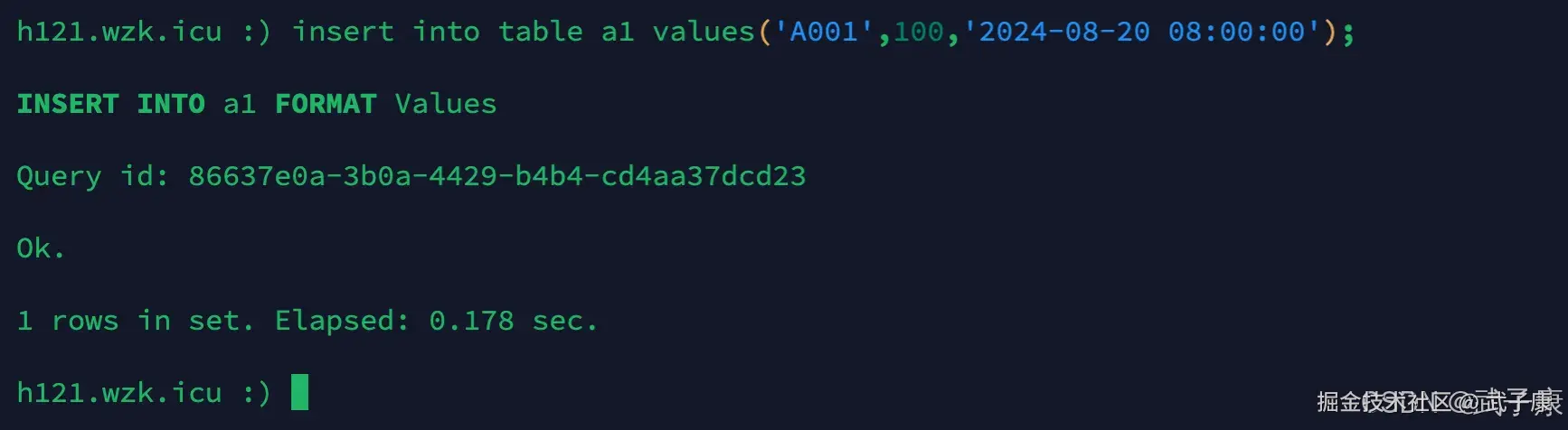
查看结果
执行完后,我们在ZK上查看数据:
shell
ls /clickhouse/tables/01/a1/blocks输出了如下的内容,插入命令执行后,在本地完成分区的目录的写入,接着向Block写入该分区的block_id:
shell
[zk: localhost:2181(CONNECTED) 6] ls /clickhouse/tables/01/a1/blocks
[202408_16261221490105862188_1058020630609096934]
[zk: localhost:2181(CONNECTED) 7] 查看日志
接下来,h121.wzk.icu 副本发起向 log 日志推送操作日志:
shell
[zk: localhost:2181(CONNECTED) 7] ls /clickhouse/tables/01/a1/log
[log-0000000000]
[zk: localhost:2181(CONNECTED) 8] 再次插入一条数据:
sql
insert into table a1 values('A002',200,'2024-08-21 08:00:00');查看 LOG 日志:
shell
ls /clickhouse/tables/01/a1/log
get /clickhouse/tables/01/a1/log/log-0000000000
get /clickhouse/tables/01/a1/log/log-0000000001输出内容如下:
shell
[zk: localhost:2181(CONNECTED) 14] ls /clickhouse/tables/01/a1/log
[log-0000000000, log-0000000001]
[zk: localhost:2181(CONNECTED) 13] get /clickhouse/tables/01/a1/log/log-0000000000
format version: 4
create_time: 2024-08-01 17:10:35
source replica: h121.wzk.icu
block_id: 202408_16261221490105862188_1058020630609096934
get
202408_0_0_0
part_type: Compact
[zk: localhost:2181(CONNECTED) 16] get /clickhouse/tables/01/a1/log/log-0000000001
format version: 4
create_time: 2024-08-01 17:16:37
source replica: h121.wzk.icu
block_id: 202408_3260633639629896920_11326802927295833243
get
202408_1_1_0
part_type: Compact拉取日志
接下来,第二个副本拉取Log日志: h122.wzk.icu节点会一直监听 /log 节点的变化,当h121.wzk.icu推送了/log/log-000000、0000001之后,h122.wzk.icu节点便会触发日志的拉取任务,并更新 log_pointer。
执行结果如下图所示: 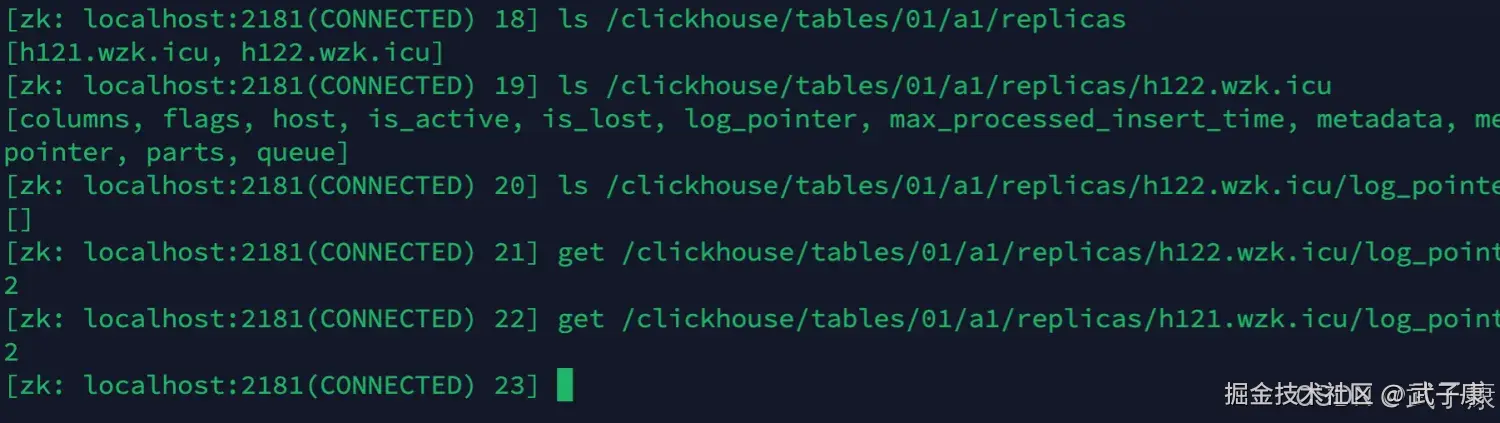
错误速查
| 症状 | 根因 | 定位 | 修复 |
|---|---|---|---|
| Not connected to ZooKeeper | ZK 地址/权限/网络 | telnet zk 2181 / system.zookeeper | 修 config、防火墙、重启 |
| 长时间 absolute_delay > 0 | 拉日志慢/积压 | system.replication_queue | SYSTEM SYNC REPLICA;查磁盘/CPU |
| Replica ... already exists | 重复注册 | system.replicas | DROP/DETACH 后 ATTACH 或换 {replica} |
| Too many parts 只读 | 小分片过多 | system.parts | 调批量/合并策略,降写入碎片 |
| 事务/DDL 不一致 | DDL 未在所有副本执行 | system.query_log | 永远用 ON CLUSTER 或 cluster_all_replicas=1 |
其他系列
🚀 AI篇持续更新中(长期更新)
AI炼丹日志-29 - 字节跳动 DeerFlow 深度研究框斜体样式架 私有部署 测试上手 架构研究 ,持续打造实用AI工具指南! AI-调查研究-108-具身智能 机器人模型训练全流程详解:从预训练到强化学习与人类反馈
💻 Java篇持续更新中(长期更新)
Java-154 深入浅出 MongoDB 用Java访问 MongoDB 数据库 从环境搭建到CRUD完整示例 MyBatis 已完结,Spring 已完结,Nginx已完结,Tomcat已完结,分布式服务正在更新!深入浅出助你打牢基础!
📊 大数据板块已完成多项干货更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余项核心组件,覆盖离线+实时数仓全栈! 大数据-278 Spark MLib - 基础介绍 机器学习算法 梯度提升树 GBDT案例 详解