文章目录
-
- [51. @Component, @Controller, @Repository, @Service 有何区别?](#51. @Component, @Controller, @Repository, @Service 有何区别?)
- [52. SpringBoot中的注解有哪些?SpringBoot的核心注解是什么?](#52. SpringBoot中的注解有哪些?SpringBoot的核心注解是什么?)
- [53. springBoot要发布一个接口需要几个注解?](#53. springBoot要发布一个接口需要几个注解?)
- [54. SpringBoot的运行原理/启动流程?](#54. SpringBoot的运行原理/启动流程?)
- [55. SpringBoot项目启动类上有什么注解?除了常用的还有什么注解?](#55. SpringBoot项目启动类上有什么注解?除了常用的还有什么注解?)
- [56. SpringBoot配置文件怎么配?](#56. SpringBoot配置文件怎么配?)
- [57. SpringBoot怎么整合MyBatis](#57. SpringBoot怎么整合MyBatis)
- [58. SpringBoot项目启动时配置文件加载顺序](#58. SpringBoot项目启动时配置文件加载顺序)
- [59. 事务的隔离级别](#59. 事务的隔离级别)
- [60. 事务的七种传播方式](#60. 事务的七种传播方式)
-
- [示例:REQUIRES_NEW vs NESTED](#示例:REQUIRES_NEW vs NESTED)
- [61. 过滤器和拦截器的区别?](#61. 过滤器和拦截器的区别?)
- [62. Spring运用了什么设计模式?讲一下哪些部分用到了这些设计模式](#62. Spring运用了什么设计模式?讲一下哪些部分用到了这些设计模式)
- [63. 去重的SQL语句怎么写?](#63. 去重的SQL语句怎么写?)
-
- [1. 单字段去重查询](#1. 单字段去重查询)
- [2. 多字段去重查询](#2. 多字段去重查询)
- [3. 删除重复记录(保留一条)](#3. 删除重复记录(保留一条))
- [4. 窗口函数去重(保留最新记录)](#4. 窗口函数去重(保留最新记录))
- [64. MYSQL大批量数据如何导入](#64. MYSQL大批量数据如何导入)
-
- [1. 使用LOAD DATA INFILE(最快)](#1. 使用LOAD DATA INFILE(最快))
- [2. 使用mysqlimport命令行工具](#2. 使用mysqlimport命令行工具)
- [3. 优化导入性能](#3. 优化导入性能)
- [65. mysql如何做大数据量分页](#65. mysql如何做大数据量分页)
- [66. mysql索引类型](#66. mysql索引类型)
-
- [1. 按数据结构分](#1. 按数据结构分)
- [2. 按功能分](#2. 按功能分)
- [3. 按存储分](#3. 按存储分)
- [67. 怎么避免索引失效](#67. 怎么避免索引失效)
- [68. 了解过MySQL数据库储存引擎么](#68. 了解过MySQL数据库储存引擎么)
- [69. 讲讲mysql最左匹配原则](#69. 讲讲mysql最左匹配原则)
- [70. 笛卡尔积是什么](#70. 笛卡尔积是什么)
- [71. 脏读,幻读,不可重复读](#71. 脏读,幻读,不可重复读)
- [72. 数据库的优化方案?一个SQL语句如何让他搜索变快?你们遇到的数据量最大的表是什么样,有多少条数据。](#72. 数据库的优化方案?一个SQL语句如何让他搜索变快?你们遇到的数据量最大的表是什么样,有多少条数据。)
- [73. 慢日志怎么使用?MYSQL怎么发现动作速度慢的SQL语句?](#73. 慢日志怎么使用?MYSQL怎么发现动作速度慢的SQL语句?)
- [74. 分库分表是怎么做的?数据库分表分库后怎么保证其一致性?](#74. 分库分表是怎么做的?数据库分表分库后怎么保证其一致性?)
- [75. MySQL表为何产生死锁?如何避免死锁?](#75. MySQL表为何产生死锁?如何避免死锁?)
- [76. oracle与mysql的区别?mysql分页和oracle分页的区别?](#76. oracle与mysql的区别?mysql分页和oracle分页的区别?)
- [77. Mysql默认的事务隔离级别?](#77. Mysql默认的事务隔离级别?)
- [78. Mysql的索引的数据结构?](#78. Mysql的索引的数据结构?)
- [79. Mysql中count()和count(1)区别](#79. Mysql中count()和count(1)区别)
- [80. Sql看执行计划?](#80. Sql看执行计划?)
- [81. 创建线程的方式及其区别](#81. 创建线程的方式及其区别)
- [82. mysql锁的粒度?并发编程锁到行还是表?(介绍页级、表级、行级)](#82. mysql锁的粒度?并发编程锁到行还是表?(介绍页级、表级、行级))
- [83. 什么是线程和进程?它们之间的区别是什么?](#83. 什么是线程和进程?它们之间的区别是什么?)
- [84. 请解释一下线程的几种状态以及状态之间的转换关系](#84. 请解释一下线程的几种状态以及状态之间的转换关系)
- [85. 什么是线程上下文切换?](#85. 什么是线程上下文切换?)
- [86. 项目中是否用到过多线程?怎么用的?](#86. 项目中是否用到过多线程?怎么用的?)
- [87. Sleep()和wait()区别?Start()和run()区别?wait,sleep,notify的区别?](#87. Sleep()和wait()区别?Start()和run()区别?wait,sleep,notify的区别?)
-
- [Sleep() vs wait()](#Sleep() vs wait())
- [Start() vs run()](#Start() vs run())
- [wait() vs notify()/notifyAll()](#wait() vs notify()/notifyAll())
- [88. 线程安全指的是什么?如何保障线程安全](#88. 线程安全指的是什么?如何保障线程安全)
- [89. 线程锁有几种方式?使用的关键字?](#89. 线程锁有几种方式?使用的关键字?)
- [90. 什么是乐观锁和悲观锁?](#90. 什么是乐观锁和悲观锁?)
- [91. synchronized和lock的区别。Synchronize关键字修饰方法和修饰代码块的区别](#91. synchronized和lock的区别。Synchronize关键字修饰方法和修饰代码块的区别)
- [92. 如何保证单例模式在多线程中的线程安全性](#92. 如何保证单例模式在多线程中的线程安全性)
- [93. 线程池的常见类型有那些?](#93. 线程池的常见类型有那些?)
- [94. 线程池中线程的停止?](#94. 线程池中线程的停止?)
- [95. 线程池中的线程数多少合适?](#95. 线程池中的线程数多少合适?)
- [96. 线程池一般是自动创建的还是手动?为什么?](#96. 线程池一般是自动创建的还是手动?为什么?)
- [97. ReentrantLock和synchronized的区别是什么](#97. ReentrantLock和synchronized的区别是什么)
- [98. 什么是死锁?如何避免死锁?](#98. 什么是死锁?如何避免死锁?)
- [99. Java 中线程间通信有哪些方式](#99. Java 中线程间通信有哪些方式)
51. @Component, @Controller, @Repository, @Service 有何区别?
通用注解,标记类为Spring管理的Bean,自动注册到容器,实例化Bean。
共同点
- 均用于标识Spring管理的Bean
- 可通过@ComponentScan自动扫描注册
- 支持自定义名称(如@Service("userService"))
52. SpringBoot中的注解有哪些?SpringBoot的核心注解是什么?
常用注解
- @RestController:@Controller + @ResponseBody(返回JSON)。
- @ConfigurationProperties:批量注入配置(如@ConfigurationProperties(prefix="app"))。
- @Bean:在配置类中定义Bean(如@Bean public RedisTemplate redisTemplate())。
- @Value:注入单个配置值(如@Value("${app.name}"))。
- @SpringBootTest:标记测试类(集成测试)。
- @Conditional:条件化注册Bean(如@ConditionalOnClass)。
- @Profile:多环境配置(如@Profile("dev"))。
核心注解:@SpringBootApplication
组合注解,包含以下三个核心功能:
- @Configuration:标记配置类(替代XML配置)。
- @EnableAutoConfiguration:自动配置Bean(根据依赖jar包)。
- @ComponentScan:扫描当前包及子包的组件(@Controller、@Service等)。
53. springBoot要发布一个接口需要几个注解?
最少需要2个核心注解:
- @RestController:标记控制器并返回JSON
- @RequestMapping(或@GetMapping/@PostMapping):映射URL
示例
java
@RestController // 1. 控制器注解
public class UserController {
@GetMapping("/api/user") // 2. 请求映射注解
public User getUser() {
return new User("张三", 20);
}
}扩展注解(可选)
- @RequestParam:获取请求参数
- @PathVariable:获取URL路径参数
- @RequestBody:接收JSON请求体
- @ResponseStatus:设置响应状态码
54. SpringBoot的运行原理/启动流程?
- 启动类执行 :
SpringApplication.run(Application.class, args) - 初始化SpringApplication :
- 推断应用类型(Web/非Web)
- 加载初始化器(Initializer)
- 设置监听器(Listener)
- 准备环境:加载配置文件(application.properties/yaml)
- 创建上下文:根据应用类型创建WebApplicationContext
- 初始化上下文 :
- 应用初始化器(ApplicationContextInitializer)
- 注册BeanDefinition
- 刷新上下文(refresh())
- 自动配置:@EnableAutoConfiguration根据classpath依赖生成Bean
- 启动完成:调用CommandLineRunner/ApplicationRunner接口
55. SpringBoot项目启动类上有什么注解?除了常用的还有什么注解?
核心注解
- @SpringBootApplication:组合注解(@Configuration + @EnableAutoConfiguration + @ComponentScan)
其他可选注解
- @EnableAsync:启用异步方法支持
- @EnableScheduling:启用定时任务
- @EnableCaching:启用缓存机制
- @EnableTransactionManagement:启用事务管理
- @ComponentScan:自定义组件扫描范围
- @PropertySource:加载额外配置文件
- @Import:导入配置类
- @Profile:指定激活的环境
示例
java
@SpringBootApplication
@EnableAsync
@EnableScheduling
@Profile("prod")
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class, args);
}
}56. SpringBoot配置文件怎么配?
配置文件类型
-
application.properties:
propertiesserver.port=8080 spring.datasource.url=jdbc:mysql://localhost:3306/db -
application.yml(推荐,结构化):
yamlserver: port: 8080 spring: datasource: url: jdbc:mysql://localhost:3306/db username: root password: 123456
多环境配置
- 开发环境:application-dev.yml
- 测试环境:application-test.yml
- 生产环境:application-prod.yml
激活方式
- 配置文件指定 :
spring.profiles.active=dev - 命令行参数 :
java -jar app.jar --spring.profiles.active=prod - VM参数 :
-Dspring.profiles.active=test
57. SpringBoot怎么整合MyBatis
整合步骤
-
添加依赖(pom.xml):
xml<dependency> <groupId>org.mybatis.spring.boot</groupId> <artifactId>mybatis-spring-boot-starter</artifactId> <version>2.3.0</version> </dependency> <dependency> <groupId>com.mysql</groupId> <artifactId>mysql-connector-j</artifactId> </dependency> -
配置数据源(application.yml):
yamlspring: datasource: url: jdbc:mysql://localhost:3306/test username: root password: 123456 mybatis: mapper-locations: classpath:mapper/*.xml # Mapper.xml路径 type-aliases-package: com.example.entity # 实体类包 -
创建实体类:
javapublic class User { private Long id; private String name; // getter/setter } -
创建Mapper接口:
java@Mapper public interface UserMapper { User selectById(Long id); } -
编写Mapper.xml:
xml<mapper namespace="com.example.mapper.UserMapper"> <select id="selectById" resultType="User"> SELECT * FROM user WHERE id = #{id} </select> </mapper> -
Service层调用:
java@Service public class UserService { @Autowired private UserMapper userMapper; public User getUser(Long id) { return userMapper.selectById(id); } }
58. SpringBoot项目启动时配置文件加载顺序
-
内部配置文件 (优先级从高到低):
如果在不同的目录中存在多个配置文件,它的读取顺序是
1、config/application.properties(项目根目录中config目录下)
2、config/application.yml
3、application.proprties (项目根目录下)
4、application.yml
5、resources/config/application.properties(项目resources目录中config目录下)
6、 resources/config/application.yml
7、resources/application.properties(项目的resources目录下)
8、resources/application.yml
如下图:
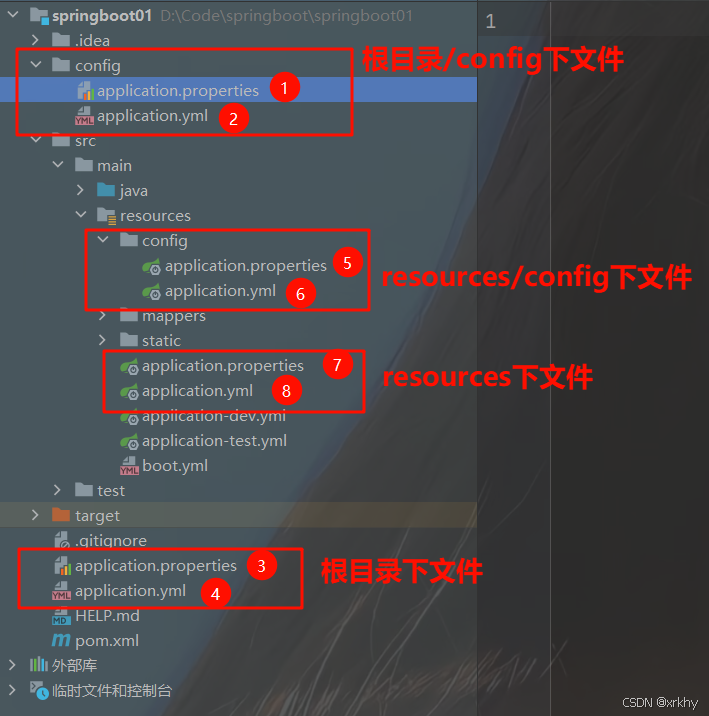
-
外部配置文件:
- 命令行参数(如--spring.config.location=file:/path/)
- 环境变量(如SPRING_CONFIG_LOCATION)
- 操作系统配置文件(如/etc/spring-boot/)
-
配置文件格式(优先级从高到低):
- .properties
- .yml
- .yaml
59. 事务的隔离级别
数据库事务隔离级别
-
读未提交(Read Uncommitted):
- 允许读取未提交的数据
- 可能导致脏读、不可重复读、幻读
-
读已提交(Read Committed):
- 只能读取已提交的数据
- 解决脏读,仍可能不可重复读、幻读
- Oracle默认级别
-
可重复读(Repeatable Read):
- 事务期间多次读取同一数据结果一致
- 解决脏读、不可重复读,仍可能幻读
- MySQL默认级别(通过MVCC机制实现)
-
串行化(Serializable):
- 最高隔离级别,事务串行执行
- 解决所有并发问题,但性能极低
Spring事务隔离级别配置
java
@Transactional(isolation = Isolation.REPEATABLE_READ)
public void saveData() {
// 业务逻辑
}60. 事务的七种传播方式
Spring事务传播机制定义了多事务方法调用时的行为规则,共七种:
| 传播行为 | 说明 |
|---|---|
| REQUIRED | 默认。如果当前有事务则加入,否则新建事务。 |
| SUPPORTS | 支持当前事务,无事务则以非事务方式执行。 |
| MANDATORY | 必须在事务中执行,否则抛异常。 |
| REQUIRES_NEW | 新建事务,挂起当前事务(独立提交/回滚)。 |
| NOT_SUPPORTED | 以非事务方式执行,挂起当前事务。 |
| NEVER | 必须非事务执行,有事务则抛异常。 |
| NESTED | 嵌套事务(若当前有事务,创建保存点;无事务则同REQUIRED)。 |
示例:REQUIRES_NEW vs NESTED
- REQUIRES_NEW:完全独立事务,外层回滚不影响内层提交。
- NESTED:内层事务依赖外层事务,外层回滚内层也回滚,但内层回滚不影响外层。
61. 过滤器和拦截器的区别?
| 特性 | 过滤器(Filter) | 拦截器(Interceptor) |
|---|---|---|
| 技术依赖 | Servlet规范 | Spring框架 |
| 作用范围 | 所有Web请求(JSP/Servlet/静态资源) | 仅Spring MVC请求(Controller方法) |
| 执行时机 | 请求进入容器后,Servlet前 | DispatcherServlet后,Controller前 |
| 实现方式 | 实现javax.servlet.Filter接口 | 实现HandlerInterceptor接口 |
| 方法参数 | ServletRequest/ServletResponse | HttpServletRequest/Response, HandlerMethod |
| 生命周期 | 随Web容器启动/销毁 | 随Spring容器管理 |
| 功能 | 通用过滤(编码/登录验证) | 业务拦截(权限/日志) |
62. Spring运用了什么设计模式?讲一下哪些部分用到了这些设计模式
- 工厂模式:BeanFactory、ApplicationContext创建Bean实例
- 单例模式:默认Bean作用域(singleton)
- 代理模式:AOP动态代理(JDK/CGLIB)
- 模板方法:JdbcTemplate、RestTemplate
- 观察者模式:事件监听机制(ApplicationEvent)
- 策略模式:Resource加载策略、事务管理策略
- 装饰器模式:BeanWrapper包装Bean对象
- 适配器模式:HandlerAdapter处理请求适配
63. 去重的SQL语句怎么写?
1. 单字段去重查询
sql
SELECT DISTINCT name FROM user;2. 多字段去重查询
sql
SELECT DISTINCT name, age FROM user; -- 所有字段组合去重3. 删除重复记录(保留一条)
sql
DELETE FROM user
WHERE id NOT IN (
SELECT MIN(id) FROM user
GROUP BY name, age -- 按重复字段分组
);4. 窗口函数去重(保留最新记录)
sql
WITH cte AS (
SELECT *, ROW_NUMBER() OVER (PARTITION BY name ORDER BY create_time DESC) rn
FROM user
)
SELECT * FROM cte WHERE rn = 1;64. MYSQL大批量数据如何导入
1. 使用LOAD DATA INFILE(最快)
sql
LOAD DATA INFILE '/path/to/data.csv'
INTO TABLE user
FIELDS TERMINATED BY ','
ENCLOSED BY '"'
LINES TERMINATED BY '\n'
IGNORE 1 ROWS; -- 忽略表头2. 使用mysqlimport命令行工具
bash
mysqlimport -u root -p --fields-terminated-by=',' dbname user.csv3. 优化导入性能
- 禁用索引:
ALTER TABLE user DISABLE KEYS;导入后启用 - 禁用事务:
SET autocommit=0;导入后提交 - 增大
max_allowed_packet参数 - 使用批量插入(INSERT INTO ... VALUES (...),(...))
65. mysql如何做大数据量分页
优化前(慢查询)
sql
SELECT * FROM user LIMIT 100000, 10; -- 偏移量大,全表扫描优化方案
- 索引覆盖+子查询:
sql
SELECT * FROM user
WHERE id >= (SELECT id FROM user LIMIT 100000, 1)
LIMIT 10;- 主键范围查询:
sql
SELECT * FROM user
WHERE id BETWEEN 100000 AND 100010; -- 适用于连续ID- 使用书签:
sql
-- 记录上一页最后一条ID
SELECT * FROM user
WHERE id > 100000
LIMIT 10;- 分表查询:水平分表后,各表独立分页
66. mysql索引类型
1. 按数据结构分
- B+树索引:最常用,支持范围查询(默认InnoDB索引)
- Hash索引:仅Memory引擎支持,等值查询快,不支持范围查询
- R树索引:空间索引,用于地理数据类型
- Full-text索引:全文索引,支持文本搜索
2. 按功能分
- 主键索引:PRIMARY KEY,唯一且非空
- 唯一索引:UNIQUE,确保字段值唯一
- 普通索引:INDEX,加速查询
- 组合索引:多字段联合索引(遵循最左前缀原则)
- 前缀索引:对字符串前缀建立索引(节省空间)
3. 按存储分
- 聚簇索引:索引与数据存储在一起(InnoDB主键索引)
- 非聚簇索引:索引与数据分离(InnoDB辅助索引)
67. 怎么避免索引失效
导致索引失效的常见情况
- 使用函数或运算 :
WHERE SUBSTR(name,1,3)='abc' - 隐式类型转换 :字符串不加引号
WHERE phone=13800138000 - 否定操作符 :
!=、<>、NOT IN、IS NOT NULL - LIKE以%开头 :
WHERE name LIKE '%abc' - OR连接非索引列 :
WHERE id=1 OR age=20(age无索引) - 组合索引不满足最左前缀 :
KEY (a,b,c)→WHERE b=1 AND c=2 - MySQL优化器认为全表扫描更快:数据量少时
避免措施
- 索引列避免函数/运算
- 保证类型匹配
- 使用覆盖索引
- 拆分OR条件为UNION
- 合理设计组合索引(最左前缀原则)
68. 了解过MySQL数据库储存引擎么
常见存储引擎
-
InnoDB(MySQL 5.5+默认)
- 支持事务(ACID)
- 行级锁、外键约束
- 聚簇索引,适合写密集型
- 崩溃恢复能力强
-
MyISAM
- 不支持事务、行锁
- 表级锁,读性能好
- 全文索引支持
- 适合读密集型(如博客)
-
Memory
- 数据存储在内存,速度快
- 不支持持久化,重启数据丢失
- 适合临时表、缓存
-
Archive
- 高压缩比,适合归档数据
- 只支持INSERT/SELECT,不支持UPDATE/DELETE
选择建议
- 事务需求:InnoDB
- 只读查询:MyISAM
- 临时数据:Memory
- 归档数据:Archive
69. 讲讲mysql最左匹配原则
定义
最左前缀原则是指组合索引中,查询条件需从索引最左列开始匹配,否则索引失效。
示例(组合索引 KEY (a,b,c))
| 查询条件 | 索引使用情况 |
|---|---|
| WHERE a=1 | 使用a列索引 |
| WHERE a=1 AND b=2 | 使用a,b列索引 |
| WHERE a=1 AND b=2 AND c=3 | 使用a,b,c列索引 |
| WHERE b=2 | 不使用索引(违反最左原则) |
| WHERE a=1 AND c=3 | 仅使用a列索引 |
| WHERE b=2 AND c=3 | 不使用索引 |
注意事项
-
索引顺序与查询条件顺序无关(MySQL优化器会调整顺序)
-
范围条件(>、<、BETWEEN)右侧列无法使用索引
sqlWHERE a=1 AND b>2 AND c=3 -- 仅a,b列使用索引,c列失效
70. 笛卡尔积是什么
定义
笛卡尔积是指两个集合中所有可能的元素组合。在SQL中,当多表连接时未指定关联条件,会产生笛卡尔积。
示例
sql
-- 表A(2行)
SELECT * FROM A; -- id: 1, 2
-- 表B(3行)
SELECT * FROM B; -- name: a, b, c
-- 笛卡尔积查询(无关联条件)
SELECT * FROM A, B; -- 结果:2×3=6行危害
- 数据量爆炸(n×m行)
- 严重消耗CPU/内存
- 查询效率极低
避免方式
- 多表连接时必须指定关联条件(如
WHERE A.id = B.a_id) - 使用INNER JOIN显式连接
71. 脏读,幻读,不可重复读
事务并发问题
-
脏读:
- 事务A读取到事务B未提交的修改
- 示例:A查询余额100 → B转账200未提交 → A查询余额300 → B回滚 → A读到脏数据
-
不可重复读:
- 事务A多次读取同一数据,事务B修改并提交,导致A读取结果不一致
- 示例:A第一次查余额100 → B转账200提交 → A第二次查余额300
-
幻读:
- 事务A按条件查询,事务B插入满足条件的新数据,A再次查询出现新数据
- 示例:A查询age>20的用户10人 → B插入age=25的用户 → A再次查询得11人
隔离级别解决
- 读未提交:允许所有问题
- 读已提交:解决脏读
- 可重复读:解决脏读、不可重复读(MySQL默认)
- 串行化:解决所有问题(性能低)
72. 数据库的优化方案?一个SQL语句如何让他搜索变快?你们遇到的数据量最大的表是什么样,有多少条数据。
数据库优化整体方案
- 索引优化:添加合适索引,避免索引失效
- SQL优化:避免全表扫描、减少JOIN、合理使用分页
- 表结构优化 :
- 分库分表(水平/垂直拆分)
- 字段类型优化(如用INT代替VARCHAR)
- 适度冗余减少JOIN
- 配置优化 :
- 调整连接数(max_connections)
- 缓存设置(query_cache_size)
- 日志优化(慢查询日志)
- 架构优化 :
- 读写分离(主从复制)
- 分库分表中间件(ShardingSphere)
- 引入缓存(Redis)
SQL语句优化技巧
- 使用索引:
WHERE、JOIN字段加索引 - 避免
SELECT *,只查需要字段(覆盖索引) - 拆分大SQL为小SQL
- 用
EXPLAIN分析执行计划 - 避免
OR,改用UNION - 批量操作代替循环单条操作
大数据量表处理经验
- 最大表规模:电商订单表,约5000万行数据
- 优化措施 :
- 水平分表(按时间/用户ID哈希)
- 历史数据归档(冷数据迁移至历史表)
- 读写分离(主写从读)
- 索引优化(仅保留必要索引)
73. 慢日志怎么使用?MYSQL怎么发现动作速度慢的SQL语句?
慢查询日志配置
-
开启慢日志:
inislow_query_log = ON slow_query_log_file = /var/log/mysql/slow.log long_query_time = 2 # 慢查询阈值(秒) log_queries_not_using_indexes = ON # 记录未使用索引的查询 -
查看慢日志:
bashmysqldumpslow -s t /var/log/mysql/slow.log # 按时间排序
发现慢SQL的方法
-
慢查询日志:记录执行时间超过阈值的SQL
-
SHOW PROCESSLIST:实时查看运行中的SQL
sqlSHOW PROCESSLIST; -- 查看阻塞进程 -
Performance Schema:详细监控SQL执行情况
sqlSELECT * FROM performance_schema.events_statements_summary_by_digest ORDER BY SUM_TIMER_WAIT DESC LIMIT 10; -
Explain分析:
sqlEXPLAIN SELECT * FROM user WHERE name = '张三';
74. 分库分表是怎么做的?数据库分表分库后怎么保证其一致性?
分库分表方案
1. 水平拆分(按数据行拆分)
- 范围拆分:按时间(如订单表按月份拆分)
- 哈希拆分:按用户ID哈希(如user_id % 8分8表)
- 地理位置拆分:按区域拆分数据
2. 垂直拆分(按列拆分)
- 按业务拆分:将大表拆分为用户表、订单表
- 按冷热数据拆分:高频字段与低频字段分离
保证一致性措施
- 分布式事务 :
- 两阶段提交(2PC)
- TCC补偿事务
- SAGA模式
- 最终一致性 :
- 消息队列异步同步
- 定时任务校验数据
- 全局ID :
- 雪花算法(Snowflake)
- UUID保证唯一性
- 分布式锁:Redis/ZooKeeper实现跨库锁
75. MySQL表为何产生死锁?如何避免死锁?
死锁产生原因
- 循环等待资源:事务A持有资源1等待资源2,事务B持有资源2等待资源1
- 锁顺序不一致:不同事务加锁顺序相反
- 长事务:事务持有锁时间过长,增加冲突概率
- 高并发:大量事务同时竞争资源
死锁示例
sql
-- 事务A
BEGIN;
UPDATE account SET balance = balance - 100 WHERE id = 1;
-- 事务B
BEGIN;
UPDATE account SET balance = balance - 100 WHERE id = 2;
-- 事务A继续
UPDATE account SET balance = balance + 100 WHERE id = 2; -- 等待B释放id=2的锁
-- 事务B继续
UPDATE account SET balance = balance + 100 WHERE id = 1; -- 等待A释放id=1的锁
-- 死锁产生!避免死锁措施
- 统一加锁顺序:所有事务按固定顺序获取锁
- 控制事务大小:减少事务持有锁的时间
- 使用低隔离级别:如READ COMMITTED
- 添加合理索引:减少锁竞争范围
- 设置超时时间 :
innodb_lock_wait_timeout - 定期检测 :
SHOW ENGINE INNODB STATUS查看死锁日志
76. oracle与mysql的区别?mysql分页和oracle分页的区别?
Oracle vs MySQL 核心区别
| 特性 | Oracle | MySQL |
|---|---|---|
| 授权方式 | 商业收费 | 开源免费 |
| 事务隔离 | 读已提交(默认) | 可重复读(默认) |
| 锁机制 | 行级锁、表级锁 | InnoDB行级锁,MyISAM表级锁 |
| 存储引擎 | 单一存储引擎 | 多存储引擎(InnoDB/MyISAM等) |
| 语法差异 | 序列(SEQUENCE)、ROWNUM等 | AUTO_INCREMENT、LIMIT等 |
| 备份恢复 | RMAN工具 | mysqldump、binlog |
分页查询区别
MySQL分页(LIMIT)
sql
SELECT * FROM user LIMIT 10 OFFSET 20; -- 从20行开始取10行Oracle分页(ROWNUM)
sql
-- 方式1:子查询
SELECT * FROM (
SELECT t.*, ROWNUM rn FROM user t WHERE ROWNUM <= 30
) WHERE rn > 20;
-- 方式2:FETCH(12c+)
SELECT * FROM user OFFSET 20 ROWS FETCH NEXT 10 ROWS ONLY;分页实现差异
- MySQL使用
LIMIT [offset,] rows,简单直观 - Oracle需借助ROWNUM伪列或FETCH子句,语法复杂
- 大数据量下,MySQL OFFSET过大会性能下降,Oracle ROWNUM需注意子查询顺序
77. Mysql默认的事务隔离级别?
MySQL默认事务隔离级别为可重复读(REPEATABLE READ)。
特点
- 保证同一事务多次读取同一数据结果一致
- 通过MVCC(多版本并发控制)实现
- 解决脏读、不可重复读问题
- 可能存在幻读(通过间隙锁解决InnoDB的幻读)
查看与修改隔离级别
sql
-- 查看当前隔离级别
SELECT @@tx_isolation;
-- 修改隔离级别
SET GLOBAL TRANSACTION ISOLATION LEVEL READ COMMITTED;78. Mysql的索引的数据结构?
MySQL主要使用B+树作为索引数据结构(InnoDB/MyISAM默认)。
B+树索引特点
- 平衡树结构:所有叶子节点在同一层,查询效率稳定(O(log n))
- 叶子节点链表:叶子节点间通过指针连接,支持范围查询
- 聚簇索引:InnoDB主键索引叶子节点存储数据行
- 非聚簇索引:叶子节点存储主键值,需回表查询数据
其他索引结构
- Hash索引:仅Memory引擎支持,等值查询快,不支持范围查询
- Full-text索引:倒排索引,用于全文搜索
- R树索引:空间索引,用于地理数据类型
79. Mysql中count()和count(1)区别
功能区别
- COUNT(*):统计所有行数,包括NULL值
- COUNT(1):统计所有行数,忽略NULL值(与COUNT(*)功能类似)
- COUNT(列名):统计非NULL值的行数
性能区别
- InnoDB中,COUNT(*) 经过优化,性能最优(不实际取值,直接计数)
- COUNT(1)性能略低于COUNT(*),需对每行计算常量1
- COUNT(列名)性能最差,需判断列是否为NULL
使用建议
- 统计总行数:优先使用COUNT(*)
- 统计非空值:使用COUNT(列名)
- COUNT(1)与COUNT()在InnoDB中性能差异不大,推荐使用COUNT()
80. Sql看执行计划?
使用EXPLAIN命令分析SQL执行计划,优化查询性能。
语法
sql
EXPLAIN SELECT * FROM user WHERE name = '张三';关键字段说明
- type:访问类型(ALL全表扫描,ref索引查找,range范围扫描)
- key:实际使用的索引
- rows:预估扫描行数
- Extra:额外信息(Using index覆盖索引,Using filesort文件排序)
优化依据
- type为ALL时需添加索引
- key为NULL表示未使用索引
- Extra出现Using filesort/Using temporary需优化
- rows值越小越好(接近实际行数)
81. 创建线程的方式及其区别
Java创建线程的四种方式
-
继承Thread类:
javaclass MyThread extends Thread { public void run() { ... } } new MyThread().start(); -
实现Runnable接口:
javaclass MyRunnable implements Runnable { public void run() { ... } } new Thread(new MyRunnable()).start(); -
实现Callable接口(有返回值):
javaclass MyCallable implements Callable<Integer> { public Integer call() { return 1; } } FutureTask<Integer> task = new FutureTask<>(new MyCallable()); new Thread(task).start(); Integer result = task.get(); // 获取返回值 -
线程池创建:
javaExecutorService executor = Executors.newFixedThreadPool(5); executor.submit(new Runnable() { public void run() { ... } }); executor.shutdown();
区别对比
| 方式 | 优点 | 缺点 |
|---|---|---|
| Thread类 | 简单直接 | 单继承限制 |
| Runnable接口 | 支持多实现 | 无返回值 |
| Callable接口 | 有返回值、可抛异常 | 实现复杂 |
| 线程池 | 复用线程、控制资源 | 需要管理线程池生命周期 |
82. mysql锁的粒度?并发编程锁到行还是表?(介绍页级、表级、行级)
MySQL锁粒度
-
表级锁:
- 锁定整个表,开销小,并发低
- MyISAM存储引擎默认锁
- 适用:全表操作(如ALTER TABLE)
-
行级锁:
- 锁定单行记录,开销大,并发高
- InnoDB存储引擎支持
- 适用:高并发写操作
-
页级锁:
- 锁定一页数据(16KB),介于表级和行级之间
- BDB存储引擎支持
- 并发中等,开销中等
并发编程锁选择
- 读多写少:表级锁(MyISAM)
- 写多读少:行级锁(InnoDB)
- 混合场景:InnoDB行级锁(默认)
InnoDB行级锁类型
- 共享锁(S锁):读锁,多个事务可同时获取
- 排他锁(X锁):写锁,独占锁定
- 间隙锁:防止幻读,锁定范围区间
83. 什么是线程和进程?它们之间的区别是什么?
定义
- 进程:操作系统资源分配的基本单位,拥有独立内存空间
- 线程:进程内的执行单元,共享进程资源,CPU调度的基本单位
区别对比
| 特性 | 进程(Process) | 线程(Thread) |
|---|---|---|
| 资源分配 | 独立地址空间、内存、文件句柄 | 共享进程资源 |
| 切换开销 | 大(保存/恢复整个进程上下文) | 小(仅保存线程上下文) |
| 通信方式 | 复杂(IPC:管道/消息队列) | 简单(共享内存/锁机制) |
| 并发性 | 低(进程切换开销大) | 高(线程切换开销小) |
| 安全性 | 高(地址空间隔离) | 低(共享资源需同步) |
| 生命周期 | 独立,父进程结束不影响子进程 | 依赖进程,进程结束线程终止 |
84. 请解释一下线程的几种状态以及状态之间的转换关系
Java线程六种状态(Thread.State)
- NEW(新建):线程创建未启动
- RUNNABLE(可运行):就绪或运行中
- BLOCKED(阻塞):等待监视器锁(synchronized竞争)
- WAITING(等待):无超时等待(Object.wait()、Thread.join())
- TIMED_WAITING(计时等待):带超时等待(Thread.sleep()、Object.wait(1000))
- TERMINATED(终止):线程执行完毕
状态转换关系
- NEW → RUNNABLE:调用start()方法
- RUNNABLE → BLOCKED:获取锁失败
- RUNNABLE → WAITING:调用wait()/join()无参方法
- RUNNABLE → TIMED_WAITING:调用sleep(time)/wait(time)
- BLOCKED/WAITING/TIMED_WAITING → RUNNABLE:获取锁/等待超时/被唤醒
- RUNNABLE → TERMINATED:run()方法执行完毕
85. 什么是线程上下文切换?
定义
线程上下文切换是指CPU从一个线程切换到另一个线程执行时,保存当前线程状态并恢复新线程状态的过程。
切换内容
- 程序计数器(下一条执行指令地址)
- 寄存器值(通用寄存器、条件码等)
- 栈指针(当前栈顶位置)
切换原因
- 线程时间片用完(操作系统调度)
- 线程阻塞(I/O、sleep()、wait())
- 高优先级线程抢占
- 线程主动让出CPU(yield())
影响
- 上下文切换有性能开销(CPU周期消耗)
- 频繁切换导致系统吞吐量下降
- 优化方向:减少线程数量、减少阻塞操作、使用无锁并发
86. 项目中是否用到过多线程?怎么用的?
项目应用场景
-
异步任务处理:
- 订单支付后异步发送短信通知
- 使用
@Async注解或线程池提交任务
-
并发数据处理:
- 批量导入数据时多线程解析文件
- 使用
CompletableFuture并行处理任务
-
定时任务:
- 商品库存定时同步
- 使用
ScheduledExecutorService或Quartz
-
高性能服务:
- Netty服务器的I/O线程模型
- Web服务器的请求处理线程池
代码示例(线程池处理异步任务)
java
@Service
public class OrderService {
@Autowired
private ThreadPoolTaskExecutor taskExecutor;
public void createOrder(Order order) {
// 保存订单(同步)
orderRepository.save(order);
// 异步发送通知
taskExecutor.execute(() -> {
notificationService.sendSms(order.getUserId());
});
}
}线程池配置
java
@Configuration
public class ThreadPoolConfig {
@Bean
public ThreadPoolTaskExecutor taskExecutor() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setCorePoolSize(5); // 核心线程数
executor.setMaxPoolSize(10); // 最大线程数
executor.setQueueCapacity(20); // 队列容量
executor.initialize();
return executor;
}
}87. Sleep()和wait()区别?Start()和run()区别?wait,sleep,notify的区别?
Sleep() vs wait()
| 特性 | Thread.sleep() | Object.wait() |
|---|---|---|
| 所属类 | Thread类静态方法 | Object类实例方法 |
| 锁释放 | 不释放锁 | 释放对象锁 |
| 唤醒方式 | 超时自动唤醒 | notify()/notifyAll()唤醒或超时 |
| 使用场景 | 暂停线程执行 | 线程间通信(等待/通知机制) |
| 异常处理 | 需捕获InterruptedException | 需捕获InterruptedException |
Start() vs run()
| 特性 | start() | run() |
|---|---|---|
| 作用 | 启动新线程,异步执行run() | 普通方法调用,同步执行 |
| 线程状态 | 将线程从NEW转为RUNNABLE | 不改变线程状态 |
| 调用次数 | 只能调用一次(多次抛异常) | 可多次调用 |
| 底层实现 | native方法,启动线程 | 普通Java方法 |
wait() vs notify()/notifyAll()
- wait():使当前线程释放锁并进入等待状态
- notify():随机唤醒一个等待该对象锁的线程
- notifyAll():唤醒所有等待该对象锁的线程
- 使用条件:必须在synchronized块中调用(获取对象锁后)
88. 线程安全指的是什么?如何保障线程安全
线程安全定义
多个线程并发访问时,无需额外同步操作,也能保证数据一致性和正确性。
线程不安全原因
- 共享可变状态(如静态变量、实例变量)
- 非原子操作(如i++)
- 指令重排序
保障线程安全的措施
- 无状态设计:不使用共享变量
- 不可变对象:使用final关键字
- 同步机制 :
- synchronized关键字(方法/代码块)
- ReentrantLock显式锁
- 原子类:AtomicInteger、AtomicReference
- 并发容器:ConcurrentHashMap、CopyOnWriteArrayList
- 线程封闭:ThreadLocal变量
- volatile关键字:保证可见性,禁止指令重排序
89. 线程锁有几种方式?使用的关键字?
Java线程锁方式及关键字
-
synchronized关键字:
- 同步方法 :
public synchronized void method() {} - 同步代码块 :
synchronized(obj) {} - 静态同步 :
public static synchronized void staticMethod() {} - 底层:对象监视器锁(隐式获取/释放锁)
- 同步方法 :
-
ReentrantLock类:
javaLock lock = new ReentrantLock(); lock.lock(); try { // 临界区 } finally { lock.unlock(); }- 特性:可中断、可超时、可尝试获取锁、公平锁选项
-
读写锁(ReentrantReadWriteLock):
javaReadWriteLock rwLock = new ReentrantReadWriteLock(); Lock readLock = rwLock.readLock(); // 读锁(共享) Lock writeLock = rwLock.writeLock(); // 写锁(排他) -
StampedLock:JDK 8+,乐观读模式提高并发性
-
volatile关键字:
- 非锁机制,保证可见性和禁止指令重排序
- 适用于单写多读场景
90. 什么是乐观锁和悲观锁?
悲观锁
- 思想:假设并发冲突会发生,操作前先加锁
- 实现:synchronized、ReentrantLock、数据库行锁
- 适用场景:写冲突频繁(如库存扣减)
- 优点:保证数据一致性
- 缺点:阻塞等待,性能开销大
乐观锁
- 思想:假设并发冲突不会发生,操作时检测冲突
- 实现 :
- 版本号机制(version字段)
- CAS算法(Compare-And-Swap)
- 适用场景:读多写少(如商品详情页)
- 优点:无锁竞争,性能高
- 缺点:ABA问题、自旋开销
实现示例
悲观锁(数据库行锁)
sql
SELECT * FROM product WHERE id=1 FOR UPDATE; -- 获取行锁
UPDATE product SET stock=stock-1 WHERE id=1;乐观锁(版本号)
sql
UPDATE product
SET stock=stock-1, version=version+1
WHERE id=1 AND version=1; -- 条件不满足则更新失败91. synchronized和lock的区别。Synchronize关键字修饰方法和修饰代码块的区别
synchronized vs Lock
| 特性 | synchronized | Lock(ReentrantLock) |
|---|---|---|
| 获取方式 | 隐式获取(进入同步块) | 显式调用lock()方法 |
| 释放方式 | 自动释放(退出同步块/异常) | 手动释放(unlock(),需finally) |
| 灵活性 | 低(不可中断、无超时) | 高(可中断、可超时、可尝试获取) |
| 性能 | JDK 6+优化后与Lock接近 | 高并发下性能更优 |
| 功能扩展 | 无 | 可实现公平锁、条件变量(Condition) |
| 底层实现 | 对象监视器(Monitor) | AQS框架(AbstractQueuedSynchronizer) |
synchronized修饰方法 vs 代码块
同步方法
java
// 实例方法:锁对象为this
public synchronized void instanceMethod() {}
// 静态方法:锁对象为类.class
public static synchronized void staticMethod() {}同步代码块
java
// 锁对象为指定对象
synchronized(obj) {
// 临界区
}
// 锁对象为this(等价于实例同步方法)
synchronized(this) {}
// 锁对象为类.class(等价于静态同步方法)
synchronized(MyClass.class) {}区别
- 锁粒度:代码块可精确控制锁范围(更小粒度)
- 性能:代码块减少锁持有时间,提高并发性
- 灵活性:代码块可指定任意锁对象,方法锁固定为this或类对象
92. 如何保证单例模式在多线程中的线程安全性
线程安全的单例实现方式
-
饿汉式:
javapublic class EagerSingleton { private static final EagerSingleton instance = new EagerSingleton(); private EagerSingleton() {} public static EagerSingleton getInstance() { return instance; } }- 类加载时初始化,天然线程安全
-
双重检查锁(DCL):
javapublic class LazySingleton { private volatile static LazySingleton instance; private LazySingleton() {} public static LazySingleton getInstance() { if (instance == null) { // 第一次检查 synchronized (LazySingleton.class) { if (instance == null) { // 第二次检查 instance = new LazySingleton(); } } } return instance; } }- volatile防止指令重排序,双重检查减少锁竞争
-
静态内部类:
javapublic class HolderSingleton { private static class Holder { private static final HolderSingleton instance = new HolderSingleton(); } public static HolderSingleton getInstance() { return Holder.instance; } }- 延迟初始化,类加载机制保证线程安全
-
枚举单例:
javapublic enum EnumSingleton { INSTANCE; // 单例方法 public void doSomething() {} }- 绝对线程安全,防反射和序列化攻击
93. 线程池的常见类型有那些?
Java线程池类型(Executors创建)
-
FixedThreadPool:固定线程数的线程池
javaExecutorService fixedPool = Executors.newFixedThreadPool(5);- 核心线程数=最大线程数,无超时,队列无界
- 适用:稳定并发场景
-
CachedThreadPool:可缓存线程池
javaExecutorService cachedPool = Executors.newCachedThreadPool();- 核心线程数0,最大线程数Integer.MAX_VALUE,60秒超时
- 适用:短期突发任务
-
SingleThreadExecutor:单线程线程池
javaExecutorService singlePool = Executors.newSingleThreadExecutor();- 保证任务顺序执行,无并发
- 适用:需串行执行的任务
-
ScheduledThreadPool:定时任务线程池
javaScheduledExecutorService scheduledPool = Executors.newScheduledThreadPool(3); scheduledPool.scheduleAtFixedRate(task, 1, 3, TimeUnit.SECONDS);- 支持延迟执行、周期执行
- 适用:定时任务、周期性任务
自定义线程池(推荐)
java
ThreadPoolExecutor executor = new ThreadPoolExecutor(
5, // 核心线程数
10, // 最大线程数
60, // 非核心线程超时时间
TimeUnit.SECONDS,
new LinkedBlockingQueue<>(100), // 任务队列
new ThreadPoolExecutor.CallerRunsPolicy() // 拒绝策略
);94. 线程池中线程的停止?
正确停止线程池的方法
-
优雅关闭(shutdown()):
javaexecutor.shutdown(); // 拒绝新任务,等待现有任务完成 -
立即关闭(shutdownNow()):
javaList<Runnable> unfinishedTasks = executor.shutdownNow(); // 尝试停止所有任务,返回未执行任务 -
等待关闭(awaitTermination()):
javaexecutor.shutdown(); if (executor.awaitTermination(1, TimeUnit.MINUTES)) { // 正常关闭 } else { // 超时处理 }
停止线程的错误方式
- 调用Thread.stop():已废弃,可能导致资源未释放
- 使用volatile标记:需配合循环检查,非原子操作
- interrupt()中断:需线程配合响应中断(检查isInterrupted())
线程协作停止
java
class Task implements Runnable {
private volatile boolean isStopped = false;
public void stop() {
isStopped = true;
}
public void run() {
while (!isStopped && !Thread.currentThread().isInterrupted()) {
// 任务逻辑
}
}
}95. 线程池中的线程数多少合适?
线程数确定原则
CPU密集型任务
- 公式:线程数 = CPU核心数 + 1
- 原因:减少线程上下文切换,充分利用CPU
- 示例:4核CPU → 5个线程
IO密集型任务
- 公式:线程数 = CPU核心数 × 2 × (1 + IO耗时/CPU耗时)
- 原因:线程等待IO时可切换执行其他任务
- 示例:4核CPU,IO耗时:CPU耗时=10:1 → 4×2×(1+10)=88线程
实际调整策略
- 监控指标:CPU利用率、等待队列长度、任务完成时间
- 逐步调整:从理论值开始,根据性能测试优化
- 考虑因素 :
- 内存限制(线程栈占用内存)
- 任务类型混合(CPU+IO)
- 第三方服务瓶颈(如数据库连接数)
工具推荐
- 使用JDK自带工具:jstack、jconsole
- 第三方监控:VisualVM、Arthas
96. 线程池一般是自动创建的还是手动?为什么?
推荐手动创建线程池
原因:
-
避免资源耗尽风险:
- Executors默认线程池存在隐患:
- FixedThreadPool/CachedThreadPool使用无界队列,可能堆积任务导致OOM
- CachedThreadPool最大线程数为Integer.MAX_VALUE,可能创建过多线程
- Executors默认线程池存在隐患:
-
精细化控制:
- 手动配置核心参数:核心线程数、最大线程数、队列容量、拒绝策略
- 根据业务场景定制(如IO密集型/CPU密集型)
-
明确拒绝策略:
- 自定义任务拒绝处理(如CallerRunsPolicy、AbortPolicy)
手动创建示例
java
ThreadPoolExecutor executor = new ThreadPoolExecutor(
5, // corePoolSize
10, // maximumPoolSize
60L, TimeUnit.SECONDS, // keepAliveTime
new LinkedBlockingQueue<>(100), // workQueue
Executors.defaultThreadFactory(), // threadFactory
new ThreadPoolExecutor.CallerRunsPolicy() // handler
);结论
生产环境中禁止使用Executors创建线程池,必须手动创建ThreadPoolExecutor,显式指定所有参数。
97. ReentrantLock和synchronized的区别是什么
核心区别
| 特性 | ReentrantLock | synchronized |
|---|---|---|
| 锁获取方式 | 显式(lock()) | 隐式(进入同步块) |
| 锁释放方式 | 显式(unlock(),需finally) | 自动释放 |
| 可中断性 | 可中断(lockInterruptibly()) | 不可中断 |
| 超时获取 | 支持(tryLock(time)) | 不支持 |
| 公平锁 | 可配置(构造参数fair=true) | 非公平锁 |
| 条件变量 | 支持(Condition) | 不支持 |
| 性能 | 高并发下更优 | JDK 6+优化后接近Lock |
| 底层实现 | AQS框架 | 对象监视器(Monitor) |
Condition条件变量示例
java
Lock lock = new ReentrantLock();
Condition notEmpty = lock.newCondition();
Condition notFull = lock.newCondition();
// 生产者
lock.lock();
try {
while (queue.size() == capacity) {
notFull.await(); // 队列满则等待
}
queue.add(item);
notEmpty.signal(); // 通知消费者
} finally {
lock.unlock();
}使用场景选择
- 简单同步:使用synchronized(简洁、不易出错)
- 高级功能(超时、中断、条件变量):使用ReentrantLock
- 高并发读多写少:考虑ReentrantReadWriteLock
98. 什么是死锁?如何避免死锁?
死锁定义
多个线程因竞争资源而造成的互相等待的僵局,若无外力作用,线程将永远阻塞。
死锁必要条件
- 互斥条件:资源不可共享
- 请求与保持:持有部分资源并等待其他资源
- 不可剥夺:资源不可强行剥夺
- 循环等待:形成资源等待环路
死锁示例
java
// 线程A
synchronized (lockA) {
Thread.sleep(100);
synchronized (lockB) { ... } // 等待lockB
}
// 线程B
synchronized (lockB) {
Thread.sleep(100);
synchronized (lockA) { ... } // 等待lockA
}避免死锁措施
- 固定加锁顺序:所有线程按相同顺序获取锁
- 使用tryLock超时 :
if (lock.tryLock(1, TimeUnit.SECONDS)) {} - 减少锁持有时间:缩小同步块范围
- 使用无锁并发:原子类、ConcurrentHashMap
- 死锁检测 :
- jstack命令查看线程状态
- 编码时使用LockSupport检测
99. Java 中线程间通信有哪些方式
线程间通信方式
-
共享内存:
- 共享变量(需同步机制保证线程安全)
- 示例:
volatile boolean flag控制线程执行
-
等待/通知机制:
- Object.wait()/notify()/notifyAll()
- Condition.await()/signal()
-
管道流:
- PipedInputStream/PipedOutputStream
- 适用于线程间字节流通信
-
Thread.join():
- 等待另一个线程执行完毕
javaThread t = new Thread(() -> { ... }); t.start(); t.join(); // 等待t线程结束 -
ThreadLocal:
- 线程私有变量,间接实现线程隔离
- 适用于线程上下文传递(如用户会话)
-
并发工具类:
- CountDownLatch:计数器等待
- CyclicBarrier:线程同步屏障
- Semaphore:信号量控制并发数
等待/通知机制示例
java
Object lock = new Object();
// 线程A等待
synchronized (lock) {
while (condition) {
lock.wait(); // 释放锁并等待
}
}
// 线程B通知
synchronized (lock) {
condition = false;
lock.notify(); // 唤醒等待线程
}