首先,我们需要一个linux,由于咱们的centos改为滚动更新,已经不太适合部署了,一开始想用下游替代AlmaLinux结果virtualbox不好用,那就只能使用地道的ubuntu(ubuntu Server 24.04.3 LTS)吧
有些东西在大多数的教程内没讲全,我把他们汇总起来并且进行了更正
比如root和普通用户的path问题,3.3.6版本不支持root用户直接启动问题,并且大多数教程是面向你拥有很多主机的情况
我这里是直接面向仅一台主机的情况,在学习上成本更小甚至为0
这里为什么使用ubuntu Server 24.04.3 LTS而不是常规ubuntu呢?
因为我电脑差...
安装linux
我给他分了4GB内存 4核心 40GB硬盘

第一步


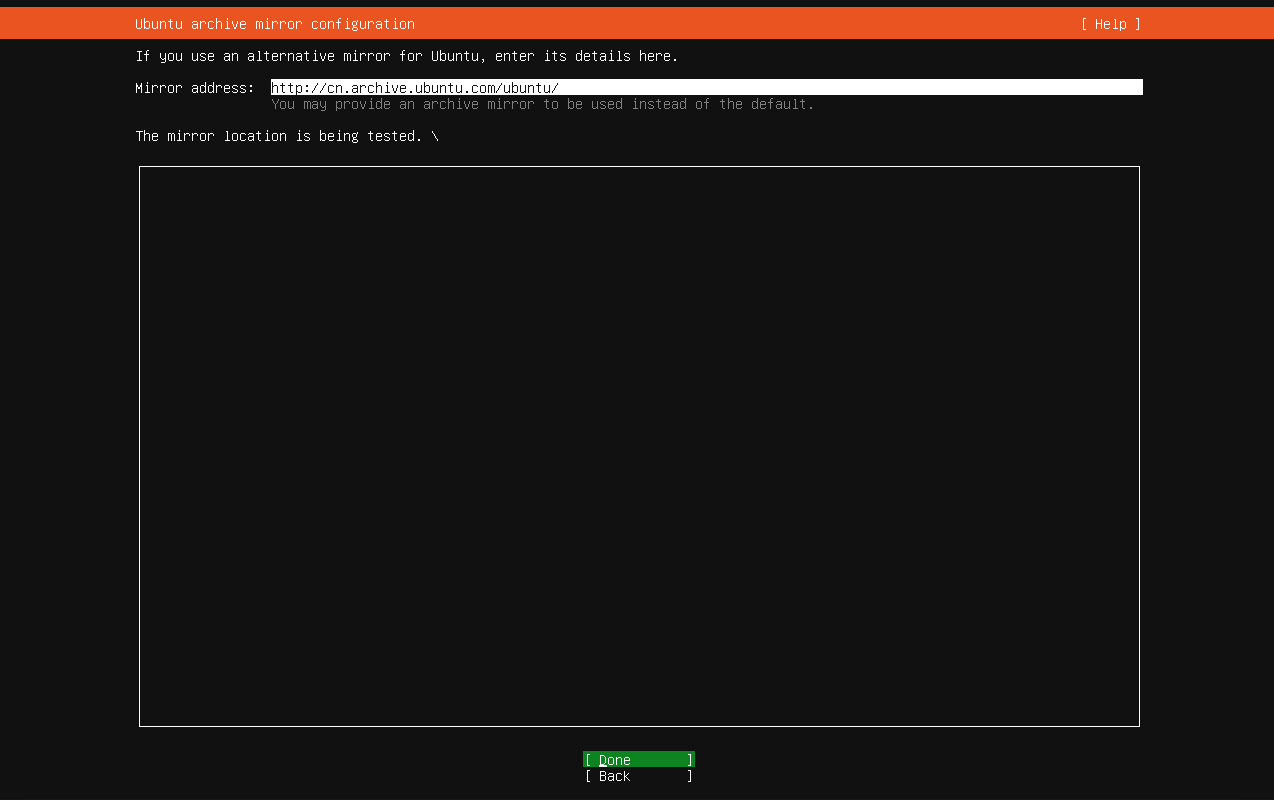



这里下面要空格点一下安装openssh

然后是安装软件,可以都不安,我就不安了,我空间不够了

然后就安装了
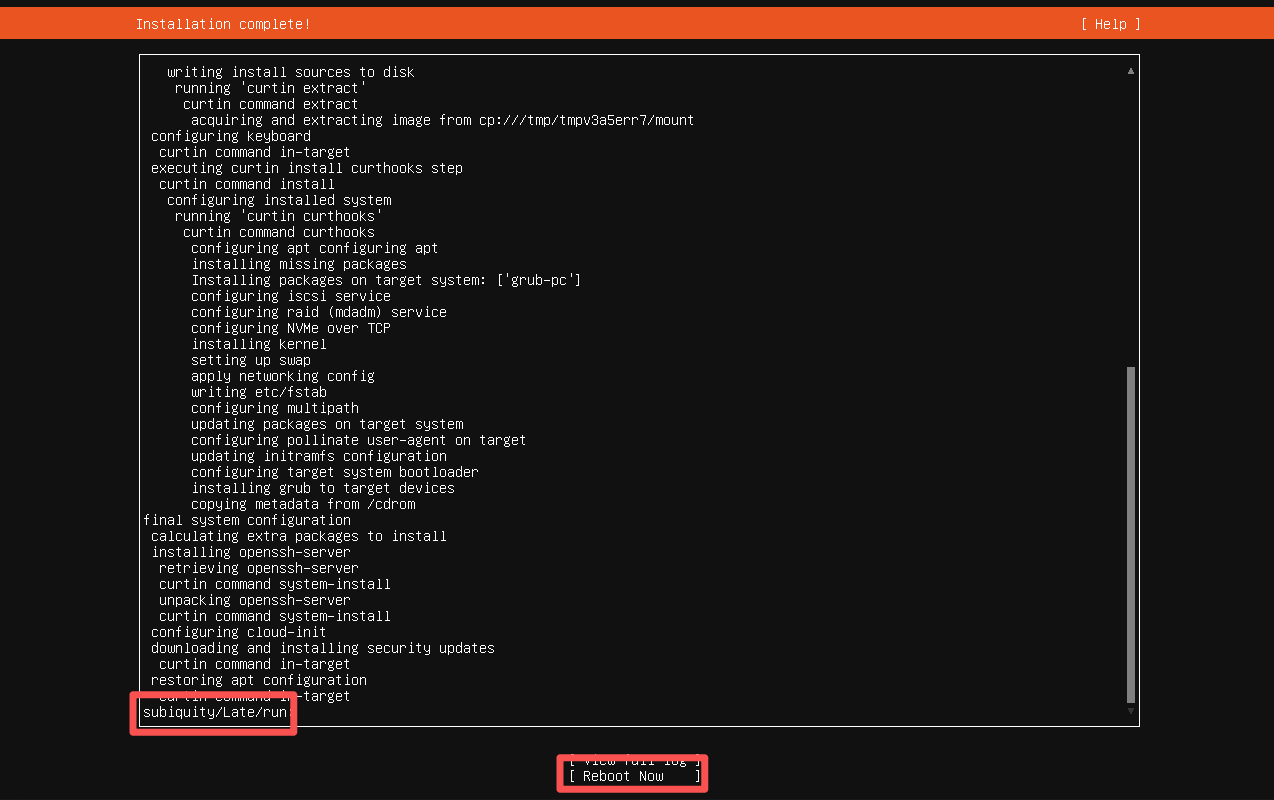
弹出这个点reboot now
此时正式开机,注意,如果你也用的virtualbox需要强制关机一次

然后输入账号密码登录
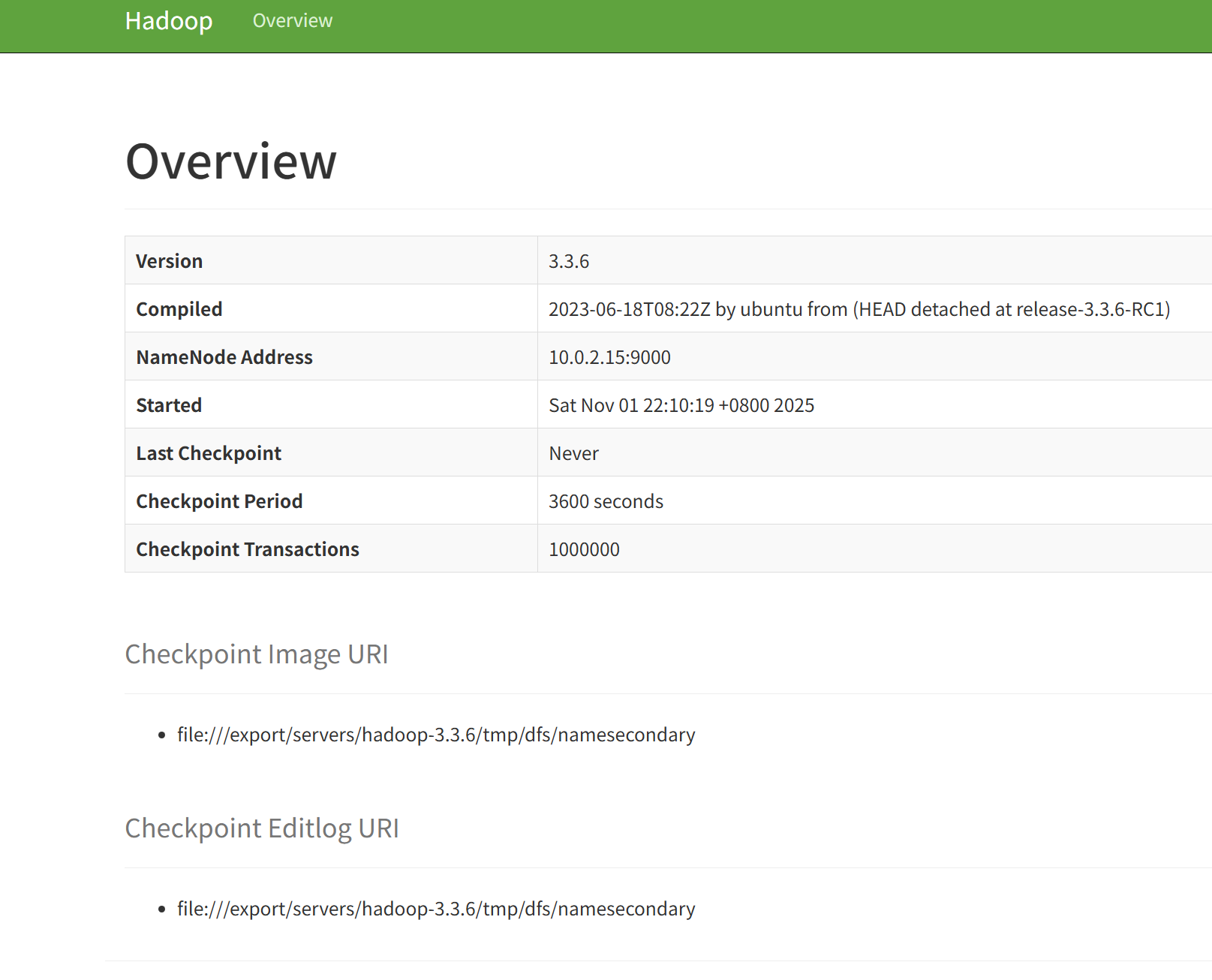
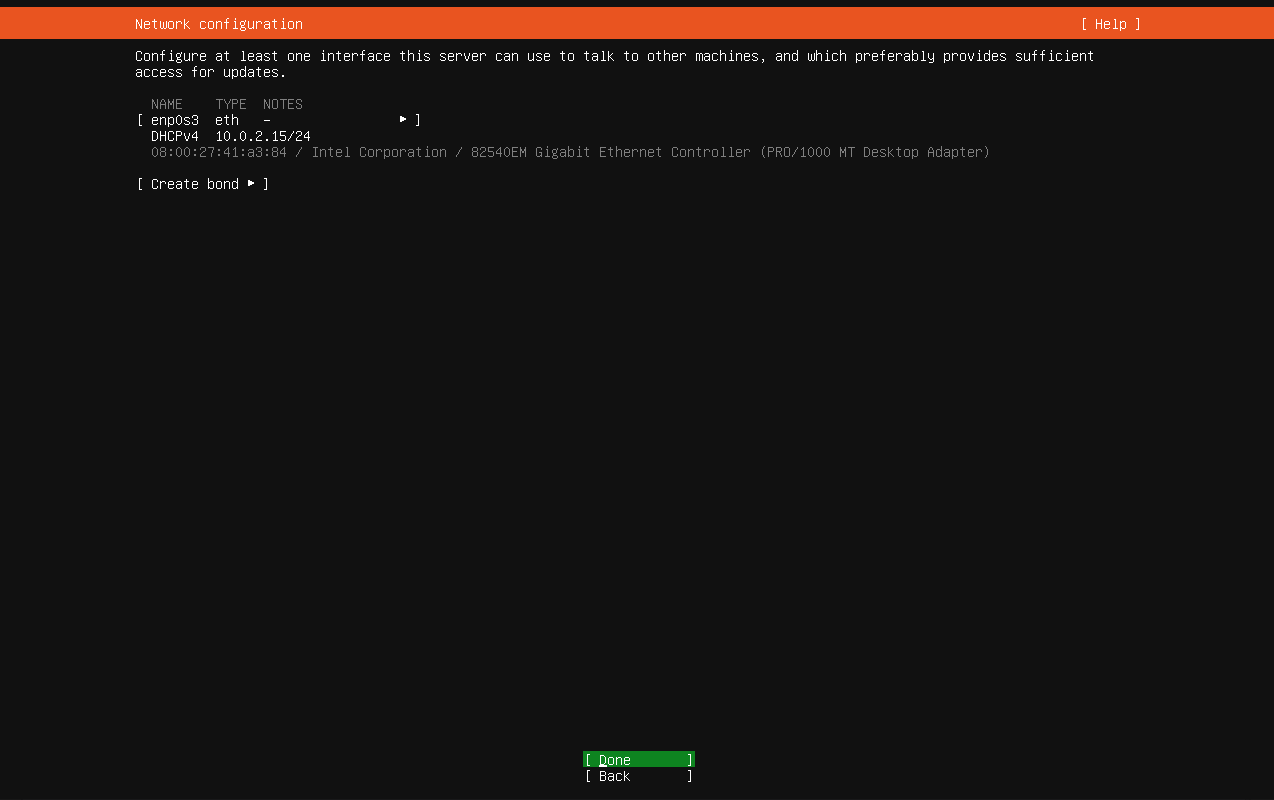
查看ip地址(使用ip addr命令)
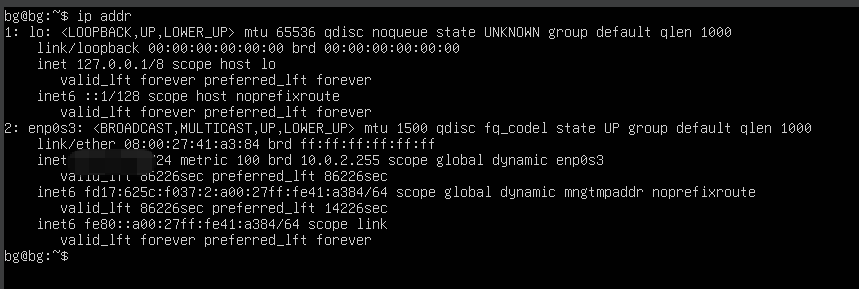
打码处是ip
然后设置为NAT和端口转发
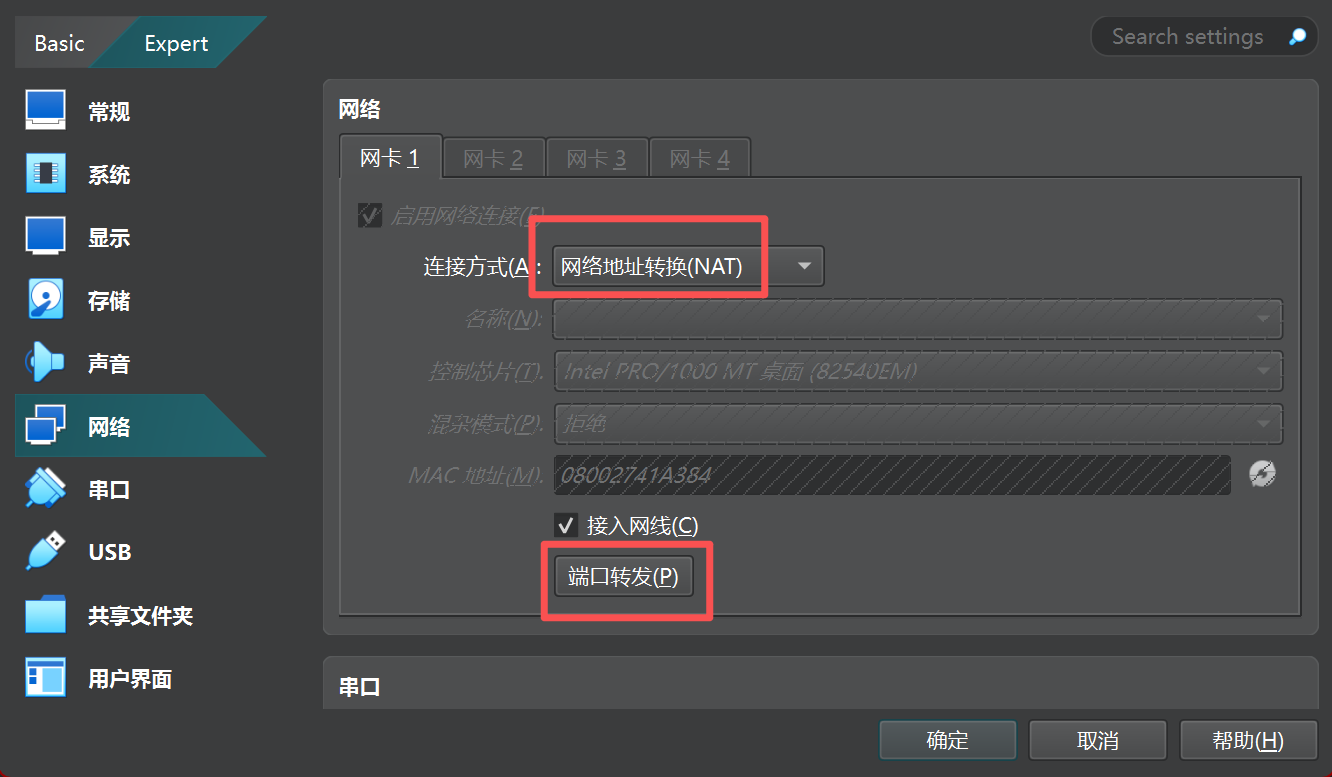
然后配置22端口转发

第二步,超级ssh
使用xshell

然后新建一下目录备用
bash
cd /
sudo mkdir -p /export/{data,servers,software}
接下来我们要传软件,提权一下
bash
sudo chmod 777 /export
sudo chmod 777 /export/software然后传输
然后
bash
sudo su
# 直接化身root权限
# 超级解压
cd /export/software
tar -zxvf jdk-8u391-linux-x64.tar.gz -C /export/servers/
# 超级改名
cd /export/servers
mv jdk1.8.0_391 jdk然后超级配置
bash
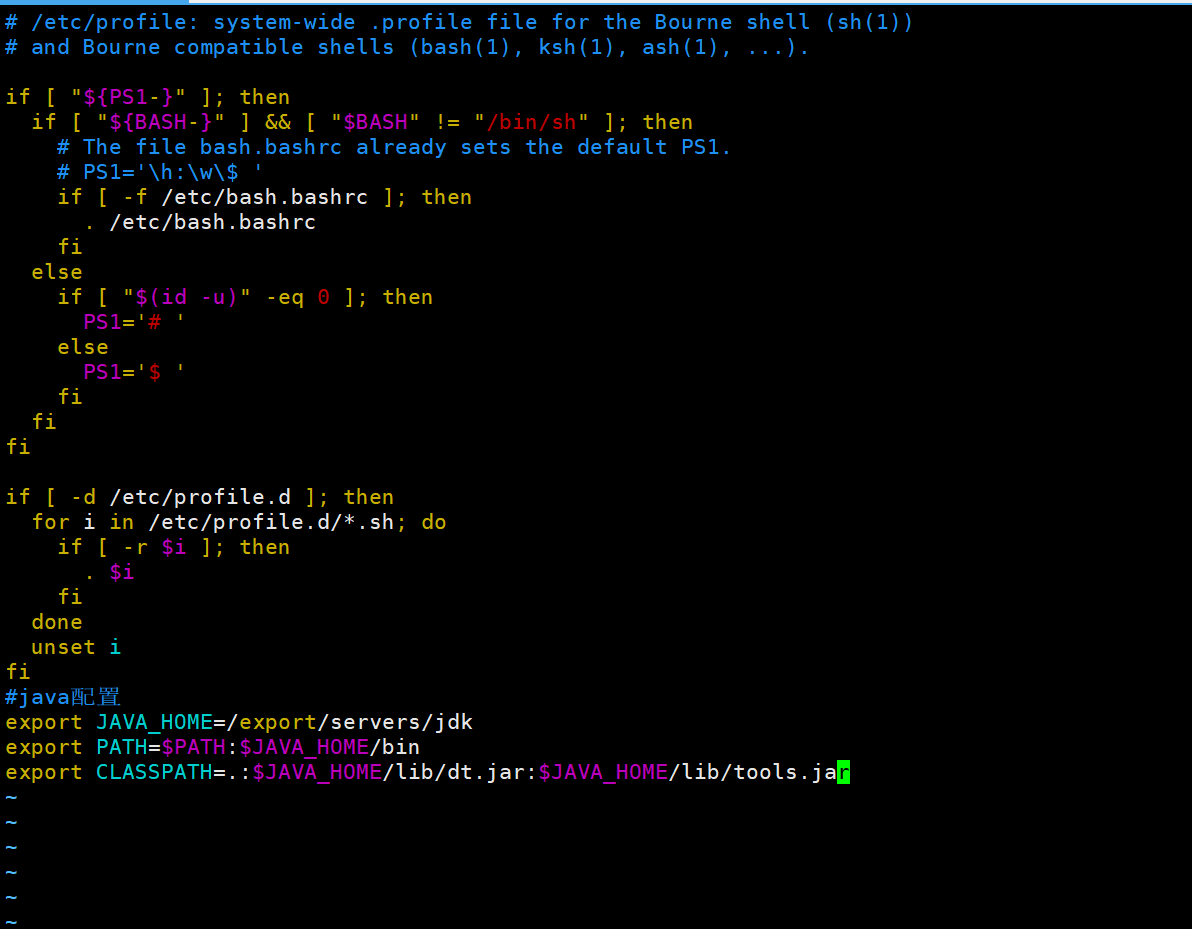
vim /etc/profile然后在打开的文件按下键盘i,并且移动到最下面输入
bash
#java配置
export JAVA_HOME=/export/servers/jdk
export PATH=$PATH:$JAVA_HOME/bin
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar大概是这个样子
然后esc,按下:wq!退出
之后强制激活
bash
source /etc/profile第三步,超级安装
现在有了jdk(java)就可以安装hadoop了
bash
cd /export/software
tar -zxvf hadoop-3.3.6.tar.gz -C /export/servers/同样的方法配置hadoop
bash
vim /etc/profile
# 在打开的文件内
#hadoop配置
export HADOOP_HOME=/export/servers/hadoop-3.3.6
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
bash
source /etc/profile第四步,去你的权限
然后这里有个小坑
就是root中权限太大了,需要单独开个java_home
bash
cd /export/servers/hadoop-3.3.6/etc/hadoop/
vim hadoop-env.sh
#然后找到export JAVA_HOME= 改成export JAVA_HOME=/export/servers/jdk
#或者直接最后一行加export JAVA_HOME=/export/servers/jdk然后修改core-site.xml
bash
vim core-site.xml
# 找到<configuration>
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop01的名称:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/export/servers/hadoop-3.3.6/tmp</value>
</property>
</configuration>
同理
bash
vim hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop02的名称:50090</value>
</property>
</configuration>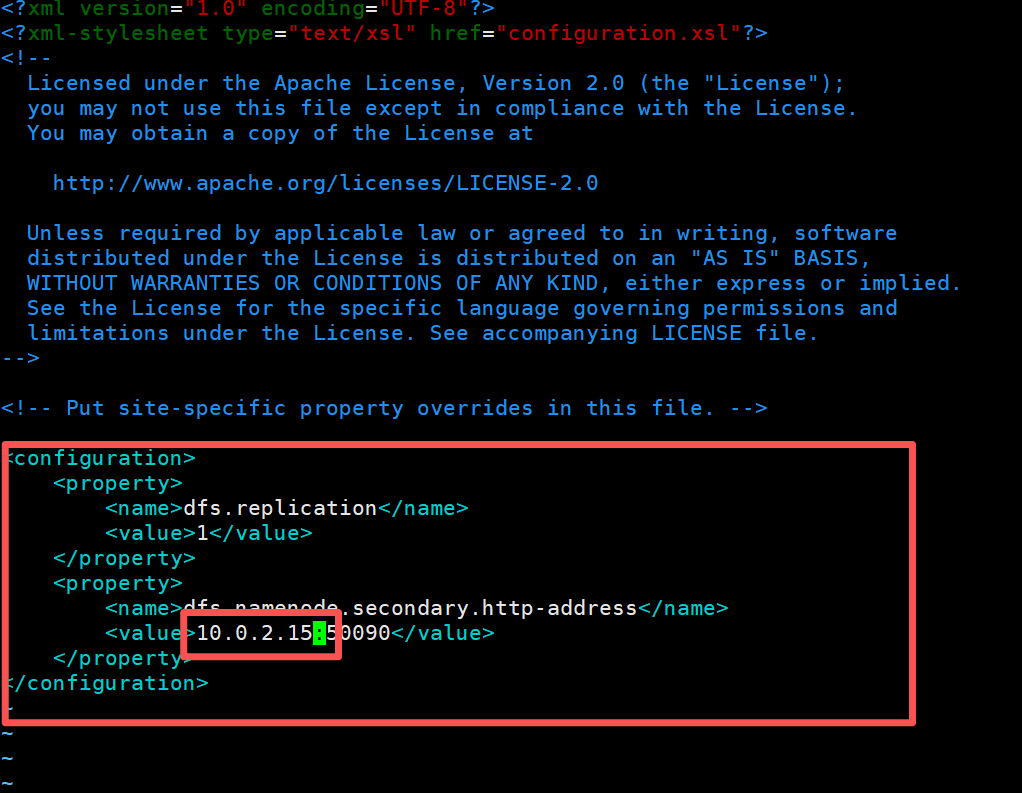
bash
vim mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
bash
vim yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop01主机</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>如果要组集群可以修改
bash
vim workers然后记得给一下用户权限
先su 一开始你创建的用户
bash
ssh-keygen -t rsa -P ""
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 700 ~/.ssh
chmod 600 ~/.ssh/authorized_keys并且对你当前用户的
bash
vim ~/.bashrc
#然后末尾java和hadoop第五步,超级格式化
bash
hdfs namenode -format最后,端口转发
然后转发一下50090 50070 9000端口就好啦