目录
一、框架调研
|-------------------|--------------------------------------|------------|
| 工具 | 优势 | 典型场景 |
| Kiln | 零代码+协作功能 | 快速原型开发 |
| Unsloth | 训练加速+低显存需求 | 低成本微调大模型 |
| LLaMA-Factory | 可视化调参界面+多模型支持+多种训练方式 | 行业专用模型快速落地 |
| PEFT | 参数高效+资源节省 | 大规模模型轻量化适配 |
| transformers | Hugging Face生态完备+社区支持 | 从实验到生产全流程 |
| Axolotl | 支持多种数据集格式以及自定义格式 | |
| Firefly | 验证了 QLoRA 训练流程的有效性 | |
| XTuner | 支持多节点跨设备微调更大尺度模型 | |
| ms-swift | 支持450+大模型与150+多模态大模型的训练、推理、评测、量化与部署。 | |
这里选用微调工具为:**LLaMA-Factory。**除此上述优势外,开发者多,文档资料足,比较容易上手。
文档可参考:https://llamafactory.readthedocs.io/zh-cn/latest/getting_started/sft.html
二、搭建环境
LLaMA-Factory 的 Github地址:https://github.com/hiyouga/LLaMA-Factory
-
创建 conda 虚拟环境(一定要 3.10 的 python 版本,不然和 LLaMA-Factory 不兼容)
conda create -n llama-factory python=3.10
-
激活虚拟环境
conda activate llama-factory
-
直接从源码安装
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
pip install -e ".[torch,metrics]" --no-build-isolation -
检验是否安装成功
llamafactory-cli version
-
启动 LLama-Factory 的可视化微调界面 (由 Gradio 驱动)
llamafactory-cli webui
三、准备数据集
llamafactory会去找json文件,而数据集信息则保持在json文件中
一般来说,json取名为:dataset_info.json
微调指令中的对应字段为:--dataset_dir /data/thomascai/codes/LLaMA-Factory-0.9.3/datasets 下一层就是 dataset_info.json
如果图形化训练界面,则

在data下会去搜索**dataset_info.json**文件。
这里以图像文本数据集为例:
-
**
dataset_info.json**的内容{
"dataset_name": {
"file_name": "dataset_name.json",
"formatting": "sharegpt",
"columns": {
"messages": "messages",
"images": "images"
},
"tags": {
"role_tag": "role",
"content_tag": "content",
"user_tag": "user",
"assistant_tag": "assistant"
}
}
} -
跟**
dataset_info.json** 同级目录下则有 **dataset_name.json**文件[
{
"messages": [
{ "role": "user", "content": "\n看这张图片,里面是什么?" },
{ "role": "assistant", "content": "这是一个矿泉水瓶。" }
],
"images": [
"images/img_0001.jpg"
]
},
{
"messages": [
{ "role": "user", "content": "\n请帮我识别这张图片中的物体。" },
{ "role": "assistant", "content": "是一瓶可乐。" }
],
"images": [
"images/img_0002.jpg"
]
}
]
准备好数据集后,即可以开始训练。
四、开始训练
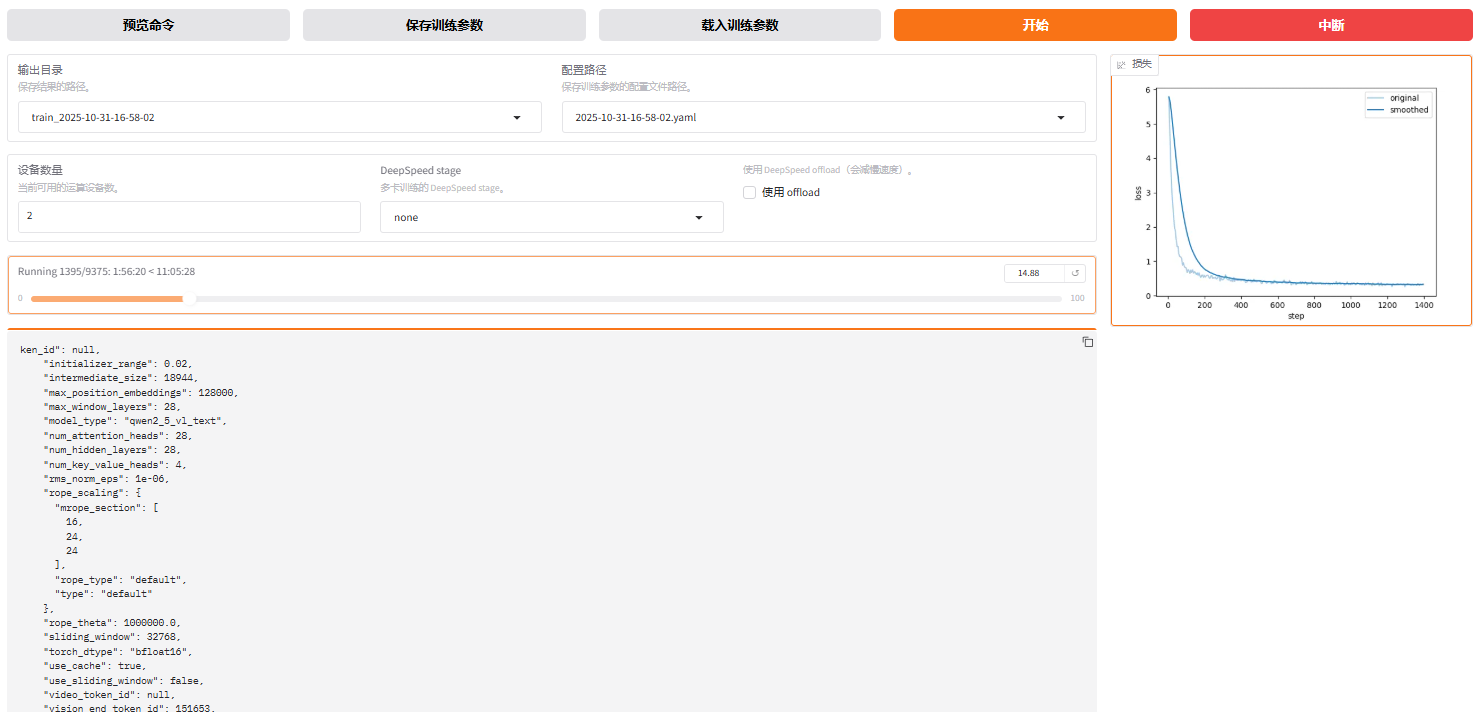
一般入门来说,图像化界面训练即可。
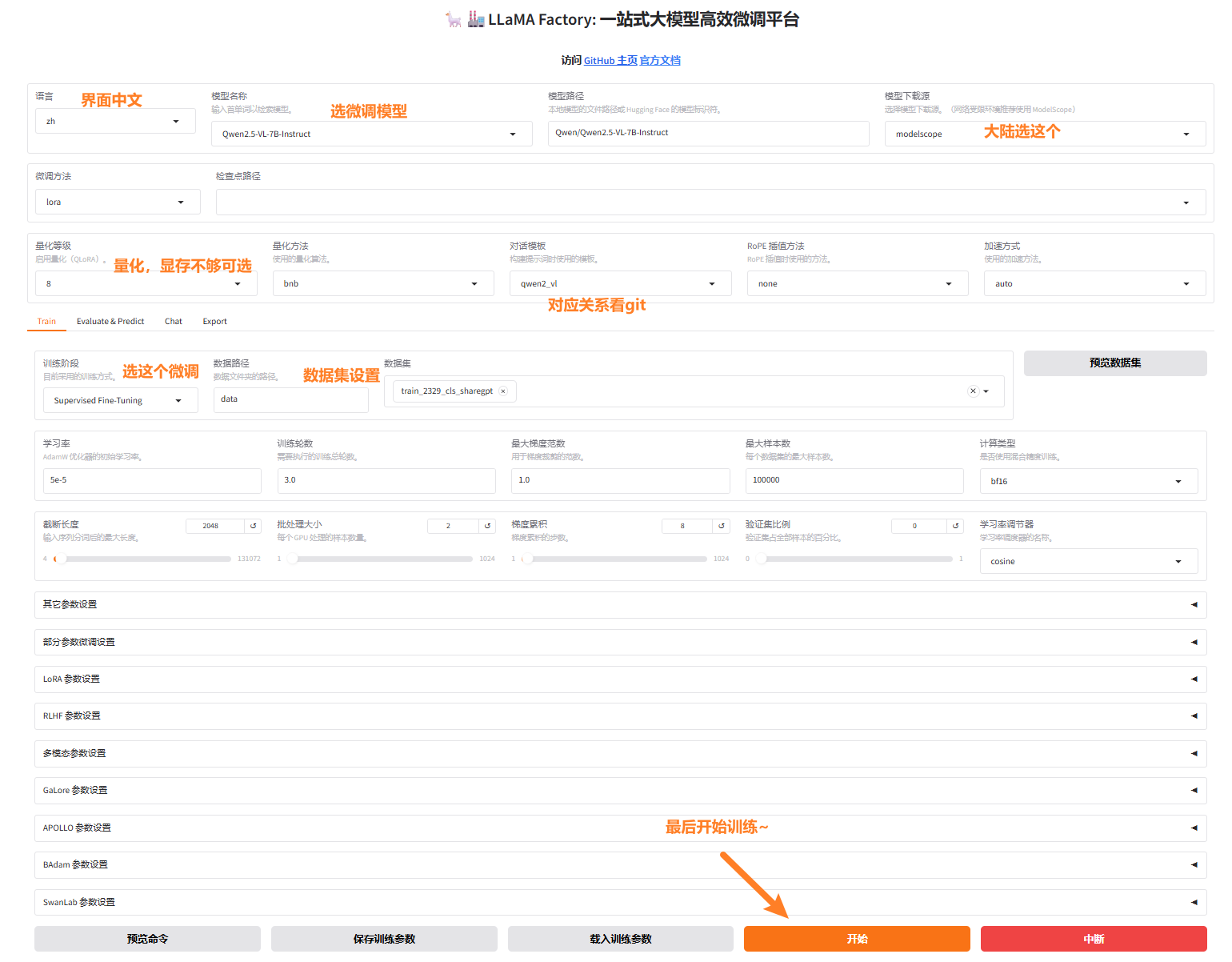
然后往下会生成损失曲线: