数据标准化是使用统计学的手段对数据样本执行一定范围的缩放,使数据元素保持在一定的范围之内,标准化的数据集合在数据分析以及图表绘制中,更加容易地体现出数据的固有特性。
算法RobustScaler的计算公式:(数据元素-中位数)/(第三分数位-第一分数位),例如,给定排序后的数据集合1,3,6,8,9,13,集合的大小为6,先计算中位数(第二分数位),集合的大小为奇数,中位数是中间位置的数据元素,集合的大小为偶数,则中位数是中间两个数据元素的均值,则中位数(6+8)/2等于7,计算第一分数位的位置(1+6)/4等于1.75,即在第1与第2个数之间的位置,则第一分数位(1+0.75*(3-1))等于2.5,计算第三分数位的位置((1+6)*3)/4等于5.25,即在第5与第6个数之间的位置,即第三分数位(9+0.25*(13-9))等于10,则使用算法RobustScaler的计算公式对数据集合实现缩放的输出数据集合-0.8,-0.53...,-0.13...,0.13...,0.26...,0.8。
Java代码示例
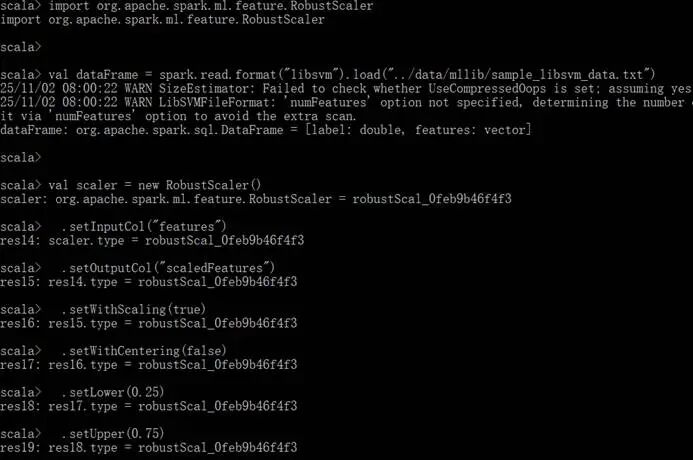
创建算法RobustScaler测试类,初始化spark实例:

加载数据分类libsvm的标准测试数据集合:

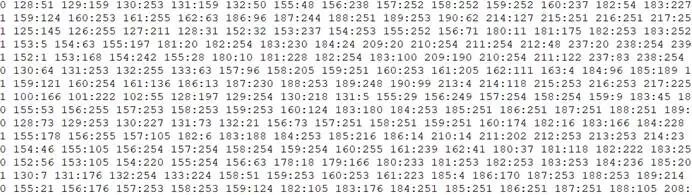
数据分类libsvm的标准测试数据集合的部分数据样本,其中,第一列是标签,用于标识数据的分类,其他列是特征数据(特征值对应的索引号:特征值):
创建算法RobustScaler实例,设置输入输出数据列的名称,设置分数位参数:

创建算法RobustScaler模型实例,用于对向量数据集合执行特征转换:
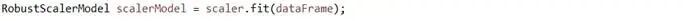
使用算法RobustScaler模型实例执行特征转换,输出标准化的向量数据集合:

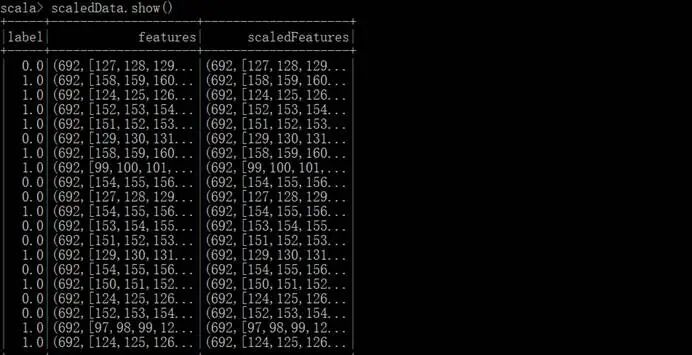
特征转换输出的部分数据样本,其中,第一列是标签,692是特征值的总数,特征值对应的索引号集合,特征转换的标准缩放的数据集合:
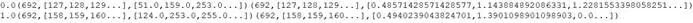
Scala代码示例
与Java代码示例的功能逻辑相同:

启动spark-shell的Scala本地运行环境:
运行RobustScaler算法代码:
特征转换输出的数据集合: