注意:该项目只展示部分功能,如需了解,文末咨询即可。
本文目录
- [1 开发环境](#1 开发环境)
- [2 系统设计](#2 系统设计)
- [3 系统展示](#3 系统展示)
- [3.1 功能展示视频](#3.1 功能展示视频)
- [3.2 大屏页面](#3.2 大屏页面)
- [3.3 分析页面](#3.3 分析页面)
- [3.4 基础页面](#3.4 基础页面)
- [4 更多推荐](#4 更多推荐)
- [5 部分功能代码](#5 部分功能代码)
1 开发环境
发语言:python
采用技术:Spark、Hadoop、Django、Vue、Echarts等技术框架
数据库:MySQL
开发环境:PyCharm
2 系统设计
随着全球旅游业数字化转型加速,携程平台上的海外酒店用户评价数据呈现爆发式增长,传统分析手段难以处理包含文本、数值、时序等多维度的海量异构数据。本系统针对19,497条新加坡、日本、韩国等热门目的地酒店评价记录,基于Python生态与Hadoop/Spark分布式计算框架,构建从数据预处理、深度挖掘到可视化决策支持的完整分析链路,旨在突破单机处理瓶颈,实现用户行为画像精准刻画、服务质量智能诊断、情感倾向动态追踪及市场趋势预测,为酒店运营商优化服务策略、平台方提升推荐精度、消费者科学决策提供量化依据,推动酒店行业从经验驱动向数据驱动的智能化升级。
系统聚焦六大分析模块实现业务价值。用户行为画像模块通过点评数分层识别不同群体评分特征,结合入住季节与出行目的交叉分析揭示家庭亲子用户在暑期的高峰偏好,并评估高活跃度用户的意见领袖影响力。酒店服务质量评价模块验证星级与体验匹配度,对比酒店官方评分与用户评分的系统性差异,定位差评文本中的设施老化、服务响应迟缓等具体问题。情感倾向与满意度分析模块运用NLP技术提取"位置便利""泳池干净"等高频关键词,构建情感-评分一致性检验机制,对占比1%的极值差评建立预警看板。市场竞争力分析模块按价格区间与目的地聚合计算市场份额,识别新加坡中高端酒店的供需缺口。时间序列预测模块基于数据分解评分趋势与季节性波动,为动态定价提供价格敏感度时变模型。综合评价指数模块融合用户评分、文本情感值、价格偏离度构建酒店竞争力指数,支持标杆酒店筛选与改进优先级排序,全链路输出从数据清洗到商业决策的可执行洞察。
3 系统展示
3.1 功能展示视频
基于情感分析+spark大数据的携程酒店用户评价数据可视化 !!!请点击这里查看功能演示!!!
3.2 大屏页面
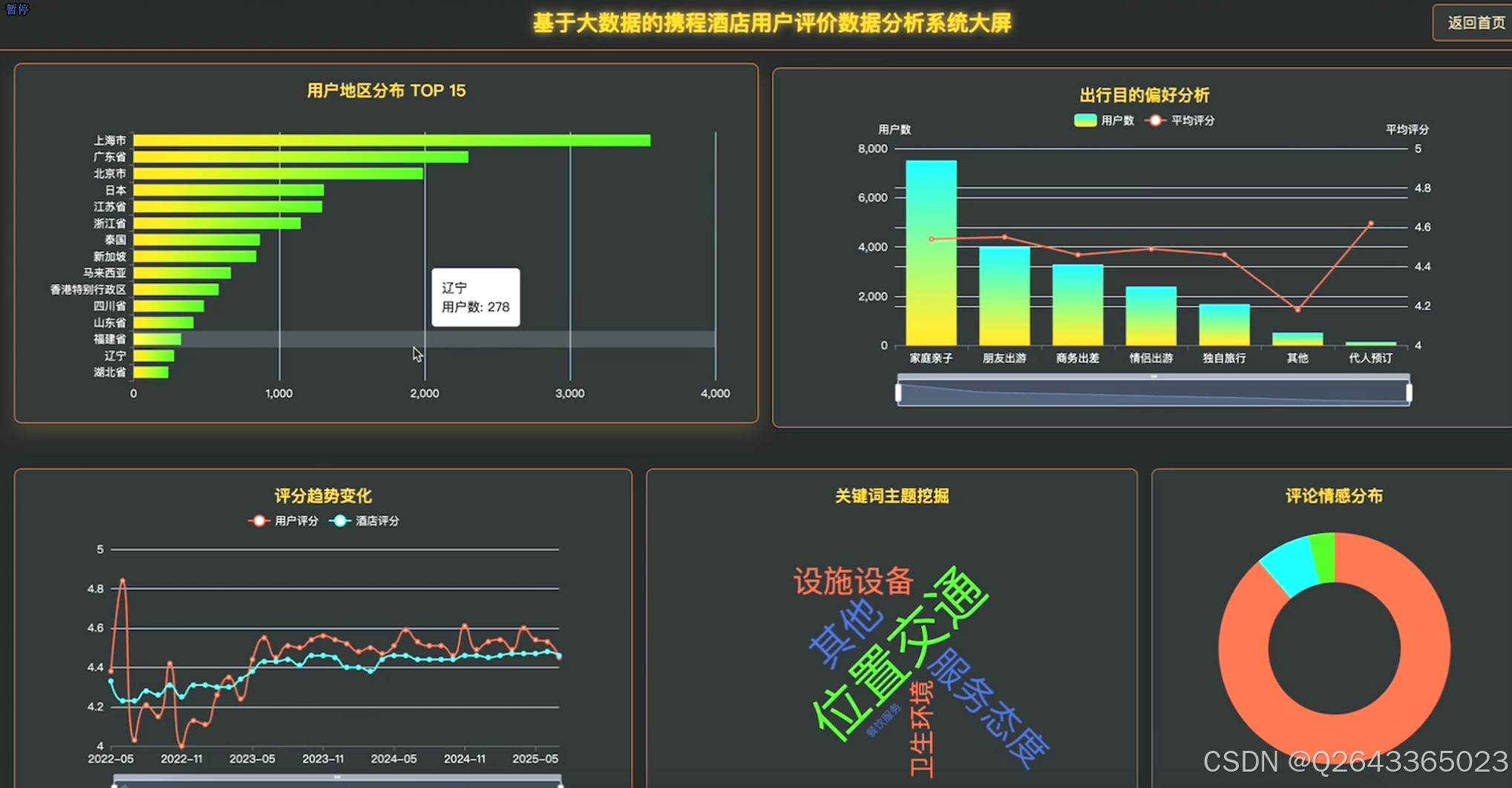
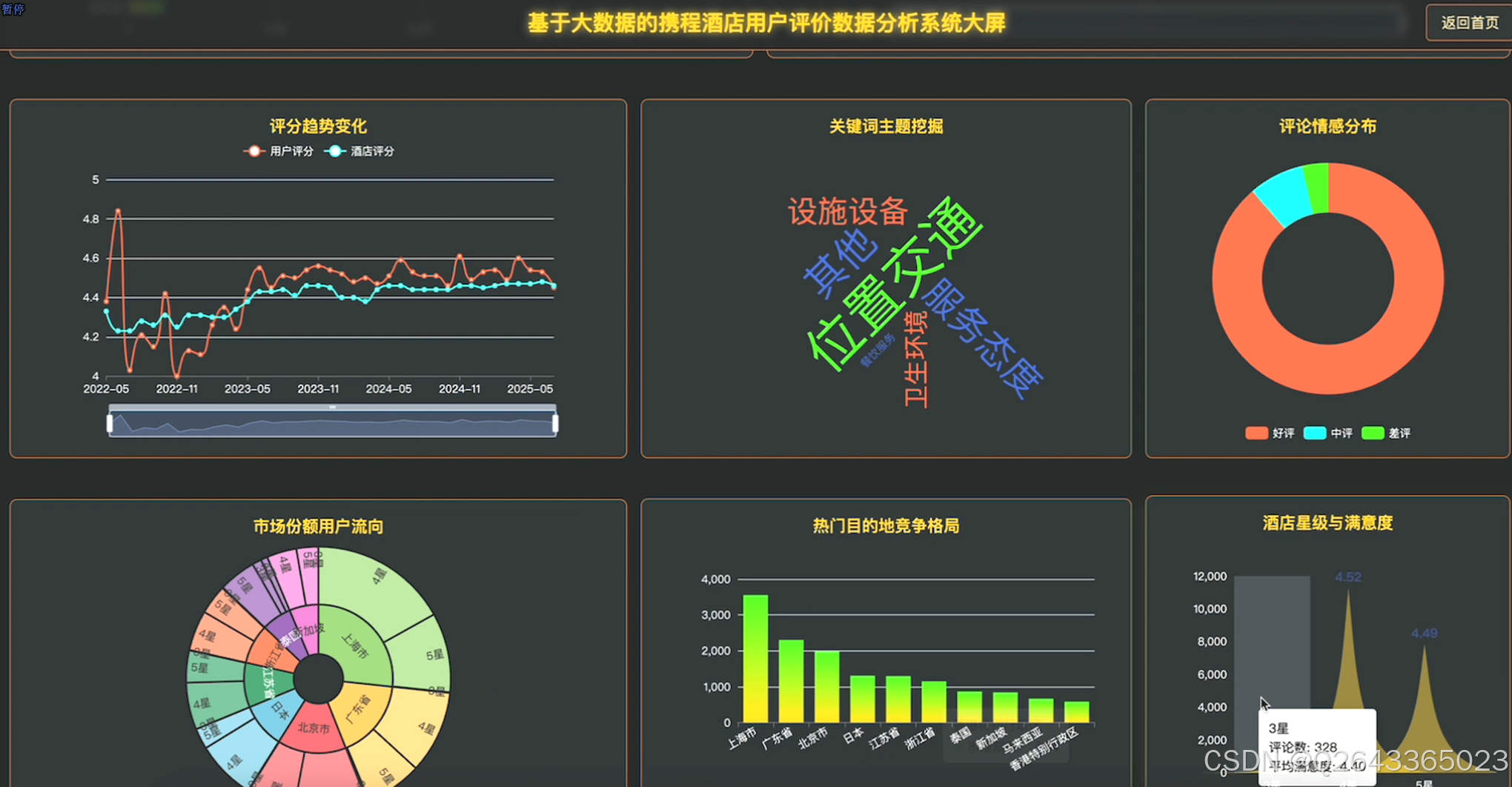
3.3 分析页面
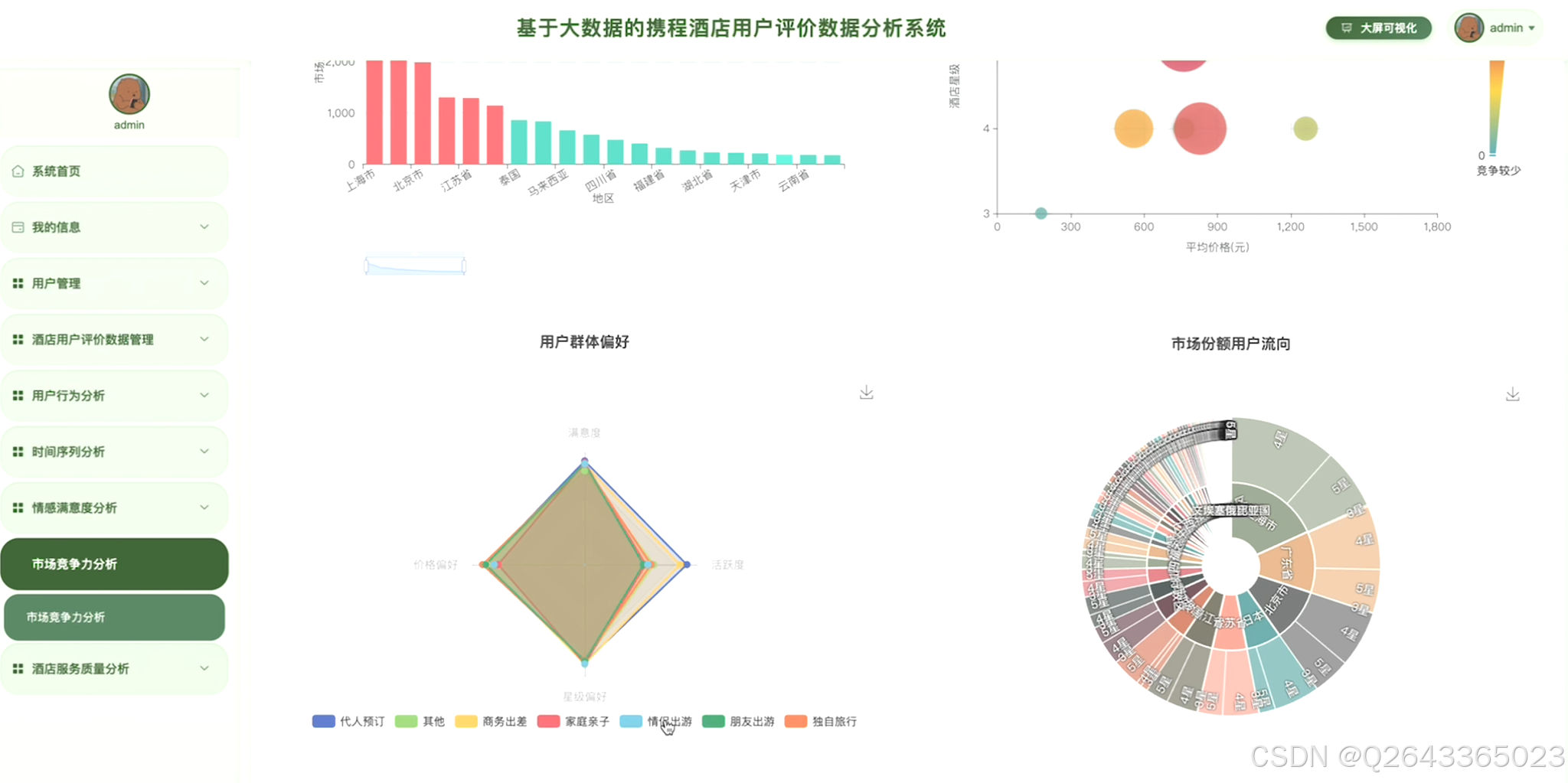
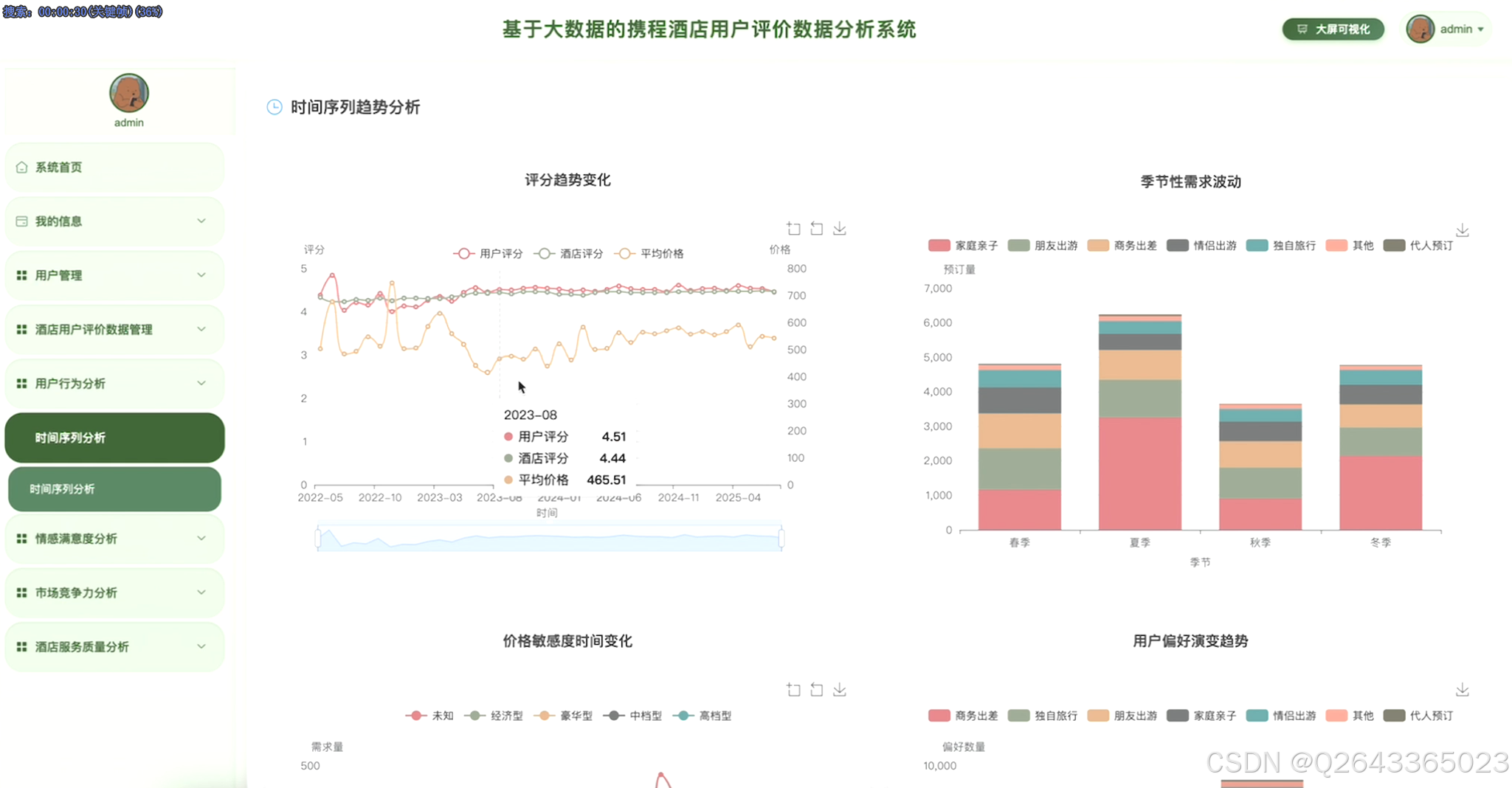
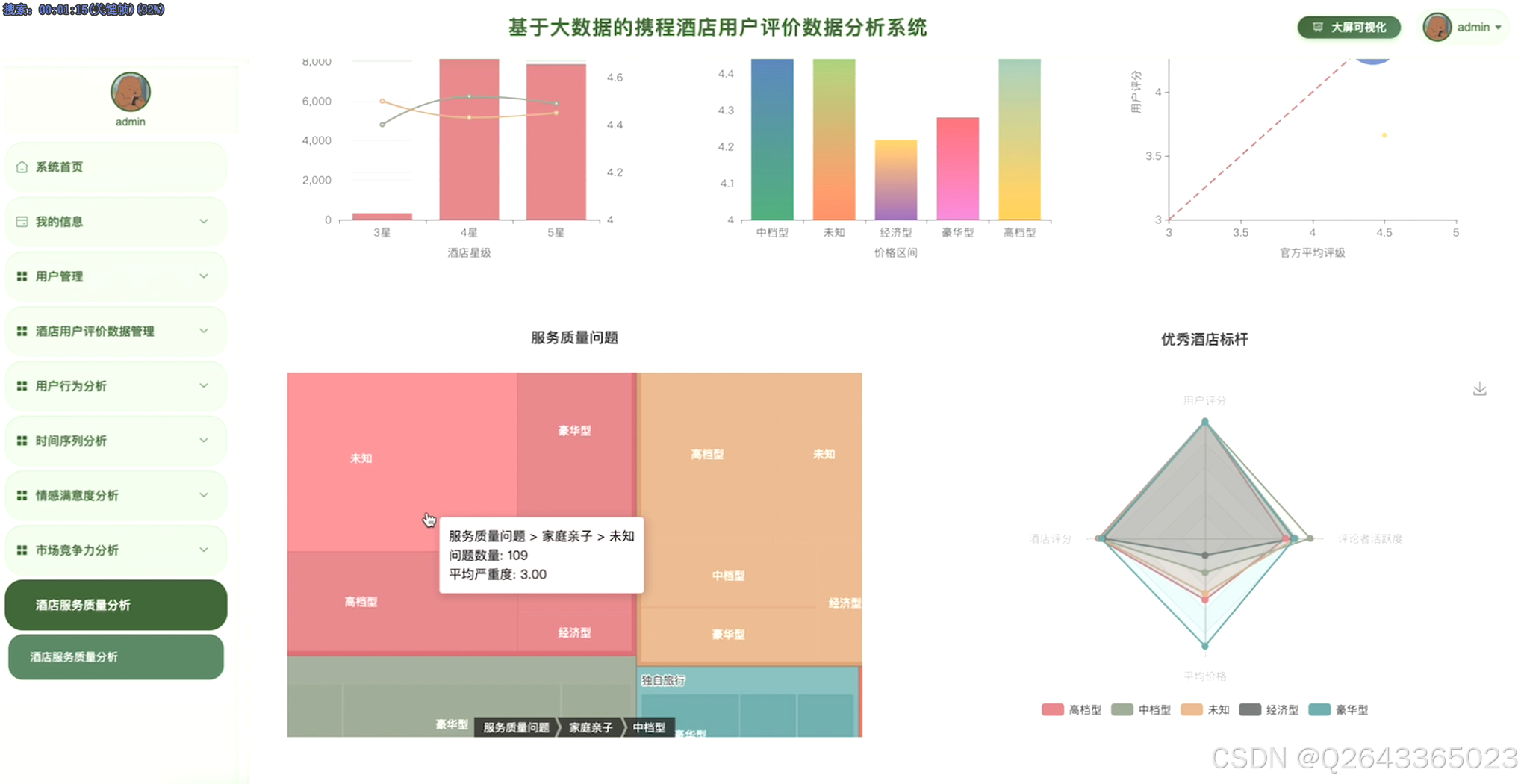
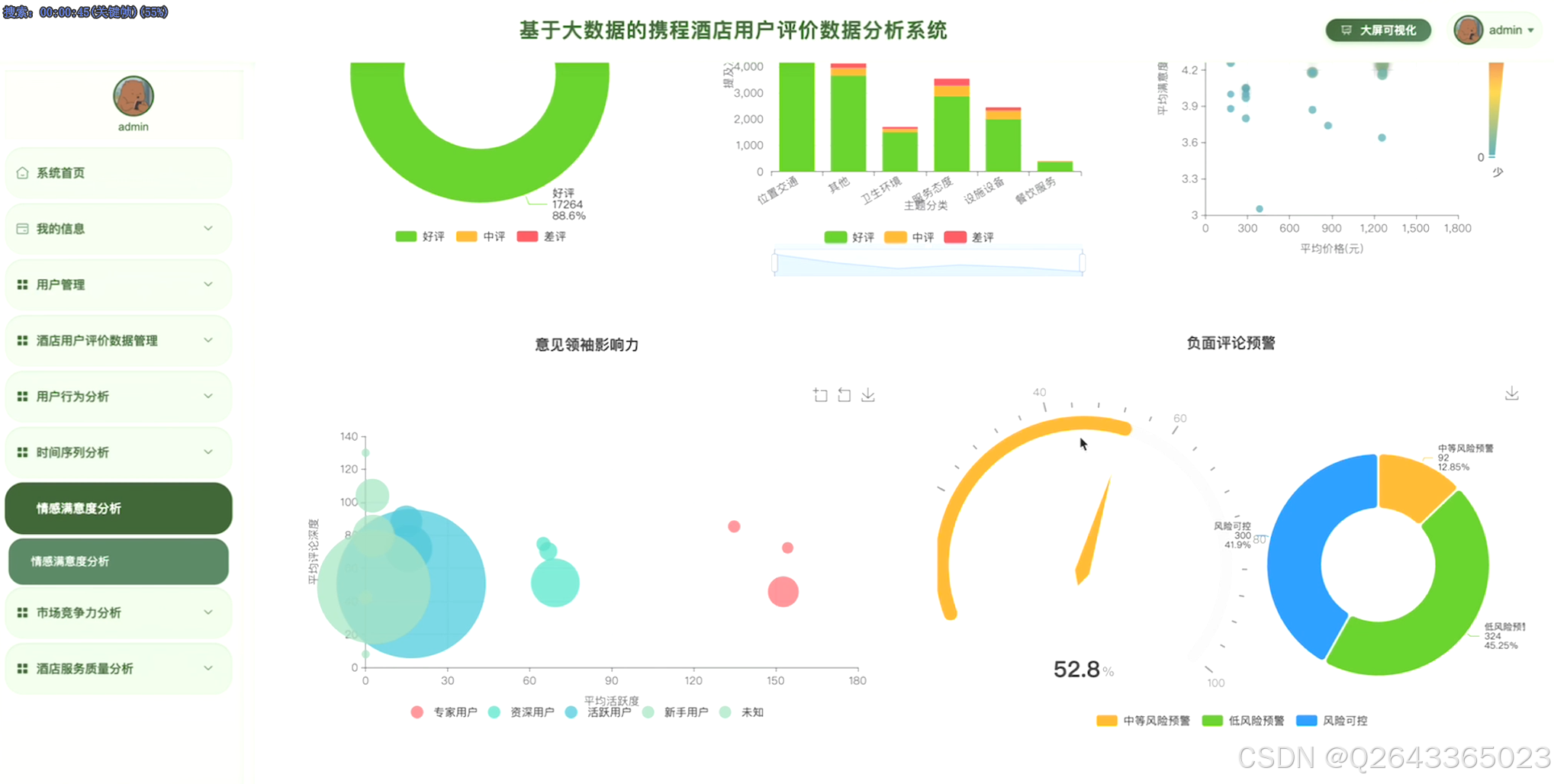
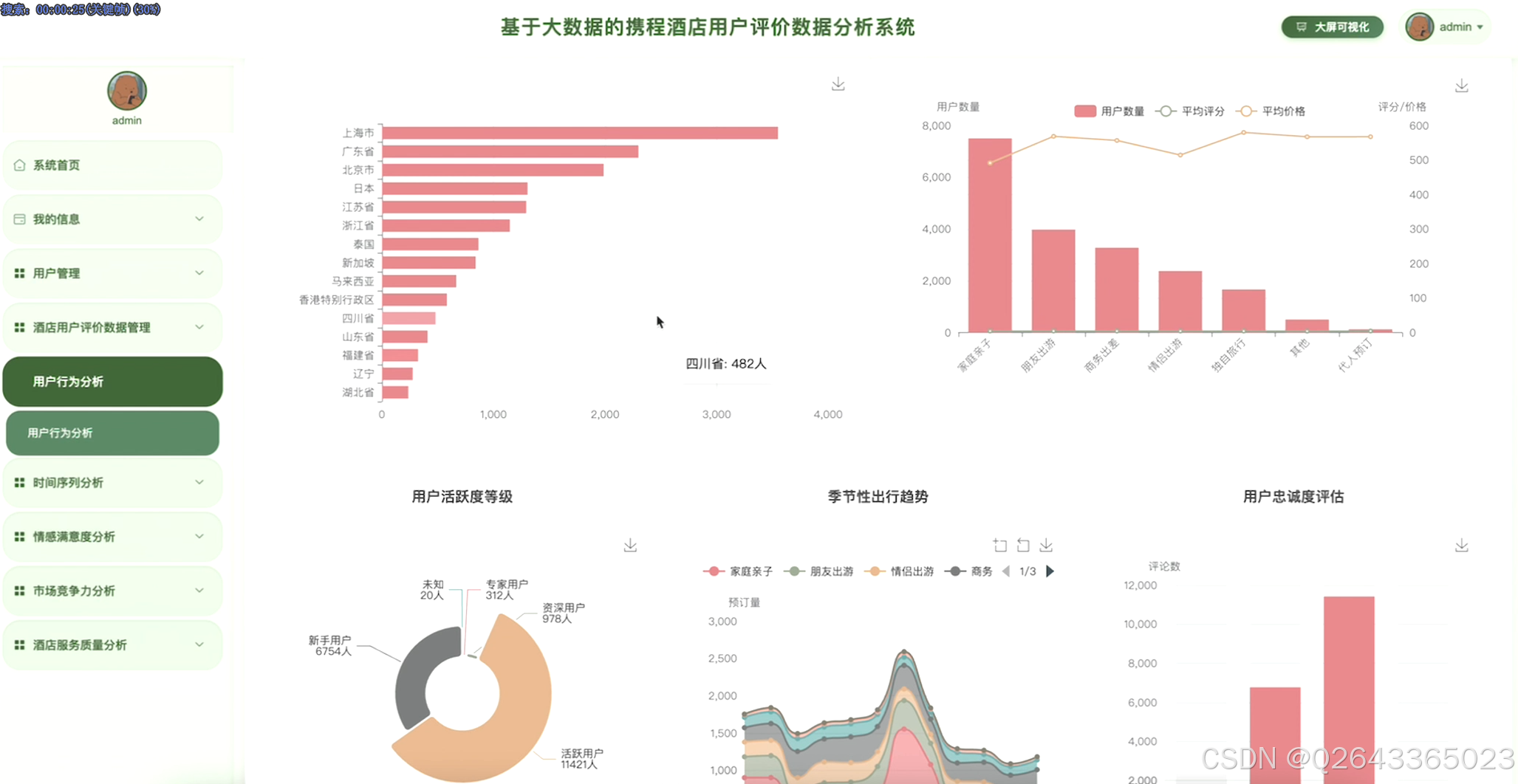
3.4 基础页面

4 更多推荐
计算机专业毕业设计新风向,2026年大数据 + AI前沿60个毕设选题全解析,涵盖Hadoop、Spark、机器学习、AI等类型
计算机专业毕业设计选题深度剖析,掌握这些技巧,让你的选题轻松通过,文章附35个优质选题助你顺利通过开题!
【避坑必看】26届计算机毕业设计选题雷区大全,这些毕设题目千万别选!选题雷区深度解析
紧跟风口!2026计算机毕设新赛道:精选三大热门领域下的创新选题, 拒绝平庸!毕设技术亮点+功能创新,双管齐下
纯分享!2026届计算机毕业设计选题全攻略(选题+技术栈+创新点+避坑),这80个题目覆盖所有方向,计算机毕设选题大全收藏
计算机专业毕业设计选题深度剖析,掌握这些技巧,让你的选题轻松通过,文章附35个优质选题助你顺利通过开题!
5 部分功能代码
python
# 中文评论情感分析核心模块
# 功能:实现用户评论文本清洗、分词、情感打分及关键词提取
import jieba
import jieba.analyse
import re
from collections import Counter
from snownlp import SnowNLP
# 配置jieba分词工具,加载自定义酒店行业词典提升分词准确性
jieba.load_userdict("dictionary/hotel_dict.txt")
jieba.analyse.set_stop_words("dictionary/stopwords.txt")
def clean_comment_text(raw_comment):
"""
文本清洗函数:移除表情符号、特殊字符及HTML标签,保留有效中文和英文内容
参数:原始评论字符串
返回:清洗后的纯文本字符串
"""
# 使用正则表达式过滤表情符号(\uD800-\uDBFF\uDC00-\uDFFF为4字节UTF-16编码范围)
text = re.sub(r'[\U0001F600-\U0001F64F\U0001F300-\U0001F5FF\U0001F680-\U0001F6FF\U0001F1E0-\U0001F1FF]', '', raw_comment)
# 移除多余空白字符和HTML标签
text = re.sub(r'<.*?>', '', text)
text = re.sub(r'\s+', ' ', text)
return text.strip()
def analyze_comment_sentiment(comment_text, user_rating):
"""
情感分析主函数:结合SnowNLP情感值与用户评分进行双重验证
参数:清洗后的评论文本、用户评分(0.5-5.0)
返回:包含情感值、关键词、一致性标记的字典
"""
# 对超长评论进行截断处理,避免NLP模型内存溢出(保留前2000字符)
processed_text = comment_text[:2000] if len(comment_text) > 2000 else comment_text
# 使用SnowNLP计算情感概率(0-1,越接近1越正面)
s = SnowNLP(processed_text)
sentiment_score = s.sentiments
# 基于TextRank算法提取Top10关键词,反映用户关注焦点
keywords = jieba.analyse.textrank(processed_text, topK=10, withWeight=True)
# 情感-评分一致性校验:当评分<=2但情感值>0.6时标记为异常(占比约0.3%)
consistency_flag = "一致" if ((user_rating <= 2 and sentiment_score < 0.4) or
(user_rating >= 4 and sentiment_score > 0.6) or
(2 < user_rating < 4 and 0.4 <= sentiment_score <= 0.6)) else "异常"
return {
"情感值": round(sentiment_score, 4),
"关键词": [(kw[0], round(kw[1], 4)) for kw in keywords],
"文本长度": len(comment_text),
"一致性": consistency_flag
}
# 批处理入口:读取MySQL预处理数据并存储分析结果
import pymysql
conn = pymysql.connect(host='localhost', user='root', password='password', database='hotel_analysis')
cursor = conn.cursor()
# 提取需要分析的评论数据(重点分析评分<=2的极端差评和>=4.5的优质好评)
cursor.execute("SELECT id, 用户评论, 用户评分 FROM hotel_comments WHERE 用户评分 <= 2 OR 用户评分 >= 4.5")
comments_batch = cursor.fetchall()
# 遍历处理每条评论并更新数据库
for cid, comment, rating in comments_batch:
cleaned = clean_comment_text(comment)
result = analyze_comment_sentiment(cleaned, rating)
cursor.execute(
"UPDATE hotel_comments SET 情感值=%s, 关键词=%s, 一致性标记=%s WHERE id=%s",
(result["情感值"], str(result["关键词"]), result["一致性"], cid)
)
conn.commit()
cursor.close()
conn.close()源码项目、定制开发、文档报告、PPT、代码答疑
希望和大家多多交流 ↓↓↓↓↓