视觉语言模型是一类强大的机器学习模型,能够同时处理视觉(图像)和文本信息。随着最近 Qwen 3 VL 模型的发布,我想带大家深入探讨一下,如何利用这些强大的 VLM 来处理文档。
为什么你需要使用 VLM
为了说明为什么有些任务需要 VLM,我想先举一个例子。这个任务需要我们同时理解文本内容以及文本的视觉布局信息。
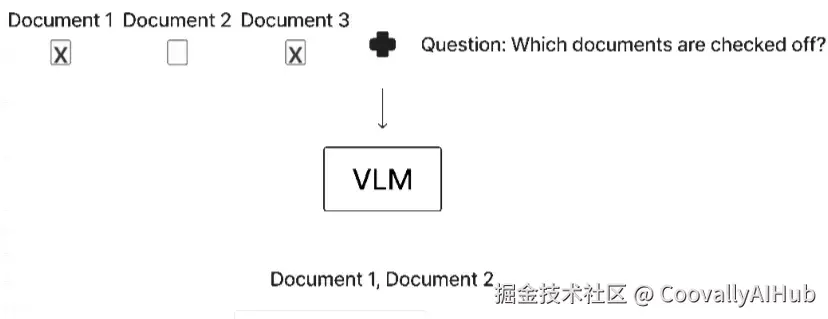
想象一下你看到下面这张图片。这些复选框表示某份文档是否应被包含在报告中,现在你需要确定该包含哪些文档。

这张图展示了一个非常适合用 VLM 解决的问题。图片中包含关于文档的文本,以及复选框。你需要根据复选框的勾选状态来判断该包含哪些文档。如果只用大语言模型来解决这个问题会很困难,因为你首先需要对图像进行 OCR 识别。识别出来的文本会丢失其在图像中的视觉位置信息,而这个信息对于正确解决这个任务至关重要。使用 VLM,你既可以轻松读取文档中的文本,又能利用其视觉位置信息(比如文本是否位于已勾选的复选框上方),从而成功解决问题。
对人类来说,这很简单:显然应该包含文档 1 和 3,排除文档 2。但是,如果你尝试用纯 LLM 来解决,就会遇到麻烦。
要运行纯 LLM,你需要先对图像进行 OCR 识别。如果你使用谷歌的 Tesseract 等工具,OCR 的输出可能会是下面这样,它是按行提取文本的:
Document 1 Document 2 Document 3 X X你可能已经发现了,LLM 很难决定该包含哪些文档,因为根本无法判断 "X" 属于哪个文档。这只是众多场景中的一个例子,说明了 VLM 在解决特定问题时的极高效率。
这里的核心要点是:要判断哪些文档被勾选,需要同时掌握文本信息和其视觉位置信息。 我将其总结为下面这句话:
当文本的含义依赖于其视觉位置时,就需要使用 VLM。
应用领域
VLM 的应用领域非常广泛。在本节中,我将介绍一些 VLM 已被证明有用的不同领域,其中也包括我成功应用 VLM 的场景。
- 智能体应用场景
如今 AI 智能体非常热门,VLM 在其中也扮演着重要角色。我将重点介绍两个 VLM 可用于智能体场景的主要领域,当然还有其他类似领域。
- 计算机操作
计算机操作是 VLM 一个有趣的应用场景。这里指的是 VLM 观察你电脑的屏幕画面,并决定下一步执行什么操作。OpenAI 的 Operator 就是一个例子。例如,VLM 可以看着你正在阅读的这篇文章的屏幕画面,然后向下滚动以阅读更多内容。
VLM 之所以对计算机操作有用,是因为仅靠 LLM 不足以决定采取何种操作。在操作电脑时,你经常需要解读按钮和信息的视觉位置,正如我在开头所描述的,这正是 VLM 的主要用武之地。
- 调试
调试代码也是 VLM 一个非常有用的智能体应用领域。想象一下,你正在开发一个 Web 应用程序,发现了一个 bug。
一种选择是开始向控制台输出日志,复制日志,向 Cursor 描述你做了什么,然后提示 Cursor 去修复它。这自然很耗时,因为需要用户手动执行很多步骤。
另一种选择是利用 VLM 来更好地解决这个问题。理想情况下,你描述如何复现这个问题,VLM 可以进入你的应用程序,重现操作流程,检查问题所在,从而调试出哪里出了错。目前有一些应用正在为此类场景开发,但据我所见,大多数还处于早期阶段。
- 问答系统
利用 VLM 进行视觉问答是使用 VLM 的经典方法之一。问答系统就是我在本文前面描述的那个关于判断复选框属于哪个文档的用例。你向 VLM 提供用户的问题和一张(或多张)图像供其处理。然后,VLM 会以文本形式提供答案。你可以通过下图了解这个过程是如何工作的。
这张图展示了一个我利用 VLM 解决问题的问答任务。你输入包含问题的图像和需要解决的任务描述。VLM 处理这些信息后,输出期望的信息。
然而,你应该权衡使用 VLM 和 LLM 的利弊。显然,当任务需要文本和视觉信息时,你需要使用 VLM 才能获得正确结果。但是,VLM 的运行成本通常也高得多,因为它们需要处理更多的 token。这是因为图像包含大量信息,从而导致需要处理的输入 token 数量激增。
此外,如果 VLM 需要处理文本,你还需要高分辨率的图像,以便 VLM 能够解读构成字母的像素。分辨率过低时,VLM 难以读取图像中的文本,你会得到质量较差的结果。
- 分类任务
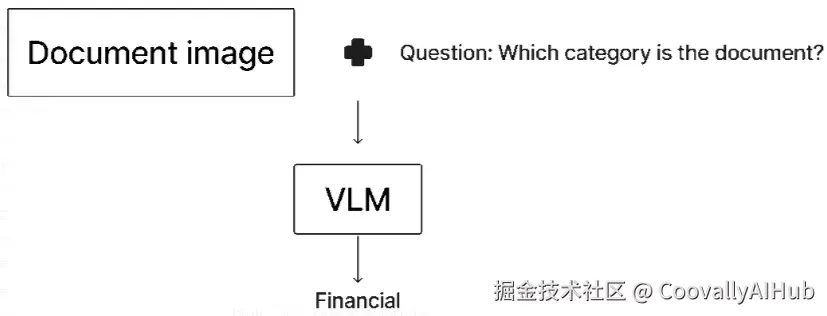
这张图说明了如何将 VLM 应用于分类任务。你向 VLM 提供文档图像和一个问题,要求它将文档分类到预定义的一组类别中。这些类别应包含在问题里,但图中因空间限制未显示。VLM 随后输出预测的分类标签。
VLM 另一个有趣的应用领域是分类。这里的分类指的是,你有一组预定义的类别,需要确定一张图像属于哪个类别。
你可以采用与使用 LLM 类似的方法,将 VLM 用于分类。你创建一个结构化的提示,包含所有相关信息,包括所有可能的输出类别。此外,你最好能涵盖不同的边缘情况,例如,在某些场景下两个类别都非常可能,VLM 必须在它们之间做出抉择。
例如,你可以设计这样一个提示:
python
def get_prompt(): return """ ## 总体说明 你需要判断给定文档属于哪个类别。 可选类别有 "legal"(法律)、"technical"(技术)、"financial"(财务)。 ## 边缘情况处理 - 如果遇到一份涉及财务信息的法律文档,则该文档属于财务类别 - ... ## 返回格式 请只回复对应的类别,不要包含其他任何文本。 """- 信息提取
你也可以有效地利用 VLM 进行信息提取,并且有很多信息提取任务需要视觉信息。你可以创建一个与上面分类提示类似的提示,并通常要求 VLM 以结构化格式(如 JSON 对象)进行回复。
在执行信息提取时,你需要考虑要提取多少个数据点。例如,如果你需要从一份文档中提取 20 个不同的数据点,你可能不希望一次性全部提取。因为模型很可能难以在一次处理中准确提取这么多信息。
相反,你应该考虑将任务拆分,例如,分两次请求各提取 10 个数据点,从而简化模型的任务。但从另一方面看,有时你会发现某些数据点是相互关联的,这意味着它们应该在同一次请求中提取。此外,发送多个请求会增加推理成本。
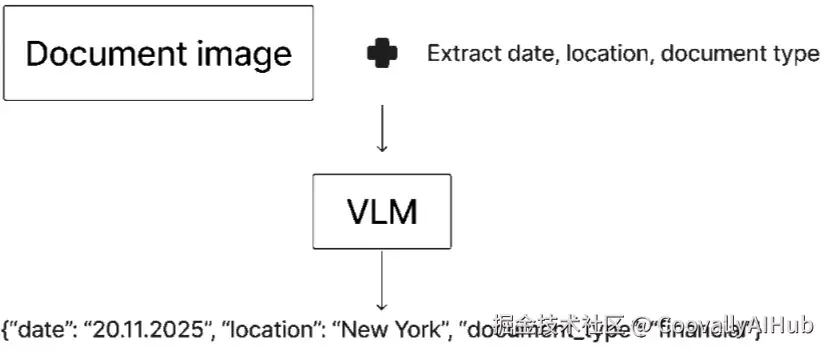
这张图展示了如何利用 VLM 执行信息提取。你再次向 VLM 提供文档图像,并提示它提取特定的数据点。在这张图中,我提示 VLM 提取文档的日期、文档中提及的地点以及文档类型。VLM 随后分析提示和文档图像,并输出一个包含所请求信息的 JSON 对象。
- VLM 的局限性所在
VLM 是惊人的模型,能够完成几年前还无法用 AI 解决的任务。然而,它们也有其局限性,我将在本节中讨论。
- 运行 VLM 的成本
第一个局限是运行 VLM 的成本,我在文章前面也简要讨论过。VLM 处理图像,而图像由大量像素组成。这些像素代表大量信息,这些信息被编码成 VLM 可以处理的 token。问题在于,由于图像包含的信息如此之多,每个图像你需要生成大量的 token,这反过来又增加了运行 VLM 的成本。
此外,你通常需要高分辨率图像,因为 VLM 需要读取图像中的文本,这导致需要处理的 token 更多。因此,无论是通过 API 调用还是自行托管 VLM,其运行成本都非常高昂。
- 无法处理长文档
图像中包含的 token 数量也限制了 VLM 一次能处理的页数。和传统 LLM 一样,VLM 也受其上下文窗口的限制。如果你要处理包含数百页的长文档,这就是个问题。当然,你可以将文档分块处理,但你可能会遇到 VLM 无法一次性访问文档全部内容的情况。
例如,如果你有一份 100 页的文档,你可以先处理第 1-50 页,然后处理第 51-100 页。但是,如果第 53 页的某些信息可能需要第 1 页的上下文(例如文档的标题或日期),这就会导致问题。
为了了解如何处理这个问题,我阅读了 Qwen 3 的使用手册,其中有一页专门介绍了如何利用 Qwen 3 处理超长文档。我肯定会在未来的文章中测试这种方法并讨论其效果如何。
在Coovally平台上汇聚了国内外开源社区超1000+ 热门模型 ,覆盖YOLOv8、YOLOv10等 主流视觉算法。同时集成300+公开数据集 ,涵盖图像分类、目标检测、语义分割等场景,一键下载即可投入训练,彻底告别"找模型、配环境、改代码"的繁琐流程!
!!点击下方链接,立即体验Coovally!!
平台链接: www.coovally.com
在实际使用中,开发者还可以借助 Coovally 平台, 通过 SSH 协议使用熟悉的工具(如 VS Code、Cursor、WindTerm 等)远程连接 Coovally 云端算力资源,进行实时代码开发与调试,享受本地级操作体验的同时,充分利用平台提供的高性能 GPU 加速训练过程。
结论
在本文中,我讨论了视觉语言模型以及如何将它们应用于不同的问题领域。我首先描述了如何将 VLM 集成到智能体系统中,例如作为计算机操作代理或用于调试 Web 应用程序。接着,我涵盖了问答系统、分类和信息提取等领域。最后,我还讨论了 VLM 的一些局限性,包括运行 VLM 的计算成本以及它们处理长文档时面临的困难。