这篇文章写得比较长,为了方便大家快速了解都说了啥,我先简单整理了一个目录如下:
- 业务背景
- 复盘与反思
- 灰度系统的初期思考
- 关于灰度发布后台的设计
- 关于灰度配置提交接口参数的设计
- 关于数据库的设计
- 关于灰度后台接口设计
- 关于如何获取用户灰度标识的设计
- 疑问:为什么不直接用 Spring Cloud Gateway
- 关于后端灰度部署设计
- 在实际部署中需要注意的问题
- 关于回滚与全量发布的流程
- 关于客户端灰度设计与实现逻辑
- 关于前端灰度的两种实现方式
- 讲讲关于灰度接入的问题
- 结语
业务背景
我之前在负责一个 to C 的 App 项目的时候,整体数据表现还不错。
首日 ROI 已经能做到 30%,在行业里算是相当高的水平了。
但问题在于回收周期太长,我们要花将近一个半月才能达到 200% 的回收。
老板对这个结果并不满意,希望我们能把周期缩短到一个月以内。
运营那边给到的反馈是,付费功能太单一,免费功能太多,用户没有形成付费习惯,整体收入增长太慢。
他们的建议是做一些差异化权益,比如增加会员体系,让用户能感受到"开通会员"能带来的额外价值,从而提高整体转化。
于是我们评估之后决定上线一个会员体系。
会员可以解锁一些增值功能,同时配合运营活动做差异化权益展示,希望能带动整体收入。
当时评审、开发、测试都顺利,版本也如期上线。
结果没想到,问题反而从这里开始。
上线后陆续有用户反馈,有部分老用户觉得会员权益和原有功能产生了冲突,
说原来免费的功能现在要开会员才能用。
于是开始在社区和评论区表达不满,觉得被"割韭菜"了。
评论区的负面声音越来越多,客服那边的工单量也在飙升。
虽然技术上没出什么大问题,但从业务层面看,这次上线可以说是一次彻底的翻车。
用户投诉骤增、差评增加、次日留存下降,付费转化率不升反降。
最后我们只能紧急回退,把会员功能先下线。
结果,这次回退直接导致当月的付费金额下滑明显,甚至影响到了后续的市场投放节奏。
复盘与反思
那时候我们才意识到,功能开发没错,问题在于上线策略。
新功能不是一刀切地推给所有人,而应该先在一部分用户群体中试运行,观察数据和反馈,再逐步放量。
但没办法,当时我们整个项目流程已经算比较成熟了。
这次上线能做到零 Bug,大家都已经松了一口气,没人再去多想上线策略的问题。
再加上上线节奏紧、版本周期短,这种"先上再看"的思维已经成了习惯。
可问题是,一旦出现这种情况,代价就非常大。
每次出问题都得紧急修复、重新打包、再提审。
为了尽量不影响用户,我们经常选在半夜更新,等用户最少的时候再操作。
那段时间团队基本都是通宵上线,凌晨四五点收工已经成了常态。
久而久之,大家都有点怕上线。
直到那次会员功能的事故之后,我才真正意识到,重要版本的更新还是得走一套灰度机制。
新功能再怎么测得再充分,也不可能百分之百覆盖所有用户场景。
上线前先让一部分用户用起来,观察数据和反馈,再决定是否全量,这才是更稳妥的方式。
但灰度这东西也没那么容易就加进去。
我们当时的项目流程其实已经算比较规范了,开发、测试、预发布、上线这一套都很齐。
只是灰度一直没被真正纳入流程。
一方面是因为团队人少、节奏快,能保证不出大问题就已经很不容易;
另一方面,当时大家都觉得预发布环境已经够用了。
可事实证明,预发布并不能代表真实用户环境。
如果没有灰度机制,每次大版本上线都像在赌运气,一旦出问题,损失往往是成倍的。
所以那次之后,我决定还是自己动手,来设计一套简单但能真正落地的灰度发布系统。
灰度系统的初期思考
其实我之前在一家比较大的公司工作的时候,用过非常成熟的一整套灰度系统。
那时候灰度策略、放量节奏、用户分组、回滚机制,全都已经做得很完善,甚至还有配套的数据监控面板。
对于那种用户体量大、业务线多的公司来说,这样的体系非常必要,也确实好用。
但到了现在这个项目里,情况完全不同。
我们这个项目团队规模不大,业务也相对集中,如果直接照搬那套完整的灰度方案,不仅开发周期长,还会让系统变得复杂、难维护。
所以我决定重新设计一套更"轻"的灰度机制,重点放在能快速落地、好用、风险可控上。
在设计思路上,我首先想到的就是------要让灰度可视化、可配置。
我以前的公司里,灰度放量这些事是有专门的后台的,运营可以在系统里创建灰度策略、设置生效时间、审批、放量、回滚,全流程都是通过后台操作完成的,不需要研发去改配置文件或重启服务。
我觉得这种方式对我们也同样适用。
所以我决定在我们现有的管理后台里,增加一个"灰度发布"模块。
让运营能在后台直接配置灰度策略,比如灰度类型、灰度范围、生效时间、审批流程等。
研发这边只要在服务中读取并执行这些策略,就能根据配置实现灰度分流。
相比网上很多文章里那种在 Nginx 里加 Lua 脚本来判断用户灰度标识的做法,我更希望整个流程是标准化的、有审批的、能追溯的。
因为一旦涉及真实用户流量,靠改配置或脚本去控制灰度,很容易出错。
而后台化的方案,虽然多花一点时间,但长远来看更安全,也更容易被运营接受。
所以我的第一步,就是要先把这套灰度策略的后台设计出来,让它成为后续整个灰度机制的基础。
关于灰度发布后台的设计
灰度系统的第一步是把整个流程做"后台化"。
所有灰度的开关、策略配置、审批操作都应该有清晰的界面和操作记录,
让运营和管理员能够独立完成灰度相关的工作,而不是依赖研发去改配置或脚本。
基于这个思路,我在项目中设计了一个「灰度管理中心」,
从灰度的申请、审批,到策略配置、发布生效,都可以在后台一站式完成。
灰度开启与审批流程
在开始设计灰度逻辑之前,我先考虑的是灰度的开启时机 。
我们虽然是双周迭代节奏,但并不是每个版本都需要灰度。
像一些小修小补或者纯配置更新,直接全量上线就够了。
只有遇到重大更新、新功能上线,或者对用户体验有明显影响的改动,才会走灰度流程。
基于这个前提,我在灰度后台设计了一个"灰度开启审批"机制。
灰度不能随便开,必须先由运营发起申请,再由管理员审批通过后才能真正启用。
这样既能防止误操作,也能保证团队对每次灰度发布都有记录和追溯。
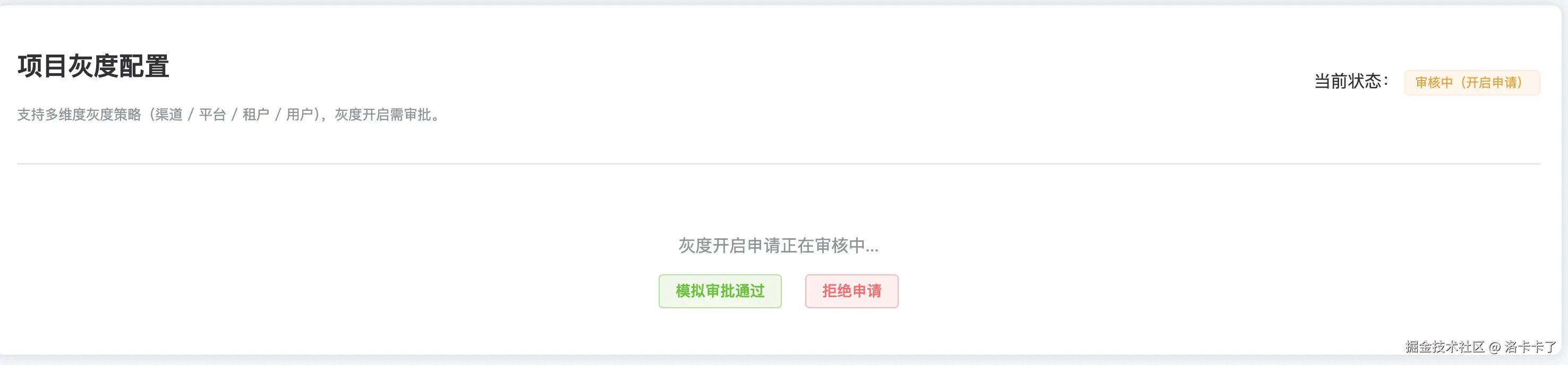
下面这张图是灰度管理中心的主界面。
当项目灰度处于关闭状态时,系统会显示当前状态为"已关闭",右侧有一个"申请开启灰度"的按钮。
如果某个版本需要灰度测试,运营就可以点击这个按钮发起申请。

点击提交申请,填写申请理由,提交审核后,状态会进入"审核中",管理员登录后台后能看到这个申请,并选择"通过"或"拒绝"。
审批通过后,状态会自动变为"灰度开启",这时灰度逻辑才会正式生效。
整个流程看起来简单,但能有效避免灰度被滥用,同时也让过程变得更清晰、更规范。
灰度开启后,系统会把当前状态同步落地到数据库中。
这个操作看似不起眼,但非常关键。
服务端会根据这个状态来决定是否执行灰度分流逻辑,
其他相关服务(比如配置中心、监控模块)也能实时读取当前灰度状态,保证全链路一致。
至于这个状态后续在分流环节具体怎么用,我会在后面讲到。
灰度策略配置页面设计
在灰度审批通过之后,接下来就是具体的灰度策略配置。
我希望运营能在后台清晰地看到灰度的版本、时间、维度和范围,而不是靠研发去改配置文件。
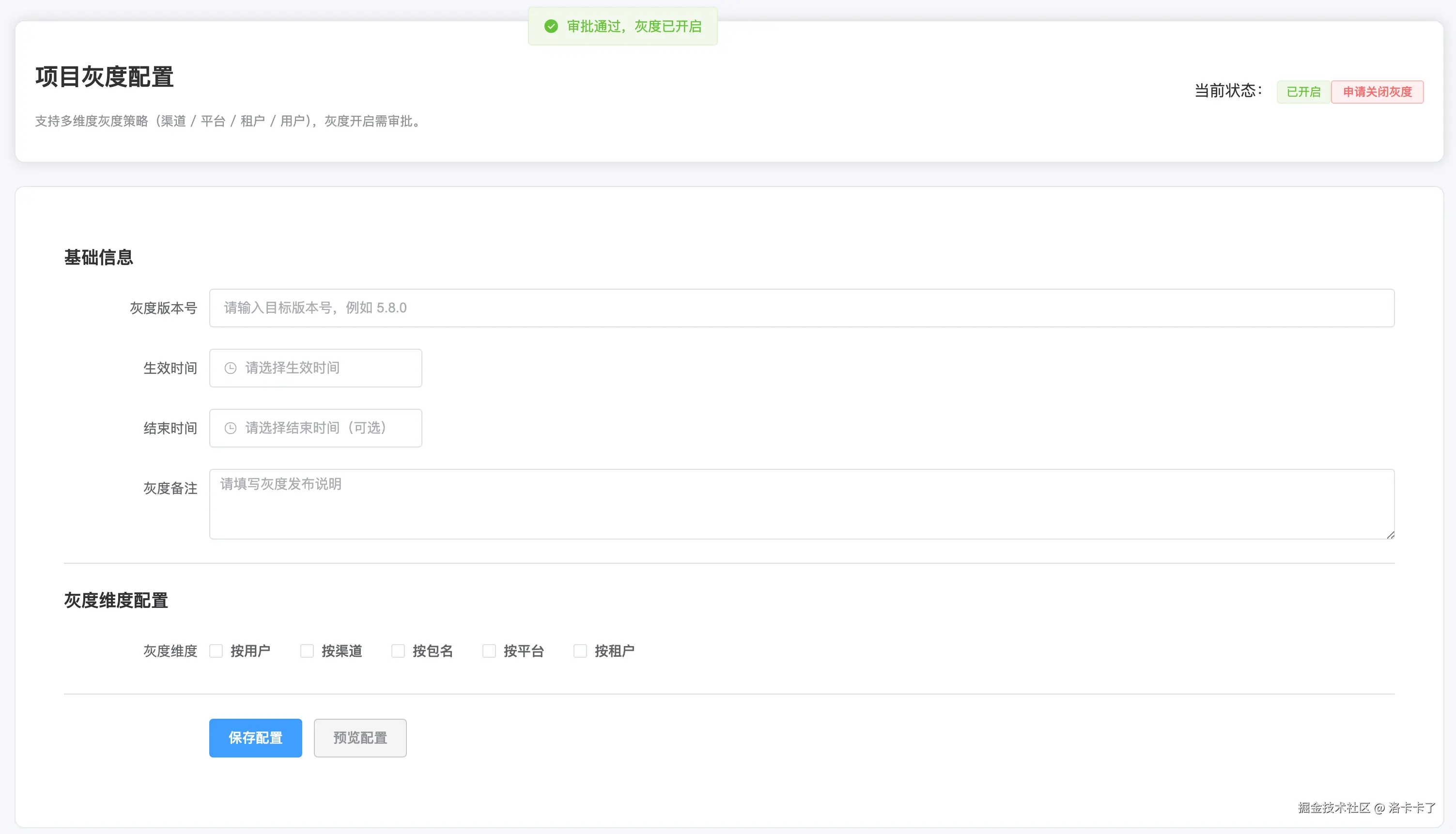
比如我们第一个页面是灰度的基础信息配置。
这里可以填写需要开启灰度的目标版本号,比如 5.8.0,并设置灰度的生效时间和结束时间。
一般来说,我们会设置一个明确的开始时间,结束时间可以留空,方便后续根据效果决定是否延长。
下面还有一个备注说明栏,用来记录灰度的目的,比如"首次开启会员功能灰度测试"之类,方便后续追溯。
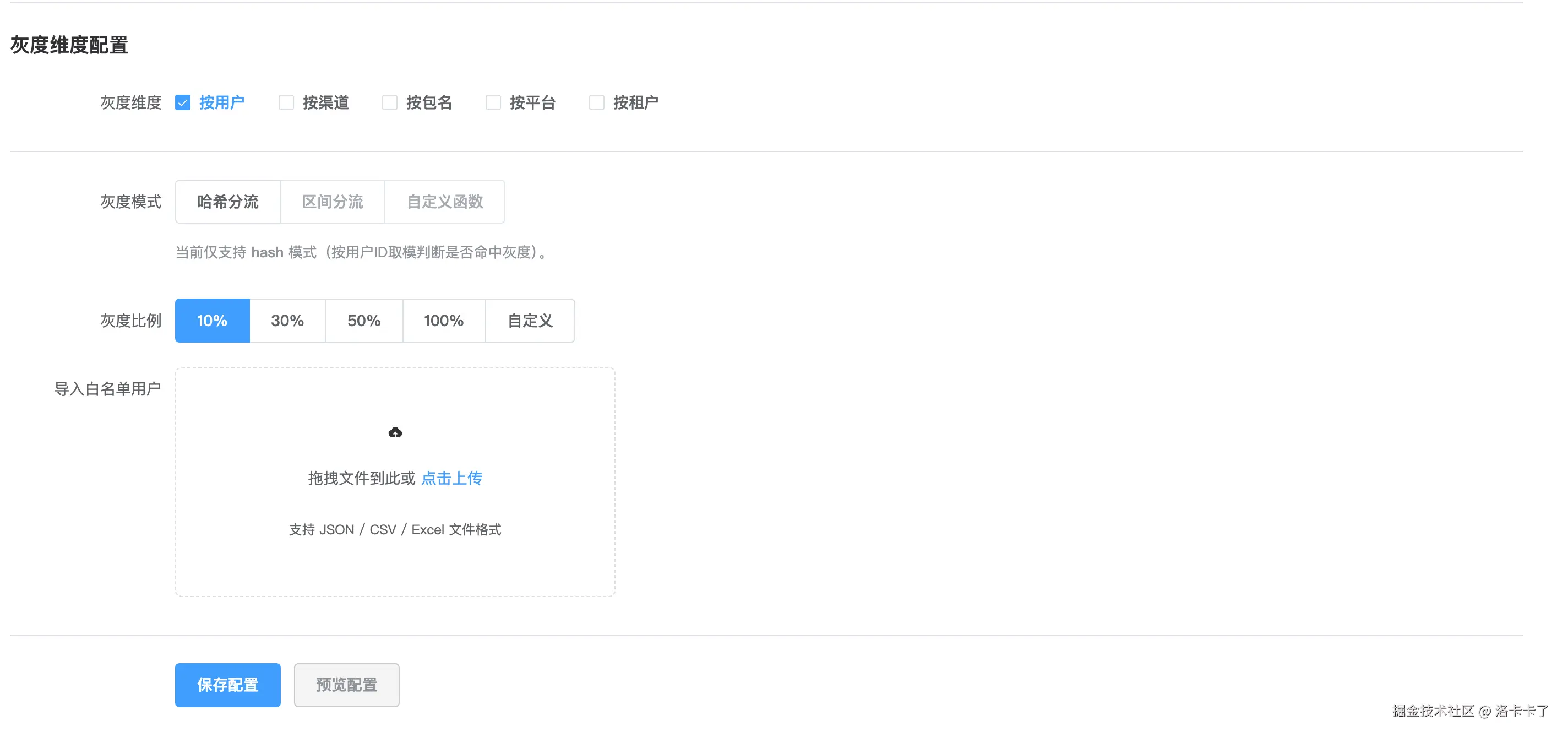
接下来是灰度维度的选择。
我希望系统支持多维度的灰度策略,可以按用户、渠道、包名、平台、租户等方式进行组合。
比如如果我们只想按用户维度来灰度,就可以勾选"按用户"。
我们还可以设置灰度模式,默认就是哈希分流 模式,当然我们也可以选择其他的模式哈。
页面会自动展示灰度比例设置,可以选择 10%、30%、50%、100%、自定义等预设比例。
此外,我们还支持上传一份灰度白名单名单。
这些用户不受比例控制,只要在名单里,就一定会进入灰度范围。
一般这类用户是内部员工或测试账号,用来提前验证功能。
当然,很多时候我们需要更细的灰度控制。
比如我们想要限定灰度范围为:租户 A 下、马甲包 AB、安卓平台、小米,OPPO,VIVO渠道的用户,灰度比例 10% 。
这种场景就可以通过勾选多个维度来实现。
配置页面会自动展开对应的筛选项,让我们灵活地组合各种条件。
这种多维度灰度方式非常适合复杂业务场景,可以精确到渠道、平台、甚至具体租户。
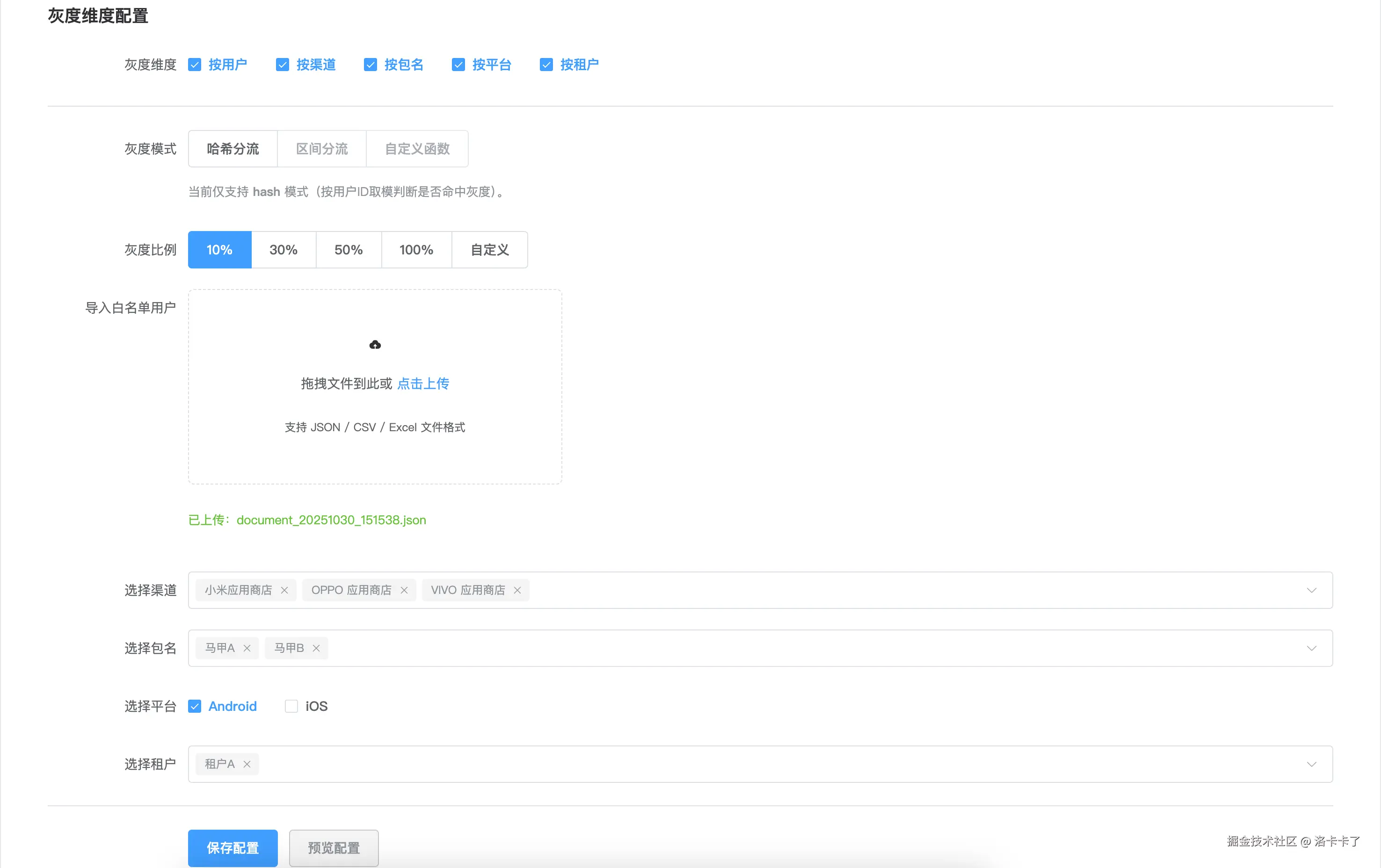
通过这样的设计,运营就能在后台自由配置灰度策略,不需要研发介入。
所有策略都能保存到数据库中,后续服务端会实时读取这些配置来做分流判断。
相比那种手动改配置或写脚本的方式,这种做法更安全,也更符合团队协作的习惯。
灰度审批流程设计
灰度策略配置完成后,并不会马上生效。
我在系统里加了一道"灰度审批"流程,目的是让每次灰度发布都能经过二次确认,避免因为配置错误造成线上风险。
毕竟灰度涉及真实用户流量,一旦配置维度选错或者比例设置不当,影响面可能会非常大。
配置保存后,灰度会进入"待审批"状态。
如图一所示,灰度审批列表会展示灰度项目的基础信息,比如项目标识、版本号、维度、备注等。
管理员可以直接在这里查看有哪些灰度发布正在等待审核。

点击右侧的"审批"按钮,就能进入详细信息页。
在这里可以看到完整的灰度配置详情,包括目标版本、生效时间、灰度维度、比例、白名单、渠道、包名、平台和租户等。
这些信息会清晰地展示出当前灰度策略的具体范围,比如"租户 A、马甲包 A、安卓平台、小米渠道的 10% 用户"。
管理员审核时就能一目了然地确认是否符合预期。
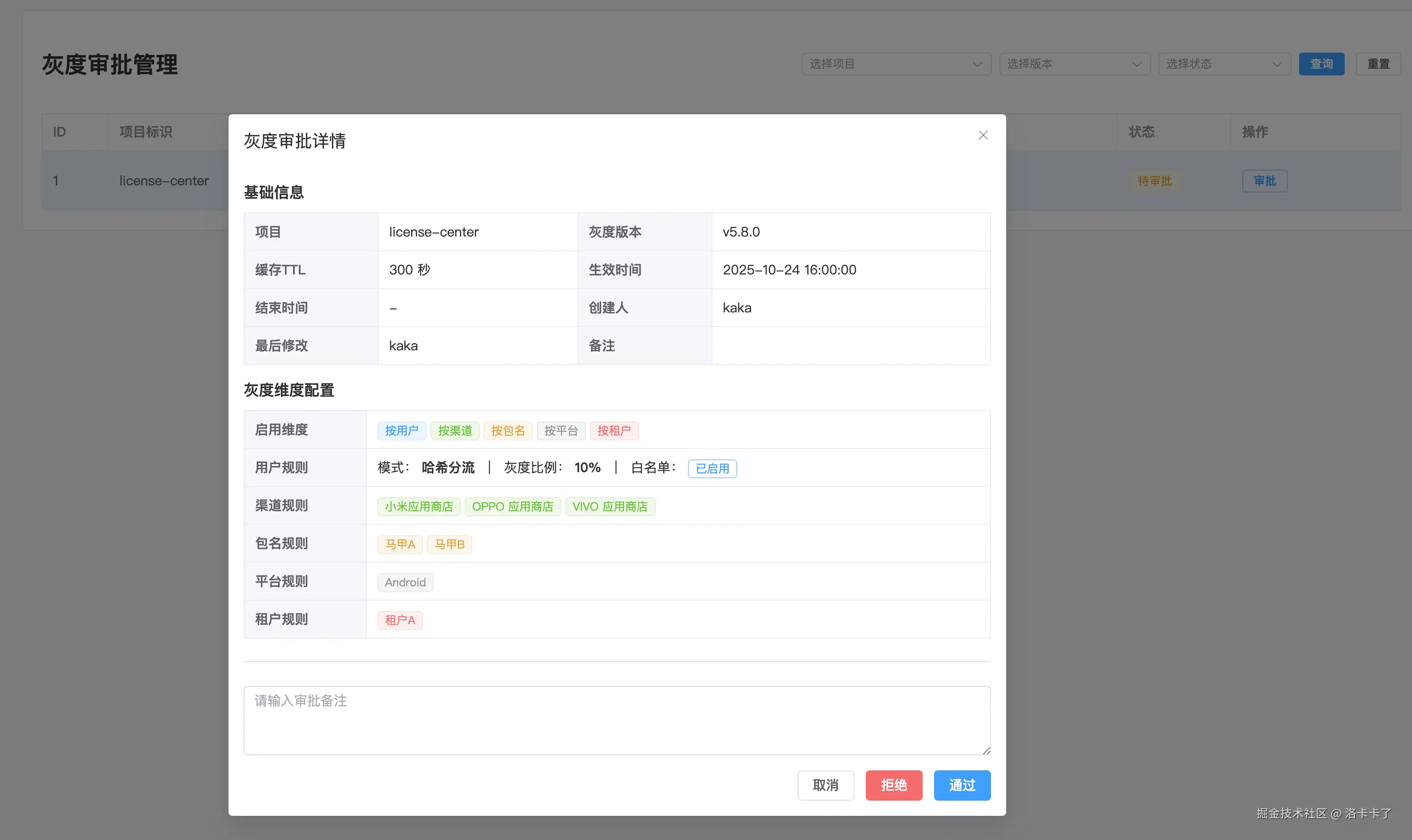
如果配置没有问题,管理员点击"通过",系统就会把审批状态更新为"已生效",并同步写入数据库。
这样服务端就能读取到最新的灰度维度信息,用于后续的请求分流逻辑。
如果发现配置不合理,也可以点击"拒绝",灰度就会保持未生效状态。
通过这样的设计,我们把灰度审批纳入了完整的发布流程。
一方面确保了每一次灰度上线都经过复核,另一方面也为后续追踪问题提供了操作记录。
灰度配置变更记录
灰度配置的变更管理是后台系统里非常关键的一环。
因为每次调整灰度维度、比例或版本,都会直接影响线上用户的访问范围。
所以我在后台加了一套「灰度配置变更记录」模块,用来完整记录每次的灰度调整历史。
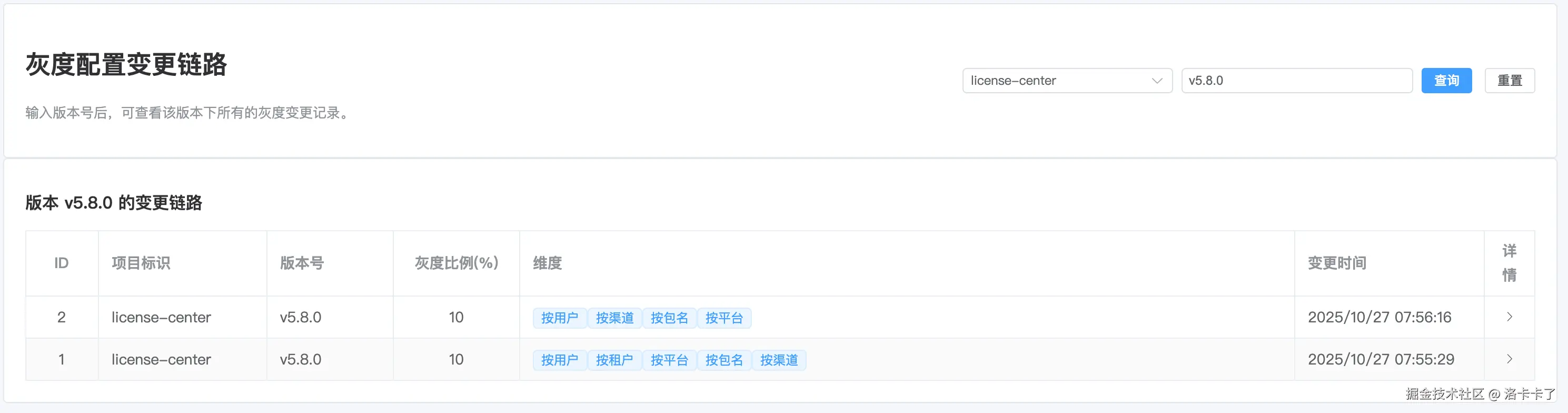
在这个页面中,我们可以通过选择项目和版本号来查看对应的灰度变更日志。
如下图所示,输入信息后系统会展示该版本下的所有灰度变更记录,包括版本号、灰度比例、维度及更新时间等。
每一条记录都对应一次灰度策略的修改,便于后续追溯。

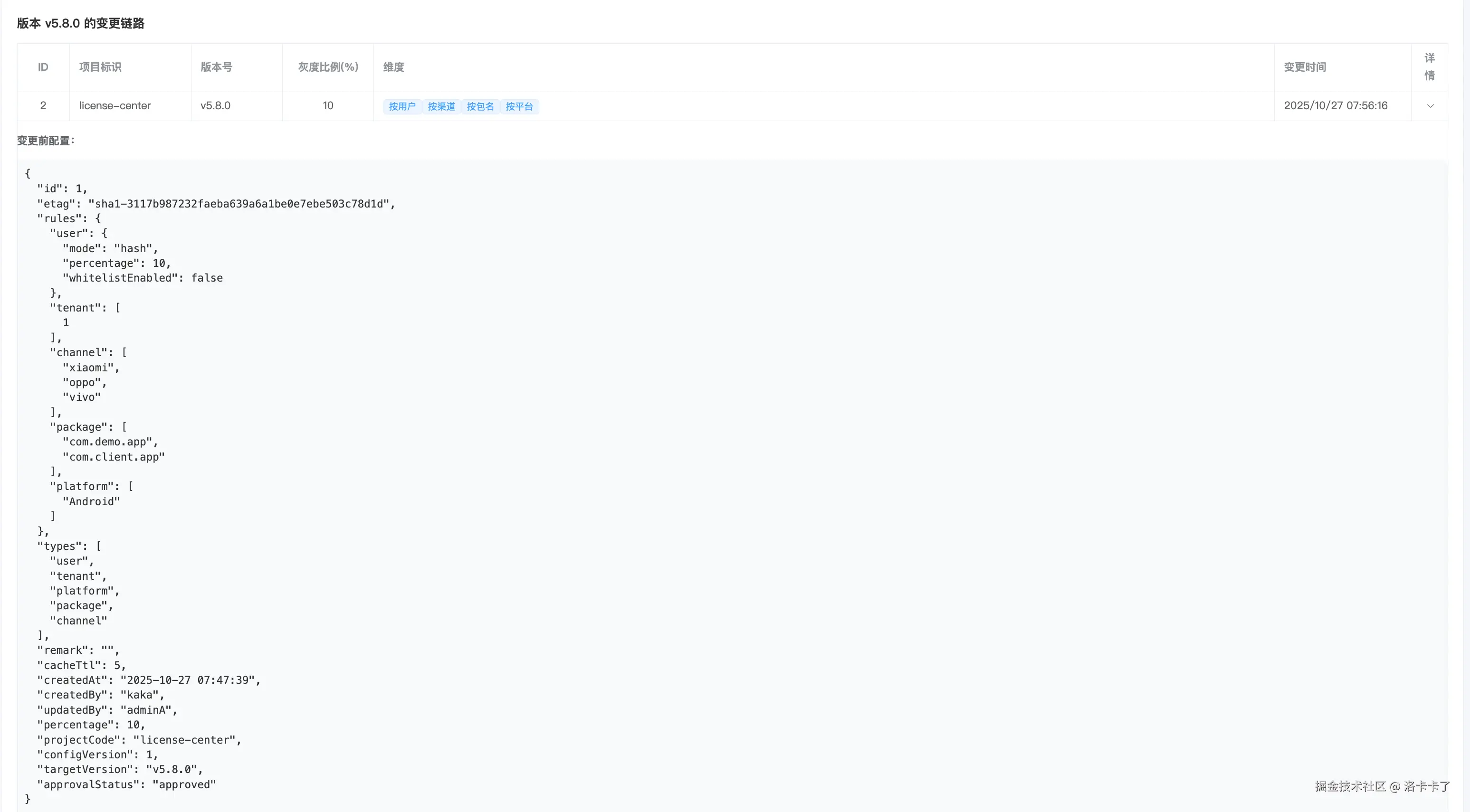
点击某条记录的详情,就能看到这次变更的完整配置信息。
页面会展示灰度的规则内容,比如涉及的渠道、包名、平台、租户等字段,
同时也能看到灰度的比例、白名单状态、创建人、更新时间等信息。
通过这些信息,管理员可以清楚了解这次变更的具体内容。
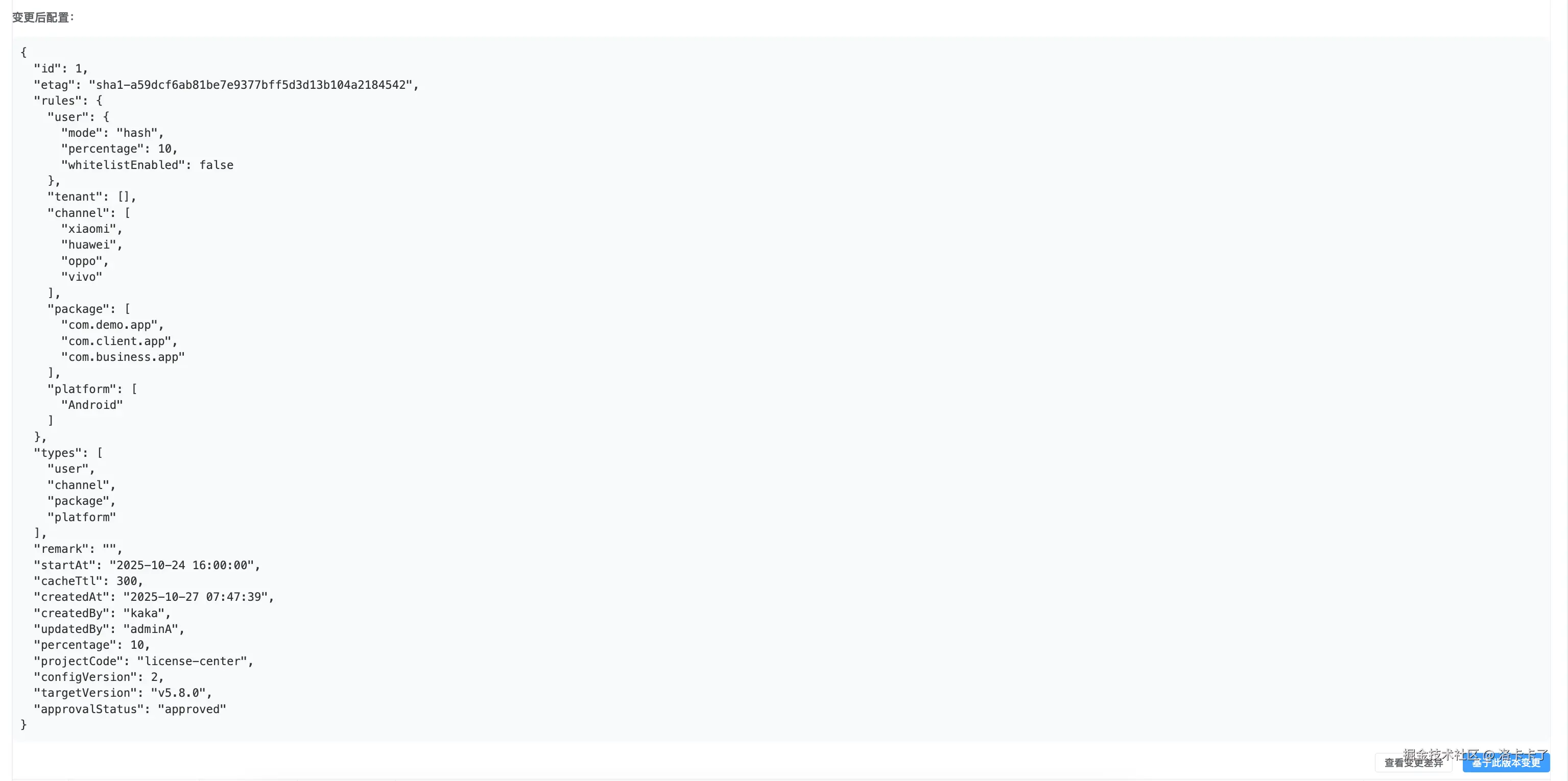
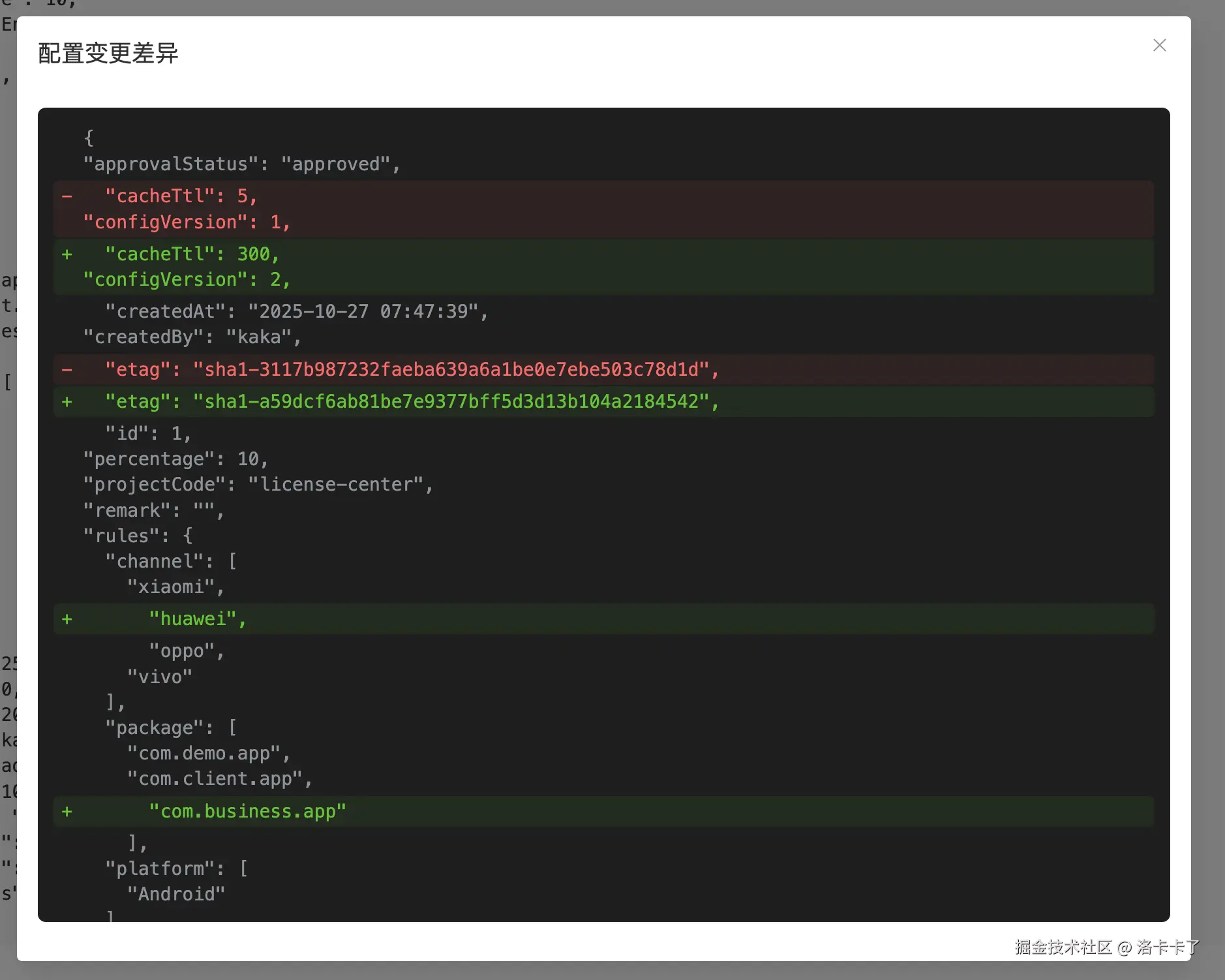
为了方便查看不同版本之间的差异,我还在右下角增加了"查看差异变更"的功能。
点击后,系统会对比前后两次配置的字段变化,并以高亮的方式展示具体的差异。
比如下图中,我们可以直观看到哪些渠道被新增、哪些包名被修改、缓存时间从 5 秒改成了 300 秒等。
这样在审查时能非常直观地发现问题或确认改动是否符合预期。
除此之外,我还支持「基于此版本变更」的功能。
每当我们想对现有灰度配置进行二次修改时,不用重新填写所有维度和规则,
只需要在变更详情页点击右下角的"基于此版本变更"按钮,
系统就会自动带入当前版本的配置,并跳转回灰度配置页面。
运营人员可以在原有配置的基础上微调,然后重新提交审批。
通过这样的设计,灰度配置的变更过程变得清晰、可追溯也可复用。
从每次修改到审批生效,所有操作都有完整记录,
不仅能帮助我们发现问题,还能保证团队对每次灰度策略都有充分的管控。
灰度运行监控与数据概览
在灰度上线后,我们还需要有一套可视化的监控页面,
用于实时追踪当前灰度版本的运行状态、阶段进度和关键指标。
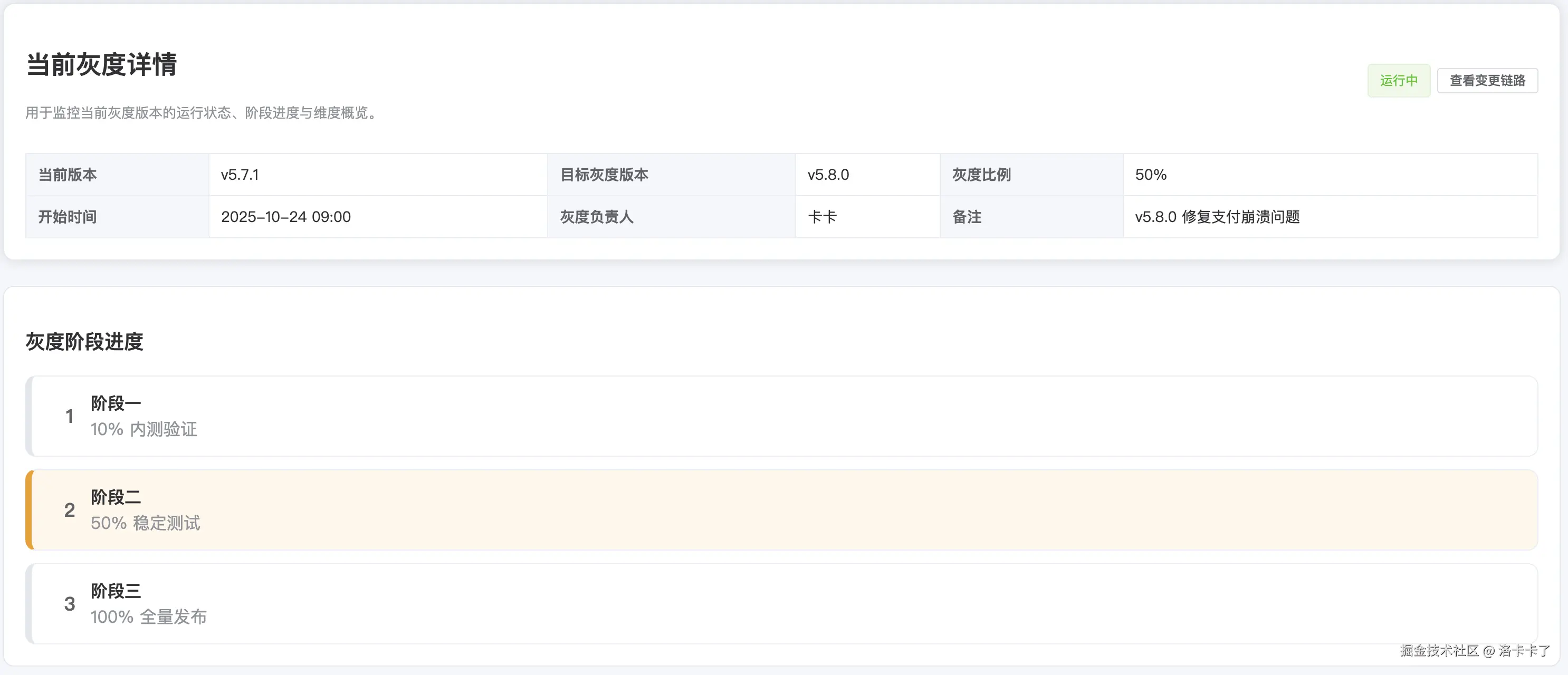
我在后台设计了一个「灰度详情」页面,用于监控整个灰度周期的运行情况。
页面的第一部分展示当前灰度的基本信息,
比如当前版本号、目标灰度版本、灰度比例、开始时间、负责人和备注等。
如图一所示,可以一眼看到当前灰度版本(例如从 v5.7.1 → v5.8.0)正在以 50% 的比例运行。
接下来是灰度的阶段进度区块。
我把灰度拆分为多个阶段,比如 10% 内测验证 → 50% 稳定测试 → 100% 全量发布 。
每个阶段都可以单独监控,管理员在后台能随时看到当前灰度处于哪个阶段、对应比例是多少。
这样的分阶段设计可以让我们更灵活地控制灰度推进速度,
遇到问题可以立即暂停,而不是一刀切地推全量。
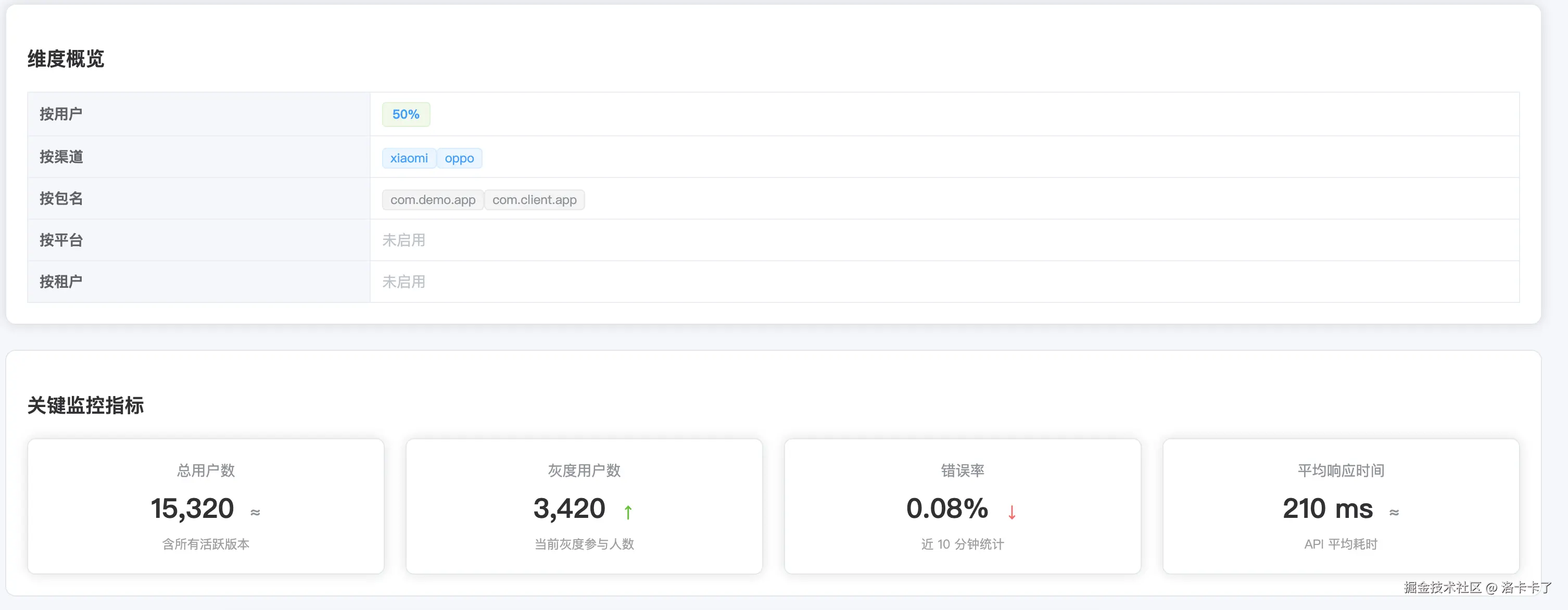
然后是维度概览和关键监控指标。
维度概览会展示本次灰度启用的纬度范围,比如按用户、按渠道、按包名、按平台、按租户等,
方便我们确认灰度命中的边界是否正确。
同时,我在页面底部加了几个关键监控指标:
- 当前总用户数与灰度参与人数
- 当前灰度用户比例
- 接口错误率(近 10 分钟统计)
- API 平均响应时间
这些指标能帮助我们在灰度运行过程中快速发现异常,比如错误率上升、接口延迟变长等。
当然,这里展示的只是一个简化版的 Demo,
在实际的生产环境里,我们还会接入更多维度的数据,
包括版本崩溃率、异常请求数、支付成功率、转化率变化趋势 等,
让灰度监控不只是"看状态",而是真正服务于灰度决策。
通过这套可视化的监控页面,我们就能做到灰度有迹可循、问题可追溯、放量可控,
让整个灰度流程形成一个完整的闭环。
关于灰度配置提交接口参数的设计
到目前为止,后台关于灰度的主要配置部分就差不多了。
接下来,我们来看下提交配置的接口参数。
其实这些字段和我们在「灰度变更记录」页面里看到的那份 JSON 是一一对应的,
下面我简单解释一下每个参数的含义。
接口请求示例如下:
json
{
"id": 1,
"etag": "sha1-3117b987232faeba639a6a1be0e7ebe503c78d1d",
"rules": {
"user": {
"mode": "hash",
"percentage": 10,
"whitelistEnabled": false
},
"tenant": [1],
"channel": ["xiaomi", "oppo", "vivo"],
"package": ["com.demo.app", "com.client.app"],
"platform": ["Android"]
},
"types": ["user", "tenant", "platform", "package", "channel"],
"remark": "",
"cacheTtl": 5,
"createdAt": "2025-10-27 07:47:39",
"createdBy": "kaka",
"updatedBy": "adminA",
"percentage": 10,
"projectCode": "license-center",
"configVersion": 1,
"targetVersion": "v5.8.0",
"approvalStatus": "approved"
}参数说明
| 字段名 | 说明 |
|---|---|
| id | 数据主键,用于唯一标识本次配置记录。 |
| etag | 配置的签名哈希,用于快速识别变更(服务端自动生成)。 |
| projectCode | 项目标识,如 license-center,区分不同系统或模块的灰度配置。 |
| configVersion | 配置版本号,每次审批通过后自动递增。 |
| approvalStatus | 审批状态,分为 pending(待审批)、approved(通过)、rejected(驳回)。 |
| targetVersion | 目标灰度版本号,如 v5.8.0,表示此次灰度面向的版本。 |
| percentage | 灰度比例,命中灰度的用户占比(0--100)。 |
| rules | 灰度规则主体,包括不同维度的灰度条件(用户、渠道、租户、包名、平台等)。 |
| types | 启用的灰度维度列表,如 ["user","channel","tenant"]。 |
| cacheTtl | 缓存有效期(秒),用于控制服务端或边缘节点缓存刷新频率。 |
| remark | 备注说明,通常用于记录灰度目的或审批意见。 |
| createdBy / updatedBy | 分别表示配置的创建人和最后修改人。 |
| createdAt / updatedAt | 创建时间与最后更新时间,用于审计追踪。 |
这个接口的核心思路是:
每次灰度提交都会生成一份独立配置快照,并与审批流程绑定,
审批通过后写入数据库并落地生效,从而保证灰度操作的安全性与可追溯性。
关于数据库的设计
为了让灰度机制具备可追踪、可审计、可恢复的能力,我在数据库层面主要设计了三张核心表,分别负责不同的职责:
- gray_strategy --- 灰度配置主表,用于保存当前灰度策略及审批状态。
- gray_strategy_log --- 灰度配置变更记录表,用于记录每一次策略调整的前后版本快照。
- gray_whitelist --- 灰度白名单表,用于标记在比例外仍需强制进入灰度的特定用户。
一、灰度配置表(gray_strategy)
这张表是整个灰度系统的核心配置记录。
每当运营或管理员提交一次灰度配置(比如修改灰度比例、调整渠道或平台等), 都会在这张表中生成一条记录。
sql
CREATE TABLE `gray_strategy` (
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT '主键',
`project_code` varchar(64) NOT NULL COMMENT '项目标识,如 license-center',
`config_version` int(11) NOT NULL DEFAULT '1' COMMENT '配置版本号(每次保存+1)',
`etag` varchar(64) DEFAULT NULL COMMENT '配置签名/哈希,便于缓存对比',
`approval_status` varchar(32) NOT NULL DEFAULT 'pending' COMMENT '配置审批状态:pending(待审批)/approved(已通过)/rejected(已驳回)',
`target_version` varchar(32) NOT NULL COMMENT '目标灰度版本号,如 v5.8.0',
`percentage` tinyint(4) NOT NULL DEFAULT '0' COMMENT '灰度比例(0-100),按用户hash生效的比例',
`start_at` datetime DEFAULT NULL COMMENT '生效开始时间',
`end_at` datetime DEFAULT NULL COMMENT '生效结束时间,可空',
`remark` varchar(512) DEFAULT NULL COMMENT '备注',
`types_json` json DEFAULT NULL COMMENT '启用的维度数组,如 ["user","channel","platform","tenant"]',
`rules_json` json DEFAULT NULL COMMENT '规则明细JSON',
`cache_ttl` int(11) NOT NULL DEFAULT '5' COMMENT '边缘缓存TTL(秒)',
`created_by` varchar(64) NOT NULL COMMENT '创建人',
`updated_by` varchar(64) NOT NULL COMMENT '最后修改人',
`created_at` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`updated_at` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
`is_deleted` tinyint(1) NOT NULL DEFAULT '0' COMMENT '逻辑删除',
PRIMARY KEY (`id`),
KEY `idx_strategy_project` (`project_code`),
KEY `idx_strategy_approval_status` (`approval_status`),
KEY `idx_strategy_updated_at` (`updated_at`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='灰度配置审批表(灰度启用态下的配置审批记录)';这张表是整个系统的"灰度当前态"数据来源。
字段 config_version 用于和日志表(gray_strategy_log)中的版本号对应,
保证每一次配置修改都有前后版本可追溯。
二、灰度配置变更记录表(gray_strategy_log)
这张表用来记录每一次灰度配置的变动轨迹,
包括操作类型(提交、审批、修改等)、变动前后版本号,以及配置快照。 通过这张表,可以完整追踪灰度策略的历史变化情况。
sql
CREATE TABLE `gray_strategy_log` (
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT '主键',
`strategy_id` bigint(20) NOT NULL COMMENT '关联灰度配置ID',
`project_code` varchar(64) NOT NULL COMMENT '项目标识',
`target_version` varchar(32) DEFAULT NULL COMMENT '灰度目标版本号,如 v5.8.0',
`change_type` varchar(32) NOT NULL COMMENT '变更类型:submit/approve/reject/update等',
`version_before` int(11) DEFAULT '0' COMMENT '变更前版本号',
`version_after` int(11) DEFAULT '0' COMMENT '变更后版本号',
`old_config` json DEFAULT NULL COMMENT '变更前配置快照',
`new_config` json DEFAULT NULL COMMENT '变更后配置快照',
`operator` varchar(64) DEFAULT NULL COMMENT '操作人',
`remark` varchar(512) DEFAULT NULL COMMENT '备注说明',
`created_at` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '操作时间',
PRIMARY KEY (`id`),
KEY `idx_strategy_log_project` (`project_code`),
KEY `idx_strategy_log_strategy` (`strategy_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='灰度配置变更日志链路表';通过字段 version_before / version_after ,
可以将同一条灰度策略的变动历史完整串联起来。
而 old_config / new_config 保存的则是配置内容的前后 JSON 快照,
方便在后台进行"差异对比"或"回滚"。
这张表的存在,使得灰度配置具备了完整的版本链路能力。
三、灰度白名单表(gray_whitelist)
这张表用于存储被强制加入灰度测试的特定用户。
这些用户不会受到灰度比例或 hash 规则的限制, 无论配置的比例是多少,只要在白名单内,就会直接进入灰度范围。
sql
CREATE TABLE `gray_whitelist` (
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT '主键ID',
`project_code` varchar(64) NOT NULL COMMENT '项目标识(如 license-center)',
`strategy_id` bigint(20) unsigned NOT NULL COMMENT '关联灰度策略ID(gray_strategy.id)',
`user_id` varchar(128) NOT NULL COMMENT '用户唯一标识(可为 userId 或 deviceId)',
`source` varchar(32) NOT NULL DEFAULT 'upload' COMMENT '来源方式:upload=文件导入,manual=手动添加,sync=系统同步',
`created_by` varchar(64) NOT NULL COMMENT '操作人(上传或添加人)',
`created_at` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
PRIMARY KEY (`id`),
UNIQUE KEY `uniq_strategy_user` (`strategy_id`,`user_id`),
KEY `idx_whitelist_project` (`project_code`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='灰度用户白名单表(用于标记强制灰度用户)';这种设计保证了白名单机制的灵活性,
支持多来源(手动添加、批量上传、系统同步),
并通过唯一索引防止重复导入同一用户。
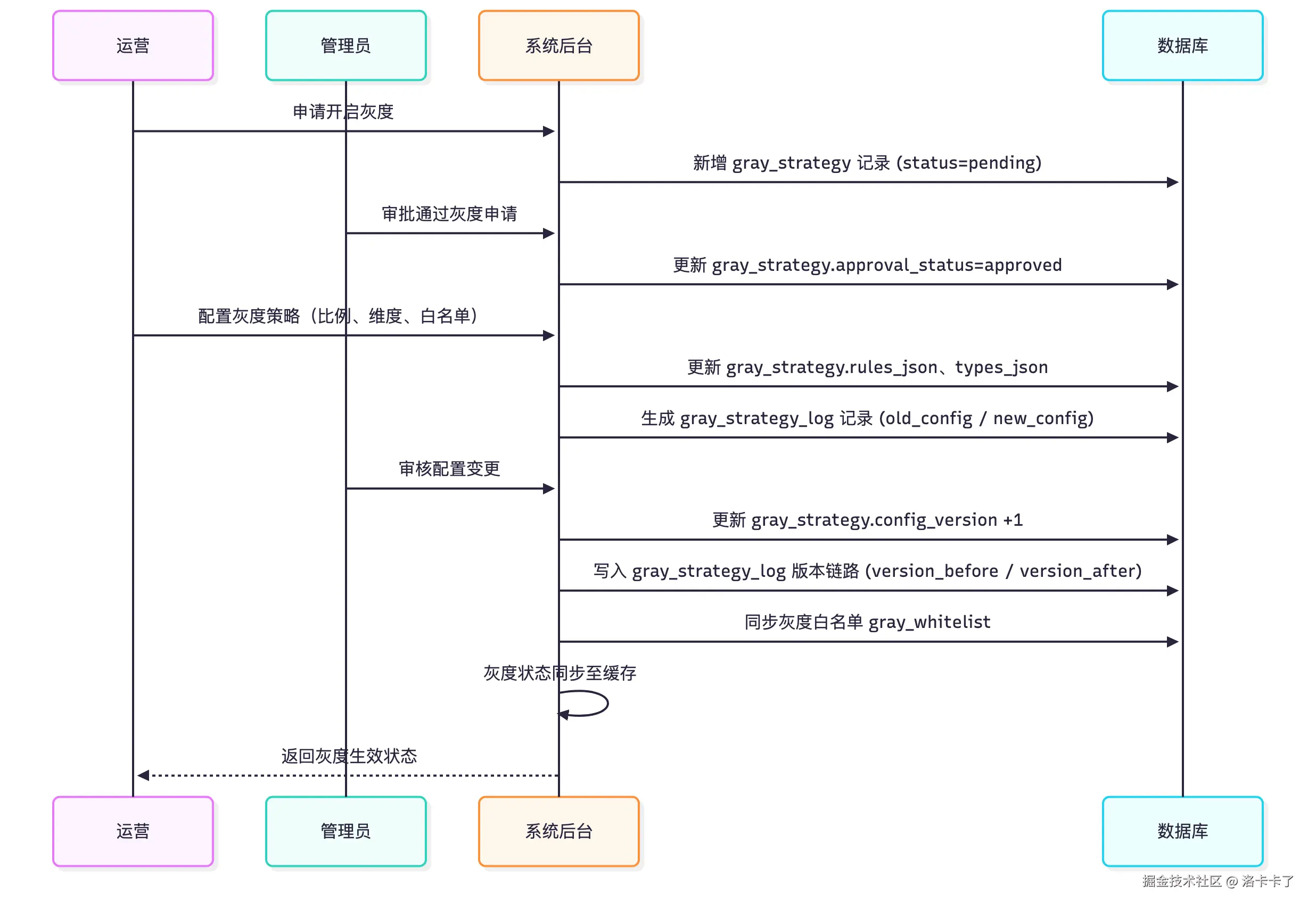
面这三张表基本构成了整个灰度系统在数据层的核心。 但从业务角度来看,它们其实是围绕着同一个流程在运转的。
从运营发起灰度申请、管理员审批、配置策略、提交变更,到日志记录与白名单同步,
整个过程都会在系统和数据库之间形成一条完整的链路。
下面这张流程图,是后台灰度操作的大致过程示意,
可以更直观地看出灰度在不同阶段是如何流转、落库和生效的:
关于灰度后台接口设计
后台页面和数据库都准备好之后,接下来就是接口层的实现。
整个灰度系统里,接口的作用主要是承上启下:
既要接收前端的配置提交,又要驱动审批流程和数据落库。
在这里我们重点讲两个核心接口:
一个是 提交灰度配置接口 ,用于保存本次灰度策略并进入审批流程;
另一个是 审批接口 ,用于管理员审核灰度申请、更新状态并触发配置生效。
这两个接口基本涵盖了灰度从"提交"到"生效"的关键路径。
提交灰度配置接口
第一个核心接口是"提交灰度配置",主要用于接收后台提交的灰度策略信息,并进入审批流程。
接口分为控制层与业务层两个部分:控制器负责接收前端请求,业务层负责逻辑处理与数据落库。
控制器部分
我们新增一个 /submit 接口,用于接收前端传来的 JSON 对象与操作者信息。
成功后返回提示"灰度配置提交成功,等待审批"。
如果发生异常,会将错误信息返回给前端。
java
@PostMapping("/submit")
public Result<String> submit(
@RequestBody Map<String, Object> payload,
@RequestHeader(value = "X-User", defaultValue = "system") String operator) {
try {
grayStrategyService.submitGrayStrategy(payload, operator);
return Result.ok("灰度配置提交成功,等待审批");
} catch (Exception e) {
e.printStackTrace();
return Result.fail("提交灰度配置失败:" + e.getMessage());
}
}然后接口实现部分代码如下:
java
/**
* 提交灰度配置
*
* @param payload 前端传入的 JSON 对象
* @param operator 当前操作人
*/
@Transactional
public void submitGrayStrategy(Map<String, Object> payload, String operator) {
String projectCode = (String) payload.get("projectCode");
String targetVersion = (String) payload.get("targetVersion");
if (projectCode == null || targetVersion == null) {
throw new IllegalArgumentException("projectCode 与 targetVersion 不能为空");
}
// 判断是否存在审批中的配置
GrayStrategy pending = grayStrategyMapper.selectOne(
new LambdaQueryWrapper<GrayStrategy>()
.eq(GrayStrategy::getProjectCode, projectCode)
.eq(GrayStrategy::getTargetVersion, targetVersion)
.eq(GrayStrategy::getApprovalStatus, "pending")
.eq(GrayStrategy::getIsDeleted, 0)
.last("LIMIT 1")
);
if (pending != null) {
throw new IllegalStateException("当前项目版本已有待审批的灰度配置,请勿重复提交。");
}
// 查询同项目+版本记录
GrayStrategy existing = grayStrategyMapper.selectOne(
new LambdaQueryWrapper<GrayStrategy>()
.eq(GrayStrategy::getProjectCode, projectCode)
.eq(GrayStrategy::getTargetVersion, targetVersion)
.eq(GrayStrategy::getIsDeleted, 0)
.last("LIMIT 1")
);
if (existing != null) {
//自增配置版本
existing.setConfigVersion(existing.getConfigVersion() + 1);
// 业务字段更新
existing.setPercentage((Integer) payload.getOrDefault("percentage", 0));
existing.setStartAt(parseToLocalDateTime(payload.get("startAt")));
existing.setEndAt(parseToLocalDateTime(payload.get("endAt")));
existing.setRemark((String) payload.get("remark"));
existing.setTypesJson(JSON.toJSONString(payload.get("types")));
existing.setRulesJson(JSON.toJSONString(payload.get("rules")));
existing.setCacheTtl(resolveCacheTtlByEnv());
// 状态重置为待审
existing.setApprovalStatus("pending");
existing.setUpdatedBy(operator);
existing.setUpdatedAt(LocalDateTime.now());
grayStrategyMapper.updateById(existing);
return;
}
// === 不存在则新建 ===
// 找该项目+该版本目前最大的 config_version
Integer maxVersion = grayStrategyMapper.selectMaxConfigVersion(projectCode, targetVersion);
int newVersion = (maxVersion == null ? 0 : maxVersion) + 1;
GrayStrategy strategy = new GrayStrategy();
strategy.setProjectCode(projectCode);
strategy.setTargetVersion(targetVersion);
strategy.setConfigVersion(newVersion);
String etag = "sha1-" + DigestUtils.sha1Hex(
projectCode + "-" + targetVersion + "-" + System.currentTimeMillis());
strategy.setEtag(etag);
strategy.setApprovalStatus("pending");
strategy.setPercentage((Integer) payload.getOrDefault("percentage", 0));
strategy.setStartAt(parseToLocalDateTime(payload.get("startAt")));
strategy.setEndAt(parseToLocalDateTime(payload.get("endAt")));
strategy.setRemark((String) payload.get("remark"));
strategy.setTypesJson(JSON.toJSONString(payload.get("types")));
strategy.setRulesJson(JSON.toJSONString(payload.get("rules")));
strategy.setCacheTtl((Integer) payload.getOrDefault("cacheTtl", 5));
strategy.setCreatedBy(operator);
strategy.setUpdatedBy(operator);
grayStrategyMapper.insert(strategy);
}大概逻辑说明
在 GrayStrategyService.submitGrayStrategy() 方法中,
我们把整个流程主要分为四步:参数校验 → 重复判断 → 版本处理 → 数据入库。
-
参数校验
校验
projectCode与targetVersion是否为空,这两个字段是灰度配置的关键定位信息,一个项目下同一版本的灰度配置必须唯一。
-
重复提交判断
首先判断该项目+版本是否已有状态为
pending的灰度配置(即正在审批中),如果存在,则直接抛出异常,避免重复提交。
-
版本控制与更新逻辑
如果该项目+版本下已经存在灰度配置记录,则:
- 将
configVersion自增 1; - 更新核心业务字段(比例、维度、时间、备注等);
- 将状态重置为
pending,重新进入审批流程; - 最后更新
updatedBy与updatedAt。
这样可以确保每次调整配置都能形成新的版本记录,
后续在日志表中就能通过版本号追溯变更历史。
- 将
-
新建记录逻辑
如果数据库中不存在当前项目+版本的记录,则创建新记录:
- 先查询最大版本号,计算新的
configVersion; - 生成唯一的配置签名
etag; - 设置状态为
pending,并写入所有配置字段; - 最后将创建人、更新时间一并落库。
- 先查询最大版本号,计算新的
审批灰度配置接口
在提交灰度配置后,下一步就是管理员的审批操作。
这一步是整个灰度流程中"决定是否生效"的关键节点。
在系统中,审批接口的职责主要是更新配置状态,并在审批通过时生成变更日志。
控制器部分
我们还是新增了一个 /approve 接口,接收前端传来的审批动作和操作者信息。
动作类型分为两种:
approved:审批通过rejected:审批驳回
执行完成后,返回统一的操作结果。
java
@PostMapping("/approve")
public Result<String> approveStrategy(
@RequestBody Map<String, Object> payload,
@RequestHeader(value = "X-User", required = false) String operator) {
try {
grayStrategyService.approveGrayStrategy(payload, operator);
return Result.ok("审批操作完成");
} catch (Exception e) {
e.printStackTrace();
return Result.fail("审批失败:" + e.getMessage());
}
}然后接口实现部分代码如下:
java
/**
* 灰度配置审批逻辑
*/
public void approveGrayStrategy(Map<String, Object> payload, String operator) {
Long strategyId = Long.valueOf(payload.get("id").toString());
String action = (String) payload.get("action"); // approved / rejected
String remark = (String) payload.getOrDefault("remark", "");
GrayStrategy strategy = grayStrategyMapper.selectById(strategyId);
if (strategy == null) {
throw new RuntimeException("灰度配置不存在");
}
// 审批通过
if ("approved".equals(action)) {
strategy.setApprovalStatus("approved");
strategy.setUpdatedBy(operator);
grayStrategyMapper.updateById(strategy);
/// 重新生成 ETag,确保缓存刷新
String newEtag = "sha1-" + DigestUtils.sha1Hex(
strategy.getProjectCode() + "-" +
strategy.getTargetVersion() + "-" +
System.currentTimeMillis());
strategy.setEtag(newEtag);
// 构造日志记录
GrayStrategyLog log = new GrayStrategyLog();
log.setStrategyId(strategyId);
log.setProjectCode(strategy.getProjectCode());
log.setTargetVersion(strategy.getTargetVersion());
log.setChangeType("approve");
log.setVersionBefore(strategy.getConfigVersion() - 1);
log.setVersionAfter(strategy.getConfigVersion());
log.setOperator(operator);
log.setRemark("审批通过:" + remark);
//当前配置(newConfig)
log.setNewConfig(buildCleanJsonSnapshot(strategy));
//获取上一个版本配置,作为 oldConfig
GrayStrategyLog prevApproved = logMapper.selectOne(
new LambdaQueryWrapper<GrayStrategyLog>()
.eq(GrayStrategyLog::getProjectCode, strategy.getProjectCode())
.eq(GrayStrategyLog::getTargetVersion, strategy.getTargetVersion())
.eq(GrayStrategyLog::getChangeType, "approve")
.eq(GrayStrategyLog::getVersionAfter, strategy.getConfigVersion() - 1)
.orderByDesc(GrayStrategyLog::getId)
.last("LIMIT 1")
);
if (prevApproved != null && prevApproved.getNewConfig() != null) {
log.setOldConfig(prevApproved.getNewConfig());
} else {
log.setOldConfig("{}");
}
//插入日志
logMapper.insert(log);
}
// 审批拒绝
else if ("rejected".equals(action)) {
strategy.setApprovalStatus("rejected");
strategy.setUpdatedBy(operator);
grayStrategyMapper.updateById(strategy);
//不写入 gray_strategy_log
}
else {
throw new IllegalArgumentException("无效的审批动作: " + action);
}
}大概逻辑说明
在 GrayStrategyService.approveGrayStrategy() 方法中,逻辑主要分为三个部分:参数解析 → 状态更新 → 日志记录。
-
参数解析与校验
从请求体中解析
strategyId、action、remark等字段。首先确认对应的灰度配置是否存在,否则直接抛出异常。
-
审批通过逻辑
当
action=approved时:- 将
approvalStatus更新为approved; - 同时重新生成新的
ETag,以便后续灰度策略缓存刷新; - 构造一条日志记录
GrayStrategyLog,记录本次变更的前后版本号、操作者、备注说明; - 并将当前策略的快照作为
newConfig,上一个版本(如果存在)作为oldConfig; - 最后将日志插入数据库,形成版本链路。
- 将
-
审批驳回逻辑
当
action=rejected时,仅更新状态为rejected,不会写入日志表,也不会触发配置生效。
因为驳回代表本次提交无效,不需要记录为有效变更历史。
关于 ETag 的重新生成
在每次审批通过时,我们都会重新生成一个新的 ETag 值:
java
String newEtag = "sha1-" + DigestUtils.sha1Hex(
strategy.getProjectCode() + "-" +
strategy.getTargetVersion() + "-" +
System.currentTimeMillis());这样做的目的,是为了确保配置缓存的刷新机制 能够及时生效。
后续在服务端或灰度分流模块中,我们会根据 ETag 来判断当前缓存是否需要更新。
只要有新的 ETag 出现,系统就会主动重新加载最新的灰度配置,
避免灰度状态延迟或缓存未更新导致的问题。
关于如何获取用户灰度标识的设计
到这里为止,我们的灰度后台部分基本已经完善了:
数据库结构、配置管理、审批流程、接口设计都已经具备,
也就是说后台已经可以完整地支撑灰度策略的录入与管理。
接下来的问题就是:前端或业务服务该如何根据这些配置,判断用户是否处于灰度状态?
既然我们已经做了一整套灰度后台,那么就没必要再在 Nginx 里通过 Lua 脚本配合 Redis 去判断用户灰度。
那种方式虽然能实现灰度分流,但可维护性差、操作复杂、上线风险也高。
因此在这一套设计中,我选择了更轻量、统一的方式:
由后端服务直接提供一个 config 接口,用于返回用户当前的灰度状态。
简单来说就是:
当客户端或业务服务需要判断某个用户是否命中灰度时,只需要调用这个接口,
系统会根据后台配置的灰度维度(用户、渠道、平台、包名、租户等)
以及当前用户的相关信息(userId、channel、platform 等)进行计算, 最终返回一个布尔值或标识字段,例如:
json
{
"gray": true,
"reason": "stable",
"version": "v5.8.0",
"hash": "09f21776ede23bdb8cc6ab5d524878572ec35374",
"configVersion": "2"
}通过这种方式,我们就把灰度逻辑从网关层解耦到了服务层,
让灰度判断既能动态配置,又能和后台保持一致的版本管理与审批机制。
同时,所有调用方(包括 Web、App、后端服务)都能统一通过这个接口获取灰度结果,
使整个灰度体系更加清晰、可控。
获取灰度标识接口设计
在灰度后台完成配置、审批并落库后,接下来最关键的一步,就是让客户端或前端能真正"感知"到灰度状态。
为此,我们设计了一个统一的接口:/config/get,用于根据后台配置和用户信息判断当前是否命中灰度。
一、请求对象
接口请求体使用 AppConfigRequest 对象来承载参数。
这些参数既能定位项目,也能保证灰度判定的准确性。
java
package org.example.gray.graydemo.controller.dto;
import lombok.Data;
/**
* 应用配置接口(/config/get)的请求对象
*
* 用途:
* - 客户端或前端请求时传入的参数,用于灰度命中判断
* - 必传:projectCode、version、userId、clientHash
*/
@Data
public class AppConfigRequest {
/** 项目唯一标识,例如 "license-center" */
private String projectCode;
/** 目标版本号,例如 "v5.8.0"(灰度目标版本) */
private String version;
/** 用户唯一标识 */
private String userId;
/** 客户端上一次计算的 hash,用于快速一致性校验 */
private String clientHash;
}二、接口控制器
我们把控制层定义在 ConfigController 中,接口路径为 /config/get,通过 POST 调用。
它负责校验基础参数,并调用 ConfigService 进行灰度计算。
java
@RestController
@RequiredArgsConstructor
@RequestMapping("/config")
public class ConfigController {
private final ConfigService configService;
/**
* 获取应用配置(灰度判定)
*
* 调用方式:
* POST /config/get
*
* 请求体:
* {
* "projectCode": "license-center",
* "version": "v5.8.0", // 用于校验客户端缓存版本
* "userId": "10002333"
* "clientHash": "abcde12345" // 客户端上次计算的 hash
* }
*
* 返回值:
* 当前项目的灰度配置判断结果(是否命中灰度)
*/
@PostMapping("/get")
public Result<AppConfigResponse> getAppConfig(@RequestBody AppConfigRequest req) {
if (req.getProjectCode() == null || req.getUserId() == null || req.getVersion() == null) {
return Result.fail("projectCode、version、userId 不能为空");
}
AppConfigResponse response = configService.getAppConfig(req);
return Result.ok(response);
}
}三、返回结果结构
接口响应使用 AppConfigResponse 对象,我们封装了下灰度命中状态及辅助信息。
java
@Data
@NoArgsConstructor
@AllArgsConstructor
public class AppConfigResponse {
/** 是否灰度用户 */
private boolean gray;
/** 命中结果描述(hit-gray / stable / no-config / not-started 等) */
private String reason;
/** 灰度目标版本号 */
private String version;
/** 本次灰度判定的结果哈希值(客户端缓存对比使用) */
private String hash;
/** 配置版本号(灰度策略版本) */
private String configVersion;
/** 快速构造稳定响应 */
public static AppConfigResponse stable(String reason, String version, String configVersion) {
return new AppConfigResponse(false, reason, version, null, configVersion);
}
/** 快速构造命中灰度响应 */
public static AppConfigResponse gray(String version, String hash, String configVersion) {
return new AppConfigResponse(true, "hit-gray", version, hash, configVersion);
}
/** 返回 304(配置未变更)场景 */
public static AppConfigResponse notModified(boolean gray, String hash) {
AppConfigResponse r = new AppConfigResponse();
r.setGray(gray); // 保持上次灰度状态
r.setReason("not-modified");
r.setHash(hash);
return r;
}
}灰度核心逻辑实现
灰度系统的核心逻辑全部集中在 ConfigService 中,它决定了每个用户是否命中灰度。
这个类既是"灰度规则的计算引擎",也是"配置缓存的控制中心"。 全部代码如下(我写的demo。很多懒得细改了 大概看看就行哈):
java
@Slf4j
@Service
@RequiredArgsConstructor
public class ConfigService {
private final RedisUtils redisUtils;
private final GrayStrategyMapper grayStrategyMapper;
private final ObjectMapper objectMapper;
private final UserProfileService userProfileService;
private final GrayWhitelistService grayWhitelistService;
/**
* 获取灰度配置结果
* @param req 请求参数:projectCode、version、userId 等
* @return 灰度判定结果
*/
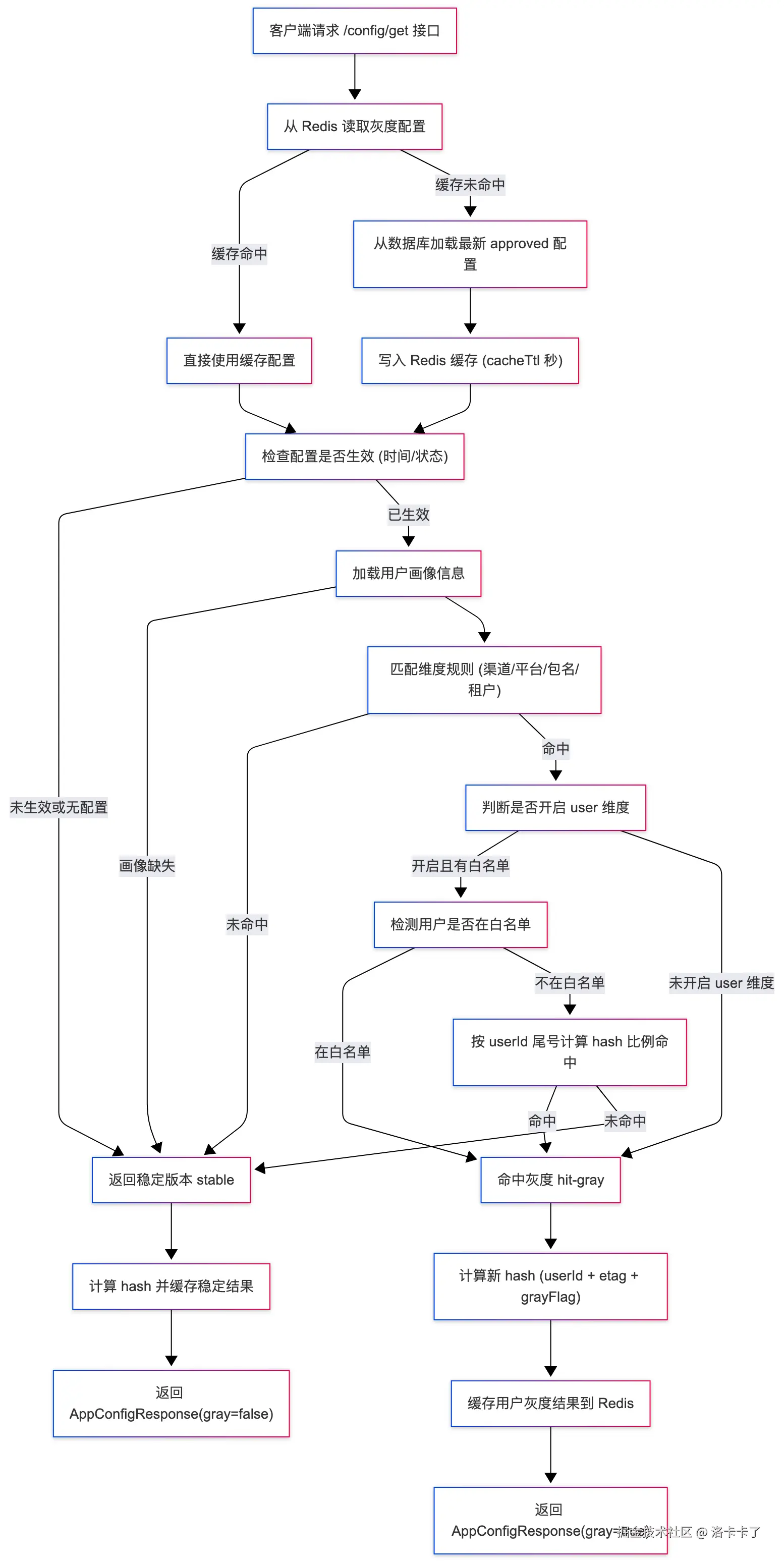
public AppConfigResponse getAppConfig(AppConfigRequest req) {
// Redis Key 按项目维度存储当前生效配置
String cfgKey = GrayRedisKeys.config(req.getProjectCode());
// Redis → DB 加载当前生效配置(仅 approved)
GrayStrategy config = redisUtils.get(cfgKey, GrayStrategy.class);
if (config == null) {
config = grayStrategyMapper.selectApprovedConfig(req.getProjectCode(), req.getVersion());
if (config != null) {
// === 使用 cache_ttl 字段 ===
int ttlSeconds = (config.getCacheTtl() == null || config.getCacheTtl() < 5)
? 5 // 默认至少缓存5秒,避免频繁访问DB
: config.getCacheTtl();
redisUtils.set(cfgKey, config, ttlSeconds);
}
}
// 无配置:走旧版本
if (config == null) {
return defaultStableResponse(req.getVersion(), "no-gray-config");
}
// 未到生效时间:稳定
if (config.getStartAt() != null && LocalDateTime.now().isBefore(config.getStartAt())) {
return stableResponse("gray-not-started", config);
}
// 解析 JSON → 业务配置
GrayConfig grayCfg = parseGrayConfig(config);
// 加载用户画像(渠道/平台/包名/租户)
UserProfile profile = userProfileService.loadByUserId(req.getUserId());
// 若用户画像都没有,无法命中维度,直接稳定
if (profile == null) {
return stableResponse("user-profile-missing", config);
}
// 尝试取用户灰度缓存
String userKey = GrayRedisKeys.userResult(req.getProjectCode(), req.getUserId());
AppConfigResponse cached = redisUtils.get(userKey, AppConfigResponse.class);
if (cached != null) {
// 如果客户端没传 hash,直接使用缓存结果即可(节省重算)
if (!StringUtils.hasText(req.getClientHash())) {
log.info("[GrayConfig] user={} 未上传 clientHash,直接返回缓存结果", req.getUserId());
return cached;
}
// 如果客户端上传的 hash 与缓存一致 -> 配置未变化
if (cached.getHash() != null && cached.getHash().equals(req.getClientHash())) {
log.info("[GrayConfig] user={} cache命中 & hash一致 -> 返回缓存", req.getUserId());
return AppConfigResponse.notModified(cached.isGray(), cached.getHash());
}
// hash 不一致(说明配置或命中状态变了) -> 继续往下计算
log.info("[GrayConfig] user={} 缓存存在但 hash 不一致 (clientHash={}, serverHash={}),重新计算",
req.getUserId(), req.getClientHash(), cached.getHash());
}
// 多维度命中 + 用户比例(hash)
boolean grayFlag = hitAllDimensionsThenUserHash(req.getUserId(), profile, grayCfg, config);
// 计算hash用于客户端比对
String hash = DigestUtils.sha1Hex(req.getUserId() + "|" + config.getEtag() + "|" + grayFlag);
// 生成响应并缓存
AppConfigResponse resp = new AppConfigResponse(grayFlag,
grayFlag ? "hit-gray" : "stable",
config.getTargetVersion(),
hash,
String.valueOf(config.getConfigVersion()));
redisUtils.set(userKey, resp, config.getCacheTtl());
return resp;
}
/**
* 解析 JSON 配置(rulesJson / typesJson)
* @param cfg GrayStrategy 原始配置
* @return GrayConfig 业务对象
*/
private GrayConfig parseGrayConfig(GrayStrategy cfg) {
try {
GrayConfig gc = new GrayConfig();
if (StringUtils.hasText(cfg.getRulesJson())) {
// rulesJson 形如:{"user":{"mode":"hash","percentage":10},"channel":["xiaomi"],"platform":["android"],"pkg":["com.demo"],"tenant":["1","2"]}
GrayConfig.Rules rules = objectMapper.readValue(cfg.getRulesJson(), GrayConfig.Rules.class);
gc.setRules(rules);
}
if (StringUtils.hasText(cfg.getTypesJson())) {
List<String> types = objectMapper.readValue(
cfg.getTypesJson(),
new TypeReference<List<String>>() {}
);
gc.setTypes(types);
}
return gc;
} catch (Exception e) {
log.error("parseGrayConfig error, project={}, err={}", cfg.getProjectCode(), e.getMessage());
return new GrayConfig();
}
}
/**
* 严格顺序:
* 1) 若 types 启用了某维度(channel/platform/pkg/tenant),则用户该维度必须命中 rules 中的集合;
* - 若该维度启用但集合为空,视为"无任何人命中",直接失败
* 2) 前述维度全部命中后,若启用了 user 维度且 mode=hash,则再做比例命中
* 3) 若 user 维度未启用,则维度全部命中即视为灰度(满足"都开启时再hash"的规则,也兼容"未开启user"的场景)
*/
private boolean hitAllDimensionsThenUserHash(String userId, UserProfile p, GrayConfig cfg, GrayStrategy strategy) {
if (cfg == null || cfg.getRules() == null || CollectionUtils.isEmpty(cfg.getTypes())) {
return false; // 未配置任何类型 → 不命中
}
GrayConfig.Rules rules = cfg.getRules();
List<String> types = cfg.getTypes();
// 维度:channel
if (types.contains("channel")) {
if (rules.getChannel() == null || rules.getChannel().isEmpty()) return false;
if (!rules.getChannel().contains(nullToEmpty(p.getChannel()))) return false;
}
// 维度:platform
if (types.contains("platform")) {
if (rules.getPlatform() == null || rules.getPlatform().isEmpty()) return false;
if (!rules.getPlatform().contains(nullToEmpty(p.getPlatform()))) return false;
}
// 维度:pkg(包名)
if (types.contains("package")) { // 若 types 里写的是 "package"
if (rules.getPkg() == null || rules.getPkg().isEmpty()) return false;
if (!rules.getPkg().contains(nullToEmpty(p.getPackageName()))) return false;
} else if (types.contains("pkg")) { // 或者统一使用 "pkg"
if (rules.getPkg() == null || rules.getPkg().isEmpty()) return false;
if (!rules.getPkg().contains(nullToEmpty(p.getPackageName()))) return false;
}
// 维度:tenant(注意:rules 里通常是字符串ID,这里转成字符串比较)
if (types.contains("tenant")) {
if (rules.getTenant() == null || rules.getTenant().isEmpty()) return false;
String userTenant = p.getTenantId() == null ? "" : String.valueOf(p.getTenantId());
if (!rules.getTenant().contains(userTenant)) return false;
}
// 所有维度命中后 → 检查用户灰度规则(前提是启用了 user 维度)
if (types.contains("user")) {
GrayConfig.UserRule userRule = rules.getUser();
if (userRule != null) {
//名单启用且用户在白名单中 → 直接灰度
if (Boolean.TRUE.equals(userRule.getWhitelistEnabled())) {
boolean inWhite = grayWhitelistService.isUserInWhitelist(strategy.getProjectCode(), strategy.getId(), userId);
if (inWhite) {
log.debug("用户 {} 命中白名单 -> 直接灰度", userId);
return true;
}
}
// 取 ID 尾号判断
if ("hash".equalsIgnoreCase(userRule.getMode())) {
int ratio = userRule.getPercentage() == null ? 0 : Math.max(0, Math.min(100, userRule.getPercentage()));
// 取ID后两位数字
int lastTwo = extractLastTwoDigits(userId);
log.info("[GrayConfig] user={} hash模式命中判定,percentage={}%,ID后两位={},阈值={}",
userId, ratio, lastTwo, ratio);
return lastTwo < ratio;
}
}
}
return true;
}
private String nullToEmpty(String s) { return s == null ? "" : s; }
private AppConfigResponse defaultStableResponse(String clientVersion, String reason) {
return new AppConfigResponse(false, reason, clientVersion, "", "0");
}
private AppConfigResponse stableResponse(String reason, GrayStrategy cfg) {
String version = cfg != null ? cfg.getTargetVersion() : "";
String configVer = cfg != null ? String.valueOf(cfg.getConfigVersion()) : "0";
return new AppConfigResponse(false, reason, version, "", configVer);
}
/**
* 从 userId 提取后两位数字
* - 如果 userId 是纯数字 → 直接取模 100
* - 如果包含字母 → 取数字部分再取模;都没有数字则 hashCode 降级
*/
private int extractLastTwoDigits(String userId) {
try {
// 优先尝试直接转数字
long val = Long.parseLong(userId.replaceAll("[^0-9]", ""));
return (int) (val % 100);
} catch (NumberFormatException e) {
// 降级:非纯数字ID,比如UUID → 用 hashCode 稳定取模
return Math.abs(userId.hashCode() % 100);
}
}
}一、核心职责
ConfigService 的主要职责可以概括为四个部分:
- 从 Redis 读取当前生效的灰度配置(减少数据库压力)
- 缓存未命中时,从数据库加载配置并写入 Redis
- 根据配置规则判断用户是否命中灰度
- 生成灰度判定结果并缓存,用于客户端快速比对
这样可以保证接口在高并发场景下依然轻量快速,同时也避免频繁命中数据库。
二、配置加载流程
第一步是从 Redis 中读取缓存的灰度策略:
java
String cfgKey = GrayRedisKeys.config(req.getProjectCode());
GrayStrategy config = redisUtils.get(cfgKey, GrayStrategy.class);如果缓存中不存在,就从数据库加载一份已审批通过 (approved) 的配置:
java
config = grayStrategyMapper.selectApprovedConfig(req.getProjectCode(), req.getVersion());拿到配置后,会根据配置的 cacheTtl(缓存有效期)将其重新写入 Redis,
默认至少缓存 5 秒,防止高并发下频繁访问数据库。
三、灰度有效性校验
加载完配置后,我们需要做几项前置校验:
- 无配置 → 返回稳定版本
- 尚未到生效时间 → 返回稳定版本
- 用户画像缺失(如渠道、平台等为空) → 返回稳定版本
这些判断可以防止用户在灰度条件不满足时被误判。
四、多维度命中逻辑
真正的灰度判定逻辑在 hitAllDimensionsThenUserHash() 方法中实现。
系统支持多种灰度维度组合:用户、渠道、平台、包名、租户。
判定顺序如下:
- 维度匹配 :
每个启用的维度(如channel、platform、tenant)都必须命中配置的集合;
若某维度启用但集合为空,视为无命中。 - 白名单优先 :
如果开启了用户白名单,并且当前用户在名单中,则直接命中灰度。 - 按用户 ID 取尾号命中比例 :
若启用了user维度且模式为hash,则取用户 ID 的后两位数字,
按比例判断是否命中,例如比例 10% 就代表尾号 00~09 的用户命中。
java
int ratio = userRule.getPercentage();
int lastTwo = extractLastTwoDigits(userId);
return lastTwo < ratio;这样既能保证灰度分配的稳定性,又能做到分布均匀。
五、结果缓存与 hash 计算
每次命中判断完成后,系统会计算一个用于客户端缓存的哈希:
java
String hash = DigestUtils.sha1Hex(req.getUserId() + "|" + config.getEtag() + "|" + grayFlag);客户端下次请求时会带上这个 clientHash。
如果服务端计算出的 hash 与客户端传来的相同,就说明配置没有变化,
这时直接返回 notModified,减少重复计算。
同时结果也会缓存到 Redis,默认缓存时长与配置的 cacheTtl 保持一致。
这个在前面我们提到过,系统会在返回结果时计算一个用于缓存校验的 hash 值。
这个 hash 是由三部分拼接计算得出的:
java
String hash = DigestUtils.sha1Hex(req.getUserId() + "|" + config.getEtag() + "|" + grayFlag);这里的 etag 是关键。
它在我们前面讲审批接口的时候提到过 ------ 每次灰度配置被修改或审批通过时,系统都会重新生成一个新的 etag。
也就是说,每一次配置变更都会导致新的 etag 出现 ,
而这个 etag 又直接参与 hash 计算,因此 hash 值也必然会随之变化。
所以当客户端下次再请求 /config/get 接口时,
它会携带上一次保存的 clientHash,服务端计算出新的 hash 后两者进行比对:
- 如果 相同 ,说明配置没变、用户灰度状态也没变,直接返回
notModified; - 如果 不同,就说明配置或灰度命中逻辑发生了变化,需要重新计算灰度状态并返回最新结果。
通过这种方式,系统可以在不增加额外字段、不强制刷新缓存的情况下,
实现灰度配置的自动同步与状态更新,让客户端与服务端的灰度判定始终保持一致。
六、整体调用流程
整个接口的执行顺序可以总结如下:
- 从 Redis 加载灰度配置;
- 若无缓存,则从数据库加载并回写缓存;
- 校验配置生效时间与用户画像;
- 按多维度判断是否命中灰度;
- 计算 hash,生成响应结果并缓存;
- 返回
AppConfigResponse给客户端。
七、我们这样设计的优点
- 性能高:Redis 缓存灰度配置与用户命中结果,接口响应轻量。
- 逻辑清晰:每个维度独立判定,顺序固定,容易扩展。
- 一致性强:审批后生成新 ETag,可自动触发缓存刷新。
- 低耦合性:不依赖 Nginx + Lua + Redis 方案,直接由服务端统一计算。
疑问:为什么不直接用 Spring Cloud Gateway
有同学可能觉得使用Spring Cloud Gateway会更好,但是如果我们项目是纯 Java 技术栈,其实用 Spring Cloud Gateway 来做灰度分流是很自然的选择。
它可以在网关层统一拦截请求、基于 Header 或参数判断用户是否命中灰度,然后把请求转发到对应的服务实例。
这种方式在单一语言生态下确实方便,延迟低、扩展性强。
但问题在于,我们的业务并不都是 Java。
除了主业务服务,还有一些是 PHP 的接口服务、Go 的中台任务、甚至还有 前端 Web 页面 。
如果灰度逻辑都放在 Java 网关层,那其他语言的服务就无法复用,也会出现"各自实现一套灰度判断"的情况,
不仅容易出现逻辑不一致,还会增加维护成本。
所以在这套设计中,我选择了更通用化 的方案:
把灰度系统独立出来,做成一个独立的服务中心。
它有自己完整的后台管理页面、配置审批机制、以及统一的规则计算引擎,
并对外暴露一个获取用户灰度标识的接口。
这样一来:
- 各语言后端(PHP / Go / Java / Web) 都不需要再各自实现灰度逻辑;
- 灰度规则改动 只需在中心后台更新即可,全局统一生效;
- 灰度算法一致,避免版本差异、逻辑漂移等问题;
- 接入方式也很简单,业务方只需要调用一个 HTTP 或 RPC 接口即可拿到用户灰度标识。
这种做法相当于把灰度能力"服务化",让它从具体技术框架中抽离出来,
成为真正意义上的 灰度控制中心。
关于后端灰度部署设计
前面我们已经实现了灰度规则的配置、审批与接口判定逻辑,
现在要解决的就是:后端服务如何根据灰度标识分流到不同版本的集群。
在我们的实际部署中,比如我们后端服务是以集群的方式运行的。
每次灰度发布时,我们可以同时部署两套集群环境:
- 一套是当前线上运行的 旧版本集群;
- 一套是本次准备灰度上线的 新版本集群。
然后通过一层统一的 Nginx 负载均衡网关 来控制流量分发。
客户端或业务方在调用服务时,会在请求头中携带 x_gray_flag,
其值为 true 表示用户命中灰度版本,为 false 表示走旧版本。
Nginx 根据这个标识,就能动态地把流量分配到不同的后端集群。
比如我们配置一个灰度分流配置如下:
lua
# -----------------------------
# 灰度分流入口配置
# -----------------------------
# -----------------------------
# 旧版本集群
# -----------------------------
upstream old_backend {
server 1.116.125.37:8080 max_fails=3 fail_timeout=10s;
server 1.116.125.38:8080 max_fails=3 fail_timeout=10s;
server 1.116.125.39:8080 max_fails=3 fail_timeout=10s;
# ↑ 多节点轮询,默认 round-robin 模式
}
# -----------------------------
# 灰度版本集群
# -----------------------------
upstream gray_backend {
server 101.35.159.154:8080 max_fails=3 fail_timeout=10s;
server 101.35.159.155:8080 max_fails=3 fail_timeout=10s;
server 101.35.159.156:8080 max_fails=3 fail_timeout=10s;
}
# -----------------------------
# 根据请求头 X-Gray-Flag 判断灰度标识
# -----------------------------
map $http_x_gray_flag $is_gray {
~*^(true|on|1)$ 1;
default 0;
}
# 动态选择上游集群
map $is_gray $target_upstream {
1 gray_backend; # 灰度用户 → 新版本
0 old_backend; # 普通用户 → 旧版本
}
# -----------------------------
# 主服务配置
# -----------------------------
server {
listen 80;
server_name _;
# 访问日志,记录灰度状态
access_log /var/log/nginx/gray_access.log;
location / {
# 动态分流
proxy_pass http://$target_upstream;
# 透传请求头信息
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
# 保留灰度标识头,供后端识别
proxy_set_header X-Gray-Flag $http_x_gray_flag;
proxy_connect_timeout 3s;
proxy_send_timeout 30s;
proxy_read_timeout 30s;
}
}灰度流量分发逻辑
-
客户端或后端服务调用灰度中心接口
/config/get,获取用户是否属于灰度用户。
- 如果命中灰度:
x_gray_flag = true - 如果未命中:
x_gray_flag = false
- 如果命中灰度:
-
客户端发起业务请求 时,
会在 HTTP Header 中携带
x_gray_flag,并请求统一的网关域名或 IP(即 Nginx)。 -
Nginx 根据 Header 判断,自动将请求分发到对应版本的集群:
- 灰度用户 →
gray_backend(新版本集群) - 普通用户 →
old_backend(旧版本集群)
- 灰度用户 →
-
请求路径、域名、参数完全一致,业务端不需要关心用户命中了哪个版本。
在实际部署中需要注意的问题
在前面的例子里,我们只有一台 Nginx 作为灰度分流器。
这种结构在开发环境、测试环境,甚至一些小规模的私有化部署里,其实已经足够用了。
它简单、清晰,配置一份 Nginx 就能完成所有灰度分流逻辑。
但问题也很明显------这是一种单点结构。
首先是流量集中问题 。
所有请求都打到这一台机器上,Server A 就成了整个系统的"流量瓶颈"。
只要它挂掉,整个系统就不可访问。
而且随着访问量增加,这台机器的 CPU、网络、IO 压力会越来越大,
一旦负载过高,就可能出现连接超时或响应延迟的问题。
其次是扩容问题 。
当我们想要增加更多 Nginx 节点时,需要修改 DNS 或手动切流,
不仅麻烦,还容易造成流量分布不均,甚至出现部分用户访问异常的情况。
所以,在真正的生产环境中,我们通常会把这层 Nginx 灰度分流器设计成一个可扩展的集群结构,
前面再加一层 SLB(负载均衡入口) 来做统一流量分发。
结构大概是这样设计的:
arduino
┌────────────────┐
│ SLB (公网入口) │
└────────────────┘
│
┌─────────────┴─────────────┐
│ │
┌──────────┐ ┌──────────┐
│Server A1 │ │Server A2 │
│Nginx灰度 │ │Nginx灰度 │
└──────────┘ └──────────┘
│ │
├── old_backend 集群 ├── gray_backend 集群
└───────────────────────────┘那我们实际部署中的调用逻辑如下:

这层 SLB(Server Load Balancer) 可以是云服务提供的负载均衡(比如阿里云 SLB、腾讯云 CLB),
也可以是我们自建的反向代理节点。
每一台 Nginx 灰度分流器(Server A1、A2)都配置相同的灰度分流逻辑:
接收请求、识别 x_gray_flag、再分流到对应的后端集群。
这样做有几个明显的好处:
- 去掉单点风险:任何一台 Nginx 掉线,SLB 会自动把流量切到健康节点上;
- 自动扩容:新增灰度节点时,只需要在 SLB 控制台加一台机器,不用改域名、不用改代码;
- 配置统一:每台分流器使用相同的 gray.conf,不会出现逻辑不一致的问题;
- 弹性伸缩:高峰期多挂几台节点,低峰期可以缩减,运维成本可控。
不过,真正要做到高可用 ,还得加上"主动探活 "。
否则如果某台 Nginx 掉了,SLB 可能还在继续分流给它,
那流量就会打到一个已经宕机的节点上。
所以在云上的 SLB 一般会自带健康检查机制,
我们可以配置一个探活 URL,比如:
bash
/healthzNginx 或应用层只要返回 200,就说明节点健康。
如果连续几次探测失败,SLB 就会自动把这台机器从转发列表里剔除,
等探测恢复正常,再自动加回来。
如果是自建的反向代理,我们其实也可以自己做一个轻量的健康检测脚本,
比如用 curl 定时去请求每台灰度分流器的 /healthz 接口,
检测不通就报警或者自动移除。
有了探活机制之后,这个架构才是真正意义上的高可用集群------
既能均衡负载,又能自动切换、自动恢复, 灰度分流的整个链路也更稳、更可靠。
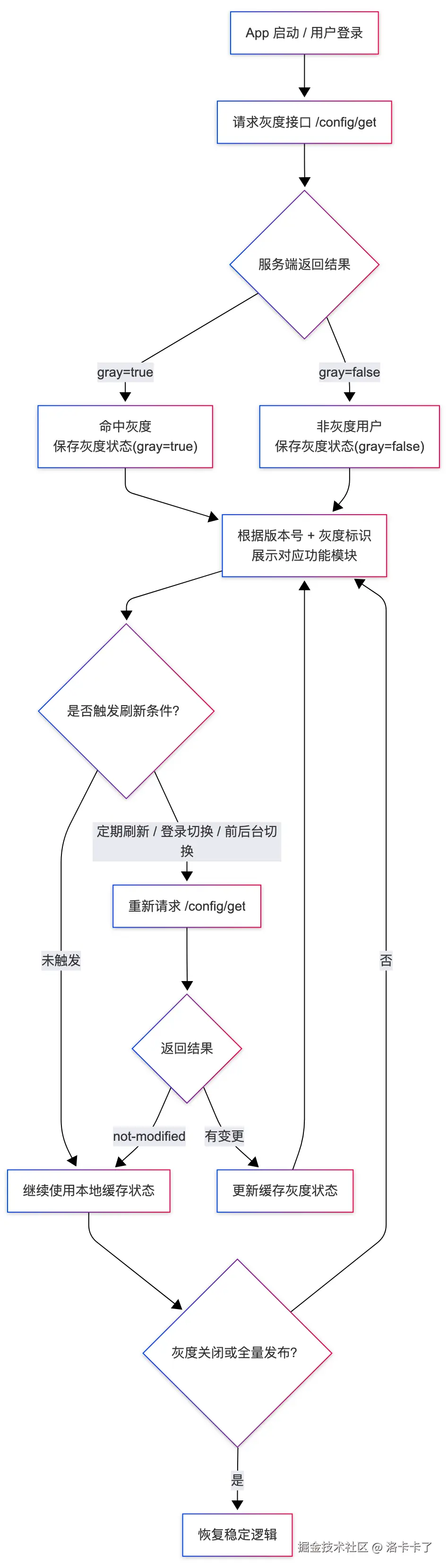
关于回滚与全量发布的流程
灰度上线最怕的,其实就是两个字------翻车 。
所以在一开始设计这套系统的时候,我就想着:
除了要能灰度,还得能随时回滚 ,出了问题能立刻切回来;
另外,灰度通过之后,也得有一套全量上线的逻辑,别每次都得重新部署。
先说回滚吧。
假如我们新版本上线后,发现有接口出错、逻辑异常、埋点不准之类的问题,
其实不用急着动集群、更不用回退代码。
只要在后台把灰度策略关掉就行了。
系统这时候返回的灰度标识就会变成 false,
客户端、Web、后端在拿到这个标识之后自然就走旧逻辑。
整个过程不用重启、不用发版,几秒钟内就能恢复。
对运维和开发来说都很安全,成本几乎为零。
再说全量。
灰度跑一段时间没问题之后,我们就把比例调成 100%,
也就是"全量灰度"。
这时候,所有请求都会进到新版本集群。
然后我们再把旧版本的集群也升级成同样的新版本,
最后把灰度开关彻底关掉------
这样,系统里其实已经没有"灰度"这个概念了,
所有用户都跑在同一个新版本上。
下次再有新版本上线,再按同样的流程开一轮灰度就行。
整个过程特别简单,也非常稳:
- 一旦出问题,就关掉灰度 → 快速回滚;
- 灰度通过了,就全量 → 升级旧集群 → 关掉灰度 → 完成全量上线。
无论我们是 Java 服务、PHP 接口,还是 Web 前端,逻辑都是一样的。
灰度标识就像一个"开关",
开了是新版本,关了就是旧版本。
只要这个开关设计得好,上线这件事就不会再那么让人提心吊胆。
关于客户端灰度设计与实现逻辑
前面的后台和服务端部分,主要解决了灰度配置怎么定义、审批、以及后端如何分流 的问题。
但整个灰度体系真正"落地"到用户身上,还得靠客户端来配合。
灰度的核心目标是------让部分用户体验到新功能,而不影响其他用户 。
所以客户端在整个流程中的作用,其实是"灰度状态的执行者"。
一、灰度配置的获取时机
还记得上面我们提到过的当灰度在后台审批通过后,系统会将"灰度开启状态"及相关规则落地到数据库。
其实就是设置一个配置项 比如灰度开启的配置标识
客户端在启动 App 或登录成功后,会通过一个统一的配置接口(例如 /api/app/config)
拉取最新的应用配置,其中就包括当前项目的灰度配置信息。如果发现灰度是开启状态则用户登录的时候会走获取用户灰度标识的接口。
所以这一阶段客户端不直接判断灰度命中逻辑,而是调用灰度中心提供的接口:
json
POST /config/get
{
"projectCode": "license-center",
"version": "v5.8.0",
"userId": "10002333",
"clientHash": "abcde12345"
}返回结果中会包含用户是否属于灰度用户:
json
{
"gray": true,
"reason": "hit-gray",
"version": "v5.8.0",
"hash": "sha1-9a0b3d...",
"configVersion": "3"
}客户端拿到结果后,会将 gray 标识与 hash 一并保存到本地缓存中。
在之后的逻辑中,这个灰度状态会影响前端的功能展示与行为控制。
二、客户端灰度标识的使用
当用户进入 App 后,不同的功能模块(例如会员中心、新版活动入口、新 UI 模块等)
都可以通过两个关键条件来决定是否展示:
- 当前版本号是否匹配灰度目标版本;
- 用户是否命中灰度(gray = true)。
例如:
scss
if (app.version === "v5.8.0" && user.isGray) {
showNewFeature(); // 显示新功能
} else {
showOldFeature(); // 保持旧版本逻辑
}通过这种方式,灰度功能的开关完全由后台控制,客户端无需发布新版本即可动态调整显示逻辑。
当然这里我只是举个例子,我不是特别熟悉客户端的这个逻辑 可能客户端会有更好更成熟的封装方式。这里只是提供一个思路哈。
三、灰度状态的更新机制
灰度状态并不是一次拉取就永远有效的。
可能我们后台在审批后调整了灰度比例、启用或关闭了灰度、或增加了新的白名单用户。
因此客户端需要定期刷新灰度状态。
通常有两种策略:
-
按时间定期刷新
- 启动时请求一次;
- 每隔固定周期(如 5 分钟或 10 分钟)自动重新拉取一次
/config/get; - 若返回
reason = "not-modified",则不更新本地状态。
-
按事件触发刷新
- 用户重新登录、切换账号;
- 应用切换前后台时;
- 检测到版本更新或本地缓存失效时。
这种方式可以在不增加太多网络开销的情况下,确保灰度状态足够新鲜。
四、设计优势
- 动态可控:灰度逻辑在服务端计算,客户端只负责展示控制;
- 无侵入性:无需在客户端硬编码用户范围,完全数据驱动;
- 轻量高效:客户端只需保存一个布尔值与 hash,接口调用频率可控;
- 可扩展性强:未来可结合埋点系统,对灰度用户行为单独采集分析。
大概流程如下:
关于前端灰度的两种实现方式
在灰度体系里,前端部分我个人觉得其实有两种常见的实现方式:
一种是在代码逻辑里做灰度判断 ,另一种是直接部署两套前端版本 。
这两种方式感觉各有优劣,适用的场景也完全不同。
一、方式一:逻辑控制式灰度
这种方式的思路是:
前端通过接口获取灰度状态(例如 /config/get 返回 gray = true),
然后在页面渲染时根据灰度状态来控制是否展示新功能。
比如:
javascript
<template>
<div>
<NewFeature v-if="gray" />
<OldFeature v-else />
</div>
</template>这种方案的优势是:
- 不需要多套部署环境;
- 新功能可以在同一个版本中提前准备,后台控制即可开启或关闭;
- 对小功能灰度、UI 变化、实验性入口都很方便。
但问题也很明显:
- 入侵性高,代码中要频繁判断;
- 随着灰度逻辑增加,页面结构会变得越来越复杂;
- 打包体积膨胀,新旧逻辑混在一起,容易出错;
- 回滚困难,一旦灰度功能有问题,必须重新构建或禁用逻辑分支。
因此,这种逻辑控制方式更适合小功能灰度 ,
比如:
- 新增一个入口按钮;
- 替换部分文案或样式;
- 做一次简单的 A/B 测试。
如果是完整的页面改版、新业务模块上线,其实就不建议继续堆这种逻辑了。
二、方式二:双版本部署式灰度
更标准、也更通用的做法是双版本部署 。
具体思路是:
当要上线一个大版本或新功能模块时,
前端直接构建出两套完整版本:
- 一套是稳定版(Stable);
- 一套是灰度版(Gray)。
然后由灰度中心接口返回用户是否命中灰度,
前端或服务端根据这个结果,决定加载哪个版本的资源。
比如:
- 灰度用户访问
https://gray.example.com - 普通用户访问
https://web.example.com
也可以通过同一域名 + 不同静态目录方式实现:
css
/var/www/html/stable/ → 稳定版
/var/www/html/gray/ → 灰度版服务端或 Nginx 根据请求头 X-Gray-Flag 动态映射:
灰度用户 → /gray/ 目录,普通用户 → /stable/ 目录。
这种方式的优点是非常明显的:
- 新旧版本完全隔离,互不影响;
- 部署可控,出问题可以一键回滚;
- 性能更好,不需要在页面逻辑里做复杂判断;
- 灰度粒度清晰,可配合服务端灰度比例精准控制。
缺点也有:
- 每次灰度需要两套构建;
- 发布成本略高;
- 对运维环境有一定要求(需要额外部署灰度静态目录或 CDN 路径)。
三、两种方案的取舍建议
一般来说我们可以这样判断:
| 场景 | 推荐方案 | 原因 |
|---|---|---|
| 小范围 UI 调整、文案替换、按钮显隐 | 逻辑控制式灰度 | 成本低、改动小 |
| 新页面、新功能模块上线 | 双版本部署式灰度 | 隔离性好、风险低 |
| 多语言或多端共用前端(Web、H5、小程序) | 双版本部署 | 统一网关分流,逻辑更清晰 |
| 快速实验 / 临时验证 | 逻辑控制 | 开发快、无需额外环境 |
讲讲关于灰度接入的问题
有同学曾经问过我一个问题:
"如果我现在这台服务器上同时跑着 MySQL、Redis 和应用服务,那我做灰度的时候,是不是得再拿一台服务器,把数据库和缓存都重新配一遍?"
其实这是个很典型的疑问,也反映出很多同学对"灰度发布"的一个常见误解。
灰度并不是每个项目都要做,更不是一上来就得配齐 SLB、集群、双版本部署。
灰度的核心目的是------降低上线风险 。
当系统复杂度高、用户量大、版本迭代频繁、甚至一次更新会影响多个业务链路时,
这时候才有必要上灰度机制。
因为它能让我们逐步放量、及时发现问题,避免一次性全量更新带来的灾难性后果。
反过来说,如果我们的项目还处在比较早期的阶段,
比如:
- 服务和数据库都在同一台机器上;
- 并发量不高;
- 用户规模可控;
- 更新频率也不算快;
那我们完全没必要一开始就做灰度。
此时的重点应该是稳定和快速迭代 ,
而不是引入一堆复杂的部署结构,让维护成本反而变高。
灰度发布更像是一个"成长阶段的产物"。
当系统逐渐变大,我们才会发现:
光靠测试环境不够用了,
光靠预发布也无法模拟真实流量,
线上一旦出错,影响面就会很广------
这个时候,灰度机制才真正体现价值。
结语
我们上面啰啰嗦嗦讲了这么多,终于算是把这套灰度系统的大致设计思路讲完了。
其实从最开始立项到现在,出发点一直都很简单,我们只是想在新功能上线前,多一道保险。
但当真正把后台、接口、数据库、审批、客户端接入、前端展示这些环节都串起来后,就会发现它不只是一个开关或者配置项,而是逐渐演变成了一套完整、可控的"上线策略体系"。
看起来有点复杂是不是? 我写起来也头疼...
但是其实等我们真正把灰度落地下来后,我们就能做到:
- 新版本逐步放量,风险可控;
- 线上问题快速回滚;
- 功能验证定向观察;
- 多端统一逻辑,减少重复开发。
这套灰度机制目前我们已经在内部多个项目中使用,
包括 Java 服务、PHP 接口、Go 网关以及 Web 前端。
所有端只需要调用统一的灰度接口,就能拿到用户标识,从而决定是否走新逻辑。
说到底,它并不是一个"大而全"的系统,
而是我们在小团队环境下,为了提高上线的安全性和可控性,用比较轻量的方式实现的一种"渐进式发布"方案。
当然哈,灰度也不是所有项目都必须要上的功能。
如果项目规模不大、发布频率不高,其实没必要搞得太复杂。
但一旦系统变得足够复杂、多人协作、一次上线就可能影响成千上万用户时,
灰度机制往往就是那道帮我们兜底的安全网。
其实灰度一点都不神秘,也不一定要很复杂。
只要思路清晰,哪怕用最简单的方式,也能把风险降到最低。
当然实际落地过程中我们要考虑的东西会更多 需要完善的东西也会比较麻烦一点。
这次 Demo 的后端接口代码我已经放在 GitHub 仓库里,感兴趣的可以去看看哈:github
文中提到的代码片段,大多都是为了演示方便写的示例。
很多地方其实都可以继续封装和优化,比如异常处理、缓存策略、接口鉴权、统一日志这些。
但对这篇文章来说,我更想先把整体思路和流程讲清楚这些--
从灰度后台、接口设计、到客户端接入与后端分流,
让大家能看到一套完整但不复杂 的灰度体系是怎么落地的。
所以代码写的很简单 只作为参考哈。
有感兴趣的同学可以看看哈。