🏍️🏍️🏍️一.情景模拟
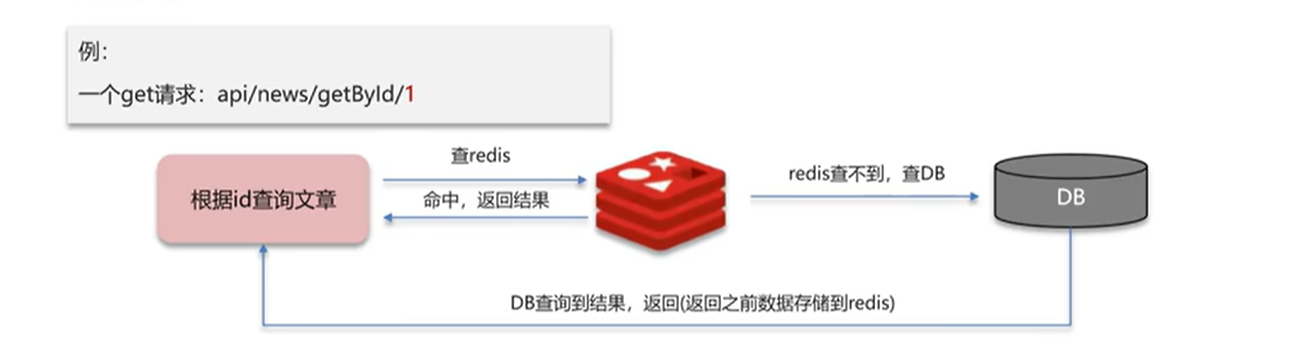
假设现在有一个请求,正常的处理应该是根据id查询redis,如果命中返回结果,如果redis查不到,就去查数据库,数据库查询到结果返回,在返回之前先把数据存储到redis。
🏍️🏍️🏍️二.什么叫缓存穿透?
缓存穿透是指查询一个一定不存在的数据,如果从存储层查不到数据则不写入缓存,这将导政这个不存在的数据每次请求都要到 DB去查询。可能导致DB挂掉。这种情况大概率是遭到了攻击。
🏍️🏍️🏍️三.解决方案
㊙️㊙️㊙️方案一 :缓存空数据,查询返回的数据为空,仍把空结果写进缓存
优点 :操作简单
缺点:(1)如果大量id都是null缓存压力就会很大(2)数据不一致问题。比如id为1的数据一开始确实没有缓存为null,但是后面添加上了,但是缓存中还是null,就导致了缓存和数据库数据不一致的问题
㊙️㊙️㊙️方案二 :使用布隆过滤器
优点 :内存占用少,没有多余的key
缺点:实现复杂,存在一定的误判
🏍️🏍️🏍️四.布隆过滤器原理解释

流程:请求首先经过布隆过滤器,如果过滤器中存在,查询redis,如果不存在直接拦截,缓存预热时需要预热布隆过滤器,热点数据可以先批量添加到缓存中,请求也会优先读取缓存,添加数据到缓存的同时也要添加到布隆过滤器中
原理:要是用于检索一个元素是否在一个集合中
㊙️㊙️㊙️存储原理:
它的底层主要是先去初化一个比较大数组。里面存放的二进制0或1.一开始全是0。当一个key来了之后经过3次(也可以多次)hash计算,模于数组长度找到数据的下标然后把数组中原来的0改为1.这样的话,三个数组的位置就能标明一个key的存在
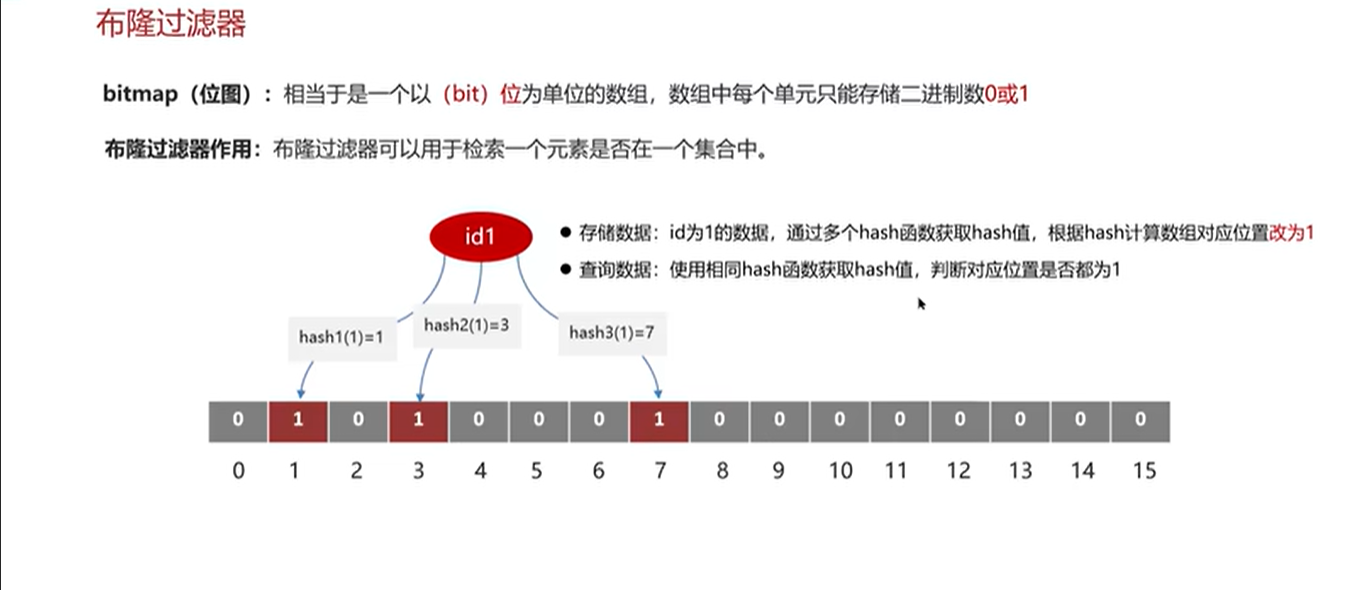
㊙️㊙️㊙️查询原理:
也是经过3次(也可以多次)哈希函数计算,如果对应位置都为1,证明key存在,但是由于哈希函数存在哈希冲突问题,会导致误判,如下图所示,id为3的数据不存在但是根据计算发现查询的位置和id为1和2的数据重合,这就是误判的情况
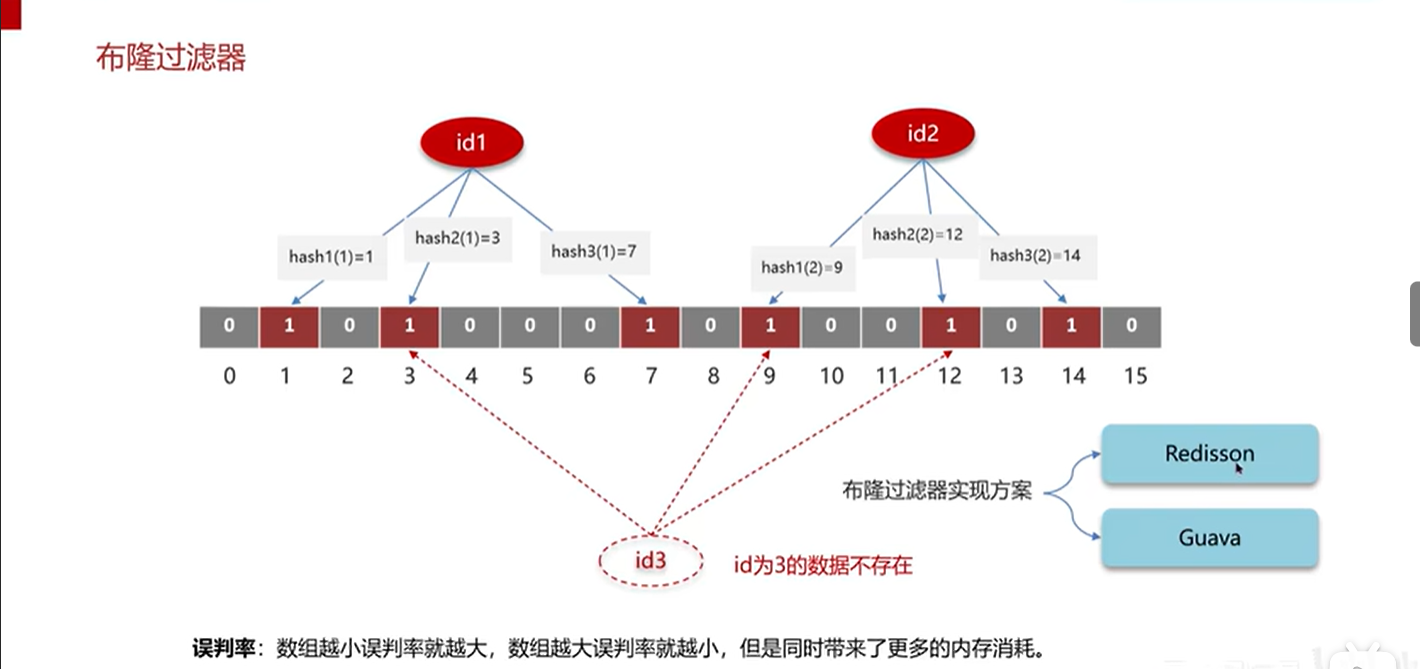
🏍️🏍️🏍️五.关于布隆过滤器的误判
我们一般可以设置这个误判率。大概不会超过5%,其实这个误判是必然存在的,要不就得增加数组的长度,消耗内存,其实已经算是很划算了。5%以内的误判率一般的项目也能接受,不至于高并发下压倒数据库