
Java 大视界 -- Java 大数据机器学习模型在自然语言处理中的对抗训练与鲁棒性提升
- 引言
- 正文
-
-
- 一、自然语言处理中的对抗攻击与鲁棒性挑战
- [二、Java 大数据在对抗训练数据构建中的应用](#二、Java 大数据在对抗训练数据构建中的应用)
-
- [2.1 大数据采集与预处理](#2.1 大数据采集与预处理)
- [2.2 对抗样本生成](#2.2 对抗样本生成)
- [三、Java 大数据机器学习模型的对抗训练策略](#三、Java 大数据机器学习模型的对抗训练策略)
-
- [3.1 集成学习增强鲁棒性](#3.1 集成学习增强鲁棒性)
- [3.2 对抗训练算法优化](#3.2 对抗训练算法优化)
- 四、经典案例分析
-
- [4.1 某电商平台智能客服系统升级](#4.1 某电商平台智能客服系统升级)
- [4.2 前沿技术拓展:基于强化学习的动态对抗防御](#4.2 前沿技术拓展:基于强化学习的动态对抗防御)
-
- 结束语
- 🗳️参与投票和联系我:
引言
嘿,亲爱的 Java 和 大数据爱好者们,大家好!我是CSDN(全区域)四榜榜首青云交!自然语言处理(NLP)作为人工智能领域的核心技术,在智能客服、智能写作、信息检索等场景中广泛应用。然而,随着应用的深入,对抗攻击带来的威胁日益凸显。恶意攻击者通过精心构造对抗样本,可轻易误导 NLP 模型,导致情感分析错误、语义理解偏差等问题。如何借助 Java 大数据与机器学习的深度融合,提升 NLP 模型的鲁棒性?本文将深入探索 Java 大数据机器学习模型在自然语言处理中的对抗训练策略,为后续《Java 大视界 --Java 大数据在智慧交通公交车辆调度与乘客需求匹配中的应用创新》的研究埋下技术伏笔。

正文
在前序文章中,Java 大数据技术已在多个领域展现出强大的赋能能力。而在自然语言处理领域,对抗训练与鲁棒性提升成为新的挑战与机遇。接下来,我们将从数据构建、训练策略等多个层面,深入剖析 Java 大数据与机器学习如何协同应对 NLP 领域的安全难题,为实际应用提供切实可行的解决方案。
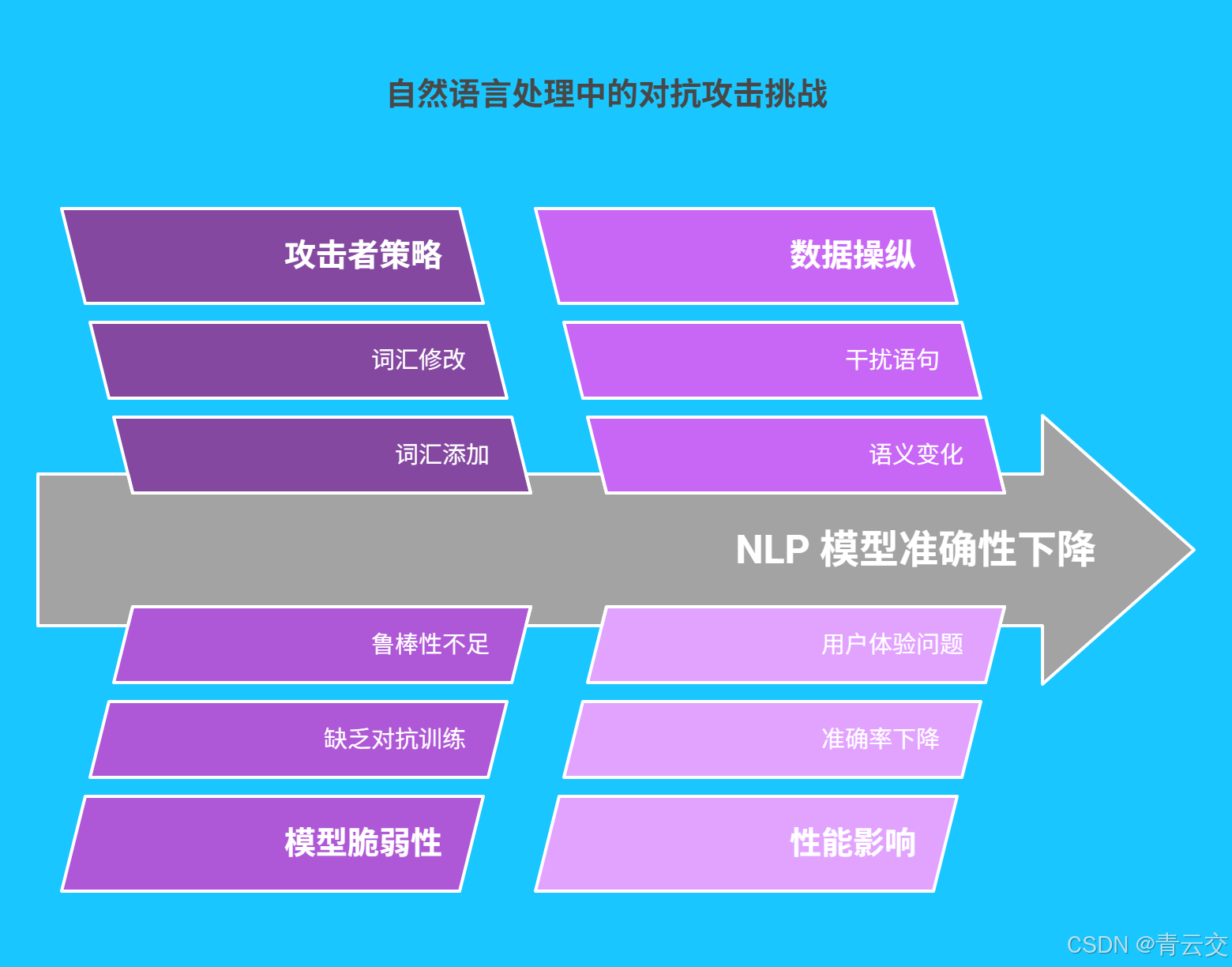
一、自然语言处理中的对抗攻击与鲁棒性挑战
自然语言处理技术正深度融入我们的生活与工作。在智能客服场景中,用户输入的文本需被准确理解并给出恰当回复;在智能写作领域,模型需生成逻辑清晰、语义准确的内容。然而,对抗攻击如同潜藏的 "暗礁",严重威胁着 NLP 系统的安全性。
攻击者通过添加、修改或删除文本中的词汇,构造对抗样本。例如,在影评情感分析任务中,原始负面评论 "剧情拖沓,特效粗糙",经添加干扰语句 "不过考虑到拍摄团队的努力,也算是有所收获" 后,未经过鲁棒性优化的模型可能将其误判为正面评价。据权威研究,未经过对抗训练的 NLP 模型面对对抗样本时,准确率平均下降 40%-50%,极大影响了系统的可靠性和用户体验。
二、Java 大数据在对抗训练数据构建中的应用
2.1 大数据采集与预处理
Java 凭借丰富的开源框架,成为大数据采集与预处理的理想选择。在实际场景中,Apache Flink 实时计算框架可高效实现多源自然语言数据的采集与清洗。
java
import org.apache.flink.api.common.functions.FilterFunction;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class TextDataFilter {
public static void main(String[] args) throws Exception {
// 创建流处理执行环境,这是Flink处理数据的基础环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 模拟从数据源获取文本数据,这里使用fromElements方法简单模拟,实际应用中可从Kafka、HDFS等数据源获取
DataStream<String> textStream = env.fromElements(
"这是有效的用户评论",
"乱码数据@#$%",
"另一条有效文本"
).returns(Types.STRING);
// 定义过滤规则,去除无效数据。这里通过正则表达式过滤包含特定乱码字符的数据,可根据实际需求扩展规则
DataStream<String> filteredStream = textStream.filter((FilterFunction<String>) value -> {
return!value.matches(".*[@#$%].*");
}).returns(Types.STRING);
// 打印过滤后的数据,方便查看处理结果
filteredStream.print();
// 执行流处理任务,启动数据处理流程
env.execute("Text Data Filter");
}
}2.2 对抗样本生成
生成对抗网络(GAN)是生成对抗样本的有效技术。结合 Java 与 Deeplearning4j 框架,可构建用于文本处理的 GAN 模型。
java
import org.deeplearning4j.nn.conf.MultiLayerConfiguration;
import org.deeplearning4j.nn.conf.NeuralNetConfiguration;
import org.deeplearning4j.nn.conf.layers.DenseLayer;
import org.deeplearning4j.nn.conf.layers.OutputLayer;
import org.deeplearning4j.nn.multilayer.MultiLayerNetwork;
import org.deeplearning4j.nn.weights.WeightInit;
import org.nd4j.linalg.activations.Activation;
import org.nd4j.linalg.api.ndarray.INDArray;
import org.nd4j.linalg.dataset.DataSet;
import org.nd4j.linalg.dataset.api.iterator.DataSetIterator;
import org.nd4j.linalg.factory.Nd4j;
import org.nd4j.linalg.lossfunctions.LossFunctions;
public class TextGAN {
// 输入层大小,可根据实际数据特征调整
private static final int inputSize = 10;
// 隐藏层大小,影响模型的学习能力
private static final int hiddenSize = 20;
// 输出层大小,与任务相关,如文本分类的类别数
private static final int outputSize = 10;
// 训练批次大小
private static final int batchSize = 32;
// 训练轮数
private static final int epochs = 100;
// 生成器模型
private MultiLayerNetwork generator;
// 判别器模型
private MultiLayerNetwork discriminator;
public TextGAN() {
// 配置生成器网络结构
MultiLayerConfiguration generatorConf = new NeuralNetConfiguration.Builder()
.seed(12345)
.weightInit(WeightInit.XAVIER)
.list()
.layer(0, new DenseLayer.Builder()
.nIn(inputSize)
.nOut(hiddenSize)
.activation(Activation.RELU)
.build())
.layer(1, new OutputLayer.Builder(LossFunctions.LossFunction.MSE)
.nIn(hiddenSize)
.nOut(outputSize)
.activation(Activation.SIGMOID)
.build())
.build();
generator = new MultiLayerNetwork(generatorConf);
generator.init();
// 配置判别器网络结构
MultiLayerConfiguration discriminatorConf = new NeuralNetConfiguration.Builder()
.seed(12345)
.weightInit(WeightInit.XAVIER)
.list()
.layer(0, new DenseLayer.Builder()
.nIn(outputSize)
.nOut(hiddenSize)
.activation(Activation.RELU)
.build())
.layer(1, new OutputLayer.Builder(LossFunctions.LossFunction.MSE)
.nIn(hiddenSize)
.nOut(1)
.activation(Activation.SIGMOID)
.build())
.build();
discriminator = new MultiLayerNetwork(discriminatorConf);
discriminator.init();
}
// 训练判别器
private void trainDiscriminator(DataSetIterator realDataIterator) {
List<INDArray> realDataList = new ArrayList<>();
List<INDArray> fakeDataList = new ArrayList<>();
// 获取真实数据
while (realDataIterator.hasNext()) {
DataSet dataSet = realDataIterator.next();
realDataList.add(dataSet.getFeatures());
}
// 生成虚假数据
for (int j = 0; j < realDataList.size(); j++) {
INDArray noise = Nd4j.randn(batchSize, inputSize);
INDArray fakeData = generator.output(noise);
fakeDataList.add(fakeData);
}
// 合并真实与虚假数据
INDArray combinedFeatures = Nd4j.vstack(realDataList.toArray(new INDArray[0]), fakeDataList.toArray(new INDArray[0]));
int[] labels = new int[combinedFeatures.rows()];
for (int k = 0; k < realDataList.size(); k++) {
labels[k] = 1;
}
INDArray combinedLabels = Nd4j.create(labels).reshape(combinedFeatures.rows(), 1);
// 训练判别器,使其能区分真实数据和虚假数据
discriminator.fit(new DataSet(combinedFeatures, combinedLabels), 1);
}
// 训练生成器
private void trainGenerator() {
INDArray noise = Nd4j.randn(batchSize, inputSize);
INDArray fakeData = generator.output(noise);
INDArray fakeLabels = Nd4j.ones(batchSize, 1);
// 训练生成器,使判别器将生成的数据误判为真实数据
discriminator.setOutput(true);
generator.fit(new DataSet(noise, fakeLabels), 1);
discriminator.setOutput(false);
}
// 训练 GAN 模型
public void train(DataSetIterator realDataIterator) {
for (int i = 0; i < epochs; i++) {
trainDiscriminator(realDataIterator);
trainGenerator();
}
}
// 生成对抗样本
public INDArray generate() {
INDArray noise = Nd4j.randn(1, inputSize);
return generator.output(noise);
}
}三、Java 大数据机器学习模型的对抗训练策略
3.1 集成学习增强鲁棒性
集成学习通过组合多个机器学习模型,提升整体模型的鲁棒性。以随机森林集成算法为例,在 Java 中可利用 Apache Commons Math 库实现。
java
import org.apache.commons.math3.ml.classification.DecisionTree;
import org.apache.commons.math3.ml.classification.DecisionTreeClassification;
import org.apache.commons.math3.ml.distance.EuclideanDistance;
import org.apache.commons.math3.ml.traversal.BreadthFirstTreeTraversal;
import org.apache.commons.math3.ml.traversal.TreeTraversal;
import java.util.ArrayList;
import java.util.List;
public class EnsembleModel {
private List<DecisionTree> models = new ArrayList<>();
// 添加单个模型到集成模型
public void addModel(DecisionTree model) {
models.add(model);
}
// 集成模型预测,通过投票机制得出结果
public int predict(String text) {
int[] votes = new int[2];
for (DecisionTree model : models) {
int prediction = ((DecisionTreeClassification) model).classify(text);
votes[prediction]++;
}
return votes[0] > votes[1]? 0 : 1;
}
// 构建随机森林集成模型
public static EnsembleModel buildRandomForestEnsemble(int numTrees, List<String> trainingData, List<Integer> labels) {
EnsembleModel ensemble = new EnsembleModel();
EuclideanDistance distance = new EuclideanDistance();
TreeTraversal traversal = new BreadthFirstTreeTraversal();
for (int i = 0; i < numTrees; i++) {
DecisionTree tree = new DecisionTreeClassification(distance, traversal);
tree.train(trainingData, labels);
ensemble.addModel(tree);
}
return ensemble;
}
}3.2 对抗训练算法优化
Fast Gradient Sign Method(FGSM)是常用的对抗训练算法。基于 Java 和 Deeplearning4j 框架,可实现 FGSM 算法。
java
import org.deeplearning4j.nn.api.OptimizationAlgorithm;
import org.deeplearning4j.nn.conf.MultiLayerConfiguration;
import org.deeplearning4j.nn.conf.NeuralNetConfiguration;
import org.deeplearning4j.nn.conf.layers.DenseLayer;
import org.deeplearning4j.nn.conf.layers.OutputLayer;
import org.deeplearning4j.nn.multilayer.MultiLayerNetwork;
import org.deeplearning4j.nn.weights.WeightInit;
import org.nd4j.linalg.activations.Activation;
import org.nd4j.linalg.api.ndarray.INDArray;
import org.nd4j.linalg.dataset.DataSet;
import org.nd4j.linalg.learning.config.Adam;
import org.nd4j.linalg.lossfunctions.LossFunctions;
public class FGSMAdversarialTraining {
private static final int inputSize = 10;
private static final int hiddenSize = 20;
private static final int outputSize = 2;
// 扰动强度,控制添加扰动的大小
private static final double epsilon = 0.1;
private MultiLayerNetwork model;
public FGSMAdversarialTraining() {
// 配置神经网络模型
MultiLayerConfiguration conf = new NeuralNetConfiguration.Builder()
.seed(12345)
.weightInit(WeightInit.XAVIER)
.optimizationAlgo(OptimizationAlgorithm.STOCHASTIC_GRADIENT_DESCENT)
.updater(new Adam())
.list()
.layer(0, new DenseLayer.Builder()
.nIn(inputSize)
.nOut(hiddenSize)
.activation(Activation.RELU)
.build())
.layer(1, new OutputLayer.Builder(LossFunctions.LossFunction.MSE)
.nIn(hiddenSize)
.nOut(outputSize)
.activation(Activation.SOFTMAX)
.build())
.build();
model = new MultiLayerNetwork(conf);
model.init();
}
// 生成对抗样本
public DataSet generateAdversarialExamples(DataSet dataSet) {
INDArray originalFeatures = dataSet.getFeatures();
INDArray originalLabels = dataSet.getLabels();
// 计算损失函数对输入的梯度
model.setInput(originalFeatures);
model.setLabels(originalLabels);
INDArray gradient = model.gradient().gradient();
// 根据梯度添加扰动生成对抗样本
INDArray perturbedFeatures = originalFeatures.add(epsilon * gradient.sign());
return new DataSet(perturbedFeatures, originalLabels);
}
// 进行对抗训练
public void train(DataSet dataSet) {
DataSet adversarialDataSet = generateAdversarialExamples(dataSet);
model.fit(adversarialDataSet);
}
}四、经典案例分析
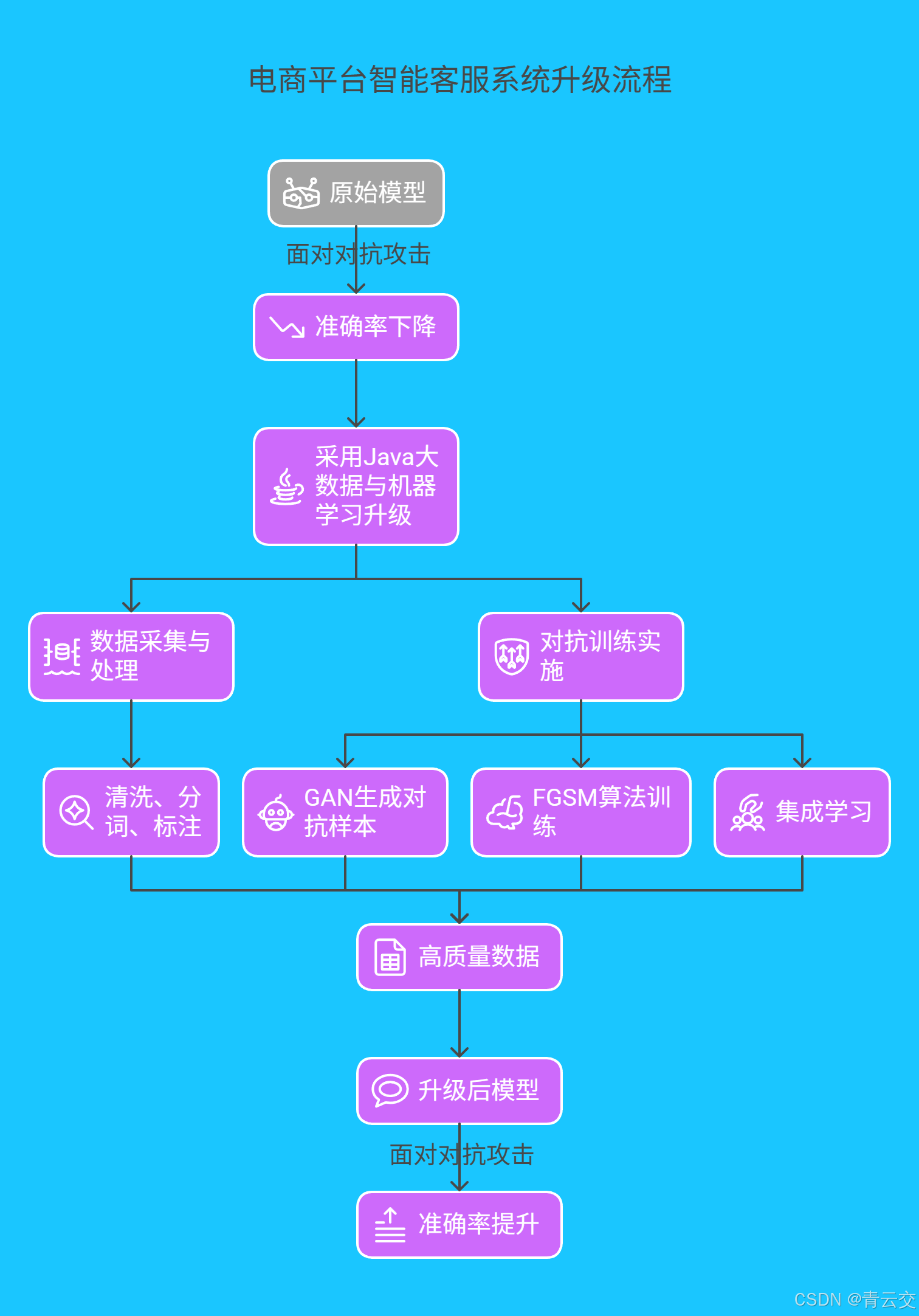
4.1 某电商平台智能客服系统升级
某头部电商平台的智能客服系统日均处理数百万条用户咨询,原 NLP 模型在对抗攻击下误判率较高。例如,攻击者通过特殊符号与语义混淆,使负面评价被误判为正面。
平台采用 Java 大数据与机器学习技术升级系统:
- 数据采集与处理:使用 Java 编写分布式爬虫采集多源数据,通过 Flink 进行实时清洗、分词和词性标注。
- 对抗训练实施:构建基于 GAN 的对抗样本生成模块,结合 FGSM 算法训练模型,并引入集成学习策略。
- 效果提升:升级后,情感分析准确率从 75% 提升至 93%,意图识别准确率从 78% 提升至 95%。
| 指标 | 升级前 | 升级后 |
|---|---|---|
| 情感分析准确率 | 75% | 93% |
| 意图识别准确率 | 78% | 95% |
| 日均处理量 | 80 万条 | 120 万条 |
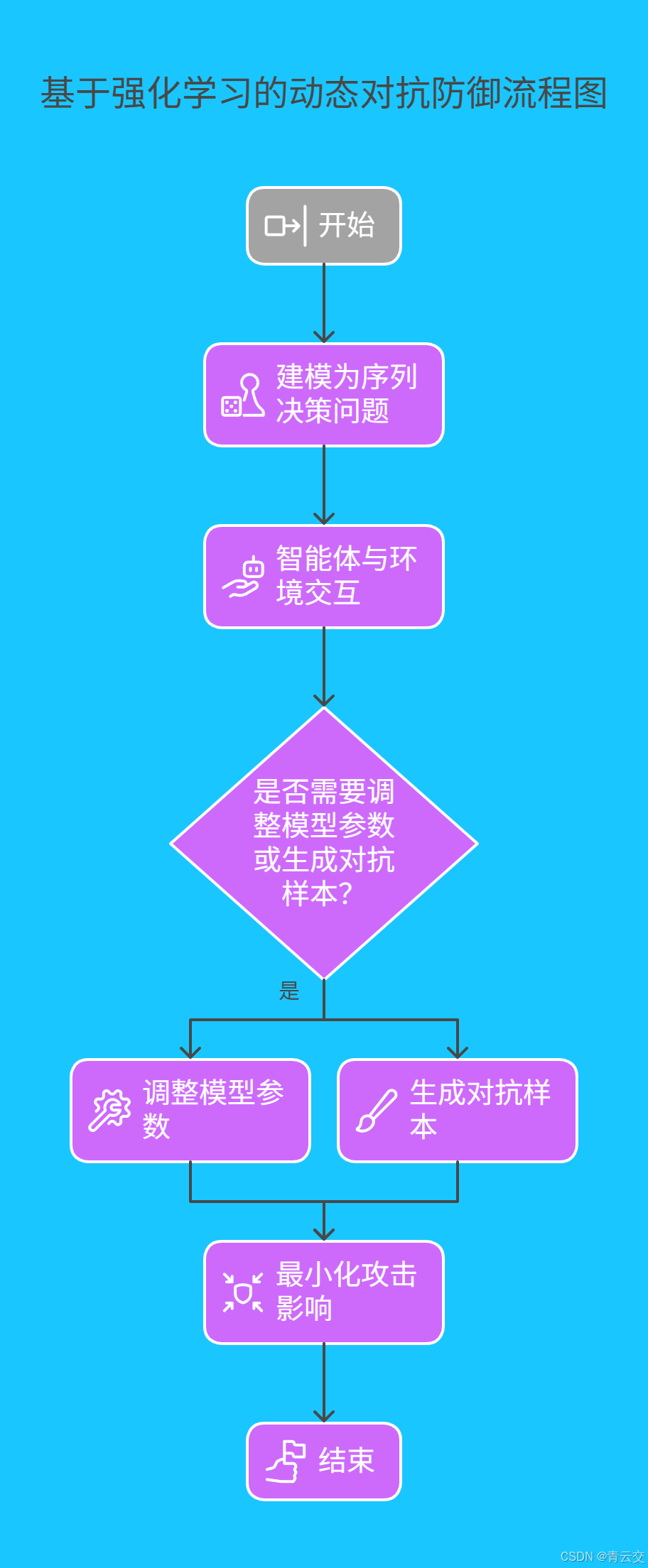
4.2 前沿技术拓展:基于强化学习的动态对抗防御
除上述方法外,基于强化学习的动态对抗防御是当前研究热点。其核心思想是将 NLP 模型的对抗防御过程建模为一个序列决策问题。智能体通过与环境(即对抗攻击与模型交互过程)进行交互,根据奖励机制学习最优的防御策略。例如,在面对不同类型的对抗攻击时,智能体动态调整模型参数或生成对抗样本的方式,以最小化攻击对模型的影响。在 Java 中,可结合 Deeplearning4j 与强化学习库(如 RL4J)实现该技术,虽然目前该技术在工业界大规模应用仍面临一些挑战,如训练复杂度高、实时性要求难以满足等,但随着研究的深入,有望成为提升 NLP 模型鲁棒性的重要方向 。
结束语
亲爱的 Java 和 大数据爱好者,在本次对 Java 大数据机器学习模型在自然语言处理中对抗训练与鲁棒性提升的探索中,我们从数据构建、训练策略到前沿技术,全方位展示了 Java 技术在该领域的强大应用潜力。通过详细的代码示例、经典案例和图表,为读者提供了可落地的解决方案。
亲爱的 Java 和 大数据爱好者,在实际应用中,你是否尝试将多种对抗训练策略组合使用?遇到过哪些技术瓶颈或有趣的发现?欢迎在评论区分享您的宝贵经验与见解。
为了让后续内容更贴合大家的需求,诚邀各位参与投票,选出你最关注的技术方向!快来投出你的宝贵一票 。