编者按: 现代大语言模型已经能够一次性处理相当于整本书的文本量,但我们是否曾想过,当模型的"记忆"容量再扩展成千上万倍,足以容纳长达数月乃至数年的交互信息时,人工智能的能力边界将会发生怎样颠覆性的变化?
我们今天为大家带来的文章,作者的核心观点是:超长上下文推理的真正潜力,并不仅仅是处理海量文档,更在于它为实现人工智能的"持续学习"和规模化"强化学习"这两大关键瓶颈提供了革命性的突破路径。
文章指出,超长上下文窗口能让 AI 系统在部署后,通过"记忆"和"反思"过往的交互案例来不断学习和纠错,这是解决当前 AI 系统无法从经验中成长这一核心障碍的关键。作者认为,强大的长上下文推理不仅能支持模型处理时间跨度更长的复杂任务(例如需要数月才能验证的科研方向),还能通过验证复杂的推理链条为模型提供高质量的训练信号,甚至可以用来生成更逼真的强化学习训练环境。
作者 | JS Denain and Anson Ho
编译 | 岳扬
从理论上讲,现代大语言模型能够一次性处理相当于多本书籍的文本量。以 Gemini 2.5 Pro 为例,其上下文窗口达到 100 万 token,足以容纳十本《哈利·波特与魔法石》的内容¹。但若能对更长的上下文进行大量推理呢?如果大模型可以接收 100 亿 token 的上下文,并且我们具备使之可以实现的硬件与算法,又将如何?
最直接的应用场景自然是处理超长文档1。但我们认为长上下文推理的意义远不止于此:
- 其一,它为模型部署后持续学习新知识提供了突破口 ------ 而这也是当前人工智能系统在实际应用中的最大瓶颈之一。
- 其二,它能极大推动强化学习的扩展:实现更复杂的推理、验证模型输出,并生成高质量的强化学习环境。
- 但瓶颈依然存在。 随着强化学习任务时长增加,研究迭代周期会放缓。同时还需要硬件与算法的双重突破,确保长上下文推理不会因速度或成本问题而难以落地。
值得注意的是,上下文长度正以每年 30 倍的速度增长2,前沿大模型利用上下文的能力也在快速提升。即便这种趋势稍有放缓,这些重大突破也极有可能在不久的将来成为现实。
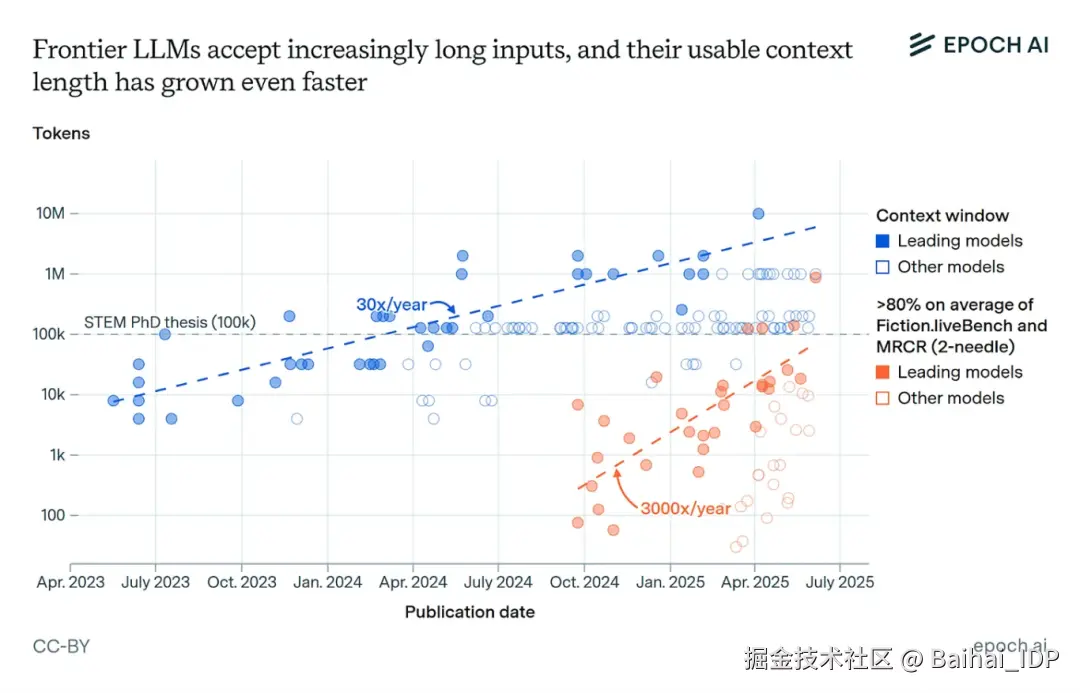
01 超长上下文推理为持续学习提供了突破口
要使大语言模型真正具备经济价值3,它们很可能需要"持续学习"的能力,即在模型部署后仍能不断吸收新知识²。这种能力对于帮助 AI 系统从犯过的错误中学习或培养研究直觉4非常重要。但当前的大模型缺乏能在长对话或多轮交互中保留的"记忆"。
部分问题在于,当前大模型的上下文窗口不够长,难以支撑有效的持续学习。 举例来说,若通过截图记录工作历程,100 万 token 的上下文仅能支持 AI Agent 执行半小时的电脑任务 ------ 远不足以获取大量隐性知识³。但更长的上下文能带来质变:1000 万 token 可覆盖约 6 小时的电脑使用记录,而 100 亿 token 便能延伸至八个月!更乐观地看,若仅凭文本和音频 token 就能表征工作经验,约 4000 万 token 或许已足以积累数月的"工作经验"⁴。
一旦拥有超长上下文,模型便能直接从上下文窗口中的过往案例学习。例如,推理模型已展现出在思维链中自我纠错5-6的能力,将这些习得的修正方案保留在上下文中,将有助于模型未来解决类似问题。
这种"超大上下文窗口+上下文学习"的持续学习路径已被探讨多次。比如 Aman Sanger 在与 Cursor 团队交流时曾提及这一方向7,Andrej Karpathy 也在 X 平台上勾勒过其实现框架8:

(译者注:这个框架的核心逻辑大概是,模型在完成任务时,先试几次 ---> 记录每次的结果和评估分数 ---> 用一个"反思提示词"让模型自己总结经验 ---> 把经验写成"lesson" ---> 存起来,下次遇到类似任务时用上 ---> 不断迭代优化。)
不过,有人可能会质疑这种方法9,理由是隐性知识很难存储在基于先前上下文的文本摘要中 ------ 这会导致关于任务执行过程的丰富信息大量丢失。这种担忧确有道理,但未必能否定该路径的可行性。
首先,如果上下文窗口比现有模型大几个数量级,我们就有可能对上下文进行深度优化。这有望克服经验压缩中的信息损耗问题。例如,假设有一个大语言模型能够存储相当于数月工作内容的上下文,我们可以结合"sleep-time compute"10机制:让模型利用(可预设的)空闲时间,将新获取的信息与既有知识建立关联进行学习。通过大量推理计算和强化学习优化后,所产生的学习上下文可能极为高效。当前模型通过强化学习已显著提升了对上下文的利用效率,而正如下一节将探讨的,这方面仍有巨大提升空间。
如果问题在于以文本形式存储信息,长上下文还可以与业界积极研究的其他方案结合。例如,token 可作为多种模态信息11的通用表征载体;又或者,隐性知识可以存储在经过学习的 KV 缓存12中,形成比文本摘要更密集的知识表征。
当然,这些技术能否真正奏效,不仅取决于纸上谈兵地扩大上下文窗口尺寸,还需要建设配套基础设施,确保相关上下文(例如近期所有工作交互记录)都能被数字化并输入大语言模型13。
我们同样需要关注长上下文在实际应用中的效果 ------ 即便模型理论支持 100 万 token 的上下文窗口,但在远未达到该长度时,其输出就可能已经开始混乱。 以 Vending Bench 基准测试14为例:模型需要运营自动售货机赚取利润,但往往在理论上下文窗口远未填满时就出现"失控",产生巨额亏损。在实际使用大语言模型时我们也能观察到类似现象:模型在长对话中会对先前的错误过度关注,导致用户不得不开启新对话重新开始。
02 能够执行大量长上下文推理有助于强化学习的规模化扩展
要确保模型在长上下文窗口中保持逻辑连贯,一种方法是延续当前强化学习与测试时计算扩展的技术路线。例如,采用一定程度的端到端强化学习训练 ------ 这种方法已为 OpenAI 的 Deep Research 系统15等产品提供了助力。它能提供训练信号,帮助模型在回应用户的长查询时保持前后一致性。
强大的长上下文推理能力正是强化学习持续扩展的重要支撑。原因之一在于它支持更长的决策轨迹16:更大的上下文窗口允许模型对耗时任务17输出更长的推理链条。
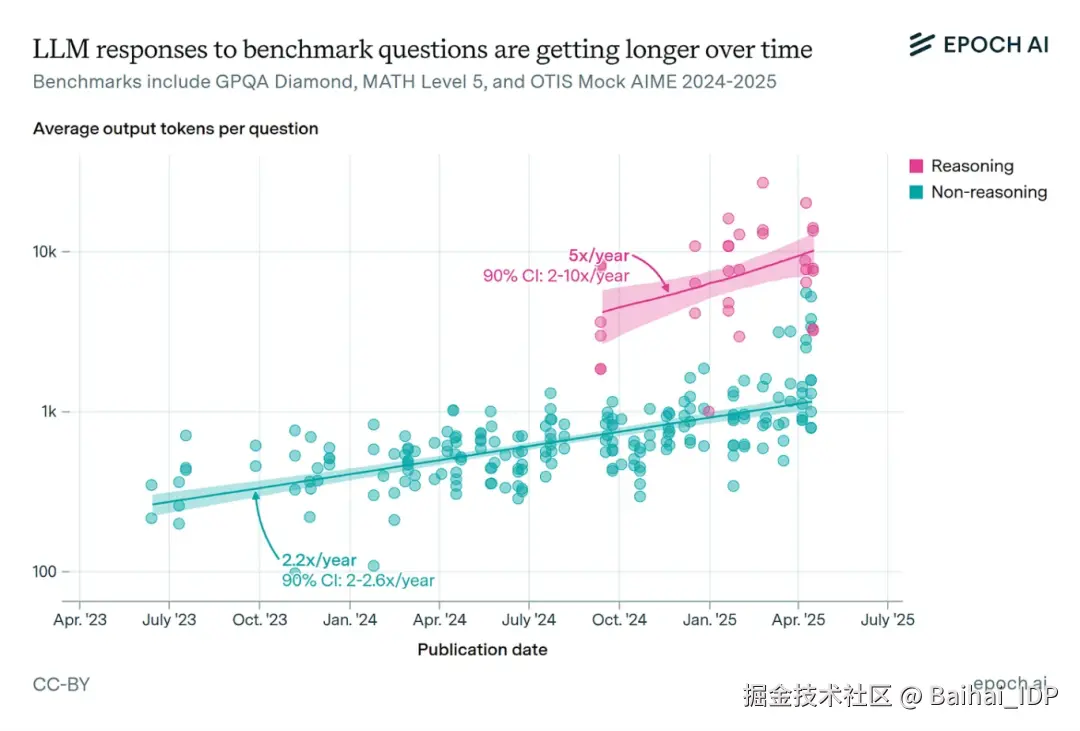
各基准测试中模型的回答正变得越来越长,尤其是通常经过强化学习训练18的推理模型。这进一步加大了对长上下文推理的需求。
随着大模型应用于更复杂的长周期任务,它们可能越来越多地面临"稀疏奖励"问题 ------ 即模型很难获得明确的行为反馈信号。 例如在 AI 研发中选择研究方向时,可能需要数月时间提出假设、设计和实施实验,才能最终判断出研究策略的优劣。对于此类任务,不仅单次决策轨迹长,更需要大量重复尝试19 ------ 这能增加至少出现一次成功轨迹的概率,为模型提供学习范本⁵。
长上下文推理还能通过验证长模型输出所需的复杂思维链,为推理模型提供高质量奖励信号⁶。高质量验证机制对 AI 的发展一直至关重要,OpenAI 用于改进 GPT-5 的"Universal Verifier20"就是明证。
此外,长上下文推理有助于生成强化学习环境(或其中的组成部分)。如 Kimi K2 的训练21就融合了 MCP22 服务器,利用大模型自动生成大量模拟的"工具"、"智能体"、"任务"和"对话记录"来为后训练阶段创建高质量的数据⁷。这个过程催生了长上下文推理的新需求场景,未来很可能扩展到强化学习任务的创建。当前这类环境大多通过程序化生成,但我们预期其质量将持续提升23。而要构建更高质量的强化学习环境,有效运用长思维链或智能体交互变得愈发关键,这正是长上下文能力的用武之地。
具体而言,我们认为长上下文推理能在扩展推理模型能力边界方面发挥关键作用,使其胜任持续数周甚至数月的长周期任务。如果这种强化学习扩展能带来类似去年推理模型的进步幅度,其影响将不可估量。
03 瓶颈:研究迭代速度放缓与潜在成本上升
这些强化学习的扩展和持续学习能力的实现,都需要付出代价。在发展道路上存在着诸多瓶颈和限制。
其中一个瓶颈是根本性的 ------ 当 AI 模型执行单次推理任务的时间被拉长到数周甚至数月时,会直接拖慢整个科研的迭代速度,从而延缓技术创新的进程。 Noam Brown 在 Latent Space 播客24中犀利指出:
"随着模型思考时间的延长,你会受到实际时钟时间(wall-clock time)的制约。当模型能够即时响应时,实验迭代非常轻松。但当它们需要三小时才能回应时,难度就完全不可同日而语了。
...
虽然可以在一定程度上将实验并行处理,但多数情况下,你必须先运行并完成当前实验、看到结果后,才能决定下一组实验的方向。我认为这恰恰是 AI 研发需要长周期的最有力佐证"
另一大瓶颈在于成本。即便在理论上能实现长上下文推理,最终能否投入使用还要看成本是否可承受。 需要硬件与推理算法25的双重突破,否则模型运行速度可能慢到无法接受,成本也会高昂得难以承受。成本问题已现端倪 ------ Google DeepMind 就曾因高昂的成本26主动放弃发布具备 1000 万 token 上下文能力的 Gemini 1.5 Pro。
但总体而言,我们相信赋予语言模型长上下文推理能力将具有重大意义。它不仅能够将现有的推理范式推向新的高度,也能为 AI 系统赋能关键能力,使其在真实场景中发挥实用价值。尽管需要付出一定代价,但这些瓶颈并非不可逾越。结合当前上下文长度的增长趋势与资源投入力度,这些影响可能很快就会显现。
本文诸多观点受 Will Brown 的启发,特此致谢。同时还要感谢 Lynette Bye 在写作方面提供的宝贵建议,以及 Josh You 和 Jaime Sevilla 的反馈意见。
1 《哈利·波特与魔法石》约含 7.5 万个单词27,即约 10 万 token。
2 需注意,某些持续学习的定义28明确包含对新数据的训练(即更新模型参数)。我们采用更宽泛的定义而不限定具体机制,因为我们主要关注模型在上下文环境中持续处理新信息的能力。
3 此计算基于每图像约 250 token29、每秒 2 帧的设定。在 100 万 token 的上下文窗口下,可处理时长约为 1,000,000 / (250 * 2) = 2000 秒(约 30 分钟)。实际场景中可能需要更多 token,尤其在文本密集的计算机操作流中 ------ 但这反而凸显了长上下文推理能力的重要性。
4 例如,假设一人每日阅读 3 万 token 文本(约合三篇论文),其思维速度与语速同步(每分钟 125 词),且每日工作场景中保持 6 小时思考,则对应新增 4.5 万词(6 万 token)。日总量约 10 万 token,年累积量约为 12×30×100,000 ≈ 3500 万 token。实际数值可能更高,因为人类思维速度通常远超语言表达速度。
5 其他方法同样有效。例如在研究过程中设置阶段性奖励30,可加速模型学习。
6 奖励信号未必仅基于最终结果 ------ 基于过程的奖励31同样具有促进作用。
7 相关案例包括阿里通义实验室的 AgentScaler32,其提出了构建智能体任务环境的标准化流程。
END
本期互动内容 🍻
❓要实现"数月工作经验"的上下文,文章指出面临成本和迭代速度两大瓶颈。你认为,在"算力成本下降"和"算法效率突破"之间,哪个是更快破局的关键?
文中链接
1cloud.google.com/transform/t...
3www.dwarkesh.com/p/timelines...
5huggingface.co/blog/Normal...
7www.youtube.com/watch?app=d...
9www.dwarkesh.com/p/timelines...
10www.letta.com/blog/sleep-...
13www.interconnects.ai/p/contra-dw...
15www.youtube.com/watch?v=bNE...
19www.youtube.com/watch?v=sLa...
20www.theinformation.com/articles/un...
22www.anthropic.com/news/model-...
23www.mechanize.work/blog/cheap-...
24www.latent.space/p/noam-brow...
26www.youtube.com/watch?v=NHM...
27jspotter.fandom.com/wiki/James_...
29web.archive.org/web/2025090...
31www.interconnects.ai/p/interview...
本文经原作者授权,由 Baihai IDP 编译。如需转载译文,请联系获取授权。
原文链接: