
训练营简介
2025年昇腾CANN训练营第二季,基于CANN开源开放全场景,推出0基础入门系列、码力全开特辑、开发者案例等专题课程,助力不同阶段开发者快速提升算子开发技能。获得Ascend C算子中级认证,即可领取精美证书,完成社区任务更有机会赢取华为手机,平板、开发板等大奖。
报名链接:https://www.hiascend.com/developer/activities/cann20252
作为一名AI工程师,我们的大部分时间都在与模型、数据和框架打交道。我们思考的是如何设计更巧妙的网络结构,如何优化损失函数,如何让模型在验证集上达到更高的精度。这,就是典型的"算法思维"------一种自顶向下、聚焦于数学逻辑和抽象实现的高层视角。但在我的昇腾AI开发之旅中,我深刻体会到,要真正释放硬件的极致性能,必须完成一次从"算法思维"到"算子思维"的认知跃തിയ。
一、 什么是"算法思维"?------我的舒适区
在项目初期,我像大多数开发者一样,沉浸在PyTorch和TensorFlow等高级框架带来的便利中。比如,要实现一个注意力机制,我的脑海里浮现的是这样的公式:
Attention ( Q , K , V ) = softmax ( Q K T d k ) V \text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V Attention(Q,K,V)=softmax(dk QKT)V
我的代码也几乎是这个公式的直接翻译。我关心的是张量的维度是否正确、逻辑是否通顺。模型能跑通,精度达标,任务就算完成。在这个阶段,底层的硬件对我来说就像一个"黑盒",我把计算任务扔给它,它返回结果,快速而高效。
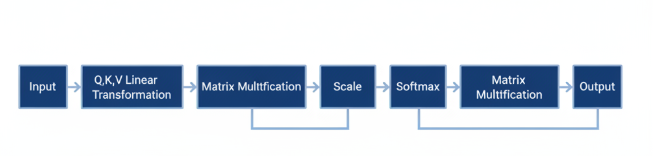
二、 撞上性能墙:从"能跑"到"跑得快"的鸿沟
问题出现在我们将一个复杂的视觉模型部署到昇腾AI硬件上时。尽管模型在GPU上表现良好,但在NPU上的初始性能却未达到预期。推理延迟、内存占用都亮起了红灯。
起初,我尝试了各种"算法思维"下的优化:模型剪枝、量化、调整Batch Size......效果虽有,但始终无法触及性能的上限。这时我意识到,我与硬件之间隔着一层厚厚的"框架之墙"。我设计的算法,并没有真正"理解"昇腾NPU的架构特性。例如,NPU拥有强大的Cube-Unit(矩阵计算单元)和Vector-Unit(向量计算单元),但我的通用框架API调用,是否最高效地利用了它们?数据在内存和缓存之间的流转是否流畅?这些问题,"算法思维"无法回答。
三、 迈入新世界:"算子思维"的启示
为了突破瓶颈,我开始深入学习昇腾的CANN(异构计算架构)。这时,一个全新的世界向我敞开------"算子思维"。
"算子思维"是一种自底向上、庖丁解牛式的视角。它不再将一个算法模块视为一个整体,而是将其拆解为一系列最基础的计算单元------算子(Operator)。
再次审视注意力机制,用"算子思维"来看,它不再是一个整体,而是一个由MatMul(矩阵乘法)、Add(或Mul,用于Scale)、Softmax、MatMul等基础算子构成的有向无环图(DAG)。
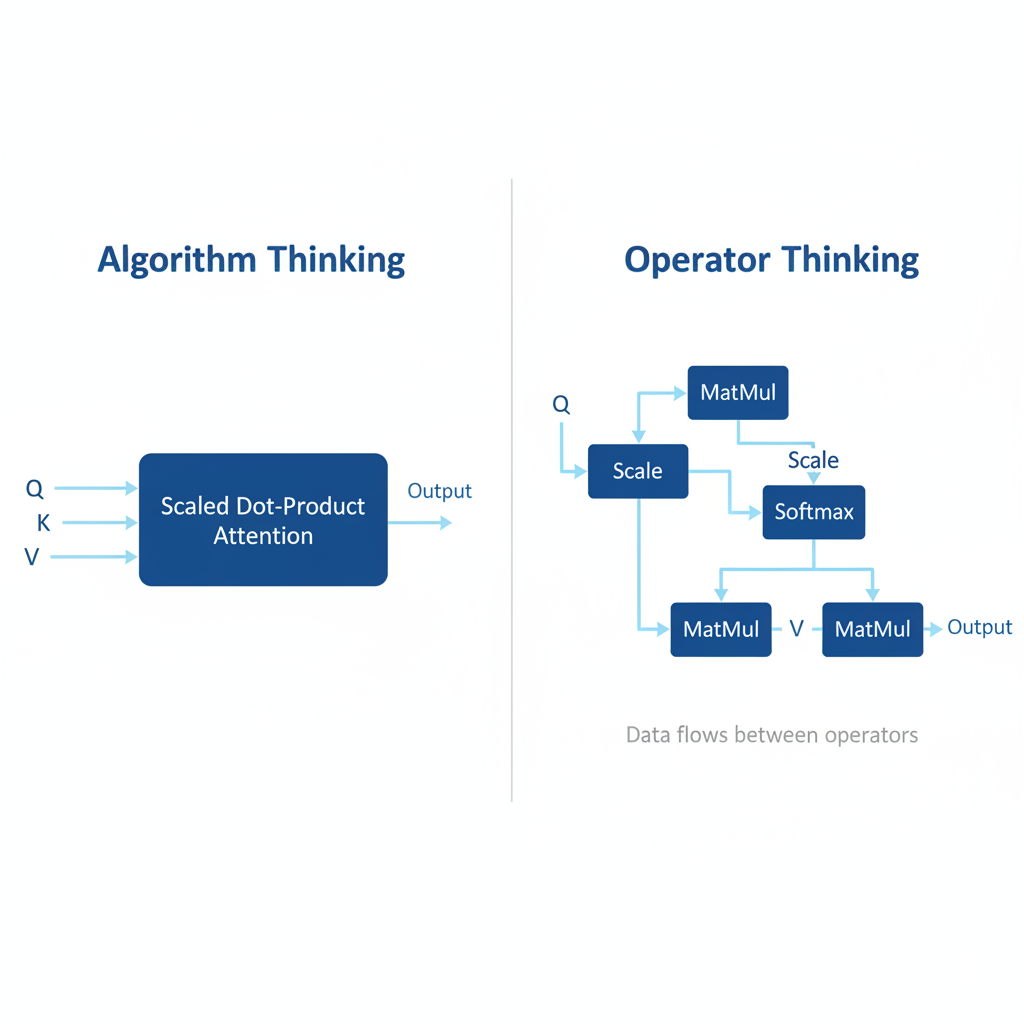
这种思维的转变带来了质的飞跃:
- 性能分析更精准: 我可以利用昇腾的Profiling工具,精确定位到是哪个算子成为了性能瓶颈。是
MatMul的计算效率不高?还是Softmax中存在不必要的数据搬运? - 优化手段更直接: 针对瓶颈算子,我可以进行针对性优化。比如,通过算子融合(Fusion),将
Scale -> Softmax这两个操作合并成一个自定义算子,减少了数据读写和函数调用的开销,极大地提升了效率。 - 硬件亲和性更强: 在开发自定义算子时,我会直接思考如何让数据排布更适合NPU的计算单元,如何设计计算逻辑以最大化并行度。我不再是"命令"硬件做什么,而是"引导"硬件以它最擅长的方式去完成任务。
四、 我的认知跃迁:在昇腾CANN中的实践
在CANN中,我学习使用TIK(Tensor Iterator Kernel)进行自定义算子开发。这就像是给了我一把可以直接操作硬件底层计算单元的"钥匙"。
我印象最深的一次实践,是优化一个包含Transpose和MatMul的组合。在"算法思维"中,这是两个独立的操作。但在"算子思维"下,我意识到Transpose本身只是数据在内存中的重新排列,如果能在MatMul算子内部,通过精巧的内存搬运直接读取转置后的数据,就可以完全消除Transpose这个算子的开销。
通过编写TIK算子,我成功实现了这个"in-place"的转置矩阵乘法,最终让这部分计算的性能提升了近40%。那一刻,我真切地感受到了"认知跃迁"带来的喜悦------从一个框架的使用者,变成了一个性能的掌控者。
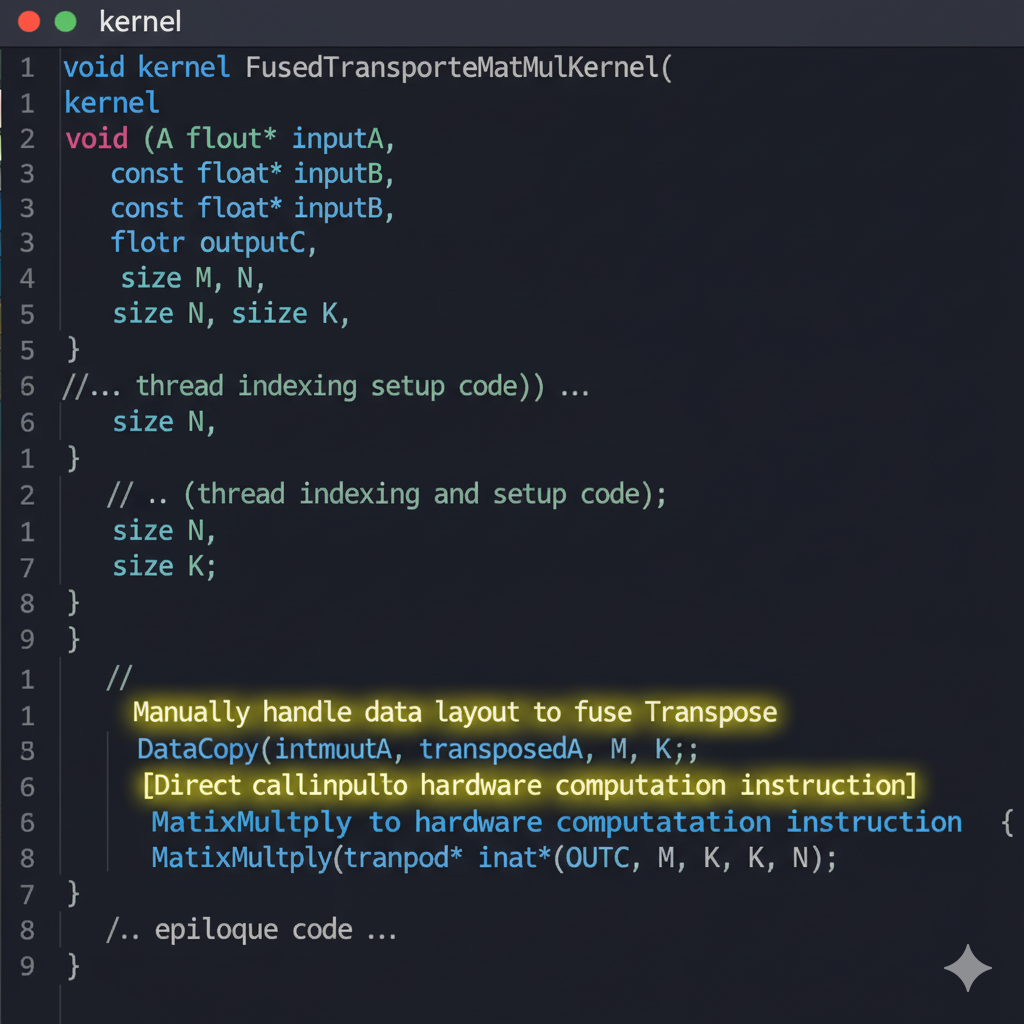
cpp
// MyTransposeMatMul.cpp
class MyKernel {
public:
void Init() {
// 1. 定义输入输出Tensor (A, B, C)
// ...
}
void Process() {
// 2. 核心计算逻辑
// 将输入B的数据以转置的方式搬运到NPU片上内存
DataCopy(B_local, B_global, /* a transpose pattern */);
// 3. 调用Cube-Unit执行矩阵乘法
MatrixMultiply(C_local, A_local, B_local_transposed);
// 4. 将结果搬运回全局内存
// ...
}
};结论:跨越鸿沟,看见新风景
从"算法思维"到"算子思维"的转变,并非对前者的否定,而是一种进化和升维。算法思维让我们站得高、看得远,快速构建模型的蓝图;而算子思维则让我们钻得深、做得实,将蓝图以最高效的方式变为现实。
对于每一位走在AI工程化道路上的开发者而言,这次跃迁或许是必经之路。当你不再满足于"能跑",而是追求"跑得极致",你会发现,深入底层,与硬件共舞,将为你打开一扇通往极致性能的、崭新的大门。在昇腾AI这个充满机遇的生态中,掌握"算子思维",无疑是我们手中最锋利的武器之一。