理论及实操题的题型分布和分值
理论知识考试采用闭卷机考方式,操作技能考核采用计算机机考方式。理论知识考试和操作技能考核均实行百分制,成绩皆达60分及以上者为合格。
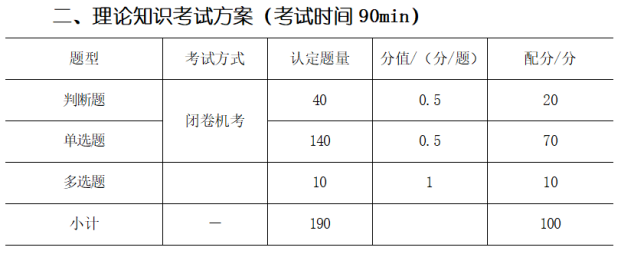
其中理论题的考试方式如下图所示。
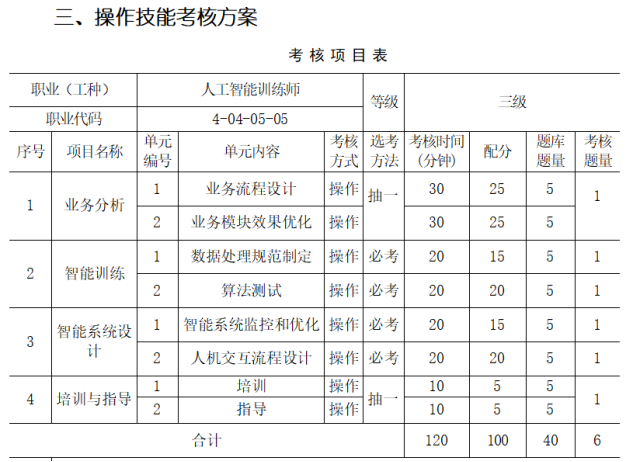
操作技能考试的方式和抽题方式如下图所示。
备考逻辑
由分值分布可知,
客观题需要多刷题库的单选和判断题
实操题需要将重心放在前3个大板块特别是2,3板块占总分值的70%,第4板块总共就5分,时间不足的情况可酌情放弃
实操题可以理解为完形填空,多记多刷,没代码基础也可以过
1.1.1-1.1.5固定搭配
1 打开文件以及之后的基本操作
pd.read_csv('文件名')
注意,pd是pandas的缩写,如果import里没有pd,要写pandas.read_xxxx
打开excel是read_excel
文件名从提干里获取,同时要加引号
看前5条数据是xx.head()
注意带括号,xx是dataframe的对象名
2 指定列名/创建新列
data'RiskLevel'
格式是 dataframe的对象名,方括号,列名
这个用的地方很多
3 创建新列,并填充数据,大致格式
data'RiskLevel' = np.where(data'DaysInHospital'>7,'高风险患者','低风险患者')
注意, np.where是设置数据条件
data'DaysInHospital'>7,'高风险患者','低风险患者'
这三个参数连起来理解,是该列数据大于7天,即住院天数大于7天,设值是'高风险患者',反之是'低风险患者'
4 统计数量,统计总数
data'RiskLevel'.value_counts()
格式是,对象'列名'.value_counts()
这是个固定搭配,一起连起来记忆
5 看到bins要写cut,cut的全部结构
pd.cut(data'Age',bins=xxx,labels=xxx,right=False)
答题时,right=False未必要你们写,就记三个参数
分别是,待操作的列,这可以从上下文获取,后面是bins=xxx,labels=xxx
bins和lables可以从上下文获取
这个结构记住,看到bins就套用
6 看到上下文有分组提示,或者最后有mean等计算均值的提示,就用groupby
说明,题目里大概率是根据mean倒推写groupby,但有个别例外,例外就根据分组等关键字倒推groupby
该结构如下,
data.groupby('列名')
data是dataframe的对象名,记住,这里后面还会再有操作,先记这半段
7 向前填充和向后填充,记住这两个搭配语句
data'列名'.fillna(method='ffill' inplace=True)
data'列名'.fillna(method='bfill' inplace=True)
inplace=True其实不用记
8 保存成为xx(大概率是csv)文件
注意两点,从dataframe的对象保存保存到文件
所以格式是
cleaned_data.to_csv('csv文件名', index=False)
cleaned_data是dataframe的对象
index=False也要记的
9 空值和重复值处理
统计空值和重复值
data.isnull().sum()
data.duplicated().sum()
删除空值和重复值
data.dropna()
data.drop_duplicates()
10 数据转换用astype,看到有数据区间,用between
11 标准化处理的格式
先减均值(mean),再除以标准差(std)