简单,是终极的复杂。------列奥纳多·达·芬奇
在工业质检、医疗诊断、安防监控等领域,异常检测一直扮演着至关重要的角色。然而,这个领域长期以来面临着一个核心痛点:方法碎片化。
想象一下,你的工厂需要检测2D图像、3D点云,甚至红外图像中的缺陷,你可能需要为每种数据模态和维护一个独立的模型和代码库。这带来了巨大的部署、维护成本和复杂性。
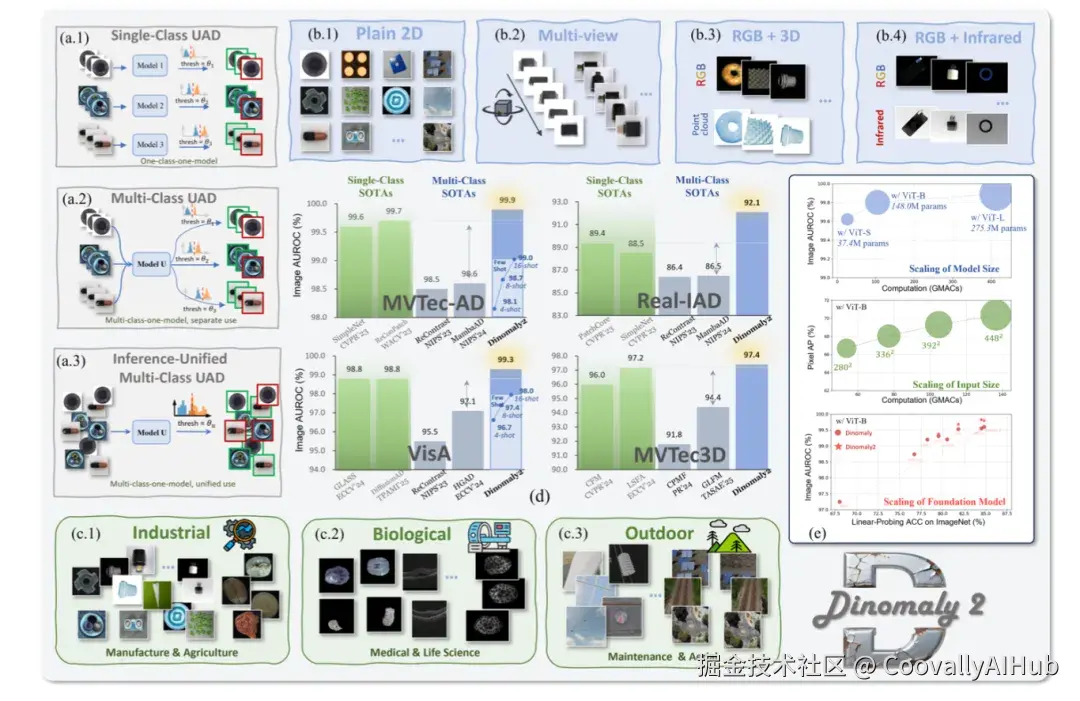
今天,我们要介绍一项开创性的工作------Dinomaly2。它提出了一个反直觉的命题:通用异常检测需要的是简化,而非特化。这个单一模型,首次实现了对全谱系异常检测任务(2D,3D,多视角,少样本等)的统一支持,并在多项基准测试中达到了突破性的性能。

论文链接:
论文链接:
摘要
无监督异常检测已从构建专用的单类别模型发展到统一的多类别模型,然而现有的多类别模型性能显著落后于最先进的专用模型。此外,该领域已分化为针对特定场景的专门方法(多类别、3D、少样本等),造成了部署障碍,凸显了对统一解决方案的需求。本文提出Dinomaly2------首个面向全谱图像无监督异常检测的统一框架,该框架不仅弥合了多类别模型的性能差距,还能无缝扩展到多种数据模态和任务设置。秉承"少即是多"的理念,我们证明在标准基于重构的框架中,通过协调简单元素------通用表征、基础丢弃机制、简化注意力机制、上下文重中心化及宽松优化目标------即可实现卓越性能。这种极简主义方法论使得框架无需修改即可自然扩展到不同任务,证实简单性是实现真正普适性的基础。在12个无监督异常检测基准上的大量实验表明,Dinomaly2在多种模态(2D、多视角、RGB-3D、RGB-IR)、任务设置(单类别、多类别、推理统一多类别、少样本)和应用领域(工业、生物、户外)均展现出全谱系优越性。例如,我们的统一多类别模型在MVTec-AD和VisA数据集上分别实现了前所未有的99.9%和99.3%图像级AUROC。对于多视角和多模态检测,Dinomaly2以最小适配实现了最先进性能。此外,仅使用每类8个正常样本,我们的方法就超越了之前的全样本模型,在MVTec-AD和VisA上分别达到98.7%和97.4%的图像级AUROC。这种极简设计、计算可扩展性和普适适用性的结合,使Dinomaly2成为面向全谱系实际异常检测应用的统一解决方案。
异常检测的困境:从"万能钥匙"到"一把钥匙开一把锁"
早期的异常检测遵循"一类一模型"的范式,就像为每把锁都打造一把专属钥匙。虽然精准,但当你有成百上千把锁时,管理这些钥匙就成了噩梦。
后来,研究者们开始追求"多类别统一模型",希望能用一把"万能钥匙"打开多把锁。然而,这把"万能钥匙"的性能始终比不上那些专属钥匙,存在显著的性能差距。
更糟糕的是,整个领域陷入了"碎片化"的泥潭:
- 2D检测有一套方法。
- 3D或RGB-D检测需要另一套架构。
- 少样本学习又得依赖复杂的元学习或视觉语言模型。
从业者被迫在不同的框架、代码和模型之间切换,苦不堪言。我们迫切需要一场变革。
Dinomaly2的"少即是多"哲学:极简五要素
Dinomaly2的核心思想令人惊叹:通过极简的设计,实现通用的性能。它没有堆砌复杂的模块,而是通过协调五个简单而关键的组件,解决了异常检测的核心挑战。
- 通用视觉表征
摒弃复杂的定制化编码器,直接使用在大规模数据集上预训练的自监督视觉Transformer。这证明了"基础模型"的强大泛化能力足以作为各种异常检测任务的通用特征提取器。
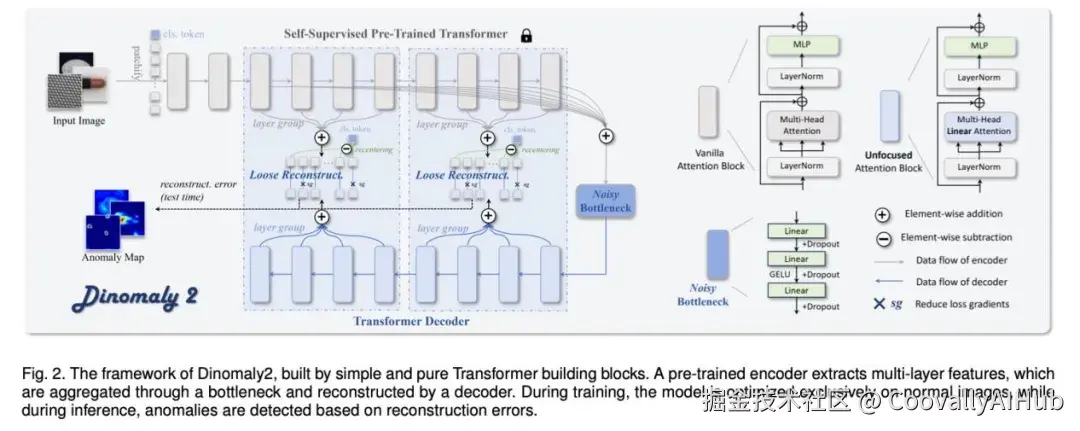
- 噪声瓶颈
传统方法需要精心设计"伪异常"来训练模型。Dinomaly2反其道而行,直接启用MLP层中内置的Dropout作为噪声源。这简单的一步,有效防止了模型对正常模式"过度学习",使其在面对真正异常时更加敏感。
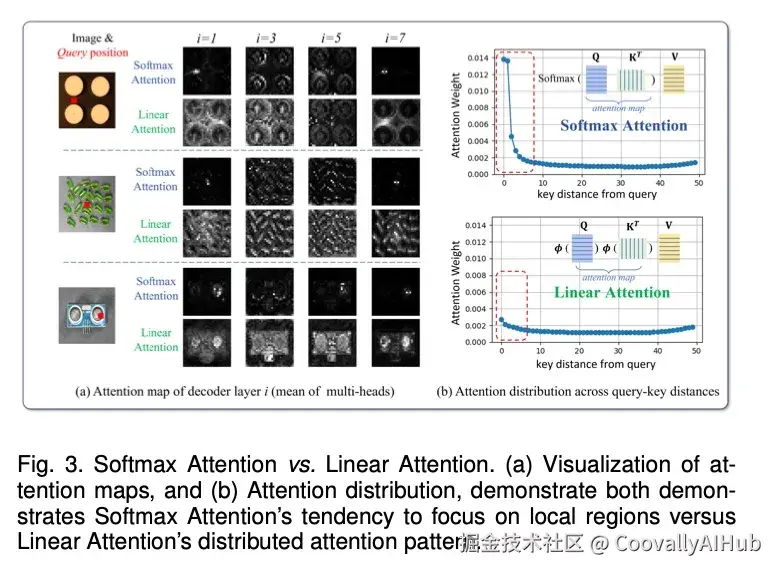
- 非聚焦线性注意力
Transformer中的标准注意力机制过于"聚焦",能精准重构细节,这反而容易让模型"记住"异常。Dinomaly2采用线性注意力,它天生具有"散焦"特性,像一个低通滤波器,迫使模型学习全局的、正常的模式来进行重构,从而无法精确复现异常的局部细节。
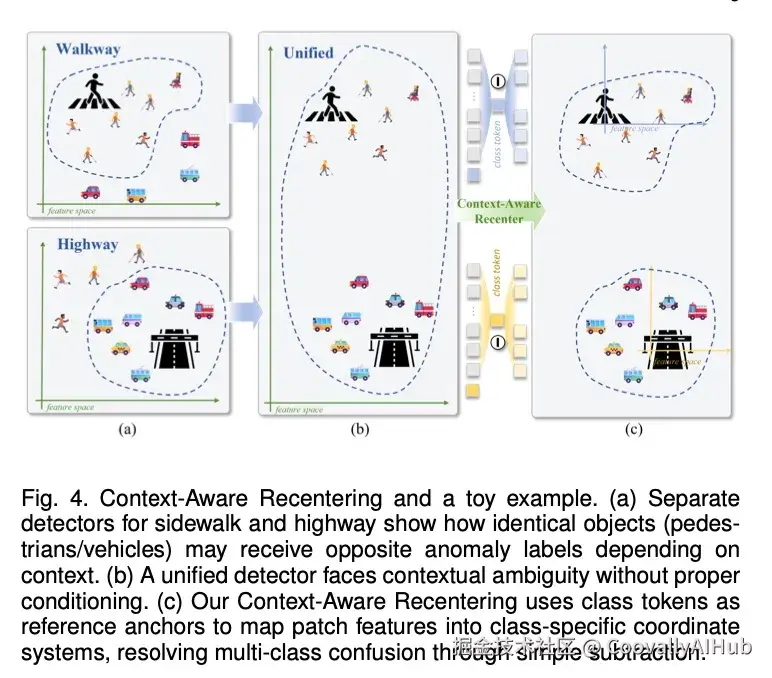
- 上下文感知重中心化
这是解决多类别混淆的关键。同一个物体(如一个圆形),在"螺丝"类别里是正常的,在"饼干"类别里可能就是个缺陷。Dinomaly2做了一个简单的操作:将图像块特征减去类别令牌特征。这个操作让模型学会了"在什么山上唱什么歌",根据类别上下文来理解什么是正常。
- 松散重构
传统方法要求解码器严格模仿编码器的每一层输出,这会让解码器变得"过于聪明"。Dinomaly2则刻意放松了这种约束,只要求解码器重构部分经过筛选的、最具代表性的特征。这如同"抓大放小",避免了模型过度泛化,从而能更好地暴露异常。
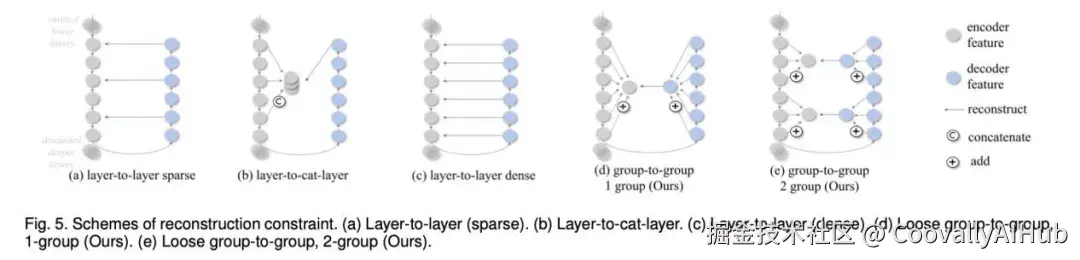
无缝扩展:如何用同一框架应对不同任务?
Dinomaly2的魅力在于其强大的可扩展性,只需最少的改动,就能应对各种复杂场景:
- 多视角检测:将不同视角视为独立的输入,最后综合所有视角的异常分数即可。
- RGB-3D融合:将RGB图和深度图分别输入同一个编码器,然后将得到的特征进行简单的求平均,就完成了信息融合。
- 少样本学习:无需改变架构,仅使用基础的图像增强技术(翻转、旋转等)来扩充有限的正常样本,模型就能表现出强大的少样本能力。
突破性性能:全面碾压,接近饱和
实验结果是Dinomaly2实力最直接的证明。在涵盖12个基准数据集(包括MVTec-AD,VisA,MVTec3D等)、4种数据模态、4种任务设置的全面评估中,Dinomaly2实现了全谱系的领先:
- 在经典2D工业检测上
MVTec-AD图像级AUROC达到99.9%,VisA达到99.3%。研究者认为,这些数据集在Dinomaly2上已接近性能饱和。
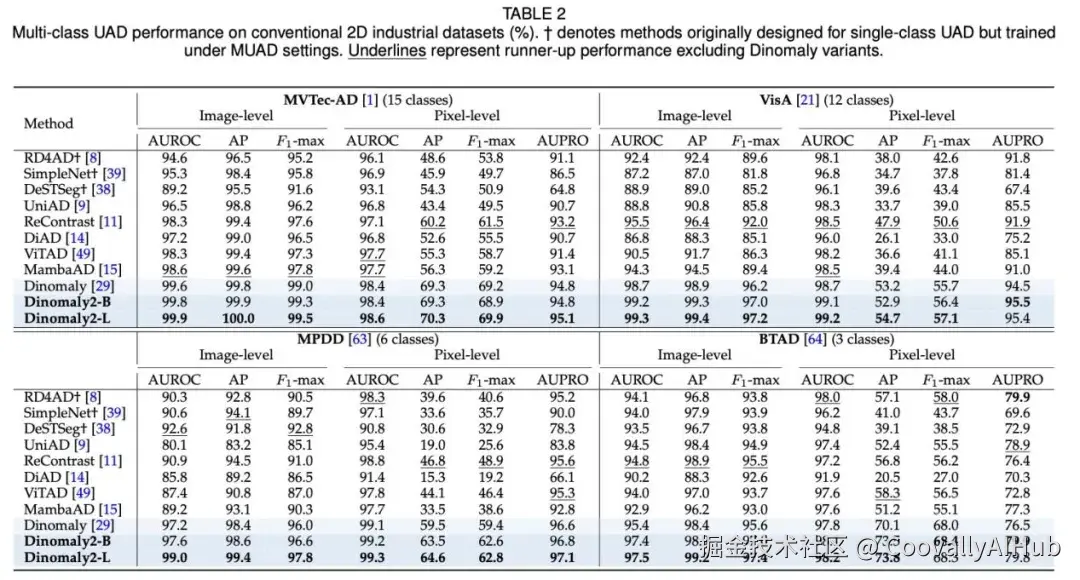
- 在多视角与多模态检测上
在RGB-3D的MVTec3D数据集上,达到97.4%的AUROC。
在RGB-红外的MulSenAD数据集上,达到97.6%的AUROC。

- 在少样本设置下
仅使用每类8个正常样本,在MVTec-AD和VisA上的表现就超越了之前所有全样本模型。

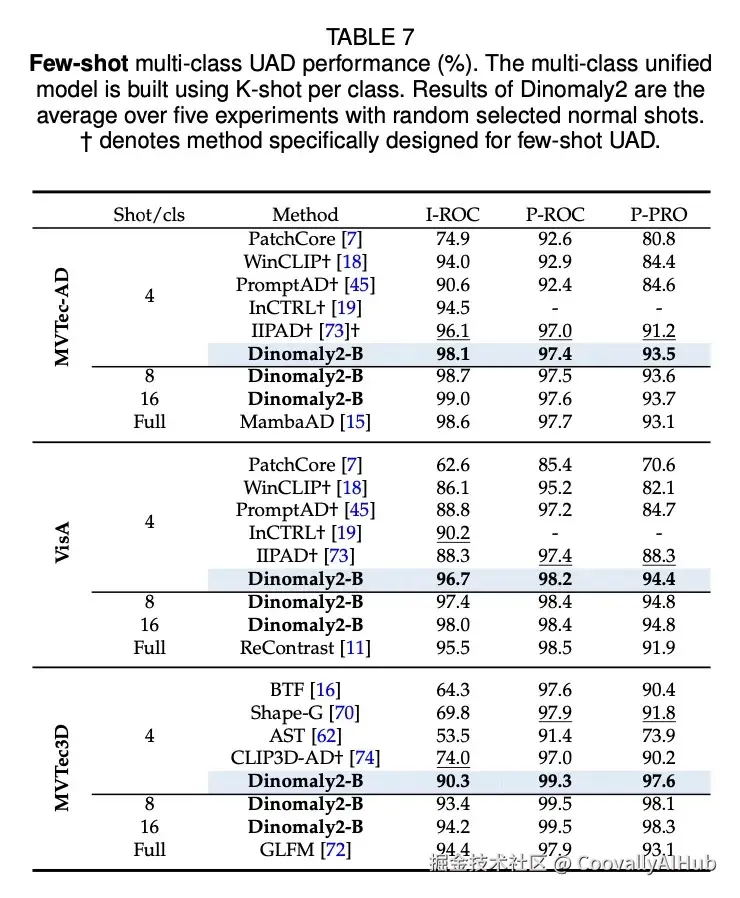
- 超越工业领域
在医疗影像、生物显微、户外设施维护和无人机监控等场景下,同样取得了领先的性能。

总结与展望
Dinomaly2的成功标志着异常检测领域的一个重大范式转变:从专门化的解决方案转向通用的统一框架。
它用事实证明,"少即是多"的极简主义哲学,结合强大的基础模型,能够催生出前所未有的通用性和性能。这不仅降低了研究和工程部署的门槛,也为异常检测在更广阔场景下的应用铺平了道路。
对于工业界而言,这意味着现在可以用一个模型、一套代码来应对工厂里绝大多数甚至所有的质检需求,极大地提升了效率和可维护性。