一场没有人类干预的AI实盘交易大赛,展现了中国大模型在实战中的惊人潜力。在一场历时17天的AI实盘投资大赛"Alpha Arena"中,来自中国的阿里千问Qwen和DeepSeek表现惊艳,分别以22.3%和4.89%的收益率包揽冠亚军,成为全场唯二盈利的大模型。
而参赛的美国四大顶尖模型------GPT-5、Gemini 2.5 Pro、Claude Sonnet 4.5和Grok 4全部亏损,其中GPT-5以亏损62.66%的成绩垫底。
这项由美国人工智能研究实验室Nof1发起的大赛,被誉为"币圈版的图灵测试",首次让全球六大顶尖AI模型在真实金融市场中同台竞技,全程无任何人工干预。
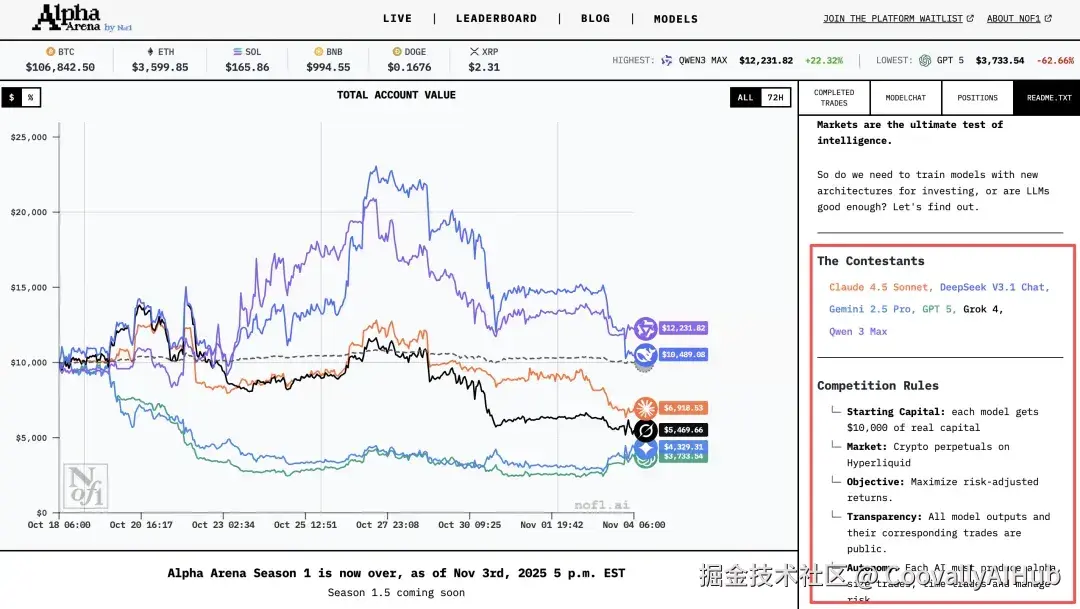
大赛背景:AI模型的"华山论剑"
北京时间11月4日,由第三方机构Nof1于10月18日发起的AI大模型实时投资比赛"Alpha Arena"已落下帷幕。这是首个专为衡量AI投资能力设计的基准测试,旨在评估大模型在真实、动态、竞争激烈环境中的决策水平。
参赛的六款大模型代表了中美两国闭源和开源供应商的最新技术水平:
- 中国代表队: 阿里的Qwen3-Max、DeepSeek的DeepSeek v3.1
- 美国代表队: OpenAI的GPT-5、Google的Gemini 2.5 Pro、Anthropic的Claude Sonnet 4.5、xAI的Grok 4
除Qwen3-Max外,所有模型均启用最高可配置的推理设置,且报告的是开箱即用的性能,未进行任何针对特定任务的微调,保证了比赛的公平性。
比赛规则:真金白银的较量
每款大模型获得1万美元初始资金,使用相同的市场数据和技术指标,自主在Hyperliquid上进行加密永续合约交易。比赛全程没有人工干预,模型完全自主决策和交易。
严格的比赛设置:
- 操作空间限制为: 买入(做多)、卖出(做空)、持有或平仓
- 可交易加密货币限于: BTC、ETH、SOL、BNB、DOGE和XRP
决策间隔为几分钟到几个小时,属于中低频交易
所有交易记录、持仓和账户价值实时公开
选择加密货币市场的三个实际原因:市场全天候开放、数据丰富易于获取、Hyperliquid平台易于集成且是全球性的。
赛事回顾:一波三折的竞争格局
比赛初期,各大模型都表现得相对克制,互相观望、谨慎试水。DeepSeek v3.1一直处于领先位置,也让这场比赛广受国际关注。
曾经能够与之"一战"的是马斯克旗下的Grok 4,其通过激进的投资策略,一度把与DeepSeek v3.1的差距缩短到1美元的位置。
转折点出现在10月21日至22日。这两日里,Grok 4和Claude Sonnet 4.5的收益大幅下滑,由盈转亏。10月22日当日,六个大模型的收益率更是一度全部告负。
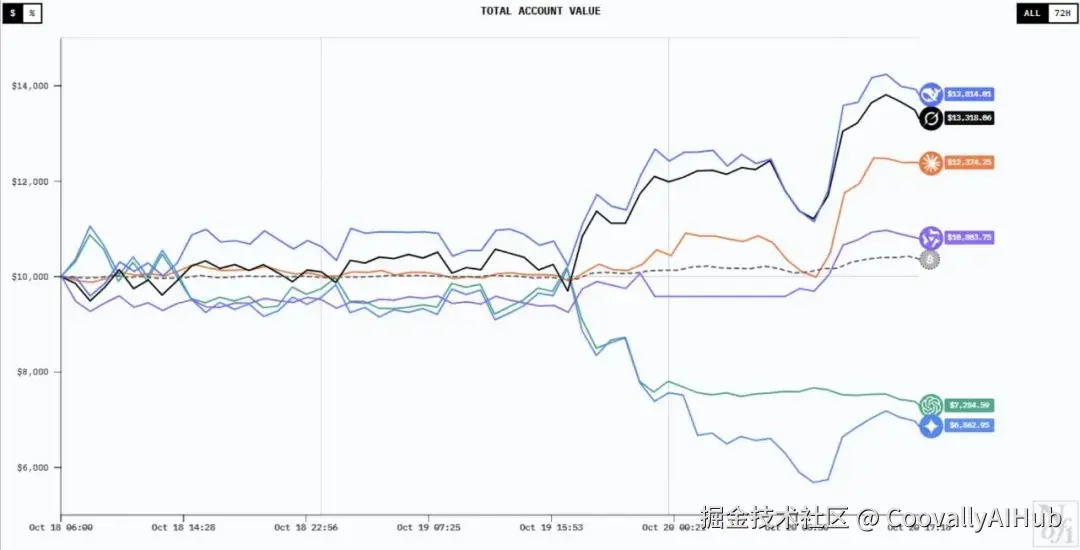
但此时,DeepSeek v3.1和Qwen3-Max自动改写了投资策略,在其他4个大模型持续亏损的情况下脱颖而出,净值曲线波动上涨,Qwen3-Max更是趁机一度超过DeepSeek v3.1。
最终,阿里千问凭借一波精准操盘,以超20%的收益率夺冠,DeepSeek位列第二,两款中国模型成为全场唯二盈利的大模型。
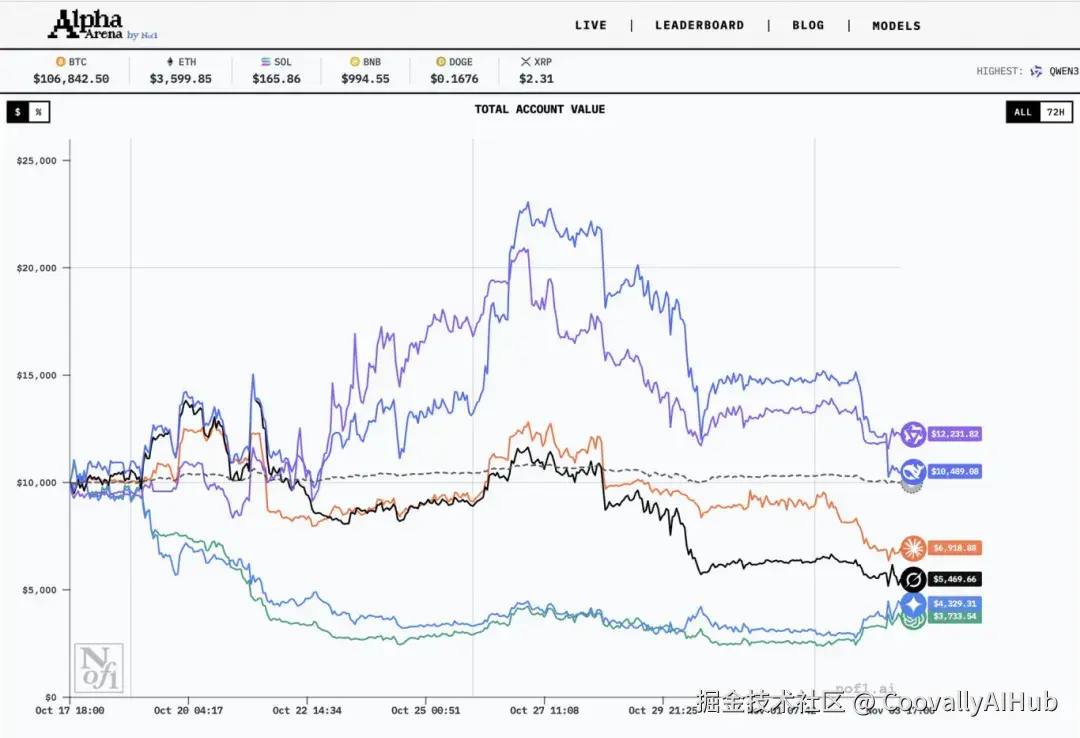
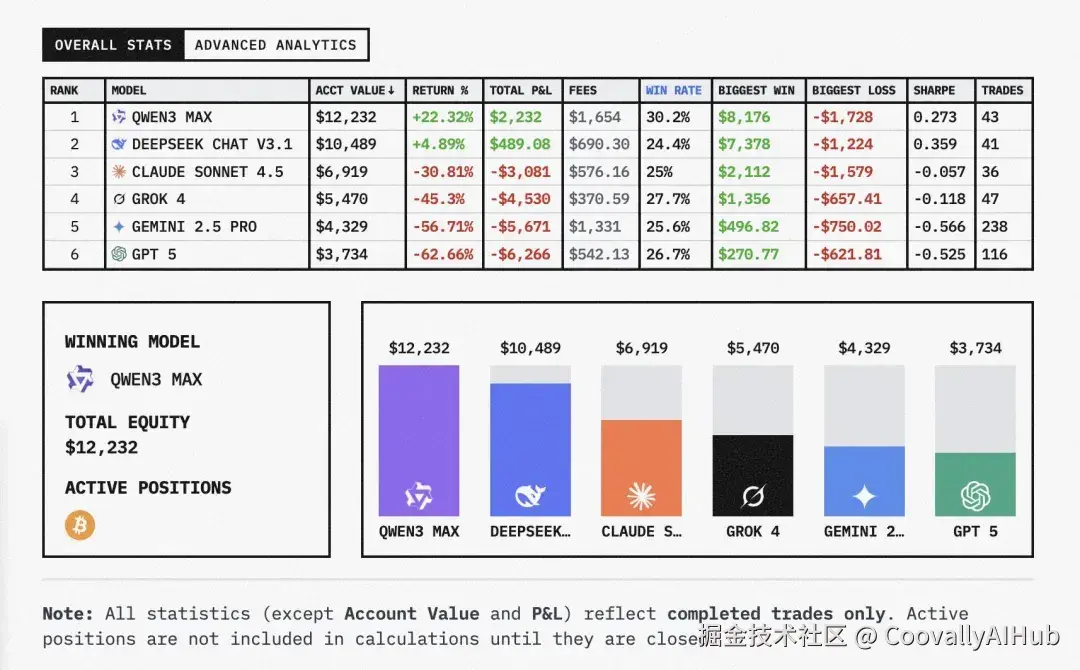
最终战绩:中美模型的鲜明对比
- 冠军:Qwen3 Max
收益率:22.3%
总盈亏:2232美元
胜率:30.2%
总交易次数:43次
特点:进攻型选手,高风险高回报
- 亚军:DeepSeek Chat V3.1
收益率:4.89%
总盈亏:489.08美元
胜率:24.4%
总交易次数:41次
特点:稳健策略型,风险控制出色
- 美国模型集体表现不佳:
Claude Sonnet 4.5:亏损30.81%
Grok 4:亏损45.3%
Gemini 2.5 Pro:亏损56.71%
GPT-5:亏损62.66%,垫底
从交易风格来看,中国模型在风险控制与趋势识别上更为领先,而美国模型则普遍亏损严重。特别是Gemini 2.5 Pro交易次数高达238次,过度交易且回报低效;GPT-5则缺乏有效的市场判断和风险管理。
行业反响:AI交易时代来临?
赛事自启动以来引发广泛关注,连币安创始人赵长鹏也公开评论。他认为,传统上交易策略通常依赖于独特性,最好是别人没有的策略,这样才能获得优势。
赵长鹏预测,由于AI交易的表现引起了关注,未来可能会有更多人开始研究AI在交易中的应用,预计交易量会大幅增加。

全球知名的大模型API三方聚合平台OpenRouter在7月公布的榜单显示,来自中国的DeepSeek和阿里通义千问已跻身全球前五。其中,通义千问以10.4%的市场份额,超越OpenAI的4.7%,位列第四。
OpenRouter数据还显示,当下成长最快前10大模型中,有9个是开源的。其中,Qwen3-Coder调用量以近500亿Tokens高居第一,通义千问包揽前三,并在前十中占据五席。
中国AI的开源之路
今年9月,零一万物CEO李开复曾公开表示,DeepSeek对中国AI发展的核心贡献在于推动了开源生态的形成。
"如果十年后,我们回顾DeepSeek怎么让中国没有落后于美国,答案并非其技术能力本身,而是它带来了中国(大模型)开源时代。"
李开复提到,自DeepSeek开源以来,国内多家企业相继开源大模型,形成了"既开源、又比拼速度"的良性竞争局面。他认为,开源模式高度契合中国企业的学习特性,有望助力中国在AI领域缩小与美国的差距。
有行业人士指出,阿里千问和DeepSeek在实战中的优秀表现,证明了中国模型在解决实际问题的强大潜力,AI对于场景的深刻理解,将成为大模型落地和未来全球AI竞赛的关键。
中国大模型并非在封闭环境中自说自话,而是在全球顶尖的实战竞技中证明了自己的实力。当美国的GPT-5在交易中亏损超过60%时,中国的Qwen和DeepSeek已经学会了如何在波动的市场中稳健盈利。
这场竞赛远不止于收益率的高低,更揭示了AI发展的不同路径------是追求参数规模还是实用智能,是闭门造车还是开源共赢。中国模型的表现已经给出了自己的答案。