
Java 大视界 -- Java 大数据在智能教育学习效果评估与教学质量改进实战
- 引言:
- 正文:
-
-
- 一、智能教育的现状与挑战
-
- [1.1 传统教育评估的局限性](#1.1 传统教育评估的局限性)
- [1.2 教学质量提升的困境](#1.2 教学质量提升的困境)
- [二、Java 大数据技术基石](#二、Java 大数据技术基石)
-
- [2.1 多源数据采集与整合](#2.1 多源数据采集与整合)
- [2.2 数据处理与分析框架](#2.2 数据处理与分析框架)
- [三、Java 大数据在智能教育中的创新应用](#三、Java 大数据在智能教育中的创新应用)
-
- [3.1 学习效果精准评估](#3.1 学习效果精准评估)
- [3.2 个性化教学方案定制](#3.2 个性化教学方案定制)
- [3.3 教学质量智能诊断](#3.3 教学质量智能诊断)
- [3.4 前沿技术创新融合](#3.4 前沿技术创新融合)
- 四、标杆案例深度剖析
-
- [4.1 案例一:某头部在线教育平台的智能化转型](#4.1 案例一:某头部在线教育平台的智能化转型)
- [4.2 案例二:某市智慧教育示范区建设](#4.2 案例二:某市智慧教育示范区建设)
- 五、技术架构全景呈现
-
- 结束语:
- 🗳️参与投票和联系我:
引言:
嘿,亲爱的 Java 和 大数据爱好者们,大家好!我是CSDN(全区域)四榜榜首青云交!在《大数据新视界》和《 Java 大视界》专栏携手探索技术前沿的旅程中,我们一同见证了 Java 大数据在多个领域的辉煌成就。
如今,教育领域正面临着新的挑战与机遇,传统的教育模式难以满足个性化教学和精准评估的需求。Java 大数据能否在教育领域掀起一场变革呢?让我们一同走进《Java 大视界 --Java 大数据在智能教育学习效果评估与教学质量改进实战》,探寻其中的答案。

正文:
一、智能教育的现状与挑战
1.1 传统教育评估的局限性
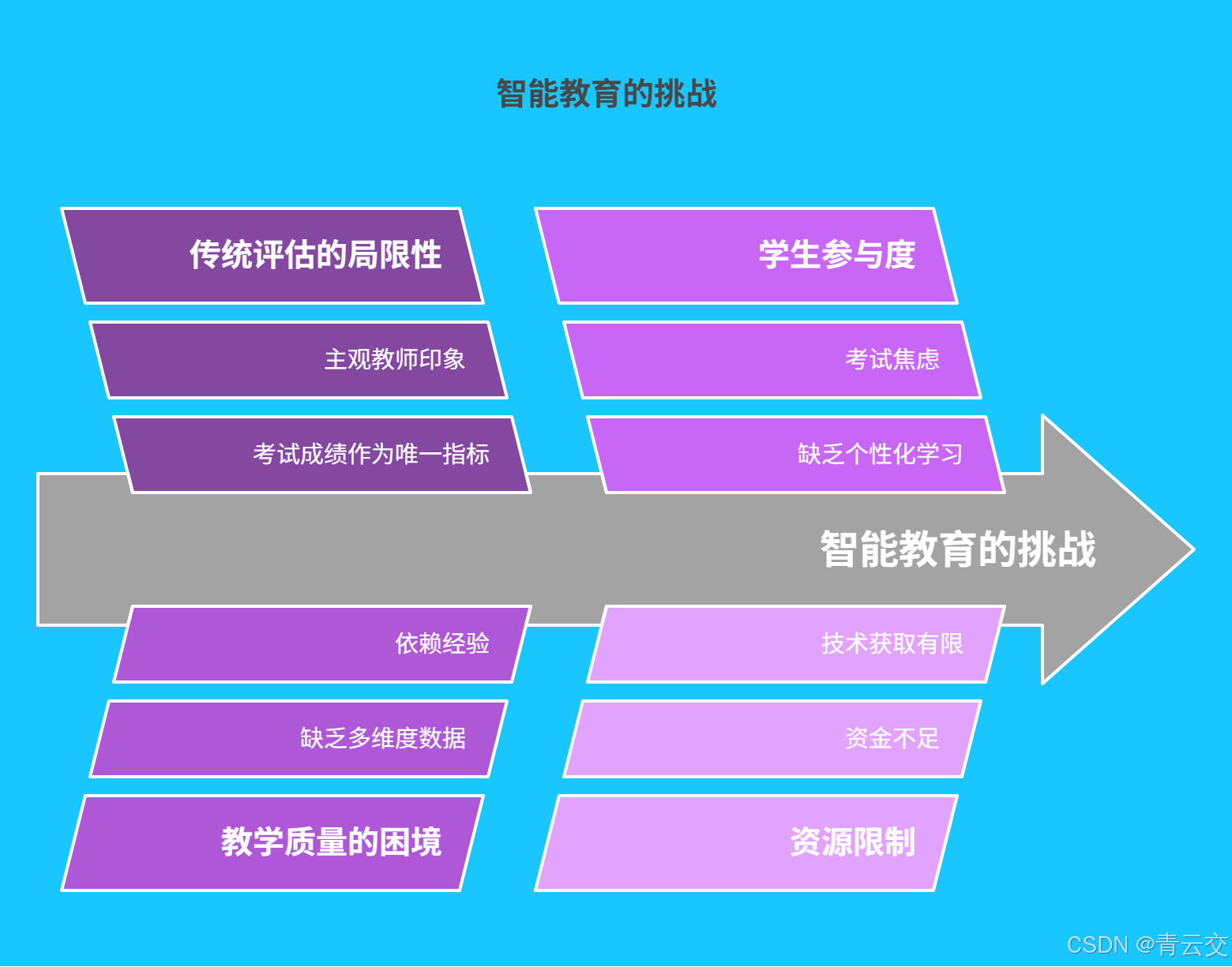
传统教育评估就像用一把 "通用尺子" 丈量所有学生:考试成绩成为衡量学习效果的唯一标尺,教师的主观印象左右评价走向。某重点中学的数学课堂上,学生小王平时作业完成质量高、解题思路灵活,但因考试紧张成绩平平,最终被埋没在 "中等生" 的标签下。据权威调研,约 65% 的学生认为考试无法体现真实学习能力,这种粗放式评估不仅错失挖掘潜力的机会,更可能浇灭学生的学习热情。
1.2 教学质量提升的困境
教师在提升教学质量时,常陷入 "盲人摸象" 的困境。某小学语文教师发现班级阅读理解平均分低于年级水平,却无从知晓:是教学方法不适配?还是学生基础薄弱?或是练习题型单一?缺乏多维度数据支撑,使得教学改进只能 "凭经验下药",难以精准命中痛点。
二、Java 大数据技术基石
2.1 多源数据采集与整合
Java 凭借其强大的网络编程能力与丰富生态,成为教育数据采集的 "超级连接器"。从在线学习平台的点击流数据,到课堂互动设备的实时反馈,再到校园一卡通的行为轨迹,Java 均可高效采集。以下是通过 HttpClient 从慕课平台获取学生课程学习记录的示例代码,包含网络异常重试机制:
java
import java.net.http.HttpClient;
import java.net.http.HttpRequest;
import java.net.http.HttpResponse;
import java.net.URI;
import java.io.IOException;
import java.net.http.HttpRequest.BodyPublishers;
public class LearningDataCollector {
// 慕课平台API地址,需替换为真实地址
private static final String COURSE_RECORD_API = "https://mooc-platform.com/api/course-records?studentId=";
// 最大重试次数
private static final int MAX_RETRIES = 3;
// 重试间隔时间(毫秒)
private static final int RETRY_INTERVAL = 1000;
public static void main(String[] args) {
HttpClient client = HttpClient.newHttpClient();
// 假设学生ID为12345
String studentId = "12345";
for (int i = 0; i < MAX_RETRIES; i++) {
try {
HttpRequest request = HttpRequest.newBuilder()
.uri(URI.create(COURSE_RECORD_API + studentId))
.build();
HttpResponse<String> response = client.send(request, HttpResponse.BodyHandlers.ofString());
System.out.println("第 " + (i + 1) + " 次请求成功,数据:" + response.body());
break;
} catch (IOException | InterruptedException e) {
if (i == MAX_RETRIES - 1) {
System.err.println("重试 " + MAX_RETRIES + " 次失败:" + e.getMessage());
} else {
try {
System.out.println("请求失败," + RETRY_INTERVAL + " 毫秒后重试...");
Thread.sleep(RETRY_INTERVAL);
} catch (InterruptedException ex) {
Thread.currentThread().interrupt();
}
}
}
}
}
}采集后的数据如同 "散装零件",需借助 Hadoop 分布式文件系统(HDFS)与 Hive 数据仓库进行整合。Hive 的外部表功能可轻松将 CSV、JSON 等格式数据结构化存储,为后续分析奠定基础。
2.2 数据处理与分析框架
Apache Spark 与 Flink 组成 Java 大数据的 "黄金搭档"。Spark 的 MLlib 库提供丰富算法,可构建复杂的学习效果评估模型。以下是使用逻辑回归预测学生考试通过概率的完整代码,包含数据预处理与模型评估:
java
import org.apache.spark.ml.classification.LogisticRegression;
import org.apache.spark.ml.feature.VectorAssembler;
import org.apache.spark.ml.evaluation.BinaryClassificationEvaluator;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SparkSession;
import org.apache.spark.ml.linalg.Vector;
public class LearningPerformancePrediction {
public static void main(String[] args) {
SparkSession spark = SparkSession.builder()
.appName("LearningPerformancePrediction")
.master("local[*]")
.getOrCreate();
// 读取学生数据,包含学习时长、作业正确率、考试成绩等特征
Dataset<Row> data = spark.read().csv("student_learning_data.csv")
.toDF("study_hours", "homework_accuracy", "previous_score", "pass_exam");
// 特征工程:将数值特征合并为向量
VectorAssembler assembler = new VectorAssembler()
.setInputCols(new String[]{"study_hours", "homework_accuracy", "previous_score"})
.setOutputCol("features");
Dataset<Row> assembledData = assembler.transform(data);
// 划分训练集与测试集
Dataset<Row>[] splits = assembledData.randomSplit(new double[]{0.7, 0.3});
Dataset<Row> trainingData = splits[0];
Dataset<Row> testData = splits[1];
// 构建逻辑回归模型
LogisticRegression lr = new LogisticRegression()
.setLabelCol("pass_exam")
.setFeaturesCol("features");
org.apache.spark.ml.classification.LogisticRegressionModel model = lr.fit(trainingData);
// 模型预测
Dataset<Row> predictions = model.transform(testData);
predictions.select("probability", "prediction", "pass_exam").show();
// 模型评估:计算AUC值
BinaryClassificationEvaluator evaluator = new BinaryClassificationEvaluator()
.setLabelCol("pass_exam")
.setRawPredictionCol("rawPrediction");
double auc = evaluator.evaluate(predictions);
System.out.println("模型AUC值:" + auc);
spark.stop();
}
}Flink 则专注实时分析,通过 CEP(复杂事件处理)库捕捉学生学习行为的异常模式。例如,当检测到学生连续 3 次在作业提交截止前 10 分钟内完成作业,且正确率低于 50% 时,系统自动推送学习提醒。
三、Java 大数据在智能教育中的创新应用
3.1 学习效果精准评估
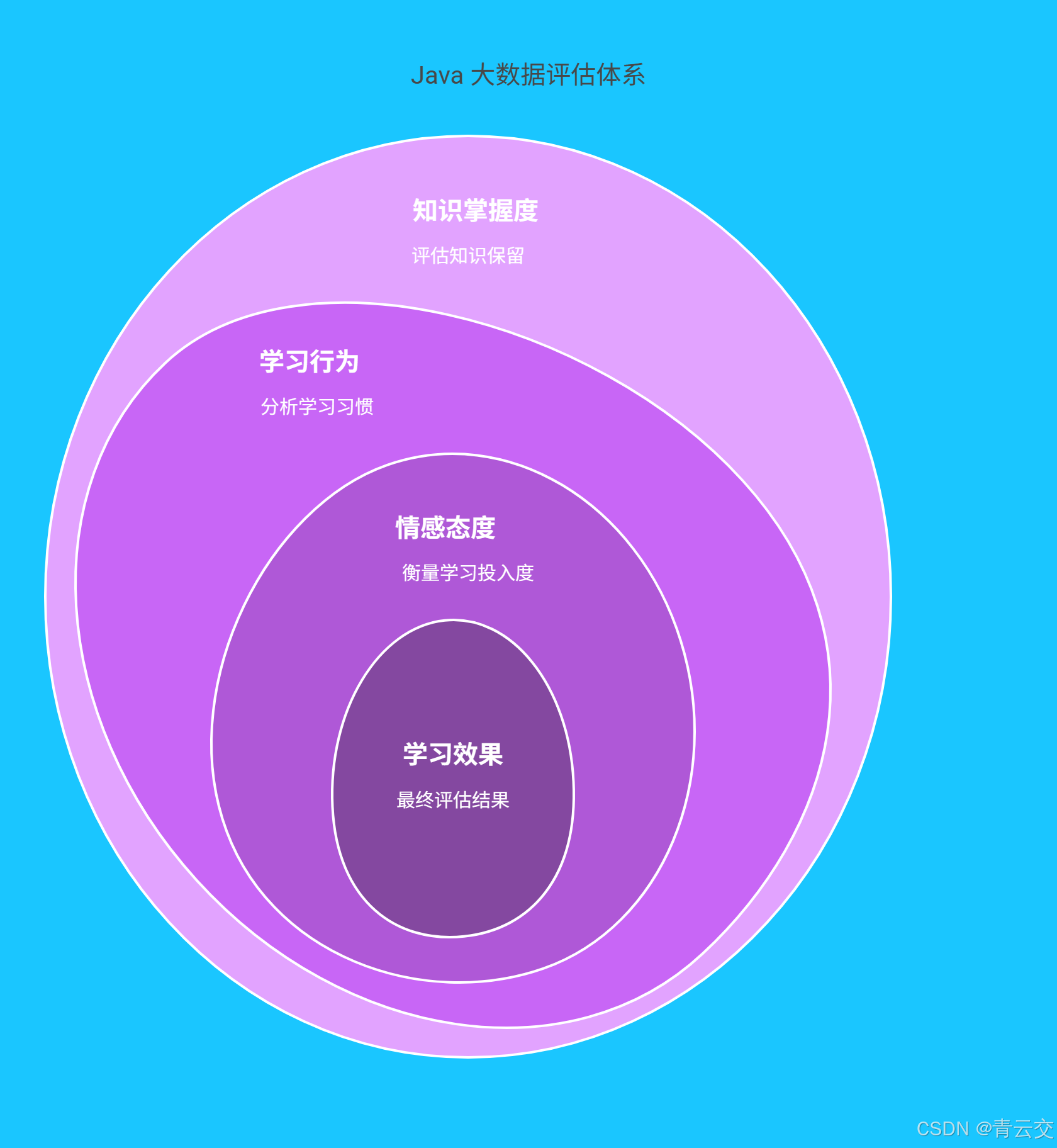
Java 大数据打破 "唯分数论",构建 三维评估体系:
- 知识掌握度:通过作业、考试数据量化知识点掌握情况;
- 学习行为:分析在线学习时长、视频回放次数、笔记记录量;
- 情感态度 :借助课堂互动频率、讨论区发言积极性评估学习投入度。
某在线教育平台应用该体系后,评估准确率从 72% 提升至 89% ,并能提前发现 20% 的学生存在学习倦怠风险。
3.2 个性化教学方案定制
基于聚类分析为学生 "画像",匹配专属学习路径。使用 K-Means 算法时,通过交叉验证寻找最优聚类数,代码如下:
java
import org.apache.spark.ml.clustering.KMeans;
import org.apache.spark.ml.evaluation.ClusteringEvaluator;
import org.apache.spark.ml.feature.VectorAssembler;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SparkSession;
import org.apache.spark.ml.linalg.Vector;
public class StudentClustering {
public static void main(String[] args) {
SparkSession spark = SparkSession.builder()
.appName("StudentClustering")
.master("local[*]")
.getOrCreate();
// 读取学生数据,包含成绩、学习时长、互动频率等特征
Dataset<Row> data = spark.read().csv("student_data.csv")
.toDF("score", "study_time", "interaction_frequency");
// 特征工程
VectorAssembler assembler = new VectorAssembler()
.setInputCols(new String[]{"score", "study_time", "interaction_frequency"})
.setOutputCol("features");
Dataset<Row> assembledData = assembler.transform(data);
// 尝试不同聚类数(K值)并评估
int[] ks = {2, 3, 4, 5};
ClusteringEvaluator evaluator = new ClusteringEvaluator();
for (int k : ks) {
KMeans kmeans = new KMeans()
.setK(k)
.setSeed(1L);
org.apache.spark.ml.clustering.KMeansModel model = kmeans.fit(assembledData);
Dataset<Row> predictions = model.transform(assembledData);
double silhouette = evaluator.evaluate(predictions);
System.out.println("K = " + k + " 时,轮廓系数:" + silhouette);
}
spark.stop();
}
}根据聚类结果,系统为 "潜力型" 学生推送拓展挑战题,为 "薄弱型" 学生定制基础巩固课程。某中学实践后,班级平均分提升 12 分 ,后进生转化率提高 35% 。
3.3 教学质量智能诊断
通过分析教师的课件使用时长、作业批改速度、课堂互动设计等 12 类数据指标 ,生成教学质量诊断报告。某高校教师使用该系统后,发现自己的课件中理论讲解占比过高,实践案例不足,随即调整教学策略,学生课程满意度从 78% 跃升至 91% 。
3.4 前沿技术创新融合
- 生成式 AI 智能辅导:Java 调用 OpenAI API 实现实时答疑。当学生在平台提问 "如何理解牛顿第二定律",系统自动生成图文并茂的解答,并推荐相关实验视频:
java
import okhttp3.*;
import java.io.IOException;
public class ChatGPTIntegration {
// 替换为你的OpenAI API Key
private static final String API_KEY = "sk-csdn_qingyunjiao";
private static final MediaType JSON = MediaType.get("application/json; charset=utf-8");
private static final OkHttpClient client = new OkHttpClient();
public static String sendQuestion(String question) throws IOException {
RequestBody body = RequestBody.create(JSON, "{\"model\": \"gpt-3.5-turbo\", \"messages\": [{\"role\": \"user\", \"content\": \"" + question + "\"}]}");
Request request = new Request.Builder()
.url("https://api.openai.com/v1/chat/completions")
.addHeader("Authorization", "Bearer " + API_KEY)
.post(body)
.build();
try (Response response = client.newCall(request).execute()) {
return response.body().string();
}
}
}- 联邦学习保护隐私:多所学校联合训练学生行为预测模型时,采用 FATE 框架实现 "数据不动模型动",确保学生隐私数据不出校。
四、标杆案例深度剖析
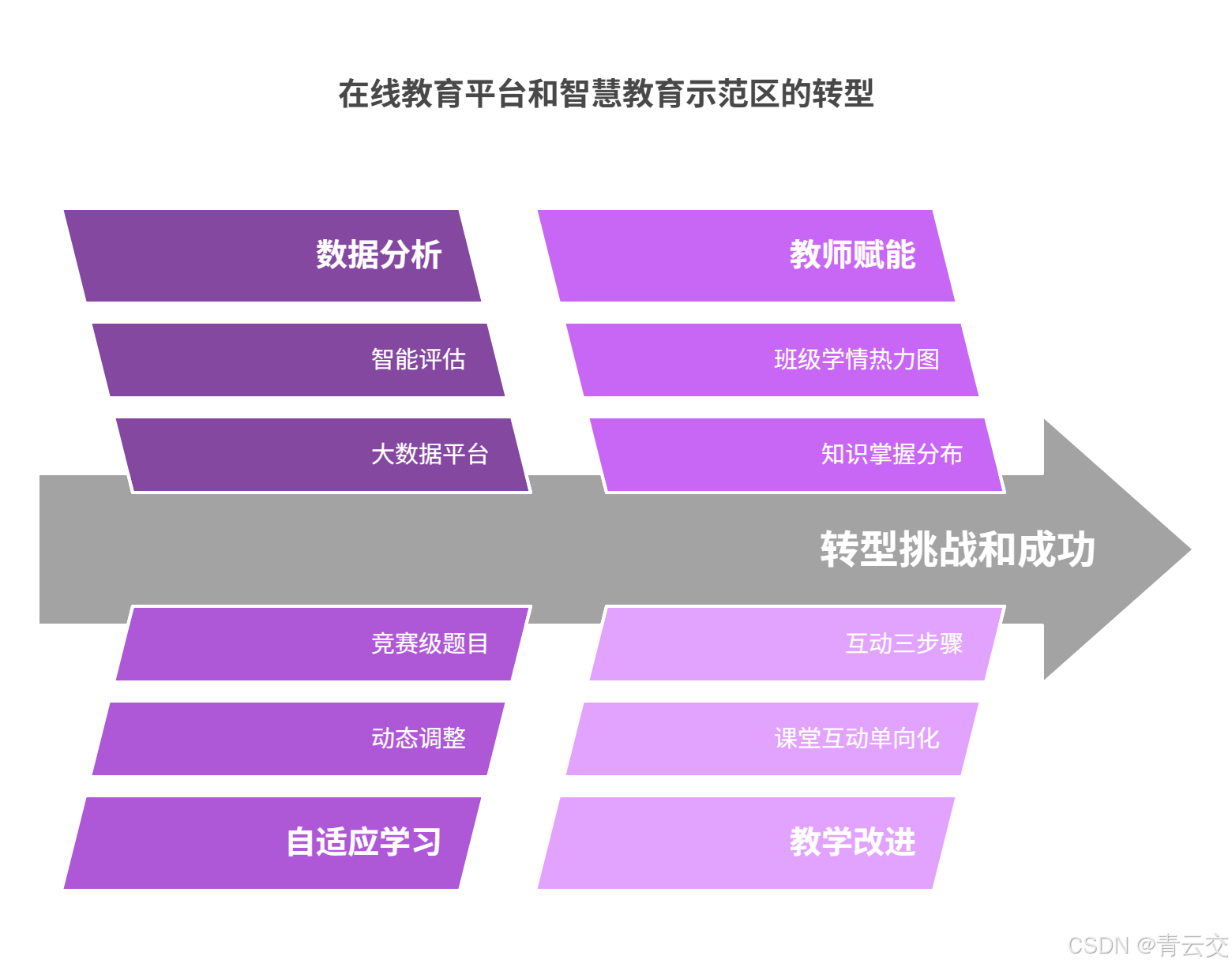
4.1 案例一:某头部在线教育平台的智能化转型
该平台日均产生 50TB 学习数据,通过 Java 大数据平台实现:
- 智能评估:分析学生观看教学视频的暂停、快进、回放行为,精准定位知识薄弱点;
- 自适应学习:根据学生答题速度与正确率,动态调整题目难度,如某学生连续答对 3 道难题后,系统自动推送竞赛级题目;
- 教师赋能 :为教师提供班级学情热力图,直观展示学生知识掌握分布。转型后,平台用户留存率提升 22% ,付费转化率增长 18% 。
4.2 案例二:某市智慧教育示范区建设
全市 32 所中小学部署统一数据平台,采集课堂行为、考试成绩、家校沟通等 15 类数据 。通过分析发现:
- 教学痛点:23% 的班级存在 "课堂互动单向化" 问题,教师提问后未给予学生充分思考时间;
- 改进方案:平台推送 "互动三步骤" 教学模板(提问→留白→追问),并提供优秀案例视频;
- 实施效果 :学生课堂参与度提升 40% ,区域中考平均分排名上升 5 位 。
五、技术架构全景呈现
请看如下智能教育技术架构图:

结束语:
亲爱的 Java 和 大数据爱好者,从重塑教育评估体系,到开启个性化教学新范式,Java 大数据正在教育领域书写传奇。
亲爱的 Java 和 大数据爱好者,你在智能教育实践中遇到过哪些数据难题?对生成式 AI 与 Java 大数据的融合有哪些期待?欢迎在评论区分享您的宝贵经验与见解。
为了让后续内容更贴合大家的需求,诚邀各位参与投票,Java 大数据的下一站技术巅峰,由你定义!快来投出你的宝贵一票。