模型参数(20B和120B版本)

考虑Attention Sink的Attention计算
大模型推理时,在大部分层上能观察到注意力很大程度关注到开头的几个token上,在StreamingLLM中被称为attention sink。究其原因,并不是开头的token一定最重要,而是当大模型无法有效关注到主要token时,由于开头的token能被后面所有token看到,所以表现出很高的attention score。
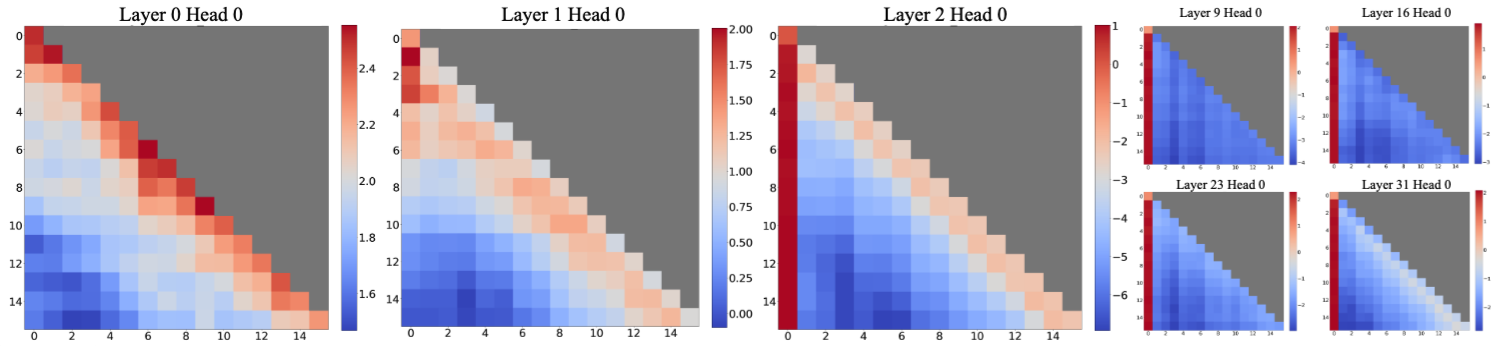
因此有一类工作聚焦于 规避attention sink的出现 ,避免这样的现象影响有效的attention计算。
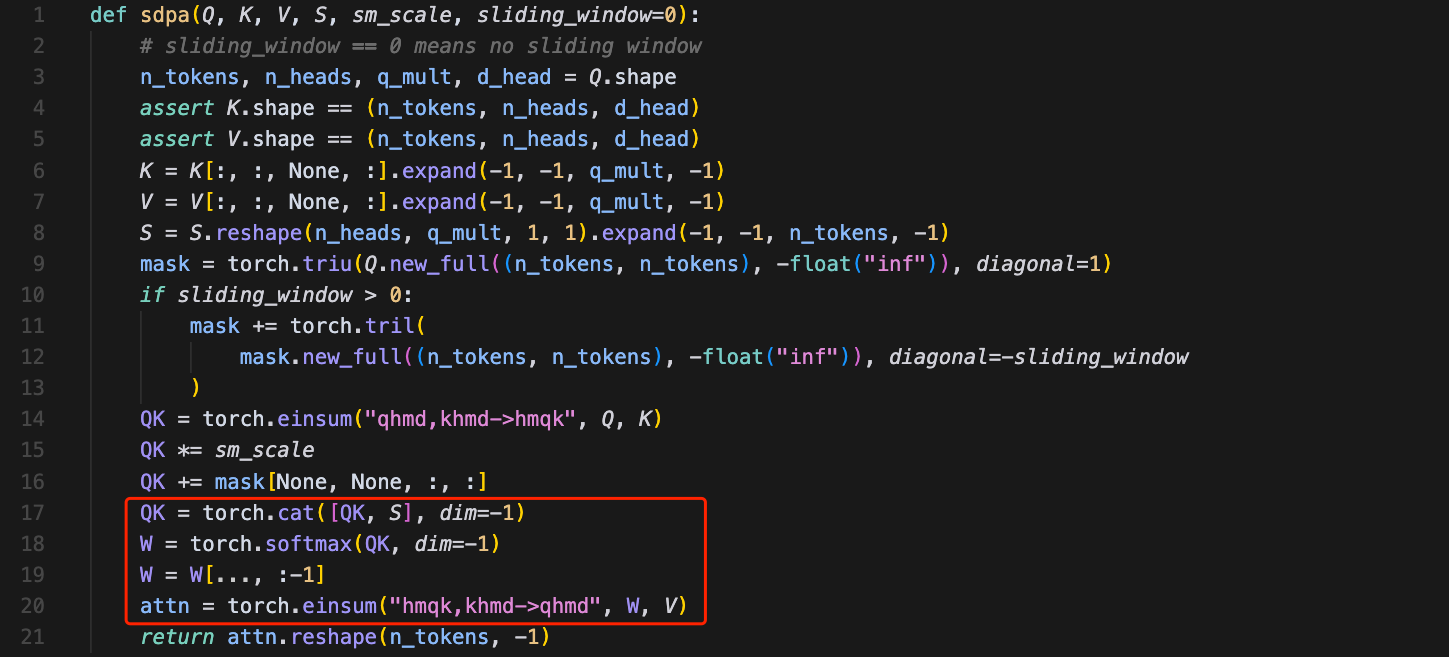
GPT-OSS提出bias项来修正attention sink,基本的思路是在计算完QK之后,给每个head拼接上额外的一个token(可学习的bias token),然后计算softmax,再把bias token丢弃,最后去和V相乘计算attention的输出。
GPT-OSS源代码如下(写法相对比较晦涩):
于是,我重新整理了一版更简洁的代码:
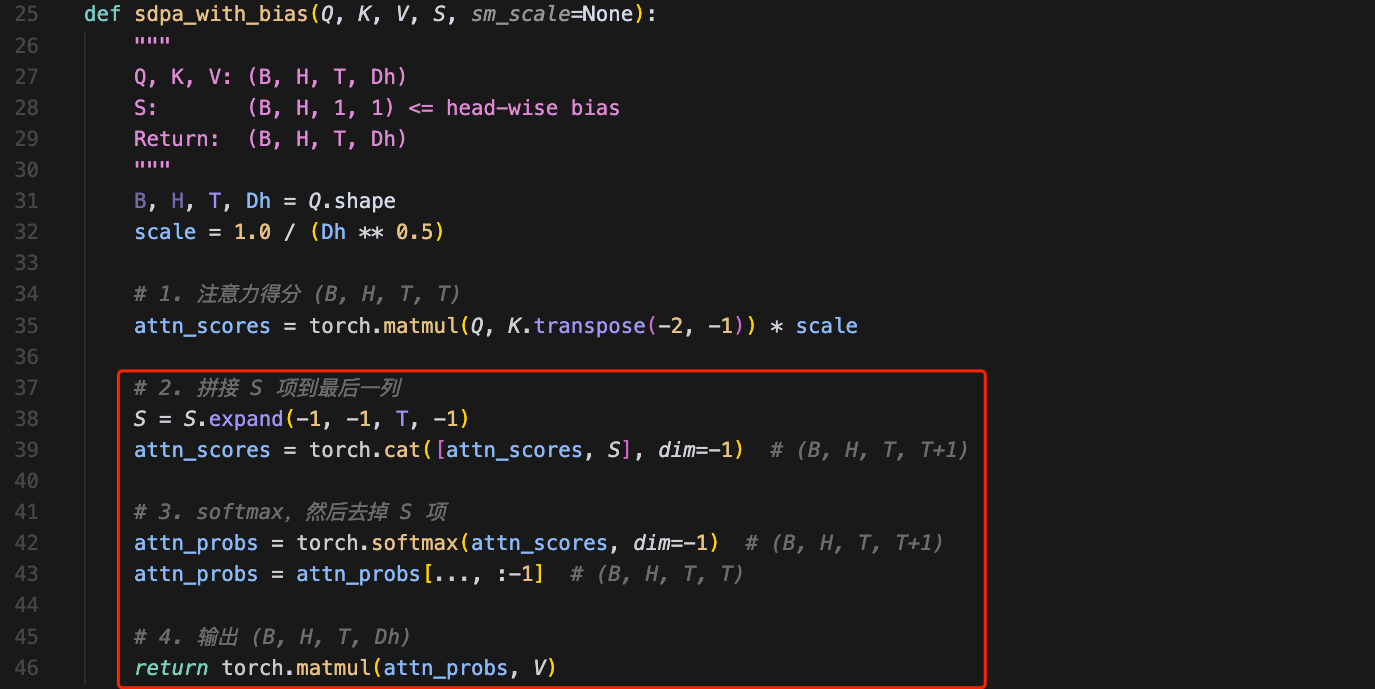
S这个可学习的bias项应该是head-wise,即给每个head都加上一个额外的token,参数定义如下:
python
self.S = torch.nn.Parameter(torch.empty(config.num_attention_heads))从数学角度分析,上面这个过程 本质上就是给attention的计算中分母的求和加上了额外的一项:
softmax(xi)=exp(xi)∑jexp(xj)→exp(xi)∑jexp(xj)+exp(S)softmax(x_i) =\frac{\exp(x_i)}{\sum_j \exp(x_j)} \rightarrow \frac{\exp(x_i)}{\sum_j \exp(x_j)+\exp(S)}softmax(xi)=∑jexp(xj)exp(xi)→∑jexp(xj)+exp(S)exp(xi)
但注意和V相乘之前,需要去掉bias token,从而得到attention的输出。
补充:也有工作是给分母上加1,达到类似的效果,不过GPT-OSS用可学习的bias项会更加灵活。
分层混合稀疏Attention
GPT-OSS采用隔层交错的attention,混合标准的GQA(full attention)和sliding window attention。
其中,window的大小是128,通过下面的方式决定哪些层用sliding window attention:
python
self.sliding_window = config.sliding_window if layer_idx % 2 == 0 else 0