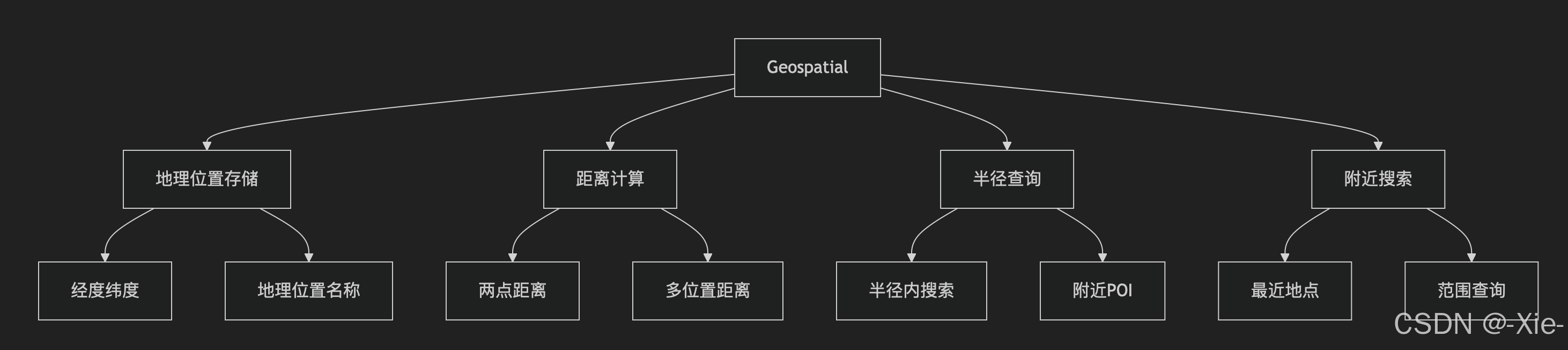
Geospatial数据类型(地理空间)
这个数据类型是Redis中用于地理位置存储和查询 的数据结构,基于有序集合(ZSet)实现。下面这个图是这个类型的主要作用。
sql
# 添加城市地理位置 key 经度 纬度 成员名
127.0.0.1:6379> GEOADD cities:china 116.397128 39.916527 "北京"
(integer) 1
# 获取多个城市坐标
127.0.0.1:6379> GEOPOS cities:china "北京" "上海" "广州"
1) 1) "116.39712810516357422"
2) "39.91652683967833443"
2) 1) "121.47370100021362305"
2) "31.23041599967836496"
3) 1) "113.26438462734222412"
2) "23.12911236438178547"
# 计算距离m- 米(默认)km- 千米 mi- 英里 ft- 英尺
127.0.0.1:6379> GEODIST cities:china "北京" "上海"
"1067591.9662" # 约1067公里
# 使用千米单位
127.0.0.1:6379> GEODIST cities:china "北京" "上海" km
"1067.5920" # 约1067公里这里是redis2.6的一些基础命令,其他的新命令或者命令详情的使用方法还是和上篇一样,小伙伴自行查找吧,我们从这个数据类型的名称就可以知道,这个类型就是为地图而生的,一般用到的地方比如租房啊、外卖啊这种会比较多。我们上一篇的结尾说的超日志(HyperLogLogs)类型是set的衍生,而GEO就是Zset的衍生了。
| 命令 | 语法 | 作用 | 返回值 | 时间复杂度 | 示例 |
|---|---|---|---|---|---|
| GEOADD | GEOADD key longitude latitude member [longitude latitude member ...] |
添加地理位置 | 新增成员数 | O(log N) | GEOADD cities 116.40 39.91 "北京" |
| GEOPOS | GEOPOS key member [member ...] |
获取成员坐标 | 坐标列表 | O(log N) | GEOPOS cities "北京" |
| GEODIST | GEODIST key member1 member2 [unit] |
计算两点距离 | 距离值 | O(log N) | GEODIST cities "北京" "上海" km |
| GEOHASH | GEOHASH key member [member ...] |
获取地理哈希 | 哈希值列表 | O(log N) | GEOHASH cities "北京" |
| GEORADIUS | GEORADIUS key longitude latitude radius unit [options] |
半径查询(旧) | 成员列表 | O(N+log M) | GEORADIUS cities 116.40 39.91 100 km |
| GEORADIUSBYMEMBER | GEORADIUSBYMEMBER key member radius unit [options] |
成员半径查询(旧) | 成员列表 | O(N+log M) | GEORADIUSBYMEMBER cities "北京" 200 km |
Pub/Sub发布订阅类型
这个发布订阅相信大家都不陌生吧,也就是我们常说的消息队列中间件如RabbitMQ,那Redsi一个干数据库的这么和消息队列抢饭吃了呢?他们之间又有什么区别呢?快下面的表格:
| 特性 | Pub/Sub | 消息队列 |
|---|---|---|
| 消息传递 | 一对多广播,也支持点对点 | 点对点传递,也支持广播 |
| 消息持久化 | 不持久化 | 可持久化 |
| 消费者状态 | 无状态 | 有状态(确认机制) |
| 实时性 | 实时推送 | 可延迟处理 |
| 适用场景 | 实时通知、事件驱动 | 任务队列、异步处理 |
Pub/Sub主包认为他们就是只负责发送的,同时像多个订阅者发送,收不收得到不关心,而消息队列更加倾向于点对点,也就是一个队列专门一部分人消费,而且是排队的,上一个消费了才能消费下一个。redis的这个发布订阅更加倾向于广播,也就是公告啊、资讯之类的推送。下面这个是一些命令:
| 命令 | 语法 | 作用 | 返回值 | 时间复杂度 | 示例 |
|---|---|---|---|---|---|
| SUBSCRIBE | SUBSCRIBE channel [channel ...] |
订阅一个或多个频道 | 订阅确认消息 | O(N) N=频道数 | SUBSCRIBE news:sports |
| UNSUBSCRIBE | UNSUBSCRIBE [channel ...] |
退订一个或多个频道 | 退订确认消息 | O(N) N=频道数 | UNSUBSCRIBE news:sports |
| PUBLISH | PUBLISH channel message |
向频道发布消息 | 接收到消息的客户端数 | O(N+M) N=订阅者数 M=模式订阅者数 | PUBLISH news:sports "比赛结果" |
| PSUBSCRIBE | PSUBSCRIBE pattern [pattern ...] |
订阅匹配模式的频道 | 订阅确认消息 | O(N) N=模式数 | PSUBSCRIBE news:* |
| PUNSUBSCRIBE | PUNSUBSCRIBE [pattern ...] |
退订匹配模式的频道 | 退订确认消息 | O(N) N=模式数 | PUNSUBSCRIBE news:* |
这个是监控和管理的命令。
| 命令 | 语法 | 作用 | 返回值 | 时间复杂度 | 示例 |
|---|---|---|---|---|---|
| PUBSUB CHANNELS | PUBSUB CHANNELS [pattern] |
查看活跃频道列表 | 频道名称列表 | O(N) N=频道数 | PUBSUB CHANNELS news:* |
| PUBSUB NUMSUB | PUBSUB NUMSUB [channel ...] |
查看指定频道的订阅者数 | 频道和订阅数键值对 | O(N) N=频道数 | PUBSUB NUMSUB news:sports |
| PUBSUB NUMPAT | PUBSUB NUMPAT |
查看模式订阅的数量 | 模式订阅总数 | O(1) | PUBSUB NUMPAT |
Streams(消息队列)
这个是Redis 5.0引入的持久化、可回溯、支持消费者组的消息流数据结构,解决了Pub/Sub和List的局限性。也就是我们常用的消息队列,我们把这个STream当作消息队列来理解就对了,这个就是redis发现pub/sub的短板后加入的一个数据类型,目的嘛就是为了抢消息队列的饭碗嘛。
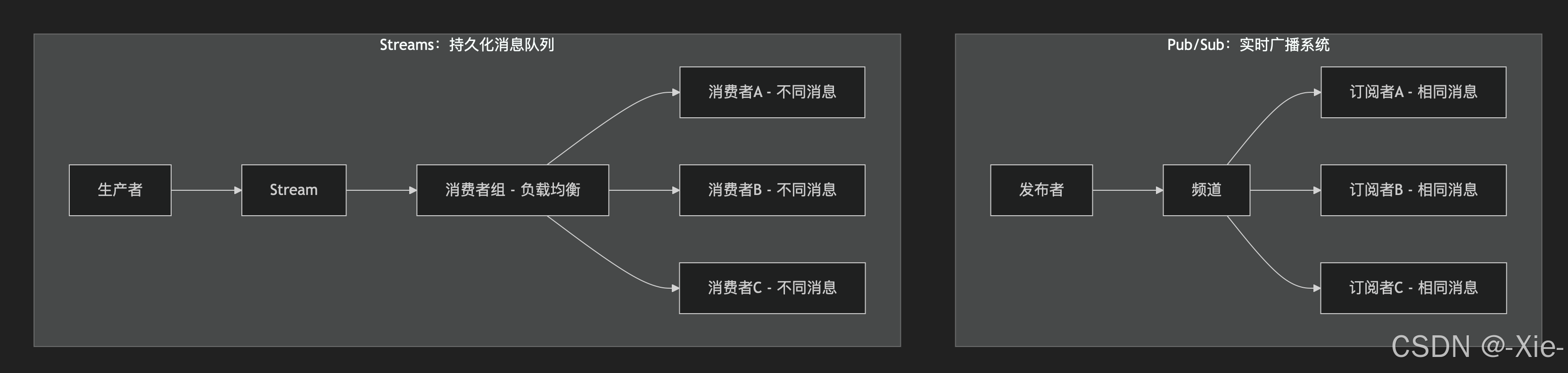
| 特性维度 | Pub/Sub(发布/订阅) | Streams(流) | 本质区别 |
|---|---|---|---|
| 数据持久化 | ❌ 消息不存储,实时推送 | ✅ 消息持久化在内存中 | Streams=有状态,Pub/Sub=无状态 |
| 消息模型 | 广播模式(一对多) | 队列模式(竞争消费) | 分发机制完全不同 |
| 消费者管理 | 简单的订阅列表 | 复杂的消费者组机制 | Streams支持负载均衡 |
| 消息回溯 | ❌ 无法重新获取历史消息 | ✅ 支持任意时间点重放 | Streams可"倒带" |
| 可靠性 | 最多一次(可能丢失) | 至少一次(可确认) | Streams更可靠 |
| 使用场景 | 实时通知、事件广播 | 任务队列、事件溯源 | 目标不同 |
这个是消费者命令:命令太多了还是老样子啊,大家想知道细节还是自己去查吧
| 命令 | 语法 | 作用 | 返回值 | 示例 | 使用场景 |
|---|---|---|---|---|---|
| XADD | XADD key ID field value [field value ...] |
添加消息到Stream | 消息ID | XADD mystream * name "John" age 30 |
消息生产者 |
| XADD (带限制) | XADD key MAXLEN [~] count ID field value ... |
添加消息并限制长度 | 消息ID | XADD mystream MAXLEN 1000 * data "msg" |
滚动窗口数据 |
| XADD (精确ID) | XADD key 1640995200000-0 field value |
使用指定ID添加 | 消息ID | XADD events 1640995200000-0 type "login" |
时间序列数据 |
Modules(模块)
Redis Modules 是Redis的可扩展架构 ,允许开发者通过C语言编写自定义数据类型和命令,扩展Redis的核心功能。主包认为这个就和java的中间件一样,可以开发者直接编写一个工具也可以从社区下载安装,所以这个类型不好细细说,大家明白他的大概意思就行,如果真要使用还是去看官方文档或者技术大牛吧。这个是一些官方的模块:
| Module | 内存使用 | CPU开销 | 适用数据量 | 优化建议 |
|---|---|---|---|---|
| RedisJSON | 中等 | 低 | 中小文档 | 避免超大JSON |
| RediSearch | 较高 | 中高 | 百万级文档 | 合理设计索引 |
| RedisGraph | 高 | 高 | 十万级节点 | 控制图复杂度 |
| RedisTimeSeries | 低 | 低 | 海量数据点 | 使用聚合规则 |
| RedisBloom | 极低 | 极低 | 无限数据 | 调整误差率 |
总结
下面我将为之前说过的几大数据类型进行总结,首先就是成员个数:基本上都是42亿个成员
| 数据类型 | 最大成员数 | 理论限制 | 实际限制 | 备注 |
|---|---|---|---|---|
| String(字符串) | 1个值 | 512MB | 系统内存 | 单个值最大512MB |
| Hash(哈希) | 2³²-1个字段 | 约42.9亿 | 系统内存 | 每个哈希最多40亿+字段 |
| List(列表) | 2³²-1个元素 | 约42.9亿 | 系统内存 | 每个列表最多40亿+元素 |
| Set(集合) | 2³²-1个成员 | 约42.9亿 | 系统内存 | 每个集合最多40亿+成员 |
| ZSet(有序集合) | 2³²-1个成员 | 约42.9亿 | 系统内存 | 每个有序集合最多40亿+成员 |
| Bitmaps(位图) | 2³²位 | 约42.9亿位 | 512MB | 最大偏移量2³²-1 |
| HyperLogLogs | 无限制 | 理论上无限 | 12KB固定 | 存储基数,非实际元素 |
| Geospatial(地理空间) | 2³²-1个成员 | 约42.9亿 | 系统内存 | 基于ZSet实现 |
| Pub/Sub(发布订阅) | 无限制 | 理论上无限 | 系统资源 | 频道和订阅者动态变化 |
| Streams(流) | 2⁶⁴个条目 | 天文数字 | 系统内存 | 每个流最多18.4亿亿条目 |
| Modules(模块) | 取决于模块 | 模块定义 | 系统内存 | 由具体模块决定 |
然后我再次添加的方法上进行区分:基本上都是add进行添加的。
| 数据类型 | 添加命令 | 批量支持 | 去重特性 | 典型场景 |
|---|---|---|---|---|
| String | SET, SETEX | MSET | 覆盖更新 | 缓存、会话 |
| Hash | HSET, HMSET | HMSET | 字段更新 | 对象存储 |
| Bitmaps | SETBIT | 单个位操作 | 位覆盖 | 标志位、签到 |
| List | LPUSH, RPUSH | 支持多元素 | 允许重复 | 队列、时间线 |
| Set | SADD | 支持多成员 | 自动去重 | 标签、关系 |
| ZSet | ZADD | 支持多成员 | 更新分数 | 排行榜、优先级 |
| HyperLogLogs | PFADD | 支持多元素 | 统计去重 | UV统计 |
| Geospatial | GEOADD | 支持多位置 | 更新坐标 | 地理位置 |
| Streams | XADD | 多字段条目 | ID唯一 | 事件流、日志 |
| Pub/Sub | PUBLISH | 单条消息 | 无存储 | 实时消息 |
好了数据类型就锁清楚了,我们下期来看其他东西。