此分类用于记录吴恩达深度学习课程的学习笔记。
课程相关信息链接如下:
- 原课程视频链接:双语字幕吴恩达深度学习deeplearning.ai
- github课程资料,含课件与笔记:吴恩达深度学习教学资料
- 课程配套练习(中英)与答案:吴恩达深度学习课后习题与答案
本篇为第二课第一周的课程习题和代码实践部分笔记。
1. 理论习题
【中英】【吴恩达课后测验】Course 2 - 改善深层神经网络 - 第一周测验
还是摆一下这位博主的链接,本周理论习题没什么难度,基本就是对理论内容的重复,因此就不再展开了。
我们把重点放在下面的代码实践部分。
2.代码实践
依旧先上链接:
吴恩达深度学习初始化与正则化
在这篇博客里,博主手动构建了几种初始化,正则化以及梯度检验的方法。
我依旧在这里给出更偏向现有框架的版本,应用本周了解到的新技术到我们从一开始就在使用的猫狗二分类数据集上 。
还是需要提前说明的是:在使用完善框架内置计算的前提下,进行梯度检验的意义不大,梯度检验本身也只是一个检验梯度计算是否出错的技术,在计算不出错的情况下不能直接帮助拟合 ,目前也几乎不再使用,就不在笔记里出现了。
我们重点展开一下权重初始化和正则化两部分。
2.1 权重初始化
我们在第一课第三周里介绍了初始化的概念,又在本周的最后一部分内容里介绍了科学的权重初始化的思想,现在看看它们的效果。
在第一课里,我们通过一层层丰富网络结构,让分类准确率从50%提升到了接近70%。实际上,在一开始,PyTorch框架就已经根据我们设置的层进行了相应的权重初始化。
我们之前设置Linear线性层,因此框架就自动进行了 He权重初始化。
先看一下我们上次更新的网络结构:
python
class NeuralNetwork(nn.Module):
def __init__(self):
super().__init__()
self.flatten = nn.Flatten()
# 隐藏层
self.hidden1 = nn.Linear(128 * 128 * 3, 5)
self.hidden2 = nn.Linear(5, 5)
self.hidden3 = nn.Linear(5, 3)
self.ReLU = nn.ReLU()
# 输出层
self.output = nn.Linear(3, 1)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
x = self.flatten(x)
x = self.hidden1(x)
x = self.ReLU(x)
x = self.hidden2(x)
x = self.ReLU(x)
x = self.hidden3(x)
x = self.ReLU(x)
x = self.output(x)
x = self.sigmoid(x)
return x实际上,权重初始化的逻辑被封装在了这几句里:
python
# PyTorch逻辑:对线性层自动进行 He 权重初始化
# He 权重初始化 也叫 Kaiming 初始化 只是一个是提出者的姓,一个是名,仅此而言。
self.hidden1 = nn.Linear(128 * 128 * 3, 5)
self.hidden2 = nn.Linear(5, 5)
self.hidden3 = nn.Linear(5, 3)
self.output = nn.Linear(3, 1) 也就是说,在PyTorch框架的构造方法里,我们每设置一个线性层,框架就会自动对其进行 He 初始化。
了解基础逻辑后,我们看几个需要展开的问题。
(1)为什么PyTorch框架的初始化针对层而不是激活函数?
回忆一下我们在上一篇里加粗的一句话:不同激活函数会改变信号统计特性,所以需要不同的初始化 。
也就是说,选择初始化方式的依据不应该是该层的激活函数吗?
再看一下我们总结的两类初始化:
| 初始化方法 | 核心思想 | 适用激活函数 | 公式 | 举例说明 |
|---|---|---|---|---|
| Xavier (Glorot) | 让输入输出方差一致 | Sigmoid / Tanh | \(Var(W)=\frac{1}{n_{in}+n_{out}}\) | 若一层输入神经元 100 个、输出 50 个: \(Var(W)=1/(150)=0.0067\) |
| He (Kaiming) | 针对 ReLU 激活的特性调整 | ReLU / Leaky ReLU | \(Var(W)=\frac{2}{n_{in}}\) | 输入 100 个神经元 → \(Var(W)=0.02\) |
结合我们的网络结构,会发现一个问题:我们的输出层实际上使用的也是He 初始化,可该层的激活函数是Sigmoid,不应该用Xavier 初始化才更合理吗?
那么,PyTorch作为目前最流行的成熟框架之一,为什么会出现这种纰漏?
其实这并不是框架的纰漏,而是设计方式不同导致的结果,我们先说原理。
(2)层和激活函数在初始化中的关系?
先说结论:初始化的推导主要基于"线性变换的输入输出方差",而不是激活函数本身。
也就是说,初始化天然与线性层更紧密相关,而非与激活函数绑定。
要理解这句话,我们先把初始化的核心目标讲清楚:
初始化的目的,是让信号在层与层之间不要越来越大,也不要越来越小。
而信号在层间传播,第一步永远是通过线性层,也就是一次矩阵乘法,这一步决定了信号的基础规模------也就是"方差是否在传播时保持稳定"。
大部分初始化方法都是从这一层面推导出来的:设定权重的范围,让线性层的输出不要突然变得特别大或特别小。
因此,初始化的数学起点是线性层的输入和输出的大小,而不是激活函数本身 。这是为什么 PyTorch 会把初始化绑定在线性层上:从框架角度看,这一步才是真正需要"方差控制"的核心点。
那与我们之前说的 "不同激活函数会改变信号统计特性,所以需要不同的初始化" 是不是矛盾?
其实并不矛盾,它们是两个层次的逻辑:
还是先说结论:因为激活函数对信号的"压缩方式"不同,所有理论上需要不同的初始化做"补偿"。
初始化需要让线性层输出稳定,是为了给下一步的激活创造良好条件,这一层面初始化和线性层的"输入/输出规模"更相关,框架默认以这一逻辑为主。
而在线性组合的基础上,不同激活函数会进一步改变信号:
- ReLU 会把一半输入砍成 0,使方差变小
- Sigmoid 会把大输入"压平",让梯度变小
- Tanh 会把两端推向 -1 或 1,也会让梯度变小
也就是说:激活函数会改变方差信号的处理方式,所以理论上需要不同的初始化去匹配它。
例如: - ReLU 会让方差减少,所以 He 初始化会把权重再放大一点
- Sigmoid 会压扁两端,所以 Xavier 初始化让权重相对小一些
但这一步是在线性变换之后发生的,是"第二层逻辑"。
总结一下:所有初始化都是先为了线性部分服务,再衍生出适配激活函数的特化版本。
打个比方:
做一道菜时,首先要把基本味道调对,基本味道就相当于线性层的方差稳定,它是菜好不好吃的核心。
然后才根据不同的食材------如辣的、甜的、酸的, 再做额外调味,让整道菜平衡好吃,这些额外调味就相当于针对激活函数的特化,让菜更好吃。

(3)PyTorch的设计逻辑?
首先这句 "不同激活函数会改变信号统计特性,所以需要不同的初始化" 是正确的。
理论上确实应该:
- ReLU 类激活配 He 初始化
- Sigmoid / Tanh 配 Xavier 初始化
但 PyTorch 的默认行为并不会根据激活函数自动切换初始化,其原因主要有三点:
- 框架在创建 Linear 层时,并不知道你之后会接什么激活函数。
激活函数是在 forward 里使用的,可能随时更换,也可能不用,因此无法在层创建时提前决定正确的初始化方式。 - 初始化的推导主要基于"线性变换的输入输出方差",而不是激活函数本身。
初始化天然与线性层更紧密相关,而非与激活函数绑定。 - PyTorch 选择了一个在大多数情况下都安全、稳妥的默认方案。
默认提供偏向 ReLU 的 Kaiming(He)初始化,使大部分网络都能正常训练。如果用户需要严格匹配某个激活函数,再手动覆盖即可。
总的来说,我们的输出层虽然接了 Sigmoid,PyTorch 仍然使用了 He 初始化------框架并不是做错了,而是在不知道具体情况下给出了一个"通用但不一定最优"的默认值。
(4)人工完善特化逻辑
了解完原因,我们就可以完善逻辑了,我们修改输出层的权重初始化方法为Xavier 初始化,代码如下:
python
class NeuralNetwork(nn.Module):
def __init__(self):
super().__init__()
self.flatten = nn.Flatten()
self.hidden1 = nn.Linear(128 * 128 * 3, 5)
self.hidden2 = nn.Linear(5, 5)
self.hidden3 = nn.Linear(5, 3)
self.ReLU = nn.ReLU()
self.output = nn.Linear(3, 1)
self.sigmoid = nn.Sigmoid()
# 对输出层进行Xavier初始化
init.xavier_uniform_(self.output.weight)
def forward(self, x):
x = self.flatten(x)
x = self.hidden1(x)
x = self.ReLU(x)
x = self.hidden2(x)
x = self.ReLU(x)
x = self.hidden3(x)
x = self.ReLU(x)
x = self.output(x)
x = self.sigmoid(x)
return x(5)和随机初始化对比效果
现在我们已经有了权重初始化合理的网络,现在再给出一版完全使用随机初始化的版本,我们实际运行一下,看看二者的差距。
随机初始化的模型代码如下:
python
class NeuralNetwork(nn.Module):
def __init__(self):
super().__init__()
self.flatten = nn.Flatten()
self.hidden1 = nn.Linear(128 * 128 * 3, 5)
self.hidden2 = nn.Linear(5, 5)
self.hidden3 = nn.Linear(5, 3)
self.output = nn.Linear(3, 1)
self.ReLU = nn.ReLU()
self.sigmoid = nn.Sigmoid()
# 对每一层权重进行随机初始化
for layer in [self.hidden1, self.hidden2, self.hidden3, self.output]:
init.uniform_(layer.weight, a=-0.1, b=0.1) # (-1,1)间随机初始化
def forward(self, x):
x = self.flatten(x)
x = self.hidden1(x)
x = self.ReLU(x)
x = self.hidden2(x)
x = self.ReLU(x)
x = self.hidden3(x)
x = self.ReLU(x)
x = self.output(x)
x = self.sigmoid(x)
return x对比部分的完整代码依旧放在文末,我们来看看一下结果:
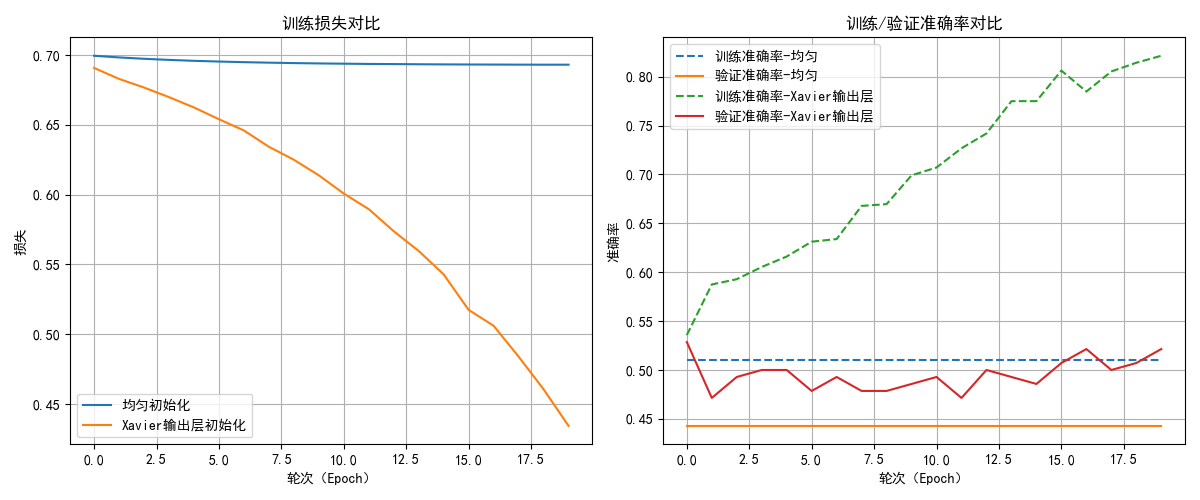
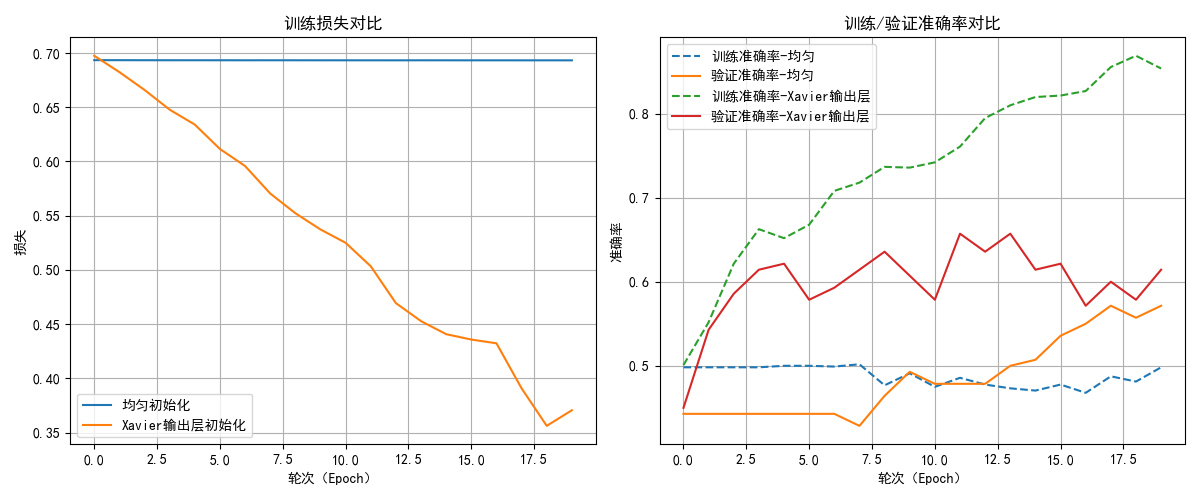
以20轮测试,我选取了其中两次的测试结果,我们来分析一下结果:
- 对于损失,随机初始化几乎次次都出现了梯度消失的现象,导致损失下降缓慢。
而合适的初始化则在稳定地进行收敛。 - 第一次的随机初始化中的梯度消失导致模型几乎无法学到任何规律,只是在胡乱猜测,导致了训练和测试的准确率不佳,有时甚至降到了50%以下,这代表模型没有任何实用价值,即使有所起伏,其上限也不高,这就相当于"一开始走错了路,在一条弯路上走到底。"
- 合适的初始化则在准确率的表现上更好一些,如果加大轮次,甚至出现了过拟合现象,这代表其确实在学习图像的规律。
总结一下,随机初始化导致梯度消失和训练不稳定,使模型难以学习有效特征,而合适的初始化能够保证梯度稳定,加速收敛,是深度神经网络训练中不可或缺的一步。
2.2 正则化
(1)构建一个可能出现过拟合的深层神经网络
在本周理论第二部分的笔记里,我们知道正则化的出现是为了缓解复杂网络对的数据过拟合问题。
因此,为了更合理的使用正则化,我们首先应构建一个可能出现过拟合的深层神经网络。
提前强调一个地方,在理论学习中,课程为了帮助我们更好地理解,基本使用的都是三个或者五个这样较少的特征数。
而我们一开始选择的数据集是图片。
对于一幅彩色图像而言,每个像素由三个通道值(R、G、B)共同表示。
因此,一幅彩色图像的特征数为:像素点个数 * 通道数。
我们继续使用进行合适初始化后的网络结构,
其实,其中有一个很不合理的层级设计,就在这里:
python
self.hidden1 = nn.Linear(128 * 128 * 3, 5) 我们把一个接近 50,000 维的输入,一下子压缩成 5 维。
这在深度学习里非常不合理,相当于:
输入图片(49152 个数字)=一本 4.9 万字的长篇小说
第一层输出只有 5 维 = 只允许你写 5 个字来总结它

(感觉GPT是在用画画的方式写中文)
其实,在实际使用中我们很少用全连接网络去学习图片,我们后面再提。
总之,这种压缩过于激进,相当于极端的信息损毁,这会让模型基本无法学到有效的图像特征。
那为什么还能有65%的准确率?
因为即使把图像极端压缩成 5 维,网络仍能从这 5 个自动学习的统计特征中抓住背景偏差、形状差异、亮度模式等低级线索,从而得到 60%~70% 的准确率。
并不是因为这个结构合理,而是:任务容易、数据有偏差、压缩层仍可学习、类别天然可分、神经网络具有强大的非线性能力。
总结一下:现在的准确率主要靠网络本身的"泛化能力 + 非线性能力"撑起来,而网络结构在拖后腿。
(2)修改网络结构实现对训练集的过拟合
按照刚刚的逻辑,现在,我们更新网络结构如下:
python
class NeuralNetwork(nn.Module):
def __init__(self):
super().__init__()
self.flatten = nn.Flatten()
self.hidden1 = nn.Linear(128 * 128 * 3, 1024)
self.hidden2 = nn.Linear(1024, 512)
self.hidden3 = nn.Linear(512, 128)
self.hidden4 = nn.Linear(128, 32)
self.hidden5 = nn.Linear(32, 8)
self.hidden6 = nn.Linear(8, 3)
self.relu = nn.ReLU()
# 输出层
self.output = nn.Linear(3, 1)
self.sigmoid = nn.Sigmoid()
init.xavier_uniform_(self.output.weight)
def forward(self, x):
x = self.flatten(x)
x = self.relu(self.hidden1(x))
x = self.relu(self.hidden2(x))
x = self.relu(self.hidden3(x))
x = self.relu(self.hidden4(x))
x = self.relu(self.hidden5(x))
x = self.relu(self.hidden6(x))
x = self.sigmoid(self.output(x))
return x你也可以试试构建更深层次,神经元下降更平缓的网络,但我并不建议在本次实践中这么做。
一来,你的硬件可能带不动更复杂的网络结构,会报内存不足,无法训练(资源足够可以忽略)。
二来,针对猫狗二分类任务,我们不会继续在全连接的网络复杂度上下功夫了,在图像的学习上,我们后面学习的卷积网络的性能对现在的全连接网络简直就是降维打击。
现在我们看看训练结果:

经过50轮的训练(之后会学到的学习率优化算法会更快达到这一结果,现在还是用笨方法)后,我们可以看到,模型的损失极小 ,且在训练集上的准确率已经近乎100% 了,可验证集的准确率还是在65%~70%波动 ,这时候,我们就可以说,模型已经过拟合了。
现在我们已经有了前提条件了,来试试正则化的效果吧。
(3)应用L2正则化
在Pytorch框架里,L2正则化被封装在了优化器模块里。
我们看看之前这部分的代码:
python
optimizer = optim.SGD(model.parameters(), lr=0.01)
# 使用随机梯度下降法(Stochastic Gradient Descent,SGD)反向传播,学习率为0.01
# 你也可以自己调试一下其他学习率,看看效果。现在,要使用L2正则化,只需要增加一个参数:
python
optimizer = optim.SGD(model.parameters(), lr=0.01,weight_decay=0.001)
# weight_decay=0.001 正则化参数设置为0.001不改变其他任何内容,来看看结果:

可以看到,相比之前近乎100%的准确率,现在的训练准确了只达到了85%左右,虽然测试的准确率变化不大,但确实缓解了过拟合情况。
那如果增大正则化参数,会不会更好一点? 我们试试:
python
optimizer = optim.SGD(model.parameters(), lr=0.01,weight_decay=0.01)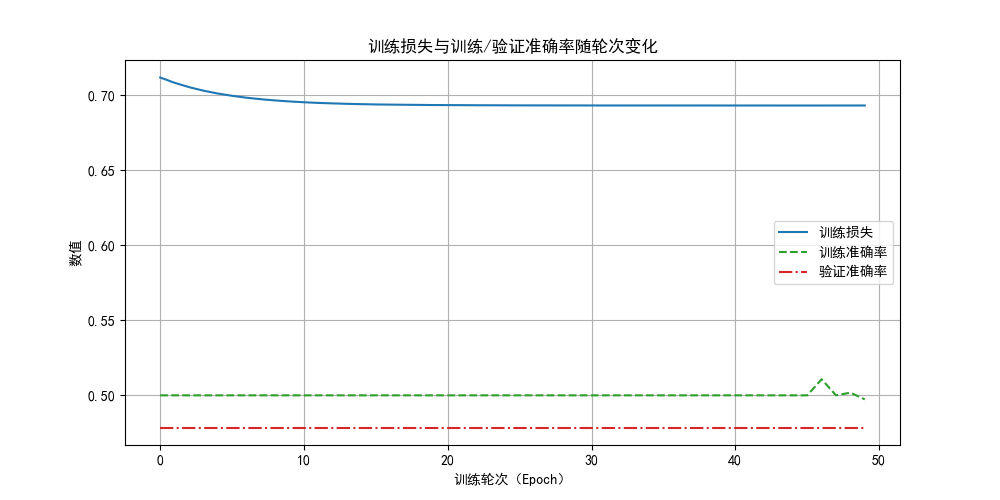
看看结果,确实没有过拟合情况了,因为现在欠拟合了。
强调一下,从本质上讲,L2 正则化是在"限制模型的学习能力" 。
因此,正则化参数作为又一个超参数,也需要我们一点点调试,让其更适合我们的任务。
(4)应用dropout正则化
在Pytorch框架里,dropout正则化不同L2正则化,它被封装在了网络结构模块里。
来看看增加了dropout模块后的模型结构:
python
class NeuralNetwork(nn.Module):
def __init__(self):
super().__init__()
self.flatten = nn.Flatten()
self.hidden1 = nn.Linear(128 * 128 * 3, 1024)
self.hidden2 = nn.Linear(1024, 512)
self.hidden3 = nn.Linear(512, 128)
self.hidden4 = nn.Linear(128, 32)
self.hidden5 = nn.Linear(32, 8)
self.hidden6 = nn.Linear(8, 3)
self.relu = nn.ReLU()
# Dropout 层
self.dropout = nn.Dropout(p=0.5) # p:丢弃概率
self.output = nn.Linear(3, 1)
self.sigmoid = nn.Sigmoid()
init.xavier_uniform_(self.output.weight)
def forward(self, x):
x = self.flatten(x)
x = self.relu(self.hidden1(x))
x = self.dropout(x) # Dropout
x = self.relu(self.hidden2(x))
x = self.dropout(x) # Dropout
x = self.relu(self.hidden3(x))
x = self.dropout(x) # Dropout
x = self.relu(self.hidden4(x))
x = self.dropout(x) # Dropout
x = self.relu(self.hidden5(x))
x = self.dropout(x) # Dropout
x = self.relu(self.hidden6(x))
x = self.dropout(x) # Dropout
x = self.sigmoid(self.output(x))
return x
optimizer = optim.SGD(model.parameters(), lr=0.01)这样,我们就可以通过调整 P 来进行dropout正则化,来看看效果如何:
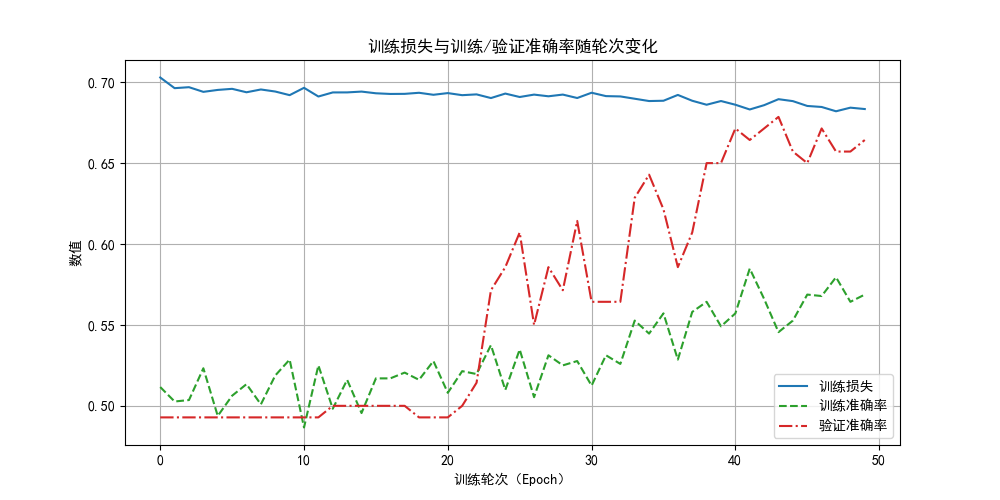
相比L2,dropout正则化有一些比较明显的区别,但也同样缓解了过拟合问题:
- 损失下降缓慢:这是因为每次迭代丢失了神经元,增加了随机性,让反向传播的效果没有那么明显。
- 验证准确率高于训练准确率:这是因为在验证时我们使用的是完整网络,而训练时只用其中一部分。
值得一提的是,由于dropout正则化随机丢弃神经元的特性,往往需要更多的训练轮次,大家可以自行尝试看看效果,本篇内容就到此为止了。
在应用了新技术后,我们发现,虽然缓解了过拟合现象,可好像还是没有提高验证准确率,到底如何才能到底一个可实用的猫狗分类器呢?我们继续学习就会得到答案。
3.附录
3.1权重初始化部分完整代码:
python
import torch
import torch.nn as nn
import torch.optim as optim
from torch.nn import init
from torchvision import datasets, transforms
from torch.utils.data import DataLoader, random_split
import matplotlib.pyplot as plt
transform = transforms.Compose([
transforms.Resize((128, 128)),
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))
])
dataset = datasets.ImageFolder(root='./cat_dog', transform=transform)
train_size = int(0.8 * len(dataset))
val_size = int(0.1 * len(dataset))
test_size = len(dataset) - train_size - val_size
train_dataset, val_dataset, test_dataset = random_split(dataset, [train_size, val_size, test_size])
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=32, shuffle=False)
test_loader = DataLoader(test_dataset, batch_size=32, shuffle=False)
class NeuralNetwork(nn.Module):
def __init__(self, init_type='uniform'):
super().__init__()
self.flatten = nn.Flatten()
self.hidden1 = nn.Linear(128*128*3, 5)
self.hidden2 = nn.Linear(5, 5)
self.hidden3 = nn.Linear(5, 3)
self.ReLU = nn.ReLU()
self.output = nn.Linear(3, 1)
self.sigmoid = nn.Sigmoid()
# 初始化
if init_type == 'uniform':
for layer in [self.hidden1, self.hidden2, self.hidden3, self.output]:
init.uniform_(layer.weight, a=-0.1, b=0.1)
elif init_type == 'xavier_output':
init.xavier_uniform_(self.output.weight)
def forward(self, x):
x = self.flatten(x)
x = self.ReLU(self.hidden1(x))
x = self.ReLU(self.hidden2(x))
x = self.ReLU(self.hidden3(x))
x = self.sigmoid(self.output(x))
return x
def train_model(model, epochs=20):
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
criterion = nn.BCELoss()
optimizer = optim.SGD(model.parameters(), lr=0.01)
train_losses = []
train_accuracies = []
val_accuracies = []
for epoch in range(epochs):
model.train()
epoch_train_loss = 0
correct_train = 0
total_train = 0
for images, labels in train_loader:
images, labels = images.to(device), labels.to(device).float().unsqueeze(1)
outputs = model(images)
loss = criterion(outputs, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
epoch_train_loss += loss.item()
preds = (outputs > 0.5).int()
correct_train += (preds == labels.int()).sum().item()
total_train += labels.size(0)
avg_train_loss = epoch_train_loss / len(train_loader)
train_acc = correct_train / total_train
# 验证
model.eval()
correct_val = 0
total_val = 0
with torch.no_grad():
for images, labels in val_loader:
images, labels = images.to(device), labels.to(device).float().unsqueeze(1)
outputs = model(images)
preds = (outputs > 0.5).int()
correct_val += (preds == labels.int()).sum().item()
total_val += labels.size(0)
val_acc = correct_val / total_val
train_losses.append(avg_train_loss)
train_accuracies.append(train_acc)
val_accuracies.append(val_acc)
return train_losses, train_accuracies, val_accuracies
model_uniform = NeuralNetwork(init_type='uniform')
model_xavier = NeuralNetwork(init_type='xavier_output')
loss_uniform, train_acc_uniform, val_acc_uniform = train_model(model_uniform)
loss_xavier, train_acc_xavier, val_acc_xavier = train_model(model_xavier)
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.figure(figsize=(12,5))
plt.subplot(1,2,1)
plt.plot(loss_uniform, label='均匀初始化')
plt.plot(loss_xavier, label='Xavier输出层初始化')
plt.title("训练损失对比")
plt.xlabel("轮次(Epoch)")
plt.ylabel("损失")
plt.legend()
plt.grid(True)
plt.subplot(1,2,2)
plt.plot(train_acc_uniform, '--', label='训练准确率-均匀')
plt.plot(val_acc_uniform, '-', label='验证准确率-均匀')
plt.plot(train_acc_xavier, '--', label='训练准确率-Xavier输出层')
plt.plot(val_acc_xavier, '-', label='验证准确率-Xavier输出层')
plt.title("训练/验证准确率对比")
plt.xlabel("轮次(Epoch)")
plt.ylabel("准确率")
plt.legend()
plt.grid(True)
plt.tight_layout()
plt.show()3.2 L2正则化部分完整代码:
python
import torch
import torch.nn as nn
import torch.optim as optim
from torch.nn import init
from torchvision import datasets, transforms
from torch.utils.data import DataLoader, random_split
import matplotlib.pyplot as plt
transform = transforms.Compose([
transforms.Resize((128, 128)),
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))
])
dataset = datasets.ImageFolder(root='./cat_dog', transform=transform)
train_size = int(0.8 * len(dataset))
val_size = int(0.1 * len(dataset))
test_size = len(dataset) - train_size - val_size
train_dataset, val_dataset, test_dataset = random_split(dataset, [train_size, val_size, test_size])
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=32, shuffle=False)
test_loader = DataLoader(test_dataset, batch_size=32, shuffle=False)
class NeuralNetwork(nn.Module):
def __init__(self):
super().__init__()
self.flatten = nn.Flatten()
self.hidden1 = nn.Linear(128 * 128 * 3, 1024)
self.hidden2 = nn.Linear(1024, 512)
self.hidden3 = nn.Linear(512, 128)
self.hidden4 = nn.Linear(128, 32)
self.hidden5 = nn.Linear(32, 8)
self.hidden6 = nn.Linear(8, 3)
self.relu = nn.ReLU()
# 输出层
self.output = nn.Linear(3, 1)
self.sigmoid = nn.Sigmoid()
# Xavier初始化输出层
init.xavier_uniform_(self.output.weight)
def forward(self, x):
x = self.flatten(x)
x = self.relu(self.hidden1(x))
x = self.relu(self.hidden2(x))
x = self.relu(self.hidden3(x))
x = self.relu(self.hidden4(x))
x = self.relu(self.hidden5(x))
x = self.relu(self.hidden6(x))
x = self.sigmoid(self.output(x))
return x
model = NeuralNetwork()
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
criterion = nn.BCELoss()
optimizer = optim.SGD(model.parameters(), lr=0.01,weight_decay=0.001)
epochs = 50
train_losses = []
train_accs = []
val_accuracies = []
for epoch in range(epochs):
model.train()
epoch_train_loss = 0
correct_train = 0
total_train = 0
for images, labels in train_loader:
images, labels = images.to(device), labels.to(device).float().unsqueeze(1)
outputs = model(images)
loss = criterion(outputs, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
epoch_train_loss += loss.item()
preds = (outputs > 0.5).int()
correct_train += (preds == labels.int()).sum().item()
total_train += labels.size(0)
avg_train_loss = epoch_train_loss / len(train_loader)
train_acc = correct_train / total_train
train_losses.append(avg_train_loss)
train_accs.append(train_acc)
# 验证
model.eval()
correct_val = 0
total_val = 0
with torch.no_grad():
for images, labels in val_loader:
images, labels = images.to(device), labels.to(device).float().unsqueeze(1)
outputs = model(images)
preds = (outputs > 0.5).int()
correct_val += (preds == labels.int()).sum().item()
total_val += labels.size(0)
val_acc = correct_val / total_val
val_accuracies.append(val_acc)
print(f"轮次: [{epoch + 1}/{epochs}], "
f"训练损失: {avg_train_loss:.4f}, "
f"训练准确率: {train_acc:.4f}, "
f"验证准确率: {val_acc:.4f}")
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.figure(figsize=(10,5))
plt.plot(train_losses, label='训练损失', color='tab:blue', linestyle='-')
plt.plot(train_accs, label='训练准确率', color='tab:green', linestyle='--')
plt.plot(val_accuracies, label='验证准确率', color='tab:red', linestyle='-.')
plt.title("训练损失与训练/验证准确率随轮次变化")
plt.xlabel("训练轮次(Epoch)")
plt.ylabel("数值")
plt.legend()
plt.grid(True)
plt.show()
# 最终测试,可省略
model.eval()
correct = 0
total = 0
with torch.no_grad():
for images, labels in test_loader:
images, labels = images.to(device), labels.to(device).float().unsqueeze(1)
outputs = model(images)
preds = (outputs > 0.5).int()
correct += (preds == labels.int()).sum().item()
total += labels.size(0)
test_acc = correct / total
print(f"测试准确率: {test_acc:.4f}")3.3 dropout正则化部分完整代码:
python
import torch
import torch.nn as nn
import torch.optim as optim
from torch.nn import init
from torchvision import datasets, transforms
from torch.utils.data import DataLoader, random_split
import matplotlib.pyplot as plt
transform = transforms.Compose([
transforms.Resize((128, 128)),
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))
])
dataset = datasets.ImageFolder(root='./cat_dog', transform=transform)
train_size = int(0.8 * len(dataset))
val_size = int(0.1 * len(dataset))
test_size = len(dataset) - train_size - val_size
train_dataset, val_dataset, test_dataset = random_split(dataset, [train_size, val_size, test_size])
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=32, shuffle=False)
test_loader = DataLoader(test_dataset, batch_size=32, shuffle=False)
class NeuralNetwork(nn.Module):
def __init__(self):
super().__init__()
self.flatten = nn.Flatten()
self.hidden1 = nn.Linear(128 * 128 * 3, 1024)
self.hidden2 = nn.Linear(1024, 512)
self.hidden3 = nn.Linear(512, 128)
self.hidden4 = nn.Linear(128, 32)
self.hidden5 = nn.Linear(32, 8)
self.hidden6 = nn.Linear(8, 3)
self.relu = nn.ReLU()
# Dropout 层
self.dropout = nn.Dropout(p=0.4)
self.output = nn.Linear(3, 1)
self.sigmoid = nn.Sigmoid()
init.xavier_uniform_(self.output.weight)
def forward(self, x):
x = self.flatten(x)
x = self.relu(self.hidden1(x))
x = self.dropout(x)
x = self.relu(self.hidden2(x))
x = self.dropout(x)
x = self.relu(self.hidden3(x))
x = self.dropout(x)
x = self.relu(self.hidden4(x))
x = self.dropout(x)
x = self.relu(self.hidden5(x))
x = self.dropout(x)
x = self.relu(self.hidden6(x))
x = self.dropout(x)
x = self.sigmoid(self.output(x))
return x
model = NeuralNetwork()
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
criterion = nn.BCELoss()
optimizer = optim.SGD(model.parameters(), lr=0.01)
epochs = 50
train_losses = []
train_accs = []
val_accuracies = []
for epoch in range(epochs):
model.train()
epoch_train_loss = 0
correct_train = 0
total_train = 0
for images, labels in train_loader:
images, labels = images.to(device), labels.to(device).float().unsqueeze(1)
outputs = model(images)
loss = criterion(outputs, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
epoch_train_loss += loss.item()
preds = (outputs > 0.5).int()
correct_train += (preds == labels.int()).sum().item()
total_train += labels.size(0)
avg_train_loss = epoch_train_loss / len(train_loader)
train_acc = correct_train / total_train
train_losses.append(avg_train_loss)
train_accs.append(train_acc)
# 验证
model.eval()
correct_val = 0
total_val = 0
with torch.no_grad():
for images, labels in val_loader:
images, labels = images.to(device), labels.to(device).float().unsqueeze(1)
outputs = model(images)
preds = (outputs > 0.5).int()
correct_val += (preds == labels.int()).sum().item()
total_val += labels.size(0)
val_acc = correct_val / total_val
val_accuracies.append(val_acc)
print(f"轮次: [{epoch + 1}/{epochs}], "
f"训练损失: {avg_train_loss:.4f}, "
f"训练准确率: {train_acc:.4f}, "
f"验证准确率: {val_acc:.4f}")
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.figure(figsize=(10,5))
plt.plot(train_losses, label='训练损失', color='tab:blue', linestyle='-')
plt.plot(train_accs, label='训练准确率', color='tab:green', linestyle='--')
plt.plot(val_accuracies, label='验证准确率', color='tab:red', linestyle='-.')
plt.title("训练损失与训练/验证准确率随轮次变化")
plt.xlabel("训练轮次(Epoch)")
plt.ylabel("数值")
plt.legend()
plt.grid(True)
plt.show()
#最终测试,可省略
model.eval()
correct = 0
total = 0
with torch.no_grad():
for images, labels in test_loader:
images, labels = images.to(device), labels.to(device).float().unsqueeze(1)
outputs = model(images)
preds = (outputs > 0.5).int()
correct += (preds == labels.int()).sum().item()
total += labels.size(0)
test_acc = correct / total
print(f"测试准确率: {test_acc:.4f}")