在这个项目使用 RAG、LangChain、FastAPI 和 Streamlit 构建 Text-to-SQL 聊天机器人中,我构建了一个由 AI 驱动的聊天机器人,它将自然语言问题转换为 SQL 查询,并直接从真实的 SQLite 数据库中检索答案。借助 LangChain、Hugging Face 向量嵌入以及 Chroma 向量库,这个应用演示了如何通过检索增强生成(RAG)工作流把非结构化的用户输入连接到结构化数据------并配套 FastAPI 后端与 Streamlit 前端界面。
1 引言:为什么是 Text-to-SQL?
设想一下:
你正在会议上,经理突然问:
"我们能看看上个月加入的所有客户吗?"
你看了一眼 SQL 编辑器......意识到你得手写一个查询、检查表名,甚至可能还要调试一个缺失的 JOIN。与此同时,另外一个人只是对着 AI 聊天机器人提了同样的问题------并立刻拿到了整齐格式化的结果。
这就是 Text-to-SQL 的魔力------把自然语言转换成数据库查询。
1.1 问题所在
SQL(结构化查询语言)是数据分析与数据工程的基石。它强大、灵活且精准------但并不是对所有人都"友好"。
很多业务用户、分析师、甚至一些开发者都觉得 SQL 语法令人望而生畏,或者在快速获取洞察时效率不高。
在大多数团队里,这会形成一个鸿沟:
- 数据是可用的,但不容易"被提问"。
- 洞察是存在的,但被 SQL 专业技能所"锁住"。
1.2 解决方案:Text-to-SQL
Text-to-SQL 通过桥接这道鸿沟来解决问题。
它允许任何人------无论是否具备技术背景------提出像:
"上一季度我们卖得最好的 5 个产品是什么?"
这样的自然语言问题,并直接从你的数据库里得到答案,AI 会在幕后完成所有翻译工作。
在幕后,Text-to-SQL 系统通常做这四件事:
- 检索相关的模式与上下文(知道有哪些表存在)。
- 从自然语言问题生成一个有效的 SQL 查询。
- 安全地验证并在数据库上执行该 SQL。
- 以人类友好的格式返回结果。
2 理解 RAG 方法
到目前为止,我们已经看到 Text-to-SQL 如何让用户提出自然问题并拿到数据库结果------但 AI 实际上是如何知道你的表、列与关系的呢?
答案在一种叫做 RAG(Retrieval-Augmented Generation,检索增强生成) 的技术里。
2.1 什么是 RAG?
从本质上看,RAG 是一种将检索 与生成结合的混合式 AI 方法:
- 检索------系统提取相关信息(在本案例中是数据库模式、表名与关系)。
- 生成------LLM 使用检索到的上下文来生成准确且有据可依的输出(即 SQL 查询)。
你可以把 RAG 想象成给你的 LLM 一张"备忘单"------它在开始写 SQL 之前需要看到的精确模式信息。
2.1.1 为什么不直接用一个普通的 LLM?
如果你直接问一个大型语言模型(LLM)比如 GPT 或 Claude:
"展示上个月加入的所有客户"
它可能会生成类似这样的 SQL:
sql
SELECT * FROM users WHERE signup_date >= '2025-09-01'看起来没问题------直到你意识到你的实际数据库里并没有叫 users 的表。也许真实的表是 customer_data 或 crm_clients。
问题在于:当缺乏上下文时,LLM 会产生幻觉(hallucinate)。
它会猜测表名、遗漏 JOIN 关系,或使用错误的列名------因为默认情况下,它并不了解你的数据库模式。
2.1.2 RAG 如何解决这个问题
RAG 通过把模型扎根在"真实、已检索的知识"中来修复幻觉。
在一个 Text-to-SQL 的 RAG 循环里会发生什么:
- 检索模式上下文
系统会从一个向量数据库或内存索引中搜索你的模式(表名、列描述、关系)。 - 生成 SQL
LLM 把你的自然语言问题和已检索到的模式一起作为输入,生成一个有效的 SQL 查询。 - 执行并返回结果
查询被验证、在真实数据库上运行,并把结果返回给用户。
这确保每个 SQL 查询都由具备模式意识的推理支撑,而不是模型的"猜测"。
2.1.3 RAG 循环的实际运行
一个简化的流程图如下:
[用户问题]
↓
[检索模式信息]
↓
[生成 SQL(LLM)]
↓
[验证 + 执行]
↓
[返回结果]
↺每个循环都确保模型在生成查询之前拥有最新 且准确的模式知识------减少幻觉并提升可靠性。
2.2 系统架构
理解了 Text-to-SQL 为什么依赖 RAG(检索增强生成) 方法后,让我们看看它的底层结构。
为了更具体,设想你正在构建一个聊天机器人,它可以回答关于公司客户数据库的自然语言问题------从"上个月谁加入了?"到"本季度我们的平均订单金额是多少?"。
下面是系统的整体架构 👇
1. SQLite 数据库------结构化数据源
每一个 Text-to-SQL 系统都从数据源开始。
为了简化,我们使用 SQLite------一种轻量级、文件型数据库,非常适合原型开发与测试。
数据就真实地存放在这里:比如 customers、orders 与 products 等表。
当用户提问时,我们的目标是将这个问题转换成一个有效的 SQL 查询并在这个数据库上执行。
2. 嵌入层------把模式转换为向量
在模型生成 SQL 之前,它需要"理解"数据库结构------表名、列名以及它们的含义。
我们使用**向量嵌入(embeddings)**来实现这一点:它是对文本的数值表示,可以捕捉语义。
借助 Hugging Face Embeddings (比如 all-MiniLM-L6-v2),我们把模式元数据转换为向量:
python
# 函数:为每一行生成唯一哈希(用于增量与重复检测)
def row_hash(values):
"""为一行生成唯一哈希值。"""
import hashlib
return hashlib.sha256("|".join(map(str, values)).encode()).hexdigest()
# 函数:将 SQLite 的一行转换为可读的文本块(便于嵌入)
def row_to_text(table, cols, row):
"""把 SQLite 行记录转为可读的文本块。"""
return f"Table: {table}\n" + "\n".join([f"{c}: {v}" for c, v in zip(cols, row)])
# 函数:将单个表写入向量库
def index_table(conn, table):
"""把一个表索引进向量库(Chroma)。"""
import sqlite3
from langchain_community.vectorstores import Chroma
from langchain_community.embeddings.huggingface import HuggingFaceEmbeddings
cur = conn.cursor()
cur.execute(f"PRAGMA table_info({table});")
cols = [c[1] for c in cur.fetchall()]
cur.execute(f"SELECT {', '.join(cols)} FROM {table}")
rows = cur.fetchall()
embeddings = HuggingFaceEmbeddings(model_name="sentence-transformers/all-MiniLM-L6-v2")
vectorstore = Chroma(collection_name="sqlite_docs", persist_directory="./chroma_persist", embedding_function=embeddings)
docs, ids, metas = [], [], []
for r in rows:
txt = row_to_text(table, cols, r)
pk = str(r[0])
hid = row_hash(r)
ids.append(f"{table}:{pk}")
docs.append(txt)
metas.append({"table": table, "pk": pk, "hash": hid})
vectorstore.add_texts(texts=docs, metadatas=metas, ids=ids)
# 函数:主索引流程
def main():
"""主索引流程:遍历所有业务表并写入向量库。"""
import os, sqlite3
from tqdm import tqdm
SQLITE_PATH = os.getenv("SQLITE_PATH", "sample_db/sample.db")
conn = sqlite3.connect(SQLITE_PATH)
cur = conn.cursor()
cur.execute("SELECT name FROM sqlite_master WHERE type='table' AND name NOT LIKE 'sqlite_%'")
tables = [t[0] for t in cur.fetchall()]
for t in tqdm(tables, desc="Indexing tables"):
index_table(conn, t)
conn.close()
print("索引完成,并持久化到 Chroma。")
if __name__ == "__main__":
main()现在,每个表与列都被表示为高维空间中的向量------后续可以实现智能检索。
3. 向量库(Chroma)------检索相关模式
接下来,我们把这些嵌入存入向量数据库 ------本例使用 Chroma。
当用户提出问题时,我们会:
- 在同一向量空间中嵌入这个问题。
- 在 Chroma 中搜索最接近的模式元素。
例如,用户问"最近注册的用户有哪些?"时,检索器可能会拉取到像 customers.signup_date 与 customers.name 这样的模式项。
这确保模型只看到相关的模式上下文------让 SQL 生成扎根于现实。
4. LangChain 组件------系统的"大脑"
LangChain 把一切串联起来。
它提供了检索、推理与 SQL 生成的模块化组件:
- 检索器:从 Chroma 拉取相关模式块。
- 链:定义步骤序列------检索 → 生成 → 验证 → 执行。
- LLM:在用户问题与检索上下文的条件下生成 SQL。
示例片段:
python
# 函数:异步检索节点(RAG 的检索阶段)
async def retriever_node(state):
"""根据用户问题从向量库检索相关模式与数据片段。"""
docs = await state["retriever"].ainvoke(state["question"])
state["retrieved_docs"] = [d.page_content for d in docs]
return state
# 函数:SQL 生成节点(清洗输出,仅保留 SELECT)
async def sql_generator_node(state):
"""从检索到的上下文与用户问题生成只读的 SQLite SELECT 语句。"""
import re
sql_prompt = state["sql_prompt"]
llm = state["llm"]
context = "\n\n".join(state.get("retrieved_docs", []))
prompt_text = sql_prompt.format(context=context, question=state["question"])
out = await llm.ainvoke(prompt_text)
if hasattr(out, "content"):
out = out.content
out = str(out).strip()
# 移除 Markdown 代码围栏与多余内容
out = re.sub(r"```(?:sql)?\n?", "", out, flags=re.IGNORECASE).replace("```", "").strip()
# 仅提取 SELECT 开头的语句
match = re.search(r"(select\b.*)", out, flags=re.IGNORECASE | re.DOTALL)
if match:
out = match.group(1).strip()
else:
out = ""
# 去掉末尾分号
out = out.rstrip(";").strip()
state["generated_sql"] = out
return stateLangChain 作为协调器,确保每个问题都顺畅地走完整个 RAG 循环。
5. FastAPI 后端------服务化管线
为了让系统具有交互性,我们将所有内容封装进 FastAPI 后端。
FastAPI 提供一种简单、高性能的方式把 RAG 管线暴露为 API。
当用户发起一个携带问题的 POST 请求时,API 会:
- 检索模式信息。
- 生成并验证 SQL。
- 执行查询。
- 返回格式化的结果。
这一层相当于你的 Text-to-SQL 聊天机器人的"机房"。
python
# 函数:API 入参模型(Pydantic)
class QueryRequest(BaseModel):
"""查询请求:包含自然语言问题与是否返回 SQL 的标记。"""
question: str
show_sql: bool = True
# 函数:主查询端点(RAG→SQL→验证→执行→返回)
@app.post("/query")
async def query(req: QueryRequest):
"""接收问题,运行完整 RAG 管线,返回 SQL 与结果。"""
state = {"question": req.question, "messages": []}
# 检索
state = await retriever_node(state)
# 生成 SQL
state = await sql_generator_node(state)
sql = state["generated_sql"]
# 验证:只允许 SELECT,且只允许白名单表
ok, reason = validate_sql(sql, ALLOWED_TABLES)
if not ok:
raise HTTPException(status_code=400, detail=f"SQL 验证失败: {reason}. SQL: {sql}")
# 执行:只读连接 + LIMIT 保护
cols, rows = execute_sql(sql)
result = [dict(zip(cols, r)) for r in rows]
return {"sql": sql if req.show_sql else None, "cols": cols, "rows": result}6. Streamlit 前端------聊天界面
最后,我们构建一个 Streamlit 前端------一个轻量的 Web 界面供用户交互。
用户可以输入问题、(可选)查看生成的 SQL,并实时查看结果。
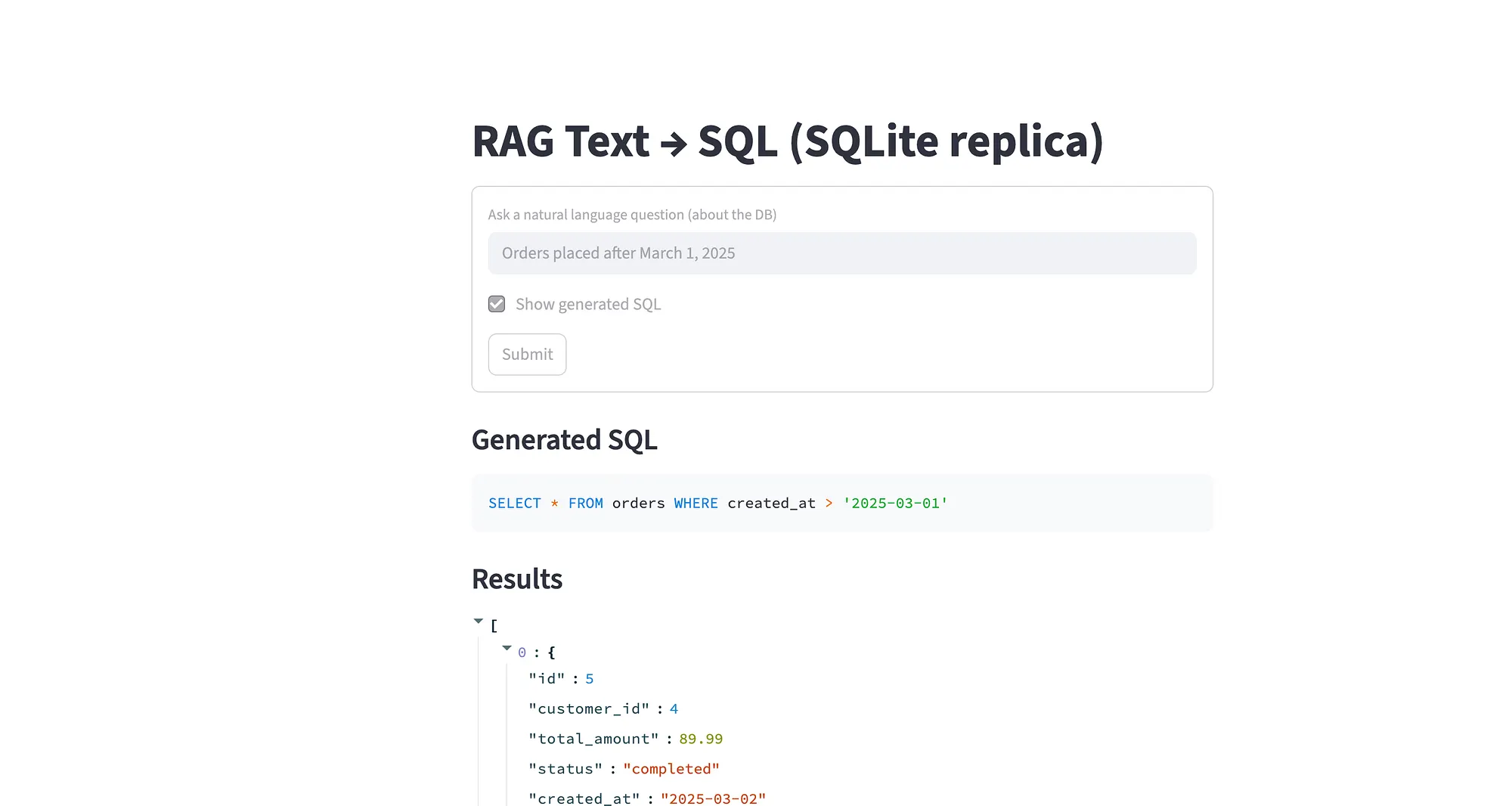
Streamlit 简洁的特性使其非常适合原型化 AI 工具:几行 Python,你就能搭一个和数据"对话"的交互面板。
7.汇总串联
端到端架构图:
用户(Streamlit UI)
↓
FastAPI 后端
↓
LangChain RAG 管线
├── 检索器(Chroma 向量库)
├── 嵌入层(Hugging Face)
├── LLM(SQL 生成)
↓
SQLite 数据库(执行 SQL)
↓
结果 → 返回到前端这条流程覆盖了一个查询的完整生命周期------从纯英文到执行 SQL,再到可读结果。
GitHub 上可以查看完整代码并开始实验:
3 分步实现
3.1 环境准备
- 安装依赖:
bash
pip install -r requirements.txt3.2 SQLite 数据库搭建
- 说明示例模式(如
customers、orders)。
python
# 函数:创建示例数据库与表并插入数据
def create_sample_db():
"""创建 SQLite 示例库与两张业务表,并插入样例数据。"""
import os, sqlite3
os.makedirs("sample_db", exist_ok=True)
DB = "sample_db/sample.db"
conn = sqlite3.connect(DB)
cur = conn.cursor()
cur.execute("""
CREATE TABLE IF NOT EXISTS customers (
id INTEGER PRIMARY KEY,
name TEXT,
email TEXT,
created_at TEXT
);
""")
cur.execute("""
CREATE TABLE IF NOT EXISTS orders (
id INTEGER PRIMARY KEY,
customer_id INTEGER,
total_amount REAL,
status TEXT,
created_at TEXT,
notes TEXT,
FOREIGN KEY(customer_id) REFERENCES customers(id)
);
""")
customers = [
(1, "Alice Johnson", "alice@example.com", "2024-12-01"),
(2, "Bob Lee", "bob@example.com", "2024-12-05"),
(3, "Carol Singh", "carol@example.com", "2024-12-10"),
(4, "David Kim", "david.kim@example.com", "2024-12-12"),
# ...
]
orders = [
(1, 1, 120.50, "completed", "2025-01-03", "First order"),
(2, 1, 15.00, "pending", "2025-01-07", "Gift wrap"),
(3, 2, 250.00, "completed", "2025-02-10", "Bulk order"),
# ...
]
cur.executemany("INSERT OR REPLACE INTO customers VALUES (?,?,?,?)", customers)
cur.executemany("INSERT OR REPLACE INTO orders VALUES (?,?,?,?,?,?)", orders)
conn.commit()
conn.close()运行下面命令创建并插入数据:
bash
python sample_db/create_sample_db.py3.2.1 嵌入与模式索引
在 AI 能生成准确 SQL 之前,它需要"理解"我们数据库的结构------有哪些表、包含哪些列、承载什么样的数据。
这正是向量嵌入 与语义索引发挥作用的地方。
3.2.2 什么是嵌入?
嵌入是文本的数值化表示------一个位于高维空间的向量,能够捕捉语义。
例如,短语:
"customer name"
与
"client full name"
在这个空间里的向量距离会很接近,因为它们大致表达的是同一个意思。
通过为每个表名 、列名 甚至样例数据 生成嵌入,模型在用户提问时就可以检索 相关上下文------比如"展示最近注册的用户",会语义匹配到 signup_date、created_at 或 join_date 等列。
3.2.3 我们将使用的工具
- Hugging Face Embeddings------把文本转为向量。
- Chroma 向量库------高效存储与检索嵌入。
- SQLite------实际要索引的数据库。
下面是索引脚本 👇
python
# 函数:主索引流程(简版)
def run_indexing():
"""遍历 SQLite 表,将行级文本块写入 Chroma 并持久化。"""
import os, sqlite3, hashlib
from tqdm import tqdm
from langchain_community.embeddings.huggingface import HuggingFaceEmbeddings
from langchain_community.vectorstores import Chroma
def row_hash(values):
"""为一行生成唯一哈希值。"""
return hashlib.sha256("|".join(map(str, values)).encode()).hexdigest()
def row_to_text(table, cols, row):
"""把 SQLite 行记录转为可读文本块。"""
return f"Table: {table}\n" + "\n".join([f"{c}: {v}" for c, v in zip(cols, row)])
SQLITE_PATH = os.getenv("SQLITE_PATH", "sample_db/sample.db")
CHROMA_DIR = os.getenv("CHROMA_DIR", "./chroma_persist")
EMBED_MODEL = os.getenv("EMBED_MODEL", "sentence-transformers/all-MiniLM-L6-v2")
embeddings = HuggingFaceEmbeddings(model_name=EMBED_MODEL)
vectorstore = Chroma(collection_name="sqlite_docs", persist_directory=CHROMA_DIR, embedding_function=embeddings)
conn = sqlite3.connect(SQLITE_PATH)
cur = conn.cursor()
cur.execute("SELECT name FROM sqlite_master WHERE type='table' AND name NOT LIKE 'sqlite_%'")
tables = [t[0] for t in cur.fetchall()]
for t in tqdm(tables, desc="Indexing tables"):
cur.execute(f"PRAGMA table_info({t});")
cols = [c[1] for c in cur.fetchall()]
cur.execute(f"SELECT {', '.join(cols)} FROM {t}")
rows = cur.fetchall()
docs, ids, metas = [], [], []
for r in rows:
txt = row_to_text(t, cols, r)
pk = str(r[0])
hid = row_hash(r)
ids.append(f"{t}:{pk}")
docs.append(txt)
metas.append({"table": t, "pk": pk, "hash": hid})
vectorstore.add_texts(texts=docs, metadatas=metas, ids=ids)
conn.close()
print("索引完成,并已持久化到 Chroma。")生成嵌入并保存到向量库:
bash
python ingestion/index_sqlite.py3.2.4 步骤详解
-
提取模式与数据
对每张表,抓取列名与若干行。每一行都变成一个小"文档",描述该表包含什么。 -
把文本转为向量
使用HuggingFaceEmbeddings将每个文本块(如"Table: customers\nname: John\nsignup_date: 2025-09-10")转为数值向量。 -
向量存储到 Chroma
这些嵌入被存入 Chroma 向量库,并与元信息关联------比如表名、主键与哈希 ID。 -
启用语义检索
当用户提出问题时,在同一向量空间里检索匹配的模式块,为 SQL 生成提供精准上下文。SQLite 数据库
↓
抽取表 + 列
↓
Hugging Face 向量嵌入
↓
存入 Chroma 向量库
↓
查询时语义检索
4 RAG 查询流程
我们已经构建了模式索引。现在,是把它用起来的时候了。
RAG 查询流程是魔力发生的地方------系统把用户问题变成可执行的 SQLite 查询,并把结果返回。
4.1 步骤 1:检索相关模式
当用户提问------比如:
"展示上个月加入的所有客户"
系统把这个问题嵌入到与数据库模式相同的向量空间(多亏我们之前生成的嵌入)。
使用 Chroma 检索器 ,它会拉取最相关的模式片段(如与 customers、signup_date 相关的表和列)。
python
# 函数:RAG 检索节点(返回文本内容列表)
async def retriever_node(state):
"""根据问题在 Chroma 中检索 TOP-K 相关文档。"""
docs = await state["retriever"].ainvoke(state["question"])
state["retrieved_docs"] = [d.page_content for d in docs]
return state现在,模型具备了真实的模式认知------一张数据库实际存在内容的"备忘单"。
4.2 步骤 2:通过 LLM 生成 SQL
我们把问题和已检索的模式上下文一起传给 LLM(例如 OpenAI、Mistral 或 Gemini)。
我们使用一个专门的提示词,让输出只 是一个有效、只读的 SELECT 语句。
python
# 函数:构造 SQL 生成提示词
def build_sql_prompt():
"""创建只读 SELECT 的提示词模板。"""
from langchain_core.prompts import PromptTemplate
return PromptTemplate.from_template("""
你是一个 SQL 生成器。基于下面的上下文,生成一个单条只读的 SQLite SELECT 查询(不加分号,不多语句)。
上下文:
{context}
问题:
{question}
仅返回 SQL 的 SELECT 语句。
""")
# 函数:清洗 LLM 输出并仅保留 SELECT 语句
def clean_llm_sql_output(text):
"""移除 Markdown 围栏与无关字符,保留且截断到 SELECT 语句。"""
import re
out = str(text or "").strip()
out = re.sub(r"```(?:sql)?\n?", "", out, flags=re.I).replace("```", "").strip()
m = re.search(r"(select\b.*)", out, flags=re.I | re.DOTALL)
out = m.group(1).rstrip(";").strip() if m else ""
return out至此,聊天机器人可以把英文输入 变成SQL 输出。
4.3 步骤 3:验证 SQL(安全优先)
在执行之前,我们要验证查询。这一步用来保护数据库并确保正确性。
我们用 sqlglot 解析器来:
- 拒绝任何非
SELECT语句(不允许DELETE、UPDATE等)。 - 检查只引用允许的白名单表。
- 安全解析语法。
python
# 函数:验证 SQL 只读与表白名单
def validate_sql(sql, allowed_tables):
"""验证 SQL:不含分号、只允许 SELECT、只使用白名单表。"""
import sqlglot
ALLOWED_STATEMENTS = {"select"}
DISALLOWED = {"delete", "update", "insert", "drop", "alter"}
if ";" in sql:
return False, "不允许分号或多语句"
for kw in DISALLOWED:
if f" {kw} " in f" {sql.lower()} ":
return False, f"不允许的关键字: {kw}"
try:
parsed = sqlglot.parse_one(sql, read="sqlite")
except Exception as e:
return False, f"SQL 解析错误: {e}"
if parsed.key.lower() not in ALLOWED_STATEMENTS:
return False, "只允许 SELECT 语句"
# 简单提取表名并校验白名单
def extract_tables(s):
import re
return set(re.findall(r"\bfrom\s+([a-zA-Z0-9_]+)", s, flags=re.I))
tables = extract_tables(sql)
if not tables.issubset(set(allowed_tables)):
return False, f"使用了不在白名单的表: {tables - set(allowed_tables)}"
return True, "ok"这一层让系统安全且只读。
4.4 步骤 4:在 SQLite 上执行
一旦验证通过,SQL 就会在 SQLite 数据库上执行。
我们增加保护措施以限制返回行数,避免重负载查询。
python
# 函数:只读执行 SQL,并限制行数
def execute_sql(sql, row_limit=1000, timeout=5.0):
"""只读执行 SQL,限制最大返回行数并设置忙等待。"""
import sqlite3
# 强制 LIMIT 保护
def enforce_limit(q, limit):
q_low = q.lower()
if " limit " in q_low:
return q
return f"{q} LIMIT {int(limit)}"
def open_ro_conn():
conn = sqlite3.connect("sample_db/sample.db")
conn.execute("PRAGMA query_only = 1;") # 只读保护
return conn
sql = enforce_limit(sql, row_limit)
conn = open_ro_conn()
conn.execute(f"PRAGMA busy_timeout = {int(timeout*1000)};")
cur = conn.cursor()
cur.execute(sql)
cols = [c[0] for c in cur.description] if cur.description else []
rows = cur.fetchmany(row_limit)
conn.close()
return cols, rows结果随后会被打包成 JSON 并返回给用户。
5 FastAPI 后端
构建并测试完 RAG 管线后,下一步就是把它暴露为 API,让用户与前端客户端可以实时发送问题、拿到 SQL 结果并互动。
这正是 FastAPI 的用武之地------它快速、类型安全、原生支持异步,非常适合为 AI 工作流提供服务。
5.1 为什么选择 FastAPI?
FastAPI 提供:
- 速度------异步 I/O 与自动文档(Swagger / ReDoc)
- 集成------易于与 LangChain、Chroma 或本地模型连接
- 验证------Pydantic 确保入参干净
- 扩展性------可部署到任意环境:Docker、Serverless 或本地
简言之:它是你的 RAG Text-to-SQL 逻辑的理想封装。
5.2 API 设计概览
我们暴露一个端点:
POST /query请求体:
json
{
"question": "Show me all customers who joined last month",
"show_sql": true
}响应:
json
{
"sql": "SELECT * FROM customers WHERE join_date >= '2025-09-01'",
"cols": ["id", "name", "join_date"],
"rows": [
{"id": 1, "name": "Alice", "join_date": "2025-09-05"},
{"id": 2, "name": "Bob", "join_date": "2025-09-12"}
]
}5.3 完整示例代码
python
# 函数:FastAPI 应用定义与主查询端点
def create_app():
"""创建 FastAPI 应用并注册 /query 端点。"""
import os
from fastapi import FastAPI, HTTPException
from pydantic import BaseModel
from dotenv import load_dotenv
from server.langgraph_nodes import retriever_node, sql_generator_node
from server.sql_validator import validate_sql
from server.executor import execute_sql
from server.utils import allowed_tables_from_db
load_dotenv()
SQLITE_PATH = os.getenv("SQLITE_PATH", "sample_db/sample.db")
ALLOWED_TABLES = allowed_tables_from_db(SQLITE_PATH)
app = FastAPI(title="RAG Text->SQL API")
class QueryRequest(BaseModel):
"""查询请求模型。"""
question: str
show_sql: bool = True
@app.post("/query")
async def query(req: QueryRequest):
"""运行完整 RAG→SQL→验证→执行流程并返回结果。"""
state = {"question": req.question, "messages": []}
state = await retriever_node(state)
state = await sql_generator_node(state)
sql = state["generated_sql"]
ok, reason = validate_sql(sql, ALLOWED_TABLES)
if not ok:
raise HTTPException(status_code=400, detail=f"SQL 验证失败: {reason}. SQL: {sql}")
cols, rows = execute_sql(sql)
result = [dict(zip(cols, r)) for r in rows]
return {"sql": sql if req.show_sql else None, "cols": cols, "rows": result}
return app5.4 流程回顾
- 接收问题
- 检索模式上下文(Chroma)
- 生成 SQL(LLM)
- 安全校验(只读 + 白名单)
- 执行与返回(SQLite)
设计之所以有效:
- 模块化:检索、生成、验证、执行各函数可替换或扩展。
- 安全 :仅允许
SELECT,并且表受白名单约束。 - 异步:整条管线支持并发,易随用户负载扩展。
- 可部署:Docker 打包后可部署到多种环境。
6 Streamlit 前端
后端已经跑起来了,现在让它可交互。
目标:做一个简洁的 Web 界面,任何人都能输入自然语言问题,查看生成的 SQL,并在数秒内看到实时查询结果。
6.1 完整代码
python
# 函数:Streamlit 应用(调用 FastAPI 并呈现结果)
def run_streamlit_app():
"""启动 Streamlit 前端,提交问题到后端并展示 SQL 与结果。"""
import streamlit as st
import requests
API_URL = "http://localhost:8000/query"
st.set_page_config(page_title="RAG Text→SQL Demo", layout="centered")
st.title("RAG Text → SQL(SQLite 副本)")
with st.form("query_form"):
question = st.text_input(
"对数据库提出一个自然语言问题",
value="Show total orders per customer"
)
show_sql = st.checkbox("显示生成的 SQL", value=True)
submitted = st.form_submit_button("提交")
if submitted:
question = str(question).strip()
show_sql = bool(show_sql)
if not question:
st.warning("请输入一个问题。")
else:
payload = {"question": question, "show_sql": show_sql}
with st.spinner("查询中..."):
try:
resp = requests.post(API_URL, json=payload, timeout=60)
resp.raise_for_status()
data = resp.json()
if show_sql:
st.subheader("🧠 生成的 SQL")
st.code(data.get("sql", ""), language="sql")
st.subheader("📊 查询结果")
rows = data.get("rows", [])
if rows:
st.dataframe(rows)
else:
st.info("该查询未返回任何行。")
except requests.exceptions.HTTPError as http_err:
st.error(f"HTTP 错误: {http_err} - {resp.text}")
except requests.exceptions.ConnectionError:
st.error("无法连接 API。请确认 FastAPI 在 localhost:8000 运行中。")
except requests.exceptions.Timeout:
st.error("请求超时,请稍后再试。")
except Exception as e:
st.error(f"意外错误: {e}")6.2 运行方式
bash
uvicorn main:app --reload
streamlit run app.py7 演示
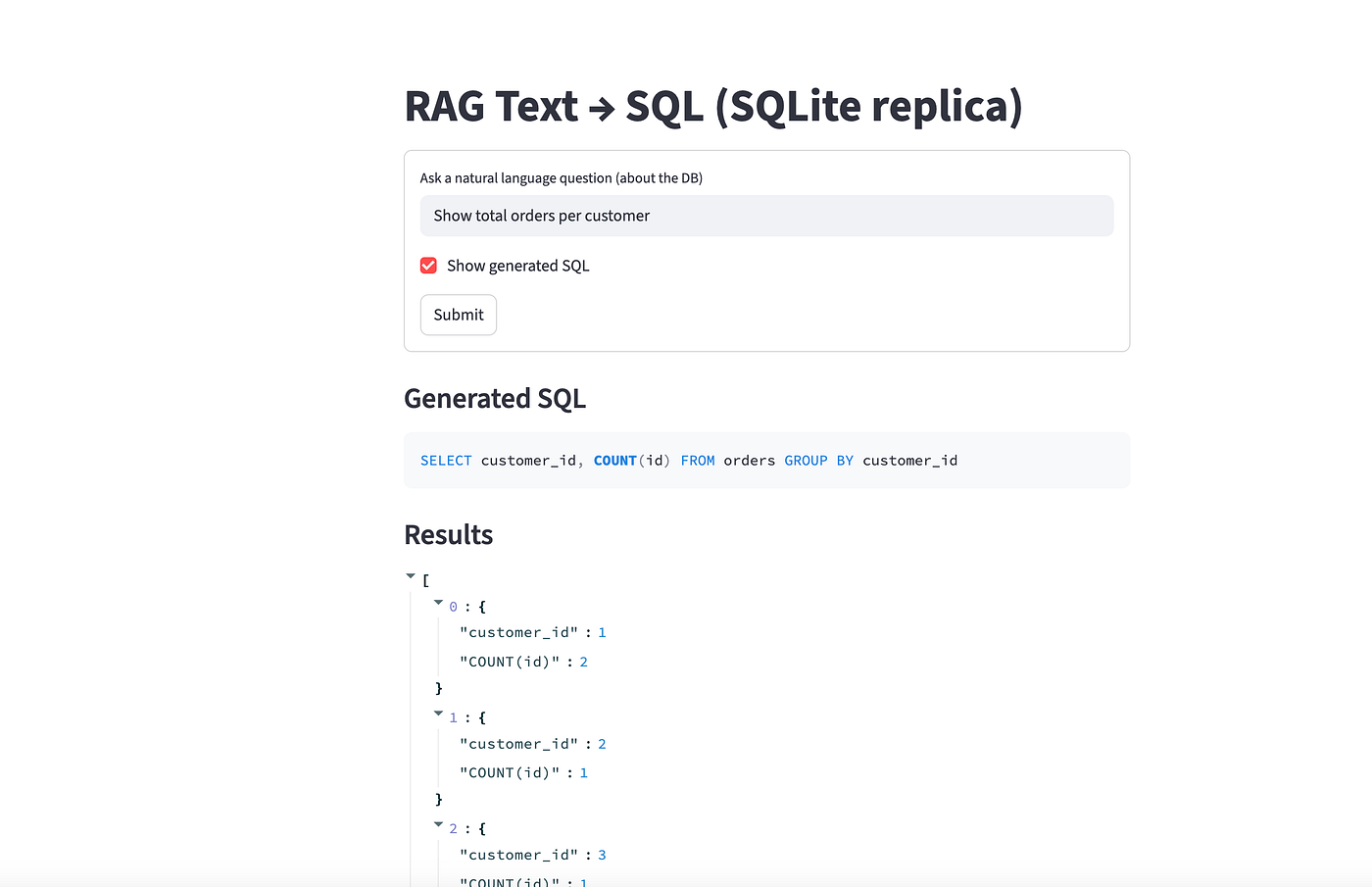
问题:Show total orders per customer(按客户统计订单总数)
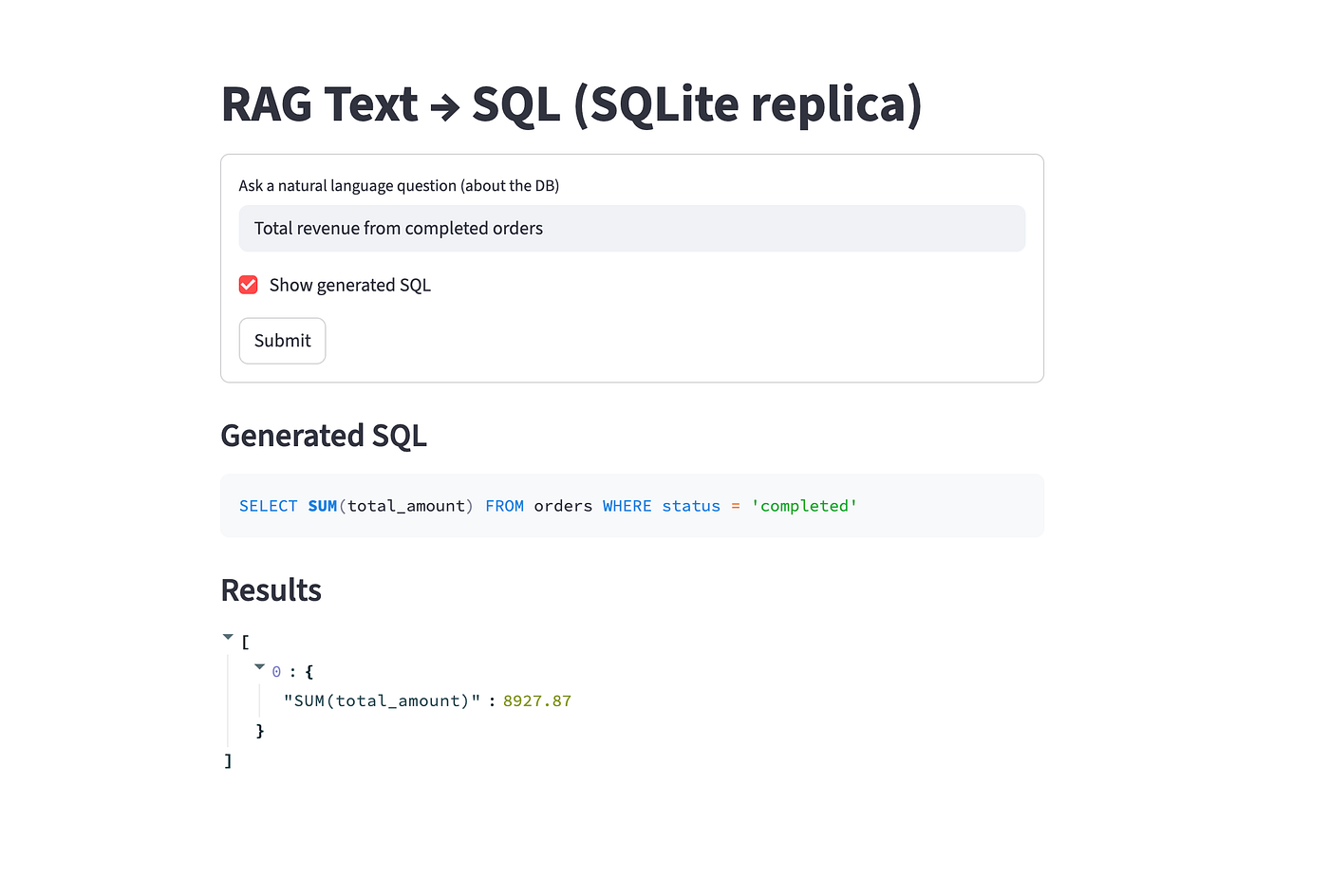
问题:Total revenue from completed orders(已完成订单的总收入)
8 下一步:增量嵌入与可扩展更新
到现在,你已经构建了一个完整的RAG 驱动的 Text-to-SQL 管线------从模式嵌入与检索,到 SQL 生成、验证与执行。
但在真实场景中,数据库是不断演变的。表会改变、新记录会插入、列定义会随时间变化。
我们如何让嵌入索引------也就是 RAG 系统------保持最新?
下面是让你的项目更"生产就绪"的几个方向。
1. 处理动态数据库
在原型里,我们在启动时索引了一次。
这对静态数据集很好,但生产系统需要在以下情况进行增量嵌入更新:
- 表结构变化(新增或删除列)。
- 新行的插入使上下文显著变化。
- 模式文档或元数据演进。
与其全量重建索引,不如仅嵌入已变化的部分。
增量索引策略
- 跟踪更新:通过时间戳或行级哈希。
- 与 Chroma 元信息(如存储的哈希 ID)对比。
- 仅重嵌入修改过的行或新增的表。
- 使用 Chroma 的增量
add_texts()API 持久化嵌入。
这种方法能最小化成本、时间与冗余------对百万级数据尤为重要。
2. 通过后台作业实现自动化
重索引或更新嵌入不应阻塞用户查询。
你可以把这些操作交给后台任务:
- Celery(配 Redis/RabbitMQ)------适合分布式任务管理。
- FastAPI BackgroundTasks------轻量的异步更新。
使用 FastAPI 后台任务的示例:
python
# 函数:调度后台嵌入更新
def schedule_update_embeddings(app):
"""注册一个触发嵌入更新的端点,采用后台任务执行。"""
from fastapi import BackgroundTasks
@app.post("/update_embeddings")
async def update_embeddings(background_tasks: BackgroundTasks):
"""触发增量重索引,不阻塞查询主流程。"""
def reindex_changed_tables():
# 在此对比哈希/时间戳并调用 add_texts() 等增量更新逻辑
pass
background_tasks.add_task(reindex_changed_tables)
return {"status": "update scheduled"}这让你的主查询端点(/query)保持响应,而索引更新在后台进行。
3. 未来增强
下面是几个值得探索的方向:
- 对公司查询日志进行微调SQL 生成器。
- 添加缓存用于高频问题。
- 在 Streamlit 中集成可视化图表,动态展示查询结果。
- 切换到更大的向量库(如 Pinecone 或 Qdrant)以支持海量数据集。
- 加入反馈回路------让用户纠正 SQL 错误并用于模型再训练。
每一项改进都会让你的系统更接近一个自学习的数据助理,它能理解你不断演变的模式与业务逻辑。
9 关键收获
你刚刚构建了一个强大的东西------完整的基于 RAG 的 Text-to-SQL 系统,能把纯英文变成可执行的数据库洞察。让我们回顾一下你完成了什么:
1. 掌握了 Text-to-SQL 的 RAG
你学会了 RAG(检索增强生成) 如何在自然语言 与结构化数据库模式之间架起桥梁,大幅提升准确性并减少 SQL 生成中的幻觉。
- ✅ 嵌入了数据库模式与样例行以提供上下文。
- ✅ 在生成查询之前检索最相关的片段。
- ✅ 将检索与 LLM 推理结合,产出可靠的 SQL。
2. 构建了模块化、可扩展的架构
你用 LangChain 与 FastAPI 像生产级 AI 服务一样构建系统:
- SQLite 作为结构化数据源。
- Hugging Face 嵌入 + Chroma 做语义检索。
- LangChain 编排检索器、提示词与模型。
- FastAPI 作为轻量、异步的后端。
- Streamlit 提供干净、友好的前端界面。
每一层都是模块化的------这意味着你可以在不破坏整体管线的情况下替换组件(比如模型或数据库)。
3. 部署了交互式聊天界面
最后,你用 Streamlit 前端把一切包起来,让用户可以:
- 输入自然语言问题;
- 查看生成的 SQL;
- 即刻在动态表格中查看结果。
你把原来只属于开发者的工作(写 SQL)变成了和数据的自然对话。
10 最后思考
这个项目展现了我们与数据交互方式中的强大转变:AI 正在民主化数据库访问 ,打破壁垒,让任何人都可以在不懂 SQL 的情况下提出复杂问题。
通过把检索增强生成与现代嵌入技术和对话界面结合起来,我们正在创造把数据直接交到人们手里的工具------让洞察更快速、更简单、更可触达。
欢迎分享你的反馈、想法,以及你构建自己的 Text-to-SQL 系统的经验。
查看 GitHub 上的完整代码并开始你的实验: