官方文档:https://docs.pytorch.org/docs/stable/torch.compiler.html
PyTorch 2.x 引入的 torch.compile 是核心优化工具,旨在解决 PyTorch 中图形捕获准确性问题,通过底层技术栈将 PyTorch 程序加速,同时标志着 PyTorch 从依赖 C++ 向 Python 主导的编译架构过渡。
一、核心定位
torch.compile 并非独立工具,而是隶属于 torch.compiler 命名空间的核心函数,其核心目标是:
-
精准图形捕获:解决传统 PyTorch 动态图模式下图形捕获不完整、不准确的问题,为后续编译优化奠定基础。
-
程序加速:通过底层编译器将捕获的计算图转换为高效机器码,提升 PyTorch 模型(训练与推理)的运行速度。
-
架构过渡:采用 Python 编写,推动 PyTorch 从传统 C++ 内核主导的架构,向更灵活、易扩展的 Python 编译架构转变。
二、使用方式
torch.compile 的使用逻辑简洁,核心是通过装饰器或函数调用方式,对 PyTorch 模型(nn.Module 实例)或函数进行编译优化,同时支持指定不同后端适配不同硬件与场景。
1. 基础使用语法
import torch
import torch.nn as nn
# 1. 定义示例模型
class SimpleModel(nn.Module):
def __init__(self):
super().__init__()
self.linear = nn.Linear(10, 2)
def forward(self, x):
return self.linear(x)
model = SimpleModel()
x = torch.randn(32, 10) # 输入数据
# 2. 编译模型(默认使用 TorchInductor 后端)
compiled_model = torch.compile(model) # 核心编译步骤
# 3. 运行编译后的模型(使用方式与原模型完全一致)
output = compiled_model(x)2. 指定后端的使用示例
不同后端适配不同硬件(CPU/GPU)和场景(训练 / 推理),通过 backend 参数指定,常见用法如下:
| 使用场景 | 代码示例 | 说明 |
|---|---|---|
| GPU 训练(默认) | compiled_model = torch.compile(model, backend="inductor") |
使用 TorchInductor 后端,适配 NVIDIA/AMD/Intel GPU,依赖 OpenAI Triton |
| GPU 训练(CUDA 图形) | compiled_model = torch.compile(model, backend="cudagraphs") |
结合 AOT Autograd,使用 CUDA 图形优化训练速度 |
| CPU 训练 / 推理 | compiled_model = torch.compile(model, backend="ipex") |
依赖 Intel IPEX 框架,优化 Intel CPU 上的运行效率 |
| 推理(TensorRT 加速) | compiled_model = torch.compile(model, backend="tensorrt") |
需先导入 torch_tensorrt,用 TensorRT 优化 GPU 推理速度 |
| 推理(TVM 加速) | compiled_model = torch.compile(model, backend="tvm") |
借助 Apache TVM 框架,适配多硬件的推理优化 |
3. 查看支持的后端
通过 torch.compiler.list_backends() 可查看当前环境中已支持的所有后端(含可选依赖),示例:
print(torch.compiler.list_backends())
# 输出示例:['inductor', 'cudagraphs', 'ipex', 'onnxrt', 'tensorrt', 'tvm', 'openvino']三、使用场景
torch.compile 并非万能,需根据硬件、任务类型(训练 / 推理)选择适配场景,以下是典型适用与不适用场景:
1. 适用场景
| 场景类型 | 具体说明 |
|---|---|
| 大规模模型训练 | 如 Transformer、ResNet 等复杂模型,编译后可通过 TorchInductor/Triton 加速 GPU 计算,降低训练耗时 |
| 高吞吐量推理 | 工业级推理场景(如推荐系统、图像识别),用 tensorrt/openvino 后端可提升批量处理速度 |
| Intel CPU 平台任务 | 依赖 ipex 后端,优化 Intel CPU 上的训练与推理效率(如服务器端 CPU 推理) |
| 多硬件适配推理 | 借助 tvm 后端,实现模型在 CPU、GPU、FPGA 等多硬件上的高效推理 |
2. 不适用场景
-
轻量级模型 / 小批量数据:如简单线性模型、单样本推理,编译过程(图形捕获、代码生成)的开销可能超过加速收益,反而变慢。
-
动态性极强的模型 :如含频繁条件分支(
if/for动态切换)、动态形状输入(每次输入维度变化)的模型,TorchDynamo 难以稳定捕获图形,优化效果差。????频繁条件分支的示例 -
非 PyTorch 原生操作:若模型中包含大量自定义 C++ 算子或第三方非兼容库,可能导致图形捕获失败,无法编译。
四、底层实现原理
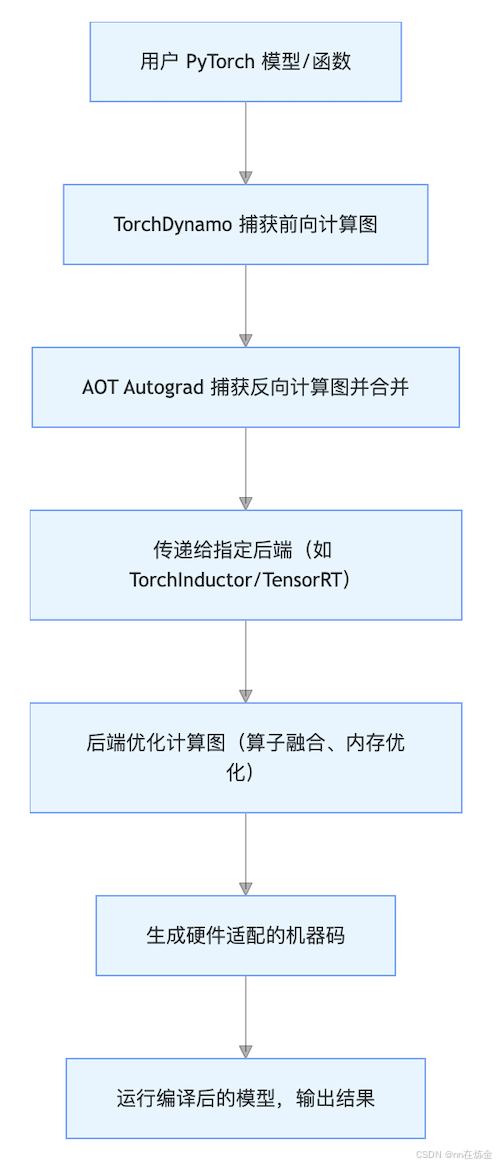
torch.compile 的加速能力依赖三大核心底层技术协同工作,形成 "图形捕获→反向传播捕获→代码生成" 的完整链路:
1. 核心技术栈拆解
(1)TorchDynamo:安全的图形捕获
-
核心作用 :作为
torch.compile的 "前端",负责从 PyTorch 动态图中精准捕获计算图,是后续优化的基础。 -
实现机制 :利用 CPython 的 Frame Evaluation API(帧评估 API),在不修改用户代码的前提下,拦截 PyTorch 操作的执行流程,将动态执行的算子序列转换为静态计算图。
-
关键优势 :安全性高,避免传统 "追踪式" 捕获(如
torch.jit.trace)因动态分支导致的图形不完整问题,支持大部分 Python 动态语法(如if/for)。
(2)AOT Autograd:提前捕获反向传播
-
核心作用:不仅捕获用户定义的前向计算图,还会 "提前(Ahead-of-Time)" 捕获反向传播(梯度计算)的计算图,实现前向 + 反向的端到端优化。
-
实现机制:基于 PyTorch 的 Autograd 机制,分析前向图中算子的梯度依赖关系,生成反向传播的计算图,并与前向图合并为统一的优化单元,再传递给后端编译器。
-
关键优势:解决传统动态图中 "反向传播实时计算" 的开销问题,让后端(如 TorchInductor)可对前向 + 反向进行联合优化(如内存复用、算子融合)。
(3)TorchInductor:默认后端与代码生成
-
核心作用 :作为
torch.compile的默认 "后端编译器",负责将 TorchDynamo 捕获的计算图转换为高效机器码,适配多硬件。 -
实现机制
- 对计算图进行优化(如算子融合、内存布局调整);
- 针对不同硬件生成底层代码:
-
NVIDIA/AMD/Intel GPU:基于 OpenAI Triton(高性能 GPU 编程框架)生成内核代码,替代传统 CUDA C++ 内核;
-
CPU:生成优化的 C++/AVX 指令代码,适配 x86/ARM 架构;
- 将生成的代码即时编译(JIT)为机器码,供模型运行调用。
2. 整体工作流程
五、关键参数含义
torch.compile 的参数可分为 "核心功能参数" 和 "后端专属参数",以下是常用核心参数的详细说明:
| 参数名 | 数据类型 | 默认值 | 核心作用 |
|---|---|---|---|
model |
nn.Module/ 函数 | 无 | 待编译的 PyTorch 模型(nn.Module 实例)或自定义函数(如 def my_func(x): return x.sum()) |
backend |
str/callable | "inductor" | 指定编译后端:- 字符串:如 "inductor"(默认)、"cudagraphs"、"ipex" 等;- 可调用对象:自定义后端编译器(需符合 PyTorch 后端接口规范) |
mode |
str | "default" | 编译模式,控制优化强度与兼容性:- "default":平衡速度与兼容性;- "max-autotune":最大化优化(如多组内核参数搜索),耗时更长但可能更快;- "reduce-overhead":降低编译开销,适合轻量级模型 |
dynamic |
bool | False | 是否支持动态形状输入:- True:允许输入形状动态变化(如 batch size 可变),但优化效果可能下降;- False:固定输入形状,优化更充分 |
fullgraph |
bool | False | 是否强制将整个模型捕获为单个计算图:- True:仅当模型可被完整捕获为单图时编译成功,优化更彻底;- False:允许将模型拆分为多个子图,兼容性更高(如含动态分支的模型) |
options |
dict | {} | 后端专属配置参数,如:- TorchInductor:{"triton.unique_kernel_names": True}(启用唯一内核名);- TensorRT:{"precision": "fp16"}(设置推理精度为 FP16) |
参数使用示例(含后端专属配置)
# 示例:用 TensorRT 后端编译模型,设置推理精度为 FP16,支持动态 batch size
compiled_model = torch.compile(
model=SimpleModel(),
backend="tensorrt",
dynamic=True, # 支持动态形状
options={"precision": "fp16"} # TensorRT 后端专属参数:FP16 精度
)六、常见问题与注意事项
-
编译耗时问题:首次编译模型时,因图形捕获、代码生成、JIT 编译等步骤,会有一定 "预热耗时",后续运行可复用编译结果(无需重复编译)。
-
兼容性问题 :若模型中含
torch.nn.functional未覆盖的自定义算子,可能导致 TorchDynamo 捕获失败,需参考 PyTorch 文档修改算子为兼容版本。
七、TorchInductor 核心优化原理
TorchInductor 作为 torch.compile 的默认后端,核心目标是将 TorchDynamo 捕获的计算图转换为高性能机器码 ,其优化原理围绕 "计算图优化→目标代码生成→高效执行" 三层链路展开,通过深度融合算子、适配硬件特性、减少冗余开销,实现 PyTorch 模型的端到端加速。以下从优化原理、核心操作、硬件适配细节三方面拆解其内部逻辑。
-
脱离 Python 解释器开销:将 PyTorch 动态图的 "逐算子 Python 调用" 转换为 "静态融合算子的机器码",彻底规避 Python 解释器的调度延迟(这是动态图模型的主要性能瓶颈之一);
-
硬件原生特性利用:针对 GPU/CPU 的架构特性(如 GPU 的 SIMT 并行、CPU 的 AVX 指令集)生成定制化代码,而非依赖通用内核;
-
端到端联合优化:结合 AOT Autograd 捕获的 "前向 + 反向" 完整计算图,进行跨前反向的全局优化(如内存复用、梯度计算与前向计算的算子融合)。
八、TorchInductor 内部核心操作(分阶段拆解)
TorchInductor 的工作流程分为 "计算图优化" 和 "代码生成与编译" 两大阶段,每个阶段包含多个关键优化步骤,最终生成硬件可执行的机器码。
-
计算层:通过算子融合、计算简化,减少总计算量;
-
内存层:通过内存复用、布局调整,降低内存访问开销(GPU 性能的核心瓶颈);
-
硬件层:通过 Triton/C++ 生成硬件专用代码,最大化 GPU/CPU 的硬件算力(如 Tensor Core、AVX 指令)。
阶段 1:计算图优化(Graph Optimization)
此阶段的目标是 **"简化计算图、减少计算量与内存访问"**,基于 PyTorch 的 fx.GraphModule(静态计算图表示)进行操作,核心步骤如下:
1. 算子融合(Operator Fusion):减少内存读写开销
算子融合是 TorchInductor 最核心的优化之一,其原理是将多个连续的 "轻量级算子" 合并为一个 "重量级算子",从而减少算子间的中间结果内存读写(内存访问速度远慢于计算速度,是 GPU 性能瓶颈的核心)。
-
常见融合模式:
-
线性层 + 激活函数:
nn.Linear(x) + nn.ReLU()→ 融合为单个 "线性 + ReLU" 算子; -
卷积 + 批归一化(BN)+ 激活:
nn.Conv2d(x) + nn.BatchNorm2d() + nn.SiLU()→ 融合为单个卷积算子(提前计算 BN 的均值 / 方差,嵌入卷积核); -
逐元素操作链:
x * 2 + 3 - 1→ 融合为单个逐元素计算算子(x * 2 + 2)。
-
-
融合优势:例如,未融合的 "卷积 + BN" 需要先写卷积结果到内存,再读内存做 BN 计算;融合后仅需一次计算、一次内存读写, latency 降低 30%~50%。
-
说明:理解TorchInductor 的算子融合能力,需先明确其与 "原生融合算子" 的核心差异 ------ 前者是动态、端到端的全局融合引擎,后者是静态、预定义的局部融合单元。即使模型中已包含原生融合算子,TorchInductor 仍能通过更深度的全局优化进一步提升性能。
2. 内存优化(Memory Optimization):减少显存占用与复用
TorchInductor 通过分析计算图的 "内存依赖关系",最大化内存复用,减少冗余内存分配:
-
中间结果复用:对于无后续依赖的中间张量(如前向计算中仅用于生成某结果、反向中不再需要的张量),直接在原地(in-place)覆盖,避免新内存分配;
-
梯度内存预分配:结合 AOT Autograd 捕获的反向图,提前规划梯度张量的内存空间,避免反向计算时频繁申请 / 释放内存(动态图中反向计算的内存碎片化问题);
-
数据布局调整 :将张量的内存布局(如
NHWC/NCHW)转换为硬件最优格式(例如 GPU 上NHWC更适合 Tensor Core 计算,CPU 上NCHW更适合 AVX 指令),减少计算时的格式转换开销。
3. 计算简化(Computation Simplification):消除冗余计算
通过静态分析计算图,移除无效或可简化的计算步骤:
-
常量折叠(Constant Folding) :若算子输入包含常量(如
torch.ones(3,3) * 2),直接在编译阶段计算出结果,避免运行时重复计算; -
死代码消除(Dead Code Elimination):移除未被后续算子使用的计算节点(如某分支的输出未被最终结果依赖);
-
算子替换 :将通用算子替换为硬件专用高效算子(例如 GPU 上用
torch.nn.functional.scaled_dot_product_attention替换自定义注意力实现,直接调用 Tensor Core 加速)。
4. 跨前反向优化(Cross Forward-Backward Optimization)
由于 AOT Autograd 已捕获 "前向 + 反向" 完整计算图,TorchInductor 可进行跨阶段优化:
-
梯度计算与前向计算融合:例如,将前向中 "计算激活值" 与反向中 "计算激活值梯度" 的算子合并,减少中间结果的内存读写;
-
动量优化融合 :将优化器的动量更新(如 Adam 的
m = beta1*m + (1-beta1)*grad)与梯度计算融合,避免单独调用优化器算子的开销。
阶段 2:代码生成与编译(Code Generation & Compilation)
此阶段的目标是 **"将优化后的计算图转换为硬件可执行的机器码"**,TorchInductor 会根据目标硬件(GPU/CPU)生成不同类型的底层代码,并通过即时编译(JIT)生成机器码。
1. 硬件感知的代码生成
TorchInductor 针对 GPU 和 CPU 采用不同的代码生成策略,核心是 "用硬件原生框架生成高效内核":
| 硬件类型 | 代码生成工具 | 核心逻辑 |
|---|---|---|
| NVIDIA/AMD GPU | OpenAI Triton | 生成 Triton 内核代码(Python 风格的 GPU 编程框架),自动适配 Tensor Core/FP16/FP8; |
| Intel/ARM CPU | 优化 C++/AVX 指令 | 生成带 AVX2/AVX512 指令的 C++ 代码,利用 CPU 的向量并行单元加速逐元素计算; |
-
以 GPU 为例(Triton 代码生成):
对于融合后的 "线性 + ReLU" 算子,TorchInductor 会生成如下风格的 Triton 代码(简化版):
import triton
import triton.language as tl@triton.jit
def linear_relu_kernel(
x_ptr, w_ptr, b_ptr, y_ptr, # 输入/输出指针
M, N, K, # 张量维度(M=batch, N=输出维度, K=输入维度)
stride_xm, stride_xk, # x 的内存步长
stride_wk, stride_wn, # w 的内存步长
stride_ym, stride_yn # y 的内存步长
):
# 1. 分配线程块与数据分区(利用 GPU 多线程并行)
pid = tl.program_id(axis=0)
x_block = tl.load(x_ptr + pid*stride_xm + tl.arange(0, K)) # 加载 x 的一行
w_block = tl.load(w_ptr + tl.arange(0, K)[:, None] * stride_wk + tl.arange(0, N)) # 加载 w 的一列# 2. 计算线性层(矩阵乘法) y = tl.dot(x_block, w_block) + tl.load(b_ptr + tl.arange(0, N)) # 加偏置 # 3. 应用 ReLU 激活 y = tl.max(y, 0) # 4. 写入结果(一次内存写操作) tl.store(y_ptr + pid*stride_ym + tl.arange(0, N), y)
这段代码的优势在于:
-
自动利用 GPU 的线程块(Block)和线程(Thread)并行,最大化 SM 利用率;
-
支持 Tensor Core(通过 Triton 内置的
tl.dot自动适配),FP16 下计算吞吐量提升 2~4 倍; -
减少内存访问次数(仅加载输入 x/w/b、写入输出 y,无中间张量读写)。
2. 即时编译(JIT Compilation):代码→机器码
生成底层代码(Triton/C++)后,TorchInductor 调用对应编译器将其转换为硬件可执行的机器码:
-
GPU(Triton 代码) :Triton 编译器会将 Python 风格的内核代码转换为 PTX 汇编(NVIDIA GPU 中间语言),再通过 NVIDIA 的
nvcc编译为 CUDA 二进制机器码; -
CPU(C++ 代码) :调用系统编译器(如
gcc/clang),并开启-O3优化和 AVX 指令集支持,将 C++ 代码编译为 x86/ARM 架构的机器码。
3. 内核调度与执行
编译生成的机器码会被封装为 "可调用内核",TorchInductor 负责在运行时调度这些内核:
-
自动线程块配置:根据张量维度(如 batch size、特征维度)动态调整 GPU 线程块大小(如 256/512 线程),最大化并行效率;
-
异步执行 :将内核调用与 Python 主线程异步分离,避免 Python 等待内核执行的阻塞开销(类似
torch.cuda.async的效果); -
批量调度:对于连续的小内核(如多个小维度的线性层),合并为单次调度,减少 GPU 内核启动开销(内核启动延迟约 1~2μs,频繁启动会浪费算力)。
九、TorchInductor 与传统 PyTorch 内核的核心差异
为更直观理解其优化效果,可对比传统 PyTorch 动态图与 TorchInductor 的执行逻辑:
| 对比维度 | 传统 PyTorch 动态图(C++ 内核) | TorchInductor(优化后) |
|---|---|---|
| 算子调用方式 | 逐算子 Python 调用(每个算子都有 Python 解释器开销) | 融合算子批量调用(仅一次 Python 调用,执行多个融合算子) |
| 内存读写 | 每个算子独立读写中间结果(多次内存访问) | 融合后仅一次读写(中间结果在寄存器 / 共享内存中流转) |
| 硬件适配 | 通用内核(适配所有 GPU 型号,未充分利用硬件特性) | 硬件专用代码(如 Tensor Core/AVX 指令,针对性优化) |
| 前反向协同 | 前向、反向、优化器独立执行(内存碎片化) | 前反向联合优化(内存预分配、算子融合) |
| 性能开销 | Python 解释器 + 内存读写 + 通用内核开销 | 几乎无 Python 开销 + 最少内存读写 + 硬件专用内核 |