Build a semantic search engine with LangChain
系列文章:
文章目录
- [1. 构建基于 LangChain 的语义搜索引擎](#1. 构建基于 LangChain 的语义搜索引擎)
-
- [1.1 概述](#1.1 概述)
- [1.2 核心概念](#1.2 核心概念)
- [1.3 环境准备](#1.3 环境准备)
-
- [1.3.1 安装依赖包](#1.3.1 安装依赖包)
- [1.3.2 LangSmith 追踪工具](#1.3.2 LangSmith 追踪工具)
- [2. 文档和文档加载器](#2. 文档和文档加载器)
-
- [2.1 文档抽象](#2.1 文档抽象)
- [2.2 加载 PDF 文档](#2.2 加载 PDF 文档)
- [2.3 文本通用分割:RecursiveCharacterTextSplitter](#2.3 文本通用分割:RecursiveCharacterTextSplitter)
- [2.4 按token进行分割](#2.4 按token进行分割)
-
- [2.4.1 tiktoken](#2.4.1 tiktoken)
- [2.4.2 SpacyTextSplitter](#2.4.2 SpacyTextSplitter)
- [2.4.3 SentenceTransformers](#2.4.3 SentenceTransformers)
- [2.4.4 NLTK 令牌化工具](#2.4.4 NLTK 令牌化工具)
- [2.4.5 Hugging Face](#2.4.5 Hugging Face)
- [2.5 按字符进行分割:character](#2.5 按字符进行分割:character)
- [2.6 按markdown分割](#2.6 按markdown分割)
-
- [2.6.1 基本用法](#2.6.1 基本用法)
- [2.6.2 如何返回Markdown行作为单独文档](#2.6.2 如何返回Markdown行作为单独文档)
- [2.6.3 如何约束块大小:双分割器](#2.6.3 如何约束块大小:双分割器)
- [2.6.4 故障排除:chunk_overlap似乎不适用](#2.6.4 故障排除:chunk_overlap似乎不适用)
- [2.7 按JSON 进行分割](#2.7 按JSON 进行分割)
-
- [2.7.1 基本使用](#2.7.1 基本使用)
- [2.7.2 如何管理列表内容的块大小](#2.7.2 如何管理列表内容的块大小)
- [2.8 代码分割器](#2.8 代码分割器)
-
- [2.8.1 Python 示例:](#2.8.1 Python 示例:)
- [2.8.2 HTML 示例](#2.8.2 HTML 示例)
- [2.9 HTML 分割器](#2.9 HTML 分割器)
-
- [2.9.1 三个分割器介绍](#2.9.1 三个分割器介绍)
-
- [2.9.1.1 HTMLHeaderTextSplitter](#2.9.1.1 HTMLHeaderTextSplitter)
- [2.9.1.2 HTMLSectionSplitter](#2.9.1.2 HTMLSectionSplitter)
- [2.9.1.3 HTMLSemanticPreservingSplitter](#2.9.1.3 HTMLSemanticPreservingSplitter)
- [2.9.2 示例](#2.9.2 示例)
-
- [2.9.2.1 使用 HTMLHeaderTextSplitter](#2.9.2.1 使用 HTMLHeaderTextSplitter)
- [2.9.2.2 使用 HTMLSemanticPreservingSplitter](#2.9.2.2 使用 HTMLSemanticPreservingSplitter)
- [2.9.2.3 使用自定义处理程序](#2.9.2.3 使用自定义处理程序)
- [3. 文本嵌入(Embeddings)](#3. 文本嵌入(Embeddings))
-
- [3.1 向量搜索简介](#3.1 向量搜索简介)
- [3.2 选择嵌入模型](#3.2 选择嵌入模型)
- [3.3 生成嵌入向量示例](#3.3 生成嵌入向量示例)
- [4. 向量存储(Vector Stores)](#4. 向量存储(Vector Stores))
-
- [4.1 向量存储简介](#4.1 向量存储简介)
- [4.2 常见向量存储集成及示例](#4.2 常见向量存储集成及示例)
- [4.3 向量存储中添加文档](#4.3 向量存储中添加文档)
- [4.4 查询向量存储](#4.4 查询向量存储)
- [5. 检索器(Retrievers)](#5. 检索器(Retrievers))
-
- [5.1 检索器概念](#5.1 检索器概念)
- [5.2 自定义简单检索器示例](#5.2 自定义简单检索器示例)
- [5.3 使用 VectorStore 自带的检索器](#5.3 使用 VectorStore 自带的检索器)
- [7 实际案例:构建基于 LangChain 的 RAG 代理](#7 实际案例:构建基于 LangChain 的 RAG 代理)
-
- [7.1 Agentic RAG 案例](#7.1 Agentic RAG 案例)
- [7.2 RAG 链](#7.2 RAG 链)
- [7.3 RAG链 与 Agentic RAG 差别在哪?](#7.3 RAG链 与 Agentic RAG 差别在哪?)
1. 构建基于 LangChain 的语义搜索引擎
1.1 概述
本教程将带你了解 LangChain 中的文档加载器 (Document Loader)、文本嵌入模型 (Embedding)和向量存储 (Vector Store)这几个核心抽象概念。它们设计用于支持从向量数据库和其他来源检索数据,以便与大型语言模型(LLM)工作流结合使用。这些技术在需要将数据检索作为模型推理一部分的应用中非常重要,比如基于检索增强生成(Retrieval-Augmented Generation,简称 RAG)。
本文以构建一个针对 PDF 文档的搜索引擎为例,展示如何检索与输入查询相似的段落,并在此基础上实现一个简易的 RAG 应用。
1.2 核心概念
本教程涵盖的主要概念包括:
| 概念 | 说明 |
|---|---|
| 文档和文档加载器 | 用于表示文本单位及其元数据,支持从多种来源加载文档 |
| 文本分割器 | 将长文本拆分成合适大小的文本块,方便检索和处理 |
| 嵌入模型 | 将文本转换成数值向量,便于通过向量相似度进行搜索 |
| 向量存储和检索器 | 存储嵌入向量并支持基于相似度的快速检索 |
1.3 环境准备
1.3.1 安装依赖包
本教程需要安装 langchain-community 和 pypdf 两个包:
bash
pip install langchain-community pypdf或者使用 Conda:
bash
conda install langchain-community pypdf -c conda-forge更多安装细节可参考 LangChain 安装指南。
1.3.2 LangSmith 追踪工具
LangChain 应用通常包含多步调用 LLM,随着应用复杂度增长,监控和调试变得非常重要。LangSmith 是一个用于追踪和查看调用细节的工具。
注册后,需设置环境变量开启追踪:
shell
export LANGSMITH_TRACING="true"
export LANGSMITH_API_KEY="你的API密钥"在 Jupyter Notebook 中也可以这样设置:
python
import getpass
import os
os.environ["LANGSMITH_TRACING"] = "true"
os.environ["LANGSMITH_API_KEY"] = getpass.getpass()2. 文档和文档加载器
2.1 文档抽象
LangChain 使用 Document 类来表示文本单元及其相关元数据。每个 Document 包含三个主要属性:
page_content:字符串,文档的文本内容。metadata:字典,存储文档的元信息,如来源、页码等。id(可选):文档的唯一标识符。
通常,一个 Document 代表一个较大文档的一个片段。
示例代码:创建两个简单文档对象
python
from langchain_core.documents import Document
documents = [
Document(
page_content="Dogs are great companions, known for their loyalty and friendliness.",
metadata={"source": "mammal-pets-doc"},
),
Document(
page_content="Cats are independent pets that often enjoy their own space.",
metadata={"source": "mammal-pets-doc"},
),
]代码解读
这段代码创建了两个 Document 实例,分别描述狗和猫的特点,并赋予它们相同的来源元数据。
2.2 加载 PDF 文档
LangChain 提供了多种文档加载器,可以方便地从不同数据源导入数据。这里我们使用 PyPDFLoader 从 PDF 文件中加载文档。
示例代码:
python
from langchain_community.document_loaders import PyPDFLoader
file_path = "../example_data/nke-10k-2023.pdf"
loader = PyPDFLoader(file_path)
docs = loader.load()
print(len(docs))代码解读
PyPDFLoader会将 PDF 的每一页加载为一个Document对象。- 通过
load()方法得到所有页的列表。 - 打印结果显示 PDF 有 107 页。
示例输出:
107查看第一页的内容和元数据:
python
print(f"{docs[0].page_content[:200]}\n")
print(docs[0].metadata)输出示例:
Table of Contents
UNITED STATES
SECURITIES AND EXCHANGE COMMISSION
Washington, D.C. 20549
FORM 10-K
(Mark One)
☑ ANNUAL REPORT PURSUANT TO SECTION 13 OR 15(D) OF THE SECURITIES EXCHANGE ACT OF 1934
FO
{'source': '../example_data/nke-10k-2023.pdf', 'page': 0}2.3 文本通用分割:RecursiveCharacterTextSplitter
来自文档:
recursive_text_splitter
单页 PDF 可能过长,不利于精细检索和问答。我们使用文本分割器将文档拆分成更小的块。
示例代码:
python
from langchain_text_splitters import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000, chunk_overlap=200, add_start_index=True
)
all_splits = text_splitter.split_documents(docs)
print(len(all_splits))代码解读
RecursiveCharacterTextSplitter会递归使用换行符等分隔符,将文本分割成不超过 1000 字符的块。- 块之间有 200 字符重叠,防止上下文断裂。
add_start_index=True会在元数据中记录每个块在原文中的起始字符位置。- 打印结果显示分割后总共有 514 个文本块。
输出示例:
514这个文本分割器是推荐用于通用文本的。它通过一个字符列表进行参数化。它尝试按顺序在这些字符上进行分割,直到块的大小足够小。默认列表为 "\\n\\n", "\\n", " ", ""。这会使所有段落(然后是句子,最后是单词)尽可能保持在一起,因为这些通常被认为是语义上最强相关的文本块。
bash
pip install -qU langchain-text-splitters要直接获取字符串内容,可以使用 .split_text。
要创建 LangChain 文档对象(例如,用于下游任务),可以使用 .create_documents。
python
from langchain_text_splitters import RecursiveCharacterTextSplitter
# 加载示例文档
with open("state_of_the_union.txt") as f:
state_of_the_union = f.read()
text_splitter = RecursiveCharacterTextSplitter(
# 设置一个非常小的块大小,仅用于演示。
chunk_size=100,
chunk_overlap=20,
length_function=len,
is_separator_regex=False,
)
texts = text_splitter.create_documents([state_of_the_union])
print(texts[0])
print(texts[1])RecursiveCharacterTextSplitter 设置的参数:
- chunk_size : 块的最大大小,其中大小由
length_function确定。 - chunk_overlap: 块之间的目标重叠。重叠的块有助于减轻当上下文在块之间被分割时的信息丢失。
- length_function: 确定块大小的函数。
- is_separator_regex: 是否将分隔符列表(默认为 "\\n\\n", "\\n", " ", "")解释为正则表达式。
一些书写系统没有单词边界,例如中文、日文和泰文。
使用默认分隔符列表 "\\n\\n", "\\n", " ", "" 进行文本分割可能会导致单词在块之间被分割。
为了保持单词完整,可以覆盖分隔符列表以包括额外的标点符号:
- 添加 ASCII 句号 "."、Unicode 全角句号 "."(用于中文文本)以及表意句号 "。"(用于日文和中文)。
- 添加零宽空格,适用于泰文、缅甸文、高棉文和日文。
- 添加 ASCII 逗号 ","、Unicode 全角逗号 "," 和 Unicode 表意逗号 "、"。
python
text_splitter = RecursiveCharacterTextSplitter(
separators=[
"\n\n",
"\n",
" ",
".",
",",
"\u200b", # 零宽空格
"\uff0c", # 全宽逗号
"\u3001", # 表意逗号
"\uff0e", # 全宽句号
"\u3002", # 表意句号
"",
],
# 现有参数
)2.4 按token进行分割
文档:
split_by_token
2.4.1 tiktoken
tiktoken 是 OpenAI 创建的快速 BPE 令牌化工具。我们可以使用 tiktoken 来估算使用的令牌数量。它对于 OpenAI 模型可能更准确。
- 如何拆分文本:按传入的字符。
- 如何测量块大小:按 tiktoken 令牌化工具。
可以直接与 tiktoken 一起使用的有 @[CharacterTextSplitter]、@[RecursiveCharacterTextSplitter] 和 @[TokenTextSplitter]。
bash
pip install --upgrade --quiet langchain-text-splitters tiktoken
python
from langchain_text_splitters import CharacterTextSplitter
# 这是我们可以拆分的长文档。
with open("state_of_the_union.txt") as f:
state_of_the_union = f.read()
# 使用 @[CharacterTextSplitter] 拆分并使用 tiktoken 合并块
text_splitter = CharacterTextSplitter.from_tiktoken_encoder(
encoding_name="cl100k_base", chunk_size=100, chunk_overlap=0
)
texts = text_splitter.split_text(state_of_the_union)
print(texts[0])输出示例:
Madam Speaker, Madam Vice President, our First Lady and Second Gentleman. Members of Congress and the Cabinet. Justices of the Supreme Court. My fellow Americans.
Last year COVID-19 kept us apart. This year we are finally together again.
Tonight, we meet as Democrats Republicans and Independents. But most importantly as Americans.
With a duty to one another to the American people to the Constitution.要强制约束块大小,可以使用 RecursiveCharacterTextSplitter.from_tiktoken_encoder,其中每个拆分将递归地拆分,如果其大小较大:
python
from langchain_text_splitters import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
model_name="gpt-4",
chunk_size=100,
chunk_overlap=0,
)我们还可以加载一个 TokenTextSplitter 拆分器,它直接与 tiktoken 一起工作,并确保每个拆分小于块大小。
python
from langchain_text_splitters import TokenTextSplitter
text_splitter = TokenTextSplitter(chunk_size=10, chunk_overlap=0)
texts = text_splitter.split_text(state_of_the_union)
print(texts[0])输出示例:
Madam Speaker, Madam Vice President, our某些书写语言(例如中文和日文)中,字符编码为两个或多个令牌。直接使用 TokenTextSplitter 可能会在两个块之间拆分字符的令牌,导致 Unicode 字符无效。使用 RecursiveCharacterTextSplitter.from_tiktoken_encoder 或 CharacterTextSplitter.from_tiktoken_encoder 可以确保块包含有效的 Unicode 字符串。
2.4.2 SpacyTextSplitter
spaCy 是一个用于高级自然语言处理的开源软件库,使用 Python 和 Cython 编写。LangChain 实现了基于 spaCy 令牌化工具的拆分器。
- 如何拆分文本:按 spaCy 令牌化工具。
- 如何测量块大小:按字符数。
bash
pip install --upgrade --quiet spacy
python
# 这是我们可以拆分的长文档。
with open("state_of_the_union.txt") as f:
state_of_the_union = f.read()
from langchain_text_splitters import SpacyTextSplitter
text_splitter = SpacyTextSplitter(chunk_size=1000)
texts = text_splitter.split_text(state_of_the_union)
print(texts[0])输出示例:
Madam Speaker, Madam Vice President, our First Lady and Second Gentleman.
Members of Congress and the Cabinet.
Justices of the Supreme Court.
My fellow Americans.
Last year COVID-19 kept us apart.
This year we are finally together again.
Tonight, we meet as Democrats Republicans and Independents.
But most importantly as Americans.
With a duty to one another to the American people to the Constitution.
And with an unwavering resolve that freedom will always triumph over tyranny.2.4.3 SentenceTransformers
SentenceTransformersTokenTextSplitter 是一个专门用于与句子转换器模型一起使用的文本拆分器。默认行为是将文本拆分为适合您想要使用的句子转换器模型的令牌窗口的块。
要根据句子转换器的令牌化工具拆分文本并约束令牌计数,请实例化 SentenceTransformersTokenTextSplitter。您可以选择性地指定:
chunk_overlap:令牌重叠的整数计数;model_name:句子转换器模型名称,默认为"sentence-transformers/all-mpnet-base-v2";tokens_per_chunk:每块的期望令牌计数。
python
from langchain_text_splitters import SentenceTransformersTokenTextSplitter
splitter = SentenceTransformersTokenTextSplitter(chunk_overlap=0)
text = "Lorem "
count_start_and_stop_tokens = 2
text_token_count = splitter.count_tokens(text=text) - count_start_and_stop_tokens
print(text_token_count)
token_multiplier = splitter.maximum_tokens_per_chunk // text_token_count + 1
# `text_to_split` 不适合单个块
text_to_split = text * token_multiplier
print(f"tokens in text to split: {splitter.count_tokens(text=text_to_split)}")输出示例:
tokens in text to split: 514
python
text_chunks = splitter.split_text(text=text_to_split)
print(text_chunks[1])输出示例:
lorem2.4.4 NLTK 令牌化工具
自然语言工具包(NLTK)是用于符号和统计自然语言处理(NLP)的库和程序套件,使用 Python 编程语言编写。我们可以使用 NLTK 基于 NLTK 令牌化工具拆分,而不仅仅是拆分在 \n\n 上。
- 如何拆分文本:按 NLTK 令牌化工具。
- 如何测量块大小:按字符数。
python
# pip install nltk
# 这是我们可以拆分的长文档。
with open("state_of_the_union.txt") as f:
state_of_the_union = f.read()
from langchain_text_splitters import NLTKTextSplitter
text_splitter = NLTKTextSplitter(chunk_size=1000)
texts = text_splitter.split_text(state_of_the_union)
print(texts[0])输出示例:
Madam Speaker, Madam Vice President, our First Lady and Second Gentleman.
Members of Congress and the Cabinet.
Justices of the Supreme Court.
My fellow Americans.
Last year COVID-19 kept us apart.
This year we are finally together again.
Tonight, we meet as Democrats Republicans and Independents.
But most importantly as Americans.
With a duty to one another to the American people to the Constitution.
And with an unwavering resolve that freedom will always triumph over tyranny.2.4.5 Hugging Face
Hugging Face 有许多令牌化工具。我们使用 Hugging Face 令牌化工具 GPT2TokenizerFast 来计算文本长度的令牌数。
- 如何拆分文本:按传入的字符。
- 如何测量块大小:按 Hugging Face 令牌化工具计算的令牌数。
python
from transformers import GPT2TokenizerFast
tokenizer = GPT2TokenizerFast.from_pretrained("gpt2")
# 这是我们可以拆分的长文档。
with open("state_of_the_union.txt") as f:
state_of_the_union = f.read()
from langchain_text_splitters import CharacterTextSplitter
text_splitter = CharacterTextSplitter.from_huggingface_tokenizer(
tokenizer, chunk_size=100, chunk_overlap=0
)
texts = text_splitter.split_text(state_of_the_union)
print(texts[0])输出示例:
Madam Speaker, Madam Vice President, our First Lady and Second Gentleman. Members of Congress and the Cabinet. Justices of the Supreme Court. My fellow Americans.
Last year COVID-19 kept us apart. This year we are finally together again.
Tonight, we meet as Democrats Republicans and Independents. But most importantly as Americans.
With a duty to one another to the American people to the Constitution.2.5 按字符进行分割:character
字符分割是文本分割的最简单方法。它使用指定的字符序列(默认:\n\n)来划分文本,块的长度由字符数来衡量。
关键点:
- 如何分割文本:通过给定的字符分隔符。
- 如何测量块大小:通过字符计数。
您可以选择以下两种方法:
.split_text--- 返回纯字符串块。.create_documents--- 返回LangChain文档对象,适用于需要保留元数据以供后续任务使用的情况。
安装
bash
pip install -qU langchain-text-splitters示例代码
python
from langchain_text_splitters import CharacterTextSplitter
# 加载示例文档
with open("state_of_the_union.txt") as f:
state_of_the_union = f.read()
text_splitter = CharacterTextSplitter(
separator="\n\n",
chunk_size=1000,
chunk_overlap=200,
length_function=len,
is_separator_regex=False,
)
texts = text_splitter.create_documents([state_of_the_union])
print(texts[0])使用元数据
使用 .create_documents 来传播与每个文档相关的元数据到输出块:
python
metadatas = [{"document": 1}, {"document": 2}]
documents = text_splitter.create_documents(
[state_of_the_union, state_of_the_union], metadatas=metadatas
)
print(documents[0])示例内容
plaintext
page_content='Madam Speaker, Madam Vice President, our First Lady and Second Gentleman. Members of Congress and the Cabinet. Justices of the Supreme Court. My fellow Americans. \n\nLast year COVID-19 kept us apart. This year we are finally together again. \n\nTonight, we meet as Democrats Republicans and Independents. But most importantly as Americans. \n\nWith a duty to one another to the American people to the Constitution. \n\nAnd with an unwavering resolve that freedom will always triumph over tyranny. \n\nSix days ago, Russia's Vladimir Putin sought to shake the foundations of the free world thinking he could make it bend to his menacing ways. But he badly miscalculated. \n\nHe thought he could roll into Ukraine and the world would roll over. Instead he met a wall of strength he never imagined. \n\nHe met the Ukrainian people. \n\nFrom President Zelenskyy to every Ukrainian, their fearlessness, their courage, their determination, inspires the world.' metadata={'document': 1}使用 .split_text 直接获取字符串内容:
python
text_splitter.split_text(state_of_the_union)[0]
plaintext
'Madam Speaker, Madam Vice President, our First Lady and Second Gentleman. Members of Congress and the Cabinet. Justices of the Supreme Court. My fellow Americans. \n\nLast year COVID-19 kept us apart. This year we are finally together again. \n\nTonight, we meet as Democrats Republicans and Independents. But most importantly as Americans. \n\nWith a duty to one another to the American people to the Constitution. \n\nAnd with an unwavering resolve that freedom will always triumph over tyranny. \n\nSix days ago, Russia's Vladimir Putin sought to shake the foundations of the free world thinking he could make it bend to his menacing ways. But he badly miscalculated. \n\nHe thought he could roll into Ukraine and the world would roll over. Instead he met a wall of strength he never imagined. \n\nHe met the Ukrainian people. \n\nFrom President Zelenskyy to every Ukrainian, their fearlessness, their courage, their determination, inspires the world.'2.6 按markdown分割
Split markdown - Docs by LangChain
例如,如果我们想拆分以下markdown:
markdown
md = '# Foo\n\n ## Bar\n\nHi this is Jim \nHi this is Joe\n\n ## Baz\n\n Hi this is Molly'我们可以指定要拆分的标题:
python
[("#", "Header 1"),("##", "Header 2")]内容根据共同标题进行分组或拆分:
python
{'content': 'Hi this is Jim \nHi this is Joe', 'metadata': {'Header 1': 'Foo', 'Header 2': 'Bar'}}
{'content': 'Hi this is Molly', 'metadata': {'Header 1': 'Foo', 'Header 2': 'Baz'}}让我们看一下下面的一些示例。
2.6.1 基本用法
bash
pip install -qU langchain-text-splitters
python
from langchain_text_splitters import MarkdownHeaderTextSplitter
markdown_document = "# Foo\n\n ## Bar\n\nHi this is Jim\n\nHi this is Joe\n\n ### Boo \n\n Hi this is Lance \n\n ## Baz\n\n Hi this is Molly"
headers_to_split_on = [
("#", "Header 1"),
("##", "Header 2"),
("###", "Header 3"),
]
markdown_splitter = MarkdownHeaderTextSplitter(headers_to_split_on)
md_header_splits = markdown_splitter.split_text(markdown_document)
md_header_splits
python
[Document(metadata={'Header 1': 'Foo', 'Header 2': 'Bar'}, page_content='Hi this is Jim \nHi this is Joe'),
Document(metadata={'Header 1': 'Foo', 'Header 2': 'Bar', 'Header 3': 'Boo'}, page_content='Hi this is Lance'),
Document(metadata={'Header 1': 'Foo', 'Header 2': 'Baz'}, page_content='Hi this is Molly')]
python
type(md_header_splits[0])
python
langchain_core.documents.base.Document默认情况下,MarkdownHeaderTextSplitter会从输出块的内容中剥离拆分的标题。可以通过设置strip_headers = False来禁用此功能。
python
markdown_splitter = MarkdownHeaderTextSplitter(headers_to_split_on, strip_headers=False)
md_header_splits = markdown_splitter.split_text(markdown_document)
md_header_splits
python
[Document(metadata={'Header 1': 'Foo', 'Header 2': 'Bar'}, page_content='# Foo \n## Bar \nHi this is Jim \nHi this is Joe'),
Document(metadata={'Header 1': 'Foo', 'Header 2': 'Bar', 'Header 3': 'Boo'}, page_content='### Boo \nHi this is Lance'),
Document(metadata={'Header 1': 'Foo', 'Header 2': 'Baz'}, page_content='## Baz \nHi this is Molly')]MarkdownHeaderTextSplitter默认会去掉空格和换行。要保留Markdown文档的原始格式,请查看ExperimentalMarkdownSyntaxTextSplitter。
2.6.2 如何返回Markdown行作为单独文档
默认情况下,MarkdownHeaderTextSplitter根据在headers_to_split_on中指定的标题聚合行。我们可以通过指定return_each_line来禁用此功能。
python
markdown_splitter = MarkdownHeaderTextSplitter(
headers_to_split_on,
return_each_line=True,
)
md_header_splits = markdown_splitter.split_text(markdown_document)
md_header_splits
python
[Document(metadata={'Header 1': 'Foo', 'Header 2': 'Bar'}, page_content='Hi this is Jim'),
Document(metadata={'Header 1': 'Foo', 'Header 2': 'Bar'}, page_content='Hi this is Joe'),
Document(metadata={'Header 1': 'Foo', 'Header 2': 'Bar', 'Header 3': 'Boo'}, page_content='Hi this is Lance'),
Document(metadata={'Header 1': 'Foo', 'Header 2': 'Baz'}, page_content='Hi this is Molly')]注意,这里标题信息在每个文档的元数据中保留。
2.6.3 如何约束块大小:双分割器
MarkdownHeaderTextSplitter + RecursiveCharacterTextSplitter
在每个markdown组内,我们可以应用任何我们想要的文本分割器,例如RecursiveCharacterTextSplitter,它允许进一步控制块大小。
python
markdown_document = "# Intro \n\n ## History \n\n Markdown[9] is a lightweight markup language for creating formatted text using a plain-text editor. John Gruber created Markdown in 2004 as a markup language that is appealing to human readers in its source code form.[9] \n\n Markdown is widely used in blogging, instant messaging, online forums, collaborative software, documentation pages, and readme files. \n\n ## Rise and divergence \n\n As Markdown popularity grew rapidly, many Markdown implementations appeared, driven mostly by the need for \n\n additional features such as tables, footnotes, definition lists,[note 1] and Markdown inside HTML blocks. \n\n #### Standardization \n\n From 2012, a group of people, including Jeff Atwood and John MacFarlane, launched what Atwood characterised as a standardisation effort. \n\n ## Implementations \n\n Implementations of Markdown are available for over a dozen programming languages."
python
headers_to_split_on = [
("#", "Header 1"),
("##", "Header 2"),
]
# MD splits
markdown_splitter = MarkdownHeaderTextSplitter(
headers_to_split_on=headers_to_split_on, strip_headers=False
)
md_header_splits = markdown_splitter.split_text(markdown_document)
# Char-level splits
from langchain_text_splitters import RecursiveCharacterTextSplitter
chunk_size = 250
chunk_overlap = 30
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=chunk_size, chunk_overlap=chunk_overlap
)
# Split
splits = text_splitter.split_documents(md_header_splits)
splits
python
[Document(metadata={'Header 1': 'Intro', 'Header 2': 'History'}, page_content='# Intro \n## History \nMarkdown[9] is a lightweight markup language for creating formatted text using a plain-text editor. John Gruber created Markdown in 2004 as a markup language that is appealing to human readers in its source code form.[9]'),
Document(metadata={'Header 1': 'Intro', 'Header 2': 'History'}, page_content='Markdown is widely used in blogging, instant messaging, online forums, collaborative software, documentation pages, and readme files.'),
Document(metadata={'Header 1': 'Intro', 'Header 2': 'Rise and divergence'}, page_content='## Rise and divergence \nAs Markdown popularity grew rapidly, many Markdown implementations appeared, driven mostly by the need for \nadditional features such as tables, footnotes, definition lists,[note 1] and Markdown inside HTML blocks.'),
Document(metadata={'Header 1': 'Intro', 'Header 2': 'Rise and divergence'}, page_content='#### Standardization \nFrom 2012, a group of people, including Jeff Atwood and John MacFarlane, launched what Atwood characterised as a standardisation effort.'),
Document(metadata={'Header 1': 'Intro', 'Header 2': 'Implementations'}, page_content='## Implementations \nImplementations of Markdown are available for over a dozen programming languages.')]2.6.4 故障排除:chunk_overlap似乎不适用
在基于标题的拆分(例如,MarkdownHeaderTextSplitter)后,使用split_documents(docs)(而不是split_text)以便在每个部分内应用重叠,并在块上保留每个部分的元数据(标题)。
重叠仅在单个部分超过chunk_size并拆分为多个块时出现。
重叠不会跨越部分/文档边界(例如,# H1 → ## H2)。
如果标题成为一个很小的第一个块,请考虑将strip_headers设置为True,以便标题行不会成为单独的块。
如果您的文本缺少换行/空格,请在分隔符中保留一个后备"",以便分割器仍然可以分割并应用重叠。
2.7 按JSON 进行分割
文档:Split JSON data - Docs by LangChain
此 JSON 分割器在允许控制块大小的同时分割 JSON 数据。它以深度优先的方式遍历 JSON 数据,并构建较小的 JSON 块。它尝试保持嵌套的 JSON 对象完整,但如果需要将块大小保持在 min_chunk_size 和 max_chunk_size 之间,则会进行拆分。
如果值不是嵌套的 JSON,而是非常大的字符串,则字符串不会被拆分。如果需要对块大小进行严格限制,可以考虑将其与递归文本分割器组合使用。还有一个可选的预处理步骤,通过首先将列表转换为 JSON(字典),然后作为这样的内容进行拆分。
2.7.1 基本使用
指定 max_chunk_size 以限制块大小:
python
from langchain_text_splitters import RecursiveJsonSplitter
splitter = RecursiveJsonSplitter(max_chunk_size=300)要获取 JSON 块,请使用 .split_json 方法:
python
# 递归分割 JSON 数据 - 如果需要访问/操作较小的 JSON 块
json_chunks = splitter.split_json(json_data=json_data)
for chunk in json_chunks[:3]:
print(chunk)示例输出:
json
{'openapi': '3.1.0', 'info': {'title': 'LangSmith', 'version': '0.1.0'}, 'servers': [{'url': 'https://api.smith.langchain.com', 'description': 'LangSmith API endpoint.'}]}
{'paths': {'/api/v1/sessions/{session_id}': {'get': {'tags': ['tracer-sessions'], 'summary': 'Read Tracer Session', 'description': 'Get a specific session.', 'operationId': 'read_tracer_session_api_v1_sessions__session_id__get'}}}}
{'paths': {'/api/v1/sessions/{session_id}': {'get': {'security': [{'API Key': []}, {'Tenant ID': []}, {'Bearer Auth': []}]}}}}要获取 LangChain 文档对象,请使用 .create_documents 方法:
python
# 分割器还可以输出文档
docs = splitter.create_documents(texts=[json_data])
for doc in docs[:3]:
print(doc)示例输出:
json
page_content='{"openapi": "3.1.0", "info": {"title": "LangSmith", "version": "0.1.0"}, "servers": [{"url": "https://api.smith.langchain.com", "description": "LangSmith API endpoint."}]}'
page_content='{"paths": {"/api/v1/sessions/{session_id}": {"get": {"tags": ["tracer-sessions"], "summary": "Read Tracer Session", "description": "Get a specific session.", "operationId": "read_tracer_session_api_v1_sessions__session_id__get"}}}}'
page_content='{"paths": {"/api/v1/sessions/{session_id}": {"get": {"security": [{"API Key": []}, {"Tenant ID": []}, {"Bearer Auth": []}]}}}}'或使用 .split_text 直接获取字符串内容:
python
texts = splitter.split_text(json_data=json_data)
print(texts[0])
print(texts[1])示例输出:
json
{"openapi": "3.1.0", "info": {"title": "LangSmith", "version": "0.1.0"}, "servers": [{"url": "https://api.smith.langchain.com", "description": "LangSmith API endpoint."}]}
{"paths": {"/api/v1/sessions/{session_id}": {"get": {"tags": ["tracer-sessions"], "summary": "Read Tracer Session", "description": "Get a specific session.", "operationId": "read_tracer_session_api_v1_sessions__session_id__get"}}}}2.7.2 如何管理列表内容的块大小
请注意,在此示例中,其中一个块的大小大于指定的 max_chunk_size 300。查看一个较大的块时,我们看到有一个列表对象:
python
print([len(text) for text in texts][:10])
print()
print(texts[3])输出示例:
json
[171, 231, 126, 469, 210, 213, 237, 271, 191, 232]
{"paths": {"/api/v1/sessions/{session_id}": {"get": {"parameters": [{"name": "session_id", "in": "path", "required": true, "schema": {"type": "string", "format": "uuid", "title": "Session Id"}}, {"name": "include_stats", "in": "query", "required": false, "schema": {"type": "boolean", "default": false, "title": "Include Stats"}}, {"name": "accept", "in": "header", "required": false, "schema": {"anyOf": [{"type": "string"}, {"type": "null"}], "title": "Accept"}}]}}}}JSON 分割器默认不分割列表。指定 convert_lists=True 以预处理 JSON,将列表内容转换为字典,键值对为索引:项:
python
texts = splitter.split_text(json_data=json_data, convert_lists=True)让我们看看块的大小。现在它们都在最大值之下:
python
print([len(text) for text in texts][:10])输出示例:
json
[176, 236, 141, 203, 212, 221, 210, 213, 242, 291]列表已被转换为字典,但即使拆分为多个块,仍保留所有必要的上下文信息:
python
print(texts[1])输出示例:
json
{"paths": {"/api/v1/sessions/{session_id}": {"get": {"tags": {"0": "tracer-sessions"}, "summary": "Read Tracer Session", "description": "Get a specific session.", "operationId": "read_tracer_session_api_v1_sessions__session_id__get"}}}}我们还可以查看文档:
python
docs[1]输出示例:
json
Document(page_content='{"paths": {"/api/v1/sessions/{session_id}": {"get": {"tags": ["tracer-sessions"], "summary": "Read Tracer Session", "description": "Get a specific session.", "operationId": "read_tracer_session_api_v1_sessions__session_id__get"}}}}')2.8 代码分割器
Splitting code - Docs by LangChain
这里只辨识python的代码
RecursiveCharacterTextSplitter 包含用于在特定编程语言中拆分文本的预构建分隔符列表。支持的语言存储在 langchain_text_splitters.Language 枚举中,包括:
- cpp
- go
- java
- kotlin
- js
- ts
- php
- proto
- python
- rst
- ruby
- rust
- scala
- swift
- markdown
- latex
- html
- sol
- csharp
- cobol
- c
- lua
- perl
- haskell
要查看给定语言的分隔符列表,请将该枚举中的值传递给 RecursiveCharacterTextSplitter.get_separators_for_language。
2.8.1 Python 示例:
python
PYTHON_CODE = """
def hello_world():
print("Hello, World!")
# Call the function
hello_world()
"""
python_splitter = RecursiveCharacterTextSplitter.from_language(
language=Language.PYTHON, chunk_size=50, chunk_overlap=0
)
python_docs = python_splitter.create_documents([PYTHON_CODE])
python_docs输出:
[Document(metadata={}, page_content='def hello_world():\n print("Hello, World!")'),
Document(metadata={}, page_content='# Call the function\nhello_world()')]2.8.2 HTML 示例
html
html_text = """
<!DOCTYPE html>
<html>
<head>
<title>🦜️🔗 LangChain</title>
<style>
body {
font-family: Arial, sans-serif;
}
h1 {
color: darkblue;
}
</style>
</head>
<body>
<div>
<h1>🦜️🔗 LangChain</h1>
<p>⚡ Building applications with LLMs through composability ⚡</p>
</div>
<div>
As an open-source project in a rapidly developing field, we are extremely open to contributions.
</div>
</body>
</html>
"""
html_splitter = RecursiveCharacterTextSplitter.from_language(
language=Language.HTML, chunk_size=60, chunk_overlap=0
)
html_docs = html_splitter.create_documents([html_text])
html_docs输出:
[Document(metadata={}, page_content='<!DOCTYPE html>\n<html>'),
Document(metadata={}, page_content='<head>\n <title>🦜️🔗 LangChain</title>'),
Document(metadata={}, page_content='<style>\n body {\n font-family: Aria'),
Document(metadata={}, page_content='l, sans-serif;\n }\n h1 {'),
Document(metadata={}, page_content='color: darkblue;\n }\n </style>\n </head'),
Document(metadata={}, page_content='>'),
Document(metadata={}, page_content='<body>'),
Document(metadata={}, page_content='<div>\n <h1>🦜️🔗 LangChain</h1>'),
Document(metadata={}, page_content='<p>⚡ Building applications with LLMs through composability ⚡'),
Document(metadata={}, page_content='</p>\n </div>'),
Document(metadata={}, page_content='<div>\n As an open-source project in a rapidly dev'),
Document(metadata={}, page_content='eloping field, we are extremely open to contributions.'),
Document(metadata={}, page_content='</div>\n </body>\n</html>')]2.9 HTML 分割器
Split HTML - Docs by LangChain
将 HTML 文档拆分为可管理的块对于各种文本处理任务(如自然语言处理、搜索索引等)至关重要。在本指南中,我们将探索 LangChain 提供的三种不同文本拆分器,您可以使用它们有效地拆分 HTML 内容:
- HTMLHeaderTextSplitter
- HTMLSectionSplitter
- HTMLSemanticPreservingSplitter
每个拆分器都有独特的特性和用例。本指南将帮助您理解它们之间的差异,为什么您可能会选择其中一个而不是其他,并且如何有效地使用它们。
bash
pip install -qU langchain-text-splitters2.9.1 三个分割器介绍
- 使用 HTMLHeaderTextSplitter 当: 您需要根据其头部层次结构拆分 HTML 文档并保持有关头部的元数据。
- 使用 HTMLSectionSplitter 当: 您需要将文档拆分为更大、更一般的部分,可能基于自定义标签或字体大小。
- 使用 HTMLSemanticPreservingSplitter 当: 您需要将文档拆分为块,同时保留诸如表格和列表等语义元素,确保它们不会被拆分,并且其上下文得以保持。
| 特性 | HTMLHeaderTextSplitter | HTMLSectionSplitter | HTMLSemanticPreservingSplitter |
|---|---|---|---|
| 基于头部拆分 | 是 | 是 | 是 |
| 保留语义元素(表格、列表) | 否 | 否 | 是 |
| 为头部添加元数据 | 是 | 是 | 是 |
| 针对 HTML 标签的自定义处理程序 | 否 | 否 | 是 |
| 保留媒体(图像、视频) | 否 | 否 | 是 |
| 考虑字体大小 | 否 | 是 | 否 |
| 使用 XSLT 转换 | 否 | 是 | 否 |
2.9.1.1 HTMLHeaderTextSplitter
- 描述 : 基于头部标签(如
<h1>,<h2>,<h3>等)拆分 HTML 文本,并为每个与给定块相关的头部添加元数据。 - 功能 :
- 在 HTML 元素级别拆分文本。
- 保留文档结构中编码的上下文丰富信息。
- 可以逐个返回块或组合具有相同元数据的元素。
2.9.1.2 HTMLSectionSplitter
- 描述 : 类似于 HTMLHeaderTextSplitter,但侧重于基于指定标签(如 ,
或自定义定义的部分)拆分 HTML 文档。 - 功能 :
- 使用 XSLT 转换检测和拆分部分。
- 内部使用 RecursiveCharacterTextSplitter 处理大部分。
- 考虑字体大小以确定部分。
2.9.1.3 HTMLSemanticPreservingSplitter
- 描述: 在确保重要元素(如表格、列表和其他 HTML 组件)不跨块拆分的情况下拆分 HTML 内容。
- 功能 :
- 保留表格、列表和其他指定 HTML 元素。
- 允许自定义处理程序处理特定 HTML 标签。
- 确保文档的语义意义得以维持。
2.9.2 示例
示例 HTML 文档
html
html_string = """
<!DOCTYPE html>
<html lang='en'>
<head>
<meta charset='UTF-8'>
<meta name='viewport' content='width=device-width, initial-scale=1.0'>
<title>Fancy Example HTML Page</title>
</head>
<body>
<h1>Main Title</h1>
<p>This is an introductory paragraph with some basic content.</p>
<h2>Section 1: Introduction</h2>
<p>This section introduces the topic. Below is a list:</p>
<ul>
<li>First item</li>
<li>Second item</li>
<li>Third item with <strong>bold text</strong> and <a href='#'>a link</a></li>
</ul>
<h3>Subsection 1.1: Details</h3>
<p>This subsection provides additional details. Here's a table:</p>
<table border='1'>
<thead>
<tr>
<th>Header 1</th>
<th>Header 2</th>
<th>Header 3</th>
</tr>
</thead>
<tbody>
<tr>
<td>Row 1, Cell 1</td>
<td>Row 1, Cell 2</td>
<td>Row 1, Cell 3</td>
</tr>
<tr>
<td>Row 2, Cell 1</td>
<td>Row 2, Cell 2</td>
<td>Row 2, Cell 3</td>
</tr>
</tbody>
</table>
<h2>Section 2: Media Content</h2>
<p>This section contains an image and a video:</p>
<img src='example_image_link.mp4' alt='Example Image'>
<video controls width='250' src='example_video_link.mp4' type='video/mp4'>
Your browser does not support the video tag.
</video>
<h2>Section 3: Code Example</h2>
<p>This section contains a code block:</p>
<pre><code data-lang="html">
<div>
<p>This is a paragraph inside a div.</p>
</div>
</code></pre>
<h2>Conclusion</h2>
<p>This is the conclusion of the document.</p>
</body>
</html>
"""2.9.2.1 使用 HTMLHeaderTextSplitter
HTMLHeaderTextSplitter 是一个"结构感知"文本拆分器,在 HTML 元素级别拆分文本并为每个与给定块相关的头部添加元数据。它可以逐个返回块或组合具有相同元数据的元素,旨在(a)保持相关文本的分组(或多或少)语义,并(b)保留编码在文档结构中的上下文丰富信息。它可以与其他文本拆分器一起用作块处理管道。
python
from langchain_text_splitters import HTMLHeaderTextSplitter
headers_to_split_on = [
("h1", "Header 1"),
("h2", "Header 2"),
("h3", "Header 3"),
]
html_splitter = HTMLHeaderTextSplitter(headers_to_split_on)
html_header_splits = html_splitter.split_text(html_string)
html_header_splits如何从 URL 或 HTML 文件中拆分
要直接从 URL 读取,将 URL 字符串传递给 split_text_from_url 方法。同样,可以将本地 HTML 文件传递给 split_text_from_file 方法。
python
url = "https://plato.stanford.edu/entries/goedel/"
headers_to_split_on = [
("h1", "Header 1"),
("h2", "Header 2"),
("h3", "Header 3"),
("h4", "Header 4"),
]
html_splitter = HTMLHeaderTextSplitter(headers_to_split_on)
html_header_splits = html_splitter.split_text_from_url(url)如何限制块大小
HTMLHeaderTextSplitter 可以与另一个基于字符长度限制的拆分器组合使用,例如 RecursiveCharacterTextSplitter。这可以通过第二个拆分器的 .split_documents 方法完成。
python
from langchain_text_splitters import RecursiveCharacterTextSplitter
chunk_size = 500
chunk_overlap = 30
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=chunk_size, chunk_overlap=chunk_overlap
)
# 拆分
splits = text_splitter.split_documents(html_header_splits)
splits[80:85]2.9.2.2 使用 HTMLSemanticPreservingSplitter
HTMLSemanticPreservingSplitter 旨在在拆分 HTML 内容的同时保留重要元素的语义结构,如表格、列表和其他 HTML 组件。这确保这些元素不会跨块拆分,从而导致上下文相关性的丢失。
python
from langchain_text_splitters import HTMLSemanticPreservingSplitter
headers_to_split_on = [
("h1", "Header 1"),
("h2", "Header 2"),
]
splitter = HTMLSemanticPreservingSplitter(
headers_to_split_on=headers_to_split_on,
max_chunk_size=50,
elements_to_preserve=["table", "ul"],
)
documents = splitter.split_text(html_string)2.9.2.3 使用自定义处理程序
HTMLSemanticPreservingSplitter 允许您为特定 HTML 元素定义自定义处理程序。
python
def custom_iframe_extractor(iframe_tag):
iframe_src = iframe_tag.get("src", "")
return f"[iframe:{iframe_src}]({iframe_src})"
splitter = HTMLSemanticPreservingSplitter(
headers_to_split_on=headers_to_split_on,
max_chunk_size=50,
custom_handlers={"iframe": custom_iframe_extractor},
)限制
HTMLHeaderTextSplitter 可能会错过某些头部,因为它假设头部始终位于其相关文本的上方。
python
url = "https://www.cnn.com/2023/09/25/weather/el-nino-winter-us-climate/index.html"
headers_to_split_on = [
("h1", "Header 1"),
("h2", "Header 2"),
]
html_splitter = HTMLHeaderTextSplitter(headers_to_split_on)
html_header_splits = html_splitter.split_text_from_url(url)
print(html_header_splits[1].page_content[:500])3. 文本嵌入(Embeddings)
3.1 向量搜索简介
向量搜索通过将文本转换为数值向量,利用向量之间的相似度(如余弦相似度)来检索相关文本。LangChain 支持多种嵌入模型,用户可根据需求选择。
3.2 选择嵌入模型
LangChain 集成了多家厂商的嵌入模型,以下是常见选项及安装示例:
| 平台 | 安装命令 | 嵌入模型导入示例 |
|---|---|---|
| OpenAI | pip install -U "langchain-openai" |
python<br>from langchain_openai import OpenAIEmbeddings<br>embeddings = OpenAIEmbeddings(model="text-embedding-3-large")<br> |
| Azure | 同 OpenAI | python<br>from langchain_openai import AzureOpenAIEmbeddings<br>embeddings = AzureOpenAIEmbeddings(azure_endpoint=..., azure_deployment=..., openai_api_version=...)<br> |
| Google Gemini | pip install -qU langchain-google-genai |
python<br>from langchain_google_genai import GoogleGenerativeAIEmbeddings<br>embeddings = GoogleGenerativeAIEmbeddings(model="models/gemini-embedding-001")<br> |
| Google Vertex | pip install -qU langchain-google-vertexai |
python<br>from langchain_google_vertexai import VertexAIEmbeddings<br>embeddings = VertexAIEmbeddings(model="text-embedding-005")<br> |
| AWS | pip install -qU langchain-aws |
python<br>from langchain_aws import BedrockEmbeddings<br>embeddings = BedrockEmbeddings(model_id="amazon.titan-embed-text-v2:0")<br> |
| HuggingFace | pip install -qU langchain-huggingface |
python<br>from langchain_huggingface import HuggingFaceEmbeddings<br>embeddings = HuggingFaceEmbeddings(model_name="sentence-transformers/all-mpnet-base-v2")<br> |
| Ollama | pip install -qU langchain-ollama |
python<br>from langchain_ollama import OllamaEmbeddings<br>embeddings = OllamaEmbeddings(model="llama3")<br> |
| Cohere | pip install -qU langchain-cohere |
python<br>from langchain_cohere import CohereEmbeddings<br>embeddings = CohereEmbeddings(model="embed-english-v3.0")<br> |
| MistralAI | pip install -qU langchain-mistralai |
python<br>from langchain_mistralai import MistralAIEmbeddings<br>embeddings = MistralAIEmbeddings(model="mistral-embed")<br> |
| Nomic | pip install -qU langchain-nomic |
python<br>from langchain_nomic import NomicEmbeddings<br>embeddings = NomicEmbeddings(model="nomic-embed-text-v1.5")<br> |
| NVIDIA | pip install -qU langchain-nvidia-ai-endpoints |
python<br>from langchain_nvidia_ai_endpoints import NVIDIAEmbeddings<br>embeddings = NVIDIAEmbeddings(model="NV-Embed-QA")<br> |
| Voyage AI | pip install -qU langchain-voyageai |
python<br>from langchain_voyageai import VoyageAIEmbeddings<br>embeddings = VoyageAIEmbeddings(model="voyage-3")<br> |
| IBM watsonx | pip install -qU langchain-ibm |
python<br>from langchain_ibm import WatsonxEmbeddings<br>embeddings = WatsonxEmbeddings(model_id="ibm/slate-125m-english-rtrvr", url="https://us-south.ml.cloud.ibm.com", project_id="<WATSONX PROJECT_ID>")<br> |
| Fake | pip install -qU langchain-core |
python<br>from langchain_core.embeddings import DeterministicFakeEmbedding<br>embeddings = DeterministicFakeEmbedding(size=4096)<br> |
当然我试用的都不是上面的,需要的是qwen的模型,所以有两个方式:
这里我试用了datascope,需要先安装:
pip install dashscope下载后,可以使用的是:
from langchain_community.embeddings import DashScopeEmbeddings
embeddings = DashScopeEmbeddings(
model="text-embedding-v1", dashscope_api_key="your-dashscope-api-key"
)
text = "This is a test document."
query_result = embeddings.embed_query(text)
print(query_result)
doc_results = embeddings.embed_documents(["foo"])
print(doc_results)3.3 生成嵌入向量示例
python
vector_1 = embeddings.embed_query(all_splits[0].page_content)
vector_2 = embeddings.embed_query(all_splits[1].page_content)
assert len(vector_1) == len(vector_2)
print(f"Generated vectors of length {len(vector_1)}\n")
print(vector_1[:10])代码解读
- 对两个文本块分别生成向量表示。
- 断言两个向量长度相同,表明嵌入维度固定。
- 打印向量长度及前10个数值,方便观察。
示例输出:
Generated vectors of length 1536
[-0.008586574345827103, -0.03341241180896759, -0.008936782367527485, -0.0036674530711025, 0.010564599186182022, 0.009598285891115665, -0.028587326407432556, -0.015824200585484505, 0.0030416189692914486, -0.012899317778646946]4. 向量存储(Vector Stores)
4.1 向量存储简介
VectorStore 是一种数据结构,支持将文本及其嵌入向量存储起来,并能高效地基于向量相似度进行检索。它通常结合嵌入模型使用。
LangChain 支持多种向量存储技术,既有本地内存实现,也有云服务和数据库集成。
4.2 常见向量存储集成及示例
| 向量存储技术 | 安装命令 | 示例代码 |
|---|---|---|
| 内存存储(In-memory) | pip install -U "langchain-core" |
python<br>from langchain_core.vectorstores import InMemoryVectorStore<br>vector_store = InMemoryVectorStore(embeddings)<br> |
| AstraDB | pip install -U "langchain-astradb" |
python<br>from langchain_astradb import AstraDBVectorStore<br>vector_store = AstraDBVectorStore(embedding=embeddings, api_endpoint=..., collection_name="astra_vector_langchain", token=..., namespace=... )<br> |
| Chroma | pip install -qU langchain-chroma |
python<br>from langchain_chroma import Chroma<br>vector_store = Chroma(collection_name="example_collection", embedding_function=embeddings, persist_directory="./chroma_langchain_db")<br> |
| FAISS | pip install -qU langchain-community faiss-cpu |
python<br>import faiss<br>from langchain_community.docstore.in_memory import InMemoryDocstore<br>from langchain_community.vectorstores import FAISS<br>embedding_dim = len(embeddings.embed_query("hello world"))<br>index = faiss.IndexFlatL2(embedding_dim)<br>vector_store = FAISS(embedding_function=embeddings, index=index, docstore=InMemoryDocstore(), index_to_docstore_id={})<br> |
| Milvus | pip install -qU langchain-milvus |
python<br>from langchain_milvus import Milvus<br>URI = "./milvus_example.db"<br>vector_store = Milvus(embedding_function=embeddings, connection_args={"uri": URI}, index_params={"index_type": "FLAT", "metric_type": "L2"})<br> |
| MongoDB | pip install -qU langchain-mongodb |
python<br>from langchain_mongodb import MongoDBAtlasVectorSearch<br>vector_store = MongoDBAtlasVectorSearch(embedding=embeddings, collection=MONGODB_COLLECTION, index_name=ATLAS_VECTOR_SEARCH_INDEX_NAME, relevance_score_fn="cosine")<br> |
| PGVector | pip install -qU langchain-postgres |
python<br>from langchain_postgres import PGVector<br>vector_store = PGVector(embeddings=embeddings, collection_name="my_docs", connection="postgresql+psycopg://...")<br> |
| PGVectorStore | pip install -qU langchain-postgres |
python<br>from langchain_postgres import PGEngine, PGVectorStore<br>pg_engine = PGEngine.from_connection_string(url="postgresql+psycopg://...")<br>vector_store = PGVectorStore.create_sync(engine=pg_engine, table_name='test_table', embedding_service=embedding)<br> |
| Pinecone | pip install -qU langchain-pinecone |
python<br>from langchain_pinecone import PineconeVectorStore<br>from pinecone import Pinecone<br>pc = Pinecone(api_key=...)<br>index = pc.Index(index_name)<br>vector_store = PineconeVectorStore(embedding=embeddings, index=index)<br> |
| Qdrant | pip install -qU langchain-qdrant |
python<br>from qdrant_client.models import Distance, VectorParams<br>from langchain_qdrant import QdrantVectorStore<br>from qdrant_client import QdrantClient<br>client = QdrantClient(":memory:")<br>vector_size = len(embeddings.embed_query("sample text"))<br>if not client.collection_exists("test"):<br> client.create_collection(collection_name="test", vectors_config=VectorParams(size=vector_size, distance=Distance.COSINE))<br>vector_store = QdrantVectorStore(client=client, collection_name="test", embedding=embeddings)<br> |
这里我沿用faiss:
pip install -qU langchain-community faiss-cpu使用实例:
import faiss
from langchain_community.docstore.in_memory import InMemoryDocstore
from langchain_community.vectorstores import FAISS
embedding_dim = len(embeddings.embed_query("hello world"))
index = faiss.IndexFlatL2(embedding_dim)
vector_store = FAISS(
embedding_function=embeddings,
index=index,
docstore=InMemoryDocstore(),
index_to_docstore_id={},
)请注意,大多数向量存储实现都允许您连接到现有的向量存储------例如,通过提供客户端、索引名称或其他信息。
4.3 向量存储中添加文档
将分割后的文本块添加到向量存储:
python
ids = vector_store.add_documents(documents=all_splits)代码解读
add_documents方法将文本块及其嵌入向量存储到向量库中,返回对应的文档 ID 列表。
4.4 查询向量存储
向量存储支持多种查询方式:
- 同步和异步查询
- 通过字符串查询或向量查询
- 返回带相似度分数的结果
- 使用最大边际相关性(Maximum Marginal Relevance,MMR)提高结果多样性
示例:基于字符串查询相似文档
python
results = vector_store.similarity_search(
"How many distribution centers does Nike have in the US?"
)
print(results[0])输出示例:
page_content='direct to consumer operations sell products through the following number of retail stores in the United States:
U.S. RETAIL STORES NUMBER
NIKE Brand factory stores 213
NIKE Brand in-line stores (including employee-only stores) 74
Converse stores (including factory stores) 82
TOTAL 369
In the United States, NIKE has eight significant distribution centers. Refer to Item 2. Properties for further information.
2023 FORM 10-K 2' metadata={'page': 4, 'source': '../example_data/nke-10k-2023.pdf', 'start_index': 3125}异步查询示例:
python
results = await vector_store.asimilarity_search("When was Nike incorporated?")
print(results[0])返回带相似度分数的查询:
python
results = vector_store.similarity_search_with_score("What was Nike's revenue in 2023?")
doc, score = results[0]
print(f"Score: {score}\n")
print(doc)输出示例:
Score: 0.23699893057346344
page_content='Table of Contents
FISCAL 2023 NIKE BRAND REVENUE HIGHLIGHTS
The following tables present NIKE Brand revenues disaggregated by reportable operating segment, distribution channel and major product line:
FISCAL 2023 COMPARED TO FISCAL 2022
•NIKE, Inc. Revenues were $51.2 billion in fiscal 2023, which increased 10% and 16% compared to fiscal 2022 on a reported and currency-neutral basis, respectively.
The increase was due to higher revenues in North America, Europe, Middle East & Africa ("EMEA"), APLA and Greater China, which contributed approximately 7, 6,
2 and 1 percentage points to NIKE, Inc. Revenues, respectively.
•NIKE Brand revenues, which represented over 90% of NIKE, Inc. Revenues, increased 10% and 16% on a reported and currency-neutral basis, respectively. This
increase was primarily due to higher revenues in Men's, the Jordan Brand, Women's and Kids' which grew 17%, 35%,11% and 10%, respectively, on a wholesale
equivalent basis.' metadata={'page': 35, 'source': '../example_data/nke-10k-2023.pdf', 'start_index': 0}基于向量查询:
python
embedding = embeddings.embed_query("How were Nike's margins impacted in 2023?")
results = vector_store.similarity_search_by_vector(embedding)
print(results[0])输出示例:
page_content='Table of Contents
GROSS MARGIN
FISCAL 2023 COMPARED TO FISCAL 2022
For fiscal 2023, our consolidated gross profit increased 4% to $22,292 million compared to $21,479 million for fiscal 2022. Gross margin decreased 250 basis points to
43.5% for fiscal 2023 compared to 46.0% for fiscal 2022 due to the following:
*Wholesale equivalent
The decrease in gross margin for fiscal 2023 was primarily due to:
•Higher NIKE Brand product costs, on a wholesale equivalent basis, primarily due to higher input costs and elevated inbound freight and logistics costs as well as
product mix;
•Lower margin in our NIKE Direct business, driven by higher promotional activity to liquidate inventory in the current period compared to lower promotional activity in
the prior period resulting from lower available inventory supply;
•Unfavorable changes in net foreign currency exchange rates, including hedges; and
•Lower off-price margin, on a wholesale equivalent basis.
This was partially offset by:' metadata={'page': 36, 'source': '../example_data/nke-10k-2023.pdf', 'start_index': 0}5. 检索器(Retrievers)
5.1 检索器概念
虽然 VectorStore 并不是 Runnable 子类,LangChain 的 Retriever 是 Runnable,实现了统一的调用接口(如同步/异步的 invoke 和 batch 方法)。检索器不仅可以基于向量存储,也可以连接非向量存储的数据源(如外部 API)。
5.2 自定义简单检索器示例
python
from typing import List
from langchain_core.documents import Document
from langchain_core.runnables import chain
@chain
def retriever(query: str) -> List[Document]:
return vector_store.similarity_search(query, k=1)
retriever.batch(
[
"How many distribution centers does Nike have in the US?",
"When was Nike incorporated?",
],
)代码解读
- 使用
@chain装饰器将函数包装成可批量调用的 Runnable。 - 函数基于向量存储的
similarity_search方法返回最相似的 1 条文档。 batch方法支持批量查询。
示例输出:
[[Document(metadata={'page': 4, 'source': '../example_data/nke-10k-2023.pdf', 'start_index': 3125}, page_content='direct to consumer operations sell products ...')],
[Document(metadata={'page': 3, 'source': '../example_data/nke-10k-2023.pdf', 'start_index': 0}, page_content='Table of Contents\nPART I\nITEM 1. BUSINESS\nGENERAL\nNIKE, Inc. was incorporated in 1967 ...')]]5.3 使用 VectorStore 自带的检索器
VectorStore 提供 as_retriever 方法,生成一个 VectorStoreRetriever,可以配置搜索类型和参数。
示例:
python
retriever = vector_store.as_retriever(
search_type="similarity",
search_kwargs={"k": 1},
)
retriever.batch(
[
"How many distribution centers does Nike have in the US?",
"When was Nike incorporated?",
],
)代码解读
- 通过
as_retriever创建检索器,指定搜索类型为相似度搜索,返回最相似的 1 条结果。 - 支持批量查询。
检索器支持三种搜索类型:
| 搜索类型 | 说明 |
|---|---|
| similarity | 基于向量相似度的标准搜索,默认类型 |
| mmr | 最大边际相关性搜索,平衡相似度和结果多样性 |
| similarity_score_threshold | 通过相似度阈值过滤检索结果 |
检索器可以方便地集成进更复杂的应用,如结合检索结果和问题生成回答的 RAG 应用。更多内容可参考 LangChain 的 RAG 教程。
7 实际案例:构建基于 LangChain 的 RAG 代理
7.1 Agentic RAG 案例
大型语言模型(LLM)最强大的应用之一是构建复杂的问答(Q&A)聊天机器人。这类应用能针对特定的源信息回答问题。它们采用一种叫做"检索增强生成"(Retrieval Augmented Generation,简称 RAG)的技术。本文教程将演示如何基于非结构化文本数据源,构建一个简单的问答应用。主要演示内容包括:
- 一个使用简单工具执行搜索的 RAG 代理(agent),适合通用场景。
- 一个两步式的 RAG 链(chain),每个查询仅调用一次 LLM,速度快且效果好,适合简单查询。
本指南将基于网站内容构建一个问答应用。示例网站是 Lilian Weng 撰写的博客文章《LLM Powered Autonomous Agents》(链接),我们可以针对文章内容提问。通过约 40 行代码即可完成索引管道和 RAG 链的构建。
需要安装:
# 大模型 - qwen
pip install langchain_qwq
# 分割
pip install langchain langchain-text-splitters langchain-community bs4
# 向量化模型 - qwen
pip install dashscope
# faiss
pip install -qU langchain-community faiss-cpu本节是语义搜索教程内容的简化版本。如果您的数据已经被索引并可以搜索(即,您有一个执行搜索的函数),或者如果您对文档加载程序、嵌入和向量存储感到满意,请随意跳过下一节的检索和生成。
索引通常按以下方式工作:
- 加载:首先,我们需要加载数据。这是通过文档加载程序完成的。
- 拆分:文本拆分器将大型文档拆分为较小的块。这对于索引数据和将其传递给模型都很有用,因为大型块更难搜索,并且无法适应模型的有限上下文窗口。
- 存储:我们需要一个地方来存储和索引我们的拆分,以便稍后可以搜索。这通常通过使用向量存储和嵌入模型来完成。
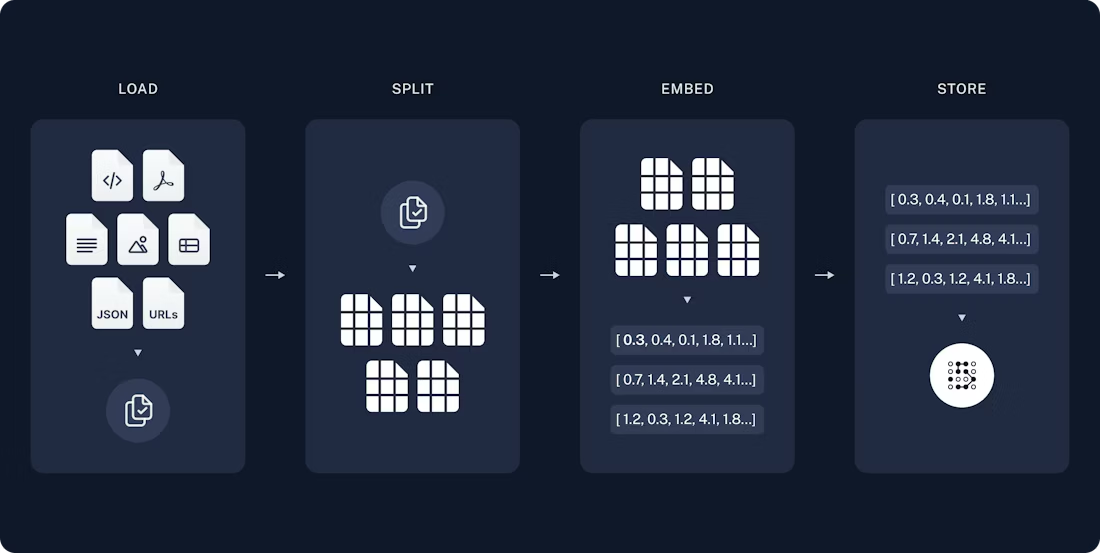
我们首先需要加载博客文章的内容。我们可以使用文档加载程序来完成此操作,它是从源加载数据并返回文档对象列表的对象。在这种情况下,我们将使用 WebBaseLoader,它使用 urllib 从网页 URL 加载 HTML,并使用 BeautifulSoup 将其解析为文本。我们可以通过将参数传递给 BeautifulSoup 解析器来自定义 HTML -> 文本解析。
以下是完整代码示例分成两段
预加载项目:
python
# 加载模型
from langchain_qwq import ChatQwQ
apikey = 'sk-xxxx'
base_url='https://dashscope.aliyuncs.com/compatible-mode/v1'
import os
os.environ["DASHSCOPE_API_KEY"] = apikey
os.environ["DASHSCOPE_API_BASE"] = base_url
model = ChatQwQ(model="qwen-plus",api_key = apikey)
response = model.invoke("Hello, how are you?")
print(response.content)
# 加载向量化模型
from langchain_community.embeddings import DashScopeEmbeddings
embeddings = DashScopeEmbeddings(
model="text-embedding-v1", dashscope_api_key=apikey
)
text = "This is a test document."
query_result = embeddings.embed_query(text)
print(query_result)RAG 应用通常按以下方式工作:
- 检索:根据用户输入,使用检索器从存储中检索相关的分段内容。
- 生成:模型使用包含问题和检索到的数据的提示来生成答案。
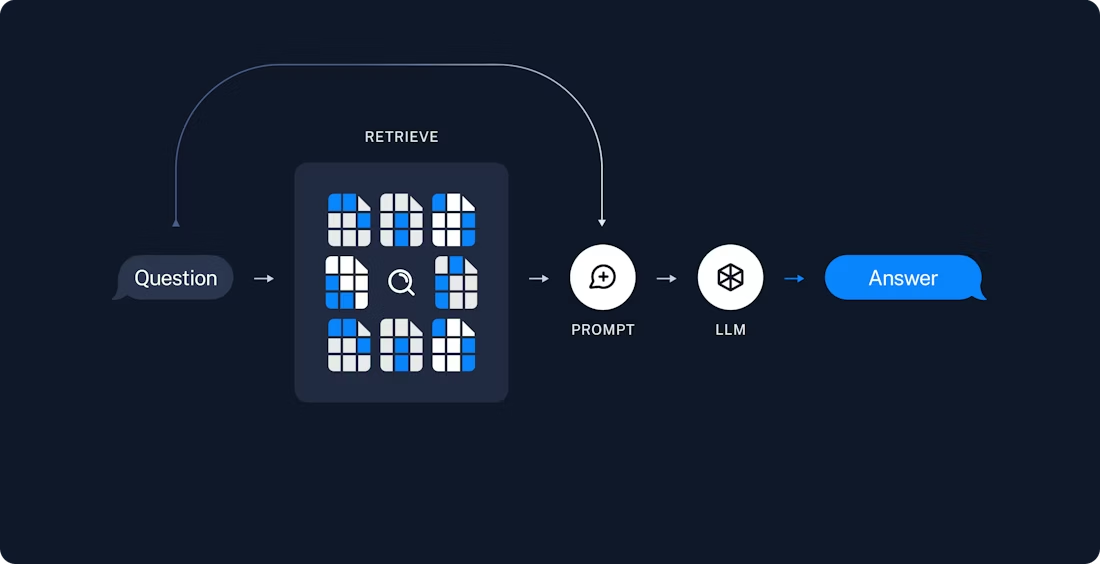
另外一段是解析我自己的博客URL + 问答
python
import bs4
from langchain.agents import AgentState, create_agent
from langchain_community.document_loaders import WebBaseLoader
from langchain.messages import MessageLikeRepresentation
from langchain_text_splitters import RecursiveCharacterTextSplitter
# 加载并分块博客内容
web_url = 'https://blog.csdn.net/sinat_26917383/article/details/154491852'
loader = WebBaseLoader(
web_paths=(web_url,),
bs_kwargs=dict(
parse_only=bs4.SoupStrainer(
class_=("blog-content-box")
)
),
)
docs = loader.load()
docs
# chunk
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
all_splits = text_splitter.split_documents(docs)
print(all_splits[10].page_content)
# 将分块文档加入向量存储
document_ids = vector_store.add_documents(documents=all_splits)
print(document_ids[:3])
# 构建用于检索上下文的工具
from langchain.tools import tool
@tool(response_format="content_and_artifact")
def retrieve_context(query: str):
"""检索帮助回答查询的信息"""
retrieved_docs = vector_store.similarity_search(query, k=2)
serialized = "\n\n".join(
(f"Source: {doc.metadata}\nContent: {doc.page_content}")
for doc in retrieved_docs
)
return serialized, retrieved_docs
tools = [retrieve_context]
# 可选自定义提示
prompt = (
"你可以使用一个工具从博客文章中检索上下文。"
"请用该工具帮助回答用户查询。"
)
agent = create_agent(model, tools, system_prompt=prompt)
query = "什么是TimeGPT?"
for step in agent.stream(
{"messages": [{"role": "user", "content": query}]},
stream_mode="values",
):
step["messages"][-1].pretty_print()
输出示例:
================================ Human Message =================================
什么是TimeGPT?
================================== Ai Message ==================================
Tool Calls:
retrieve_context (call_c36fc7d342d1471e852687)
Call ID: call_c36fc7d342d1471e852687
Args:
query: TimeGPT
================================= Tool Message =================================
Name: retrieve_context
Source: {'source': 'https://blog.csdn.net/sinat_26917383/article/details/154491852'}
Content: 简单来说,它在多种多样的时间序列数据上进行了训练,这就是为什么它几乎可以应对任何给定的数据。
TimeGPT的主要特点包括:
✅ 易于使用:通过简单的API访问,因此用户可以发送他们的数据并获得预测结果。
✅ 泛化能力:跨行业工作,无需构建单独的模型。
✅ 灵活性:可用于预测之外的任务,如异常检测或情景模拟。
使TimeGPT特别令人兴奋的是它的可访问性。没有专门数据科学团队的公司仍然可以从先进的预测中受益。对于专家来说,它通过提供一个强大的基线模型来节省大量时间,如果需要,可以进一步调整。
它实际上标志着从定制的、针对特定问题的预测向通用、可扩展的预测解决方案的转变。
但真正的问题是:它能兑现承诺吗?
这就是我们要找出的!
4 TimeGPT实战!
既然我们已经讨论了基础模型的一般情况以及用于时间序列预测的情况,让我们看看TimeGPT的表现如何。
我们将在之前文章中使用的相同数据集上测试它,以便我们可以将结果与其他模型进行比较。
为了使用TimeGPT,您需要创建一个帐户并从Nixtla获取API密钥。它在一段时间内是免费的,大约一个月。
4.1 航空公司数据集
让我们从我们在这篇文章中使用过的"airline-passengers"数据集开始:
这是一个相当简单的数据集,通常用于初学者的预测。使用SARIMA,我们已经实现了预测最后6个月的目标,RMSE约为15名乘客:
Source: {'source': 'https://blog.csdn.net/sinat_26917383/article/details/154491852'}
Content: 简单来说,它在多种多样的时间序列数据上进行了训练,这就是为什么它几乎可以应对任何给定的数据。
TimeGPT的主要特点包括:
✅ 易于使用:通过简单的API访问,因此用户可以发送他们的数据并获得预测结果。
✅ 泛化能力:跨行业工作,无需构建单独的模型。
✅ 灵活性:可用于预测之外的任务,如异常检测或情景模拟。
使TimeGPT特别令人兴奋的是它的可访问性。没有专门数据科学团队的公司仍然可以从先进的预测中受益。对于专家来说,它通过提供一个强大的基线模型来节省大量时间,如果需要,可以进一步调整。
它实际上标志着从定制的、针对特定问题的预测向通用、可扩展的预测解决方案的转变。
但真正的问题是:它能兑现承诺吗?
这就是我们要找出的!
4 TimeGPT实战!
既然我们已经讨论了基础模型的一般情况以及用于时间序列预测的情况,让我们看看TimeGPT的表现如何。
我们将在之前文章中使用的相同数据集上测试它,以便我们可以将结果与其他模型进行比较。
为了使用TimeGPT,您需要创建一个帐户并从Nixtla获取API密钥。它在一段时间内是免费的,大约一个月。
4.1 航空公司数据集
让我们从我们在这篇文章中使用过的"airline-passengers"数据集开始:
这是一个相当简单的数据集,通常用于初学者的预测。使用SARIMA,我们已经实现了预测最后6个月的目标,RMSE约为15名乘客:
================================== Ai Message ==================================
TimeGPT 是一种基于大型基础模型的时间序列预测工具,经过多种时间序列数据的训练,能够广泛适用于不同行业和场景的预测任务。其主要特点包括:
1. **易于使用**:通过简单的 API 接口访问,用户可以轻松上传数据并获取预测结果。
2. **泛化能力强**:无需为每个特定问题构建单独的模型,即可跨行业工作。
3. **灵活性高**:除了时间序列预测外,还可用于异常检测、情景模拟等任务。
TimeGPT 的一个重要优势是其可访问性------即使是没有专业数据科学团队的企业也能利用先进的预测技术。对于数据科学专家而言,它可以作为一个强大的基线模型,大幅节省建模时间,并在必要时进行进一步优化。
总的来说,TimeGPT 标志着从传统的定制化预测模型向通用、可扩展的预测解决方案的转变。要使用 TimeGPT,用户需要从 Nixtla 平台注册账户并获取 API 密钥(目前提供一段时间的免费试用)。retrieve_context中涉及到以下的步骤,比如我咨询:
"什么是大模型?"
接下来演示具体步骤:
- 第一步骤:Agent 根据用户问题"什么是大模型",生成第一个查询,去知识库里检索与"大模型定义"相关的文本。找到一段权威或通用的解释文本,比如:
"大模型是指参数规模达到数十亿甚至数千亿的深度学习模型,通常用于自然语言处理、计算机视觉等领域。"
- 第二步骤:Agent 得到这段定义文本,知道了大模型的基本含义和特点。
- 第三步骤:Agent 基于第一次查询得到的定义,自动生成第二个查询,目的是寻找关于"大模型"的常见扩展信息,比如:
大模型的训练技巧、大模型的应用场景等 - 第四步骤:Agent 将第一步的基本定义和第二步的扩展信息整合,生成一个更完整、更详细的回答
整体步骤比较繁琐
7.2 RAG 链
先来对比一下:
Agentic RAG(RAG 代理)与RAG Chains(RAG 链)有什么差别。
| 方面 | Agentic RAG(RAG 代理) | RAG Chains(RAG 链) |
|---|---|---|
| 调用方式 | LLM 根据需要主动调用检索工具,可以多次调用搜索接口。 | 先固定执行一次检索,再一次性调用 LLM 生成答案。 |
| 灵活性 | 高,模型可以根据对话上下文灵活决定何时搜索、搜索什么内容。 | 低,检索步骤固定,不会根据上下文动态调整搜索行为。 |
| 推理调用次数 | 多次调用:一次生成搜索查询,一次或多次调用模型生成回答。 | 只调用一次模型,检索和生成分两步,但只调用一次模型接口。 |
| 响应速度 | 较慢,因为可能多次调用模型和工具。 | 较快,减少模型调用次数,延迟更低。 |
| 搜索次数 | 可能多次搜索,支持复杂的多轮检索。 | 只做一次检索,适合简单查询。 |
| 控制权 | LLM 自主决定是否搜索和如何搜索,可能出现漏搜或过度搜索。 | 由应用逻辑控制,搜索行为固定,更可控。 |
| 适用场景 | 复杂对话、多轮交互、需要动态检索的场景。 | 简单查询、对延迟要求高、检索内容固定的场景。 |
| 实现难度 | 需要设计工具调用和模型交互,调试较复杂。 | 实现较简单,流程固定,易于维护。 |
核心,笔者认为两者的差别,就是是否有反思系统,可能会
RAG 链不再在循环中调用模型,而是进行单次传递。
我们可以通过从代理中删除工具而将检索步骤纳入自定义提示来实现此链:
- 将检索到的相关文档内容整合成上下文信息,构造一个包含这些上下文的系统提示(System Prompt)。
- 将用户的查询和检索到的上下文一起传给语言模型,让模型基于这些信息生成回答。
python
from langchain.agents.middleware import dynamic_prompt, ModelRequest
@dynamic_prompt
def prompt_with_context(request: ModelRequest) -> str:
"""将上下文注入状态消息。"""
last_query = request.state["messages"][-1].text
retrieved_docs = vector_store.similarity_search(last_query)
docs_content = "\n\n".join(doc.page_content for doc in retrieved_docs)
system_message = (
"您是一个有用的助手。请在您的响应中使用以下上下文:"
f"\n\n{docs_content}"
)
return system_message
agent = create_agent(model, tools=[], middleware=[prompt_with_context])
query = "什么是TimeGPT?"
for step in agent.stream(
{"messages": [{"role": "user", "content": query}]},
stream_mode="values",
):
step["messages"][-1].pretty_print()输出的示例:
================================ Human Message =================================
什么是TimeGPT?
================================== Ai Message ==================================
TimeGPT是由Nixtla公司开发的一种**用于时间序列预测的基础模型(Foundation Model)**,它标志着时间序列分析领域的一项重大突破。类似于自然语言处理中的大语言模型(如GPT系列),TimeGPT在大量多样化的时间序列数据上进行了预训练,使其能够"理解"时间模式,并对几乎任何给定的时间序列数据进行准确预测,而无需为每个具体问题单独建模。
### ✅ TimeGPT的核心特点:
1. **易于使用(Easy to Use)**
通过简单的API接口,用户只需上传自己的时间序列数据,就能快速获得预测结果,极大降低了技术门槛。
2. **强大的泛化能力(Generalization Across Domains)**
它在来自不同行业和场景的多种时间序列数据上训练而成,因此可以跨领域工作------无论是销售、金融、气象还是能源数据,都能有效处理,**无需为每种任务构建专门模型**。
3. **灵活性高(Flexibility)**
不仅可用于未来值预测,还可应用于:
- 异常检测(Anomaly Detection)
- 情景模拟与假设分析(What-if Scenarios)
- 数据插补(填补缺失值)
4. **零样本/少样本学习能力(Zero-shot / Few-shot Learning)**
即使没有或仅有少量历史数据,TimeGPT也能基于其预训练知识做出合理预测,这对于新业务或新产品预测尤其有价值。
5. **可访问性强(Accessibility)**
- 对中小企业友好:即使没有专业数据科学团队,也能使用先进预测工具。
- 对专家有用:提供一个强大、可靠的基线模型,节省大量建模时间,后续可根据需要微调。
---
### 🚀 TimeGPT的意义
TimeGPT代表了从传统的"定制化预测模型"向"通用型预测平台"的转变。过去,构建一个高精度的时间序列模型通常需要大量特征工程、参数调优和领域知识;而现在,TimeGPT实现了"即插即用"的预测体验。
> 简单来说:**它就像ChatGPT之于文本生成,是时间序列领域的"通才"模型**。
---
### 🔍 实际表现如何?
文章中通过多个经典数据集测试了TimeGPT的表现,例如:
- **航空乘客数据集(Airline Passengers)**:与传统SARIMA模型相比,TimeGPT在预测未来6个月趋势时表现出色,RMSE相近甚至更优,且无需复杂建模过程。
- **太阳黑子、风速、需求预测等数据集**:展示了其在不同频率、周期性和噪声水平下的稳健性。
---
### 总结一句话:
> **TimeGPT是一个基于大规模预训练的通用时间序列预测模型,让高效、精准的预测变得简单、快捷且可扩展,正在推动时间序列分析进入"大模型时代"。**
是否能完全兑现承诺?实测结果显示:**它不仅能做到,而且已经接近甚至超越许多传统方法,尤其是在效率和通用性方面具有压倒性优势。**7.3 RAG链 与 Agentic RAG 差别在哪?
首先明确一下,Agentic RAG的复杂度在于agent的设置,来观察一下:
# Agentic RAG
create_agent(model, tools, system_prompt=prompt)
# RAG链
create_agent(model, tools=[], middleware=[prompt_with_context])Agent 负责接收用户输入,决定是否调用工具(tool),调用后再综合工具输出和自身能力生成回答。
-
Agentic RAG ,传入了非空的 tools,意味着 Agent 具备调用工具的能力。Agent 会自动尝试"思考-调用工具-再思考"的流程
- 先根据用户问题判断是否需要调用工具。
- 调用工具(比如检索函数)获取辅助信息。
- 再结合工具输出生成最终回答。
- 这就引入了多轮交互和工具调用的复杂流程,导致整体执行步骤和日志较多,看上去"繁琐"。
-
RAG链 ,
tools=[]表示 Agent 没有任何工具可调用,整个过程就是单轮的纯语言模型调用。Agent 不会执行"调用工具"的步骤,直接根据输入和上下文生成回答。middleware可以用来注入检索到的上下(prompt_with_context),相当于提前把辅助信息放进 prompt 里,避免了动态调用工具的复杂流程。- 流程简单,只有一次 LLM 调用。