在大型语言模型(LLM)深度融入各行业的当下,检索增强生成(Retrieval-Augmented Generation,RAG)技术已成为优化 LLM 知识精准度与时效性的核心手段。
它借助'LLM+外部知识库"的组合模式,成功破解了 LLM 存在的知识更新滞后、易产生"幻觉回答"等关键痛点。
但技术的迭代永无止境,RAG 体系也在持续进化。从早期结构固定的传统 RAG,到如今在技术圈备受瞩目的Agentic RAG(智能体驱动型 RAG),RAG 系统正朝着更智能、更灵活、更具解决复杂问题能力的方向发展。
本文将通过深度对比两种 RAG 技术范式,详细拆解 AgenticRAG 如何凭借"智能体"这一核心概念,为 RAG 系统的能力升级开辟新路径。
一、传统 RAG 的核心架构: 简洁与高效并存, * 线性高效的"检索-生成"闭环*
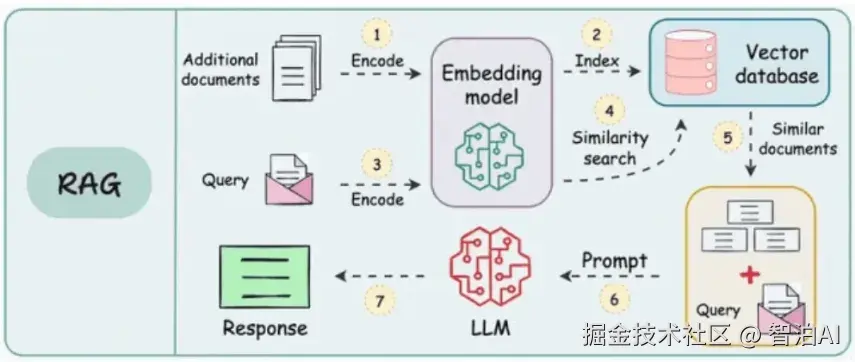
要理解 RAG 技术的演进,首先需要回顾传统 RAG 的基础架构。如上图所示,传统 RAG 的核心优势在于其线性无分支的"检索-生成"流程,整个链路清晰可控,能以较低的成本快速落地。
传统 RAG 的完整工作流程:
1.知识库预处理: 编码与索引(步骤1&2)
系统首先对外部补充文档(Additionaldocuments)进行预处理: 通过嵌入模型(Embedding model)将文档内容转化为计算机可识别的高维向量(即"编码"过程),再将这些向量批量索引(Index)并存储到向量数据库(Vectordatabase)中。
这一步属于"离线准备阶段",通常在系统上线前完成,目的是为后续实时检索提供高效支持。
更多AI大模型学习视频及资源,都在智泊AI。
2.用户查询编码(步骤 3)
当用户输入查询需求(Query)后,系统会使用与知识库编码完全一致的嵌入模型,将用户查询转化为对应的查询向量--这一设计是确保检索结果准确性的关键,避免因模型差异导致语义匹配偏差
3.相似性检索(步骤 4&5)
生成的查询向量会被输入向量数据库,通过相似性搜索算法(如余弦相似度)筛选出与查询语义最贴近的候选文档(Similar documents)。此时,系统完成了"从用户需求到知识库相关内容"的精准匹配。
4.提示构建与答案生成(步骤 6& 7)
检索到的候选文档会作为上下文信息(Context),与用户原始查询整合为一份结构化的提示词(Prompt),随后将这份提示词输入大型语言模型(LLM)。LLM 基于上下文信息和用户需求,最终生成符合要求的回答(Response)
传统 RAG 的核心特性:
优势: 架构简单易懂,开发落地门槛低,无需复杂的决策逻辑;在处理"单轮、明确、无歧义"的问答需求(如"2023 年全球 GDP 总量是多少")时,响应速度快,资源消耗低。
局限: 线性流程决定了其"一步到位"的处理模式,无法应对需要多步推理的复杂需求(如"分析 2023 年全球 GDP 增长的主要驱动因素,并对比 2022 年的变化")。
缺乏对检索结果的评估和修正能力,若检索到无关或错误信息,会直接导致 LLM 生成"幻觉回答"仅依赖向量数据库,无法调用外部工具补充实时或结构化数据。
二、Agentic RAG 的核心突破: 引入"智能体"思维, * 智能体主导"决策-迭代"*
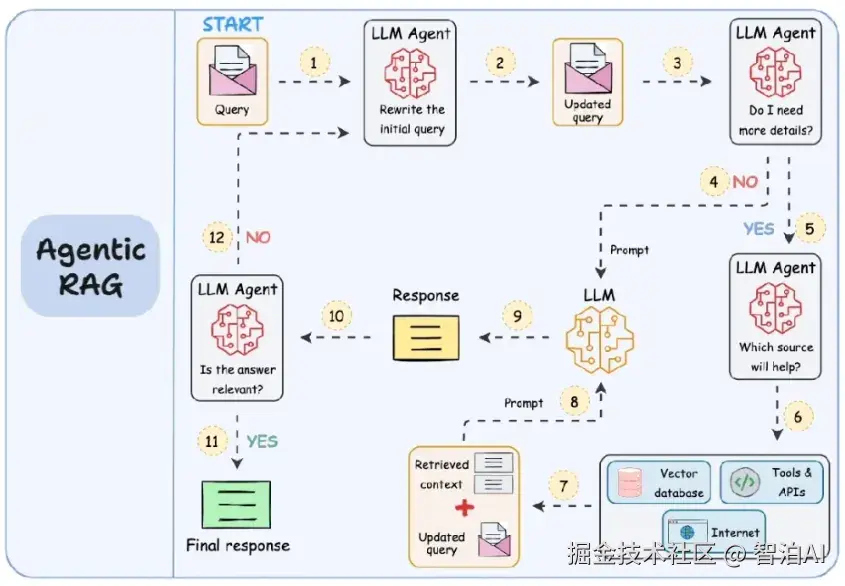
与传统 RAG 的"线性单向流程"不同,Agentic RAG 的核心创新在于引入了"智能体(Agent)"模块--它赋予LLM 自主思考、规划和执行的能力,让 RAG 系统从"被动响应"升级为"主动解决问题"。
如上图所示,Agentic RAG的关键特征体现在循环迭代、动态决策和多工具调用三个方面。
Agentic RAG 的完整工作流程:
1.智能体预处理: 优化查询与初步判断(步骤 1-3)
用户输入初始查询后,不会直接进入检索环节,而是先由 LLM 智能体(LLM Agent)进行处理:
首先对模糊或冗长的查询进行重写优化(例如将"怎么提升公司业绩"改写为"2024 年中小制造企业提升营收的了个核心策略,需包含成本控制和市场拓展维度")。
使其更符合检索需求;随后智能体进行自我评估,判断当前查询是否需要补充外部信息(如"是否需要调用行业报告数据库""是否需要实时搜索最新政策")。
2.动态规划: 工具选择与调用(步骤 4-6)
若智能体判断需要补充信息,会进一步"思考":
"哪些工具能满足当前需求?"--这里的工具不再局限于向量数据库,还可包括互联网搜索引擎(获取实时信息)、结构化数据库(如 SQL 数据库,获取财务数据)、第三方 API(如行业数据接口、天气接口)等。
智能体根据需求自主选择工具并发起调用,例如查询"实时天气对农产品价格的影响"时,会先调用天气 API获取目标地区天气数据,再调用农产品价格数据库进行关联分析。
3.检索整合与初步生成(步骤 7-9)
工具调用完成后,系统会收集所有检索结果,整理为结构化上下文(Retrieved context),并与智能体重写后的查询结合,生成一份更全面的提示词(Prompt);将这份提示词输入 LLM,生成初步回签(Preliminary Response)
4.循环迭代: 自我评估与修正(步骤 10-12)
初步回答生成后,智能体并不会直接返回给用户而是启动二次评估流程:判断回答是否覆盖了用户需求的所有维度?是否存在信息冲突或逻辑漏洞?是否需要补充更多细节?
若评估不通过,智能体会回到之前的环节重新规划(如"重新调用另一个工具补充数据""优化查询关键词再次检索"),直到生成符合要求的最终回答。这种"评估-修正"的反馈循环,是 Agentic RAG 解决复杂问题的核心能力。
Agentic RAG 的核心特性:
优势:
复杂推理能力更强: 通过多步规划和工具调用0可处理多跳查询(如"分析 A 公司 2024 年 Q1净利润下降的原因,并预测其对 B行业的影响")和逻辑链较长的需求;
回答准确性更高: 自我评估和迭代修正机制大幅0降低了"幻觉回答"的概率,即使检索出现偏差也能通过后续步骤修正;
场景适应性更广: 支持多类型工具调用,可对接实时数据、结构化数据等,适用于金融分析、科研辅助、企业决策等复杂场景;
过程可追溯性更好: 智能体的"思考过程"(如查)询重写记录、工具调用日志)可完整留存,便于问题排查和结果解释。
局限:
系统复杂度显著提升: 需设计智能体的决策逻辑、工具调用接口、评估标准等,开发和调试成本更高;
响应延迟可能增加: 多轮迭代和工具调用会消耗更多时间,在对响应速度要求极高的场景(如实时客服)中需谨慎使用;
资源消耗更大: 频繁的 LLM 调用和工具请求会增加算力和 API成本,需做好资源管控。
三、深度对比: 传统 RAG与 Agentic RAG 的核心差异
为了更清晰地展现两种技术范式的区别,我们通过下表从7 个关键维度进行汇总分析:

总结: 选择适合场景的 RAG 技术
传统 RAG 作为 RAG 技术的"基石",凭借其简洁高效的特性,在简单问答、固定知识库查询、低延迟需求等场景中(如产品说明书问答、内部文档检索)仍具有不可替代的价值,是许多企业入门 RAG 技术的首选方案。
而 Agentic RAG 则代表了 RAG 技术的"进阶方向"--它通过赋予系统"智能体思维",突破了传统 RAG 的能力边界更适合复杂决策、跨数据源整合、高准确性要求的场景(如金融市场分析、科研文献综述、企业战略规划)
在实际应用中,两种技术并非"非此即彼"的关系:企业可根据需求场景灵活选择--对于简单需求采用传统 RAG 控制成本,对于复杂需求引入 Agentic RAG 提升能力:甚至可构建"混合架构",让智能体根据查询类型自动切换流程,实现"效率与能力"的平衡。
随着 LLM 能力的持续提升和工具生态的不断完善Agentic RAG 必将在更多高阶场景中落地应用,成为构建"强知识、高可靠、高自主"AI系统的核心技术之一。
更多AI大模型学习视频及资源,都在智泊AI。