用于糖尿病视网膜病变图像生成的GAN
本项目利用 TensorFlow 构建了一个生成对抗网络 (GAN),用于生成逼真的糖尿病视网膜病变 (DR) 图像。该 GAN 由基于 ResNet 的生成器和鉴别器组成。
资料来源
1. 数据集
结构:
/diabetic-retinopathy/
0/ -> 健康
1/ -> 轻度糖尿病视网膜病变
2/ -> 中度糖尿病视网膜病变
3/ -> 重度糖尿病视网膜病变
4/ -> 增生性糖尿病视网膜病变
4/ -> proliferative DR
分割:60% 用于训练,20% 用于验证,20% 用于测试
变量:train_paths、train_labels、val_paths、val_labels、test_paths、test_labels
图像尺寸调整为 128×128×3,并归一化为 -1, 1
- 预处理
python
def load_image(image_path):
img = tf.io.read_file(image_path)
img = tf.image.decode_jpeg(img, channels=3)
img = tf.image.resize(img, IMG_SIZE)
img = (tf.cast(img, tf.float32) - 127.5) / 127.5
return img
train_dataset = tf.data.Dataset.from_tensor_slices(train_paths)
train_dataset = train_dataset.map(load_image, num_parallel_calls=tf.data.AUTOTUNE)
train_dataset = train_dataset.shuffle(BUFFER_SIZE).batch(BATCH_SIZE).prefetch(tf.data.AUTOTUNE)3. GAN 架构
生成器(ResNet 风格)
输入随机噪声向量 (NOISE_DIM = 100)
通过 Conv2DTranspose + BatchNorm + LeakyReLU 进行上采样
使用 tanh 激活函数输出 128×128×3 的图像
生成器 = make_generator_model()
鉴别器(ResNet 风格)
输入 128×128×3 的图像
通过残差块 + AveragePooling2D 进行下采样
使用 S 型函数输出单个值(真实/虚假概率)
鉴别器 = build_discriminator(img_shape=(128,128,3))
4. 损失与优化器
python
cross_entropy = tf.keras.losses.BinaryCrossentropy(from_logits=True)
generator_optimizer = tf.keras.optimizers.Adam(1e-4, beta_1=0.5)
discriminator_optimizer = tf.keras.optimizers.Adam(1e-4, beta_1=0.5)生成器损失:它欺骗鉴别器的程度
鉴别器损失:它区分真假的能力
5. 训练步骤
python
@tf.function
def train_step(images):
noise = tf.random.normal([BATCH_SIZE, NOISE_DIM])
with tf.GradientTape() as gen_tape, tf.GradientTape() as disc_tape:
generated_images = generator(noise, training=True)
real_output = discriminator(images, training=True)
fake_output = discriminator(generated_images, training=True)
gen_loss = cross_entropy(tf.ones_like(fake_output), fake_output)
real_loss = cross_entropy(tf.ones_like(real_output), real_output)
fake_loss = cross_entropy(tf.zeros_like(fake_output), fake_output)
disc_loss = (real_loss + fake_loss) / 2
gradients_of_generator = gen_tape.gradient(gen_loss, generator.trainable_variables)
gradients_of_discriminator = disc_tape.gradient(disc_loss, discriminator.trainable_variables)
generator_optimizer.apply_gradients(zip(gradients_of_generator, generator.trainable_variables))
discriminator_optimizer.apply_gradients(zip(gradients_of_discriminator, discriminator.trainable_variables))
return gen_loss, disc_loss6. 训练循环
python
seed = tf.random.normal([NUM_EXAMPLES, NOISE_DIM])
for epoch in range(1, EPOCHS + 1):
for image_batch in train_dataset:
gen_loss, disc_loss = train_step(image_batch)
print(f"Epoch {epoch}, Generator Loss: {gen_loss:.4f}, Discriminator Loss: {disc_loss:.4f}")
generate_and_save_images(generator, epoch, seed)7. 可视化
生成的图像:每个 epoch 后
鉴别器置信度:绿色 = 真实,红色 = 虚假
python
preds = discriminator(fake_images, training=False).numpy()
pred_value = preds[i][0]
color = 'green' if pred_value > 0.5 else 'red'8. 测试/评估
GAN 不像分类器那样具有"准确性"。
检查生成图像的视觉质量。
生成图像的鉴别器置信度 (0-1)。
可选计算 FID(Fréchet 初始距离)进行定量评估。
注意:您可以根据 GPU 性能调整 IMG_SIZE、BATCH_SIZE 和 NOISE_DIM。
所需库
python
import os ,glob
import random
import warnings
import numpy as np # linear algebra
import pandas as pd # data processing
import matplotlib.pyplot as plt
from PIL import Image
from IPython.display import Image
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
import tensorflow as tf
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.models import Model
from sklearn.utils import shuffle
from tensorflow.keras import layers
from tensorflow.keras.utils import plot_model
from tensorflow.keras.layers import Dense, GlobalAveragePooling2D, Dropout
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.preprocessing import image
print("Library Called ")拆分数据并创建类
python
# Path of Data File
path='/input/diabetic-retinopathy'
if not os.path.exists(path):
print("Dataset folder not found at:", path)
print("Download and extract the dataset to that path.")
raise SystemExit(1)
#discover classes and image paths
class_dirs = sorted([d for d in os.listdir(path) if os.path.isdir(os.path.join(path, d))])
if not class_dirs:
print("No class subfolders found. Expect: data/diabetic_retinopathy/<class>/*.jpg")
raise SystemExit(1)
print("Found classes:", class_dirs)
# List after split (images , Labels)
image_paths = []
labels = []
for idx, cls in enumerate(class_dirs):
files = glob.glob(os.path.join(path, cls, "*"))
files = [f for f in files if os.path.splitext(f)[1].lower() in (".jpg", ".jpeg", ".png")]
for f in files:
image_paths.append(f)
labels.append(idx)
print("Total images:", len(image_paths))
if len(image_paths) == 0:
print("No images found - check paths.")
raise SystemExit(1)
#Combination and Random distribution
combined=list(zip(image_paths,labels))
random.seed(42)
random.shuffle(combined)
image_paths,labels = zip(*combined)
image_paths=list(image_paths)
labels=list(labels)
n =len(image_paths)
# ٍSplitting Fractions
train_frac = 0.60
val_frac = 0.20
n_train = int(n* train_frac)
n_val = int(n*val_frac)
n_test = n - n_train - n_val
train_paths = image_paths[:n_train]
train_labels =labels[:n_train]
val_paths = image_paths[n_train:n_train+n_val]
val_labels = labels[n_train:n_train+n_val]
test_paths = image_paths[n_train+n_val:]
test_labels = labels[n_train+n_val:]
print("Split sizes -> train:", len(train_paths), "val:", len(val_paths), "test:", len(test_paths))
dist = pd.DataFrame({
"train": pd.Series(train_labels).value_counts().sort_index(),
"val": pd.Series(val_labels).value_counts().sort_index(),
"test": pd.Series(test_labels).value_counts().sort_index()
}).fillna(0).astype(int)
print("\nClass distribution (by index):\n", dist)
python
Found classes: ['Healthy', 'Mild DR', 'Moderate DR', 'Proliferate DR', 'Severe DR']
Total images: 2750
Split sizes -> train: 1650 val: 550 test: 550
Class distribution (by index):
train val test
0 594 200 206
1 212 77 81
2 547 183 170
3 181 55 54
4 116 35 39GAN模型参数
python
# Parameters
BUFFER_SIZE = 60000
BATCH_SIZE = 128
NOISE_DIM = 100
# Hyperparameters
LATENT_DIM = 100
EPOCHS = 80
NUM_EXAMPLES = 16
IMG_SIZE = (128, 128)将它们转换为 TensorFlow 数据集
python
def load_image(image_path):
img = tf.io.read_file(image_path)
img = tf.image.decode_jpeg(img, channels=3)
img = tf.image.resize(img, IMG_SIZE)
img = (tf.cast(img, tf.float32) - 127.5) / 127.5 # Normalize [-1,1]
return img建立管道
python
# Build tf.data pipeline correctly
train_dataset = tf.data.Dataset.from_tensor_slices(train_paths)
train_dataset = train_dataset.map(load_image, num_parallel_calls=tf.data.AUTOTUNE)
train_dataset = train_dataset.shuffle(BUFFER_SIZE).batch(BATCH_SIZE).prefetch(tf.data.AUTOTUNE)
val_dataset = tf.data.Dataset.from_tensor_slices(val_paths)
val_dataset = val_dataset.map(load_image, num_parallel_calls=tf.data.AUTOTUNE)
val_dataset = val_dataset.batch(BATCH_SIZE).prefetch(tf.data.AUTOTUNE)
test_dataset = tf.data.Dataset.from_tensor_slices(test_paths)
test_dataset = test_dataset.map(load_image, num_parallel_calls=tf.data.AUTOTUNE)
test_dataset = test_dataset.batch(BATCH_SIZE)
python
for images in train_dataset.take(1): # take one batch
plt.figure(figsize=(10, 10))
for i in range(9):
ax = plt.subplot(3, 3, i + 1)
plt.imshow((images[i] * 127.5 + 127.5).numpy().astype("uint8"))
plt.axis("off")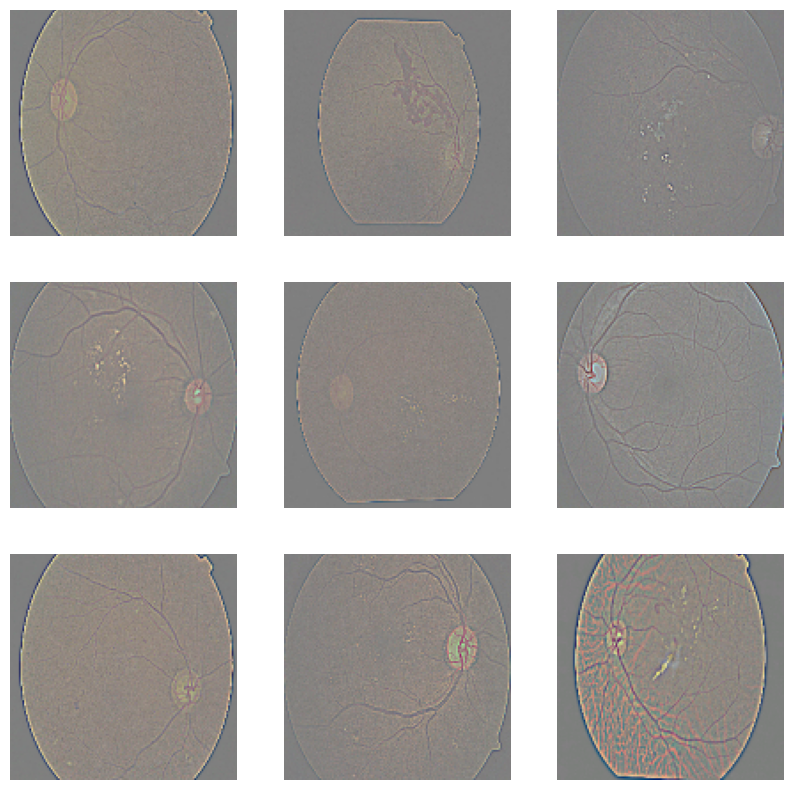
构建生成器
我们有两种选择来构建生成器(基于 ResNet 或从头开始制作生成器)
| 概念 | DCGAN 生成器(您的代码) | 基于 ResNet 的生成器(我的) |
|---|---|---|
| 架构类型 | 顺序堆叠的转置卷积层 | 带有跳跃连接的残差块 |
| 数据流 | 简单的向上卷积堆栈 | 每个块学习残差并加回到输入 |
| 跳跃连接 | ❌ 无跳跃连接(普通结构) | ✅ 使用 x + F(x) 来保持梯度流 |
| 梯度流 | 训练期间可能梯度消失或爆炸(对复杂数据稳定性较差) | 稳定得多(梯度可以通过跳跃连接"捷径"传播) |
| 图像质量 | 在简单数据集上效果良好 | 对于高分辨率或复杂图像效果更好 |
| 训练稳定性 | 中等;可能需要调整学习率 | 更高;通常收敛更平滑 |
| 模型灵活性 | 更易于实现;参数较少 | 更强大但稍显复杂 |
| 适用场景 | 用于小型、低分辨率数据集训练时 | 用于医学、真实感或高分辨率数据集训练时 |
首先构建块
python
def residual_block(x, filters):
shortcut = x
x = layers.Conv2D(filters, kernel_size=3, padding='same')(x)
x = layers.BatchNormalization()(x)
x = layers.ReLU()(x)
x = layers.Conv2D(filters, kernel_size=3, padding='same')(x)
x = layers.BatchNormalization()(x)
x = layers.add([shortcut, x])
x = layers.ReLU()(x)
return x构建生成器(接受噪声参数)
python
def build_generator(noise_dim):
inputs = layers.Input(shape=(noise_dim,))
x = layers.Dense(8 * 8 * 256, use_bias=False)(inputs)
x = layers.Reshape((8, 8, 256))(x)
x = layers.ReLU()(x)
# Residual blocks
for _ in range(3):
x = residual_block(x, 256)
# Upsampling layers
x = layers.Conv2DTranspose(128, 4, strides=2, padding='same')(x)
x = layers.ReLU()(x)
x = layers.Conv2DTranspose(64, 4, strides=2, padding='same')(x)
x = layers.ReLU()(x)
x = layers.Conv2DTranspose(32, 4, strides=2, padding='same')(x)
x = layers.ReLU()(x)
# Output
outputs = layers.Conv2D(3, (7,7), padding='same', activation='tanh')(x)
return Model(inputs, outputs, name="generator")
python
generator = build_generator(NOISE_DIM)
generator.summary()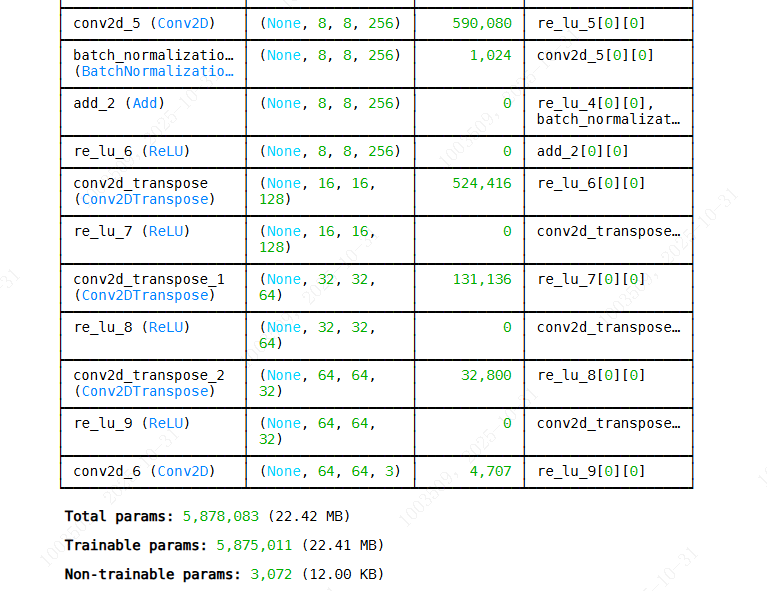
🧱构建判别器
python
def residual_block(x, filters, downsample=False):
shortcut = x
# First convolution
x = layers.Conv2D(filters, (3, 3), padding='same')(x)
x = layers.BatchNormalization()(x)
x = layers.LeakyReLU(alpha=0.2)(x)
# Second convolution
x = layers.Conv2D(filters, (3, 3), padding='same')(x)
x = layers.BatchNormalization()(x)
# Optionally downsample
if downsample:
x = layers.AveragePooling2D(pool_size=(2, 2))(x)
shortcut = layers.Conv2D(filters, (1, 1), padding='same')(shortcut)
shortcut = layers.AveragePooling2D(pool_size=(2, 2))(shortcut)
# Add skip connection
x = layers.add([x, shortcut])
x = layers.LeakyReLU(alpha=0.2)(x)
return x
def build_discriminator(img_shape=(128, 128, 3)):
inp = layers.Input(shape=img_shape)
x = layers.Conv2D(64, (7,7), strides=2, padding='same')(inp)
x = layers.LeakyReLU(alpha=0.2)(x)
# Residual blocks with downsampling
for filters in [64, 128, 256]:
x = residual_block(x, filters, downsample=True)
x = layers.GlobalAveragePooling2D()(x)
x = layers.Dense(1, activation='sigmoid')(x)
model = tf.keras.Model(inp, x, name="Discriminator")
return model
discriminator = build_discriminator()
discriminator.summary()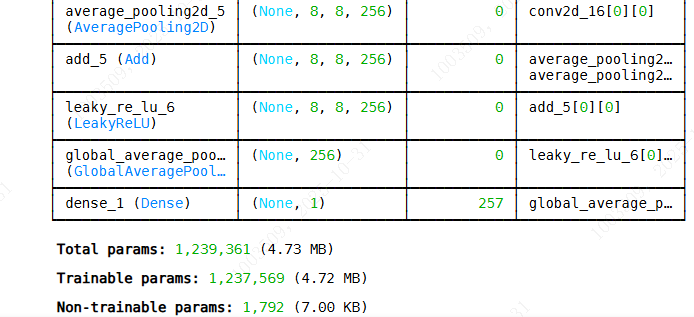
定义损失函数和优化器
python
cross_entropy = tf.keras.losses.BinaryCrossentropy(from_logits=True)
generator_optimizer = tf.keras.optimizers.Adam(1e-4) # => for generator
discriminator_optimizer = tf.keras.optimizers.Adam(1e-4) # => for Discriminator显示训练数据的随机样本
python
train_dataset = tf.data.Dataset.from_tensor_slices(train_paths)
train_dataset = train_dataset.map(load_image, num_parallel_calls=tf.data.AUTOTUNE)
train_dataset = train_dataset.shuffle(BUFFER_SIZE).batch(BATCH_SIZE)
# Take one batch from dataset
for image_batch in train_dataset.take(1):
sample_images = image_batch[:16] # first 16 images
break
# Denormalize from [-1,1] → [0,1] for display
sample_images = (sample_images + 1) / 2.0
# Plot them
plt.figure(figsize=(8, 8))
for i in range(16):
plt.subplot(4, 4, i + 1)
plt.imshow(sample_images[i])
plt.axis("off")
plt.suptitle("Random Samples from Training Data", fontsize=14)
plt.show()
生成器可视化

解决问题
python
noise = tf.random.normal([1, 100])
generated_image = generator(noise, training=False)
print(generated_image.shape)(1, 64, 64, 3)
python
layers.Conv2DTranspose(3, (5,5), strides=(2,2), padding='same', activation='tanh')这个版本输出 (128, 128, 3) --- 完美适合你的判别器
python
def make_generator_model():
model = tf.keras.Sequential([
layers.Dense(8*8*512, use_bias=False, input_shape=(100,)),
layers.BatchNormalization(),
layers.LeakyReLU(),
layers.Reshape((8, 8, 512)),
layers.Conv2DTranspose(256, (5,5), strides=(2,2), padding='same', use_bias=False),
layers.BatchNormalization(),
layers.LeakyReLU(), # 16x16
layers.Conv2DTranspose(128, (5,5), strides=(2,2), padding='same', use_bias=False),
layers.BatchNormalization(),
layers.LeakyReLU(), # 32x32
layers.Conv2DTranspose(64, (5,5), strides=(2,2), padding='same', use_bias=False),
layers.BatchNormalization(),
layers.LeakyReLU(), # 64x64
# 👇 ADD ONE MORE UPSAMPLING TO REACH 128x128
layers.Conv2DTranspose(32, (5,5), strides=(2,2), padding='same', use_bias=False),
layers.BatchNormalization(),
layers.LeakyReLU(), # 128x128
layers.Conv2DTranspose(3, (5,5), strides=(1,1), padding='same', use_bias=False, activation='tanh')
])
return model
python
# check again the output
generator = make_generator_model()
noise = tf.random.normal([1, 100])
print(generator(noise).shape)构建 Gans 模型
python
# Loss and optimizers
cross_entropy = tf.keras.losses.BinaryCrossentropy(from_logits=True)
generator_optimizer = tf.keras.optimizers.Adam(1e-4, beta_1=0.5)
discriminator_optimizer = tf.keras.optimizers.Adam(1e-4, beta_1=0.5)🧠 定义训练步骤
python
@tf.function
def train_step(images):
noise = tf.random.normal([BATCH_SIZE, NOISE_DIM])
with tf.GradientTape() as gen_tape, tf.GradientTape() as disc_tape:
generated_images = generator(noise, training=True)
real_output = discriminator(images, training=True)
fake_output = discriminator(generated_images, training=True)
# Losses
gen_loss = cross_entropy(tf.ones_like(fake_output), fake_output)
real_loss = cross_entropy(tf.ones_like(real_output), real_output)
fake_loss = cross_entropy(tf.zeros_like(fake_output), fake_output)
disc_loss = (real_loss + fake_loss) / 2
# Compute gradients
gradients_of_generator = gen_tape.gradient(gen_loss, generator.trainable_variables)
gradients_of_discriminator = disc_tape.gradient(disc_loss, discriminator.trainable_variables)
# Apply updates
generator_optimizer.apply_gradients(zip(gradients_of_generator, generator.trainable_variables))
discriminator_optimizer.apply_gradients(zip(gradients_of_discriminator, discriminator.trainable_variables))
return gen_loss, disc_loss定义函数以可视化结果
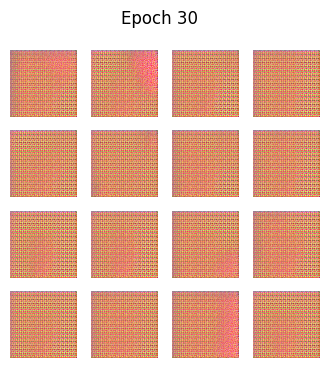
python
def generate_and_save_images(model, epoch, test_input):
predictions = model(test_input, training=False)
predictions = (predictions + 1) / 2.0 # back to [0,1]
fig = plt.figure(figsize=(4,4))
for i in range(predictions.shape[0]):
plt.subplot(4, 4, i+1)
plt.imshow(predictions[i])
plt.axis('off')
plt.suptitle(f"Epoch {epoch}")
plt.show()🧪 训练循环
python
seed = tf.random.normal([NUM_EXAMPLES, NOISE_DIM])
from tqdm import tqdm # => to display epochs when training
for epoch in range(1, EPOCHS + 1):
for image_batch in tqdm(train_dataset, desc=f"Epoch {epoch}/{EPOCHS}"):
gen_loss, disc_loss = train_step(image_batch)
print(f"Epoch {epoch}, Generator Loss: {gen_loss:.4f}, Discriminator Loss: {disc_loss:.4f}")
generate_and_save_images(generator, epoch, seed)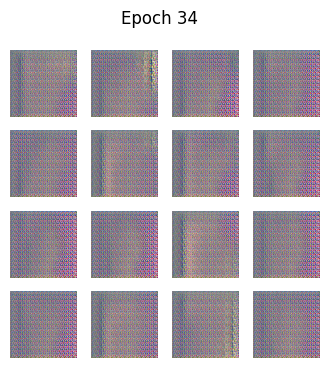


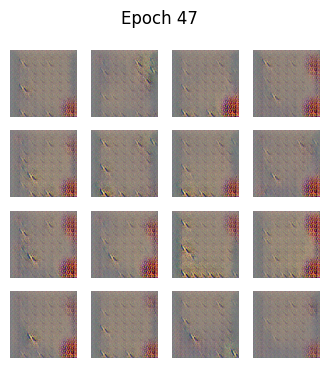





























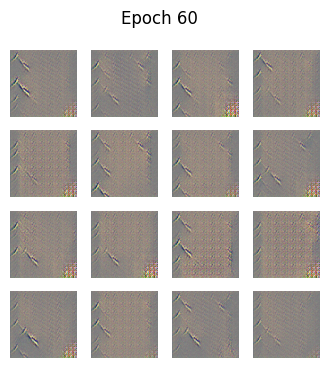



















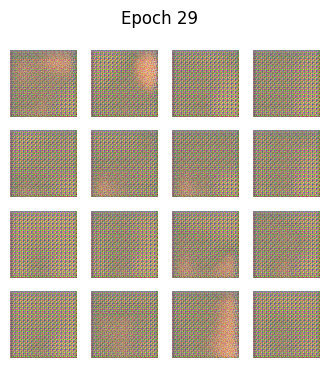

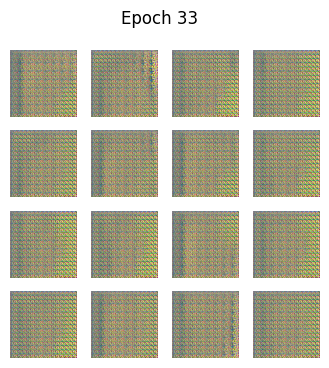

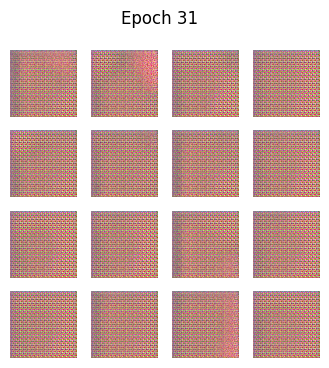








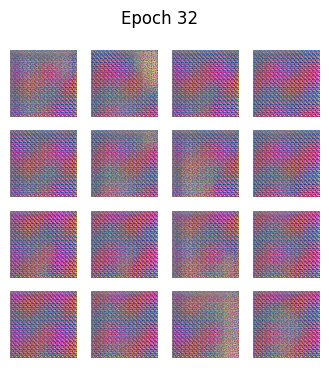





🎯 为什么GAN中没有"准确率"
在GAN中,你有两个模型:
-
- 生成器(G):尝试创建看起来真实的假图像。
-
- 判别器(D):尝试区分真实与虚假。
它们是对抗训练的:
-
- 当生成器成功欺骗判别器时,它会得到提升。
-
- 当判别器正确识别假图像时,它会得到提升。
因此,你追踪的是损失,而不是准确率:
-
- gen_loss → 生成器欺骗判别器的能力
-
- disc_loss → 判别器区分真伪的能力如果两者随时间稳定(而不是发散),说明训练在正常进行。
python
# Generate noise
noise = tf.random.normal([16, NOISE_DIM])
# Generate fake images
generated_images = generator(noise, training=False)
# Plot them
plt.figure(figsize=(4, 4))
for i in range(generated_images.shape[0]):
plt.subplot(4, 4, i + 1)
plt.imshow((generated_images[i] * 127.5 + 127.5).numpy().astype("uint8"))
plt.axis("off")
plt.show()
python
# Generate fake images
noise = tf.random.normal([100, NOISE_DIM])
fake_images = generator(noise, training=False)
# Discriminator output for generated images
predictions = discriminator(fake_images, training=False)
# Check how "real" the discriminator thinks they are
mean_pred = tf.reduce_mean(predictions).numpy()
print(f"Average discriminator confidence (real=1, fake=0): {mean_pred:.3f}")保存模型
python
generator.save('generator_model.h5')
discriminator.save('discriminator_model.h5')调用 CNN 模型
python
from tensorflow.keras.models import load_model
classifier = load_model('/input/cnn/keras/default/1/improved_dr_cnn.h5')下一步 分析与解读 🔍
python
N_SAMPLES = 500 # increase if you want
noise = tf.random.normal([N_SAMPLES, NOISE_DIM])
generated_images = generator(noise, training=False)
# recove the image to the real size
generated_images = (generated_images + 1) / 2.0
python
preds = classifier.predict(generated_images)
pred_labels = np.argmax(preds, axis=1)
python
class_names = ['Healthy', 'Mild DR', 'Moderate DR','Proliferate DR', 'Severe DR']
plt.figure(figsize=(12, 12))
for i in range(16):
plt.subplot(4, 4, i + 1)
plt.imshow(generated_images[i])
plt.title(class_names[pred_labels[i]])
plt.axis("off")
plt.suptitle("Predicted Classes for GAN Generated Images", fontsize=16)
plt.show()
上传 GAN 模型,训练轮次 = 100
python
generator = load_model("/input/gans-model/keras/epoch-100/1/generator_model.h5", compile=False)
discriminator = load_model("/input/gans-model/keras/epoch-100/1/discriminator_model.h5", compile=False)
python
NOISE_DIM = 100
NUM_IMAGES = 500
noise = tf.random.normal([NUM_IMAGES, NOISE_DIM])
generated_images = generator(noise, training=False)
generated_images = (generated_images + 1) / 2.0 # normalize to [0, 1]
print(f"✅ Generated {NUM_IMAGES} fake images from GAN")
python
# Resize if classifier expects a different size (224x224)
IMG_SIZE = classifier.input_shape[1]
generated_images_resized = tf.image.resize(generated_images, (IMG_SIZE, IMG_SIZE))
# Predict classes
predictions = classifier.predict(generated_images_resized)
pred_classes = np.argmax(predictions, axis=1)
python
# Class labels (edit if your CNN uses other labels)
class_names = ["Healthy", "Mild DR", "Moderate DR", "Proliferate DR","Severe DR"]
python
#Show sample images per class
n = 5 # show 5 samples per class
plt.figure(figsize=(15, 8))
for i, class_id in enumerate(unique):
idxs = np.where(pred_classes == class_id)[0][:n]
for j, idx in enumerate(idxs):
plt.subplot(len(unique), n, i * n + j + 1)
plt.imshow(generated_images[idx])
plt.axis("off")
if j == 0:
plt.ylabel(class_names[class_id], fontsize=12)
plt.suptitle("Example Generated Images by Predicted Class", fontsize=16)
plt.show()
python
IMG_SIZE = classifier.input_shape[1]
def preprocess_path(p):
img = tf.io.read_file(p)
img = tf.image.decode_jpeg(img, channels=3)
img = tf.image.resize(img, (IMG_SIZE, IMG_SIZE))
img = img / 255.0
return img
# Build val dataset if you have val_paths & val_labels
val_imgs = np.stack([preprocess_path(p).numpy() for p in val_paths])
preds_val = classifier.predict(val_imgs, batch_size=32)
pred_labels_val = np.argmax(preds_val, axis=1)
# report per-class accuracy
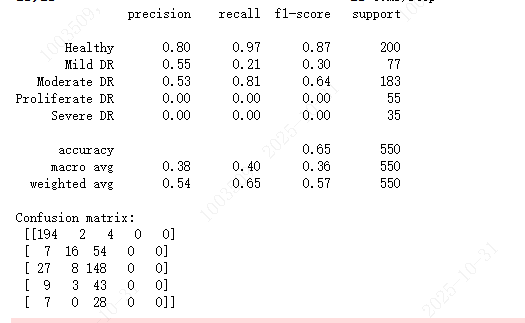
from sklearn.metrics import classification_report, confusion_matrix
print(classification_report(val_labels, pred_labels_val, target_names=class_names))
print("Confusion matrix:\n", confusion_matrix(val_labels, pred_labels_val))